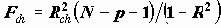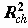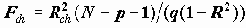Средняя зарплата по децилям.
Таблица 6.5. Средняя зарплата по децилям.
|
WAGE децили зарплаты |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
DJ10 зарплата за 30 дней |
101 |
211 |
307 |
416 |
542 |
703 |
853 |
1108 |
1565 |
3464 |
Полученные средние используем для формирования переменной, соответствующей укрупненной зарплате (для удобства, чтобы коэффициенты регрессии не были слишком малы, в качестве единицы ее измерения возьмем сто рублей).
recode wage (1=1.01) (2=2.11) (3=3.07) (4=4.16) (5=5.42) (6=7.03) (7=8.53) (8=11.08) (9=15.65) (10 =34.64).
recode dj6.0 (sysmis=4)(1 thru 5=1)(6 thru 10=2) (10 thru hi=3) into manag.
var lab manag "статус" wage "зaработок".
val lab manag 4 "не начальник" 1 "шеф" 2 "начальничек" 3 "начальник".
exec.
Далее формируем переменную manag - " статус" из переменной dj6.0 - количество подчиненных.
Запускаем команду построения регрессии LOGISTIC REGRESSION, в которой использованы переменные wage - зарплата, manag статус, dh5 - пол (1 мужчины, 2 женщины) smoke - курение (1 курит, 0 не курит), dh5* wage - "взаимодействие" пола с зарплатой (для женщин значение - 0, для мужчин - совпадает с зарплатой).
LOGISTIC REGRESSION VAR=alcohol /METHOD=ENTER wage manag dh5 smoke dh5*wage /CONTRAST (dh5)=Indicator /CONTRAST (manag)=Indicator /CONTRAST (smoke)=Indicator /PRINT=CI(95) /CRITERIA PIN(.05) POUT(.10) ITERATE(20) CUT(.69) .
В выдаче программа, прежде всего, сообщает о перекодировании данных:
Dependent Variable Encoding:
Original Internal
Value Value
.00 0
1.00 1
Следует обратить внимание, что зависимая переменная здесь должна быть дихотомической, и ее максимальный код считается кодом события, вероятность которого прогнозируется. Например, если Вы закодировали переменную ALCOHOL 1-употреблял, 2-не употреблял, то будет прогнозироваться вероятность не употребления алкоголя.
Далее идут сведения о кодировании индексных переменных для категориальных переменных; из-за их естественности мы их здесь не приводим.
Далее следуют обозначения для переменных взаимодействия, в нашем простом случае это:
Interactions:
INT_1 DH5(1) by WAGE
Средняя жилплощадь в группах семей по покупкам молочных продуктов.
Таблица 3.13. Средняя жилплощадь в группах семей по покупкам молочных продуктов.

Узнать это, определить, какое смещение значимо, а какое - нет, помогут множественные сравнения Z-статистик отклонения средних в клетках от среднего по всей совокупности (см. таблицу 5). В ней выделена единственная значимая на 5% уровне клетка, показывающая относительно малую обеспеченность жилплощадью покупателей кисломолочных продуктов (скорее всего, эти покупатели - из молодых семей с детьми). Абсолютная величина ее значения (-2.87) случайно может быть перекрыта лишь с вероятностью 0.029 (наблюдаемая множественная значимость равна 2.9%).
Статистика хи-квадрат
Анализируя таблицу 5.1, уже по отклонениям расчетных значений от ожидаемых (см. столбец RESIDUAL), видим, что эмпирическое распределение сильно отличается от теоретического. Достаточно высокое значение критерия (Chi-Square =8.333, таблица 5.2) мало информативно. Ответ о совпадении нашего распределения с теоретическим заключен в анализе наблюдаемого уровня значимости. Его малая величина (Asymp. Sig.=0.016) показывает, что полученные отклонения значимы: вероятность получить большие значения Хи-квадрат равна 1.6%, гипотеза о соответствии выборки указанной генеральной совокупности может быть отвергнута на уровне значимости 5%.
Таким образом, для данного случая тест показал существенное различие теоретического и эмпирического распределений.
Приведем пример применения метода статистического моделирования Монте-Карло. В этом примере производится 100000 экспериментов по моделированию выборки из генеральной совокупности с заданными вероятностями (p1=0.3, p2=0.3, p3=0.4):
NPAR TEST /CHISQUARE=w9 /EXPECTED=3 3 4 /METHOD=MC CIN(99) SAMPLES(100000).
Естественно при такой большой выборке был получен тот же результат (таблица 5.3). Уровень значимости этим методом оценивается приближенно, на основе статистических экспериментов - чем больше экспериментов, тем точнее. Поскольку оценка значимости получена на основе случайных экспериментов, выдается доверительный интервал для уровня значимости (99%-й по умолчанию). Точечная оценка наблюдаемого уровня значимости (Monte Carlo Sig) совпадает с асимптотической оценкой (Asymp. Sig., табл.5.3), "оптимистическая" нижняя граница равна 0.015, "пессимистическая" верхняя - 0.017. Таким образом, со всех точек зрения отклонение распределения значимо.
Статистики по переменной V - "Душевой доход", выданные командой FREQUENCIES
Таблица 3.2. Статистики по переменной V14 - "Душевой доход", выданные командой FREQUENCIES
|
N |
Valid |
673 |
|
Missing |
48 | |
|
Mean |
229.11 | |
|
Std. Error of Mean |
5.83 | |
|
Median |
200 | |
|
Mode |
200 | |
|
Std. Deviation |
151.342 | |
|
Variance |
22904.531 | |
|
Skewness |
3.035 | |
|
Std. Error of Skewness |
0.094 | |
|
Kurtosis |
15.080 | |
|
Std. Error of Kurtosis |
0.188 | |
|
Range |
1479 | |
|
Minimum |
21 | |
|
Maximum |
1500 | |
|
Sum |
154190 | |
|
Percentiles |
10 |
100 |
|
25 |
140 | |
|
50 |
200 | |
|
75 |
280 | |
|
90 |
400 |
Чем больше четвертый момент, тем больше пикообразность распределения; нулевое значение KURTOSIS означает, что пикообразность распределения совпадает с пикообразностью нормального распределения. Существенность отклонений статистик от теоретических можно проверить, используя стандартные ошибки этих статистик (в основе лежит факт, что отношение статистики к ее стандартной ошибке имеет распределение, близкое к нормальному).
Перечисленные статистики играют в анализе данных особую роль - они позволяют провести первый этап статистических исследований выборки, проверить нормальность ее распределения. Ниже приведен пример описательных статистик, полученных для переменной "Среднемесячный душевой доход в семье", построенной по ответам на 14-й вопрос анкеты "Курильские острова" командой
FREQUENCIES VARIABLES=V14 /NTILES=4 /PERCENTILES= 10 90
/STATISTICS=STDDEV VARIANCE RANGE MINIMUM MAXIMUM SEMEAN MEAN MEDIAN MODE SUM SKEWNESS SESKEW KURTOSIS SEKURT .
которая вычисляет, также, n-тили и процентили.
Анализируя полученные данные (таблица 3.2), видим, что доход в семьях меняется в диапазоне от 21 рубля до 1500 рублей (разброс равен 1479). При этом средний доход составил около 230 рублей. Приближенными границами пятипроцентного доверительного интервала для истинного среднего будут значения: 229.11± 1.96*5.83, где 1.96 - критическое значение нормального распределения для p=0.05/2=0.025. Скошенность skewness=3.035 Пикообразность kurtosis=15.080 и пикообразность kurtosis=15.080 значительно больше нуля (их стандартные ошибки, 0.094 и 0.188, свидетельствуют о статистической значимости такого отличия).
Результатом задания процентилей и n-тилей являются выданные в таблице процентили (у 10% выборки доход меньше 100 руб., у 90% - меньше 400; имеются также 25%, 50%, 75% процентили).
Связь наблюдения и предсказания в логистической регрессии
Таблица 6.6. Связь наблюдения и предсказания в логистической регрессии
|
Наблюдается |
Предсказано |
||
|
Не пьет |
Пьет |
Всего | |
|
Не пьет |
43.8% |
21.5% |
31.3% |
|
Пьет |
56.2% |
78.5% |
68.7% |
Связь "Точки зрения на
Таблица 3.4. Связь "Точки зрения на иностранную помощь" и "Возможн. удовлетворить территор. требований Японии" (частоты и проценты)
|
V1 точка зрения на иностранную помощь |
V4 Возможность удовлетворить территориториальные требования Японии |
Total | |||
|
1 отдать |
2 не надо |
3 не знаю |
|||
|
не нужна |
Count |
21 |
143 |
11 |
175 |
|
% row |
12.0 |
81.7 |
6.3 |
100.0 | |
|
% col |
19.6 |
27.2 |
13.9 |
24.6 | |
|
огранич. |
Count |
57 |
326 |
48 |
431 |
|
% row |
13.2 |
75.6 |
11.1 |
100.0 | |
|
% col |
53.3 |
62.0 |
60.8 |
60.5 | |
|
Нужна |
Count |
27 |
32 |
14 |
73 |
|
% row |
37.0 |
43.8 |
19.2 |
100.0 | |
|
% col |
25.2 |
6.1 |
17.7 |
10.3 | |
|
не знаю |
Count |
2 |
25 |
6 |
33 |
|
% row |
6.1 |
75.8 |
18.2 |
100.0 | |
|
% col |
1.9 |
4.8 |
7.6 |
4.6 | |
|
Total |
Count |
107 |
526 |
79 |
712 |
|
% row |
15.0 |
73.9 |
11.1 |
100.0 | |
|
% col |
100.0 |
100.0 |
100.0 |
100.0 | |
В таблице 3.5 получен ответ на поставленный в начале раздела вопрос: смещение частоты в клетке "Отдать острова" - "Нужна помощь" (residual=16) оказалось существенным, Z=5.5, в то же время смещение частоты на 5.3 в клетке "помощь не нужна - отдать" - не значимо (Z=1.3). Кроме того, в полученной значимой связи можно еще раз убедиться, рассмотрев таблицу 6 с процентными распределениями (в среднем по совокупности 15% считают, что острова можно отдать, в то время как в этой группе таковых 37%!). В то же время, судя по статистикам, хотя видна отрицательная связь значений "нужна ограниченная помощь" - "отдать острова", она не достаточно значима.
Надеемся, что нам удалось показать, что эти статистики наиболее интересны для интерпретации. К сожалению, в SPSS расчет
T-тест на связанных выборках, корреляции
Таблица 4.6. T-тест на связанных выборках, корреляции
|
N |
Correlation |
Sig. | |
|
AM1 Вес 1995 & BM1 Вес 1996 |
793 |
0.914 |
0.0000 |
T-тест на связанных выборках, описательные статистики
Таблица 4.5. T-тест на связанных выборках, описательные статистики
|
Mean |
N |
Std. Deviation |
Std. Error Mean | |
|
AM1 Вес 1995 |
67.59 |
793 |
13.72 |
0.49 |
|
BM1 Вес 1996 |
68.12 |
793 |
14.22 |
0.50 |
T-тест на связанных выборках, сравнение средних
Таблица 4.7. T-тест на связанных выборках, сравнение средних
|
Paired Differences Mean |
Std. Deviation |
Std. Error Mean |
95% Confidence Interval of the Difference |
t |
Df |
Sig. (2-tailed) | ||
|
Lower |
Upper | |||||||
|
AM1 Вес 1995 & BM1 Вес 1996 |
-0.53 |
5.81 |
0.21 |
-0.93 |
-0.12 |
-2.547 |
792 |
0.011 |
Женщины в среднем набрали по полкилограмма веса и этот прирост статистически значим. Значим и коэффициент корреляции - вес в целом имеет свойство сохраняться.
T-тест, описательные статистики по группам
Таблица 4.3. T-тест, описательные статистики по группам
|
V9 Возраст |
N |
Mean |
Std. Deviation |
Std. Error Mean | |
|
LNV14M |
>= 30 |
521 |
0.019 |
0.517 |
0.023 |
|
< 30 |
133 |
-0.177 |
0.593 |
0.051 |
T-тест, сравнение средних и дисперсий в группах
Таблица 4.4. T-тест, сравнение средних и дисперсий в группах
|
Levene's Test for Equality of Variances |
T |
Df |
Sig. (2-tailed) |
Mean Difference |
Std. Error Difference |
95% Confidence Interval of the Difference | |||
|
F |
Sig. | ||||||||
|
Lower |
Upper | ||||||||
|
Equal variances assumed |
2.47 |
0.1162 |
3.78 |
652 |
0.000 |
0.196 |
0.052 |
0.094 |
0.298 |
|
Equal variances not assumed |
3.48 |
186.42 |
0.001 |
0.196 |
0.056 |
0.085 |
0.307 | ||
В таблицах 4.3 и 4.4 приведен пример сравнения средних логарифмов душевых доходов в группах населения до 30 лет и старше 30. Статистика Ливиня в этом случае свидетельствует, что гипотеза равенства дисперсий не отвергается (sig=0.1162). Поэтому, для сравнения средних можно воспользоваться строкой" Equal variances assumed" - "Предполагаются равные дисперсии". Соответствующая статистика показывает, что средние различиются существенно (sig=0.000). Впрочем, даже если мы не удовлетворены статистикой Ливиня, в данном случае и без предположения равенства дисперсий мы можем утверждать то же самое (sig=0.001). Кроме того, это подтверждает и доверительный интервал, не включающий нуля.
Tест Фридмана. Средние ранги.
Таблица 5.18. Tест Фридмана. Средние ранги.
|
Mean Rank | |
|
AM1 вес в 1994г. |
2 |
|
BM1 вес в 1995г. |
2.13 |
|
CM1 вес в 1996г. |
1.87 |
Tест Фридмана. Значимость.
Таблица 5.19. Tест Фридмана. Значимость.
| N | 15 |
| Chi-Square | 0.561 |
| Df | 2 |
| Asymp. Sig. | 0.755 |
Глава 5. Непараметрические тесты *
5.1. Одновыборочные тесты. *
Тест Хи-квадрат. *
Тест, основанный на биномиальном распределении *
Тест Колмогорова-Смирнова *
5.2. Тесты сравнения нескольких выборок *
Двухвыборочный тест Колмогорова-Смирнова *
Тест медиан *
5.3. Тесты для ранговых переменных *
Двухвыборочный тест Манна-Уитни (Mann-Witney)- *
Одномерный дисперсионный анализ Краскэла-Уоллиса (Kruskal-Wallis) *
5.4. Тесты для связанных выборок (related samples) *
Двухвыборочный критерий знаков (Sign) *
Двухвыборочный знаково-ранговый критерий Уилкоксона (Wilcoxon) *
Критерий Фридмана (Friedman) *
Тест Краскэла Уоллиса. Средние ранги.
Таблица 5.12. Тест Краскэла Уоллиса. Средние ранги.
|
TP тип поселен |
N |
Mean Rank | |
|
V14 Ср.мес. душевой доход в семье |
1.00 растущие |
174 |
382 |
|
2.00 стабильные |
230 |
365.2 | |
|
3.00 крупные |
201 |
304.6 | |
|
4.00 гигант |
68 |
222.2 | |
|
Total |
673 |
Тест Краскэла-Уоллиса. Значимость критерия.
Таблица 5.13. Тест Краскэла-Уоллиса. Значимость критерия.
|
V14 Ср.мес. душевой доход в семье | |
|
Chi-Square |
43.702 |
|
Df |
3 |
|
Asymp. Sig. |
0 |
Тест показывает (Sig=0), что точка зрения респондента на иностранную помощь существенно связана типом населенного пункта, в котором он проживает (таблицы 5.12-13).
Тест знаков для парных наблюдений. Частоты
Таблица 5.14. Тест знаков для парных наблюдений. Частоты
|
Frequencies |
||
|
N | ||
|
BM1 вес в 1995г. - AM1 вес в 1994г. |
Negative Differences |
877 |
|
Positive Differences |
722 | |
|
Ties |
350 | |
|
Total |
1949 |
Судя по таблице 5.14, мужчины чаще худели, чем толстели, причем этот факт подтверждается отрицательным значением статистики критерия, наблюдаемая значимость которой равна 0.000118 (таблица 5.15.).
Таблица 5.15. Тест знаков для парных наблюдений. Значимость критерия.
|
Test Statistics |
|
|
BM1 вес в 1995г. - AM1 вес в 1994г. | |
|
Z |
-3.8512 |
|
Asymp. Sig. (2-tailed) |
0.000118 |
Тесты ХИ-квадрат
Таблица 3.6. Тесты ХИ-квадрат
|
Value |
df |
Asymp. Sig. (2-sided) | |
|
Pearson Chi-Square |
10.517 |
3 |
.015 |
|
Likelihood Ratio |
10.708 |
3 |
.013 |
|
Linear-by-Linear Association |
.156 |
1 |
.693 |
|
N of Valid Cases |
708 |
a 0 cells (.0%) have expected count less than 5. The minimum expected count is 22.25.

В приведенном примере наблюдаемая значимость CHISQ составила около 1.5% (см. Asymp. Sig. (2-sided)), значимость LI примерно 1.3%. С такой вероятностью случайно в условиях независимости можно получить большие значения соответствующих статистик, поэтому, в соответствии с 5% уровнем значимости, переменные v8 и v1 следует считать связанными (1.3%<5%). Таким образом, мужчины и женщины имеют разные мнения в вопросе об иностранной помощи.
Если теперь взглянуть на Z-статистики, можно увидеть, в клетке "мужчины" - "помощь нужна" эта статистика равна 2.9, и о помощи говорят вдвое больше мужчин, чем женщин. Мы не будем приводить здесь эту таблицу, а покажем лишь столбиковую диаграмму на Рисунок 3.4, полученную командой
ROSSTABS v8 by v4 /cells count row col asresid/BARCHART.
Z-статистики и значимость
Таблица 3.11. Z-статистики и значимость (%) связи покупки алкоголя и табачных изделий и наличие крупной собственности (фрагмент таблицы, Z-статистики)

В таблице 3.12 отмечены значимые с точки зрения множественнях сравнений Z-статистики. При этом оценка 5% критического значения Z равна 3.09, а не 1.96, как это было бы в обычном анализе.
В каждой клетке расположены также наблюдаемые множественные значимости. Например, Z статистика 6.46 в клетке "Легковой автомобиль - пиво" практически не может быть получена случайно (вероятность получить большее значение равна нулю), а связь, характеризуемая значением Z=2.84 в клетке "Другая квартира - водка" - под сомнением: такие и большие значения в одной из 28 клеток таблицы можно получить случайно с вероятностью 10.8%.
Z-статистики отклонений
Таблица 3.12. Z-статистики отклонений частот и их наблюдаемая множественная значимость (в %, 5% критическое значение max|Zij|=3.09).

Z-статистики отклонений средних для таблицы ( множественное критическое значение равно ).
Таблица 3.14. Z-статистики отклонений средних для таблицы 4 (5% множественное критическое значение равно 2.69).
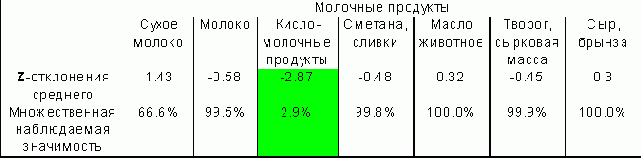
Таблица 3.16. Z-статистики отклонений средних для таблицы 6 (5% множественное критическое значение равно 3.1).

Таким образом, мы одновременно рассматриваем Z статистики для каждой группы и проводим множественные сравнения 21 смещения средних (покупателями джема и варенья оказались только жители отдельных квартир, поэтому для части клеток таблицы средние и, следовательно, Z-статистики их отклонений не определены). Способы определения значимости смещений в двумерной таблице и одномерной таблице средних идентичны, здесь также используется перемешивание данных по зависимой переменной.
На основании таблицы 3.16 можно достоверно утверждать, что среди обитателей отдельных квартир большие доходы имеют семьи любителей мороженого, конфет и печенья с пирожными; среди жильцов отдельных домов существенно выделяются по доходам семьи у покупателей сахара (только в 5% случаев в таблице случайно можно получить большие Z-статистики). В остальных клетках таблицы Z - статистики незначимы - либо отклонения несущественны, либо выборка маловата, чтобы делать надежные выводы.
Значимость критерия хи-квадрат
Таблица 5.3. Значимость критерия хи-квадрат
|
W9 | |||
|
Chi-Square |
8.333 | ||
|
Df |
2 | ||
|
Asymp. Sig. |
0.016 | ||
|
Monte Carlo Sig |
Sig. |
0.016 | |
|
99% Confidence Interval |
Lower Bound |
0.015 | |
|
Upper Bound |
0.017 |
Таблица 5.4. Значимость критерия хи-квадрат
|
Category |
N |
Observed Prop. |
Test Prop. |
Asymp. Sig. (2-tailed) |
Exact Sig. (2-tailed) | |
|
Group 1 |
1 муж. |
362 |
0.508 |
0.5 |
0.708 |
0.708 |
|
Group 2 |
2 жен. |
351 |
0.492 |
|||
|
Total |
713 |
1 |
В таблице 5.4 выдается расчетная 0.508 и заданная теоретическая вероятность Test Prop.=0.5. Выборочное распределение почти совпало с заданным. Этот результат окончательно подтверждает величина двусторонней значимости: 0.708 - вероятность случайно получить значение, большее полученного. Так как 70% - это большая вероятность, мы делаем вывод, что распределение совпадает с заданным. Двусторонний тест показал незначимое отличие доли мужчин в выборке от ожидаемой доли (нулевая гипотеза не отвергается).
Знаково-ранговый тест Вилкоксона. Средние ранги.
Таблица 5.16. Знаково-ранговый тест Вилкоксона. Средние ранги.
|
BM1 вес в 1995г. - AM1 вес в 1994г. |
N |
Mean Rank |
Sum of Ranks | |
|
Negative Ranks |
877 |
802.2 |
703500 | |
|
Positive Ranks |
722 |
797.4 |
575700 | |
|
Ties |
350 |
|||
|
Total |
1949 |
Таблица 5.17. Знаково-ранговый тест Вилкоксона. Средние ранги.
|
BM1 вес в 1995г. - AM1 вес в 1994г. | |
|
Z |
-3.46504 |
|
Asymp. Sig. (2-tailed) |
0.00053 |
Тест Хи-квадрат
5.1.1. Тест Хи-квадрат
Критерий Хи-квадрат основан на статистике
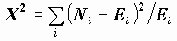
где
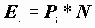
Пример. Пусть, согласно статистическим данным, 30% трудоспособного населения имеют возраст до 30 лет, 30% - от 30 до 40 лет и 40% свыше 40 лет. Соответствует ли выборочное распределение признака "возраст" в обследовании "Курильские острова" распределению возраста в генеральной совокупности?
RECODE v9 (1 THR 30 =1)(31 THR 40 =2)(41 THRU HI =3) INTO w9.
NPAR TESTS /CHISQUARE = W9 /EXPECTED 3 3 4.
Подкоманда /CHISQUARE задает тестируемую переменную; в подкоманде /EXPECTED задаем через пробел ожидаемые пропорции распределения.
Выполнение этих команд позволяет получить значение критерия и оценить степень соответствия нашей выборки распределению генеральной совокупности (табл. 5.1, 5.2).
Тест медиан
5.2.2. Тест медиан
Этот тест позволяет сравнивать распределения исследуемой переменной сразу в нескольких группах. Тест весьма груб, но прост.
NPAR TESTS MEDIAN = V14 BY V1(1,3).
Внешне задание теста похоже на задания критерия Колмогорова-Смирнова.
Задание сравниваемых групп. После слова BY за именем переменной в скобках указывается интервал значений. В приведенном примере сравниваются распределения в трех группах. Тестом можно сравнить также и пару групп, если в скобках вначале указать большее значение, затем меньшее (при задании V4(3,1) сравниваются только 1-я и 3-я группы).
Суть проверки гипотезы состоит в следующем. Значения исследуемой переменной (в нашем примере - V14) делятся на две группы: больше медианы и меньше или равно медиане. Такое разделение можно считать заданием новой, дихотомической переменной. Вычисляется таблица сопряженности полученной дихотомической переменной и переменной, задающей группы. Далее применяется известный критерий Хи-квадрат. Если величина наблюдаемой значимости критерия мала, естественно предположить, что распределение исследуемой переменной в группах различается существенно.
Замечание. Для получения дихотомии можно, также, навязать точку "разрыва" переменной, не совпадающую с медианой, указав в скобках за словом MEDIAN соответствующее значение.
Пример. Курильское обследование проходило в 21 городе Западной Сибири. Экспертным путем все города разделены на 4 типа: 1 растущие, 2 стабильные, 3 крупные, 4 гиганты. Типу города в наших данных соответствует переменная TP.
Исследуется связь доходов и типа населенного пункта.:
npar test med=v14 by TP(1,4).
Тесты для ранговых переменных
5.3. Тесты для ранговых переменных
В ряде методов по имеющимся числовым значениям исследуемой переменной объектам приписываются ранги. Для вычисления рангов объекты упорядочиваются от минимального значения переменной к максимальному, и порядковые номера объектов считаются рангами. Если для некоторых объектов числовые значения переменной повторяются, то всем этим объектам приписывается единый ранг, равный среднеарифметическому значению их порядковых номеров. Об объектах, ранги которых совпадают, говорят, что они имеют связанные ранги. Наличие связанных рангов в выдаче по ранговым тестам обозначается словом "ties" (связи). Обычно выводится число связей и статистика критерия, скорректированная для связей.
В качестве примера построения рангов возьмем упорядоченную информацию об успеваемости 7 студентов.
Средний балл: 3.0 3.1 4.0 4.2 4.2 4.5 5.0
Ранг: 1 2 3 4.5 4.5 6 7
Первые три объекта имеют ранги 1, 2, 3; следующая пара -ранг 4.5 =(4+5)/2, следующая пара - 6 и 7.
Тесты для связанных выборок (related samples)
5.4. Тесты для связанных выборок (related samples)
Напомним, что связанными выборками называются совокупности повторных измерений на одних и тех же объектах. Например, доходы семьи в различных волнах панельного обследования RLMS; психологические характеристики мужа и жены и т.п.
Тесты сравнения нескольких выборок
5.2. Тесты сравнения нескольких выборок
Эти тесты предназначены для проверки гипотезы совпадения распределений в выборках. В отличие от t-теста и известных методов дисперсионного анализа, здесь не предполагается нормальность теоретического распределения.
Многие тесты основаны на поиске определенного типа противоречия с гипотезой совпадения распределений и не может обнаружить всех отличий. Например, тест медиан проверяет совпадение только медиан. Поэтому иногда полезно воспользоваться несколькими тестами.
Тип шкалы измерения переменных.
Тип шкалы измерения переменных.
Формируя данные, исследователь ставит в соответствие значениям переменной, имеющей содержательный смысл ("пол - мужской", "профессия - учитель"), числовые значения. Такое соответствие называется шкалой измерения переменной. В зависимости от свойств переменной выделяют шкалы: номинальную, ординальную (ранговую), интервальную и шкалу отношений.
ТИПИЧНЫe ПРИМЕРы ИСПОЛЬЗОВАНИЯ Multiple Response Tables
ТИПИЧНЫe ПРИМЕРы ИСПОЛЬЗОВАНИЯ Multiple Response Tables
Подготовка дихотомически закодированного неальтернативного признака.
В анкете имеются вопросы "Сколько лет проживали
14. В Западной Сибири?
15. В Восточной Сибири?
16. На Дальнем Востоке?
Рассмотрим, как получить в одной таблице распределение по неальтернативному признаку "Места проживания", полученному по ответам на эти вопросы. Элементарные дихотомические переменные, соответствующие данному признаку, можно построить с помощью следующих команд:
COMPUTE m1=V14.
COMPUTE m2=V15.
COMPUTE m3=V16.
RECODE m1 m2 m3 (1 THR HI=1).
VAR LAB m1 "Зап Сиб" m2 "Вост Сиб" m3 "Дальн Вост".
* General Tables.
TABLES
/MRGROUP $v3 'Мешает договору' v3s1 to v3s8
/MDGROUP $region m1 m2 m3 ( 1 )
/GBASE=RESPONSES
/FTOTAL= $t000005 "Total" $t000006 "Total"
/TABLE=$region + $t000005 BY $v3 + $t000006
/STATISTICS count( $v3( F5.0 ))
rpct( $v3( PCT5.1 ) 'Row Response %':$region )
rpct( $v3( PCT5.1 ) 'Col Response %':$v3 ).
Объединение подсказок в неальтернативном признаке, закодированном в виде списка. Объединение подсказок можно сделать за счет приведения этих переменных в дихотомическую форму.
Задача: объединить в 7-м вопросе ответы: "продажа островов" и "продажа с компенсацией" и исследовать его связь с регионом проживания респондента (переменная R). Для этого следует выполнить программу:
COUNT D1 = V7S1 TO V7S7 (1)/
D2 = V7S1 TO V7S7 (2,3)/
D3 = V7S1 TO V7S7(4 TO 10).
RECODE D1 TO D3(1 THR 10 =1).
*метки переменных.
VAR LAB D1 'Жесткий вариант'
D2 'Совместное использование'
D3 'мягкий вариант'.
TABLES MDGROUPS D "Степень жесткости позиции" D1 D2 D3(1)
/TABLES D+T BY R+T/ STAT COUNT(D) CPCT(D:D) CPCT(D:R).
Типы кодирования переменных.
Типы кодирования переменных.
В статистическом пакете SPSS предусмотрено 8 типов кодирования переменных. Подробнее о них можно узнать в [Руководство пользователя. Книга 1. - М.: Статистические системы и сервис, 1995]. Мы остановимся лишь на строчных (STRING) и числовых (NUMERIC) переменных.
Строчные переменные используются достаточно редко, например, для введения ответов на открытые вопросы или фамилий респондентов, если имеется такая возможность и в них есть необходимость, например переменная dj56.1.1 8-й волны RLMS содержит ответы на вопрос "В чем состояла эта Ваша работа?"
Но обычно, при внесении в компьютер информации для статистической обработки, ответы на вопросы анкеты кодируются числами. Хотя с формальной точки зрения практически любая обрабатывающая программа может использовать эти цифры независимо от того, кодируется ли профессия, возраст или сведения о цвете глаз. Различные методы анализа данных ориентированы на данные определенного типа. Для получения интерпретируемых результатов перед применением программы исследователь должен определить тип обрабатываемых соответствующим методом переменных.
Типы переменных
1.2. Типы переменных
Типы переменных можно рассмотреть с технической точки зрения и в аспекте применения математических методов.
Управление работой пакета
2.3. Управление работой пакета
Управление работой пакета происходит в основном через меню, при этом соблюдаются стандарты системы WINDOWS. Каждое окно имеет свое меню, многие команды меню доступны из различных окон.
Условное выполнение команд.
Команды DO IF, ELSE IF, ELSE и ENDIF используются для того, чтобы сделать преобразование переменных на подмножествах объектов сразу несколькими командами.
Пусть, например, в файле "Курильские острова" требуется проинтервалировать возраст (v9), но так, чтобы интервалы отделяли пенсионный возраст, который различен для мужчин и женщин (v8):
Вероятность правильного предсказания
Вероятность правильного предсказания
На основе модели логистической регрессии можно строить предсказание произойдет или не произойдет событие {Y=1}. Правило предсказания, по умолчанию заложенное в процедуру LOGISTIC REGRESSION устроено по следующему принципу: если
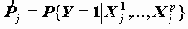
Поэтому здесь необходима другая классификация, которая демонстрирует связь между зависимой и независимыми переменными. С этой целью стоит отнести к предсказываемому классу


Ввод данных с экрана
При загрузке пакета появляется таблица, похожая на электронные таблицы. Данные можно вводить непосредственно с экрана. По умолчанию переменные будут иметь имена VAR0001.. Var0002 и т.д. Для изменения имен переменных, назначения их типов и расширенных названий (меток) можно щелкнуть мышкой дважды на существующих названиях столбцов. При этом открывается окно диалога по описанию переменной.
Ниже приводятся команды VARIABLE LABELS, VALUE LABELS, MISSING VALUES, дублирующие основные функции этого диалога.
Взаимодействие переменных
Взаимодействие переменных
Предположим, что мы рассматриваем пару индикаторных переменных: X1 - для выделения группы женатых и X2 - для выделения группы "начальников", а прогнозируем с помощью уравнения регрессии все тот же логарифм дохода: Y=B0+B1*X1+B2*X2.
Это уравнение моделирует ситуацию, когда действие факторов X1 и X2 складывается, т.е. считается, к примеру, что женатый начальних имеет зарплату B1+B2, не женатый начальник B2. Это достаточно смелое предположение, так как, скорее всего, закономерность не так груба и существует взаимодействие между факторами, в результате которого их совместный вклад имеет другую величину. Для учета такого взаимодействия можно ввести в уравнение переменную, равную произведению X1 и X2:
Y=B0+B1*X1+B2*X2+B3*X1*X2.
Произведение X1*X2 равно единице, если факторы действуют совместно и нулю, если какой либо из факторов отсутствует.
Аналогично можно поступить для учета взаимодействия обычных количественных переменных, а также индексных переменных с количественными.
Для получения переменных взаимодействия, следует воспользоваться средствами преобразования данных SPSS.
В процедуре логистической регрессии в SPSS предусмотрены средства для автоматического включения в уравнение переменных взаимодействий. В диалоговом окне в списке исходных переменных для этого следует выделить имена переменных, взаимодействия которых предполагается рассмотреть, затем переправить выделенные имена в окно независимых переменных кнопкой c текстом >a*b>.
Взвешенная регрессия
Взвешенная регрессия
Пусть прогнозируется вес ребенка в зависимости от его возраста. Ясно, что дисперсия веса для четырехлетнего младенца будет значительно меньше, чем дисперсия веса 14-летнего юноши. Таким образом, дисперсия остатка e i зависит от значений X, а значит условия для оценки регрессионной зависимости не выполнены. Проблема неоднородности дисперсии в регрессионном анализе называется проблемой гетероскедастичности.
В SPSS имеется возможность корректно сделать соответствующие оценки за счет приписывания весов слагаемым минимизируемой суммы квадратов. Эта весовая функция должна быть равна 1/?2(x), где ?2(x) - дисперсия y как функция от x. Естественно, чем меньше дисперсия остатка на объекте, тем больший вес он будет иметь. В качестве такой функции можно использовать ее оценку, полученную при фиксированных значениях X.
Например, в приведенном примере на достаточно больших данных можно оценить дисперсию для каждой возрастной группы и вычислить необходимую весовую переменную. Увеличение влияния возрастных групп с меньшим возрастом в данном случае вполне оправдано.
В диалоговом окне назначение весовой переменной производится с помощью кнопки WLS (Weighed Least Squares - метод взвешенных наименьших квадратов).
Взвешивание выборки WEIGHT
Социологи достаточно часто некорректно работают со статистическими данными. К примеру, перед ними стоит задача изучить социальные факторы людей, занятых в правовых органах. Известно, что в органах юстиции занято 2% трудоспособного населения. При определении объектов исследования на практике возникают трудности с репрезентативностью выборки. Например, если будет отобрано 500 человек, то из них может оказаться только 10 занятых в органах юстиции. Их обследование будет недостаточно для формирования выводов.
Поэтому социологи осознанно выбирают большее число занятых в этих органах, например 50 из 500. Иногда они рассчитывают целую половозрастную, отраслевую и т.д. таблицу, по которой решают, сколько человек в каждой социальной группе опросить. Это, как правило, деформирует выборку, от которой требуется репрезентация населения, например, всего города. Чтобы уменьшить влияние деформированности выборки на результаты статистического анализа, применяют взвешивание объектов: группы, которые были искусственно уменьшены, выбираются с весовым коэффициентом, превышающим единицу. Обычно суммарный вес объектов равен числу объектов в рассматриваемом файле.
Пусть, например, опрошено 300 человек, из них 100 мужчин, 200 женщин (бухгалтеров застать на рабочем месте было проще всего). Предполагается, что в генеральной совокупности 50% мужчин, 50% женщин. Целесообразно учитывать мужчину с весом 1.5, а женщину - с весом 0.75, тогда с учетом весов выборка будет выровнена.
Пусть переменная SEX содержит сведения о поле респондентов (1 - мужской, 2 - женский). Соответствующие веса будут назначены соответствующими командами
Recode SEX (1=1.5)(2=0.75) into wsex.
WEIGHT by wsex
Execute.
Вообще, если известно распределение объектов k групп в генеральной совокупности p1,…,pk; получено частотное распределение n1,…,nk, то i-й группе должен быть
| приписан вес wi=pi/ni*n, где n= | 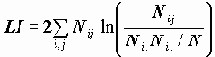 |
Назначение веса можно сделать также через меню редактора данных (DATA->WEIGHT CASES).
Замечания: взвешивание - это не физическое повторение наблюдения. Если значение веса отрицательное или неопределенное (предварительно определенное как SYSMIS), то оно обрабатывается статистическими процедурами как вес, равный нулю.
Z статистика отклонения средних
Z статистика отклонения средних
При анализе средних в таблицах для неальтернативных признаков, каждая ячейка рассматривается по отдельности и среднее в группе, соответствующей ячейке, сравнивается со средними в ее дополнении.
Обозначим A совокупность объектов, соответствующую i-тому ответу вертикального и j-му ответу горизонтального вопросов, B - ее дополнение. Число объектов в группе A равно

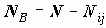


Для проверки значимости различия средних в группах A и B в предположении теоретического нормального распределения, при несовпадении дисперсии в группах используется статистика
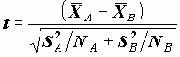
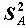
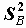
Статистика t характеризует отклонение среднего в группе A от среднего в группе B, но, поскольку
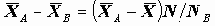
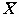
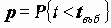
Z-статистика значимости отклонения частот
Z-статистика значимости отклонения частот
Для исследования значимости связи ответов изучается полученная из исходной таблицы четырехклеточная матрица частот
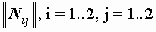
В качестве статистики значимости используется асимптотически нормально (~N(0,1)) распределенная статистика Z=(N11-E11)/s . Мы уже рассматривали эту статистику под названием ASRESID (Adjusted residuals) в CROSSTABS. Для малых выборок эта статистика корректируется на основе прямого вычисления вероятностей так, чтобы для нее выполнялись соотношения нормального распределения.
Задание факторного анализа
Задание факторного анализа
Задание факторного анализа может быть весьма простым. Например, достаточно задать команду FACTOR и подкоманду VARIABLES с указанием переменных и запустить команду на счет. Однако если удобнее самому управлять расчетами, то следует задать некоторые параметры.
Рассмотрим работу такой команды на агрегированном по городам файле наших учебных данных (напоминаем, что объектами этого файла являются города, в которых проводился опрос по поводу возможности передачи Японии курильских островов, см. выше).
FACTOR /VARIABLES W3D1 TO W3D6 /PLOT EIGEN
/CRITERIA FACTORS (2) /SAVE REGRESSION (ALL F).
Команда задана для получения факторов по переменным - долям числа респондентов, указавших различные причины неподписания договора (/VARIABLES W3D1 TO W3D6): W3D1 - нет необходимости; W3D2 - традиционное недоверие; W3D3 - незаинтересованность Японии; W3D4 - разные политические симпатии; W3D5 - нежелание Японии признать границы; W3D6 - нежелание СССР рассматривать вопрос об островах.
Подкоманда /PLOT EIGEN - выдает графическую иллюстрацию долей объясненной дисперсии. Подкоманда /CRITERIA FACTORS (2) задает получение 2-х факторов; если этой подкоманды не будет, программа сама определит число факторов. Заданием /SAVE REGRESSION (ALL f) мы получаем регрессионным методом непосредственно в активном файле оценки всех (ALL) факторов. Это будут переменные F1, F2 с заданным нами корневым именем F и добавленными к нему номерами факторов.
Рассмотрим результаты анализа.
Значимость включения переменной в регрессию
Значимость включения переменной в регрессию
При последовательном подборе переменных в SPSS предусмотрена автоматизация, основанная на значимости включения и исключения переменных. Рассмотрим, что представляет собой эта значимость.
Обозначим
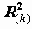
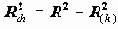
Для оценки значимости включения переменной xk используется статистика