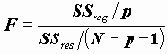МНОЖЕСТВЕННЫЕ СРАВНЕНИЯ
МНОЖЕСТВЕННЫЕ СРАВНЕНИЯ
Множественные сравнения являются одной из труднейших проблем в математической статистике. В действительности при анализе данных исследователи сталкиваются с ними на каждом шагу.
Пусть, например, мы рассматриваем 100 независимых таблиц сопряженности пар переменных, отбирая среди них "интересные" для анализа с использованием критических значений хи-квадрат 5%-го уровня значимости. Тогда при отсутствии связи переменных мы будем в среднем в таких испытаниях получать 5 "интересных" (значимых) таблиц, даже если связь между всеми переменными отсутствует. Таким образом, какие бы ни были плохие данные, мы что-либо будем интерпретировать. Но при повторном сборе данных - мы можем получить противоположные результаты. Вот что значит множественные сравнения!
Сравнение групповых средних это одна из немногих задач, где удалось справиться с этой проблемой.
Суть задачи состоит в отборе значимых различий множества пар групп, определяемых переменной группирования. Сравнение пары средних мы научились делать с помощью процедуры T-TEST и, казалось бы, можно, задавшись уровнем значимости, пропустить через этот тест все пары групп и отобрать различающиеся по за данному уровню. Однако, перебирая группы, мы перебираем множество случайных чисел, и, благодаря этому, можем наткнуться на значимое отличие с гораздо большей вероятностью, чем при рассмотрении одной пары групп. В частности, если группы независимы и не связаны с тестируемой переменной, при 10 сравнениях по уровню значимости 0.05 мы с вероятностью 1-(1-0.05)10=0.4 случайно получим хотя бы одно "значимое" различие.
Для пояснения механизма работы тестов множественных сравнений остановимся на 3-х из 20 тестах, реализованных в SPSS.
Согласно методу Бонферрони, в случае множественных сравнений назначается более строгий уровень значимости для попарных сравнений. Он определяется так: задается уровень значимости для множественных сравнений a m и в качестве попарного уровня значимости берется a =(1/k)a m., где k - число сравнений.
Пусть Ai - событие, состоящее в том, что мы в i- том сравнении выявили существенное отличие средних, когда средние совпадают, тогда, в соответствии с заданным уровнем значимости, P{Ai}<a . Ясно, что P{A1+A2+…+Ak}?P{A1}+P{A2}+…+P{Ak}<ka =a m, поэтому метод Бонферрони гарантирует нас от ошибки с вероятностью, не меньшей a m. В независимых сравнениях неравенство P{A1+A2+…+Ak}<ka , будет выполняться почти точно, так как 1-(1-a )k» ka . Критерий несколько жестче, чем необходимо, так как средние в группах связаны - их взвешенная сумма равна общему среднему.
Метод Шеффе построен на контрастах. С его помощью проверяется гипотеза равенства нулю сразу всех контрастов, не только тех, что сравнивают пары групп. В результате он часто оказывается еще строже, чем критерий Бонферрони.
Множественные сравнения в таблицах для неальтернативных вопросов. Программа Typology Tables
3.4. Множественные сравнения в таблицах для неальтернативных вопросов. Программа Typology Tables
Как уже было отмечено, в сложных табличных отчетах SPSS отсутствуют статистики значимости. Это касается также таблиц для неальтернативных вопросов. Этот пробел восполнила программа Typology Tables, разработанная в Институте экономики и ОПП СО РАН, г.Новосибирск.
В программе рассматриваются двумерные таблицы частотных распределений и таблицы средних по количественным переменным в группах по сочетаниям ответов на неальтернативные вопросы. Исследуется значимость отклонений частот от ожидаемых в условиях независимости ответов и отклонений средних от средних в итоговых ячейках. Эта программа может быть вставлена пунктом командой меню в SPSS версий 8, 9, 10.
Можно ли в регрессии использовать неколичественные переменные?
Можно ли в регрессии использовать неколичественные переменные?
Однозначно можно сказать, что они не могут быть использованы в качестве зависимой переменной Y. Это будет грубейшей ошибкой; в этом случае уравнением регрессии может быть предсказан, к примеру, пол имеющий код 1.5 или 0.5 при общепринятой кодировке пола 1-мужчины, 2-женщины. Может быть, это как-то интерпретируется с медицинской точки зрения, но в практике социальных исследований это будет едва ли возможно.
Для использования в качестве независимой переменной применяются индексные переменные (в англоязычной литературе dummy-variables).
Например, для семейного положения в данных Курильского обследования (женат, вдов, разведен, холост) стоит ввести три индикаторные переменные t1, t2 и t3 для выделения женатых, вдовых, и разведенных. Эти переменные будут равны, соответственно единице или нулю, в зависимости от того принадлежит или не принадлежит респондент к соответствующей группе по семейному положению.
Почему не 4 индексные переменные? Четвертая переменная определяется однозначно через первые три, поэтому, введение ее вызвало бы коллинеарность, не позволяющую найти коэффициенты регрессии.
Вот задание, которое позволяет изучить зависимость душевого дохода от возраста и семейного положения:
compute lnv14m =ln(v14/200).
compute t1=(v11=1).
compute t2=(v11=2).
compute t3=(v11=3).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2 t1 t2 t3 /SAVE PRED.
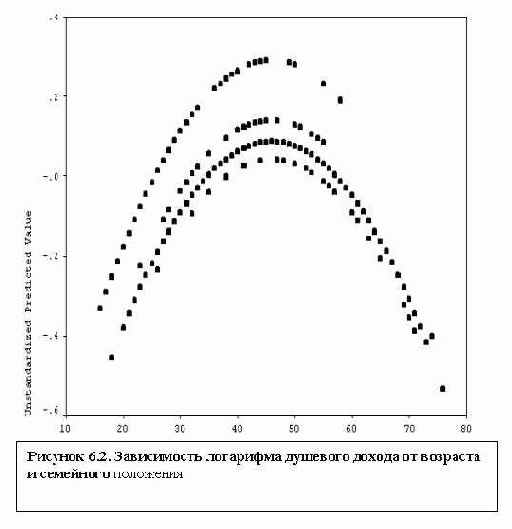
График связи возраста (V9) с предсказанным уравнением логарифмом доходов (переменная pre_2) получается командой
GRAPH /SCATTERPLOT(BIVAR)=v9 WITH pre_2 /MISSING=LISTWISE
Он представляет собой 4 параболы (рисунок 6.2). В соответствии с коэффициентами перед t1, t2 и t3 (см. таблицу 6.4), эти пораболы соответствуют, сверху вниз, холостякам, разведенным, женатым и вдовцам (порабола холостяков получается при t1=t2=t3=0).
Вероятно, полученное уравнение можно улучшить, исключив из уравнения переменные с незначимыми коэффициентами. Поскольку индексные переменные должны быть в определенной степени взаимосвязаны, уровень наблюдаемой значимости может определяться здесь коллинеарностью, поэтому "ревизию" переменных нужно проводить осторожно, чтобы существенно не ухудшить полученного уравнения.
Из-за взаимосвязи переменных здесь нет возможности говорить о том, какая переменная больше влияет на зависимую переменную. Обратите внимание на довольно редкий эффект: бета-коэффициенты для возраста и его квадрата по абсолютной величине больше 1!
Надежность и значимость коэффициента регрессии
Надежность и значимость коэффициента регрессии
Для изучения "механизма" действия мультиколлинеарности на регрессионные коэффициенты рассмотрим выражение для дисперсии отдельного регрессионного коэффициента
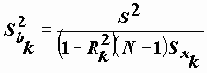
Здесь
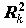
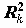
Величина 1-
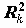
Дисперсия коэффициента позволяет получить статистику для проверки его значимости
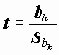
Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте Bk получить значение статистики, большее по абсолютной величине, чем выборочное.
Неальтернативные признаки
Еще более сложны данные по так называемым неальтернативным (многозначным) вопросам. Часто встречаются вопросы: "Какие варианты ответов, предлагаемых анкетой, Вам кажутся разумными?". В анкете на такой вопрос предлагается несколько ответов. В этих случаях признаки принято называть неальтернативными или многозначными. Неальтернативный признак можно кодировать одним из двух способов:
1. Для каждой подсказки заводится переменная, которая соответствует столбцу матрицы и кодируется с помощью 0 и 1. В частности, для ответов на четвертый вопрос анкеты примера 1 отводится 5 столбцов матрицы данных, они заполняются нулями и единицами (Рисунок 1). Нередко вместо кодов 0 и 1 используются другие коды, тогда в программах получения таблиц по неальтернативным вопросам нужно специально указывать код, соответствующей ответу "Да". Например, вопрос может быть задан следующим образом:
Согласны ли вы с тем, что
А. Нужна новая конституция?
1. Нет 2. Да 3. Не знаю
Б. Нужно переизбрать Думу?
1. Нет 2. Да 3. Не знаю
В. Нужен новый президент
1. Нет 2. Да 3. Не знаю
Г. . . . . . .
В этом случае дихотомия определяется кодом 2 и остальными кодами.
Такое представление неальтернативного признака в виде переменных, соответствующих подсказкам, называется дихотомическим. В ряде программ SPSS для обозначения этого представления данных используется текст Dichotomies counted value.
2. Кодирование порядковых номеров подсказок из текста анкеты, указанных респондентом (3 группа столбцов матрицы из примера 1.1. Рисунок 1.1). Это кодирование в виде списка. В этом случае количество столбцов матрицы, отведенных для ответов на вопрос, может быть меньше, чем количество подсказок в этом вопросе, оно зависит от числа возможных ответов. Например, для третьего вопроса анкеты из нашего примера достаточно отвести три столбца матрицы данных. Для обозначения этого способа кодирования используется ключевое слово Categories.
В приведенной выше анкете предлагается несколько вариантов ответов на третий и четвертый вопросы; ответы респондента на них кодируются в нескольких позициях строки матрицы данных.
Неколичественные данные
Неколичественные данные
Если в обычной линейной регрессии для работы с неколичественными переменными нам приходилось подготавливать специальные индикаторные переменные, то в реализации логистической регрессии в SPSS это делается автоматически. Для этого в диалоговом окне специально предусмотрены средства, сообщающие пакету, что ту или иную переменную следует считать категориальной. При этом, чтобы не получить линейно зависимых переменных, максимальный код ее значения (или минимальный, в зависимости от задания процедуры) не перекодируется в дихотомическую (индексную) переменную. Впрочем, средства преобразования данных позволяют не учитывать любой код значения. Имеются другие способы перекодирования категориальных (неколичественных) переменных в несколько переменных, но мы будем пользоваться только указанным, как наиболее естественным.
Неколичественные шкалы
НОМИНАЛЬНАЯ шкала является самым "низким" уровнем измерения. В этом случае используется только равенство или неравенство значений. Примером таких переменных являются "пол", "профессия".
ОРДИНАЛЬНАЯ или РАНГАВАЯ. Часто значения признака выражают степень проявления какого-либо свойства и могут быть упорядочены. Например, работа "интересна", "безразлична" или "не интересна". Такая шкала называется ранговой или ординальной.
О статистике Вальда
О статистике Вальда
Как отмечено в документации SPSS, недостаток статистики Вальда в том, что при малом числе наблюдений она может давать заниженные оценки наблюдаемой значимости коэффициентов. Для получения более точной информации о значимости переменных можно воспользоваться пошаговой регрессией, метод FORWARD LR (LR - likelihood ratio - отношение правдоподобия), тогда будет для каждой переменной выдана значимость включения/исключения, полученная на основе отношения функций правдоподобия модели. Поскольку основная выдача построена на основе статистики Вальда, первые выводы удобнее делать на ее основе, а потом уже уточнять результаты, если это необходимо.
Объединение файлов (merge files)
Объединение файлов (merge files)
В пакете реализована возможность объединять файлы. Его предпочтительно делать с помощью меню DATA/ MERGE.
Назначение: команда позволяет объединить данные различных файлов. Рассмотрим, какие виды объединения файлов возможны.
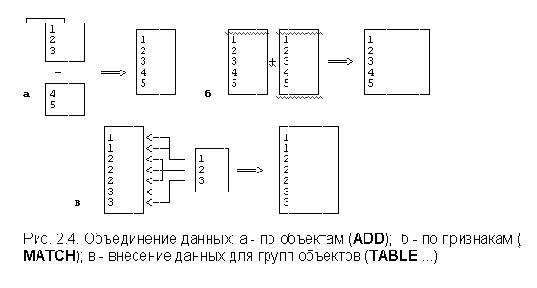
Во-первых, это дополнение массива данных новыми ОБЪЕКТАМИ (функция ADD). На практике такая операция необходима, если
происходит многоэтапное исследование по одной и той же анкете, опрос в нескольких регионах и т.п.; исследователю повезло - удалось получить информацию другого обследования (не панельного, то есть, опрошены другие люди), частично совместимую по переменным с имеющейся; но необходимо составить общий массив данных.Во-вторых, дополнение данных новыми ПЕРЕМЕННЫМИ (функция MATCH). Такое пополнение массива данных обычно необходимо, если
не удается сразу закодировать все данные; на подмножестве данных нужно произвести срочные расчеты, другую часть необходимо еще подготовить к вводу; - необходимо соединить данные панельных обследований; - дополнение данными из агрегированного файла (функция TABLE). Пусть, например, получены точные сведения о промышленности города, детской смертности, загрязнении атмосферы и т.д.. Эти данные необходимо внести в каждую анкету. Их можно закодировать, но экономичнее и быстрее сделать файл агрегированных данных и этой процедурой приписать к объектам-анкетам в исходный файл (см. Рисунок 2.4).Подробно о выполнении объединения файлов следует смотреть Руководство пользователя. Книга 1.
В качестве примера проведем присоединение данных агрегированного файла (см. пример из предыдущего раздела) к анкетным данным курильского обследования:
get file "D:oct.sav".
SORT CASES BY g (A) .
MATCH FILES /FILE=* /TABLE='D: Aggr.sav' /BY g.
EXECUTE.
Сортировка файлов данных по ключевой переменной здесь обязательна; если данные не отсортированы, есть риск их потерять.
После объединения, в данных D:oct.sps появятся переменные d1, d2, d3, d4, d5 и d6, a также w1, w2, w4, w8, w9, w10 и wr. Теперь можно изучать, как связано "общественное мнение" с индивидуальными характеристиками респондентов.
Заметим, что "ручное" написание команды в данном случае требует особой внимательности, так как диагностика ошибок в этой команде сделана здесь не на высоком уровне.
Оценка факторов
Оценка факторов
Математический аппарат, используемый в факторном анализе, в действительности позволяет не вычислять непосредственно главные оси. И факторные нагрузки до и после вращения факторов и общности вычисляются за счет операций с корреляционной матрицей. Поэтому оценка значений факторов для объектов является одной из проблем факторного анализа.
Факторы, имеющие свойства полученных с помощью метода главных компонент, определяются на основе регрессионного уравнения. Известно, что для оценки регрессионных коэффициентов для стандартизованных переменных достаточно знать корреляционную матрицу переменных. Корреляционная матрица по переменным Xi и Fk определяется, исходя из модели и имеющейся матрицы корреляций Xi. Исходя из нее, регрессионным методом находятся факторы в виде линейных комбинаций исходных переменных:
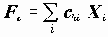
Оценка влияния независимой переменной
Оценка влияния независимой переменной
Если переменные X независимы между собой, то величина коэффициента bi интерпретируется как прирост y, если Xi увеличить на единицу.
Можно ли по абсолютной величине коэффициента судить о роли соответствующего ему фактора в формировании зависимой переменной? То есть, если b1>b2, будет ли X1 важнее X2?
Абсолютные значения коэффициентов не позволяют сделать такой вывод. Однако при небольшой взаимосвязи между переменными X, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию.
Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis)
5.3.2. Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis)
В основе сравнения средних рангов заданного числа групп лежит одномерный дисперсионный анализ, в котором вместо значений переменных используются ранги объектов исследуемой переменной.
NPAR TESTS K-W = V14 BY V4(1,3).
В условиях гипотезы равенства распределений в группах нормированный межгрупповой разброс имеет распределение, близкое к распределению хи-квадрат. В выдаче распечатывается значимость этой статистики.
Следующий пример показывает различие доходов жителей населенных пунктов разного типа.
npar test k-w=v9 by tp(1,4).
Одномерный дисперсионный анализ (ONEWAY)
Одномерный дисперсионный анализ (ONEWAY)
Данная процедура позволяет проводить одномерный дисперсионный анализ, ее преимущества перед командой Means в возможности исследования равенства дисперсий в группах, исследовании полиномиальных трендов, проведения множественных сравнений:
ONEWAY lnv14m BY w10 /STATISTICS HOMOGENEITY
/POSTHOC = BTUKEY SCHEFFE BONFERRONI ALPHA(.05).
Задается тестируемая переменная, служебное слово "BY", переменная группирования, список значений в скобках. Проверка однородности дисперсий задается подкомандой /STATISTICS HOMOGENEITY, множественные сравнения - подкомандой /POSTHOC = ….
Контрасты. Контрастом называется линейная комбинация средних в группах
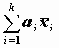
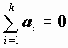
Одновыборочные тесты
5.1. Одновыборочные тесты
Эти тесты служат для проверки соответствия распределения выборки заданному.
Одновыборочный тест (One sample T-test).
Одновыборочный тест (One sample T-test).
Одновыборочный тест предназначен для проверки гипотезы о равенстве математического ожидания переменной заданной величине (в общепринятых обозначениях H0: m =m 0). Напомним, что для проверки этой гипотезы используется статистика
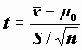
Команда для проверки гипотезы выдает также двусторонний доверительный интервал.
Примеры применения одновыборочного T-теста.
Пример 1. Для устранения влияния текущего уровня цен, инфляции на выводы об уровне жизни населения уровень доходов нормируют на средние значения или медиану. Целесообразно и нам использовать промедианный доход.
Почти одновременно с моментом сбора данных на аналогичной выборке очень большего объема была получена оценка медианы душевых доходов населения (200 руб.). Если допустить, что логарифм доходов имеет нормальное распределение, то среднее промедианных доходов должно незначимо отличаться от нуля (поскольку нормальное распределение симметрично относительно математического ожидания). Проверим это:
compute lnv14m=ln(v14/200).
Variable labels lnv14m "логарифм промедианного дохода".
T-TEST /TESTVAL=0 /VARIABLES=lnv14m /CRITERIA=CIN (.95) .
Основные функции и операторы команд COMPUTE и IF:
Основные функции и операторы команд COMPUTE и IF:
Арифметические операторы + , -, *, / в этих командах употребляются обычным порядком, две звездочки ** означают возведение в степень.
Результатом логической операции будет 1, если логическое выражение истинно и 0, если выражение ложно (логическое выражение (v9>30) равно 1, если v9>30, и равно 0, если v9<=30).
Допустимы операторы сравнения <, <=,<, <=, ~=, где последний оператор означает "не равно" и логические операторы ~ -отрицание (not), & - логическое "и" (and) и логическое "или" - | (or).
При вычислении логического выражения, если порядок выполнения не задан скобками, сначала выполняются арифметические операции, затем сравнения, затем логические операции. Приоритетность выполнения операций - естественна, как обычно определяется в математике и языках программирования, но следует заметить, что операции сравнения находятся на одном уровне. В частности значение выражения (5>3>2) ,будет равно 0 ("ложь"), так как в соответствии с порядком выполнения операций в этом выражении (5>3>2)=((5>3)>2)=(1>2)=0 !.
Наряду с арифметическими операторами в арифметических выражениях могут использоваться логические выражения, что позволяет достаточно компактно реализовывать преобразования данных:
Compute x=(v9>30)+v10>x+z.
Эта хитроумная команда превращает вначале выражение (v9>30) в 0 или 1 в зависимости от его истинности, затем производит вычисления левой ( (v9>30)+v10 ) и правой ( x+z )частей неравенства и в зависимости от результата сравнения присваивает переменной x значение 0 или 1.
Кроме того, имеется возможность использовать:
Арифметические функции, такие как ABS - абсолютное значение, RND - округление, TRUNC - целая часть, EXP - экспонента, LN натуральный логарифм и др. Например,
Compute LNv9=LN(V9).
Статистические функции: SUM сумма, MEAN - среднее, SD стандартное отклонение, VARIANCE - дисперсия, MIN -минимум и MAX - максимум.
Например, команда
Compute S=меаn(d1 to d10).
Вычисляет переменную, равную среднему валидных значений переменных d1,…,d10.
Функции распределения, например:
CDF.CHISQ(q,a) - распределения хи-квадрат, CDF.EXP(q,a) - экспоненциального распределения, CDF.T(q,a) - Стьюдента и др. (q - аргумент функции распределения, a - параметр соответствующего распределения). Команда
Compute y=CDF.T(x,10).
Вычисляет переменную Y, значения которой суть значения функции распределения Стьюдента с 10 степенями свободы от значений переменой x.
Если есть подозрение, что X имеет именно такое распределение, то переменная y должна иметь равномерное на отрезке (0,1) распределение. Благодаря этому можно проверить предположение о распределении X.
То же самое можно сказать о других видах распределений.
Обратные функции распределения, например,
IDF.CHISQ(p,a) - обратная функция распределения (по сути дела квантиль) хи-квадрат, IDF.F(p,a,b) - квантиль распределения Фишера, IDF.T(p,a) - квантиль распределения Стьюдента и др. (p - вероятность, a и b - параметры соответствующего распределения). Например,
Compute z= IDF.CHISQ(X,10).
Вычисляет квантиль порядка X распределения хи квадрат с 10 степенями свободы.
Такие функции полезны для вычисления значимости статистик в массовом порядке, например значимость отклонения среднего возраста по городам, в которых произведен сбор данных.
Датчики случайных чисел, например:
RV.LNORMAL(a,b) - датчик лог-нормального распределения. RV.NORMAL(a,b) - датчик нормального распределения, RV.UNIFORM(a,b) - датчик равномерного распределения (a, b - параметры соответствующего распределения).
Функция, дающая значения переменной на предыдущем объекте LAG. Пример использования (см. Рисунок 1.1, данные "Проблем и жалоб")
COMPUTE age1 = LAG(age) .
COMPUTE age2 = LAG(age,3) .
Execute.
Указанное преобразование дает сдвиг информации, показанный на Рисунок 2.1.
| N Анкеты | Пол SEX | Возраст (Age) | Возраст (Age1) | Возраст (Age2) |
| 1 | 1 | 20 | ||
| 2 | 1 | 25 | 20 | |
| 3 | 2 | 34 | 25 | |
| 4 | 1 | 18 | 34 | 20 |
| . | . | . |
Функция полезна для анализа временных рядов, при анализе анкетных данных - для поиска повторов объектов, других вспомогательных операций.
Логические функции:
RANGE(v,a1,b1,a2,b2,…) - 1, если значение V попало хотя бы в один из интервалов [a1,b1], [a2,b2],… .
ANY(v,a1,a2,…) - 1, если значение V совпало хотя бы с одним из значений a1, a2, … .
Кроме того, в пакете имеются строчные функции, функции обработки данных типа даты и времени.
Основные команды меню SPSS:
FILE
Обеспечивает доступ к файлам данных, к выходным файлам и программам преобразования данных. С файлами данных связываются окна. Если текущее окно соответствует данным наблюдений, то команда FILE обслуживает сохранение и замену данных. Если окно содержит файл синтаксиса (SYNTAX) или выдачи результатов счета (OUTPUT), то обеспечивается обработка файла синтаксиса или выдачи.
EDIT
Обеспечивает редактирование командных файлов, выходных файлов и файлов данных статистических наблюдений и др..
DATA
Обеспечивает операции над данными - сортировку, слияние различных файлов данных, агрегирование, организацию подвыборки из данных. Эта команда имеется только в меню окна редактора данных.
TRANSFORM
Обеспечивает преобразование данных. Эта команда также имеется только в меню окна редактора данных.
STATISTICS
Команда обеспечивает доступ и реализацию методов анализа данных; в 9-й версии SPSS она заменена на команду ANALISIS.
GRAPHS
Графическое представление данных.
UTILITIES
Обслуживающие программы.
WINDOOW
Обеспечивает переключение окон.
HELP
Содержит справочную информацию.
Кроме того, при работе с графиками и мобильными таблицами (PIVOT TABLES) появляются меню специального назначения.
Приведенные команды - далеко не полное описание меню, а лишь наиболее используемая его часть.
Как принято в современном интерфейсе программ, под МЕНЮ на верхней части окна в обычном режиме работы находится строка с панелью инструментов - ряд кнопок, с которыми связаны различные действия пакета. При движении курсора по этим кнопкам, на статусной строке внизу во внешней части экрана высвечивается сведения о назначении кнопки. Ниже см. дополнительную информацию о статусной строке.
Основные Команды описания данных
основные Команды описания данных
Команда VARIABLE LABELS назначает ПЕРЕМЕННЫМ метки (расширенные текстовые наименования), которые используются при оформлении листингов.
VARIABLE LABELS V8 'ПОЛ'
V9 'Возраст'.
Синтаксис: за именем переменной указывается в апострофах ее текстовое наименование - метка. Вы должны помечать каждую переменную отдельно. Максимальная длина метки 255 символов.
Команда VALUE LABELS назначает ЗНАЧЕНИЯМ переменных метки - наименования, которые используются при оформлении листингов
VALUE LABELS V1 1 "расчет на свои силы"
2 "пределы"
3 "помощь"/
V8 1 "МУЖЧИНА"
2 "ЖЕНЩИНА"/
x1 to x10 1 "да" 2 "нет" 3 "не знаю".
Синтаксис: за именем переменной или списком переменных и кодом значения в апострофах следует метка. Максимальная длина метки не больше 60 символа. Такое назначение меток может быть определено и для списка переменных. Назначения меток должны разделяться слэшами, в качестве образца используйте приведенный пример.
Команда ADD VALUE LABELS делает то же, что и команда VALUE LABELS, но если VALUE LABELS при повторном запуске замещает все ранее назначенные метки указанных в ней переменных, команда ADD VALUE LABELS назначает метки только указанным кодам.
Команда MISSING VALUES. Как было указано выше, на практике приходится обрабатывать информацию с пропущенными данными. При кодировании неопределенных данных (таких, как ответы "не знаю", отказа ответа) необходимо выбрать символы или цифры - коды отсутствующих значений, и сообщить пакету, что они соответствует пропущенным данным. Это делается командой MISSING VALUES, которая сохраняет в справочной информации файла данных объявленные пользователем коды для неопределенных значений переменной или списка переменных. В дальнейшем, в статистических процедурах и при преобразовании данных эти коды обрабатываются специальным образом. Возможно назначение до 3-х неопределенных кодов или интервал кодов и не более одного кода.
Примеры:
MISSING VALUES X Y Z(-1)/ R(9, 99, 999)/ S1 TO S20(999 thru 100000)/ SEX (9).
MISSING VALUES v2 (Lowest thru -1)/ v10 (-1, 900 THRU Highest).
В указанном выше примере -1 назначается кодом неопределенного значения для X, Y и Z; 9, 99, 999 - для R; от 999 до 100000 - коды неопределенности переменных от S1 до S20; 9 - для SEX; от минимального кода до -1 - для v2; -1 и коды от 900 до максимального - для v10.
Ключевое слово thru определяет интервал кодов; Lowest, Highest - минимальный и максимальный коды, соответственно. Возможны сокращения этих ключевых слов до 2-х букв (th, lo, hi).
В команде указывается список переменных (разделять символом "/" необязательно), у которых может встретиться неопределенное значение, и за которым в круглых скобках указан объявленный код. Объекты с такими значениями переменных при выполнении многих пакетных процедур просто исключаются из рассмотрения.
Неопределенные значения, описанные командой MISSING VALUES, называются пользовательскими неопределенными значениями. Однако и в процессе счета могут возникнуть ситуации, когда невозможно осуществить преобразование данных: деление на 0; корень из отрицательного числа; в вычисления попал код отсутствующего значения; при чтении данных нет совпадения типа (число, символ) данных и т.д. Пакет таким неопределенным значениям присваивает специальный системный код, который в данных изображается точкой. Системный код неопределенности в процедурах и командах обозначается ключевым словом SYSMIS.
Объявление пользовательских неопределенных значений можно отменить командой MISSING VALUES с пустыми скобками.
MISSING VALUES X Y Z() R()/ S1 TO S20()/ SEX().
Основные команды преобразования данных
основные команды преобразования данных
Для преобразования данных в меню окна редактора данных имеется пункт TRANSFORMATIONS, и заготовки команд можно получать, пользуясь этим пунктом.
Преобразования в анализе данных одна из самых трудоемких частей работы. Специалист, освоивший технику преобразования данных, имеет существенный шанс для получения содержательных результатов. На практике в большинстве случаев можно обойтись следующими командами:
COMPUTE - арифметические операции над переменными;
IF - условные арифметические операции над переменными;
RECODE - перекодирование переменных;
COUNT - подсчет числа заданных кодов в списке переменных.
Основные правила написания команд на языке пакета
Основные правила написания команд на языке пакета
Команды, имена переменных, ключевые слова могут вводиться большими или маленькими буквами. Список последовательно расположенных в активном файле переменных можно задавать в тексте команды, пользуясь сокращением:
<первая переменная TO последняя переменная> Ключевые слова могут усекаться до первых трех символов В метках переменных и значений учитывается регистр буквы Команды могут начинаться с любой позиции и должны кончаться символом конца команды (точкой). Продолжение команды начинается с любой позиции строки. Подкоманды разделяются слэшами (/). Имена файлов заключаются в апострофы или в кавычки. Символ "*" в начале строки означает, что на данной строке расположен комментарий, комментарий также должен заканчиваться точкой.
Редактирование программ осуществляется по правилам, схожим с правилами, принятыми в распространенных редакторах системы WINDOWS.
Набрав программу, ее можно запустить полностью или частично (выделив блок), нажав кнопку
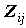
Среди инструментов в окне редактирования файла SYNTAX имеется кнопка для вызова подсказки
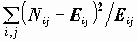
Среди команд SPSS можно выделить три основных типа команд - команды описания данных, команды преобразования данных и статистические процедуры.
Команды описания данных устанавливают метки, неопределенные значения, типы переменных, форматы выдачи и др.
Команды преобразования данных предназначены для вычисления новых переменных и модификации имеющихся. Запуск этих команд не вызывает непосредственного преобразования данных, само преобразование происходит после запуска команды EXECUTE. Такая организация расчетов необходима для уменьшения числа обращений к данным на магнитном носителе.
Статистические процедуры предназначены для получения статистик, оценки параметров моделей, получения графиков и др.
Деление это условно. Например, статистические программы также могут вычислять новые переменные, а команды агрегирования данных, как мы увидим ниже, вычисляют статистики для групп объектов. Кроме того, имеются команды управления данными, манипуляции файлами и другие команды, не вписывающиеся в эти три группы команд.
Отбор подмножеств наблюдений
Отбор подмножеств наблюдений
Для выбора подмножества наблюдений необходимо использовать команду из главного меню:
DATA
SELECT CASES
после выполнения этих команд появляется окно диалога с вариантами организации отбора данных по условию.
Невыбранные объекты могут быть исключены из сеанса работы или временно отфильтрованы. Имеется возможность организовать случайную выборку, например, выбрать 10% данных.
Если необходимость во временной выборке отпала, нужно снова обратиться к этому же пункту меню и в диалоге указать ,что необходимы все объекты (ALL CASES).
Добавление команд временного отбора данных в файл синтаксиса с использованием диалогового окна (Paste) приводит к появлению в программе целой серии команд, такой как
USE ALL.
COMPUTE filter_$=(v8 = 1).
VARIABLE LABEL filter_$ 'v8 = 1 (FILTER)'.
VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'.
FORMAT filter_$ (f1.0).
FILTER BY filter_$.
EXECUTE .
Как видно из сгенерированного SPSS текста, в случае использования условия для временной подвыборки объектов, программа выборки создает переменную фильтра (filter_$) и использует команду FILTER BY filter_$.
Можно не использовать диалога, а для временной выборки объектов сформировать программу, создающую переменную фильтра, в частности для выборки мужчин в нашем учебном массиве можно воспользоваться командой
FILTER BY V8.
Для отмены фильтра необходимо запустить команду
FILTER OFF.
Для сохранения массива данных только отобранных объектов в команде SAVE нужно использовать подкоманду /UNSELECTED DELETE:
SAVE FILE='D:\mydir\city' /KEEP=x1 to x10, x15
/UNSELECTED DELETE/COMPRESSED.
Если необходимо исключить наблюдения из массива, диалог даст последовательность команд такого типа
USE ALL.
SELECT IF(v8 = 1).
EXECUTE .
Можно обойтись и одной командой SELECT IF(v8 = 1).
Обратим еще раз внимание на то, что в результате применения команды SELECT IF не выбранные объекты теряются полностью.
Отношение шансов и логит
Отношение шансов и логит
Отношение вероятности того, что событие произойдет к вероятности того, что оно не произойдет P/(1-P) называется отношением шансов.
С этим отношением связано еще одно представление логистической регрессии, получаемое за счет непосредственного задания зависимой переменной в виде Z=Ln(P/(1-P)), где P=P{Y=1|X1,…,Xp}. Переменная Z называется логитом.По сути дела, логистическая регрессия определяется уравнением регрессии Z=B0+B1X1+…+BpXp.
В связи с этим отношение шансов может быть записано в следующем виде
P/(1-P)=
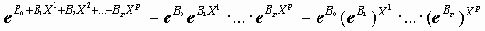
Отсюда получается, что, если модель верна, при независимых X1,…,Xp изменение Xk на единицу вызывает изменение отношения шансов в
Парные корреляции
Парные корреляции
Команда Bivariate… меню производит вычисление таблицы коэффициентов Пирсона, характеризующего степень линейной связи, а также коэффициентов ранговой корреляции BTAU и Спирмена (Spearman). В синтаксисе эта команда имеет вид:
CORRELATIONS /VARIABLES=v9 lnv14m /PRINT=TWOTAIL NOSIG.
для обычного коэффициента корреляции и
NONPAR CORR /VARIABLES=v10 v9 v14 /PRINT=SPEARMAN.
или
NONPAR CORR /VARIABLES=v10 WITH v9 v14 /PRINT=KENDALL.
для ранговых корреляций
Подкоманда /VARIABLES в этих командах указывает список переменных или два списка переменных, разделенных словом WITH. Если указывается один список переменных, то рассчитываются коэффициенты корреляции каждой переменной с каждой переменной (квадратная таблица). Если указываются два списка, разделенные служебным словом WITH, то рассчитываются коэффициенты корреляции всех переменных, расположенных слева от WITH, с переменными, расположенными справа (прямоугольная таблица). Ключевое слово WITH можно использовать только в окне синтаксиса.
Процедура CORRELATIONS выводит: r - коэффициент корреляции Пирсона; число наблюдений (объектов) в скобках и значимость коэффициента корреляции. Коэффициент корреляции Пирсона:
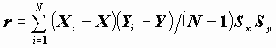
Коэффициент корреляции может принимать значения от -1 до +1. При этом значимый отрицательный коэффициент корреляции позволяет принять гипотезу о наличии линейной отрицательной связи. Метод, используемый для проверки гипотезы, предполагает, также, двумерную нормальность распределения (X,Y). На практике это соответствует тому, что увеличению значения одной переменной в большинстве случаев соответствует уменьшение значения коррелируещей с ней переменной. Значимый положительный коэффициент корреляции свидетельствует о положительной связи переменных: увеличению одной переменной соответствует увеличение другой. Чем ближе абсолютное значение r к единице, тем более линейный характер носит зависимость исследуемых переменных; близость к 0 означает отсутствие линейной связи.
Насколько полученное значение коэффициента корреляции не случайно, определяется по величине значимости (Sig. (2-tailed)) - вероятности получить большее, чем выборочное значение коэффициента корреляции.
Для оценки значимости коэффициента Пирсона используется критерий t=r*(N-2)/(1-r2)0.5, который в условиях нормальности и независимости переменных имеет распределение Стьюдента. Таким образом, наряду с формулировкой нулевой гипотезы здесь формулируется предположение о двумерной нормальности - довольно жесткое условие.
Для оценки значимости коэффициентов Спирмена и Кендалла используется нормальная аппроксимация этих коэфициентов. По-сути коэффициент ранговой корреляции является коэффициентом корреляции между переменными, преобразованными в ранги (или процентили), поэтому для исследования значимости с помощью этих коэффициентов не требуется делать предположения о распределении данных. Пример выдачи коэффициентов Спирмена представлен в табл.4.15. Не обнаруживается значимой связи возраста и образования (что вполне естественно), но среднемесячный душевой доход связан с образованием (это мы уже показывали).
Переменные, порождаемые регрессионным уравнением
Переменные, порождаемые регрессионным уравнением
Сохранение переменных, порождаемых регрессией, производится подкомандой SAVE.
Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной
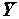
Поскольку коэффициенты регрессии - случайные величины, линия регрессии также случайна. Поэтому прогнозные значения случайны и имеют некоторое стандартное отклонение
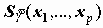
Кроме того, с учетом дисперсии остатка могут быть вычислены доверительные границы значений Y (не средних, а индивидуальных!).
Для каждого объекта может быть вычислен остаток ei=
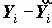
Для изучения отклонений от модели удобно использовать стандартизованный остаток - деленный на стандартную ошибку регрессии.
Случайность оценки прогнозных значений Y вносит дополнительную дисперсию в регрессионный остаток, из-за этого дисперсия остатка зависит от значений независимых переменных (
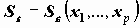
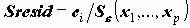
Таким образом, мы можем получить: оценку (прогнозную) значений зависимой переменной Unstandardized predicted value), ее стандартное отклонение (S.E. of mean predictions), доверительные интервалы для среднего Y(X) и для Y(X) (Prediction intervals - Mean, Individual).
Это далеко не полный перечень переменных, порождаемых SPSS.
Порядок выполнения команд
При выполнении команд необходимо, чтобы для них были определены данные. Например, если заранее не вычислена переменная x, нельзя запустить команды
Compute y=x+1.
Descriptive var=y.
Команда compute не может вычислить переменную y, так как отсутствует переменная x, поэтому команда Descriptive не будет выполнена, так как отсутствует y.
Пошаговая процедура построения модели
Пошаговая процедура построения модели
Основным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. В SPSS очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными.
По умолчанию программа включает все заданные переменные (метод ENTER).
Метод включения и исключения переменных (STEPWISE) состоит в следующем.
Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один xk, который более всего связан корреляционной зависимостью с y. Для этого рассчитываются частные коэффициенты корреляции остальных переменных с y при xk, включенном в регрессию, и выбирается следующая переменная с наибольшим частным коэффициентом корреляции. Это равносильно следующему: вычислить регрессионный остаток переменной y; вычислить регрессионный остаток независимых переменных по регрессионным уравнениям их как зависимых переменных от выбранной переменной (т.е. устранить из всех переменных влияние выбранной переменной); найти наибольший коэффициент корреляции остатков и включить соответствующую переменную x в уравнение регрессии. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д.
Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы выделенные исследователем, удовлетворяющие критериям значимости включения.
Замечание: во избежание зацикливания процесса включения/исключения значимость включения устанавливается меньше значимости исключения.
Матрица данных, собранных на основании
Пример 1.1.
Анкета обследования жалоб и проблем населения (шутка)
1. Пол
мужской Женский 2. Возраст …………
3. Проблемы (укажите 3 основные проблемы):
1. Учеба
2. Свободное время
3. Любовь
4. Музыка
4. Жалобы:
1. Служба
2. Здоровье
3. Зарплата
4. Жена
5. Собака соседа
Матрица данных, собранных на основании такой анкеты, изображена на Рисунок 1.1. Пол здесь закодирован в соответствии с содержимым анкеты кодами 1 - мужчины, 2 - женщины; возраст непосредственно введен в данные; проблемы закодированы в трех переменных - указаны коды обведенных при опросе подсказок; для каждой жалобы отведена своя переменная.
| N Анкеты | 1. Пол | 2. Возраст | 3. Проблемы: | 4. Жалобы: | ||||||
| 1. Служба | 2. Здоровье | 3. Зарплата | 4. Жена | 5. Собака соседа | ||||||
| 1 | 1 | 20 | 1 | 4 | . | 1 | 0 | 0 | 0 | 1 |
| 2 | 1 | 25 | 2 | 3 | 4 | 1 | 0 | 1 | 0 | 1 |
| 3 | 2 | 34 | 1 | 2 | 4 | 1 | 0 | 0 | 0 | 1 |
| 4 | 1 | 18 | 1 | 2 | . | 0 | 0 | 0 | 0 | 1 |
| . | . | . | . | . | . | . | . | . | . | . |
На протяжении всего текста мы будем иллюстрировать работу пакета на более серьезном примере анкеты "Курильские острова", текст которой приведен в приложении 1, кроме того, иногда мы будем привлекать для анализа данные Российского мониторинга экономического положения и здоровья населения (RLMS, [13]).
использования программы Typology Tables
Пример использования программы Typology Tables
В информации RLMS сведения о покупках 3700 семей, сделанных в течение 1 недели (молочных продуктов, спиртного и табака, сладостей и другого), о размерах жилья и имеющихся в жилье удобствах, о наличии в семье дорогостоящих предметов и недвижимости.
Связаны ли ответы о покупках спиртного и табака с наличием автомобиля, дачи и других предметов крупной собственности? Этот вопрос мы проанализируем с помощью Typology Tables.
Пример логистической регрессии и статистики
Пример логистической регрессии и статистики
Процедура логистической регрессии в SPSS в диалоговом режиме вызывается из меню командой Statistics\Regression\Binary logistic….
В качестве примера по данным RLMS изучим, как связано употребление спиртных напитков с зарплатой, полом, статусом (ранг руководителя), курит ли он.
Для этого подготовим данные: выберем в обследовании RLMS население старше 18 лет, сконструируем индикаторы курения (smoke) и пития (alcohol) (в обследовании задавался вопрос "Употребляли ли Вы в течении 30 дней алкогольные напитки")
COMPUTE filter_$=(vozr>18).
FILTER BY filter_$.
compute smoke=(dm71=1).
val lab smoke 1 "курит" 0 "не курит".
compute alcohol=(dm80=1).
val lab alcohol 1 "пьет" 0 "не пьет".
Укрупним переменную dj10 -(зарплата на основном рабочем месте). В данном случае группы по значениям этой переменной в основном достаточно наполнены, но мы с методической целью покажем один из способов укрупнения. Для этого вначале получаем переменную wage, которая содержит номера децилей по зарплате, затем среднюю зарплату по этим децилям (см. таблицу 6.5).
missing values dj6.0 (9997,9998,9999) dj10(99997,99998,99999).
RANK VARIABLES=dj10 (A) /NTILES (10) into wage /PRINT=YES /TIES=MEAN .
MEANS TABLES=dj10 BY wage /CELLS MEAN.
построения модели
Пример построения модели
Обычно демонстрацию модели начинают с простейшего примера, и такие примеры Вы можете найти в Руководстве по применению SPSS. Мы пойдем немного дальше и покажем, как получить полиномиальную регрессию.
Курильский опрос касался населения трудоспособного возраста. Как показали расчеты, в среднем меньшие доходы имеют молодые люди и люди старшего возраста. Поэтому, прогнозировать доход лучше квадратичной кривой, а не простой линейной зависимостью. В рамках линейной модели это можно сделать, введя переменную - квадрат возраста. Приведенное ниже задание SPSS предназначено для прогноза логарифма промедианного дохода (ранее сформированного).
Compute v9_2=v9**2.
*квадрат возраста.
REGRESSION /DEPENDENT lnv14m /METHOD=ENTER v9 v9_2
/SAVE PRED MCIN ICIN.
*регрессия с сохранением предсказанных значений и доверительных интервалов средних и индивидуальных прогнозных значений.
Работа с функциями Missing и Sysmis.
Работа с функциями Missing и Sysmis.
В РМЭЗ (российском мониторинге экономики и здоровья), волна 2, имеется переменная BO2a - ответ на вопрос "Сколько времени в течение последних 7 дней Вы потратили на работу …?", причем коды 997, 998, 999 соответствуют ответам "ЗАТРУДНЯЮСЬ ОТВЕТИТЬ", "ОТКАЗ ОТ ОТВЕТА", "НЕТ ОТВЕТА". Имеет смысл эти коды объявить пользовательскими неопределенными, а системные неопределенные коды перекодировать в 0. Делается это следующими командами.
MISSING VALUES BO2a (997, 998, 999).
If (SYSMIS(BO2a)) BO2a=0.
Execute.
Аналогичным путем в других обстоятельствах можно употребить и функцию Missing.
Работа с неопределенными значениями
Работа с неопределенными значениями
Вообще говоря, если в арифметическом выражении встретится переменная с неопределенным значением, результат будет не определен, однако значения выражения
0*неопределенное значение
и
0/ неопределенное значение
приравниваются к нулю.
Работа с пользовательскими неопределенными значениями
Работа с пользовательскими неопределенными значениями
В данных по вопросу о Курильских островах переменные V15, V16, v17 означают время проживания в Западной Сибири, Восточной Сибири и на Дальнем Востоке. Допустим, для удобства проведения текущих расчетов нулевые коды этих переменных объявлены неопределенными
Missing values V15, V16, v17 (0).
Тогда вычисление времени проживания за Уралом командой
COMPUTE Y = V15 + V16 + v17.
приведет в большинстве случаев к неопределенным значениям Y.
В этом случае функция VALUE позволит работу с пользовательскими неопределенными значениями, как с определенными:
COMPUTE Y = VAL(V15) + VAL(V16)+VAL(V17).
Работа с программой Typology Tables
Работа с программой Typology Tables
Коротко статистический анализ таблиц при помощи Typology Tables можно представить последовательностью следующих естественных действий.
Задание групповых переменных Выбор переменных для строк, столбцов, если необходимо - переменных для вычисления средних и условий (слоев). Выбор таблицы сопряженности или средних (на основе числа валидных ("немиссинговых") объектов в нутри таблицы. Статистический эксперимент. Выдача результатов. Программа может выводить результат в текстовый файл, формат, применяемый в интернет (HTML) и в виде файла EXCEL.
Каждое из этих действий в программе обеспечено своей экранной формой; переход от одной формы к другой происходит естественным путем (запуском очередных расчетов) или с помощью специальных кнопок-переключателей.
Регрессионный анализ
6. Регрессионный анализ
Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии.
Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена логистической регрессии, целью которой является построение моделей, предсказывающих вероятности событий.
Решение уравнения с использованием логита.
Решение уравнения с использованием логита.
Механизм решения такого уравнения можно представить следующим образом
Получаются агрегированные данные по переменным X, в которых для каждой группы, характеризуемой значениями Xj=
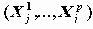
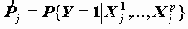
Еще одна особенность состоит в том, что в реальных данных очень часто группы по X оказываются однородными по Y, поэтому оценки
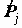
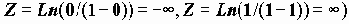
В некоторых статистических пакетах такие группы объектов просто-напросто отбрасываются.
В настоящее время в статистическом пакете для оценки коэффициентов используется метод максимального правдоподобия, лишенный этого недостатка. Тем не менее, проблема, хотя и не в таком остром виде остается: если оценки вероятности для многих групп оказываются равными нулю или единице, оценки коэффициентов регрессии имеют слишком большую дисперсию. Поэтому, имея в качестве независимых переменных такие признаки, как душевой доход в сочетании с возрастом, их следует укрупнить по интервалам, приписав объектам средние значения интервалов.
Режим диалога и командный режим
2.4. Режим диалога и командный режим
Самый простой способ работы в пакете - использование диалоговых окон, возникающих при вызове команд из меню.
Более сложный способ - написание программ на языке пакета. Этот способ предпочтителен при достаточно большом объеме преобразований данных. Исследователь должен иметь перед глазами программу выполненных действий для уверенности в правильности результата. Кроме того полезна возможность копирования и редактирования текста программы преобразования и анализа данных.
Впрочем, важно оптимальное сочетание диалоговых окон и языка.
Диалоговый способ удобен тем, что в диалоговом окне всегда присутствует подсказка о параметрах процедуры преобразования или анализа данных, параметры вводятся в жестко закрепленные поля, поэтому ошибки в нем практически невозможны. Этот способ оказывается полезным также для формирования команды в командном файле. Обычно в диалоговом окне присутствуют “кнопки” OK -непосредственное исполнение команды, PASTE - дописать команду в файл SYNTAX. Благодаря последнему можно писать программы не зная синтаксиса языка программирования в пакете.
Для эффективной работы в пакете необходимо знать и понимать язык программирования SPSS.
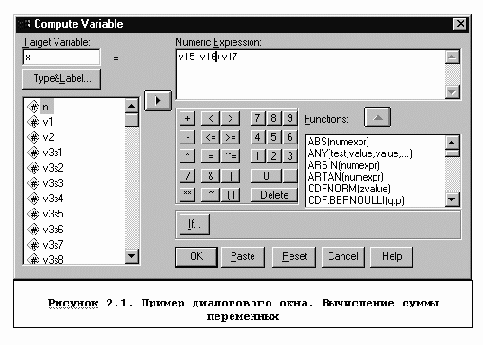
Схема организации данных, окна SPSS
2.2. Схема организации данных, окна SPSS
Прежде чем приступить к описанию работы с пакетом, необходимо рассмотреть списки входных (файлов данных) и выходных файлов (создаваемых пакетом в процессе его работы).
К входным данным в системе SPSS относятся:
1. Исходные данные статистических наблюдений. Они могут быть представлены в виде системного SPSS-файла данных, в виде ASCII-файла, файла, получаемого в электронных таблицах (EXCEL, QUATTRO) в виде файлов баз данных и др.
Естественно, среди этих видов данных наиболее удобны для работы системные данные SPSS. Они содержат не только сами данные и имена переменных, но и их расширенные имена и метки значений, а также информацию о кодах неопределенных значений. Начиная с 8-й версии SPSS, хранится также информация о неальтернативных переменных.
Имена файлов эмпирических данных SPSS имеет расширение .sav. Например, D:CITY.SAV. Непосредственный ввод данных и просмотр информации в таких файлах в SPSS осуществляется через окно редактирования данных (SPSS for Windows Data Editor).
2. Данные, полученные из диалогов. Команды, запущенные из меню, вызывают диалоговые окна, которые позволяют назначить параметры и переменные для программ обработки данных.
3. Файлы синтаксиса, содержащие задание для пакета на специализированном языке пакета. Использование в анализе исключительно диалоговых окон удобно только для новичка. Опытный специалист пишет настоящие программы преобразования данных. Эти программы позволяют в любой момент воспроизвести проведенные расчеты, обнаружить ошибку преобразования данных. Они легко модифицируются для решения других задач.
Имена Файлов с программами на языке пакета имеют расширение .sps. Например, d:work1.sps. По умолчанию они будут иметь имена SYNTAX1.sps, SYNTAX2.sps,… . При необходимости эти файлы можно сохранять для дальнейшей работы.
Для создания программ на языке SPSS в SPSS предусмотрено окно синтаксиса (SYNTAX).
К выходным данным относятся:
Файлы результатов, содержащие таблицы, текстовые результаты, графики, расчетов имеющие имена с расширением .SPO.По умолчанию файлам результатов даются имена, OUTPUT1.SPO, OUTPUT2.SPO … . Для просмотра этих файлов используется окно навигатора вывода (OUTPUT). Часть окна навигатора вывода отведена для дерева выдачи, что облегчает просмотр результатов расчетов. Файлы, которые в дальнейшем могут представлять собой также входную информацию. Преобразованные данные входного файла данных наблюдений (с расширением .sav), файл синтаксиса (.sps) - также могут стать выходными данными. Следует заметить, что кроме указанных окон в пакете могут открываться и другие окна, связанные с просмотром и редактированием графиков, просмотром и редактированием таблиц, написанием программ на языке более низкого уровня, чем язык синтаксиса (Scripts). Язык скриптов в данном учебном пособии мы не будем рассматривать.
Поскольку содержимое всех файлов можно просматривать и редактировать, выделение входных и выходных данных условно и определяется скорее основным их назначением.
Следует заметить, что мы не показали
Следует заметить, что мы не показали здесь часть таблицы попарных сравнений с результатами для метода Бонферрони и Шеффе; результаты аналогичны, но для указанной пары групп значимость различия по Шеффе - 0.041, по Бонферрони - 0.016. Это показывает большую чуствительность теста Тьюки.
Сложные табличные отчеты. Таблицы для неальтернативных вопросов
3.3. Сложные табличные отчеты. Таблицы для неальтернативных вопросов
Получить сложные многоуровневые таблицы, содержащие описательные статистики по числовым переменным, можно используя раздел меню Custom Tables. Этот раздел соответствует команде синтаксиса TABLES. Синтаксис этой команды весьма сложен, поэтому при "ручном" наборе команды TABLES легко можно ошибиться, поэтому мы здесь не будем даже пытаться познакомить читателя с ее текстовым заданием.
Хотя раздел меню состоит из четырех команд: Basic Tables, General Tables, Multiple Responcse Tables и Tables of Frequencies. Мы не будем описывать все нюансы работы с этими командами, покажем лишь принципиально новые возможности по сравнению с Crosstabs.
Ячейки таблицы, получаемой с помощью Basic Tables, соответствуют комбинациям значений переменных. В этих ячейках
могут располагаться частоты, всевозможные проценты, средние по количественным переменным. Например, можно вычислить средние возраст и доход при различных сочетаниях пола, семейного положения и образования. Всего в диалоговом окне может быть задано около 30 статистик, но ни одной статистики, по которой можно было бы проверить значимости связи переменных и значимости различия средних в группах. Недоступны для обработки неальтернативные вопросы.
Команда Tables of Frequencies по сути объединяет в одну таблицу множество одномерных распределений одних переменных в группах по комбинациям значений других переменных. Статистики - только частоты и проценты.
Не имея возможности рассматривать все возможности пакета, мы предлагаем читателю самостоятельно разобраться с командами
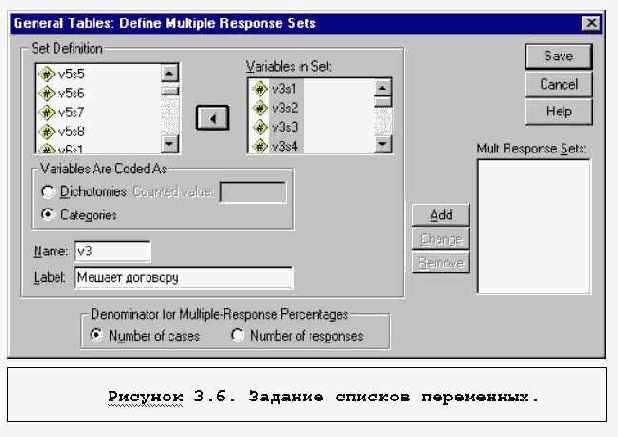
Basic Tables и Tables of Frequencies, вместо этого рассмотрим команду General Tables, имеющую принципиальное значение для анализа неальтернативных вопросов.
Итак, команда General Tables отличается тем, что с ее помощью можно обрабатывать неальтернативные вопросы и комбинации ответов неальтернативных вопросов; в клетках таблиц для неальтернативных и обычных вопросов можно также получать средние количественных переменных.
Для получения таблицы с использованием неальтернативных вопросов необходимо через диалоговое окно General Tables (см. Рисунок 3.5) выйти в окно задания списков переменных для неальтернативных вопросов (см. кнопку Mult Response Sets, Рисунок 3.6) и задать списки этих переменных. Словом Dichotomies Counted Value обозначается дихотомическое кодирование этих вопросов, словом Categories - кодирование в виде списка подсказок.
При вычислении процентов в таблицах для неальтернативных вопросов рассматриваются две возможности, в качестве знаменателя использовать сумму ответов или число наблюдений (анкет). Причем в последнем случае берутся не все объекты, а только анкеты ответивших на соответствующий вопрос.
В SPSS, начиная с 8-й версии, информация о неальтернативных вопросах сохраняется в файле данных. Поэтому, если группы переменных были уже сформированы в прошлых сеансах работы с SPSS, соответствующие имена можно использовать непосредственно.
После задания групп переменных в окне Mult Response основного окна General Tables: появятся их имена, начинающиеся со знака доллара. Эти имена могут использоваться для задания строк, столбцов, слоев таблицы.
Для того, чтобы в таблице были статистики количественной переменной, нужно эту переменную разместить в окно Layers и отметить, что она суммируема (Is summarized в сведенниях о выбранной переменной в основном диалоговом окне General Tables). По умолчанию средние выводятся в целом формате, что часто неудобно, поэтому обычно нужно его исправить (кнопка Format).
Итоговые строки и столбцы назначаются специально (кнопка Totals).
При вычислении частотных таблиц следует позаботиться о задании процентов в числе статистик. Не забудьте, что частотные таблицы без задания процентов в большинстве случаев бессмысленны.
Сохранение переменных
Сохранение переменных
Программа позволяется сохранить множество переменных, среди которых наиболее полезной является, вероятно, предсказанная вероятность.
Стандартизация переменных. Бета коэффициенты
Стандартизация переменных. Бета коэффициенты
Стандартизация переменных, т.е. замена переменных xk на
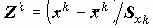
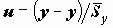
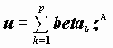
где k - порядковый номер независимой переменной.
Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. Более того, если "независимые" переменные независимы между собой, beta коэффициенты суть коэффициенты корреляции между xk и y. Таким образом, в последнем случае коэффициенты beta непосредственно характеризуют связь x и y.
В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Несмотря на связь переменных xk и y, beta - коэффициент может оказаться равным нулю; мало того, его величина может оказаться больше единицы!
Взаимосвязь аргументов в правой части регрессионного уравнения называется мультиколлинеарностью. При наличии мультиколлинеарности переменных по коэффициентам регрессии нельзя судить о влиянии этих переменных на функцию.
Статистические гипотезы в факторном анализе
Статистические гипотезы в факторном анализе
В SPSS предусмотрена проверка теста Барлетта о сферичности распределения данных. В предположении многомерной нормальности распределения здесь проверяется, не диагональна ли матрица корреляций. Если гипотеза не отвергается (наблюдаемый уровень значимости велик, скажем больше 5%) - нет смысла в факторном анализе, поскольку направления главных осей случайны. Этот тест предусмотрен в диалоговом окне факторного анализа, вместе с возможностью получения описательных статистик переменных и матрицы корреляций. На практике предположение о многомерной нормальности проверить весьма трудно, поэтому факторный анализ чаще применяется без такого анализа.
Статистические эксперименты
Статистические эксперименты
Для выяснения критического значения max|Zij| многократно (заданное число раз) имитируется ситуация независимости ответов, соответствующих строкам и столбцам. В ходе имитации в клетках таблицы получаются значения Z-статистик. Такая имитация осуществляется за счет случайного перемешивания данных, которое можно представить так: мы как будто рассыпали листочки с разными вопросами анкеты и случайно собираем их вместе.
По эмпирической функции распределения получается критические значения для максимума Z-статистики.
Эксперименты позволяют также оценить в каждой клетке наблюдаемую множественную значимость Z-статистики - вероятность на всей таблице случайно получить большее значение Z-статистики.
Статистический эксперимент для оценки значимости и ее прямое вычисление
Статистический эксперимент для оценки значимости и ее прямое вычисление
Что же делать, когда количество наблюдений не позволяет воспользоваться аппроксимацией распределения статистики CHISQ распределением хи-квадрат? В действительности нормальная аппроксимация необходима лишь для того, чтобы можно было вычислить вероятность P{CHISQтеор.>CHISQвыбороч.}. То, что CHISQтеор. имеет распределение хи-квадрат - лишь техническая подробность, связанная с упрощением и ускорением вычислений. То же касается и других статистик значимости (CTAU, BTAU). Современная вычислительная техника позволяет во многих случаях обойтись без использования аппроксимации, вычислить вероятности за счет имитации сбора данных в условиях независимости (метод Монте-Карло) или воспользовавшись непосредственным вычислением вероятности.
В многих процедурах SPSS, в том числе и в Crosstabs, реализованы метод Монте-Карло и прямое вычисление вероятностей.
В методе Монте-Карло проводятся компьютерные эксперименты, в которых многократно случайно перемешиваются данные. В каждом эксперименте вычисляется значение статистики значимости и сравнивается с наблюдаемой ее величиной. Доля случаев, когда статистика превысила наблюдаемое значение, является оценкой уровня значимости. Поскольку оценка вычисляется на основе случайных экспериментов, в дополнеие к оценке уровня значимости выдается его доверительный интервал. Число экспериментов и доверительная вероятность задается заранее.
В методе прямого вычисления рассматривается обобщение гипергеометрического распределения для таблицы сопряженности. Процедура весьма трудоемка и имеет смысл для небольших данных. Заранее задается время счета и, если программа не успела справиться с вычислениями, выдается результат, полученный на основе аппроксимаций.
В диалоговом окне Crosstabs (как, впрочем, и в окнах для других непараметрических процедур) указанные методы включаются с помощью кнопки EXACT.
Пример. Решается вопрос, как связаны "Точка зрения на иностранную помощь" и "Возможность удовлетворить территориальные требований Японии" на выборке, ограниченной жителями Дальнего Востока (276 наблюдений).
Для решения используется
CROSSTABS /TABLES=v4 BY v1 /STATISTIC=CHISQ /CELLS= COUNT Row Col /METHOD=MC CIN(99) SAMPLES(10000).
Параметры последней подкоманды, "/METHOD=MC CIN(99) SAMPLES(10000)", говорят о том, что значимость оценивается методом Монте Карло (MC), будет получен 99% доверительный интервал для оценки наболюдаемой значимости (CIN(99)) с использованием 10000 экспериментов (SAMPLES(10000)).
В результате получаем таблицу 3.8, в которой размещены значимости всех исследуемых статистик. Исследуемые в статистическом эксперименте статистики включают дополнительно обобщение точного теста Фишера (Fisher's Exact Test). Статистика для этого теста имеет вид FI=-2log(g P), где g - константа, зависящая от итоговых частот таблицы, а P - вероятность получить наблюдаемую таблицу в условиях независимости переменных. Статистика FI также имеет асимптотическое распределение хи-квадрат (в условиях гипотезы независимости). Следует заметить, что значимость, вычисленная на основе аппроксимации, выглядит значительно оптимистичнее с точки зрения обнаружения связи, чем при прямых вычислениях, да это и не мудрено - доля клеток, в которых ожидаемая частота меньше 5 равна 56.3%, а минимальная ожидаемая частота равна 0.47.
Опыт показывает, что точный тест на основе прямого вычисления вероятности требует очень много времени. Нашей задаче оказалось недостаточным 25 мин. на персональном компьютере с процессором 200mhz.
STATISTICS - исследование связи неколичественных перемееных
STATISTICS - исследование связи неколичественных перемееных
В предыдущем разделе изучалась связь значений переменных. Для получения ответа о связи переменных в целом используется подкоманда STATISTICS с параметрами, указывающими на статистику или коэффициент для исследования связи переменных. Вот некоторые из этих параметров:
CHISQ - позволяет оценить связь с помощью критерия Xи-квадрат; кроме коэффициента Xи-квадрат при задании этого ключевого слова выдается отношение правдоподобия (Likelihood Ratio). А также статистика для проверки линейной связи. Последняя статистика редко используется, в связи с чем не рассматривается в данных методических рекомендациях.
PHI - коэффициент PHI-Пирсона; вместе с этим коэффициентом выдается коэффициент V-Крамера;
CC - коэффициент контингенции;
BTAU - Тау-В Кендалла для ранговых переменных;
CTAU - Тау-С Стюарта для ранговых переменных;
ALL - указанные статистики и еще около десятка различных статистик.
Как можно охарактеризовать в целом связь НЕКОЛИЧЕСТВЕННЫХ переменных? Для характеристики связи номинальных переменных наиболее часто используется критерий Xи-квадрат (CHISQ), основанный на вычислении статистики
CHISQ=
Эта статистка показывает расстояние эмпирически полученной таблицы сопряженности от ожидаемой теоретически: расстояние между значениями выборочной таблицы Nij и ожидаемой в условиях независимости таблицы Eij. Само по себе значение статистики ни о чем не говорит, важно знать вероятность получения расстояния CHISQ, большего, чем наблюдаемое на случайной выборке. Эта вероятность называется наблюдаемой значимостью и обозначается словом SIGNIFICANCE (возможны сокращения - Sig., P-значения).
CHISQ в условиях независимости и при достаточном числе наблюдений имеет распределение, близкое к распределению Xи-квадрат с (r-1)(c-1) степенями свободы, где r - число строк в таблице, с число столбцов (CHISQтеор.» c 2((r-1)(c-1))). Существует эмпирическое правило, по которому считается, что CHISQ достаточно точно аппроксимируется теоретическим распределением c 2((r-1)(c-1)), если среди ожидаемых частот Eij не более 20% меньше 5 и нет Eij, меньших 1.
Поэтому рекомендуется использовать критерий хи-квадрат в CROSSTABS для переменных с небольшим числом значений, что достигается перекодировкой переменных. В выдаче присутствует информация о числе клеток, где это соотношение не выполняется. Пакет выдает выборочное значение CHISQ и его значимость. Вместе с критерием Xи-квадрат выдается также логарифм отношения правдоподобия LI:
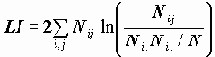
имеющее асимптотически то же распределение, но более устойчивое к объему выборки. Поэтому при оценке связи пары признаков мы рекомендуем пользоваться отношением правдоподобия. Для всех критериев выдается значимость:
SIGNIFICANCE - вероятность случайно получить большее значение, чем выборочное. Таким образом, для CHISQ наблюдаемая значимость (SIG) равна P{CHISQтеор.>CHISQвыбороч.} и, аналогично, для отношения правдоподобия LI наблюдаемая значимость (SIG) равна P{LIтеор.>LIвыбороч.}. Пример задания для исследования связи ответа на вопрос о необходимости иностранной помощи (v1) и полом (v8):
CROSSTABS v8 by v1 /cells count row col asresid /STATISTICS=CHISQ.
Статусная строка
Статусная строка показывает, текущее состояние данных и процесса счета, например:
Transformations pending - задержка преобразований (например, если за преобразованиями не следует команда EXECUTE или статистическая процедура).
Weight on - данные взвешены
Split on - данные для проведения расчетов разбиты на группы
Filter on - включена временная выборка данных
Другая информация.
Структура пакета
Пакет включает в себя команды определения данных, преобразования данных, команды выбора объектов. В нем реализованы следующие методы статистической обработки информации:
- суммарные статистики по отдельным переменным;
- частоты, суммарные статистики и графики для произвольно го числа переменных;
- построение N-мерных таблиц сопряженности и получение мер связи;
- средние, стандартные отклонения и суммы по группам;
- дисперсионный анализ и множественные сравнения;
- корреляционный анализ;
- дискриминантный анализ;
- однофакторный дисперсионный анализ;
- обшая линейная модель дисперсионного анализа (GLM);
- факторный анализ;
- кластерный анализ;
- иерархический кластерный анализ;
- иерархический лог-линейный анализ;
- многомерный дисперсионный анализ;
- непараметрические тесты;
- множественная регрессия;
- методы оптимального шкалирования;
- и т.д.
Кроме того, пакет позволяет получать разнообразные графики - столбиковые и круговые, ящичковые диаграммы, поля рассеяния и гистограммы и др..
Существует ли линейная регрессионная зависимость?
Существует ли линейная регрессионная зависимость?
Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом:
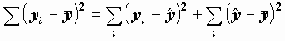
В этом разложении обычно обозначают
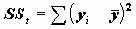
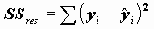
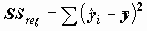
Статистика