Дисперсионный анализ
Дисперсионный анализ
Основные идеи Разбиение суммы квадратов Многофакторный дисперсионный анализ Эффекты взаимодействия Сложные планы Межгрупповые планы и планы повторных измерений Неполные (гнездовые) планы Ковариационный анализ (ANCOVA) Фиксированные ковариаты Переменные ковариаты Многомерные планы: многомерный дисперсионный и ковариационный анализ Межгрупповые планы Планы с повторными измерениями Суммы значений переменной и дисперсионного анализа Анализ контрастов и апостериорные критерии Почему сравниваютсяотдельные множества средних? Анализ контрастов Апостериорные критерии Предположения и эффекты их нарушения Нормальность распределения Однородность дисперсии Однородность дисперсии и ковариации Сферичность и сложная симметрия Методы дисперсионного анализа
Этот раздел содержит вводный обзор и обсуждение некоторых методов дисперсионного анализа, включая планы с повторными измерениями, ковариационный анализ, многомерный дисперсионный анализ, несбалансированные и вложенные планы, эффекты контрастов, апостериорные сравнения и др. Дополнительно, можно обратиться к разделу Компоненты дисперсии (разделы связанные с оцениванием компонент дисперсии в смешанных планах), Планирование эксперимента (разделы связанные со специальными областями применения дисперсионного анализа в промышленных условиях), а также Анализ повторяемости и воспроизводимости (разделы, относящиеся к оцениванию надежности и точности измерительных систем).
Основные идеи
Разбиение суммы квадратов
Многофакторный дисперсионный анализ
Эффекты взаимодействия
Сложные планы
Межгрупповые планы и планы повторных измерений
Неполные (гнездовые) планы
Ковариационный анализ (ANCOVA)
Фиксированные ковариаты
Переменные ковариаты
Многомерные планы: многомерный дисперсионный и ковариационный анализ
Межгрупповые планы
Планы с повторными измерениями
Суммы значений переменной и дисперсионного анализа
Анализ контрастов и апостериорные критерии
Почему сравниваютсяотдельные множества средних?
Анализ контрастов
Апостериорные критерии
Предположения и эффекты их нарушения
Нормальность распределения
Однородность дисперсии
Однородность дисперсии и ковариации
Сферичность и сложная симметрия
Методы дисперсионного анализа
Этот раздел содержит вводный обзор и обсуждение некоторых методов дисперсионного анализа, включая планы с повторными измерениями, ковариационный анализ, многомерный дисперсионный анализ, несбалансированные и вложенные планы, эффекты контрастов, апостериорные сравнения и др.
Дополнительно, можно обратиться к разделу Компоненты дисперсии (разделы связанные с оцениванием компонент дисперсии в смешанных планах), Планирование эксперимента ( разделы связанные со специальными областями применения дисперсионного анализа в промышленных условиях), а также Анализ повторяемости и воспроизводимости (разделы, относящиеся к оцениванию надежности и точности измерительных систем).
Основные идеи
Цель дисперсионного анализа.
Основной целью дисперсионного анализа является исследование значимости различия между средними. Раздел Элементарные понятия статистики содержит краткое введение в исследование статистической значимости. Если вы просто сравниваете средние в двух выборках, дисперсионный анализ даст тот же результат, что и обычный t-критерий для независимых выборок (если сравниваются две независимые группы объектов или наблюдений) или t-критерий для зависимых выборок (если сравниваются две переменные на одном и том же множестве объектов или наблюдений). Если вы не достаточно знакомы с этими критериями, рекомендуем обратиться к разделу Основные статистики и таблицы.
Откуда произошло название Дисперсионный анализ? Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними двух (или нескольких) групп, мы на самом деле сравниваем (т.е. анализируем) выборочные дисперсии. Фундаментальная концепция дисперсионного анализа предложена Фишером в 1920 году. Возможно, более естественным был бы термин анализ суммы квадратов или анализ вариации, но в силу традиции употребляется термин дисперсионный анализ.
Разбиение суммы квадратов
Многофакторный дисперсионный анализ
Эффекты взаимодействия
Также смотрите разделы.
Сложные планы
Ковариационный анализ (ANCOVA)
Многомерные планы: многомерный дисперсионный и ковариационный анализ
Анализ контрастов и апостериорные критерии
Предположения и эффекты их нарушения
См.
также Методы дисперсионного анализа, Компоненты дисперсии и смешанная модель ANOVA/ANCOVA, а также Планироване эксперимента.
Разбиение суммы квадратов
Разбиение суммы квадратов
Для выборки объема n выборочная дисперсия вычисляется как сумма квадратов отклонений от выборочного среднего, деленная на n-1 (объем выборки минус единица). Таким образом, при фиксированном объеме выборки n дисперсия есть функция суммы квадратов (отклонений), обозначаемая, для краткости, SS (от английского Sum of Squares - Сумма квадратов). Далее слово выборочная мы часто опускаем, прекрасно понимая, что рассматривается выборочная дисперсия или оценка дисперсии. В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Рассмотрим следующий набор данных:
Таблица 1
Таблица 1
| 2 3 1 |
6 7 5 |
| 2 2 |
6 2 |
| 4 28 |
|
Таблица 2
Таблица 2
| 24.0 4.0 |
1 4 |
24.0 1.0 |
24.0 |
.008 |
Как видно из таблицы, общая сумма квадратов SS = 28 разбита на компоненты: сумму квадратов, обусловленную внутригрупповой изменчивостью (2+2=4; см.
вторую строку таблицы) и сумму квадратов, обусловленную различием средних значений между группами (28-(2+2)=24; см первую строку таблицы). Заметим, что MS в этой таблице есть средний квадрат, равный SS, деленная на число степеней свободы (ст.св).
SS ошибок и SS эффекта. Внутригрупповая изменчивость (SS) обычно называется остаточной компонентой или дисперсией ошибки. Это означает, что обычно при проведении эксперимента она не может быть предсказана или объяснена. С другой стороны, SS эффекта (или компоненту дисперсии между группами) можно объяснить различием между средними значениями в группах. Иными словами, принадлежность к некоторой группе объясняет межгрупповую изменчивость, т.к. нам известно, что эти группы обладают разными средними значениями.
Проверка значимости. Основные идеи проверки статистической значимости обсуждаются в разделе Элементарные понятия статистики. В этом же разделе объясняются причины, по которым многие критерии используют отношение объясненной и необъясненной дисперсии. Примером такого использования является сам дисперсионный анализ. Проверка значимости в дисперсионном анализе основана на сравнении компоненты дисперсии, обусловленной межгрупповым разбросом (называемой средним квадратом эффекта или MSэффект) и компоненты дисперсии, обусловленной внутригрупповым разбросом (называемой средним квадратом ошибки или MSошибка; эти термины были впервые использованы в работе Edgeworth, 1885). Если верна нулевая гипотеза (равенство средних в двух популяциях), то можно ожидать сравнительно небольшое различие выборочных средних из-за чисто случайной изменчивости. Поэтому, при нулевой гипотезе, внутригрупповая дисперсия будет практически совпадать с общей дисперсией, подсчитанной без учета групповой принадлежности. Полученные внутригрупповые дисперсии можно сравнить с помощью F-критерия, проверяющего, действительно ли отношение дисперсий значимо больше 1. В рассмотренном выше примере F-критерий показывает, что различие между средними статистически значимо (значимо на уровне 0.008).
Основная логика дисперсионного анализа. Подводя итоги, можно сказать, что целью дисперсионного анализа является проверка статистической значимости различия между средними (для групп или переменных). Эта проверка проводится с помощью разбиения суммы квадратов на компоненты, т.е. с помощью разбиения общей дисперсии (вариации) на части, одна из которых обусловлена случайной ошибкой (то есть внутригрупповой изменчивостью), а вторая связана с различием средних значений. Последняя компонента дисперсии затем используется для анализа статистической значимости различия между средними значениями. Если это различие значимо, нулевая гипотеза отвергается и принимается альтернативная гипотеза о существовании различия между средними.
Зависимые и независимые переменные. Переменные, значения которых определяется с помощью измерений в ходе эксперимента (например, балл, набранный при тестировании), называются зависимыми переменными. Переменные, которыми можно управлять при проведении эксперимента (например, методы обучения или другие критерии, позволяющие разделить наблюдения на группы или классифицировать) называются факторами или независимыми переменными. Более подробно эти понятия описаны в разделе Элементарные понятия статистики.
Многофакторный дисперсионный анализ
Многофакторный дисперсионный анализ
В рассмотренном выше простом примере вы могли бы сразу вычислить t-критерий для независимых выборок, используя соответствующую опцию модуля Основные статистики и таблицы. Полученные результаты, естественно, совпадут с результатами дисперсионного анализа. Однако дисперсионный анализ содержит гораздо более гибкие и мощные технические средства, позволяющие исследовать планы практически неограниченной сложности.
Множество факторов.
Множество факторов.
Мир по своей природе сложен и многомерен. Ситуации, когда некоторое явление полностью описывается одной переменной, чрезвычайно редки. Например, если мы пытаемся научиться выращивать большие помидоры, следует рассматривать факторы, связанные с генетической структурой растений, типом почвы, освещенностью, температурой и т.д.
Таким образом, при проведении типичного эксперимента приходится иметь дело с большим количеством факторов. Основная причина, по которой использование дисперсионного анализа предпочтительнее повторного сравнения двух выборок при разных уровнях факторов с помощью серий t-критерия, заключается в том, что дисперсионный анализ существенно более эффективен и, для малых выборок, более информативен. Вам нужно сделать определенные усилия, чтобы овладеть техникой дисперсионного анализа, реализованной на STATISTICA, и ощутить все ее преимущества в конкретных исследованиях.
Управление факторами. Предположим, что в рассмотренном выше примере анализа двух выборок мы добавим еще один фактор, например, Пол - Gender. Пусть каждая группа теперь состоит из 3 мужчин и 3 женщин. План этого эксперимента можно представить в виде таблицы 2 на 2:
Таблица 3
Таблица 3
| 2 3 1 |
6 7 5 |
| 2 | 6 |
| 4 5 3 |
8 9 7 |
| 4 | 8 |
Итак, при введении дополнительного фактора: пол, остаточная дисперсия уменьшилась. Это связано с тем, что среднее значение для мужчин меньше, чем среднее значение для женщин, и это различие в средних значениях увеличивает суммарную внутригрупповую изменчивость, если фактор пола не учитывается. Управление дисперсией ошибки увеличивает чувствительность (мощность) критерия. На этом примере видно еще одно преимущество дисперсионного анализа по сравнению с обычным t-критерием для двух выборок. Дисперсионный анализ позволяет изучать каждый фактор, управляя значениями других факторов. Это, в действительности, и является основной причиной его большей статистической мощности (для получения значимых результатов требуются меньшие объемы выборок). По этой причине дисперсионный анализ даже на небольших выборках дает статистически более значимые результаты, чем простой t-критерий.
Эффекты взаимодействия
Существует еще одно преимущество дисперсионного анализа перед обычным t-критерием: дисперсионный анализ позволяет обнаружить эффекты взаимодействия между факторами и, поэтому, позволяет проверять более сложные гипотезы. Рассмотрим еще один пример, иллюстрирующий только что сказанное. (Термин взаимодействие впервые был использован Фишером в работе Fisher, 1926)
Главные эффекты, попарные (двухфакторные) взаимодействия.
Главные эффекты, попарные (двухфакторные) взаимодействия.
Предположим, что имеется две группы студентов, причем психологически студенты первой группы настроены на выполнение поставленных задач и более целеустремленны, чем студенты второй группы, состоящей из более ленивых студентов. Разобьем каждую группу случайным образом пополам и предложим одной половине в каждой группе сложное задание, а другой - легкое. После этого измерим, насколько напряженно студенты работают над этими заданиями. Средние значения для этого (вымышленного) исследования показаны в таблице:
Таблица 4
Таблица 4
| 10 5 |
5 10 |
Какой вывод можно сделать из этих результатов? Можно ли заключить, что: (1) над сложным заданием студенты трудятся более напряженно; (2) честолюбивые студенты работают упорнее, чем ленивые? Ни одно из этих утверждений не отражает сущность систематического характера средних, приведенных в таблице. Анализируя результаты, правильнее было бы сказать, что над сложными заданиями работают упорнее только честолюбивые студенты, в то время как над легкими заданиями только ленивые работают упорнее. Другими словами характер студентов и сложность задания взаимодействуя между собой влияют на затрачиваемое усилие. Это является примером попарного взаимодействия между характером студентов и сложностью задания. Заметим, что утверждения 1 и 2 описывают главные эффекты.
Взаимодействия высших порядков. В то время как объяснить попарные взаимодействия еще сравнительно легко, взаимодействия высших порядков объяснить значительно сложнее. Представьте, что в рассматриваемый выше пример, введен еще один фактор пол и получена следующая таблица средних значений:
Таблица 5
Таблица 5
| 10 5 |
5 10 |
| 1 6 |
6 1 |
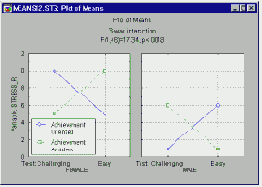
Глядя на график, можно сказать, что у женщин существует взаимодействие между характером и сложностью теста: целеустремленные женщины работают над трудным заданием более напряженно, чем над легким. У мужчин то же взаимодействие носит обратный характер. Видно, что описание взаимодействия между факторами становится более запутанным.
Общий способ описания взаимодействий. В общем случае взаимодействие между факторами описывается в виде изменения одного эффекта под воздействием другого.
В рассмотренном выше примере двухфакторное взаимодействие можно описать как изменение главного эффекта фактора, характеризующего сложность задачи, под воздействием фактора, описывающего характер студента. Для взаимодействия трех факторов из предыдущего параграфа можно сказать, что взаимодействие двух факторов (сложности задачи и характера студента) изменяется под воздействием Пола. Если изучается взаимодействие четырех факторов, можно сказать, что взаимодействие трех факторов, изменяется под воздействием четвертого фактора, т.е. существуют различные типы взаимодействий на разных уровнях четвертого фактора. Оказалось, что во многих областях взаимодействие пяти или даже большего количества факторов не является чем-то необычным.
| В начало |
Сложные планы
Сложные планы
В этом разделе будет дан обзор основных "кирпичиков", из которых строятся сложные планы. Межгрупповые планы и планы повторных измерений Неполные (гнездовые) планы Для просмотра других разделов Вводного обзора выберите соответствующее название ниже. Основные идеи Ковариационный анализ (ANCOVA) Многомерные планы: дисперсионный и ковариационный анализ Аналих контрастов и апостериорные критерии Предположения и последствия их нарушения См. также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование экспермента.
Межгрупповые планы и планы с повторными измерениями
Межгрупповые планы и планы с повторными измерениями
При сравнении двух различных групп обычно используется t-критерий для независимых выборок (из модуля Основные статистики и таблицы). Когда сравниваются две переменные на одном и том же множестве объектов (наблюдений), используется t-критерий для зависимых выборок. Для дисперсионного анализа также важно зависимы или нет выборки. Если имеются повторные измерения одних и тех же переменных (при разных условиях или в разное время) для одних и тех же объектов, то говорят о наличии фактора повторных измерений (называемого также внутригрупповым фактором, поскольку для оценки его значимости вычисляется внутригрупповая сумма квадратов).
Если сравниваются разные группы объектов (например, мужчины и женщины, три штамма бактерий и т.п.), то разница между группами описывается межгрупповым фактором. Способы вычисления критериев значимости для двух описанных типов факторов различны, но общая их логика и интерпретации совпадает.
Меж- и внутригрупповые планы. Во многих случаях эксперимент требует включение в план и межгруппового фактора, и фактора повторных измерений. Например, измеряются математические навыки студентов женского и мужского пола (где пол -межгрупповой фактор) в начале и в конце семестра. Два измерения навыков каждого студента образуют внутригрупповой фактор (или фактор с повторными измерениями). Интерпретация главных эффектов и взаимодействий для межгрупповых факторов и факторов повторных измерений совпадает, и оба типа факторов могут, очевидно, взаимодействовать между собой (например, женщины приобретают навыки в течение семестра, а мужчины их теряют).
Неполные (гнездовые) планы
Неполные (гнездовые) планы
Во многих случаях можно пренебречь эффектом взаимодействия. Это происходит или когда известно, что в популяции эффект взаимодействия отсутствует, или когда осуществление полного факторного плана невозможно. Например, пусть изучается влияние четырех добавок к топливу на расход горючего. Выбираются четыре автомобиля и четыре водителя. Полный факторный эксперимент требует, чтобы каждая комбинация: добавка, водитель, автомобиль - появились хотя бы один раз. Для этого нужно не менее 4 x 4 x 4 = 64 групп испытаний, что требует слишком больших временных затрат. Кроме того, вряд ли существует взаимодействие между водителем и добавкой к топливу. Принимая это во внимание, можно использовать план типа Латинские квадраты, в котором содержится лишь 16 групп испытаний (четыре добавки обозначаются буквами A, B, C и D):
Таблица 6
Таблица 6
| A B C D |
B C D A |
C D A B |
D A B C |
Латинские квадраты описаны в большинстве книг по планированию экспериментов (например, Hays, 1988; Lindman, 1974; Milliken and Johnson, 1984; Winer, 1962), и здесь они не будут детально обсуждаться. Отметим, что латинские квадраты это неnолные планы, в которых участвуют не все комбинации уровней факторов. Например, водитель 1 управляет автомобилем 1 только с добавкой А, водитель 3 управляет автомобилем 1 только с добавкой С. Уровни фактора добавки (A, B, C и D) вложены в ячейки таблицы автомобиль x водитель как яйца в гнезда. Это мнемоническое правило полезно для понимания природы гнездовых планов. Модуль Дисперсионный анализ предоставляет простые способы анализ планов такого типа.
Отметим, что анализ планов такого типа возможен и в некоторых других модулях системы STATISTICA. Подробнее см. в разделе Методы дисперсионного анализа. В частности, модуль Компоненты дисперсии и смешанные модели ANOVA/ANCOVA очень эффективен при анализе планов с несбалансированной вложенностью (т.е. когда вложенные факторы имеют различное число уровней при разных уровнях факторов, в которые они вложены), очень больших гнездовых планов (например, с общим числом уровней более 200) или иерархически вложенных планов (содержащих или не содержащих случайные факторы).
| В начало |
Ковариационный анализ (ANCOVA)
Ковариационный анализ (ANCOVA)
Основная идея
В разделе Основные идеи кратко обсуждалась идея управления факторами и то, каким образом включение аддитивных факторов позволяет уменьшить остаточную сумму квадратов и увеличить статистическую мощность плана. Все это может быть распространено и на переменные с непрерывным множеством значений. Когда такие непрерывные переменные включаются в план в качестве факторов, они называются ковариатами. Фиксированные ковариаты Переменные ковариаты Для просмотра других разделов Вводного обзора выберите соответствующее название ниже. Основные идеи Сложные планы Многомерные планы: многомерный дисперсионный и ковариационный анализ Анализ контрастов и апостериорные критерии Предположения и последствия их нарушения См.
также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование эксперимента.
Фиксированные ковариаты
Фиксированные ковариаты
Предположим, что сравниваются математические навыки двух групп студентов, которые обучались по двум различным учебникам. Предположим также, что имеются дополнительные данные о коэффициенте интеллекта (IQ) каждого студента. Можно предположить, что коэффициент интеллекта связан с математическими навыками, и использовать эту информацию. Для каждой из двух групп студентов можно вычислить коэффициент корреляции между IQ и математическими навыками (см. Основные статистики и таблицы). Используя этот коэффициент корреляции, можно выделить долю дисперсии в группах, объясняемую IQ и необъясняемую долю дисперсии (см. также Элементарные понятия статистики и Основные статистики и таблицы). Оставшаяся доля дисперсии используется при проведении анализа как дисперсия ошибки. Если имеется корреляция между IQ и математическими навыками, то таким образом можно существенно уменьшить дисперсию ошибки SS/(n-1).
Влияние ковариат на F критерий. F критерий оценивает статистическую значимость различия средних в группах, при этом вычисляется отношение межгрупповой дисперсии (MSошибка) к дисперсии ошибок (MSошибка). Если MSошибка уменьшается, например, при учете фактора IQ, значение F увеличивается.
Множество ковариат. Рассуждения, использованные выше для одной ковариаты (IQ), легко распространяются на несколько ковариат. Например, кроме IQ, можно включить измерение мотивации, пространственного мышления и т.д. Вместо обычного коэффициента корреляции при этом используется множественный коэффициент корреляции (см. раздел Множественная регрессия).
Когда значение F-критерия уменьшается. Иногда введение ковариат в план эксперимента уменьшает значение F-критерия. Обычно это указывает на то, что ковариаты коррелированы не только с зависимой переменной (например, математическими навыками), но и с факторами (например, с разными учебниками).
Предположим, что IQ измеряется в конце семестра, после почти годового обучения двух групп студентов по двум разным учебникам. Хотя студенты разбивались на группы случайным образом, может оказаться, что различие учебников настолько велико, что и IQ и математические навыки в разных группах будут сильно различаться. В этом случае, ковариаты не только уменьшают дисперсию ошибок, но и межгрупповую дисперсию. Другими словами, после контроля за разностью IQ в разных группах, разность в математических навыках уже будет несущественной. Ту же мысль можно выразить иначе: после "исключения" влияния IQ, неумышленно исключается и влияние учебника на развитие математических навыков.
Скорректированные средние. Когда ковариата влияет на межгрупповой фактор, следует вычислять скорректированные средние, т.е. такие средние, которые получаются после удаления всех оценок ковариат.
Взаимодействие между ковариатами и факторами. Также как исследуется взаимодействие между факторами, можно исследовать взаимодействия между ковариатами и группами факторов. Предположим, что один из учебников особенно подходит для умных студентов. Второй учебник для умных студентов скушен, а для менее умных студентов этот же учебник труден. В результате имеется положительная корреляция между IQ и результатом обучения в первой группе (более умные студенты, лучше результат) и нулевая или небольшая отрицательная корреляция во второй группе (чем умнее студент, тем менее вероятно приобретение математических навыков из второго учебника). В некоторых исследованиях эта ситуация обсуждается как пример нарушения предположений ковариационного анализа (см. Предположения и последствия их нарушения). Однако так как в модуле Дисперсионный анализ используются самые общие способы ковариационного анализа, можно, в частности, оценить статистическую значимость взаимодействия между факторами и ковариатами.
Переменные ковариаты
Переменные ковариаты
В то время как фиксированные ковариаты обсуждаются в учебниках достаточно часто, переменные ковариаты упоминаются намного реже.
Обычно, при проведении экспериментов с повторными измерениями, нас интересуют различия в измерениях одних и тех же величин в разные моменты времени. А именно, нас интересует значимость этих различий. Если одновременно с измерениями зависимых переменных проводится измерение ковариат, можно вычислить корреляцию между ковариатой и зависимой переменной. Например, можно изучать интерес к математике и математические навыки в начале и в конце семестра. Интересно было бы проверить, коррелированы ли между собой изменения в интересе к математике с изменением математических навыков. Модуль Дисперсионный анализ в STATISTICA автоматически оценивает статистическую значимость изменения ковариат в тех планах, где это возможно.
| В начало |
Многомерные планы: Многомерный дисперсионный и ковариационный анализ Межгрупповые планы Планы с повторными измерениями Суммы значений переменной и многомерный дисперсионный анализ Для просмотра других обзорных разделов выберите соответствующее название ниже. Основные идеи Сложные планы Ковариационный анализ (ANCOVA) Анализ контрастов и апостериорные критерии Предположения и последствия их нарушения См. также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование эксперимента.
Межгрупповые планы
Межгрупповые планы
Все рассматриваемые ранее примеры включали только одну зависимую переменную. Когда одновременно имеется несколько зависимых переменных, возрастает лишь сложность вычислений, а содержание и основные принципы не меняются. Например, проводится исследование двух различных учебников. При этом изучаются успехи студентов в изучении физики и математики. В этом случае имеются две зависимые переменные и нужно выяснить, как влияют на них одновременно два разных учебника. Для этого можно воспользоваться многомерным дисперсионным анализом (MANOVA). Вместо одномерного F критерия, используется многомерный F критерий (лямбда-критерий Уилкса), основанный на сравнении ковариационной матрицы ошибок и межгрупповой ковариационной матрицы.
Если зависимые переменные коррелированы между собой, то эта корреляция должна учитываться при вычислении критерия значимости. Очевидно, если одно и то же измерение повторяется дважды, то ничего нового получить при этом нельзя. Если к имеющемуся измерению добавляется коррелированное с ним измерение, то получается некоторая новая информация, но при этом новая переменная содержит избыточную информацию, которая отражается в ковариации между переменными.
Интерпретация результатов. Если общий многомерный критерий значим, можно заключить, что соответствующий эффект (например, тип учебника) значим. Однако встают следующие вопросы. Влияет ли тип учебника на улучшение только математических навыков, только физических навыков, или одновременно на улучшение тех и других навыков. В действительности, после получения значимого многомерного критерия, для отдельного главного эффекта или взаимодействия исследуются одномерные F-критерии. Другими словами, отдельно исследуются зависимые переменные, которые вносят вклад в значимость многомерного критерия.
Планы с повторными измерениями
Планы с повторными измерениями
Если измеряются математические и физические навыки студентов в начале семестра и в конце семестра, то это и есть повторные измерения. Изучение критерия значимости в таких планах это логическое развитие одномерного случая. Заметим, что методы многомерного дисперсионного анализа обычно также используются для исследования значимости одномерных факторов повторных измерений, имеющих более чем два уровня. Соответствующие применения будут рассмотрены позднее в этой части.
Суммы значений переменной и дисперсионный анализ
Суммы значений переменной и дисперсионный анализ
Даже опытные пользователи одномерного и многомерного дисперсионного анализа часто приходят в затруднение, получая разные результаты при применении многомерного дисперсионного анализа, например, для трех переменных, и при применении одномерного дисперсионного анализа к сумме этих трех переменных, как к одной переменной.
Идея суммирования переменных состоит в том, что каждая переменная содержит в себе некоторую истинную переменную, которая и исследуется, а также случайную ошибку измерения. Поэтому при усреднении значений переменных, ошибка измерения будет ближе к 0 для всех измерений и усредненное значений будет более надежным. На самом деле, в этом случае применение дисперсионного анализа к сумме переменных разумно и является мощным методом. Однако, если зависимые переменные по своей природе многомерны, то суммирование неуместно. Например, пусть зависимые переменные состоят из четырех показателей успеха в обществе. Каждый показатель характеризует совершенно независимую сторону человеческой деятельности (например, профессиональный успех, преуспевание в бизнесе, семейное благополучие и т.д.). Сложение этих переменных подобно сложению яблока и апельсина. Сумма этих переменных не будет подходящим одномерным показателем. Поэтому с такими данными нужно обходится как с многомерными показателями в многомерном дисперсионном анализе.
| В начало |
Анализ контрастов и апостериорные критерии Почему сравниваютсяотдельные множества средних? Анализ контрастов Апостериорные критерии Для просмотра других обзорных разделов выберите соответствующее название ниже. Основные идеи Сложные планы Ковариационный анализ (ANCOVA) Многомерные планы: многомерный дисперсионный и ковариационный анализ Предположения и последствия их нарушения См. также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование эксперимента.
Анализ контрастов и апостериорные критерии Почему сравниваютсяотдельные множества средних? Анализ контрастов Апостериорные критерии Для просмотра других обзорных разделов выберите соответствующее название ниже. Основные идеи Сложные планы Ковариационный анализ (ANCOVA) Многомерные планы: многомерный дисперсионный и ковариационный анализ Предположения и последствия их нарушения См. также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование эксперимента.
Почему сравниваются отдельные множества средних?
Почему сравниваются отдельные множества средних?
Обычно гипотезы относительно экспериментальных данных формулируются не просто в терминах главных эффектов или взаимодействий. Примером может служить такая гипотеза: некоторый учебник повышает математические навыки только у студентов мужского пола, в то время как другой учебник примерно одинаково эффективен для обоих полов, но все же менее эффективен для мужчин. Можно предсказать, что эффективность учебника взаимодействует с полом студента. Однако этот прогноз касается также природы взаимодействия. Ожидается значительное различие между полами, обучающимися по одной книге, и практически не зависимые от пола результаты для обучающихся по другой книге. Такой тип гипотез обычно исследуется с помощью анализа контрастов.
Анализ контрастов
Анализ контрастов
Если говорить коротко, то анализ контрастов позволяет оценивать статистическую значимость некоторых линейных комбинаций факторов сложного плана. Анализ контрастов главный и обязательный элемент любого сложного плана дисперсионного анализа. Модуль Дисперсионный анализ имеет достаточно разнообразные возможности анализа контрастов, которые позволяют выделять и анализировать любые типы сравнений средних (способы задания контрастов описаны в разделе Примечания).
Апостериорные критерии
Апостериорные критерии
Иногда в результате обработки эксперимента обнаруживаются неожиданные различия в средних. Хотя в большинстве случаев творческий исследователь сможет объяснить эти различия, ему сложно провести дальнейший анализ. Эта проблема является одной из тех, для которых используются апостериорные критерии, то есть критерии, не использующие априорные гипотезы. Для иллюстрации рассмотрим следующий эксперимент. Предположим, что на 100 карточках записаны числа от 1 до 10. Опустив все эти карточки в шапку, мы случайным образом выбираем 20 раз по 5 карточек, и вычисляем для каждой выборки среднее значение (среднее чисел, записанных на карточки).
Можно ли ожидать, что найдется две выборки, у которых средние значения значимо отличаются? Это очень правдоподобно! Выбирая две выборки с максимальным и минимальным средним, можно получить разность средних значений, сильно отличающуюся от разности средних значений, например, первых двух выборок. Эту разность можно исследовать, например, с помощью анализа контрастов. Если не вдаваться в детали, то существует несколько, так называемых апостериорных критериев, которые основаны в точности на первом сценарии (взятие экстремальных средних из 20 выборок), т. е. эти критерии основаны на выборе наиболее отличающихся средних для сравнения всех средних значений в плане. Модуль Дисперсионный анализ предлагает широкий выбор таких критериев. Когда в эксперименте встречаются неожиданные результаты, то используются апостериорные процедуры для исследования их статистической значимости.
| В начало |
Предположения и последствия их нарушения
Предположения и последствия их нарушения
Отклонение от предположения о нормальности распределений Однородность дисперсии Однородность дисперсии и ковариаций Сферичность и сложная симметрия Для просмотра других обзорных разделов выберите соответствующее название ниже. Основные идеи Сложные планы Ковариационный анализ (ANCOVA) Многомерные планы: многомерный дисперсионный и ковариационный анализ Анализ контрастов и апостериорные критерии См. также Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование эксперимента.
Нормальность распределения
Нормальность распределения
Предположения.
Предположения.
Имеются следующие предположения дисперсионного анализа: зависимая переменная измерена в интервальной шкале (см. раздел Элементарные понятия статистики); зависимая переменная имеет нормальное распределение внутри каждой группы. Модуль Дисперсионный анализ содержит широкий набор графиков и статистик для проверки этих предположений.
Эффекты нарушения.
Эффекты нарушения.
Вообще F-критерий очень устойчив к отклонению от нормальности (подробнее см.
Lindman, 1974). Если эксцесс (см. Основные статистики и таблицы) больше 0, то значение статистики F может стать очень маленьким. Нулевая гипотеза при этом не может быть отвергнута, хотя она и не верна. Ситуация меняется на противоположную, если эксцесс меньше 0. Асимметрия распределения обычно незначительно влияет на F статистику. Если число наблюдений в ячейке достаточно большое, то отклонение от нормальности не имеет особого значения в силу центральной предельной теоремы, в соответствии с которой, распределение среднего значения при большом объеме выборки близко к нормальному, независимо от начального распределения. Подробное обсуждение устойчивости F статистики можно найти в Box and Anderson (1955) или Lindman (1974).
Однородность дисперсии
Однородность дисперсии
Предположения.
Предположения.
Предполагается, что дисперсии в разных группах одинаковы. Это предположение называется предположением об однородности дисперсии. Напомним, что в предыдущих разделах описывая вычисление суммы квадратов ошибок мы производили суммирование внутри каждой группы. Если дисперсии в двух группах отличаются друг от друга, то сложение их не естественно и не дает верной оценки общей внутригрупповой дисперсии (так как в этом случае общей дисперсии вообще не существует). Модуль Дисперсионный анализ -ANOVA/MANOVA содержит большой набор статистических критериев, позволяющих обнаружить неоднородность дисперсии.
Эффекты нарушения. Линдман (Lindman 1974, стр. 33) показывает, что F критерий вполне устойчив относительно нарушения предположений однородности дисперсии (см. также Box, 1954a, 1954b; Hsu, 1938).
Специальный случай: коррелированность средних и дисперсий. Бывают случаи, когда F статистика может вводить в заблуждение. Это бывает, когда в ячейках плана средние значения коррелированы с дисперсией. Модуль Дисперсионный анализ позволяет строить диаграммы рассеяния дисперсии или стандартного отклонения относительно средних для обнаружения такой корреляции. Причина, по которой такая корреляция опасна, состоит в следующем.
Представим себе, что имеется 8 ячеек в плане, 7 из которых имеют почти одинаковое среднее, а в одной ячейке среднее намного больше остальных. Тогда F критерий может обнаружить статистически значимый эффект. Но предположим, что в ячейке с большим средним значением и дисперсия значительно больше остальных, т.е. среднее значение и дисперсия в ячейках зависимы (чем больше среднее, тем больше дисперсия). В этом случае большое среднее значение ненадежно, так как оно может быть вызвано большой дисперсией данных. Однако F статистика, основанная на объединенной дисперсии внутри ячеек, будет фиксировать большое среднее, хотя критерии, основанные на дисперсии в каждой ячейке не все различия в средних будут считать значимыми.
Специальный случай: коррелированность средних и дисперсий. Бывают случаи, когда F статистика может вводить в заблуждение. Это бывает, когда в ячейках плана средние значения коррелированы с дисперсией. Модуль Дисперсионный анализ позволяет строить диаграммы рассеяния дисперсии или стандартного отклонения относительно средних для обнаружения такой корреляции. Причина, по которой такая корреляция опасна, состоит в следующем. Представим себе, что имеется 8 ячеек в плане, 7 из которых имеют почти одинаковое среднее, а в одной ячейке среднее намного больше остальных. Тогда F критерий может обнаружить статистически значимый эффект. Но предположим, что в ячейке с большим средним значением и дисперсия значительно больше остальных, т.е. среднее значение и дисперсия в ячейках зависимы (чем больше среднее, тем больше дисперсия). В этом случае большое среднее значение ненадежно, так как оно может быть вызвано большой дисперсией данных. Однако F статистика, основанная на объединенной дисперсии внутри ячеек, будет фиксировать большое среднее, хотя критерии, основанные на дисперсии в каждой ячейке не все различия в средних будут считать значимыми.
Такой характер данных (большое среднее и большая дисперсия) часто встречается, когда имеются резко выделяющиеся наблюдения.
Одно или два резко выделяющихся наблюдений сильно смещают среднее значение и очень увеличивают дисперсию.
Однородность дисперсии и ковариаций
Однородность дисперсии и ковариаций
Предположения.
Предположения.
В многомерных планах, с многомерными зависимыми измерениями, также применяются предположение об однородности дисперсии, описанные ранее. Однако так как существуют многомерные зависимые переменные, то требуется так же чтобы их взаимные корреляции (ковариации) были однородны по всем ячейкам плана. Модуль Дисперсионный анализ предлагает разные способы проверки этих предположений.
Эффекты нарушения.
Эффекты нарушения.
Многомерным аналогом F- критерия является лямбда-критерий Уилкса. Не так много известно об устойчивости (робастности) лямбда-критерия Уилкса относительно нарушения указанных выше предположений. Тем не менее, так как интерпретация результатов модуля Дисперсионный анализ основывается обычно на значимости одномерных эффектов (после установления значимости общего критерия), обсуждение робастности касается, в основном, одномерного дисперсионного анализа. Поэтому должна быть внимательно исследована значимость одномерных эффектов.
Специальный случай:ковариационный анализ.
Специальный случай:ковариационный анализ.
Особенно серьезные нарушения однородности дисперсии/ковариаций могут происходить, когда в план включаются ковариаты. В частности, если корреляция между ковариатами и зависимыми измерениями различна в разных ячейках плана, может последовать неверное истолкование результатов. Следует помнить, что в ковариационном анализе, в сущности, проводится регрессионный анализ внутри каждой ячейки для того, чтобы выделить ту часть дисперсии, которая соответствует ковариате. Предположение об однородности дисперсии/ковариации предполагает, что этот регрессионный анализ проводится при следующем ограничении: все регрессионные уравнения (наклоны) для всех ячеек одинаковы. Если это не выполняется, могут появиться большие ошибки. Модуль Дисперсионный анализ имеет несколько специальных критериев для проверки этого предположения.
Можно посоветовать использовать эти критерии, для того, чтобы убедиться, что регрессионные уравнения для различных ячеек примерно одинаковы.
Сферичность и сложная симметрия
Сферичность и сложная симметрия
Причины использования многомерного подхода к повторным измерениям в дисперсионном анализе. В планах, содержащих факторы повторных измерений с более чем двумя уровнями, применение одномерного дисперсионного анализа требует дополнительных предположений: предположения о сложной симметрии и о сферичности. Эти предположения редко выполняются (см. ниже). Поэтому в последние годы многомерный дисперсионный анализ завоевал популярность в таких планах (оба подхода совмещены в модуле Дисперсионный анализ). Предположение о сложной симметрии состоит в том, что дисперсии (общие внутригрупповые) и ковариации (внутри групп) для различных повторных измерений однородны (одинаковы). Это достаточное условие для того, чтобы одномерный F критерий для повторных измерений был обоснованным (т.е. выданные F-значения в среднем соответствовали F-распределению). Однако, в данном случае, это не условие не является необходимым. Условие сферичности является необходимым и достаточным условием для обоснованного применения F-критерия. Смысл условия состоит в том, что внутри групп все наблюдения должны быть независимы и одинаково распределены. Природа этих предположений, а также влияние их нарушений обычно не очень хорошо описаны в книгах по дисперсионному анализу. Мы даем это описание в следующих параграфах. Там же будет показано, что результаты одномерного подхода могут отличаться от результатов многомерного подхода, и будет объяснено, что это означает.
Необходимость независимости гипотез. Общий способ анализа данных в дисперсионном анализе - это подгонка модели. Если относительно модели, соответствующей данным, имеются некоторые априорные гипотезы, то дисперсия разбивается для проверки этих гипотез (проверка главных эффектов, взаимодействий). С вычислительной точки зрения этот подход строит некоторое множество контрастов (множество сравнений средних в плане).
Однако если контрасты не независимы друг от друга, то разбиение дисперсии на компоненты не имеет смысла. Например, если два контраста A и B тождественны, то соответственная им компонента дисперсии выделяется дважды. Например, глупо и бессмысленно выделять две гипотезы: "среднее в ячейке 1 выше среднего в ячейке 2" и "среднее в ячейке 1 выше среднего в ячейке 2". Итак, гипотезы должны быть независимы или ортогональны (термин ортогональность впервые использован в работе Yates, 1933).
Независимые гипотезы при повторных измерениях. Общий алгоритм, реализованный в модуле Дисперсионный анализ, будет пытаться для каждого эффекта генерировать независимые (ортогональные) контрасты (см. раздел Технические замечания руководства пользователя). Для фактора повторных измерений эти контрасты задают множество гипотез относительно разностей между уровнями рассматриваемого фактора. Однако если эти разности коррелированы внутри групп, то результирующие контрасты не являются больше независимыми. Например, в обучении, где обучающиеся измеряются три раза за один семестр, может случиться, что изменения между 1 и 2 измерением отрицательно коррелируют с изменением между 2 и 3 измерениями субъектов. Те, кто большую часть материала освоил между 1 и 2 измерениями, осваивают меньшую часть в течение того времени, которое прошло между 2 и 3 измерением. В действительности, для большинства случаев, где дисперсионный анализ используются при повторных измерениях, можно предположить, что изменения по уровням коррелированы по субъектам. Однако когда это происходит, предположение о сложной симметрии и сферичности не выполняются и независимые контрасты не могут быть вычислены.
Влияние нарушений и способы их исправления. Когда предположения о сложной симметрии или о сферичности не выполняются, дисперсионный анализ может выдать ошибочные результаты. До того, как были достаточно разработаны многомерные процедуры, было предложено несколько предположений для компенсации нарушений этих предположений. (См., например, работы Greenhouse & Geisser, 1959 и Huynh & Feldt, 1970).
Эти методы до сих пор широко используются (поэтому они представлены в модуле Дисперсионный анализ).
Подход многомерного дисперсионного анализа к повторным измерениям. В целом проблемы сложной симметрии и сферичности относятся к тому факту, что множества контрастов, включенных в исследование эффектов факторов повторных измерений (с числом уровней больше двух) не независимы друг от друга. Однако им не обязательно быть независимыми, если используется многомерный критерий для одновременной проверки статистического значимости двух или более контрастов фактора повторных измерений. Это является причиной того, что методы многомерного дисперсионного анализа стали чаще использоваться для проверки значимости факторов одномерных повторных измерений с более чем 2 уровнями. Этот подход широко распространен, так как он, в общем случае, не требует предположения о сложной симметрии и предположения о сферичности.
Случаи, в которых подход многомерного дисперсионного анализа не может быть использован. Существуют примеры (планы), когда подход многомерного дисперсионного анализа не может быть применен. Обычно это случаи, когда имеется небольшое количество субъектов в плане и много уровней в факторе повторных измерений. Тогда для проведения многомерного анализа может быть слишком мало наблюдений. Например, если имеется 12 субъектов, p = 4 фактора повторных измерений, и каждый фактор имеет k = 3 уровней. Тогда взаимодействие 4-х факторов будет "расходовать" (k-1)p = 24 = 16 степеней свободы. Однако имеется лишь 12 субъектов, следовательно, в этом примере многомерный тест не может быть проведен. Модуль Дисперсионный анализ самостоятельно обнаружит эти наблюдения и вычислит только одномерные критерии.
Различия в одномерных и многомерных результатах. Если исследование включает большое количество повторных измерений, могут возникнуть случаи, когда одномерный подход дисперсионного анализа к повторным измерениям дает результаты, сильно отличающиеся от тех, которые были получены при многомерном подходе.
Это означает, что разности между уровнями соответствующих повторных измерений коррелированы по субъектам. Иногда этот факт представляет некоторый самостоятельный интерес.
Методы дисперсионного анализа
Методы дисперсионного анализа
Методы дисперсионного анализа обсуждаются в нескольких разделах этого учебника. Хотя многие из доступных статистических методов описываются одновременно в нескольких главах, каждый из них наиболее удобен при работе в определенной области приложений.
Диспресионный анализ:
Диспресионный анализ:
Эта глава включает обзор полнофакторных планов, планов с повторными измерениями, планов многомерного дисперсионного и ковариационного анализа (MANOVA), планов с балансированной вложенностью (планы бывают не сбалансированными, т.е. имеющими различные размеры выборок n при некоторых испытаниях), а также описание оценивания спланированных и апостериорных сравнений и мн. др.
Компоненты дисперсии и смешанная модель ANCOVA:
Компоненты дисперсии и смешанная модель ANCOVA:
Эта глава включает обсуждение экспериментов со случайными эффектами (смешанная модель дисперсионного анализ), оценивание компонент дисперсии для случайных эффектов, планов с большими главными эффектами (например, с факторами, имеющими более 100 уровней) с/без случайных эффектов, а также в случае планов с большим числом факторов, когда необходимо оценить все взаимодействия.
Планирование эксперимента:
Планирование эксперимента:
Эта глава включает обсуждение стандартных экспериментальных планов, используемых в промышленных/производственных приложениях, включая 2**(k-p) и 3**(k-p) планы, центральные композиционные и нефакторные планы, планы для смесей, D- и A-оптимальные планы, а также планы для произвольных ограниченных областей значений экспериментальных данных.
Анализ повторяемости и воспроизводимости (в главе Анализ процессов):
Анализ повторяемости и воспроизводимости (в главе Анализ процессов):
Этот раздел главы Анализ процессов включает обсуждение планов специального вида, используемых для оценивания надежности и точности измерительных устройств; Эти планы обычно включают два или три случайных фактора и набор специализированных статистик, позволяющих оценить качество измерительной системы (обычно в промышленных/производственных приложениях).
Таблицы группировки (в главе Основные статистики и таблицы):
Таблицы группировки (в главе Основные статистики и таблицы):
Эта глава включает обсуждение экспериментов, одного (многоуровневого) или нескольких (любых) факторов в случаях, когда не требуется проведение полного дисперсионного анализа.
Дополнительная информация по методам анализа данных, добычи данных, визуализации и прогнозированию содержится на Портале StatSoft (http://www.statsoft.ru/home/portal/default.asp) и в Углубленном Учебнике StatSoft (Учебник с формулами).
| В начало |

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.
Главные компоненты и факторный анализ
Главные компоненты и факторный анализ
Основная цель Факторный анализ как метод редукции данных Факторный анализ как метод классификации Другие результаты и статистикиОсновная цель
Основная цель
Главными целями факторного анализа являются: (1) сокращение числа переменных (редукция данных) и (2) определение структуры взаимосвязей между переменными, т.е. классификация переменных. Поэтому факторный анализ используется или как метод сокращения данных или как метод классификации. Ниже описываются принципы факторного анализа и способы его применения для достижения этих двух целей. Предполагается, что вы знакомы с логикой статистических выводов в объеме, содержащемся в разделе Элементарные понятия статистики. Предполагается также, что вы знакомы с понятиями дисперсии и корреляции (см. например, раздел Основные статистики и таблицы).
Существует множество прекрасных книг по факторному анализу. Практические примеры и советы по применению можно, например, найти в книге Стивенса (Stevens, 1986); более подробное описание приводят Кули и Лонес (Cooley, Lohnes, 1971); Харман (Harman, 1976); Ким и Мюллер (Kim, Mueller, 1978a, 1978b); Лоули и Максвелл (Lawley, Maxwell, 1971); Линдеман, Меренда и Голд (Lindeman, Merenda, Gold, 1980); Моррисон (Morrison, 1967) и Мулэйк (Mulaik, 1972). Интерпретация вторичных факторов в иерархическом факторном анализе, как альтернатива традиционному вращению факторов, дана Верри (Wherry, 1984).
Подтверждающий факторный анализ.Подтверждающий факторный анализ.
Моделирование структурными уравнениями (SEPATH) позволяет проверять частные гипотезы о факторной структуре для множества переменных (подтверждающий факторный анализ) в одной или нескольких выборках (например, вы сможете сравнить факторные структуры разных выборок (опытов)). Анализ соответствий.
Анализ соответствий.
Анализ соответствий - это описательные/разведочные методы, предназначенные для анализа двух- и многовходовых таблиц, содержащих некоторые взаимосвязи между строками и столбцами.
Результаты этого анализа дают информацию, похожую на ту, которую предоставляет факторный анализ, и позволяют изучить структуру категориальных переменных, входящих в таблицу. За более полной информацией об этих методах обратитесь к описанию Анализа соответствий.
| В начало |
Факторный анализ как метод редукции данных
Факторный анализ как метод редукции данных
Предположим, что вы проводите (до некоторой степени "глупое") исследование, в котором измеряете рост ста людей в дюймах и сантиметрах. Таким образом, у вас имеются две переменные. Если далее вы захотите исследовать, например, влияние различных пищевых добавок на рост, будете ли вы продолжать использовать обе переменные? Вероятно, нет, т.к. рост является одной характеристикой человека, независимо от того, в каких единицах он измеряется.
Теперь предположим, вы хотите измерить удовлетворенность людей жизнью, для чего составляете вопросник с различными пунктами; среди других вопросов задаете следующие: удовлетворены ли люди своим хобби (пункт 1) и как интенсивно они им занимаются (пункт 2). Результаты преобразуются так, что средние ответы (например, для удовлетворенности) соответствуют значению 100, в то время как ниже и выше средних ответов расположены меньшие и большие значения, соответственно. Две переменные (ответы на два разных пункта) коррелированы между собой. (Если вы не знакомы с понятием коэффициента корреляции, рекомендуем обратиться к разделу Основные статистики и таблицы - Корреляции). Из высокой коррелированности двух этих переменных можно сделать вывод об избыточности двух пунктов опросника.
Объединение двух переменных в один фактор.
Объединение двух переменных в один фактор.
Зависимость между переменными можно обнаружить с помощью диаграммы рассеяния. Полученная путем подгонки линия регрессии дает графическое представление зависимости. Если определить новую переменную на основе линии регрессии, изображенной на этой диаграмме, то такая переменная будет включить в себя наиболее существенные черты обеих переменных.
Итак, фактически, вы сократили число переменных и заменили две одной. Отметим, что новый фактор (переменная) в действительности является линейной комбинацией двух исходных переменных.
Анализ главных компонент.
Анализ главных компонент.
Пример, в котором две коррелированные переменные объединены в один фактор, показывает главную идею факторного анализа или, более точно, анализа главных компонент (это различие будет обсуждаться позднее). Если пример с двумя переменными распространить на большее число переменных, то вычисления становятся сложнее, однако основной принцип представления двух или более зависимых переменных одним фактором остается в силе.
Выделение главных компонент.
Выделение главных компонент.
В основном процедура выделения главных компонент подобна вращению, максимизирующему дисперсию (варимакс) исходного пространства переменных. Например, на диаграмме рассеяния вы можете рассматривать линию регрессии как ось X, повернув ее так, что она совпадает с прямой регрессии. Этот тип вращения называется вращением, максимизирующим дисперсию, так как критерий (цель) вращения заключается в максимизации дисперсии (изменчивости) "новой" переменной (фактора) и минимизации разброса вокруг нее (см. Стратегии вращения).
Обобщение на случай многих переменных.
Обобщение на случай многих переменных.
В том случае, когда имеются более двух переменных, можно считать, что они определяют трехмерное "пространство" точно так же, как две переменные определяют плоскость. Если вы имеете три переменные, то можете построить 3М диаграмму рассеяния.
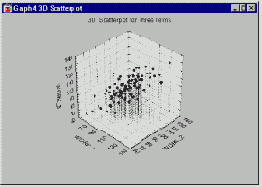
Для случая более трех переменных, становится невозможным представить точки на диаграмме рассеяния, однако логика вращения осей с целью максимизации дисперсии нового фактора остается прежней.
Несколько ортогональных факторов.
Несколько ортогональных факторов.
После того, как вы нашли линию, для которой дисперсия максимальна, вокруг нее остается некоторый разброс данных. И процедуру естественно повторить. В анализе главных компонент именно так и делается: после того, как первый фактор выделен, то есть, после того, как первая линия проведена, определяется следующая линия, максимизирующая остаточную вариацию (разброс данных вокруг первой прямой), и т.д.
Таким образом, факторы последовательно выделяются один за другим. Так как каждый последующий фактор определяется так, чтобы максимизировать изменчивость, оставшуюся от предыдущих, то факторы оказываются независимыми друг от друга. Другими словами, некоррелированными или ортогональными.
Сколько факторов следует выделять?
Сколько факторов следует выделять?
Напомним, что анализ главных компонент является методом сокращения или редукции данных, т.е. методом сокращения числа переменных. Возникает естественный вопрос: сколько факторов следует выделять? Отметим, что в процессе последовательного выделения факторов они включают в себя все меньше и меньше изменчивости. Решение о том, когда следует остановить процедуру выделения факторов, главным образом зависит от точки зрения на то, что считать малой "случайной" изменчивостью. Это решение достаточно произвольно, однако имеются некоторые рекомендации, позволяющие рационально выбрать число факторов, как показано в Обзоре результатов анализа главных компонент, см. раздел Собственные значения и задача о числе факторов. Обзор результатов анализа главных компонент.
Обзор результатов анализа главных компонент.
Посмотрим теперь на некоторые стандартные результаты анализа главных компонент. При повторных итерациях вы выделяете факторы с все меньшей и меньшей дисперсией. Для простоты изложения считаем, что обычно работа начинается с матрицы, в которой дисперсии всех переменных равны 1.0. Поэтому общая дисперсия равна числу переменных. Например, если вы имеете 10 переменных, каждая из которых имеет дисперсию 1, то наибольшая изменчивость, которая потенциально может быть выделена, равна 10 раз по 1. Предположим, что при изучении степени удовлетворенности жизнью вы включили 10 пунктов для измерения различных аспектов удовлетворенности домашней жизнью и работой. Дисперсия, объясненная последовательными факторами, представлена в следующей таблице:
Таблица 1
Таблица 1
| 1 2 3 4 5 6 7 8 9 10 |
6.118369 1.800682 .472888 .407996 .317222 .293300 .195808 .170431 .137970 .085334 |
61.18369 18.00682 4.72888 4.07996 3.17222 2.93300 1.95808 1.70431 1.37970 .85334 |
6.11837 7.91905 8.39194 8.79993 9.11716 9.41046 9.60626 9.77670 9.91467 10.00000 |
61.1837 79.1905 83.9194 87.9993 91.1716 94.1046 96.0626 97.7670 99.1467 100.0000 |
Собственные значения
Собственные значения
Во втором столбце ( Собственные значения) таблицы результатов вы можете найти дисперсию нового, только что выделенного фактора. В третьем столбце для каждого фактора приводится процент от общей дисперсии (в данном примере она равна 10) для каждого фактора. Как можно видеть, первый фактор (значение 1) объясняет 61 процент общей дисперсии, фактор 2 (значение 2) - 18 процентов, и т.д. Четвертый столбец содержит накопленную или кумулятивную дисперсию. Дисперсии, выделяемые факторами, названы собственными значениями. Это название происходит из использованного способа вычисления.
Собственные значения и задача о числе факторов
Собственные значения и задача о числе факторов
Как только получена информация о том, сколько дисперсии выделил каждый фактор, вы можете возвратиться к вопросу о том, сколько факторов следует оставить. Как говорилось выше, по своей природе это решение произвольно. Однако имеются некоторые общеупотребительные рекомендации, и на практике следование им дает наилучшие результаты.
Критерий Кайзера.
Критерий Кайзера.
Сначала вы можете отобрать только факторы, с собственными значениями, большими 1. По существу, это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается. Этот критерий предложен Кайзером (Kaiser, 1960), и является, вероятно, наиболее широко используемым. В приведенном выше примере на основе этого критерия вам следует сохранить только 2 фактора (две главные компоненты).
Критерий каменистой осыпи.
Критерий каменистой осыпи.
Критерий каменистой осыпи является графическим методом, впервые предложенным Кэттелем (Cattell, 1966). Вы можете изобразить собственные значения, представленные в таблице ранее, в виде простого графика.

Кэттель предложил найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Предполагается, что справа от этой точки находится только "факториальная осыпь" - "осыпь" является геологическим термином, обозначающим обломки горных пород, скапливающиеся в нижней части скалистого склона.
В соответствии с этим критерием можно оставить в этом примере 2 или 3 фактора.
Какой критерий следует использовать.
Какой критерий следует использовать.
Оба критерия были изучены подробно Брауном (Browne, 1968), Кэттелем и Джасперсом (Cattell, Jaspers, 1967), Хакстианом, Рожерсом и Кэттелем (Hakstian, Rogers, Cattell, 1982), Линном (Linn, 1968), Тюкером, Купманом и Линном (Tucker, Koopman, Linn, 1969). Теоретически, можно вычислить их характеристики путем генерации случайных данных для конкретного числа факторов. Тогда можно увидеть, обнаружено с помощью используемого критерия достаточно точное число существенных факторов или нет. С использованием этого общего метода первый критерий (критерий Кайзера) иногда сохраняет слишком много факторов, в то время как второй критерий (критерий каменистой осыпи) иногда сохраняет слишком мало факторов; однако оба критерия вполне хороши при нормальных условиях, когда имеется относительно небольшое число факторов и много переменных. На практике возникает важный дополнительный вопрос, а именно: когда полученное решение может быть содержательно интерпретировано. Поэтому обычно исследуется несколько решений с большим или меньшим числом факторов, и затем выбирается одно наиболее "осмысленное". Этот вопрос далее будет рассматриваться в рамках вращений факторов.
Анализ главных факторов
Анализ главных факторов
Прежде, чем продолжить рассмотрение различных аспектов вывода анализа главных компонент, введем анализ главных факторов. Вернемся к примеру вопросника об удовлетворенности жизнью, чтобы сформулировать другую "мыслимую модель". Вы можете представить себе, что ответы субъектов зависят от двух компонент. Сначала выбираем некоторые подходящие общие факторы, такие как, например, "удовлетворение своим хобби", рассмотренные ранее. Каждый пункт измеряет некоторую часть этого общего аспекта удовлетворения. Кроме того, каждый пункт включает уникальный аспект удовлетворения, не характерный для любого другого пункта.
Общности.
Общности.
Если эта модель правильна, то вы не можете ожидать, что факторы будут содержать всю дисперсию в переменных; они будут содержать только ту часть, которая принадлежит общим факторам и распределена по нескольким переменным. На языке факторного анализа доля дисперсии отдельной переменной, принадлежащая общим факторам (и разделяемая с другими переменными) называется общностью. Поэтому дополнительной работой, стоящей перед исследователем при применении этой модели, является оценка общностей для каждой переменной, т.е. доли дисперсии, которая является общей для всех пунктов. Доля дисперсии, за которую отвечает каждый пункт, равна тогда суммарной дисперсии, соответствующей всем переменным, минус общность. С общей точки зрения в качестве оценки общности следует использовать множественный коэффициент корреляции выбранной переменной со всеми другими (для получения сведений о теории множественной регрессии сошлемся на раздел Множественная регрессия). Некоторые авторы предлагают различные итеративные "улучшения после решения" начальной оценки общности, полученной с использованием множественной регрессии; например, так называемый метод MINRES (метод минимальных факторных остатков; Харман и Джоунс (Harman, Jones, 1966)), который производит испытание различных модификаций факторных нагрузок с целью минимизации остаточных (необъясненных) сумм квадратов.
Главные факторы в сравнении с главными компонентами.
Главные факторы в сравнении с главными компонентами.
Главные факторы в сравнении с главными компонентами. Основное различие двух моделей факторного анализа состоит в том, что в анализе главных компонент предполагается, что должна быть использована вся изменчивость переменных, тогда как в анализе главных факторов вы используете только изменчивость переменной, общую и для других переменных. Подробное обсуждение всех "за" и "против" каждого подхода находится за пределами данного введения. В большинстве случаев эти два метода приводят к весьма близким результатам.
Однако анализ главных компонент часто более предпочтителен как метод сокращения данных, в то время как анализ главных факторов лучше применять с целью определения структуры данных (см. следующий раздел).
| В начало |
Факторный анализ как метод классификации
Факторный анализ как метод классификации
Возвратимся к интерпретации результатов факторного анализа. Термин факторный анализ теперь будет включать как анализ главных компонент, так и анализ главных факторов. Предполагается, что вы находитесь в той точке анализа, когда в целом знаете, сколько факторов следует выделить. Вы можете захотеть узнать значимость факторов, то есть, можно ли интерпретировать их разумным образом и как это сделать. Чтобы проиллюстрировать, каким образом это может быть сделано, производятся действия "в обратном порядке", то есть, начинают с некоторой осмысленной структуры, а затем смотрят, как она отражается на результатах. Вернемся к примеру об удовлетворенности; ниже приведена корреляционная матрица для переменных, относящихся к удовлетворенности на работе и дома.
Таблица 2
Таблица 2
| РАБОТА_1 РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 |
1.00 .65 .65 .14 .15 .14 |
.65 1.00 .73 .14 .18 .24 |
.65 .73 1.00 .16 .24 .25 |
.14 .14 .16 1.00 .66 .59 |
.15 .18 .24 .66 1.00 .73 |
.14 .24 .25 .59 .73 1.00 |
Переменные, относящиеся к удовлетворенности на работе, более коррелированы между собой, а переменные, относящиеся к удовлетворенности домом, также более коррелированы между собой. Корреляции между этими двумя типами переменных (переменные, связанные с удовлетворенностью на работе, и переменные, связанные с удовлетворенностью домом) сравнительно малы. Поэтому кажется правдоподобным, что имеются два относительно независимых фактора (два типа факторов), отраженных в корреляционной матрице: один относится к удовлетворенности на работе, а другой к удовлетворенности домашней жизнью.
Факторные нагрузки.
Факторные нагрузки.
Теперь проведем анализ главных компонент и рассмотрим решение с двумя факторами. Для этого рассмотрим корреляции между переменными и двумя факторами (или "новыми" переменными), как они были выделены по умолчанию; эти корреляции называются факторными нагрузками.
Таблица 3
Таблица 3
| РАБОТА_1 РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 |
.654384 .715256 .741688 .634120 .706267 .707446 |
.564143 .541444 .508212 -.563123 -.572658 -.525602 |
| Общая дисперсия Доля общей дисп. |
2.891313 .481885 |
1.791000 .298500 |
По-видимому, первый фактор более коррелирует с переменными, чем второй. Это следовало ожидать, потому что, как было сказано выше, факторы выделяются последовательно и содержат все меньше и меньше общей дисперсии.
Вращение факторной структуры.
Вращение факторной структуры.
Вы можете изобразить факторные нагрузки в виде диаграммы рассеяния. На этой диаграмме каждая переменная представлена точкой. Можно повернуть оси в любом направлении без изменения относительного положения точек; однако действительные координаты точек, то есть факторные нагрузки, должны, без сомнения, меняться. Если вы построите диаграмму для этого примера, то увидите, что если повернуть оси относительно начала координат на 45 градусов, то можно достичь ясного представления о нагрузках, определяющих переменные: удовлетворенность на работе и дома.
Методы вращения.
Методы вращения.
Существуют различные методы вращения факторов. Целью этих методов является получение понятной (интерпретируемой) матрицы нагрузок, то есть факторов, которые ясно отмечены высокими нагрузками для некоторых переменных и низкими - для других. Эту общую модель иногда называют простой структурой (более формальное определение можно найти в стандартных учебниках). Типичными методами вращения являются стратегии варимакс, квартимакс, и эквимакс.
Идея вращения по методу варимакс была описана выше (см. Выделение главных компонент), и этот метод можно применить успешно и к рассматриваемой задаче.
Как и ранее, вы хотите найти вращение, максимизирующее дисперсию по новым осям; другими словами, вы хотите получить матрицу нагрузок на каждый фактор таким образом, чтобы они отличались максимально возможным образом и имелась возможность их простой интерпретации. Ниже приведена таблица нагрузок на повернутые факторы.
Таблица 4
Таблица 4
| РАБОТА_1 РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 |
.862443 .890267 .886055 .062145 .107230 .140876 |
.051643 .110351 .152603 .845786 .902913 .869995 |
| Общая дисперсия Доля общей дисп. |
2.356684 .392781 |
2.325629 .387605 |
Интерпретация факторной структуры.
Интерпретация факторной структуры.
Теперь картина становится более ясной. Как и ожидалось, первый фактор отмечен высокими нагрузками на переменные, связанные с удовлетворенностью на работе, а второй фактор - с удовлетворенностью домом. Из этого вы должны заключить, что удовлетворенность, измеренная вашим вопросником, составлена из двух частей: удовлетворенность домом и работой, следовательно, вы произвели классификацию переменных.
Рассмотрим следующий пример, здесь к предыдущему примеру добавились четыре новых переменных Хобби.
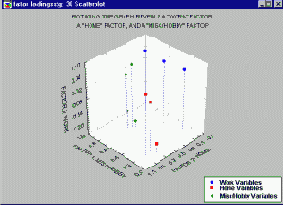
На этом графике факторных нагрузок 10 переменных были сведены к трем факторам - фактор удовлетворенности работой (work), фактор удовлетворенности домом (home), и фактор удовлетворенности хобби (hobby/misc). Заметим, что факторные нагрузки для каждого фактора имеют сильно различающиеся значения для остальных двух факторов, но большие значения именно для этого фактора. Например, факторные нагрузки для переменных, относящихся к хобби (выделены зеленым цветом) имеют и большие, и малые значения для "дома" и "работы", но все четыре переменные имеют большие факторные нагрузки для фактора "хобби".
Косоугольные факторы.
Косоугольные факторы.
Некоторые авторы (например, Харман (Harman, 1976), Дженнрих и Сэмпсон (Jennrich, Sampson, 1966); Кларксон и Дженнрих (Clarkson, Jennrich, 1988)) обсуждали довольно подробно концепцию косоугольных (не ортогональных) факторов, для того чтобы достичь более простой интерпретации решений.
В частности, были развиты вычислительные стратегии, как для вращения факторов, так и для лучшего представления "кластеров" переменных без отказа от ортогональности (т.е. независимости) факторов. Однако косоугольные факторы, получаемые с помощью этих процедур, трудно интерпретировать. Возвратимся к примеру, обсуждавшемуся выше, и предположим, что вы включили в вопросник четыре пункта, измеряющих другие типы удовлетворенности (Хобби). Предположим, что ответы людей на эти пункты были одинаково связаны как с удовлетворенностью домом (Фактор 1), так и работой (Фактор 2). Косоугольное вращение должно дать, очевидно, два коррелирующих фактора с меньшей, чем ранее, выразительностью, то есть с большими перекрестными нагрузками.
Иерархический факторный анализ.
Иерархический факторный анализ.
Вместо вычисления нагрузок косоугольных факторов, для которых часто трудно дать хорошую интерпретацию, вы можете использовать стратегию, впервые предложенную Томсоном (Thompson, 1951) и Шмидтом и Лейманом (Schmidt, Leiman, 1957), которая было подробно развита и популяризирована Верри (Wherry, 1959, 1975, 1984). В соответствии с этой стратегией, вначале определяются кластеры и происходит вращение осей в пределах кластеров, а затем вычисляются корреляции между найденными (косоугольными) факторами. Полученная корреляционная матрица для косоугольных факторов затем подвергается дальнейшему анализу для того, чтобы выделить множество ортогональных факторов, разделяющих изменчивость в переменных на ту, что относятся к распределенной или общей дисперсии (вторичные факторы), и на частные дисперсии, относящиеся к кластерам или схожим переменным (пунктам вопросника) в анализе (первичные факторы). Применительно к рассматриваемому примеру такой иерархический анализ может дать следующие факторные нагрузки:
Таблица 5
Таблица 5
| РАБОТА_1 РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 ХОББИ_1 ХОББИ_2 ХОББИ_3 ХОББИ_4 |
.483178 .570953 .565624 .535812 .615403 .586405 .780488 .734854 .776013 .714183 |
.649499 .687056 .656790 .117278 .079910 .065512 .466823 .464779 .439010 .455157 |
.187074 .140627 .115461 .630076 .668880 .626730 .280141 .238512 .303672 .228351 |
Внимательное изучение позволяет сделать следующие заключения: Имеется общий (вторичный) фактор удовлетворенности, которому, по-видимому, подвержены все типы удовлетворенности, измеренные для 10 пунктов; Имеются вероятно две первичные уникальных области удовлетворения, которые могут быть описаны как удовлетворенностью работой, так и удовлетворенностью домашней жизнью. Верри (Wherry, 1984) обсудил подробно примеры такого иерархического анализа и объяснил, каким образом могут быть получены значимые и интерпретируемые вторичные факторы.
Подтверждающий факторный анализ.
Подтверждающий факторный анализ.
Последние 15 лет так называемые методы подтверждения имели все большую популярность (например, см. Joreskog, Sorbom, 1979). Можно априори выбрать набор факторных нагрузок для некоторого числа ортогональных или косоугольных факторов, а затем проверить, может ли быть наблюдаемая корреляционная матрица воспроизведена при этом выборе. Подтверждающий факторный анализ может быть проведен с помощью Моделирования структурными уравнениями (SEPATH).
| В начало |
Другие результаты и статистики
Другие результаты и статистики
Значения факторов.
Значения факторов.
Вы можете оценить действительные значения факторов для отдельных наблюдений. Эти значения используются, когда желают провести дальнейший анализ факторов.
Воспроизведенные и остаточные корреляции.
Воспроизведенные и остаточные корреляции.
Дополнительным способом проверки числа выделенных факторов является вычисление корреляционной матрицы, которая близка исходной, если факторы выделены правильно. Эта матрица называется воспроизведенной корреляционной матрицей. Для того чтобы увидеть, как эта матрица отклоняется от исходной корреляционной матрицы (с которой начинался анализ), можно вычислить разность между ними. Полученная матрица называется матрицей остаточных корреляций. Остаточная матрица может указать на "несогласие", т.е. на то, что рассматриваемые коэффициенты корреляции не могут быть получены с достаточной точностью на основе имеющихся факторов.
Плохо обусловленные матрицы.
Плохо обусловленные матрицы.
Если имеются избыточные переменные, то нельзя вычислить обратную матрицу. Например, если переменная является суммой двух других переменных, отобранных для этого анализа, то корреляционная матрица для такого набора переменных не может быть обращена, и факторный анализ принципиально не может быть выполнен. На практике это происходит, когда вы пытаетесь применить факторный анализ к множеству сильно коррелированных (зависимых) переменных, что иногда случается, например, в исследованиях вопросников. Тогда вы можете искусственно понизить все корреляции в матрице путем добавления малой константы к диагональным элементам матрицы, и затем стандартизировать ее. Эта процедура обычно приводит к матрице, которая может быть обращена, и поэтому к ней применим факторный анализ; более того, эта процедура не влияет на набор факторов. Однако оценки оказываются менее точными.
Таблица 6
Таблица 6
| РАБОТА_1 РАБОТА_2 РАБОТА_3 ДОМ_1 ДОМ_2 ДОМ_3 ХОББИ_1 ХОББИ_2 ХОББИ_3 ХОББИ_4 |
.483178 .570953 .565624 .535812 .615403 .586405 .780488 .734854 .776013 .714183 |
.649499 .687056 .656790 .117278 .079910 .065512 .466823 .464779 .439010 .455157 |
.187074 .140627 .115461 .630076 .668880 .626730 .280141 .238512 .303672 .228351 |
Внимательное изучение позволяет сделать следующие заключения: Имеется общий (вторичный) фактор удовлетворенности, которому, по-видимому, подвержены все типы удовлетворенности, измеренные для 10 пунктов; Имеются вероятно две первичные уникальных области удовлетворения, которые могут быть описаны как удовлетворенностью работой, так и удовлетворенностью домашней жизнью. Верри (Wherry, 1984) обсудил подробно примеры такого иерархического анализа и объяснил, каким образом могут быть получены значимые и интерпретируемые вторичные факторы.
| В начало |
(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.
Графические методы анализа данных
Графические методы анализа данных
Краткий обзор типов графиков
2М графики                    3М XYZ графики     |
  3М последовательные графики      4М/Тернарные графики      2М категоризованные графики   |
3М категоризованные графики Тернарные категоризованные графики n-мерные пиктографики         Матричные графики    |
Типичные методы визуализации
Категоризованные графики Что такое категоризованные графики? Методы категоризации Гистограммы Диаграммы рассеяния Вероятностные графики Графики квантиль-квантиль Графики вероятность-вероятность Линейные графики Диаграммы размаха Круговые диаграммы Графики пропущенных значений и диапазонов 3М графики Тернарные графики Закрашивание Сглаживание двумерных распределений Послойное сжатие Проекции трехмерных наборов данных Пиктографики Анализ пиктографиков Систематизация пиктографиков Стандартизация значений Применения Близкие способы графического представления Типы графиков Маркировка пиктограмм Выборка данных Вращение (в трехмерном пространстве) Категоризованные графики
Категоризованные графики
Одним из наиболее мощных аналитических методов исследования является разделение ("разбиение") данных на группы для сравнения структуры получившихся подмножеств. Эти методы широко применяются как в разведочном анализе данных, так и при проверке гипотез и известны под разными названиями (классификация, группировка, категоризация, разбиение, расслоение и пр.). Например, взаимосвязь между возрастом и риском инфаркта может отличаться для мужчин и женщин (для мужчин эта зависимость сильнее). Или например, зависимость между приемом лекарств и снижением уровня холестерина может наблюдаться только для женщин с пониженным давлением и в возрасте 30-40 лет. Производительность или гистограммы мощности могут различаться для временных промежутков, когда управление осуществляется разными операторами. Разным экспериментальным группам также могут соответствовать разные наклоны линий регрессии.
Для количественного описания различий между группами наблюдений разработаны многочисленные вычислительные методы, основанные на группировке данных (например, дисперсионный анализ). Однако графические средства (такие как рассматриваемые в этом разделе категоризованные графики) дают особые преимущества и позволяют выявить закономерности, которые трудно поддаются количественному описанию и которые весьма сложно обнаружить с помощью вычислительных процедур (например, сложные взаимосвязи, исключения или аномалии). В этих случаях графические методы предоставляют уникальные возможности многомерного аналитического исследования или "добычи" данных.
Что такое категоризованные графики
Что такое категоризованные графики
Термин "категоризованные графики" впервые был использован в программе STATISTICA компании StatSoft в 1990 году (кроме того, Becker, Cleveland и Clark из Bell Labs называют их графиками на решетке).
Эти графики представляют собой наборы двумерных, трехмерных, тернарных или n-мерных графиков (таких как гистограммы, диаграммы рассеяния, линейные графики, поверхности, тернарные диаграммы рассеяния и пр.), по одному графику для каждой выбранной категории (подмножества) наблюдений, например, опрашиваемых из Нью-Йорка, Чикаго или Далласа. Эти "входящие" графики располагаются последовательно в одном графическом окне, позволяя сравнивать структуру данных для каждой из указанных подгрупп (например, городов).
Для выбора подгрупп можно использовать множество методов, самый простой из них - это введение категориальной переменной (например, переменной City с значениями New York, Chicago и Dallas). На следующем графике показаны гистограммы переменной, представляющей данные о самооценке стресса жителями каждого из трех городов.
На основе этих данных можно сделать вывод о том, что жители Далласа не очень подвержены стрессам, в то время как распределения уровня стресса в Нью-Йорке и Чикаго довольно похожи.
Некоторые программы (например, система STATISTICA) поддерживают двухвходовую или многомерную категоризацию, где для задания подгрупп используется не один (например, City), а два или более критериев (например, City и Time ). Двухвходовые категоризованные графики можно рассматривать как "таблицы графиков", где каждый входящий график находится на "пересечении" определенных значений первой (например, City) и второй (например, Time) группирующих переменных.

Добавление второго фактора показывает, что картины стрессовых нагрузок в Нью-Йорке и Чикаго в действительности сильно различаются, если учитывается время опроса, в то время как фактор времени практически ничего не меняет в Далласе.
Категоризованные и матричные графики. Матричные графики также состоят из нескольких графиков; однако здесь каждый из них основывается (или может основываться) на одном и том же множестве наблюдений, и графики строятся для всех комбинаций переменных из одного или двух списков.
Для категоризованных графиков требуется такой же выбор переменных, как и для некатегоризованных графиков соответствующего типа (например, две переменных для диаграммы рассеяния). В то же время для категоризованных графиков необходимо указать по крайней мере одну группирующую переменную (или способ разбиения наблюдений на категории), где содержалась бы информация о принадлежности каждого наблюдения к определенной подгруппе (например, Chicago, Dallas). Группирующая переменная не будет непосредственно изображена на графике (т.е. не будет построена), однако она будет служить критерием для разделения всех анализируемых наблюдений на отдельные подгруппы. Как показано выше, для каждой группы (категории), определяемой группирующей переменной, будет построен один график.
Общие и независимые шкалы.
Общие и независимые шкалы.
Каждый элементарный график, входящий в состав категоризованного графика, может быть масштабирован в соответствии со своим собственным диапазоном значений (независимые шкалы).
Или все графики могут иметь общую шкалу, достаточно широкую, чтобы охватить весь диапазон значений.

Общий масштаб позволяет сравнивать диапазоны и распределения значений разных категорий. Однако, если эти диапазоны сильно различаются (что приводит к очень большой общей шкале), то исследование некоторых графиков может быть затруднено. Использование независимого масштаба может упростить выявление трендов и определенных закономерностей внутри категорий, но в то же время затруднить сравнение диапазонов значений разных подгрупп.
Методы категоризации
Методы категоризации
Существует пять основных методов категоризации значений, которые будут кратко описаны в этом разделе: целые числа, категории, границы, коды и сложные подгруппы. Обратите внимание, что одни и те же методы категоризации можно использовать как для разбиения наблюдений по входящим графикам, так и для категоризации наблюдений внутри входящих графиков ( например, на гистограммах или диаграммах размаха).
Целые числа.
Целые числа.
При использовании этого режима для определения категорий будут использованы целые значения выбранной группирующей переменной, и для всех наблюдений, принадлежащих каждой категории (заданной этими целыми числами), будет построено по одному графику.
Если выбранная группирующая переменная содержит не целочисленные значения, то программа автоматически округлит каждое значение выделенной переменной до целого числа.
Категории.
Категории.
В этом режиме категоризации нужно указать желаемое число категорий. Программа разделит весь диапазон значений выбранной группирующей переменной (от минимального до максимального) на указанное число интервалов равной длины.

Границы.
Границы.
Метод границ также представляет собой интервальную категоризацию, однако в этом случае интервалы могут иметь произвольную (например, различную) длину, определяемую пользователем (например, "меньше -10", "больше или равно -10, но меньше 0", "больше или равно 0, но меньше 10" и "больше или равно 10").
Коды.
Коды.
Этот метод следует использовать в том случае, если выбранная группирующая переменная содержит "коды " (т.е. особые смысловые значения, такие как Male, Female), по которым можно разбить данные на категории.
Сложные подгруппы.
Сложные подгруппы.
Этот метод дает возможность пользователю использовать для выделения подгрупп более одной переменной. Другими словами, категоризация, основанная на выделении сложных подгрупп, может представлять не распределения конкретных переменных, а распределения частот определенных "событий" при заданной комбинации значений любого числа переменных текущего набора данных. Например, можно указать шесть категорий, задаваемых комбинациями значений трех переменных Gender, Age и Employment.
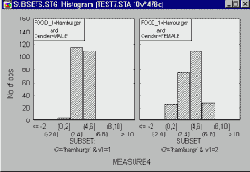
Гистограммы
Гистограммы
Гистограммы используются для изучения распределений частот значений переменных. Такое частотное распределение показывает, какие именно конкретные значения или диапазоны значений исследуемой переменной встречаются наиболее часто, насколько различаются эти значения, расположено ли большинство наблюдений около среднего значения, является распределение симметричным или асимметричным, многомодальным (т.е.
имеет две или более вершины) или одномодальным и т.д. Гистограммы также используются для сравнения наблюдаемых и теоретических или ожидаемых распределений.
Категоризованные гистограммы представляют собой наборы гистограмм, соответствующих различным значениям одной или нескольких категоризующих переменных или наборам логических условий категоризации (см. Методы категоризации).
Частотные распределения могут представлять интерес по двум основным причинам. По форме распределения можно судить о природе исследуемой переменной (например, бимодальное распределение позволяет предположить, что выборка не является однородной и содержит наблюдения, принадлежащие двум различным множествам, которые в свою очередь нормально распределены). Многие статистики основываются на определенных предположениях о распределениях анализируемых переменных; гистограммы позволяют проверить, выполняются ли эти предположения. Как правило, работа с новым набором данных начинается с построения гистограмм всех переменных.
Гистограммы и группировка. Категоризованные гистограммы предоставляют такую же информацию о данных, как и группировка (например, среднее, медиану, минимум, максимум, разброс и т.п.; см. главу Основные статистики и таблицы). Хотя конкретные (числовые) значения описательных статистик легко увидеть в таблице, в то же время общую структуру и глобальные характеристики распределения проще изучать на графике. Более того, график дает качественную информацию о распределении, которую невозможно отразить с помощью какого-либо одного параметра. Например, по асимметрии распределения значений дохода можно сделать вывод о том, что большинство населения имеет низкий, а не высокий уровень доходов. Если помимо этого провести группировку данных по этническому и половому признакам, то можно обнаружить, что в некоторых подгруппах эта структура распределения станет еще более ярко выраженной. Хотя эта информация содержится в значении коэффициента асимметрии (для каждой подгруппы), но она легче воспринимается и запоминается, будучи графически представленной на гистограмме. Кроме того, на гистограмме можно наблюдать некоторые "впадины и выпуклости", которые могут свидетельствовать о социальном расслоении в исследуемой группе населения или об аномалиях в распределении дохода отдельных подгрупп, связанных с недавней налоговой реформой.
Категоризованные гистограммы и диаграммы рассеяния. Полезное применение категоризации для непрерывных переменных - это представление взаимосвязи трех переменных одновременно. Ниже показана диаграмма рассеяния для двух переменных Load 1 и Load 2.
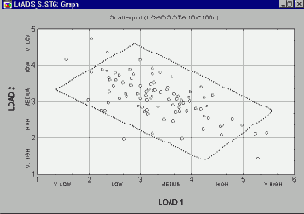
Предположим, к ним нужно добавить третью переменную (Output) и исследовать ее распределение при различных значения совместного распределения переменных Load 1 и Load 2. Для этого можно построить следующий график:
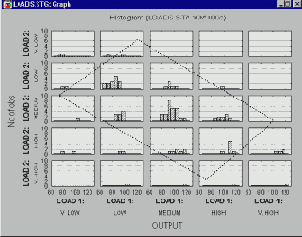
На этом графике обе переменные Load 1 и Load 2 сгруппированы в 5 интервалов, и для каждой комбинации этих интервалов вычислено распределение переменной Output. Обратите внимание, что внутри "прямоугольника" (параллелограмма) находятся наблюдения, одинаковые для обоих показанных выше графиков.
Диаграммы рассеяния
Диаграммы рассеяния
Двумерные диаграммы рассеяния используются для визуализации взаимосвязей между двумя переменными X и Y (например, весом и ростом). На этих диаграммах отдельные точки данных представлены маркерами на плоскости, где оси соответствуют переменным. Две координаты (X и Y), определяющие положение точки, соответствуют значениям переменных. Если между переменными существует сильная взаимосвязь, то точки на графике образуют упорядоченную структуру (например, прямую линию или характерную кривую). Если переменные не взаимосвязаны, то точки образуют "облако".
Можно построить также категоризованные диаграммы рассеяния, сгруппированные по значениям одной или нескольких переменных, а с помощью метода сложных подгрупп (см. Методы категоризации) - диаграммы рассеяния, категоризованные по заданным логическим условиям выбора подгрупп наблюдений.
Категоризованные диаграммы рассеянияпредставляют собой мощный исследовательский и аналитический метод для изучения взаимосвязей между двумя и более переменными среди различных подгрупп.
Однородность двумерных распределений (форма взаимосвязей).Диаграммы рассеяния обычно используются для выявления природы взаимосвязи двух переменных (например, кровяного давления и уровня холестерина), поскольку они предоставляют гораздо больше информации, чем коэффициент корреляции.
Например, неоднородность выборки, по которой рассчитываются корреляции, может привести к искажению значений коэффициента корреляции. Предположим, коэффициент корреляции рассчитывается по данным, полученным в двух экспериментальных группах, но этот факт при вычислениях игнорируется. Пусть эксперимент в одной из подгрупп привел к увеличению значений обеих переменных, и на диаграмме рассеяния данные из каждой группы образуют отдельные "облака" (как показано на картинке).
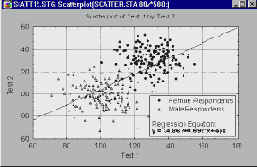
В этом примере большое значение коэффициента корреляции целиком обусловлено распределением по группам и не отражает "истинную" взаимосвязь между двумя переменными, которая практически близка к 0 (это хорошо видно, если рассматривать каждую группу отдельно).
Если вы предполагаете, что подобная структура присутствует и в ваших данных, и знаете, каким образом выделить "подгруппы" наблюдений, то имеет смысл построить категоризованную диаграмму рассеяния.
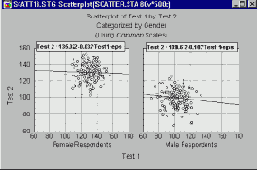
Такой график поможет вам прояснить структуру взаимосвязей между переменными X и Y внутри каждой подгруппы (после соответствующего разбиения наблюдений).
Нелинейные зависимости. С помощью диаграмм рассеяния можно исследовать и нелинейные взаимосвязи между переменными. При этом не существует каких-либо "автоматических" или простых способов оценки нелинейности. Стандартный коэффициент корреляции Пирсона r позволяет оценить только линейность связи, а некоторые непараметрические корреляции, например, Спирмена R, дают возможность оценить нелинейность, но только для монотонных зависимостей. На диаграммах рассеяния можно изучить структуру взаимосвязей, чтобы затем с помощью преобразования привести данные к линейному виду или выбрать подходящую нелинейную подгонку.
Дополнительную информацию можно найти в разделах Основные статистики, Непараметрическая статистика и распределения, Множественная регрессия и Нелинейное оценивание.
Вероятностные графики
Вероятностные графики
Существует три типа категоризованных вероятностных графиков: нормальные, полунормальные и с исключенным трендом.
Нормальные вероятностные графики - это быстрый способ визуальной проверки степени соответствия данных нормальному распределению.
В свою очередь категоризованные вероятностные графики дают возможность исследовать близость к нормальному распределению различных подгрупп данных .
Категоризованные нормальные вероятностные графики представляют собой эффективный инструмент для исследования однородности группы наблюдений с точки зрения соответствия нормальному распределению.
Графики квантиль-квантиль
Графики квантиль-квантиль
Категоризованные графики квантиль-квантиль (или К-К) используются для поиска в определенном семействе распределений того распределения, которое наилучшим образом описывает имеющиеся данные.
В случае категоризованных графиков К-К строится набор графиков квантиль-квантиль, по одному для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации). Для графиков К-К используются следующие семейства распределений: экспоненциальное, экстремальное, нормальное, Релея, бета-, гамма-, логнормальное и Вейбулла.
Графики вероятность-вероятность
Графики вероятность-вероятность
Категоризованные графики вероятность-вероятность (или В-В) используются для проверки соответствия конкретного теоретического распределения имеющимся исходным данным. На этих графиках для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации) создается по одному графику вероятность-вероятность.

На графиках В-В строится наблюдаемая функция распределения (доля непропущенных значений

Если не все точки данных располагаются на диагональной линии, то на таком графике можно визуально выделить группы наблюдений, соответствующие и не соответствующие искомому распределению (если, к примеру, точки образуют кривую S-образной формы вокруг диагональной линии, то к ним можно применить определенное преобразование для приведения к нужной форме распределения).
Линейные графики
Линейные графики
На линейных графиках отдельные точки данных соединяются линиями. Это простой способ визуального представления последовательности значений (например, цены на фондовом рынке за несколько дней торгов). Категоризованные линейные графики строятся в том случае, если необходимо разбить данные на несколько групп (категоризовать) с помощью группирующей переменной (например, цены при закрытии рынка по понедельникам, вторникам и т.д.) или с помощью логических условий, составленных по нескольким переменным (например, цены при закрытии рынка в те дни, когда две другие акции и индекс Доу Джонса выросли по сравнению с другими ценами закрытия; см. Методы категоризации).
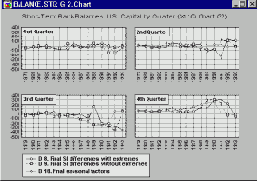
Диаграммы размаха
Диаграммы размаха
На диаграммах размаха (этот термин был впервые использован Тьюки в 1970 году) представлены диапазоны значений выбранной переменной (или переменных) для отдельных групп наблюдений. Для выделения этих групп используются от одной до трех категориальных (группирующих) переменных или набор логических условий выбора подгрупп.
Для каждой группы наблюдений вычисляется центральная тенденция (медиана или среднее), а также размах или изменчивость (квартили, стандартные ошибки или стандартные отклонения). Выбранные параметры отображаются на графике одним из пяти способов (Прямоугольники-Отрезки, Отрезки, Прямоугольники, Столбцы или Верхние-нижние засечки). На этом графике можно показать и выбросы (см. разделы о выбросах и крайних точках).
На следующем графике, например, выбор факторов можно было бы считать вполне удачным, если бы не "досадное" несоответствие, на которое указывают выделенные на рисунке выбросы (в данном случае это значения, попадающие за пределы 1,5 квартильных размахов):
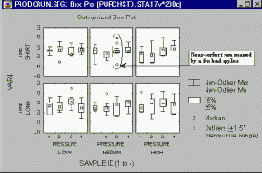
А на следующем рисунке не показаны ни выбросы, ни крайние точки.
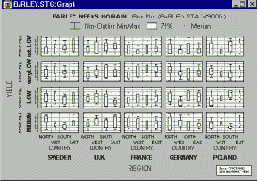
Можно выделить два основных направления использования диаграмм размаха: (a) отображение диапазонов значений отдельных элементов, наблюдений или выборок (например, типичные минимаксные графики цен на акции или товары или графики агрегированных данных с диапазонами), (б) отображение изменения значений в отдельных группах или выборках (например, когда точкой внутри прямоугольника представлено среднее значение для каждой выборки, сам прямоугольник соответствует значениям стандартной ошибки, а меньший прямоугольник или пара "отрезков" обозначает стандартное отклонение от среднего).
С помощью диаграмм размаха, на которых представлены характеристики изменчивости, можно быстро оценить и "интуитивно представить" силу связи между группирующей и зависимой переменной. Предположив, что зависимая переменная нормально распределена, и зная долю наблюдений, попадающих, к примеру, в интервал ±1 или ±2 стандартных отклонения от среднего (см. Элементарные понятия статистики), можно сделать, например, вывод о том, что 95% наблюдений из экспериментальной группы 1 попадают в другой диапазон значений, нежели 95% наблюдений из группы 2.
На этих графиках можно изобразить и так называемые усеченные средние (этот термин был впервые использован Тьюки в 1962 году), которые вычисляются после исключения заданного пользователем процента наблюдений с концов (хвостов) распределения.
Круговые диаграммы
Круговые диаграммы
Одним из наиболее широко используемых типов графического представления данных являются круговые диаграммы, на которых показаны пропорции или сами значения переменных. Категоризованные графики этого типа состоят из нескольких круговых диаграмм, где данные разделены по группам с помощью одной или нескольких группирующих переменных (например, gender) или категоризованы согласно логическим условиям выбора подгрупп (см.
Методы категоризации).
В дальнейшем, говоря о категоризации этих графиков, мы будем иметь ввиду круговые диаграммы частот (в противоположность круговым диаграммам значений). Эти типы графиков, называемые также частотными круговыми диаграммами, представляют данные аналогично гистограммам. Все значения выбранной переменной категоризуются с помощью заданного метода категоризации, а затем относительные значения частот отображаются в виде сегментов круговой диаграммы пропорционального размера. Таким образом, эти графики являются альтернативным представлением гистограммы частот (см. раздел о категоризованных гистограммах).
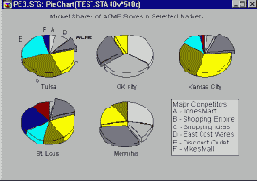
Диаграммы рассеяния круговых диаграмм. Еще одно очень полезное применение категоризованных круговых диаграмм - это представление относительных частот значений какой-либо переменной в различных "местах" совместного распределения двух других переменных. Например:

Обратите внимание, что круговые диаграммы изображены только в тех "местах", где имеются данные. Показанный выше график напоминает диаграмму рассеяния (переменных L1 и L2), где маркерами точек являются круговые диаграммы. Однако помимо обычной информации, содержащейся в диаграмме рассеяния, здесь в каждой точке дополнительно показано относительное распределение третьей переменной (а именно, доля значений Low, Medium и High Quality).
Графики пропущенных значений и данных вне диапазона
Графики пропущенных значений и данных вне диапазона
На этих графиках можно наглядно представить структуру распределения точек данных, содержащих пропущенные значения или находящихся "вне диапазонов", заданных пользователем. При этом строится по одной двумерной диаграмме для каждой группы наблюдений, выделенной с помощью группирующих переменных или с помощью условий выбора сложных подгрупп (см. Методы категоризации).
Эти типы графиков используются в разведочном анализе данных, чтобы определить, является ли случайным распределение точек с пропущенными значениями, а также для оценки их диапазона.
Трехмерные (3М) графики
Трехмерные (3М) графики
Трехмерные диаграммы рассеяния (пространственные, спектральные, трассировочные и диаграммы отклонений), карты линий уровня и поверхности также можно построить для подгрупп наблюдений, заданных с помощью выбранной категориальной переменной или логических условий выбора (см. Методы категоризации). Основная задача этих графиков - упростить сравнение взаимосвязей между тремя и более переменными для различных групп или категорий наблюдений.
Применения. Трехмерные графики в координатах XYZ отображают взаимосвязи между тремя переменными. С помощью различных способов категоризации можно исследовать эти зависимости при различных условиях (т.е. в разных группах).
Изучая, например, показанный ниже категоризованный график поверхности, можно сделать вывод о том, что величина допуска прибора не влияет на измерения (переменные Depend1, Depend2 и Height), кроме случая, когда она
Этот вывод становится еще более очевидным, если использовать вместо поверхности карту линий уровня.
Тернарные графики
Тернарные графики
Категоризованные тернарные графики используются для исследования взаимосвязей между тремя и более переменными, три из которых представляют собой компоненты смеси (т.е. для каждого наблюдения значения их суммы являются постоянной величиной), при этом отдельный график строится для каждого уровня группирующей переменной.
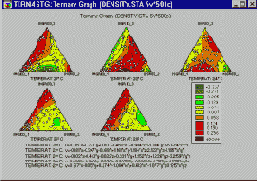
Для построения тернарных графиков используется треугольная система координат на плоскости или в пространстве и строится зависимость между четырьмя (или более) переменными (компонентами X, Y и Z и откликами V1, V2 и т.д.). При этом накладываются ограничения на относительные значения каждой из компонент, чтобы они в сумме давали одинаковую величину для каждого наблюдения (например, 1).
На категоризованных тернарных графиках строится по одному графику для каждого значения группирующей переменной (или заданного пользователем подмножества данных), и все они отображаются в одном графическом окне, чтобы можно было сравнивать различные подгруппы наблюдений.
Применения. Эти графики применяются для анализа результатов эксперимента, в котором измеряемый отклик зависит от относительного соотношения трех компонент (например, трех химических веществ при составлении смесей), которое варьируется с целью определения его оптимального значения. Эти типы графического представления можно использовать и в других случаях, когда взаимосвязь между переменными, на которые наложены определенные ограничения, необходимо исследовать для различных групп или категорий наблюдений.

| В начало |
Закрашивание
Закрашивание
Закрашивание является одним из первых и, по-видимому, наиболее широко распространенных методов, известных как графический разведочный анализ данных. Этот метод позволяет интерактивно выделять на экране отдельные точки или подмножества данных и задавать их характеристики, или исследовать их влияние на взаимосвязи между переменными (например, на матрицах диаграмм рассеяния) и идентифицировать выбросы(например, с помощью меток).
Связи между переменными можно наглядно представить с помощью аппроксимирующих функций (например, двумерных кривых или трехмерных поверхностей) и доверительных интервалов. Интерактивно удаляя или добавляя определенные подгруппы наблюдений, можно наблюдать за изменениями этих функций и их параметров. Одно из применений метода закрашивания - это, например, выделение на матричной диаграмме рассеяния всех точек данных, принадлежащих определенной категории (например, на показанном ниже рисунке на правом верхнем графике выделена группа наблюдений, соответствующих значению "среднего" уровня дохода).
Такое исследование помогает определить, как эти конкретные наблюдения влияют на связи между другими переменными того же набора данных (например, на корреляцию между "расходами" и "активами").
В режиме "динамического закрашивания" (см. следующий пример) или "автоматического обновления функции подгонки" можно задать движение кисти по определенным последовательным диапазонам выбранной переменной (например, непрерывной, а не дискретной, как на показанном ранее примере) и исследовать динамику вклада этой переменной в связи между другими переменными этого набора данных.

| В начало |
Сглаживание двумерных распределений
Сглаживание двумерных распределений
Для наглядного представления таблицы значений двух переменных используются трехмерные гистограммы. Их можно рассматривать как объединение двух простых гистограмм для совместного анализа частот значений двух переменных. Чаще всего на этом графике для каждой "ячейки" таблицы нарисован один трехмерный столбец, а его высота соответствует частоте значений в этой ячейке. При построении трехмерной гистограммы для каждой из двух переменных можно использовать свой метод категоризации (см. ниже).
Когда предусмотрены процедуры сглаживания данных, то трехмерное представление частот значений можно аппроксимировать поверхностью. Такое сглаживание можно осуществить для любой трехмерной гистограммы. Для достаточно простой структуры данных (как на предыдущем рисунке) такое сглаживание не имеет особого смысла.
Однако, в случае более сложной картины распределения частот эта процедура может оказаться эффективным инструментом разведочного анализа данных

и позволит выявить особенности, которые трудно обнаружить на обычной трехмерной гистограмме (например, показанную выше "волновую структуру" поверхности).
| В начало |
Послойное сжатие
Послойное сжатие
На графиках этого типа за счет сокращения области основного графика освобождается место для графиков на полях, которые располагаются в правой и верхней части графического окна (включая маленький угловой график). Эти графики на полях представляют собой соответственно вертикально и горизонтально сжатые изображения основного графика.
Послойное сжатие двумерных графиков является методом разведочного анализа данных, который дает возможность скрытые тренды и структуры двумерных наборов данных. Рассмотрим следующий рисунок.
Здесь на примере, приведенном Кливландом (Cleveland, 1993), можно убедиться, что в каждом цикле солнечной активности число пятен уменьшается гораздо медленнее, чем нарастает в начале цикла.
Такое поведение совершенно не очевидно при исследовании обычного линейного графика, в то время как сжатый график позволяет обнаружить эту скрытую картину.
| В начало |
Проекции трехмерных наборов данных
Полезным методом изучения и аналитического исследования структуры поверхности (созданной, как правило, по трехмерным наборам данных) является построение ее проекции на плоскость в виде карты линий уровня.

Эти графики менее эффективны для быстрого визуального анализа формы трехмерных структур по сравнению с графиками поверхности,
однако их преимущество заключается в возможности точного исследования формы поверхности -

на картах линий уровня отображается ряд не искаженных горизонтальных "сечений".
| В начало |
Пиктографики
Пиктографики
На пиктографиках каждое наблюдение представлено в виде многомерного символа, что позволяет использовать эти типы графического представления данных в качестве не очень простого, но мощного исследовательского инструмента. Главная идея такого метода анализа основана на человеческой способности "автоматически" фиксировать сложные связи между многими переменными, если они проявляются в последовательности элементов (в данном случае "пиктограмм"). Иногда понимание (или "чувство") того, что некоторые элементы "чем-то похожи" друг на друга, приходит раньше, чем наблюдатель (аналитик) может объяснить, какие именно переменные обусловливают это сходство (Lewicki, Hill, & Czyzewska, 1992). Конкретную природу проявившихся взаимосвязей между переменными позволяет выявить уже последующий анализ данных, основанный на изучении этого интуитивно обнаруженного сходства.

Основная идея пиктографиков заключается в представлении элементарных наблюдений как отдельных графических объектов, где значения переменных соответствуют определенным чертам или размерам объекта (обычно одно наблюдение = одному объекту). Это соответствие устанавливается таким образом, чтобы общий вид объекта менялся в зависимости от конфигурации значений.
Таким образом, объекты имеют определенный "внешний вид", который уникален для каждой конфигурации значений и может быть идентифицирован наблюдателем. Изучение таких пиктограмм помогает выявить как простые связи, так и сложные взаимодействия между переменными.
Анализ пиктографиков
Анализ пиктографиков
Целесообразно проводить анализ пиктографиков в пять этапов. Сначала выберите порядок анализируемых переменных. В большинстве случаев наилучшим вариантом оказывается случайная последовательность. Кроме того, можно попробовать расположить их в порядке, соответствующем полученному уравнению множественной регрессии, факторным нагрузкам или объясняемым факторам (см. главу Факторный анализ). Таким образом можно упростить и сделать более "однородным" общий вид пиктограмм, чтобы легче идентифицировать слабо выраженные различия. В то же время такой подход может затруднить идентификацию некоторых структур. На этом этапе можно дать только один универсальный совет: прежде чем использовать какие-либо сложные методы, попробуйте наиболее простой и быстрый вариант, а именно, случайную последовательность переменных. Попробуйте обнаружить какие-либо закономерности, например, сходства между группами пиктограмм, выбросы или определенные связи между элементами (например, " если первые два луча звезды длинные, то как правило, с другой стороны есть один или два коротких луча"). На этом этапе лучше использовать пиктографики кругового типа. При обнаружении закономерностей постарайтесь сформулировать их в терминах конкретных переменных. Измените соответствие переменных и элементов пиктограмм (или переключитесь на один из последовательных пиктографиков), чтобы проверить обнаруженную структуру взаимосвязей (например, попробуйте переместить ближе друг к другу элементы, между которыми обнаружена связь). В некоторых случаях в конце этого этапа целесообразно исключить из рассмотрения те переменные, которые не вносят явного вклада в обнаруженную структуру. И наконец, используйте один из численных методов (таких как регрессионный анализ, нелинейное оценивание, дискриминантный или кластерный анализ), чтобы проверить и попытаться количественно оценить обнаруженные закономерности или хотя бы их часть. Систематизация пиктографиков
Систематизация пиктографиков
Большинство пиктографиков можно отнести к одной из двух групп: круговые и последовательные.
Круговые пиктографики. Круговые пиктографики (звезды, лучи, многоугольники) имеют вид "велосипедного колеса", на них значения переменных представлены расстояниями между центром пиктограммы ("втулкой") и их концами.
Такие графики могут помочь в обнаружении связей между переменными, которые проявляются в общей структуре пиктограмм и зависят от конфигурации значений самих переменных.
Чтобы описать такую " общую картину" в терминах конкретных моделей или проверить имеющиеся предположения, имеет смысл использовать последовательные пиктографики, которые могут оказаться более эффективными, если уже известно, что именно требуется обнаружить.
Последовательные пиктографики. Последовательные пиктографики (столбцы, профили, линии) представляют собой набор картинок с маленькими последовательными графиками (различных типов).
Последовательные пиктографики. Последовательные пиктографики (столбцы, профили, линии) представляют собой набор картинок с маленькими последовательными графиками (различных типов).

Значения переменных представлены здесь расстояниями между основанием пиктограммы и последовательными точками (например, высотами показанных выше столбцов). Эти графики менее эффективны на начальной стадии разведочного анализа, поскольку пиктограммы очень похожи между собой. Однако, как уже упоминалось ранее, такое представление может быть весьма полезным для проверки уже сформулированной гипотезы.
Пиктограммы круговых диаграмм. Эти пиктографики нельзя однозначно отнести к одной из двух групп. Все они имеют круговую форму, но в то же время последовательно разделены в соответствии с значениями переменных.
Пиктограммы круговых диаграмм. Эти пиктографики нельзя однозначно отнести к одной из двух групп. Все они имеют круговую форму, но в то же время последовательно разделены в соответствии с значениями переменных.
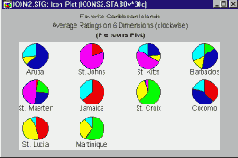
Их можно отнести скорее к последовательным, чем к круговым пиктографикам, но можно использовать и в том, и в другом случае.
"Лица Чернова". Этот тип пиктографиков составляет отдельную группу. Здесь каждое наблюдение представляет собой схематичное изображение лица, определенным чертам которого соответствуют относительные значения выбранных переменных.
"Лица Чернова". Этот тип пиктографиков составляет отдельную группу. Здесь каждое наблюдение представляет собой схематичное изображение лица, определенным чертам которого соответствуют относительные значения выбранных переменных.

Некоторые исследователи рассматривают этот способ графического представления данных как уникальный многомерный метод разведочного анализа, позволяющий выявить такие скрытые картины взаимосвязей между переменными, которые не могут быть обнаружены другими методами. Вероятно, такое заявление можно считать преувеличением. Кроме того, следует заметить, что этот способ исследования весьма непрост в применении и требует большого опыта в том, что касается сопоставления переменных чертам лица. См. также раздел Методы "добычи данных" .
Стандартизация значений
Стандартизация значений
Как правило, при построении пиктографиков значения переменных должны быть стандартизованы, чтобы их можно было сравнивать в пределах одной пиктограммы. Исключения составляют те случаи, когда на пиктограммах необходимо отобразить глобальные различия диапазонов выбранных переменных. Поскольку масштаб пиктограммы определяется наибольшим значением, то на пиктограмме могут отсутствовать те переменные, которые имеют значения другого порядка малости, например, на пиктограмме звезды некоторые лучи могут оказаться настолько короткими, что совсем не будут видны..
Применения
Применения
Пиктографики обычно используются: (1) для обнаружения структур или кластеров наблюдений и (2) для исследования сложных взаимосвязей между несколькими переменными. Первый вариант соответствует кластерному анализу; т.е. процедуре классификации наблюдений.
Предположим, вы изучали характеры актеров и записали их ответы на вопросы анкеты.
С помощью пиктографика можно определить, существуют ли группы артистов, которые отличаются по их ответам на заданные вопросы (можно, к примеру, обнаружить, что некоторые артисты являются творческими, недисциплинированными и независимыми личностями, в то время как другая группа состоит из умных, дисциплинированных людей, которые ценят свою популярность).
Другая область применений - изучение взаимосвязей между переменными - напоминает факторный анализ, который используется для исследования вопроса о зависимости переменных. Предположим, изучалось мнение группы людей о различных марках автомобилей. В файле данных записаны средние оценки по каждому из свойств (рассматриваемых как переменные) для каждого из автомобилей (рассматриваемых как наблюдения).
При изучении "лиц Чернова" (где каждое лицо представляет мнение об одном из автомобилей) может оказаться, что улыбающиеся лица обычно имеют большие уши; при этом, если цене соответствует "ширина" улыбки, а динамическим качествам - размер ушей, то это "открытие" означает, что быстрые машины являются более дорогими. Разумеется, это очень простой пример; однако при реальном анализе данных применение этого метода может сделать более очевидными сложные взаимосвязи между многими переменными.
Близкие способы графического представления
Близкие способы графического представления
Связи между переменными из одного или двух списков могут быть представлены на матричных графиках. Использование матричных графиков одновременно с выделением подгрупп позволяет получить информацию, подобную той, которая отображается на пиктографиках.
Если использовать методы выделения подгрупп на диаграммах рассеяния, то для исследования взаимосвязей между двумя переменными можно использовать обычные 2М диаграммы рассеяния; а в случае трех переменных - 3Мдиаграммы рассеяния.
Типы графиков
Типы графиков
Существуют различные типы пиктографиков.
"Лица Чернова". Для каждого наблюдения рисуется отдельное "лицо"; при этом относительные значения выбранных переменных соответствуют форме и размерам определенных его черт (например, длине носа, изгибу бровей, ширине лица).
Дополнительно см. абзац "Лица Чернова" в разделе Систематизация пиктографиков.
Звезды. Это пиктографики кругового типа. Для каждого наблюдения рисуется пиктограмма в виде звезды; относительные значения выбранных переменных соответствуют относительным длинам лучей каждой звезды (по часовой стрелке, начиная с 12:00). Концы лучей соединены линиями.

Лучи. Эти пиктографики также относятся к круговому типу. Для каждого наблюдения строится одна пиктограмма. Каждый луч соответствует одной из выбранных переменных (по часовой стрелке, начиная с 12:00), и на нем отложено значение соответствующей переменной. Эти значения соединены линиями.

Многоугольники. Это пиктографикикругового типа. Для каждого наблюдения рисуется отдельный многоугольник; относительные значения выбранных переменных соответствуют расстояниям вершин от центра многоугольника (по часовой стрелке, начиная с 12:00).

Круговые диаграммы. Это пиктографики кругового типа. Для каждого наблюдения рисуется круговая диаграмма; относительные значения выбранных переменных соответствуют размерам сегментов диаграммы (по часовой стрелке, начиная с 12:00).
Столбцы. Это пиктографики последовательного типа. Для каждого наблюдения строится столбчатая диаграмма; относительные значения выбранных переменных соответствуют высотам последовательных столбцов.
Линии. Это пиктографики последовательного типа.
Для каждого наблюдения строится линейный график; относительные значения выбранных переменных соответствуют расстояниям точек излома линии от основания графика.
Профили. Это пиктографики последовательного типа. Для каждого наблюдения строится зонный график; относительные значения выбранных переменных соответствуют расстояниям последовательных пиков сечения над линией основания.

Маркировка пиктограмм
Маркировка пиктограмм
Если программа позволяет вам выделять подгруппы наблюдений, то это свойство можно использовать и для маркировки соответствующих пиктограмм.
При этом вокруг выделенных пиктограмм будут нарисованы рамки.

Шаблоны рамок, идентифицирующих заданные подгруппы, будут показаны в условных обозначениях рядом с текстом соответствующих условий выбора наблюдений. На следующем графике показан пример маркированных подгрупп.

Все наблюдения, удовлетворяющие условию для подгруппы 1 (значение переменной Iristype равно значению переменной Setosa и номер наблюдения меньше 100), обозначены специальной рамкой вокруг пиктограммы.
А все наблюдения, которые удовлетворяют условию для подгруппы 2 (значение переменной Iristype равно значению переменной Virginic и номер наблюдения меньше 100), обозначены на графике рамкой другого цвета.
| В начало |
Выборка данных
Выборка данных
Иногда отображение на графике слишком большого числа точек данных затрудняет изучение их структуры (см. следующий рисунок). Если файл данных слишком большой, то имеет смысл показать на графике лишь подмножество наблюдений, чтобы общая картина не была скрыта маркерами точек.

Некоторые программы предлагают методы выборки (или оптимизации) данных, которые в ряде случаев могут оказаться весьма полезны. При этом пользователь может задать целое число n, меньшее числа наблюдений в файле данных, а программа случайным образом выберет из этого файла приблизительно n допустимых наблюдений и именно их построит на графике.
Заметим, что такие методы сокращения набора данных (или размера выборки) эффективно отображают случайную структуру этих данных. Очевидно, эти методы принципиально отличаются от методов выделения конкретного подмножества или подгруппы наблюдений с помощью определенных критериев (например, по полу, области или уровню холестерина). Последние можно применять интерактивно (например, в режиме динамического закрашивания) или каким-либо другим способом (например, на категоризованных графиках или с помощью условий выбора наблюдений). Все эти методы в равной мере могут помочь в идентификации сложной структуры большого набора данных.
| В начало |
Вращение (в трехмерном пространстве)
Вращение (в трехмерном пространстве)
Изменение угла зрения при отображении трехмерной диаграммы рассеяния (простой, спектральной или пространственной) может оказаться эффективным средством для выявления некоторой структуры, которая видна только при определенном повороте "облака" точек (см. следующий рисунок).
Некоторые программы предоставляют полезный инструмент для интерактивного изменения перспективы и вращения изображения. Эти средства контроля изображения позволяют подобрать подходящий угол зрения и перспективу, чтобы найти наиболее удачное расположение "точки зрения" на график, а также дают возможность управлять его вращением в горизонтальной и вертикальной плоскости.
Эти инструменты могут оказаться весьма полезными не только при начальном разведочном анализе данных, но и при исследовании факторного пространства (см.Факторный анализ) или пространства размерностей (см. Многомерное шкалирование).
| В начало |
(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.
ISO 9000 Bases
Основы ISO 9000
Введение Изучаемые темы ISO 9000, с чего начать? Основы Система STATISTICA Сравнение стандартов ISO 9000 Терминология и основные понятия Регистратор Аудиторы Технический специалист Ведущие аудиторы Поставщик Покупатель Аудиты первой, второй и третьей стороны Регистрация Инспектирование Консультант Документы I, II и III уровня Цель ISO 9000 Преимущества ISO 9000 Как внедрить ISO 9000 Этапы Пример регистрации компании Регистрационный процесс в подробностях До вызова регистратора Подбор регистратора и его действия Регистрация Подведем некоторые итоги Что спросить у регистратора Как подобрать консультанта Девять основных Требований ISO 9000, SPC. Введение Управление процессами Корректирующие и упреждающие действия Статистические методы Идентификация продукции и прослеживаемость Регистрация данных о качестве Контроль и проведение испытаний Статус контроля и испытаний Контроль документов и данных Контрольное, измерительное и испытательное оборудование Резюме
Введение
Изучаемые темы
ISO 9000, с чего начать?
Основы
Система STATISTICA
Сравнение стандартов ISO 9000
Терминология и основные понятия
Регистратор
Аудиторы
Технический специалист
Ведущие аудиторы
Поставщик
Покупатель
Аудиты первой, второй и третьей стороны
Регистрация
Инспектирование
Консультант
Документы I, II и III уровня
Цель ISO 9000
Преимущества ISO 9000
Как внедрить ISO 9000
Этапы
Пример регистрации компании
Регистрационный процесс в подробностях
До вызова регистратора
Подбор регистратора и его действия
Регистрация
Подведем некоторые итоги
Что спросить у регистратора
Как подобрать консультанта
Девять основных Требований ISO 9000, SPC.
Введение
Управление процессами
Корректирующие и упреждающие действия
Статистические методы
Идентификация продукции и прослеживаемость
Регистрация данных о качестве
Контроль и проведение испытаний
Статус контроля и испытаний
Контроль документов и данных
Контрольное, измерительное и испытательное оборудование
Резюме
Введение
ISO 9000 - это добровольный международный стандарт для системы управления процессом проверки качества. В этом курсе рассмотрены основные принципы стандарта, способ регистрации и реальные преимущества, которыми обладают зарегистрированные организации перед теми, кто еще не получил сертификат.
Изучаемые темы
Изучаемые темы
В рамках этого курса вы освоите следующее:
сущность и особенности ISO 9000
элементы системы управления процессом проверки качества
различные способы регистрации доступные компаниям
как подготовить компанию к регистрации
как обеспечить управление качеством
требования SPC (статистического контроля процессов)
ISO 9000, с чего начать?
Если Вы не знакомы с ISO 9000, пожалуйста, прочтите эти страницы. Я полагаю, Вы знаете очень мало по данному предмету, но Вам необходимо узнать о нем максимально много.
Недавно я посетил несколько конференций и семинаров по различным тематикам, начиная с юридических, заканчивая образовательными. ISO 9000 был основной темой для обсуждения. Возможно, это наиболее динамически развивающийся стандарт в области контроля качества, с тех пор, как были введены статистические методы.
Основы
Основы
Лучше всего начать изложение с основ. Во-первых, стандарт называется ISO 9000, но в действительности он объединяет пять стандартов.
ISO 9001 - Модель контроля качества в Проектировании, Разработке, Производстве, Монтаже и Обслуживании
ISO 9002 - Модель контроля качества в области Производства, Монтажа и Обслуживания
ISO 9003 - Модель для обеспечения качества при контроле и испытаниях готовой продукции
Указания по регистрационным стандартам:
ISO 9000-1 - Общие руководства по Выбору и Использованию
ISO 9004-2 - Управление качеством и элементы Системы качества - Указания
Фундаментальное положение, которое следует запомнить, заключается в том, что ISO 9000 является моделью управления системой контроля качества. Другими словами, главное внимание уделяется управлению Вашей компанией, от начала и до конца. Стандарт не является руководством по организации структуры отдела, занимающегося контролем качества.

Штаб-квартира IOS в Женеве
Международная Организация по Стандартизации (IOS= International Organization for Standardization) расположена в Женеве (Швейцария). ISO 9000 - это один из стандартов, который создала и успешно распространяет эта организация. Термин "iso" происходит от латинской основы "equal" - "равный."
Стандарт сообщается каждой стране - участнице организации, которая, в свою очередь, дает стандарту собственное национальное название. Например, авторскими провами на этот стандарт в США обладает Американский Национальный Институт Стандартов (ANSI=American National Standards Institute). Стандарт так же распространяется и поддерживается Американским Обществом Качества (ASQ= American Society for Quality). Таким образом, в США, он носит название ANSI/ASQ Q-9000: 1994. На данный момент, свыше 90 стран используют этот стандарт, и более 50 из них присвоили стандарту свои национальные обозначения. После принятия Россией международного стандарта ISO 9001-94 последовало его превращение в национальный ГОСТ P ИСО 9001-96. (Это справедливо и по отношению к стандартам ISO 9002 и 9003).
Каждый из трех регистрационных стандартов приведенных выше, является моделью для формирования системы управления качеством. Другими словами, как главное управление организует распределение полномочий по проверке качества в масштабах всей компании. Первоначально предполагалось, что ISO 9000 будет общим стандартом для компаний-заказчиков, предназначенным для сертификации продукции их поставщиков (это называется аудитом второго лица "second-party audit"). Однако, в 1990-х годах, ориентированные на потребителя требования по ISO 9000 быстро превратили его в аудит третьей стороны "third-party audit". Обычно компании требуется аудит третьей стороны для того, чтобы удовлетворить требованиям сразу нескольких заказчиков. Это тем более верно для компании участвующей в международной торговле.


С помощью STATISTICA процесс внедрения ISO 9000 уже не покажется рутинной работой. Тем более, что требования ISO 9000, касающиеся статистического контроля процессов, с преобретением промышленной STATISTICA удовлетворяются автоматически. Вот эти решения: карты контроля качества анализ производственных процессов планирование эксперимента А так же, совсем недавно, появилась мощнейшая система SEWSS, обеспечивающая контроль качества в масштабах производства. Данное корпоративное решение признано лучшим всеми независимыми изданиями, например, всемирно известным аналитическим журналом Scientific Computing World .
Движущей силой стандарта, благодаря которой он используется все шире, является Европейский Экономический Союз (EU= European Economic Union). Частью соглашения 1992 года, при формировании EU, было принятие ISO 9000 одним из стандартов, использование которого облегчило бы торговые отношения между участниками союза. Сегодня, свыше 60,000 фирм в Европе зарегистрированы в этом стандарте.
Иногда, к удивлению североамериканских фирм, стандарт ISO 9000 вдруг становится требованием в их взаимоотношениях с заказчиком. Это происходит потому, что многие европейские фирмы ведут расширенную коммерческую деятельность в северной Америке.Такие компании как DuPont, Sony и Volvo устанавливают требования ISO 9000 для своих поставщиков в Северной Америке.
В добавок, для свободного распространения внутри EU фармацевтической продукции требуется, чтобы она производилась только компаниями, имеющими сертификат ISO 9000. Таким образом, количество фирм-пользователей стандартом быстро возрастает. Любая компания, связанная с Европой или с европейской компанией находится под давлением на предмет сертификации ISO 9000.
Многие компании рассматривают ISO 9000 как отличное средство продвижения своей продукции на рынке. С целью роста, компании возлагают на стандарт большие надежды. Банки, юридические фирмы, даже школы задумываются о принятии моделей, предлагаемых ISO 9000.
По оценочным данным около 10,000 было зарегистрировано в США в начале 1997. Количество регистраций в США, Канаде и Мексике на данный момент одинаково. Чтобы понять то как все это работает, давайте рассмотрим некоторые данные.
Сравнение стандартов ISO 9000
Сравнение стандартов ISO 9000
Таблица 1
Таблица 1
| Элементы ISO 9001 (1994) | ISO 9002 | ISO 9003 |
| 4.1 Ответственность руководства | +++ | |
| 4.2 Система Качества | +++ | |
| 4.3 Анализ контракта | ||
| 4.4 Управление проектированием | *** | *** |
| 4.5 Управление документацией | ||
| 4.6 Закупки продукции | *** | |
| 4.7 Продукция, поставляемая потребителем | ||
| 4.8 Идентификация продукции и прослеживаемость | +++ | |
| 4.9 Управление процессами | *** | |
| 4.10 Контроль и проведение испытаний | ||
| 4.11 Контрольное, измерительное и испытательное оборудование |
||
| 4.12 Статус контроля и испытаний | ||
| 4.13 Управление несоответствующей продукцией | +++ | |
| 4.14 Корректирующие и предупреждающие действия | +++ | |
| 4.15 Погрузочно-разгрузочные работы, хранение, упаковка и поставка |
||
| 4.16 Регистрация данных о качестве | +++ | |
| 4.17 Внутренние проверки качества | ||
| 4.18 Подготовка кадров | +++ | |
| 4.19 Техническое обслуживание | *** | |
| 4.20 Статистические методы | +++ |
*** = не является требованием стандарта
+++ = уменьшено в объеме, заимствовано из ISO 9001 со сниженными требованиями Как Вы можете видеть, в каждом из этих стандартов много элементов. Мы рассмотрим лишь один или два из этих элементов достаточно подробно, чтобы вы хорошо поняли основные идеи стандарта.
Терминология и основные понятия
Давайте познакомимся с основними понятиями, которые играют важную роль в ISO 9000.
Регистратор
Регистратор
- это организация, которая проводит аудит третьей стороны, инспектирование и регистрацию. Регистратора, в свою очередь, проверяет национально признанная организация - аккредитующий орган. В США такую функцию выполняет Министерство Регистраций и Аккредитаций (RAB) . NACCB делает тоже самое в Великобритании , RvA в Нидерландах, Госстандарт в России. Именно регистратор проверяет Вашу компанию и сертифицирует её в случае удовлетворения требованиям ISO 9000. Аудиторы
Аудиторы
(иногда их называют асессорами) - это люди, которые приезжают, чтобы осмотреть Вашу компанию. Аудитору необходимо пройти курс и сдать сертификационный экзамен на тему, как проводить проверки ISO 9000 . Эти люди известны как сертифицированные аудиторы. У такого человека имеется регистрационный номер, выданный, например RAB,UKAS или RvA. Любой может называть себя аудитором, но только сертифицированные аудиторы являются легитимными асессорами ISO 9000. Регистратор обычно нанимает сертифицированных асессоров для выполнения аудиторской проверки в клиентской компании. Технический специалист
Технический специалист
- часто регистраторы прибегают к помощи технических специалистов и включают их в аудиторскую группу. Роль такого специалиста - заполнить недостающий пробел знаний в команде аудиторов в специфической области. Например, для проверки химической компании может потребоваться химик в команде аудиторов, для того, чтобы её члены были компетентными в наборе обычно выполняемых процедур, применяемых для контроля качества продукции на химическом производстве. Ведущие аудиторы
Ведущие аудиторы
(или ведущие асессоры) - В каждой аудиторской команде, создаваемой регистратором, имеется лидер. Этого человека называют главным аудитором. Звание главного аудитора присваивается регистратором. Так же, можно получить соответствующий сертификат . Сертифицированный главный аудитор - это человек, который удовлетворяет всем требованиям сертифицированного аудитора и состоял главным аудиторской группы по крайней мере в пяти аудиторских проверках под непостредственным надзором регистратора. Поставщик
Поставщик
- в терминологии стандарта ISO 9000 слово "поставщик" означает Вашу компанию - претендент на получение регистрации. Покупатель
Покупатель
- в стандарте ISO 9000 это еще один термин для Вашего потребителя. Аудиты первой, второй и третьей стороны
Аудиты первой, второй и третьей стороны
- когда Вы проводите внутреннюю проверку, это называется аудитом первой стороны, или первого лица (first-party). Когда Ваш потребитель проверяет Вашу систему качества, это называется аудитом второй стороны (second-party). Когда независимая организация (такая как регистратор) проверяет Вашу компанию, это называется аудитом третьей стороны (third- party). Регистрация
Регистрация
- это цель аудита третьего лица. Регистрация означает, что третья сторона (регистратор) сертифицировал Вашу компанию, как удовлетворяющую требованиям ISO 9000. Инспектирование
Инспектирование
- примерно дважды в год, сертифицированная или зарегистрированная компания должна пройти инспекцию у регистратора на предмет поддержания соответствия требованиям ISO 9000. Через 3 года, проводится перепроверка. Консультант
Консультант
- стороннее лицо, которое предлагается Вашей компании в качестве помощника для получения регистрации ISO 9000. На сегодня, не существует сертификатов, отражающих уровень подготовки консультанта. Таким образом, Вам следует подойти с осторожностью к проблеме выбора консультанта. Документы I, II и III уровня
Документы I, II и III уровня
- ISO 9000 использует уникальную схему именования документов.
Основные положения - " документ уровеня I." Стандартно выполняемые процедуры - "документ уровня II. " Рабочие инструкции и регистрация данных по качеству рассматриваются как "документ уровня III." Цель ISO 9000
Сначала, давайте поговорим о том, что не делает ISO 9000. Стандарт не гарантирует качество продукции. Фактически, качество продукта на прямую не упоминается в стандарте. Во-вторых, он не похож на другие требования к поставщику по проверке качества. Он содержит много похожих требований, но серьезность и объективность выполняемой процедуры регистрации очень отличается.
Цель ISO 9000 - внести согласованность и объективность в действия системы контроля качества поставщика. Предполагается, что ISO 9000 будет использоваться в отношениях между компаниями, обычно в форме потребитель/поставщик. Стандарт помогает компаням формализовать их систему управления процессом проверки качества и соответствия продукции. Подразумеваются постоянные дополнеиня. Использование независимого третьего лица улучшает доверительные отношения между оранизациями.
Требования стандарта не являются радикальными. Наоборот, они имеют свойство подстраиваться под существующую форму системы. Поэтому, Вам необходимо задокументировать политику Вашей фирмы , процедуры и рабочие инструкции. Они должны записываться для того, чтобы персонал выполнял их постоянно и неукоснительно. Записав, их также можно проверить на эффективность и поправить.
Предполагается, что ISO 9000 - гибкий стандарт. Если у Вас компания с уникальными методами работы, стандарт учитывает это. Возможны исключения и дополнения к требованиям.
Преимущества ISO 9000
Существуют три основных преимущества использования стандарта ISO 9000. Первое,- это удовлетворение регулирующим требованиям. Товары, связанные с безопасностью и здоровьем, продаваемые в Европе, уже регулируются требованием использовать стандарт. С каждым годом будет добавляться все большее количество подукции.
Второе, - это удовлетворение требованиям потребителя.
Наибольшее давление на предмет использования стандарта ISO 9000 исходит со стороные производственного рынка. Стандарт быстро становится международным минимумом по контролю качества. Значит, любая компания, торгующая зарубежом, должна придерживаться стандарта. Всякой компании следует опрашивать всех своих потребителей об их планах на ISO 9000. Вы можете удивиться количеству, но каждая начинает требовать стандарт или предполагает его использовать.
Третье заключается в том, что отличная модель ISO 9000 создает компании формализованную систему управления контролем качества. Фактически, ISO 9004-1 может использоваться отдельно как модель полного управления качеством.
Как внедрить ISO 9000
Ниже приводится короткое описание способа внедрения стандарта ISO 9000, как модель управления системой контроля качества. Такой подход не является обязательным. Мы настоятельно рекомендуем Вам обсудить его с Вашим персоналом и обговорить нестандартные элементы дела. Затем Вам следует подправить план внедрения стандарта для того, чтобы сделать этот процесс как можно эффективнее. Похожие этапы проходятся при внедрении других стандартов, таких как BS 7750, QS 9000, ISO 14000.
Этапы
Этапы
Существует несколько моделей введения ISO 9000. Следующий список- это сборная солянка нескольких подходов. 1. Обучиться самому . Если Вы советник по внедрению стандарта в Вашей организации, Вам следует очень ответственно подойти к изучению проблемы. Web-страницы поддержки (ISO 9000/QS-9000 Support Group) предоставляют Вам всю основную информацию по ISO 9000. После того, как Вы во всем хорошо разобрались, Вы можете выработать концепцию управления и начать процесс внедрения.
2. Создать управляющую комиссию. Управляющая комиссия - это группа главных менеджеров Вашей организации. Они принимают план внедрения проекта и следят за его выполнением. Управляющая комиссия также обрабатывает всю информацию, касающуюся введения ISO 9000 и выделяет необходимые средства. Для этой группы Вам обязательно следует провести дневной обзорный семинар по ISO 9000, чтобы они хорошо познакомились с процедурой регистрации.
3. Выбрать менеджера программы ISO 9000 . Вероятнее всего, что Вы будите менеджером программы. Если нет, то эту обязанность принимает на себя менеджер по качеству. Менеджер программы служит связующим звеном между Вашей компанией и регистратором. Он является контактным лицом компании, в обязанность которого входит отвечать на все вопросы регистраторов, касающиея управления системой контроля качества. Проследите, чтобы этот человек получил необходимые знания, хотябы на уровне квалифицированного внутреннего аудитора стандарта ISO 9000.
4. Проверить себя. Получите копию стандарта ISO 9000, выберите стандарт, который наилучшим образом применим к Вашей организации, а затем проверьте текущее положение дел в управлении качеством (проведите внутренний аудит). Если Вы менеджер программы и обучились проводить внутренний аудит для ISO 9000, Вы можете провести это самотестирование. Целью проверки является создание списка слабых мест в Вашей системе.
5. Составить программу для менеджеров. По результатам внутренней проверки Вы составляете план действий по исправлению слабых мест. Ответственность за выполнение программы должна быть возложена на ключевых менеджеров. Например, если уровень создания отчетов посчитался слабым, то Главный инженер получает задание по разработке более совершенной процедуры. Управляющая комиссия должна установить сроки выполнения проекта.
6. Написать инструкции. Документ I уровня - это набор инструкций о том, как Ваша компания планирует удовлетворить каждому из требований выбранного Вами стандарта. Управляющая комиссия сама может написать эти инструкции, пока разрабатываются новые процедуры по улучшению системы работы компании. Менеджер программы должен лично убедиться в том, что составленные инструкции удовлетворяют требованиям стандарта.
7. Разработать руководство II уровня. После того как менеджеры сделали слабые места Вашей компании сильными, соответствующие изменения проверяет управляющая комиссия.
8. Усовершенствовать документы III уровня.
Документы III уровня ( такие как рабочие инструкции) должны быть проверены на соответствие улучшенным процедурам.
9. Выбрать регистратора. Порядковый номер этого этапа- спорный вопрос. Некоторые консультанты советуют, что регистратора следует подбирать раньше, так чтобы можно было кому- нибудь задавать возникающие вопросы. Другие полагают, что начинать общение с регистратором следует только тогда, когда большая часть работы по внедрению уже выполнена. В любом случае, Вам желательно составить список регистраторов, в котором Вы будите отмечать уровень их квалификации. При знакомстве с регистратором спросите у них копию контракта, условия опаты и соглашения. Составьте список организаций, предоставляющих похожие услуги, и узнайте их условия прежде чем принимать решение. Убедитесь в том, что регистратор имеет опыт работы в вашем производственном направлении.
10. Проверить систему еще раз. После того, как вся документация в порядке, самое время провести повторный внутренний аудит в Вашей компании. Это поможет Вам выяснить готовы ли Вы приступить непосредственно к регистрационной проверке, или Вам еще нужно время.
11. Просмотр документации. Если Вы решили продолжить, передайте документы I уровня регистратору на официальное рассмотрение. Так же спланируйте время первого визита регистратора.
12. Предпроверка. Большинство регистраторов предлагают однодневную предпроверку Вашей системы ISO 9000. Всякой компании следует принять такое предложение, если она не до конца уверена в успешной процедуре регистрации. Регистратор изучит Вашу систему и предоставит письменный отчет о её соответствии.
13. Регистрационная проверка. В итоге, проводится регистрационная проверка компании на предмет её полного соответствия стандарту.
14. Регистрация. Если Вы соответствуете стандарту, Вас рекомендуют зарегистрировать. Если нет, от Вас потребуют создать план корректировки компании для достижения соответствия.
Как видите, это общий подход к проблеме внедрения ISO 9000. Некоторые компании предпочитают более формальный подход.
Пример регистрации компании
Пример регистрации компании
Теперь рассмотрим типичный пример компании, внедряющей стандарт ISO 9000. У Полиграфа Полиграфовича есть маленькая фирма, производящая печатные платы для компьютеров. В компании работают 200 человек. Шариков недавно услышал от своего потребителя - Преображенского, что ISO 9000 скоро станет требованием для поддержания их дальнейшего сотрудничества.
Полиграф Полиграфыч начал с того, что получил копию стандарта и некоторые описательные статьи. Он быстро освоил, что стандарт делится на пять частей. ISO 9000-1 говорит ему о том, какие из следующих трех стандартов ему следует выбрать. ISO 9001 кажется, не подходит , потому, что заказчик решает задачу конструирования плат. ISO 9003, получается, предназначен для дистрибьютеров. Таки образом, он выбирает ISO 9002. Похоже именно этот стандарт соответствует структуре его бизнеса. ISO 9004-1 дает технические рекомендации о том, как внедрить стандарт, в нашем случае, ISO 9002.
ISO 9002 предъявляет 19 требований. Полиграф Полиграфович решает, что следующий его шаг – проверить систему управления и выявить несоответствия стандарту. К сожалению, Шариков не уверен до конца в том, как это сделать. Поэтому, Полиграф Полиграфович записывается на обзорный семинар по ISO 9000. Затем он выбирает независимого аудитора – Шводера из состава его компании. Шариков и аудитор Швондер посещают теперь курс лекций "Внутренний аудит для ISO 9000." Здесь они научатся тому как проводить аудит в рамках стандарта ISO 9002.
Аудитор Шарикова, Швондер, теперь занимается проверкой компании и составляет письменный отчет, в котором говорится, что на данный момент компания удовлетворяет только лишь трем или четырем из девятнадцати требований. “Хорошенькое дело”, - думает Шариков и начинает работу с управляющим персоналом своей фирмы. Шариков готовит план действий.
Во-первых, управляющая комиссия составляет серию стратегических положений. Каждое положение объясняет то, какие действия собирается предпринять компания Шарикова, чтобы удовлетворить каждому требованию ISO 9002.
Список таких положений стставляет документ I уровня. На следующем этапе, каждая процедура, выполняемая в процессе производства будет проверена на предмет соответствия стандарту. Это называется документацией II уровня.
В процессе подготовки документации, Полиграф Полиграфович начинает подбирать регистратора. Он подбирает сертифицированного регистратора с опытом работы в электронной промышленности. Шариков интересуется ценами, услугами, рекомендациями, копией договора и прочим.
Позже Шариков подберет опытного регистратора, с которым, как ему кажется, будет удобнее всего работать. Регистратор начинает с того, что просит предоставить документацию I уровня. Представители регистратора обсуждают основные положения процесса регистрации с Шариковым и его управляющими. Затем они предоставляют обзорный отчет. Регистратор полагает, что документы I уровня выглядят отлично и планирует регистрационную проверку.
Прежде чем проводить проверку, Шариков проводит еще один внутренний аудит в компании, чтобы быть уверенным в том, что все нормально. Убедившись что все готово, Полиграф Полиграфович ожидает регистрационной проверки.
В течение трех дней, три аудитора проверяют всю систему управления контролем качества компании. Управление- ключевая цель аудита. Полисы, процедуры, рабочие инструкции и записи по качеству подвергаются тщательной проверке.
В последний день, аудиторы проводят заключительную встречу и подводят итоги проверки. Они обнаружили, что компания Шарикова удовлетворяет всем требованиям, за исключением двух составляющих. Полиграф Полиграфович и его менеджеры составляют план корректировки.
Через две недели Шариков получает официальный письменный отчет регистратора. Он, в свою очередь, высылает план корректировки, в котором указано, что на выполнение работы требуется 60 дней. Через 2 месяца главный аудитор возвращается для того, чтобы удостовериться, в том, что запланированные действия выполнены и оказались действенными.
Главный аудитор предоставляет конечный отчет по компании Шарикова и рекомендует её зарегистрировать.
Вскоре у Шарикова появляется сертификат стандарта ISO 9002, который можно размещать на печатном фирменном бланке и в объявлениях.
Регистрационный процесс в подробностях
Процесс регистрации ISO 9000 начинается с осознанного решения компании соблюдать стандарт. Таким образом, даже перед тем как вызывать регистратора следует пройти много стадий подготовки.
До вызова регистратора
До вызова регистратора
Первый шаг в регистрации – создание управляющего комитета. Без действий такого органа, шансы на регистрацию очень маленькие. Именно top management Вашей компании является основной целью регистрациононго процесса. Таким образом, менеджерам придется выделить время, деньги и персонал под этот проект. Самое важное, им придется участвовать в создании системы, которая будет соответствовать стандарту ISO 9000. Пожалуйста имейте в виду, что даже если ISO 9000 не является Вашей целью, вам все равно придется выполнять очень похожие действия при получении лицензий других стандартов, таких как TQM, Baldrige и других.
Следующим этапом, управление должно создать управляющую комиссию. Для маленькой компании её могли бы составить лишь один или два человека. В случае больших компаний в неё должны входить главные управляющие всех отделов. Эта комиссия будет заниматься составлением заданий, установкой сроков, проверкой выполненных проектов и постоянной проверкой системы на соответствие.
Другая обязанность комиссии – объяснить каждому служащему что такое ISO 9000, и какое участие он будет принимать в процессе регистрации.
Затем, управление назначает первый из многих внутренних аудитов на предмет соответствия стандарту ISO 9000. Можно воспользоваться услугами консультантов. Управление, в результате первой проверки, получает список дефектов (несоответствий) и план действий по их устранению.
В конечном итоге, управляющая комиссия составляет список действий для каждого отдела на основе рекомендаций первого внутреннего аудита. Комиссия будет наблюдать за правильностью выполнения работы во всех отделах.
Это позволяет отделам, отвечающим за определенные части ISO 9000 составить собственные инструкции и процедуры.
Затем, старые полисы и процедуры заменяются новыми. Для того, чтобы формализировать действия персонала, необходимо провести тренинги по новой системе во избежание ошибок. Задокументированные записи собираются для того, чтобы был заметен эффект вводимых процедур. После этого вызывают регистратора.
Подбор регистратора и его действия
Подбор регистратора и его действия
Регистратору придется удовлетворить как Ваши нужды так и требования Ваших заказчиков. После того как регистратор подобран, с ним начинают плотно сотрудничать. Первый шаг - заполнение начальной формы. Обычно она содержит анкету, куда заносятся данные о Вашей компании, и приложение. Некоторые регистраторы включают туда контракт, информационные материалы и прочее. Заполните форму и отошлите назад. Контракт следует подписывать только после того, как Вам предоставили прайс-лист и полный список условий регистрации.
Внимательно прочитайте контракт. Там говорится о ситуациях, в которых теряется регистрация. Рассмотрен процесс подачи жалобы, и ожидаемые действия. Спокойно торгуйтесь с регистраторами и сравнивайте их услуги и цены. Помните, что после подписания контракта Вы связываете свои отношения с регистратором примерно на три года.
Регистратор планирует первый визит обычно после подписания контракта. Главный аудитор, приписанный Вам, может пробыть в Вашей компании от двух часов до целого дня.
Вам следует показать ему работу компани. Это поможет ему узнать больше о Вас, и он спланирует наиболее еффективную проверку. В конечном итоге, он, попросит Вас предоставить документацию I уровня. Различные регистраторы проводят осмотр документов в разное время. Некоторые перед начальным визитом, другие лишь перед непосредственной регистрационной проверкой. Чем раньше Вы сможете добиться просмотра документации, тем лучше. Это даст Вам время на подготовку к встрече с главным асессором.
Основной элемент данного уровня – предпроверка.
Регистратор посылает одного или двух аудиторов проверить Вашу компанию на предмет несоответствий стандарту. Такую услугу придется оплатить. В результате у Вас будет краткий отчет о том, что им удалось найти.
Существует много толков по вопросам предпроверки. Многие консультанты считают, что к этому моменту Вам следует знать существуют ли в Вашей системе управления несответствия стандарту.
В конечном итоге, регистратор планирует регистрационную проверку. Обычно она продолжается в течение одного- пяти дней, в зависитмости от размеров компании. Она начинается с открытого совещания, где представители компании знакомятся с аудиторами. Встреча, как правило, короткая. На ней освещается план проверки и ожидаемые действия.
Каждый день аудиторы собирают сведения путем общения с персоналом, просмотра документации и наблюдения за процессом в действии. В конце проверки проводится заключительное собрание. На нем, главный асессор докладывает об обнаруженных нарушениях. Если не все в порядке, он даёт некоторые указания управляющим и отводит необходимое для исправлений время. Позднее, Вы получите письменный отчет об обнаруженных нарушениях (обычно в течение недели).
Если Вам не поступило требований по исправлению, значит Вас рекомендовали зарегистрировать. Отчет по проверке поступает в лицензионную комиссию регистратора для принятия конечного решения. Обычно, комиссия проводится раз в месяц (или раз в два месяца). Таким образом, Вам, возможно, придется немного подождать, пока не прийдет официальный документ, подтверждающий акт регистрации.
Если Вам необходимо провести доработку, регистрация откладывается до тех пор, пока Вы не пришлете письменного отчета о завершении работ. Затем, главный аудитор проводит дневную перепроверку Вашей системы. Как только все доработки будут завершены, Вас рекомендуют зарегистрировать.
Регистрация
Регистрация
После регистрации процесс только начинается. Теперь регистрационные органы будут проверять Вас дважы в год. Если находятся нарушения, Вам дается время на корректировку.
Если Вы не справляетесь, регистратор начинает процесс отзыва лицензии. В добавок, от Вас требуют проводить регулярные внутренние проверки. Эффективность системы управления – ключевая цель проверки. Таки образом, ISO 9000 подразумевает постоянное улучшение Вашей системы. Постоянное целенаправленное исправление системы качества в Ваших же интересах.
Через три года, регистратор высылает предложение по перепроверке. Это самая лучшая возможность для Вас поменять регистратора. У Вас есть от 6 месяцев до года на поиски регистратора перед плановой перепроверкой. Шансы на успешный исход проверки при смене регистратора практически не изменяются.
Подведем некоторые итоги Станадарты ISO 9000 были разработаны с целью оказания помощи компаниям в управлении системой контроля качеством путем внедрения идеальной модели управления. Вам следует просмотреть общие руководства и выбрать один из трех стандартов ISO 9001, 9002 или 9003. Вам следует провести анализ для того, чтобы определить на сколько Ваша система разнится с той, которую предлагает стандарт. Эта информация поможет Вам спланировать внедрение. Регистратор третьего уровня может отправить к Вам аудиторов для проведения проверки (аудита третьего лица) на предмет соответствия стандарту. Что спросить у регистратора
Что спросить у регистратора
Выбор регистратора, вероятно, самый важный шаг при получении сертификата ISO 9000. Неправильно выбранный регистратор может причинить головную боль. Однако, хорошо подобранный регистратор может значительно облегчить процесс регистрации. То, что компания хочет получить от регистратора, зависит от Ваших конкретных целей. Например, регистраторы могут быть признаны национальными аккредитационными органами ISO 9000, такими как NACCB в Великобритании или RvA в Нидерландах. Такое признание дает Вам возможность приема в Европейский Экономический Союз. Если Ваша компания имеет деловые связи с Европой, такое признание просто необходимо.
Ниже приводится список вопросов, которые рекомендуется задать регистратору.
Вам следует опросить по крайненей мере трех регистраторов для сравнения услуг и цен. Это сохранит Вам время и деньги.
1. Какие национальные организации признают Вашу регистрационную деятельность по ISO 9000?
Если Вам нужен сертификат ISO 9000, признаваемый вне Вашей страны, то поищите международно-признанного регистратора на Вашем целевом рынке.
2. Подписаны ли Вами соглашения о взаимном сотрудничестве “memorandums of understanding (MOUs)” с регистраторами из других стран?
Некоторые регистраторы без национального признания имеют подписанные соглашения с зарубежными регистраторами. Убедитесь в том, что те регистрационные органы покрывают Ваш целевой рынок.
3. Если Вами подписано MOU, сколько компаний получило с Вашей помощью единый сертификат?
Это проверка эффективности MOU. Некоторые договоры MOU никогда не использовались.
4. В какой сфере производства Вы выдаете сертификаты ISO 9000?
Одно из требований к регистратору, претендующему на национальное признание, - это ограничение производственных направлений в которых они выдают сертификаты. Убедитесь в том, что если Вы, скажем, компьютерная компания, то Вы выбрали регистратора, который уже сертифицировал другие компьютерные компании.
5. Сколько у Вас штатных и нештатных главных аудиторов?
Главному аудитору необходимо обучиться и получить сертификат в национально признанной организации. Сертифицированный аудитор – это цель регистратора, который хочет повысить уровень своих проверок.
6. Сколько компаний Вы зарегистрировали?
Это поможет выявить неопытных регистраторов.
7. Вы консультируете компании, которые Вы проверяете?
Технически, асессор не может консультировать и потом проверять одну и ту же компанию. Будьте осторожны с регистраторами. предлагающими обе услуги одновременно.
8. Сколько стоят услуги по: просмотру документации, пре-проверке, полной проверке, переезду и по плановому надзору?
Изучите цены регистратора. Это поможет в последствии при планировании непредвиденных расходов.
9. Сколько будет стоить регистрация нашей компании?
Для получения точных расценок Вам необходимо послать информацию о размерах Вашей компании и другой необходимой информации.
10. Могу я получить бесплатные рекомендации?
Вы хотите связаться с компаниями, которые были зарегистрированы данным орагном. Узнайте у них на сколько гладко все прошло и как соответствуют затраты на регистрацию заранее предложенным ценам.
11. Могу я получить список компаний, которые Вы зарегистрировали?
Эта информация говорит нам о том, с каким типом компаний они сотрудничали, на сколько большой опыт работы у регистратора, какой именно из стандартов наиболее часто внедряется с их помощью. Ежели регистратор занимался только стандартом ISO 9002, а Вам нужна регистрация ISO 9001, продолжайте поиски.
14. Сколько вы существуете на рынке?
Этот вопрос можно использовать для того, чтобы отличить твердо стоящую на ногах фирму от фирм-однодневок.
Как подобрать консультанта
Как подобрать консультанта
Консультирование и проверка на соответствие стандарту – разные вещи. Консультант обязан проникнуться существующей системой компании и помочь Вам поправить систему качества, а не перенести свой любимый шаблонный вариант управления на Вашу организацию. Толковый консультант должен иметь большой опыт работы с клиентами. Что следует узнать о консультанте:
1.Серитификация успешно прослушанные курсы на главного аудитора доведение до конца двух проверок под руководством главного аудитора предоставление детального отчета о любом успешно выполненном проекте 2. Подтверждение-пересертификация предъявление подтверждения успешной деятельности (например, письма как минимум двух клиентов и детальный отчет по выполненным проектам) выполнение двух проверок в год в качестве члена аудиторской комиссии или главного аудитора. Мы полагаем, что Вы учтете эти пожелания при выборе консультанта.
Девять основных Требований ISO 9000, SPC.
Введение
Введение
ISO 9000 особенно выделяет важность использования статистических методов в системе управления качеством. Основные принципы SPC (Статистический Контроль Процесса) просты для понимания и легко применимы.
Ими просто необходимо руководствоваться каждому, кто занимается контролем и повышением качества, а так же внедрением стандарта ISO 9000. SPC применяется для: определения дееспособности процесса определения соответствия продукта плановым спецификациям наблюдения за процессом с целью проверки его надежности планирования выборочного контроля, с целью экономии времени и средств Ниже дается обзор девяти базовых требований, предъявляемых к производственному процессу стандартом ISO 9000. А так же взгляд компании StatSoft на проблему удовлетворения этим требованиям.
Управление процессами
Управление процессами
Грамотное управление процессами гарантирует предсказуемость и стабильность качества продукции на всех этапах производства до получения конечной продукции. В сертифицируемой организации должны быть четкие рабочие инструкции установленного образца на все процессы, оказывающие влияние на качество продукции. Рабочие документы на процесс должны определять необходимое оборудование, производственную среду, нормативные документы, планы по качеству.
Применяемое оборудование должно иметь утвержденные рабочие инструкции, определяющие требования к его эксплуатации. Эти инструкции должны периодически пересматриваться в целях поддержания их соответствия установленным требованиям. Также в обязанности руководства организации входит обеспечение доступности для работников данных инструкций.
Грамотно спланировать промышленный эксперимент, без труда проанализировать производственный процесс, а так же постоянно контролировать качество продукции помогут соответствующие модули STATISTICA.
Корректирующие и упреждающие действия
Корректирующие и упреждающие действия
Данные действия должны основываться на любых жалобах потребителей, ошибках в обслуживании, записях по качеству и т.д. Они позволят обнаружить причины несоответствий и скорректировать процедуры с целью предупреждения любого несоответствия производимой продукции или оказываемой услуги установленным требованиям. Для этого необходимо: систематически проводить анализ несоответствующей продукции определять меры по усовершенствованию продукции и процессов осуществлять выработку корректирующих мероприятий во избежание рисков получения продукции низкого качества проводить контроль эффективности корректирующих действий вносить изменения в инструкции с целью исключения несоответствий Карты контроля качества системы STATISTICA позволяют выявить изменения ключевых параметров процесса и упредить возможные отклонения процесса от нормы даже в режиме реального времени. Методы модуля “планирование эксперимента” позволят усовершенствовать продукцию, максимизируя функцию эффективности производства.
Упреждение- это главная цель контроля качества и стандартов ISO.
Статистические методы
Статистические методы
Данный раздел говорит о том, что организация должна устанавливать статистические методы для подтверждения возможности производства своей продукции и достижения требуемых характеристик этой продукции. Все применяемые статистические методы должны быть задокументированы и верны.
Документация по системе качества должна включать в себя исчерпывающее руководство по использованию соответствующих методов, карт и статистик.
Справочная система STATISTICA содержит всю необходимую документацию. Она имеет простой интерфейс, который упрощает интерпретацию карт контроля качества. Все применяемые методы в STATISTICA безусловно верны и имеют научное обоснование.
ISO 9000 особо устанавливает, что результаты, нанесенные на карты контроля качества должны быть точными.
Идентификация продукции и прослеживаемость
Идентификация продукции и прослеживаемость
Под идентификацией продукции понимается обозначение изделия, а под прослеживаемостью - возможность определения его пути с самого начала. Организация должна поддерживать процедуры идентификации материалов и их движения в процессе производства, упаковки и поставки, чтобы обеспечить уверенность в удовлетворении требований потребителей. Организация ответственна за то, чтобы методы идентификации и прослеживаемости продукции были документально оформлены и имелась возможность продемонстрировать их соответствие требованиям потребителя.
STATISTICA предоставляет широкий выбор типизации данных (дата время и т.д.) в таблицах, облегчающий идентификацию
Регистрация данных о качестве
Регистрация данных о качестве
Организация должна регистрировать данные о качестве продукции. Эти данные обязательно содержат результаты внутренних проверок, оценки поставщиков, анализа контрактов с потребителями, пересмотра проектов, предпринятых корректирующих и предупреждающих действий, контроля и испытаний продукции. Данные о качестве должны быть точно определены, зафиксированы и храниться в легкодоступном месте.
При помощи этих данных обеспечивается прослеживаемость продукции.
Все данные в STATISTICA записываются и восстановимы в любой момент и наглядно представимы в форме таблиц. Вы свободно можете просмотреть как весь файл так и часть данных.
Контроль и проведение испытаний
Контроль и проведение испытаний
Контроль качества должен подтверждать выполнение заданных требований к продукции. Это включает в себя: входной контроль (материалы не должны использоваться в процессе без контроля; проверка входящего продукта должна соответствовать плану качества, закрепленным процедурам и может иметь различные формы) промежуточный контроль (организация должна иметь специальные документы, фиксирующие процедуру контроля и испытаний внутри процесса, и осуществлять этот контроль систематически) окончательный контроль (предназначен для выявления соответствия между фактическим конечным продуктом и тем, который предусмотрен планом по качеству; включает в себя результаты всех предыдущих проверок и отражает соответствие продукта необходимым требованиям) регистрация результатов контроля и испытаний (документы о результатах контроля и испытаний предоставляются заинтересованным организациям и лицам) Статус контроля и испытаний
Статус контроля и испытаний
Прохождение контроля и испытаний продукции должно подтверждаться наглядно (например, с помощью этикеток, бирок, пломб и т.д.). Те продукты, которые не соответствуют критериям проверки, отделяются от остальных. Также необходимо определить специалистов, ответственных за проведение такого контроля и установить их полномочия.
Контроль документов и данных
Контроль документов и данных
Действующая документация должна быть вовремя предоставлена, рассмотрена и принята уполномоченными специалистами. Все документы, определяющие порядок и методы выполнения требований стандартов ИСО, должны быть рассмотрены и одобрены руководством до их применения в производстве. Эти документы включают: политику организации в области качества; цели; Руководство по качеству; методики и процедуры контроля; отчеты о проверке работы и т.д.
Необходимо обеспечить, чтобы выпуски документов были доступны всем исполнителям, а устаревшая документация своевременно изымалась. Это означает: регулярную проверку документации (кем разработана, проверена, утверждена, срок ее действия и соответствует ли она действующим нормативным документам); распределение документации, т.е. ее рассылка, учет и своевременное внесение изменений во все копии; устранение устаревшей документации. Используя STATISTICA для SPC можно быть уверенным в том, что Ваши статистические вычисления верны и основаны на теории статистики.
Контрольное, измерительное и испытательное оборудование
Контрольное, измерительное и испытательное оборудование
Точность измерительного и испытательного оборудования влияет на достоверность оценки качества, поэтому обеспечение его качества особенно важно. При управлении контрольным, измерительным и испытательным оборудованием организация должна: определить, какие измерения должны быть сделаны, какими средствами и с какой точностью; оформить документально соответствие оборудования необходимым требованиям; регулярно проводить калибровку (проверку делений прибора); определить методику и периодичность калибровки; документально оформлять результаты калибровки; обеспечить условия применения измерительной техники с учетом параметров окружающей среды; устранять неисправные или непригодные контрольно-измерительные средства; производить регулировку оборудования и программного обеспечения с помощью только специально обученного персонала.
Резюме
Резюме
Таким образом, STATISTICA идеально подходит для решения задачи SPC на любом промышленном производстве. Использование STATISTICA значительно упростит процесс внедрения стандарта ISO 9000.
© Copyright StatSoft, Inc., 1984-2001
STATISTICA is a trademark of StatSoft, Inc.
Канонический анализ
Канонический анализ
Вводный обзор Вычислительные методы и результаты Предположения Основные идеи Суммы значений Канонические корни и переменные Число корней Извлечение корней
Вводный обзор
Вычислительные методы и результаты
Предположения
Основные идеи
Суммы значений
Канонические корни и переменные
Число корней
Извлечение корней
Вводный обзор
Вводный обзор
Во многих модулях STATISTICA можно вычислить парные коэффициенты корреляции для выражения зависимости между двумя переменными. Можно также вычислить матрицы парных коэффициентов корреляции. Например, коэффициент корреляции Пирсона (r) показывает степень линейной зависимости двумя переменными, измеренными в интервальной шкале. Модуль Непараметрическая статистика и распределения предлагает различные статистики, основанные на рангах исследуемых переменных. Модуль Множественная регрессия позволяет оценить зависимость между зависимой переменной (откликом) и множеством предикторных переменных. Модуль Многомерный анализ соответствий позволяет исследовать зависимости внутри множества категориальных переменных.
Модуль Каноническая корреляция
предназначен для анализа зависимостей между списками переменными. Если говорить точнее, он позволяет исследовать зависимость между двумя множествами переменных, и в этом смысле он развивает возможности других модулей. Например, исследователь в сфере образования может оценить зависимость между навыками по трем учебным дисциплинам и оценками по пяти школьным предметам. Социолог может исследовать зависимость между прогнозами социальных изменений, печатаемыми в двух газетах, и реальными изменениями, оцененными с помощью четырех различных статистических признаков. Медик может изучить зависимость между различными неблагоприятными факторами и появлением определенной группы симптомов заболевания. Во всех этих случаях нас интересует зависимость между двумя множествами переменных, для анализа которой и предназначен модуль Каноническая корреляция.
В следующих разделах мы кратко познакомим вас с основными идеями канонического анализа корреляции.
Предполагается, что вы уже знакомы с обычным коэффициентом корреляции, описанным в разделе Основные статистики и таблицы, а также имеете общее представление о множественной регрессии, описанной во Вводном обзоре раздела
Множественная регрессия.
| В начало |
Вычислительные методы и результаты
Вычислительные методы и результаты
Далее мы рассмотрим использование некоторых вычислительных методов и дадим пояснение основным получаемым результатам.
Собственные значения.
Собственные значения.
При вычислении канонических корней STATISTICA подсчитывает собственные значения матрицы корреляций. Эти значения равны доле дисперсии, объясняемой корреляцией между соответствующими каноническими переменными. При этом полученная доля вычисляется относительно дисперсии канонических переменных, т.е. взвешенных сумм по двум множествам переменных; таким образом, собственные значения не показывают абсолютного значения, объясняемого в соответствующих канонических переменных. При проведении анализа программа вычислит столько собственных значений, сколько имеется канонических корней, т.е. столько, сколько переменных имеется в наименьшем множестве.
Последовательно вычисляемые собственные значения будут все меньшего и меньшего размера.
Последовательно вычисляемые собственные значения будут все меньшего и меньшего размера.
На первом шаге программа вычисляет веса, максимизирующие корреляцию между взвешенными суммами по двум множествам и определяет соответствующее им значение первого корня. Далее, на каждом шаге, программа находит следующую пару канонических переменных, имеющих максимальную корреляцию и не
коррелированных с предыдущими парами, и вычисляет соответствующее ей значение канонического корня.
Канонические корреляции.
Канонические корреляции.
Если извлечь квадратный корень из полученных собственных значений, получим набор чисел, который можно проинтерпретировать как коэффициенты корреляции (см. также разделе Основные статистики и таблицы). Поскольку они относятся к каноническим переменным, их также называют каноническими корреляциями.
Как и собственные значения, корреляции между последовательно выделяемыми на каждом шаге каноническими переменными, убывают. Поэтому, в выводимом на экран отчете о коррелированности между множествами переменных часто приводят лишь первое, т.е. максимальное значение. Однако другие канонические переменные также могут быть значимо коррелированы, и эти корреляции часто допускают достаточно осмысленную интерпретацию.
Значимость корней.
Значимость корней.
Критерий значимости канонических корреляций сравнительно несложен. Во-первых, канонические корреляции оцениваются одна за другой в порядке убывания. Только те корни, которые оказались статистически значимыми, оставляются для последующего анализа. Хотя на самом деле вычисления происходят немного иначе. Программа сначала оценивает значимость всего набора корней, затем значимость набора, остающегося после удаления первого корня, второго корня, и т.д.
Некоторые авторы подвергали критике использование последовательных критериев значимости для канонических корней (см., например, работу Harris, 1976). Однако, эта процедура была "реабилитирована" с помощью метода Монте-Карло в вышедшей позднее книге Mendoza, Markos and Gonter (1978).
Исследования показали, что используемый критерий обнаруживает большие канонические корреляции даже при небольшом размере выборки (например, n = 50). Слабые канонические корреляции (например, R = .3) требуют больших размеров выборки (n > 200) для обнаружения в 50% случаев. Отметим, что канонические корреляции небольшого размера обычно не представляют практической ценности, поскольку им соответствует небольшая реальная изменчивость исходных данных. Чуть позднее, мы поговорим об этом подробнее, а также обсудим влияние на результаты размера выборки.
Канонические веса.
Канонические веса.
После определения числа значимых канонических корней возникает вопрос об интерпретации каждого (значимого) корня. Напомним, что каждый корень в действительности представляет две взвешенные суммы, по одной на каждое множество переменных.
Одним из способов толкования "смысла" каждого канонического корня является рассмотрение весов, сопоставленных каждому множеству переменных. Эти веса также называются каноническими весами.
При анализе, обычно, пользуются тем, что чем больше приписанный вес (т.е., абсолютное значение веса), тем больше вклад соответствующей переменной в значение канонической переменной. Для проведения более подробного сравнительного анализа обычно рассматриваются стандартизованные переменные, т.е. z-преобразованные переменные с
нулевым средним и единичным стандартным отклонением.
Если вы знакомы с множественной регрессией, вы можете применить для канонических весов интерпретацию, использованную для бета - весов в уравнении множественной регрессии. Канонические веса, в некотором смысле, аналогичны частным корреляциям переменных, соответствующих каноническому корню. Если вы знакомы с факторным анализом, то можете интерпретировать канонические веса аналогично весовым коэффициентам факторов. Таким образом, рассмотрение канонических весов позволяют понять "значение" каждого канонического корня, т.е. увидеть, как конкретные переменные в каждом множестве влияют на взвешенную сумму (т.е. каноническую переменную).
Канонические значения.
Канонические значения.
Канонические веса также могут использоваться для вычисления значений канонических переменных. Для этого достаточно сложить исходные переменные с соответствующими весовыми коэффициентами. Напомним, что канонические веса обычно
определяются для стандартизированных (z - преобразованных) переменных.
Факторная структура.
Факторная структура.
Еще одним способом интерпретации канонических корней является рассмотрение обычных корреляций между каноническими переменными (или факторами) и переменными из каждого множества. Эти корреляции также называются каноническими
нагрузками факторов. Считается, что переменные, сильно коррелированные с канонической переменной, имеют с ней много общего. Поэтому, при описании смысла канонической переменной следует исходить в основном из реального смысла этих сильно коррелированных переменных.
Такой способ интерпретации канонических переменных похож на метод, используемый в факторном анализе.
Факторная структура и канонические веса.
Факторная структура и канонические веса.
Иногда канонические веса для переменной оказываются близкими к нулю, а соответствующие им нагрузки очень велики. Также возможна обратная ситуация, когда канонические веса велики, а нагрузки небольшие. В таких случаях вывод может оказаться достаточно противоречивым. Однако следует помнить, что канонические веса соответствуют уникальному вкладу каждой переменной, а нагрузки канонических факторов представляют простые суммарные корреляции. Например, пусть в наше исследование удовлетворения от различных видов деятельности мы включили два вопроса, соответствующих примерно одному внешнему фактору: (1) "Удовлетворены ли вы отношениями с вашим руководителем подразделения?" и (2) "Удовлетворены ли вы отношениями с руководством?" Таким образом, ответы на эти вопросы содержат излишнюю информацию. Когда программа вычисляет веса для
взвешенных сумм (канонических переменных) по каждому множеству, максимизируя их корреляцию, ей потребуется включить в сумму только одну из этих двух переменных. Если при этом больший вес будет приписан первому ответу, вклад второго ответа становится несущественным. Следовательно, он получит нулевой или пренебрежительно малый вес. Тем не менее, если вы рассмотрите обычные корреляции между соответствующими суммарными значениями и значениями двух канонических переменных (т.е. нагрузки факторов), они могут оказаться существенными у обоих факторов. Таким образом, еще раз повторим, что канонические значения соответствуют уникальному вкладу вносимому соответствующей переменной во взвешенную сумму или каноническую переменную; нагрузки канонических факторов отражают полную корреляцию между соответствующей переменной и взвешенной суммой.
Извлеченная дисперсия.
Извлеченная дисперсия.
Коэффициенты канонической корреляции соответствуют корреляции между взвешенными суммами по двум множествам переменных.
Они не говорят ничего о том, какую часть изменчивости (дисперсии) каждый канонический корень объясняет в переменных. Однако, вы можете сделать заключение о доле объясняемой дисперсии, рассматривая нагрузки канонических факторов. Напомним, что они представляют собой корреляции между каноническими переменными и исходными переменными в соответствующем множестве. Если вы возведете эти корреляции в квадрат, полученные числа будут отражать долю дисперсии, объясняемую каждой переменной. Для каждого корня вы можете вычислить среднее значение этих долей. При этом получится средняя доля изменчивости объясненной в этом множестве на основании соответствующей канонической переменной. Другими словами, вы можете вычислить среднюю долю дисперсии, извлеченной каждым корнем.
Избыточность.
Избыточность.
Каноническая корреляция при возведении в квадрат дает долю дисперсии, общей для сумм по каждому множеству (канонической переменной). Если вы умножите эту долю на долю извлеченной дисперсии, вы получите меру избыточности множества переменных, т.е., величину, показывающую, насколько избыточно одно множество переменных, если задано другое множество. Избыточность может быть записана следующим образом:
Избыточностьлев = [

Избыточностьправ = [
В этих уравнениях, p обозначает число переменных в первом (левом) множестве переменных, а q число переменных во втором (правом) множестве. Величина Rc2 соответствует квадрату соответствующей канонической корреляции.
Отметим, что вы можете вычислить избыточность первого (левого) множества переменных при заданном втором (правом) множестве, и избыточность второго (правого) множества переменных при заданном первом (левом) множестве. Поскольку последовательно извлекаемые канонические корни не коррелированны между собой, то вы можете просто просуммировать избыточности по всем (или только по значимым) корням, получив при этом общий коэффициент избыточности (как предлагается в работе Stewart and Love, 1968).
Практическая значимость.
Практическая значимость.
Для измерения избыточности также бывает полезным определение практической значимости канонических корней. При больших размерах выборки (см. ниже), канонические корреляции со значением R = .30 могут оказаться статистически значимыми (см. выше). Если возвести этот коэффициент в квадрат (R-квадрат = .09) и использовать формулу для избыточности, становится ясным, что такие канонические корни объясняют лишь незначительную долю изменчивости переменных. Хотя, разумеется, окончательное решение о практической значимости принимается на основании субъективной позиции исследователя. Однако для получения правдоподобных оценок того, насколько реальная изменчивость переменных объясняется конкретным каноническим корнем, бывает полезным не забывать о мере избыточности, т.е., о том насколько реальная изменчивость в одном множестве переменных объясняется другим множеством.
| В начало |
Предположения
Предположения
В этом разделе приводится список наиболее важных предположений анализа канонической корреляции, выполнение которых обеспечивает получение достоверных и обоснованных результатов.
Распределение.
Распределение.
Применение критерия значимости при анализе канонической корреляции основано на предположении, что переменные в выборке имеют многомерное нормальное распределение. Как и большинство других модулей пакета STATISTICA, модуль Каноническая корреляция позволяет провести графический анализ данных, т.е., построить гистограмму частот с наложенной на нее нормальной кривой, или вывести на экран диаграмму рассеяния наблюдаемой переменной. Теоретически, последствия нарушения этого предположения мало изучены. Однако при очень больших размерах выборки (см. ниже) результаты анализа канонической корреляции достаточно устойчивы или робастны.
Объем выборки.
Объем выборки.
В книге Stevens (1986) приводится подробное обсуждение размера выборки, необходимого для получения достоверных результатов. Как уже говорилось, при наличии больших корреляций между данными (например, R > .7), даже малые размеры выборки (например, n = 50) позволяют в большинстве случаев обнаружить эти корреляции.
Однако, для получения достоверных оценок нагрузок канонических факторов (для интерпретации), Стивенс рекомендует использовать как минимум в 20 раз больше наблюдений, чем число переменных, используемых в анализе, если нужно интерпретировать только наиболее значимый корень. Для получения достоверных оценок
для двух канонических корней, в книге Barcikowski and Stevens (1975) авторы рекомендуют, основываясь на исследовании с помощью метода Монте-Карло, использовать в 40 - 60 раз больше наблюдений, чем число исследуемых переменных.
Выбросы.
Выбросы.
Наличие выбросов может оказывать большое влияние на значение коэффициентов корреляции (см. Основные статистики и таблицы). Поэтому выбросы могут оказывать заметное влияние на вычисление канонических корреляций. Конечно, чем больше размер выборки, тем меньшее значение оказывают один или два выброса. Однако при проведении анализа все-таки хорошо было бы построить диаграмму рассеяния (как показано на анимационном ролике внизу)
См. также Доверительный эллипс.
Плохо обусловленные матрицы.
Плохо обусловленные матрицы.
Еще одним предположением является требование, чтобы переменные в обоих множествах не были полностью избыточным. Например, если включить одну и ту же переменную дважды в одно из множеств, то окажется непонятным, какие ей следует придать веса. С вычислительной точки зрения, такая избыточность нарушает ход анализа. При наличии полной коррелированности между наблюдаемыми переменными (R = 1.0) корреляционная матрица не может быть обращена, и вычисления, необходимые для анализа канонической корреляции, таким образом, не могут быть завершены. Подобные корреляционные матрицы называются плохо обусловленными.
Таким образом, смысл этого предположения достаточно прост. Однако, при анализе большого количества сильно избыточных переменных, как бывает при анализе ответов в массовых опросах, оно зачастую "почти" нарушается.
| В начало |
Основные идеи
Основные идеи
В качестве примера использования анализа канонических корреляций рассмотрим исследование анкет некоторого опроса.
Анкетируемые оценивали свое удовлетворение от выполняемой ими работы, отвечая на три вопроса, а также удовлетворение от деятельности в других сферах, отвечая еще на семь вопросов. Нам хотелось бы понять, как связано удовлетворение от работы с удовлетворением, получаемым в другой сфере жизни.
Суммы значений
Суммы значений
Проще всего просуммировать значения откликов по двум множествам вопросов и посчитать корреляцию полученных сумм. Если полученная корреляция статистически значима, можно заключить, что существует зависимость между удовлетворением от работы и удовлетворением в других сферах.
Следует, однако, заметить, что это достаточно поспешное заключение. Ведь мы так ничего и не узнали о связи удовлетворения в конкретных сферах и удовлетворения от работы. По сути дела, упрощая задачу и суммируя отклики, мы, в общем случае, теряем важную информацию. Например, если значения двух откликов второго множества соответствуют удовлетворению от отношений с супругом и удовлетворению от финансового положения, то складывать их все равно, что складывать яблоки с апельсинами. Таким образом, мы заранее предположили, что материально обеспеченный человек, имеющий проблемы в отношениях с супругом, в целом сравним с необеспеченным, но счастливым в личной жизни человеком. Скорее всего, психологический портрет человека не настолько прост...
Проблема заключается в том, что, просто вычисляя корреляцию сумм по множествам, мы теряем важную информацию, и, возможно, просто "разрушаем" существующие зависимости между переменными, складывая "яблоки с апельсинами".
Использование взвешенных сумм.
Использование взвешенных сумм.
Для исправления положения разумно немного изменить изучаемые объекты. Вместо рассмотрения обычных сумм по множествам, полезно рассматривать взвешенные суммы, чтобы веса, приписанные отдельным слагаемым, соответствовали реальной "структуре" переменных, т.е. их взаимной значимости. Например, если на удовлетворение, получаемое от работы, мало влияет удовлетворение от отношений с супругом, но сильно влияет удовлетворение от материального положения, первому следует придать меньший вес, чем второму.
Эту общую идею можно выразить следующим уравнением:
a1*y1 + a2*y2 + ... + ap*yp = b1*x1 + b2*x2 + ... + bq*xq
Таким образом, если у нас имеется два множества, содержащие p и q переменных соответственно, мы будем исследовать зависимость между взвешенными суммами переменных из каждого множества (т.е., между линейными комбинациями p и q переменных соответственно).
Определение весов.
Определение весов.
После того, как мы сформулировали в общем виде "уравнение модели" для канонической корреляции, нам осталось только определить веса для двух наборов переменных. Взвешенные суммы, слабо коррелированные друг с другом, не представляют никакого интереса для исследователя, поэтому при подборе весовых коэффициентов мы будем исходить из условия максимальной коррелированности двух множеств.
| В начало |
Канонические корни/переменные
Канонические корни/переменные
Используя терминологию анализа канонической корреляции, можно сказать, что взвешенные суммы определяют канонический корень или каноническую переменную. Эти канонические переменные (взвешенные суммы) можно рассматривать как обозначения некоторых "скрытых" переменных, лежащих в основе наблюдаемых явлений. Например, если для второго рассматриваемого множества факторов (связанного с получением удовлетворения от различных сфер деятельности), мы получим взвешенную сумму с большими весами для факторов, относящихся к удовлетворению от работы, то можем заключить, что соответствующая каноническая переменная измеряет удовлетворение от
работы.
Число корней
Число корней
До сих мы предполагали, что для двух наборов переменных имеется ровно одна пара канонических переменных (взвешенных сумм). Однако, возможно, что множество факторов, касающихся удовлетворения от работы содержит факторы, связанные с удовлетворением размером заработной платы и отношениями с коллегами по работе. Тогда логично допустить, что удовлетворенность размером заработной платы коррелированна с удовлетворенностью материальным положением, а удовлетворенность отношениями с коллегами по работе коррелированна с удовлетворенностью отношениями с супругом.
В таком случае полезно рассмотреть две дополнительные взвешенные суммы, отражающие сложность структуры исследуемых данных.
В действительности, канонический анализ практически всегда приводит к вычислению более чем одной пары взвешенных сумм. Если быть точным, число канонических корней вычисляемых программой равно числу переменных в меньшем множестве. В нашем примере, когда анализируемые группы содержали три и семь переменных соответственно, число канонических корней будет равно трем.
Извлечение корней
Извлечение корней
Как мы уже отметили, при вычислении корней программа рассматривает все максимально коррелированные взвешенные суммы (максимизирует значение корреляции между каноническими переменными). При вычислении более чем одного корня каждая последующая пара канонических переменных объясняет свою уникальную долю изменчивости в этих двух наборах переменных. При этом последовательно получаемые пары канонических переменных не коррелированны друг с другом и объясняют все меньшую и меньшую долю изменчивости.
| В начало |
© Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.
Карты контроля качества
Карты контроля качества
Основные задачи Общий подход Установка контрольных пределов Наиболее часто используемые типы контрольных карт Краткие контрольные карты Краткие карты для переменных Краткие карты по альтернативному признаку Многопоточные групповые карты Неравные объемы выборок Контрольные карты для переменных и карты по альтернативному признаку Контрольные карты для отдельных наблюдений Разладка процесса: критерии серий Операционные характеристики (ОХ-кривые) Индексы пригодности процесса Другие специальные типы контрольных карт
Основные задачи
Основные задачи
Общий подход
Установка контрольных пределов
Наиболее часто используемые типы контрольных карт
Краткие контрольные карты
Краткие карты для переменных
Краткие карты по альтернативному признаку
Многопоточные групповые карты
Неравные объемы выборок
Контрольные карты для переменных и карты по альтернативному признаку
Контрольные карты для отдельных наблюдений
Разладка процесса: критерии серий
Операционные характеристики (ОХ-кривые)
Индексы пригодности процесса
Другие специальные типы контрольных карт
Основные задачи
При организации любого производственного процесса возникает задача установки пределов характеристик изделия, в рамках которых произведенная продукция удовлетворяет своему предназначению. Вообще говоря, существует два "врага" качества продукции: (1) отклонения от плановых спецификаций и (2) слишком большой разброс реальных характеристик изделий (относительно плановых спецификаций). На ранних стадиях отладки производственного процесса для оптимизации этих двух показателей качества часто используются методы планирования эксперимента (см. Планирование эксперимента). Методы, содержащиеся в модуле "Контроль качества", предназначены для построения процедур контроля качества продукции в процессе ее производства, т.е. текущего контроля качества. За детальным описанием принципов построения контрольных карт и примерам обратитесь к работам Buffa (1972), Duncan (1974), Grant and Leavenworth (1980), Juran (1962), Juran and Gryna (1970), Montgomery (1985, 1991), Shirland (1993) или Vaughn (1974).
В качестве превосходных вводных курсов, построенных на основе подхода "как - чтобы", можно указать монографии Hart and Hart (1989) и Pyzdek (1989), а также изданные на немецком языке курсы Rinne and Mittag (1995) и Mittag (1993).
| В начало |
Общий подход
Общий подход
Общий подход к текущему контролю качества достаточно прост. В процессе производства проводятся выборки изделий заданного объема. После этого на специально разлинованной бумаге строятся диаграммы изменчивости выборочных значений плановых спецификаций в этих выборках и рассматривается степень их близости к заданным значениям. Если диаграммы обнаруживают наличие тренда выборочных значений или оказывается, что выборочные значения находятся вне заданных пределов, то считается, что процесс вышел из-под контроля, и предпринимаются необходимые действия для того, чтобы найти причину его разладки. Иногда такие специально разлинованные бумаги называют контрольными картами Шуэрта (в честь W. A. Shewhart, который общепризнанно считается первым, применившим на практике описываемые здесь методы анализа; см. Shewhart, 1931). Интерпретация контрольных карт.
Интерпретация контрольных карт.
В компьютерном варианте контрольных карт наиболее часто встречается ситуация, когда на экране находятся две карты (и две гистограммы), одна из них называется Х-картой, а другая - R-картой.
В обеих контрольных картах по горизонтальной оси откладываются номера соответствующих выборок; по вертикальной оси в случае X -карты отложены выборочные средние исследуемых характеристик, а в случае R-карты - размахи соответствующих выборок. Пусть, например, производятся контрольные измерения диаметра поршневых колец, изготавливаемых на вашем предприятии. Тогда центральная линия на X -карте будет соответствовать размеру, используемому в качестве стандарта (например, установленному диаметру кольца в миллиметрах), в то время как центральная линия R-карты будет соответствовать приемлемому (т.е.
находящемуся в пределах плановой спецификации) размаху диаметра поршневого кольца в выборках; таким образом, последняя контрольная карта представляет собой карту изменчивости процесса (чем больше изменчивость, тем больше диапазон отклонения от стандарта). Кроме центральной линии, на карте обычно присутствуют две дополнительные горизонтальные прямые, обозначающие верхний и нижний контрольные пределы (ВКП и НКП соответственно). Принципы определения этих линий обсуждаются ниже. Обычно нанесенные на карты отдельные точки соответствуют выборочным значениям и соединяются прямыми линиями. Если результирующая кривая на графике выходит за верхний или нижний контрольный предел или ее конфигурация выражает определенную тенденцию поведения для следующих друг за другом выборок (см. Критерий серий), то это рассматривается как указание на существование проблем с качеством.
| В начало |
Установка контрольных пределов
Установка контрольных пределов
Несмотря на то, что можно достаточно произвольно определить момент разладки производственного процесса (например, при выходе соответствующих значений за границы верхних и нижних контрольных пределов), обычной практикой является применение статистических методов для определения этого момента. В разделе Элементарные понятия статистики обсуждаются свойства выборочного распределения, а также дается сводка характеристик нормального распределения. Метод установления верхнего и нижнего контрольных пределов представляет собой прямое следствие применения описанных в этом разделе принципов. Пример.
Пример.
Предположим, вы контролируете среднее значение некоторой величины - например, диаметра поршневых колец. Пусть среднее значение диаметров и дисперсия в процессе производства не меняются. Тогда выборочные средние, полученные для последовательных выборок, будут распределены нормально относительно истинного среднего. Более того, не вдаваясь в тонкости, связанные с выводом формул, можно заключить (согласно центральной предельной теореме и сделанному предположению о нормальности выборочных средних размеров колец; см, например, работу Hoyer and Ellis, 1996), что стандартное отклонение распределения выборочных средних будет равно сигме (стандартному отклонению отдельных наблюдений или измерений диаметра отдельных колец), деленному на квадратный корень из n (n - размер выборки).
Следовательно, примерно 95% значений выборочных средних попадут в интервал

Общий случай.
Общий случай.
Описанный выше частный принцип установления контрольных пределов применяется во всех типах контрольных карт. После выбора контролируемой характеристики (например, стандартного отклонения) оценивается ее ожидаемая изменчивость в выборках того размера, который будет использоваться в контролируемой процедуре. Затем с помощью полученных оценок изменчивости устанавливают контрольные пределы карты.
| В начало |
Наиболее часто используемые типы контрольных карт
Наиболее часто используемые типы контрольных карт
Классификация типов контрольных карт часто осуществляется согласно типам величин, которые выбраны для отслеживания характеристик качества. Так, различают контрольные карты для непрерывных переменных и контрольные карты по альтернативному признаку. В частности, для контроля по непрерывному признаку обычно строятся следующие контрольные карты: X-карта. На эту контрольную карту наносятся значения выборочных средних для того, чтобы контролировать отклонение от среднего значения непрерывной переменной (например, диаметров поршневых колец, прочности материала и т.д.). R-карта. Для контроля за степенью изменчивости непрерывной величины в контрольной карте этого типа строятся значения размахов выборок. S-карта. Для контроля за степенью изменчивости непрерывной переменной в контрольной карте данного типа рассматриваются значения выборочных стандартных отклонений. S**2-карта. В контрольной карте данного типа для контроля изменчивости строится график выборочных дисперсий. Для контроля качества продукции по альтернативному признаку обычно применяются следующие типы контрольных карт: C-карта. В таких контрольных картах строится график числа дефектов (в партии, в день, на один станок, в расчете на 100 футов трубы и т.п.).
При использовании карты этого типа делается предположение, что дефекты контролируемой характеристики продукции встречаются сравнительно редко, при этом контрольные пределы для данного типа карт рассчитываются на основе свойств распределения Пуассона (распределения редких событий).

| В начало |
Краткие контрольные карты
Краткие контрольные карты
Краткая контрольная карта ( контрольная карта для кратких производственных серий) представляет собой график наблюдаемых значений характеристик качества (значений непрерывной переменной или альтернативного признака) для нескольких частей процесса, причем все значения контролируемой характеристики наносятся на одну и ту же карту. Разработка кратких контрольных карт стала следствием необходимости адаптации контрольных карт к тем ситуациям, когда требуется выполнить несколько десятков измерений контролируемой характеристики процесса, прежде чем вычислить контрольные пределы. Часто данное требование выполняется с трудом на тех стадиях производственного процесса, в ходе которых изготавливается ограниченное (малое) число деталей, которые необходимо подвергнуть измерениям. Так, например, на целлюлозно-бумажном комбинате процесс может быть организован следующим образом: выпускается только три-четыре больших рулона бумаги определенного сорта (часть процесса), а затем переходят к выпуску бумаги другого сорта. Однако, если измерения переменных (таких, например, как толщина бумаги или альтернативных признаков, таких, как наличие/отсутствие пятен) производятся для нескольких десятков рулонов, скажем, десяти различных сортов, то контрольные пределы для переменной "толщина бумаги" и признака "наличие/отсутствие пятен" могут быть вычислены на основе преобразованных значений (в рамках краткой производственной серии). Более точно, эти преобразования заключаются в таком изменении масштаба контролируемых переменных, при котором амплитуды их изменения в различных производственных сериях (различных частях процесса) будут сравнимыми. Контрольные пределы, рассчитанные по этим преобразованным значениям, могут применяться в дальнейшем при контроле толщины бумаги и наличия/отсутствия пятен, вне зависимости от сорта выпускаемой бумаги. Для того чтобы определить, произошла разладка процесса или нет, могут быть использованы статистические процедуры контроля процесса.
Этими процедурами можно воспользоваться также для постоянного контроля производства и разработки способов постоянного улучшения качества.
Более подробное описание кратких карт контроля качества можно найти в работах Bothe (1988), Johnson (1987) или Montgomery (1991).
Краткие карты для переменных
Краткие карты для переменных
Номинальная карта, карта плановых спецификаций.
Номинальная карта, карта плановых спецификаций.
Существует несколько типов кратких контрольных карт. Наиболее часто используются следующие карты: номинальная карта и карта плановых спецификаций. При построении данных карт преобразование наблюдаемых значений контролируемой характеристики в различных частях процесса производится путем вычитания определенной постоянной из измерений (для наблюдений каждой части используется своя постоянная). В качестве таких постоянных могут выступать как значения номинала для соответствующих частей процесса (результатом такого подхода будет номинальная краткая карта), так и плановые спецификации, рассчитанные по "историческим" средним контролируемой характеристики для каждой части (краткая X-карта плановых спецификаций и краткая R-карта плановых спецификаций). Так, например, сравнение внутренних диаметров поршневых колец для различных блоков мотора, находящихся в производстве, только тогда может быть обоснованно, когда до проведения сравнения из измерений диаметров будут вычтены средние разности между внутренними диаметрами поршневых колец для моторов различного размера (для определения непротиворечивости значений диаметров). Такое сравнение становится возможным при построении краткой номинальной карты или краткой карты плановых спецификаций. Заметим, что при построении номинальной карты и карты плановых спецификаций делается предположение о равенстве дисперсий различных частей процесса, чтобы применение рассчитанных по общей оценке сигма процесса контрольных пределов можно было считать корректным.
Стандартизованная краткая карта.
Стандартизованная краткая карта.
Если изменчивость различных частей процесса нельзя считать одинаковой, то прежде чем нанести на одну карту данные, относящиеся к разным частям процесса, необходимо провести еще одно преобразование. При построении карты данного типа это преобразование заключается в следующем: вычисляются отклонения выборочных средних контролируемой характеристики от средних для соответствующих частей процесса (т.е. от номинальных значений или плановых спецификаций для частей), далее для каждой части процесса эти отклонения делятся на постоянные, пропорциональные изменчивости соответствующих частей. Так, в случае кратких X-карты и R-карты, для построения точек графика X-карты вначале из каждого выборочного среднего вычитается определенная постоянная, соответствующая рассматриваемой части процесса (т.е. среднее этой части процесса или значение номинала для данной части), затем эта разность делится на другую постоянную - например на средний размах соответствующей части процесса. В результате таких преобразований масштабы выборочных средних различных частей процесса станут сравнимыми.
Краткие карты по альтернативному признаку
Краткие карты по альтернативному признаку
В случае контрольных карт по альтернативному признаку (C-, U-, Np- или P-карт) оценка изменчивости процесса (доля, частота и т.д.) зависит от среднего значения процесса (средней доли, средней относительной частоты и т.д.) - так, например, стандартное отклонение доли p равно квадратному корню из p*(1-p)/n). Следовательно, для альтернативных признаков могут быть построены только стандартизованные краткие карты. К примеру, точки краткой P-карты находятся вычитанием из соответствующих выборочных значений долей p средних p для части процесса, с последующим делением результата на стандартное отклонение средних p.
| В начало |
Многопоточные групповые карты
Многопоточные групповые карты
Групповая контрольная карта дает возможность нанести данные для нескольких потоков наблюдаемых значений непрерывной переменной или альтернативного признака (характеристик качества) на одну и ту же карту.
Это упрощает интерпретацию карты при одновременном управлении большим числом процессов или их характеристик. Здесь термином "потоки процесса" могут обозначаться данные, полученные для различных станков, сборочных линий, операторов и так далее. Все эти данные могут быть нанесены на одну контрольную карту. При построении групповой X-карты для каждой из выборок с измерениями контролируемой характеристики на карту наносится две точки, в результате чего на графике образуются две линии. Верхняя из них представляет собой график наиболее высоких средних значений каждой выборки для всех нанесенных на карту потоков переменных или альтернативных признаков, а нижняя - подобный график наименьших средних значений каждой выборки. Для каждой выборки верхняя и нижняя точка представляют собой максимальное и минимальное средние всех нанесенных на карту потоков переменных или альтернативных признаков. Если эти экстремальные значения не выходят за рамки заданных контрольных пределов, очевидно, что все остальные средние также будут находиться в области, ограниченной контрольными пределами. Следовательно, с помощью групповой X-карты, можно быстро определить, не началась ли разладка процесса в одном или нескольких потоках процесса или контролируемых характеристиках, не переходя к проверке всех измерений подряд.
В групповых R-, S- или S**2-картах для переменных, как и в групповых C-, U-, Np- или P-картах для альтернативных признаков, две точки, наносимые на карту для каждой выборки, соответствуют минимальному и максимальному размаху, стандартному отклонению и т.п. от средних переменных или альтернативных признаков, измеряемых для каждой выборки в нескольких потоках. Как и в случае групповой X-карты, сравнение этих экстремальных значений с заданными контрольными пределами дает возможность быстро определить, не началась ли разладка потока процесса или его контролируемой характеристики.
Групповая карта для одной части процесса называется стандартной групповой картой или, обычно, просто групповой картой.
Групповые карты для нескольких частей процесса называются групповыми краткими картами. Для построения групповых кратких карт используется та же процедура, что и для стандартных групповых карт; единственное их отличие от стандартных состоит в том, что точки на график наносятся только после того, как будут выполнены все преобразования данных в пределах отдельных частей процесса.
| В начало |
Неравные объемы выборок
Неравные объемы выборок
При построении на контрольной карте графика для выборок неодинакового объема контрольные пределы, находящиеся по обе стороны от центральной линии (плановой спецификации), не могут быть изображены прямыми линиями. Так, например, вернувшись к формуле сигма/квадратный корень из n, которая была введена для вычисления контрольных пределов X-карты, можно видеть, что неравные значения n приведут к получению различных контрольных пределов для разных объемов выборки. Существует три способа, позволяющих справиться с такой ситуацией. Средние объемы выборок.
Средние объемы выборок.
В том случае, когда желательно оставить контрольные пределы в виде прямых линий (например, чтобы облегчить чтение карты и ее использование в презентациях), можно найти среднее значение объема выборки n по всем рассматриваемым выборкам и установить контрольные пределы на основе полученного среднего объема выборки. Эту процедуру нельзя назвать "точной". И все же, пока объемы выборок несильно отличаются друг от друга, применение данного метода можно считать вполне адекватным.
Переменные контрольные пределы.
Переменные контрольные пределы.
С другой стороны, для каждой выборки можно отдельно определить контрольные пределы на основе ее объема. При таком подходе будут получены переменные контрольные пределы. На графике такие пределы будут изображены ступенчатой линией. Этот метод позволяет получить точные контрольные пределы для каждой из использующихся выборок. Однако при этом теряется простота и наглядность контрольных пределов, отмечаемых на карте прямой линией.
Стабилизированная (нормализованная) карта.
Стабилизированная (нормализованная) карта.
Наилучший вариант - изображающиеся прямыми линиями контрольные пределы, которые при этом точны - может быть получен путем стандартизации контролируемой численной характеристики (среднего значения, доли и т.д.) согласно единицам сигмы. При этом контрольные пределы изображаются прямыми линиями, но расположение точек выборочных значений на графике определяется не только значениями контролируемой характеристики, но и объемом n соответствующих выборок. Недостаток данного метода заключается в следующем: по вертикальной оси контрольной карты (оси Y) величины выражаются в единицах сигма, а не в первоначальных единицах измерения контролируемой характеристики, поэтому их нельзя считывать по выводимому на графике значению. Так, например, выборочная величина со значением 3 отстоит на 3 сигма от плановой спецификации. Для перевода данного значения в первоначальные единицы измерения придется выполнить некоторый объем вычислений.
| В начало |
Контрольные карты для непрерывных переменных и контрольные карты по альтернативному признаку
Контрольные карты для непрерывных переменных и контрольные карты по альтернативному признаку
Иногда инженеру, занимающемуся контролем качества, приходится выбирать между применением контрольной карты для непрерывных переменных и контрольной карты по альтернативному признаку. Преимущества контрольных карт по альтернативному признаку.
Преимущества контрольных карт по альтернативному признаку.
Преимущество контрольных карт по альтернативному признаку состоит в возможности быстро получить общее представление о различных аспектах качества анализируемого изделия; то есть, на основании различных критериев качества инженер может сразу принять или забраковать продукцию. Далее, контрольные карты по альтернативному признаку иногда позволяют обойтись без применения дорогих точных приборов и требующих значительных затрат времени измерительных процедур. Кроме того, этот тип контрольных карт более понятен менеджерам, которые не разбираются в тонкостях методов контроля качества.
Таким образом, с помощью таких карт можно более убедительно продемонстрировать руководству наличие проблем с качеством изделий.
Преимущества контрольных карт для непрерывных переменных.
Преимущества контрольных карт для непрерывных переменных.
Контрольные карты для непрерывных переменных обладают большей чувствительностью, чем контрольные карты по альтернативному признаку (см. Montgomery, 1985, стр. 203). Благодаря этому, контрольные карты для непрерывных переменных могут указать на существование проблемы ухудшения качества, прежде чем в потоке продукции появятся настоящие бракованные изделия, выделяемые с помощью контрольной карты по альтернативному признаку. В работе Montgomery (1985) автор называет контрольные карты для непрерывных переменных основными индикаторами ухудшения качества, которые предупреждают об этих проблемах задолго до того, как в процессе производства резко возрастет доля бракованных изделий.
Контрольные карты для отдельных наблюдений
Контрольные карты для отдельных наблюдений
Кроме выборок, состоящих из нескольких наблюдений, контрольные карты для переменных могут быть построены также для отдельных наблюдений, полученных в ходе производственного процесса. Иногда такой подход необходим в силу дороговизны, неудобства или невозможности анализа выборок, состоящих из ряда наблюдений. Примером может служить ситуация, когда число претензий потребителей или случаев возврата изделий может быть получено только по итогам месяца, тем не менее, существует необходимость в проведении текущего анализа этих данных для выявления ухудшения качества продукции. Другим широко встречающимся примером применения карт данного типа является проверка автоматическим тестирующим прибором каждой единицы произведенной продукции. В этом случае обычно стремятся обнаружить небольшие отклонения качества выпускаемой продукции (например, постепенное ухудшение качества, обусловленное износом оборудования). При этом наилучшее применения находят контрольные карты типа CUSUM, MA, и EWMA (контрольные карты для накопленных сумм и взвешенных средних).
| В начало |
Разладка процесса: критерии серий
Разладка процесса: критерии серий
Как уже было отмечено ранее в вводной части, когда точка на контрольной карте, соответствующая выборочному значению контролируемой характеристики (например, среднему значению в X-карте) оказывается вне ограниченной контрольными переделами области, это дает основания предполагать, что производственный процесс разладился. Далее, при этом необходимо отслеживать появление систематической тенденции в расположении точек (например, выборочных средних) на контрольной карте, так как наличие такой тенденции может служить свидетельством тренда среднего значения контролируемого процесса. Эти критерии иногда называют критериями серий типа AT&T (см. AT&T, 1959) или критериями против альтернатив специального вида (см. Nelson, 1984, 1985; Grant and Leavenworth, 1980; Shirland, 1993). Термин специальные альтернативы, как альтернатива случайным или общим причинам, был использован в работе Шуэрта (Shewhart) для того, чтобы сделать разграничение между нормальным производственным процессом, вариации в котором появляются только в силу действия случайных причин, и вышедшим из-под контроля процессом , в котором вариации характеристик обусловлены некоторыми неслучайными, то есть специальными факторами (см. Montgomery, 1991, стр. 102). Как и обсуждавшиеся ранее контрольные пределы, выраженные в единицах сигмы, критерии серий имеют в своей основе "статистическое" обоснование. Так, например, вероятность того, что любое выборочное среднее значение для X-карты окажется выше центральной линии, равна 0.5 при следующих условиях: (1) производственный процесс находится в нормальном состоянии (т.е. центральная линия проведена через значение, равное среднему контролируемой характеристики генеральной совокупности изделий), (2) средние значения следующих друг за другом выборок независимы (т.е. отсутствует автокорреляция) и (3) выборочные средние значения контролируемой характеристики распределены по нормальному закону. Проще говоря, при таких условиях для выборочного среднего значения шансы попасть выше или ниже центральной линии составляют 50 на 50.
Поэтому вероятность того, что два следующих друг за другом выборочных средних окажутся выше центральной линии, будет равна 0.5, умноженному на 0.5 , т.е. 0.25.
Соответственно, вероятность того, что выборочные средние девяти последующих выборок (или серия из 9 точек контрольной карты) окажется с одной стороны от центральной линии, составит 0.59 = .00195. Заметим, что это значение приблизительно равно вероятности того, что отдельное выборочное среднее значение не попадет в интервал, ограниченный контрольными пределами в 3 сигма (при условии нормального распределения выборочных средних и нормальности производственного процесса). Поэтому, в качестве еще одного индикатора разладки производственного процесса можно рассматривать ситуацию, когда девять последовательных выборочных средних находятся с одной стороны от центральной линии. Со статистической интерпретацией других, более сложных критериев можно ознакомиться в работе Duncan (1974).
Зоны A, B, C.
Зоны A, B, C.
Обычно для задания критериев поиска серий область контрольной карты над центральной линией и под ней делится на три "зоны".
По умолчанию, зона А определяется как область, расположенная на расстоянии от 2 до 3 сигма по обе стороны от центральной линии. Зона В определяется как область, отстоящая от центральной линии на расстояние от 1 до 2 сигма, а зона С - как область, расположенная между центральной линией по обе ее стороны и ограниченная прямой, проведенной на расстоянии одной сигма от центральной линии.
точек в зоне С или за ее пределами (с одной стороны от центральной линии).
9 точек в зоне С или за ее пределами (с одной стороны от центральной линии).
Если этот критерий выполняется (т.е. если на контрольной карте обнаружено такое расположение точек), то делается вывод о возможном изменении среднего значения процесса в целом. Заметим, что здесь делается предположение о симметричности распределения исследуемых характеристик качества вокруг среднего значения процесса на графике. Но это условие не выполняется, например, для R-карт, S-карт и большинства карт по альтернативному признаку.
Тем не менее, данный критерий полезен для того, чтобы указать занимающемуся контролем качества инженеру на присутствие потенциальных трендов процесса. Например, здесь стоит обратить внимание на последовательные выборочные значения с изменчивостью ниже среднего, так как с их помощью можно догадаться, каким образом снизить вариацию процесса.
точек монотонного роста или снижения, расположенные подряд
6 точек монотонного роста или снижения, расположенные подряд
. Выполнение этого критерия сигнализирует о сдвиге среднего значения процесса. Часто такой сдвиг обусловлен изнашиванием инструмента, ухудшением технического обслуживания оборудования, повышением квалификации рабочего и т.п. (Nelson, 1985).
точек подряд в "шахматном" порядке (через одну над и под центральной линией).
14 точек подряд в "шахматном" порядке (через одну над и под центральной линией).
Если этот критерий выполняется, то это указывает на действие двух систематически изменяющихся причин, которое приводит к получению различных результатов. Например, в данном случае может иметь место использование двух альтернативных поставщиков продукции или отслеживание двух различных альтернативных воздействий.
из 3-х расположенных подряд точек попадают в зону A или выходят за ее пределы.
2 из 3-х расположенных подряд точек попадают в зону A или выходят за ее пределы.
Этот критерий служит "ранним предупреждением" о начинающейся разладке процесса. Заметим, что для данного критерия вероятность получения ошибочного решения (критерий выполняется, однако процесс находится в нормальном режиме) в случае Х-карт составляет приблизительно 2 %.
из 5-ти расположенных подряд точек попадают в зону B или за ее пределы.
4 из 5-ти расположенных подряд точек попадают в зону B или за ее пределы.
Как и предыдущий, этот критерий может рассматриваться в качестве индикатора - "раннего предупреждения" о возможной разладке процесса. Процент принятия ошибочного решения о наличии разладки процесса для этого критерия также находится на уровне около 2%.
точек подряд попадают в зону C ( по обе стороны от центральной линии).
15 точек подряд попадают в зону C (по обе стороны от центральной линии).
Выполнение этого критерия указывает на более низкую изменчивость по сравнению с ожидаемой (на основании выбранных контрольных пределов).
точек подряд попадают в зоны B, A или выходят за контрольные пределы, по обе стороны от центральной линии (без попадания в зону C).
8 точек подряд попадают в зоны B, A или выходят за контрольные пределы, по обе стороны от центральной линии (без попадания в зону C).
Выполнение этого критерия служит свидетельством того, что различные выборки подвержены влиянию различных факторов, в результате чего выборочные средние значения оказываются распределенными по бимодальному закону. Такая ситуация может сложиться, например, когда отмечаемые на Х-карте выборки изделий были произведены двумя различными станками, один из которых производит изделия со значением контролируемой характеристики выше среднего, а другой - ниже.
| В начало |
Операционные характеристики (ОХ - кривые)
Операционные характеристики (ОХ - кривые)
Стандартные карты контроля качества обычно дополняются графиком, который носит название операционная характеристика (ОХ-кривая). При использовании стандартных контрольных карт для непрерывных переменных или для дискретных переменных возникает вопрос: насколько чувствительна используемая процедура контроля качества? Точнее говоря, какова вероятность не обнаружить выборочную точку анализируемой характеристики (например, среднего значения на Х-карте) вне контрольных пределов (т.е. посчитать процесс производства текущим "в нормальном режиме"), когда, на самом деле, произошел сдвиг процесса на некоторую величину? Обычно эту вероятность называют вероятностью бета-ошибки (

Кривые операционных характеристик оказываются исключительно полезным средством при оценивании мощности применяемой процедуры контроля качества. На практике решение об установлении объема контрольных выборок должно опираться не только на стоимость выполнения контрольной операции (т.е. на расходы в расчете на одно включенное в выборку изделие), но также на затраты, которые повлечет за собой не обнаруженное ухудшение качества. С помощью ОХ-кривых инженер может оценить вероятности необнаружения отклонений качества контролируемой продукции на определенную величину.
Индексы пригодности процесса
Индексы пригодности процесса
В случае контрольных карт для непрерывных переменных часто возникает необходимость включить в итоговый вывод результатов анализа так называемые индексы пригодности процесса. Коротко говоря, индексы пригодности процесса выражают (в виде отношения), какая часть деталей или изделий, производимых в рамках текущего производственного процесса, по своим характеристикам попадает в определенные технологами пределы (в частности, в инженерные допуски). К примеру, так называемый индекс Cp находится следующим образом:
Cp = (ВГС-НГС)/(6*сигма)
где сигма представляет собой оценку стандартного отклонения процесса, ВГС и НГС - соответственно верхнюю и нижнюю границы плановой спецификации (инженерные допуски). Если распределение контролируемой характеристики качества или переменной (например, размер поршневых колец) подчиняется нормальному закону, и процесс абсолютно точно центрирован (т.е. среднее значение процесса соответствует положению центральной линии на контрольной карте), то данный индекс может интерпретироваться как та часть стандартной кривой нормального распределения (ширина процесса), которая находится внутри границ инженерных допусков. В случае нецентрированного процесса, вместо рассмотренного выше индекса используется уточненный индекс Cpk . Для "пригодного" процесса индекс Cp должен быть больше 1. Это означает, что для того, чтобы можно было ожидать попадание более 99% всех выпущенных деталей или изделий в рамки приемлемых инженерных спецификаций, величина интервала между контрольными пределами плановых спецификаций должна превышать 6 сигма.
Более подробно обсуждение этого и других индексов приводится в модуле Анализ процессов.
| В начало |
Другие специализированные типы контрольных карт
Другие специализированные типы контрольных карт
Далее рассматривается ряд других наиболее широко используемых методов и соответствующих им типов контрольных карт - "рабочих лошадок" контроля качества. Однако, с приходом недорогих персональных компьютеров, все большую популярность приобретают процедуры, требующие проведения большего объема вычислений. X-карты для данных с негауссовским распределением.
X-карты для данных с негауссовским распределением.
Контрольные пределы для стандартных X-карт вычисляются, исходя из предположения о приблизительно нормальном распределении выборочных средних. Следовательно, для отдельных наблюдений в выборках нормальность распределения не обязательна, так как. по мере увеличения объема выборок распределение выборочных средних будет приближаться к нормальному (см. обсуждение центральной предельной теоремы в разделе Элементарные понятия статистики. Однако необходимо отметить, что при построении R-карты, S-карты и S**2-карты предполагается, что отдельные наблюдения обладают нормальным распределением). В монографии Шуарта (Shewhart, 1931) автор экспериментирует с различными негауссовскими распределениями отдельных наблюдений и оценивает полученные в результате распределения средних для выборок объема 4. В результате было обнаружено, что, на самом деле, до тех пор, пока распределение отдельных наблюдений в выборках является приблизительно нормальным, можно применять вычисленные на основе нормального распределения стандартные контрольные пределы. Введение в данный вопрос и обсуждение предположений о распределении данных при контроле качества путем построения контрольных карт можно найти в работе Hoyer and Ellis, 1996.
Однако, как отмечено в работе Ryan (1989), при малых объемах выборок и сильной асимметрии распределения наблюдений, построенные по таким данным стандартные контрольные пределы приводят как к получению большого числа ложных сигналов тревоги (т.е.
росту вероятности альфа-ошибки), так и увеличению числа случаев, когда при фактически произошедшей разладке процесс продолжает считаться контролируемым (росту вероятности бета-ошибки). В программе STATISTICA существует возможность расчета контрольных пределов для X-карт (а также индексов пригодности процесса) на основе так называемых кривых Джонсона (Johnson, 1949), с помощью которых аппроксимируется асимметрия и эксцесс большой группы негауссовских распределений (см. также раздел Подгонка распределений в модуле Анализ процессов). Негауссовские X-карты рекомендуется применять в том случае, когда распределение выборочных средних обладает явной асимметрией или является негауссовским.
Контрольная карта T**2 Хотеллинга.
Контрольная карта T**2 Хотеллинга.
Когда исследуется несколько взаимосвязанных характеристик качества (заданных в виде нескольких переменных), для всех средних значений можно построить общий график, воспользовавшись для этого многомерной статистикой Хотеллинга T**2 (впервые предложена в работе Hotelling, 1947).

Контрольная карта накопленных сумм (CUSUM-карта).
Контрольная карта накопленных сумм (CUSUM-карта).
Контрольная карта типа CUSUM была впервые предложена в работе Page (1954). Обсуждение использующихся при ее построении математических принципов можно найти в работах Ewan (1963), Johnson (1961), а также Johnson and Leone (1962).

Если строить график накопленной суммы отклонений от плановых спецификаций для следующих друг за другом выборочных средних, то даже малые постоянные сдвиги среднего значения процесса постепенно приведут к накоплению ощутимой суммы отклонений. Поэтому данный тип контрольных карт особенно хорошо подходит для обнаружения малых постоянных сдвигов процесса, которые могут оказаться незамеченными при применении Х-карты. Например, когда из-за износа оборудования процесс медленно "выскальзывает" из-под контроля, в результате чего размеры изделий превышают плановые спецификации (или становятся ниже их), при применении контрольной карты данного типа будет получен монотонно растущий (или снижающийся) график накопленной суммы отклонений от плановых спецификаций.
Для установления контрольных пределов в CUSUM-картах в работе Barnhard (1959) было предложено использовать так называемую V-маску, которая наносится на график после построения точки для последней выборки (самой правой точки на графике). Можно считать, что V-маска представляет собой верхний и нижний контрольный пределы для накопленных сумм. Однако, вместо того, чтобы быть параллельными центральной линии, эти прямые сходятся под определенным углом вправо, образуя в результате фигуру, похожую на лежащую букву V. Если график накопленной суммы пересекает любую из линий маски, то процесс считается вышедшим из-под контроля.
Контрольная карта скользящего среднего (MA-карта).
Контрольная карта скользящего среднего (MA-карта).
Возвращаясь к примеру с размером поршневых колец, предположим, что наибольший интерес для инженера по контролю качества представляет обнаружение малых трендов последовательных выборочных средних. Например, необходимо обнаружить износ оборудования, который приводит к медленному, но постоянному ухудшению качества (т.е. отклонению размеров изделий от требований плановой спецификации. Одним из способов отслеживания таких трендов и обнаружения незначительных постоянных сдвигов среднего значения процесса является построение описанной выше CUSUM-карты. Другой способ состоит в использовании одной из схем установления весов данных, согласно которой осуществляется суммирование нескольких средних. При движении такого взвешенного среднего вдоль выборочных точек получается контрольная карта скользящего среднего, приведення на следующем рисунке.
Контрольная карта экспоненциально взвешенного скользящего среднего (EWMA-карта).
Контрольная карта экспоненциально взвешенного скользящего среднего (EWMA-карта).
Идея построения скользящих средних для последовательных (соседних) выборочных значений может быть обобщена. В принципе, чтобы обнаружить тренд, необходимо присвоить веса следующим друг за другом выборочным значениям, получив таким образом скользящее среднее.
Однако, вместо простого арифметического скользящего среднего, можно найти геометрическое скользящее среднее (соответствующая контрольная карта показана на следующем рисунке и называется картой геометрического скользящего среднего, см. работу Montgomery,1985, 1991).
В частности, можно рассчитать значения для каждой точки графика по следующей формуле:
zt =

В данной формуле значение каждой точки zt рассчитывается как произведение
Регрессионные контрольные карты.
Регрессионные контрольные карты.
Иногда может понадобиться обнаружить взаимосвязь между двумя различными параметрами производственного процесса. Например, руководство почтовой организации может захотеть узнать, сколько человеко-часов тратится на обработку некоторого объема корреспонденции. Эти две анализируемые переменные должны быть приблизительно линейно связаны друг с другом. Тогда эту взаимосвязь можно описать с помощью широко известного коэффициента корреляции Пирсона r. Описание свойств этой статистки можно найти в разделе Основные статистики. На регрессионной контрольной карте строится линия регрессии, которая выражает линейную взаимосвязь между двумя рассматриваемыми переменными. На карту также наносятся точки данных для всех наблюдений.
Вокруг линии регрессии строится доверительный интервал, в который должна попадать определенная доля выборки (например, 95%). Присутствие выбросов на этом графике будет свидетельствовать о том, что для некоторых выборок не соблюдается общая тенденция взаимосвязи, которая характерна для рассматриваемых переменных.
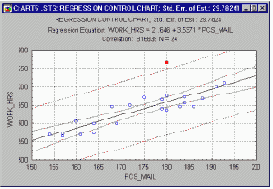
Применения.
Применения.
Для регрессионных контрольных карт существует множество областей применения. Так, например, профессиональные аудиторы могут с помощью карт данного типа обнаружить, у каких розничных торговцев число наличных трансакций превышает ожидаемое для данного уровня общего объема продаж или выделить те бакалейные магазины, в которых для существующего уровня продаж число погашенных купонов, дающих покупателю право на премию из ассортимента магазина при накоплении определенного числа купонов, превышает ожидаемое. В обоих случаях выбросы на регрессионных контрольных картах (т.е. слишком большое число наличных платежей, слишком большой объем погашенных купонов) могут привлечь к себе внимание и служить основанием для более тщательной проверки.
Контрольные карты Парето.
Контрольные карты Парето.
На практике оказывается, что равномерное распределение нарушения качества на различных стадиях производственного процесса или на различных предприятиях, выпускающих продукт, встречается довольно редко. Скорее, причиной большинства проблем является наличие лишь нескольких "паршивых овец в стаде". Данный принцип стал широко известен под названием принципа Парето и утверждает, что потери качества столь "плохо" распределены, что малое число возможных причин его ухудшения отвечает за большинство возникающих проблем. К примеру, вполне возможно, что в основном загрязнение воздуха возникает из-за относительно небольшого числа "грязных" автомобилей. Или, в большинстве компаний основное число убытков является следствием неудачи с одним или двумя выпускаемыми продуктами. Для выявления "паршивых овец в стаде" строят контрольные карты Парето.
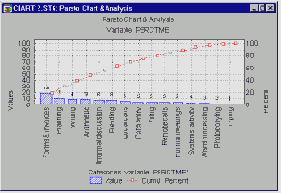
Они представляют собой гистограммы, на которых показано распределение потерь от ухудшения качества (например, в долларах) по некоторым категориям. Обычно категории - причины потери качества - приводятся в нисходящем порядке значимости (по частоте возникновения, стоимости в долларах и т.д.). Очень часто карта Парето помогает определить, на что направить усилия по улучшению качества продукта.
| В начало |
(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.