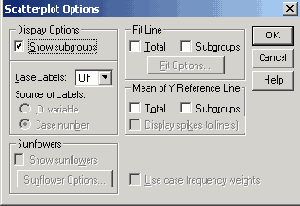
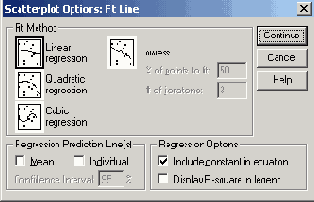
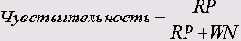Простые столбчатые диаграммы
22.1.1 Простые столбчатые диаграммы
Откройте файл с данными об исследовании гипертонии (файл hyper.sav).
Мы хотим построить столбчатую диаграмму для процентных показателей частот четырёх возрастных групп (переменная ak).
Щёлкните на области Simple (Простая) и оставьте предварительную установку Summaries for groups of cases (Обработка категорий одной переменной).
Щёлкните по кнопке Define (Определить); откроется соответствующее диалоговое окно.
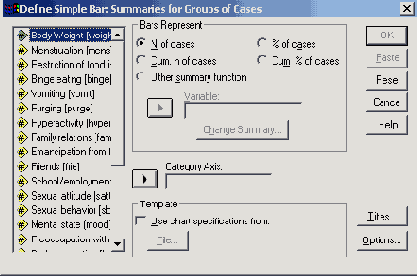
В поле Category Axis: (Ось категорий) введите переменную ak, активируйте % of cases (% наблюдений) и, пройдя выключатель Titles... (Заголовок), введите заголовок для диаграммы.
Щёлкните на ОК.
Кластеризованные столбчатые диаграммы
22.1.2 Кластеризованные столбчатые диаграммы
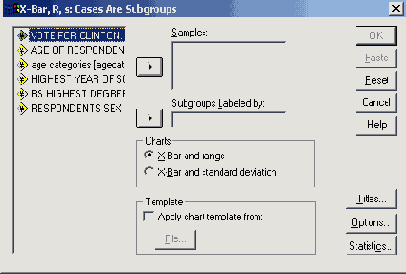
Теперь в целях обработки данных, полученных в ходе исследования гипертонии (файл hyper.sav), отдельно для двух методик лечения (переменная med с двумя своими значениями, равными 1 и 2) в графическом виде должны быть представлены частотные показатели четырёх возрастных групп (переменная ak) в процентном выражении.
Откройте файл hyper.sav.
В диалоговом окне Bar Charts (Столбчатые диаграммы) щёлкните на области Clustered (Кластеризованная); активируйте опцию, устанавливаемую по умолчанию, Summaries for groups of cases (Обработка категорий одной переменной).
Щёлкните на кнопке Define (Определить); откроется главное диалоговое окно, изображённое на рисунке 22.10.
Состыкованные диаграммы
22.1.3 Состыкованные диаграммы
Как правило, состыкованная столбчатая диаграмма применяется тогда, когда столбцы отражают частоты, которые должны быть разделены при помощи некоторой внешней переменной. В таком случае, и обзор суммарных частот предоставляется пользователю иначе, нежели в виде кластеризованной столбчатой диаграммы.
Откройте файл studium.sav, содержащий данные опроса студентов.
Мы хотим отобразить в графическом виде распределение частот, отражающих психологическое состояние студентов (переменная psyche), отдельно для каждого пола (переменная sex).
В диалоговом окне Bar Charts (Столбчатые диаграммы) щёлкните на области Stacked (Состыкованная) и активируйте опцию, устанавливаемую по умолчанию, Summaries for groups of cases (Обработка категорий одной переменной). Щелчком по кнопке Define (Определить) откройте соответствующее диалоговое окно.
В поле Category Axis: (Ось категорий) введите переменную psyche, а в поле Define Stacks by: (Создать штабели при помощи:) введите переменную sex. Оставьте установку по умолчанию N of cases (Количество наблюдений).
Пройдя выключатель Titles... (Заголовок), введите подходящий заголовок.
В данном примере имеются пропущенные значения, которые в соответствии с установками по умолчанию будут обрабатываться как отдельные категории.
Для того, чтобы запретить это действие щёлкните на выключателе Options... (Параметры) и уберите отметку для опции Display groups defined by missing values (Пропущенные значения отображать как категории).
Вернувшись в диалоговое окно Define Stacked Bar: Summaries for groups of cases (Построение состыкованной диаграммы: Обработка категорий одной переменной) щелчком на ОК начните построение диаграммы (см. рис. 22.11).
В следующем примере рассматривается графическое представление уже имеющихся (готовых) данных. Приведенная ниже таблица содержит показатели рождаемости в западных и восточных землях Германии, начиная с 1985 по 1992 год:
Столбчатые диаграммы
22.1 Столбчатые диаграммы
Столбчатые диаграммы применяются, как правило, в следующих ситуациях:
Отображение частот переменных, относящихся к номинальной или порядковой шкале
Простые линейчатые диаграммы
22.2.1 Простые линейчатые диаграммы
В файле buecher.sav хранится информация о развитии книгопечатания в Германии с 1962 по 1991 год.
Откройте файл buecher.sav и просмотрите его содержимое в редакторе данных.
В диалоговом окне Line Charts (Линейчатые диаграммы) щёлкните на области Simple (Простая) и оставьте, опцию Summaries for groups of cases (Обработка категорий одной переменной), устанавливаемую по умолчанию.
После щелчка по выключателю Define (Определить) откроется соответствующее диалоговое окно.
В поле Category Axis: (Ось категорий) введите переменную jahr (год). В группе Line Represent (Значения линий) активируйте Other summary function (Другая обрабатывающая функция) и в появившееся поле введите переменную anz (количество). Вместо установленной по умолчанию функции Mean of values (Средние значения), пройдя выключатель Change Summary...(Изменить метод обработки), отметьте функцию суммы значений (Sum of values) (которая в данном случае, правда, дает тот же эффект).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок.
Начните построение диаграммы щелчком на ОК.
Сложные линейчатые диаграммы
22.2.2 Сложные линейчатые диаграммы
Следующая таблица демонстрирует тенденцию нарушения законов по охране окружающей среды в Западной Германии с 1985 по 1992 год:
| Гол | Нарушения | ||
| UA | CV | UB | |
| 1985 | 2.750 | 8.562 | 901 |
| 1986 | 3.682 | 9.294 | 1.161 |
| 1987 | 5.390 | 10.529 | 1.311 |
| 1988 | 6.748 | 1 1 .968 | 1.671 |
| 1989 | 8.559 | 1 1 .827 | 1.590 |
| 1990 | 8.157 | 9.942 | 1.525 |
| 1991 | 9.724 | 9.601 | 1.457 |
| 1992 | 12.453 | 8.687 | 1.573 |
Где
UA — Переработка мусора, наносящая вред окружающей среде
GV — Загрязнение воды
UB — Использование запрещённого промышленного оборудования
Эти данные построчно сохранены в переменных jahr (год), ua, gv и ub в файле umwelt.sav.
Откройте файл umwelt.sav и просмотрите его содержимое в редакторе данных.
В диалоговом окне Line Charts (Линейчатые диаграммы) щёлкните на области Multiple (Сложная) и активируйте опцию Summaries of separate variables (Обработка отдельных переменных).
После щелчка по выключателю Define (Определить) откроется соответствующее диалоговое окно (см. рис. 22.19).
В поле Category Axis: (Ось категорий) введите переменную jahr. В поле Line Represent (Значения линий) по очереди введите переменные ua, gv и ub; вместо установленной по умолчанию функции Mean of values (Средние значения), с помощью выключателя Change Summary...(Изменить метод обработки), отметьте функцию суммы значений (Sum of values).
После щелчка по выключателю Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Связанные линейчатые диаграммы
22.2.3 Связанные линейчатые диаграммы
Это разновидность сложной линейчатой диаграммы, в котором точки данных обозначены разными символами и соединены вертикальной связью.
Воспользуйтесь примером из предыдущего раздела и в диалоговом окне Line Charts (Линейчатые диаграммы) щёлкните на области Drop-line (Связанные линии).
Во всём остальном поступите так же, как и в предыдущем разделе.
Линейчатые диаграммы
22.2 Линейчатые диаграммы
Линейчатую диаграмму вместо столбчатой следует выбирать тогда, когда необходимо отобразить большое количество столбцов, а также тогда, когда столбцы располагаются в определённой последовательности. Как правило, это временная последовательность.
Простая диаграмма с областями
22.3.1 Простая диаграмма с областями
Следующая таблица содержит информацию о производстве велосипедов с 1986 по 1992 год. Производственные показатели разбиты дополнительно на сбыт внутри страны и экспорт.
| Год | Штук (млн.) | ||
| Производство | Внутри страны | Экспорт | |
| 1986 | 4,00 | 3,14 | 0,86 |
| 1987 | 3,74 | 3,01 | 0,73 |
| 1988 | 3,88 | 3,14 | 0,74 |
| 1989 | 4,40 | 3,67 | 0,73 |
| 1990 | 4,81 | 4,08 | 0,73 |
| 1991 | 4,91 | 4,35 | 0,56 |
| 1992 | 4,55 | 4,10 | 0,45 |
Эти данные построчно сохранены в переменных jahr (год), gesamt (общий объем производства), inland (внутри страны) и export (экспорт) в файле fahrrad.sav.
Откройте файл fahrrad.sav и просмотрите его содержимое в окне редактора данных.
Сначала данные о совокупном производстве представим в виде простой диаграммы с областями.
В диалоговом окне Area Charts (Диаграммы с областями) щёлкните на области Simple (Простая) и оставьте опцию Summaries for groups of cases (Обработка категорий одной переменной), устанавливаемую по умолчанию.
После щелчка по выключателю Define (Определить) откроется главное диалоговое окно (см. рис. 22.23).
В поле Category Axis: (Ось категорий) введите переменную jahr и в группе Area Represents (Значения областей) установите маркер возле Other summary function (Другая обрабатывающая функция). В появившееся поле введите переменную gesamt и оставьте функцию Mean of values (Средние значения), устанавливаемую по умолчанию.
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Состыкованные диаграммы с областями
22.3.2 Состыкованные диаграммы с областями
Этот вид диаграмм следует применять только тогда, когда штабелируемые области дают не лишенный смысла эффект суммирования. Мы ещё раз обратимся к примеру, рассмотренному в предыдущем разделе, но теперь совокупную производительность разделим на продукцию, реализуемую внутри страны и экспорт.
В диалоговом окне Area Charts (Диаграммы с областями) щёлкните на области Stacked (Состыкованная) и отметьте опцию Summaries of separate variables (Обработка отдельных переменных).
После щелчка по выключателю Define (Определить) откроется соответствующее диалоговое окно.
В поле Category Axis: (Ось категорий) введите переменную jahr, а в поле Areas Represent (Значения областей) введите обе переменные inland и export и оставьте функцию Sum of values (Сумма значений), устанавливаемую по умолчанию.
Минуя выключатель Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Диаграммы с областями
22.3 Диаграммы с областями
Диаграммы с областями являются разновидностью линейчатой диаграммы, в которой области, находящиеся под линиями, закрашиваются благодаря чему график выглядит более наглядным.
Для построения диаграммы с областями, после открытия необходимого файла SPSS, выберите в меню Graphs (Графики) Area... (С областями)
Откроется диалоговое окно Area Charts (Диаграммы с областями) Вы можете построить простую или состыкованную диаграмму с областями. И здесь данные, отображаемые в этих диаграммах, могут быть заданы как категории одной переменной, как разные переменные или как значения отдельных наблюдений.
Круговые диаграммы
22.4 Круговые диаграммы
Представление данных в виде круговых диаграмм стоит выбирать тогда, когда частоты или значения переменных можно, не нарушая здравого смысла, сложить вместе и эта сумма будет соответствовать ста процентам.
Отобразим при помощи круговой диаграммы частоты категорий переменной psyche (психологическое состояние студентов) из файла studium.sav.
Откройте файл studium.sav и выберите в меню Graphs (Графики) Pie... (Круговые) Откроется диалоговое окно Pie Charts (Круговые диаграммы).
Оставьте опцию Summaries for groups of cases (Обработка категорий одной переменной), установленную по умолчанию и щелчком на кнопке Define (Определить) откройте следующее диалоговое окно.
Простые биржевые диаграммы - потолок-пол-закрытие
22.5.1 Простые биржевые диаграммы - потолок-пол-закрытие
Предположите, что вы располагаете некоторыми акциями и фиксировали их котировки в течение десяти дней:
Кластеризованные диаграммы - максимум-минимум-закрытие
22.5.2 Кластеризованные диаграммы - максимум-минимум-закрытие
При помощи этого метода осуществляется возможность представить несколько процессов потолок-пол-закрытие в одной диаграмме. Для реализации этой возможности в диалоговом окне High-Low Charts (Диаграммы максимума-минимума) щёлкните на области Clustered high-low-close (Кластеризованная диаграмма — максимум-минимум-закрытие).
Линейчатые диаграммы разностей
22.5.3 Линейчатые диаграммы разностей
При помощи этой диаграммы может быть представлено взаимное изменение значений двух переменных, причём обе результирующие кривые могут пересекаться. Это пересечение как раз и может быть очень наглядно представлено с помощью линейчатых диаграмм разностей.
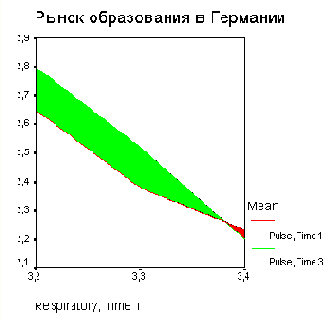
Нижеследующая таблица содержит данные о развитии рынка образования в Германии с 1985 по 1992 год.
|
Год |
Количество учебных мест | |
| Предложение | Спрос | |
|
1985 |
719.110 |
755.994 |
|
1986 |
715.880 |
730.980 |
|
1987 |
690.287 |
679.622 |
|
1988 |
665.964 |
628.793 |
|
1989 |
668.649 |
602.014 |
|
1990 |
659.435 |
559.531 |
|
1991 |
668.000 |
550.671 |
|
1992 |
721.756 |
608.121 |
Откройте файл lehre.sav, в котором в переменными jahr (год), angeb (предложение) и nachf (спрос) хранятся необходимые нам данные.
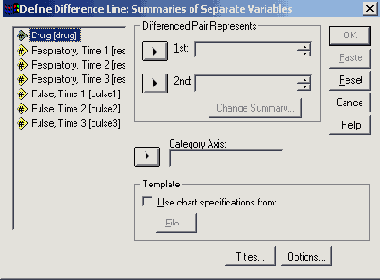
В диалоговом окне High-Low Charts (Диаграммы максимума-минимума) щёлкните на области Difference Line (Линия разностей). Установите метку возле опции Summaries of separate variables (Обработка отдельных переменных).
Нажатием выключателя Define (Определить) откройте следующее диалоговое окно (см. рис. 22.34).
В поле Category Axis: (Ось категорий) введите переменную jahr и в группе Differenced Pair Represents (Значения разностных пар) в поля 1 и 2 введите переменные angeb и nachf. Активируйте функцию суммы (Sum of values) с помощью кнопки Change Summary (Сменить процедуру обработки).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок.
Начните построение диаграммы щелчком на ОК.
Простые интервальные столбцы
22.5.4 Простые интервальные столбцы
Этот вид диаграммы является разновидностью простой диаграммы — потолок-пол-закрытие, в которой, однако, отображается только максимальное и минимальное значения, а окончательное отсутствует.
В качестве примера рассмотрим ситуацию, когда Вы, предположим, на протяжении десяти дней фиксировали свою максимальную и минимальную температуры:
| День | Температура(°С) | |
| Минимум | Максимум | |
| 14 марта 1994 | 2,4 | 11,3 |
| 15 марта 1994 | 2,6 | 11,5 |
| 16 марта 1994 | 3,7 | 12,4 |
| 17 марта 1994 | 6,2 | 14,8 |
| 18 марта 1994 | 6,2 | 14,8 |
| 19 марта 1994 | 1,9 | 9,7 |
| 20 марта 1994 | 4,3 | 11,3 |
| 21 марта 1994 | 7,6 | 13,4 |
| 22 марта 1994 | 7,0 | 12,9 |
| 23 марта 1994 | 6,3 | 11,0 |
Эти данные построчно сохранены в трёх переменных (tag (день), train (минимальная температура), tmax (максимальная температура)) в файле celsius.sav.
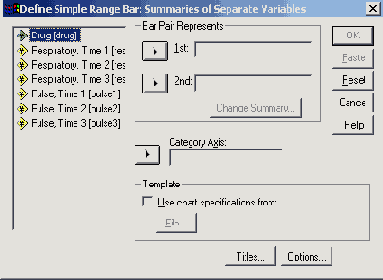
Откройте файл celsius.sav и в диалоговом окне High-Low Charts (Диаграммы максимума-минимума) щёлкните на области Simple range bar (Простые интервальные столбцы).
Установите метку возле опции Summaries of separate variables (Обработка отдельных переменных).
Нажатием выключателя Define (Определить) откройте следующее диалоговое окно (см. рис. 22.36).
В поле Category Axis: (Ось категорий) введите переменную tag и в группе Bar Pair Represents (Значения пары столбцов) введите переменные tmin и tmax в поля 1 и
2. Установленную по умолчанию функцию Mean of values (Средние значения) можете оставить.
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Кластеризованные интервальные столбцы
22.5.5 Кластеризованные интервальные столбцы
В одной диаграмме при помощи интервальных столбцов могут быть представлены и изменения нескольких переменных.
Для этого в диалоговом окне High-Low Charts (Диаграммы максимума-минимума) щёлкните на области Clustered range bar (Кластеризованные интервальные столбцы).
Диаграммы максимальных и минимальных значений
22.5 Диаграммы максимальных и минимальных значений
Если вы посмотрите на поведение биржевых котировок акций, то заметите, что для фиксированного промежутка времени, к примеру, для одного дня, существует три важнейших характеристики: максимальное и минимальное значения, а также значение в конце промежутка, при закрытии биржи. Такой и подобные ему процессы могут быть представлены при помощи диаграммы максимальных и минимальных значений, которая на биржевом сленге иногда называется потолок-пол-закрытие.
После открытия необходимого Вам файла SPSS выберите в меню Graphs (Графики) High-Low... (Максимум-минимум)
После этого откроется соответствующее диалоговое окно.
Существует пять видов диаграмм максимума-минимума, данные для которых, как и для предыдущих графиков, могут интерпретироваться тремя различными способами.
Простые коробчатые диаграммы
22.6.1 Простые коробчатые диаграммы
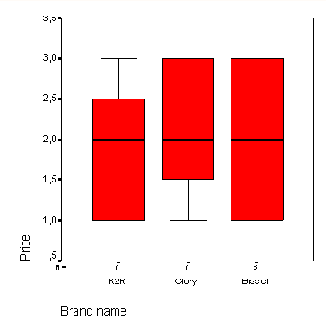
В рамках исследования гипертонии (файл hyper.sav) мы хотим для четырёх разных возрастных категорий (переменная ak) отобразить исходные показатели систолического кровяного давления (переменная rrs0).
Откройте файл hyper.sav.
В диалоговом окне Boxplot (Коробчатая диаграмма) щёлкните на области Simple (Простая) и оставьте опцию Summaries for groups of cases (Обработка категорий одной переменной), устанавливаемую по умолчанию.
Щелчком по выключателю Define (Определить) откройте главное диалоговое окно, в котором в поле Category Axis: (Ось категорий) введите переменную ak, а в поле Variable: (Переменная) переменную rrs0. Если Вы введёте какую-либо переменную в поле Label Cases by: (Метки наблюдений), то её метки значений будут использованы для обозначения пропущенных и экстремальных значений.
Начните построение диаграммы щелчком на ОК (см. рис. 22.39).
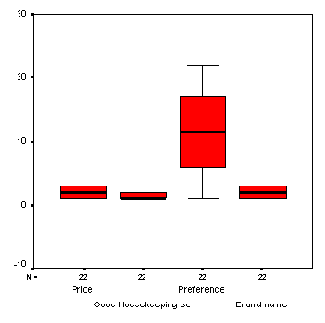
Если необходимо отобразить изменение систолического давления с течением времени, то для этого следует выбрать переменные rrs0, rrs1, rrs6 и rrs12.
Щёлкните вновь на области Simple (Простая), но теперь поставьте маркер возле опции Summaries of separate variables (Обработка отдельных переменных).
Щелчком по выключателю Define (Определить) откройте следующее диалоговое окно, в котором в поле Boxes Represent (Значения коробок) по очереди введите переменные rrs0, rrs1, rrs6 и rrs12.
Вновь начните построение диаграммы щелчком на ОК (см. рис. 22.40).
На этой диаграмме метки отображаются не полностью, поэтому их ещё необходимо доработать.
Кластеризованные коробчатые диаграммы
22.6.2 Кластеризованные коробчатые диаграммы
Вы можете использовать в данной диаграмме ещё одну переменную, тогда коробчатые диаграммы будут сгруппированы по категориям этой переменной.
Для этого в диалоговом окне Boxplot (Коробчатая диаграмма) щёлкните на области Clustered (Кластеризованная).
Коробчатые диаграммы
22.6 Коробчатые диаграммы
Метод, при помощи которого, можно отобразить медиану и оба квартиля, минимальные и максимальные значения, а также пропущенные и экстремальные значения, уже рассматривался в главе 10.4.1. Эти диаграммы могут быть построены в ходе предварительного исследования данных или через меню графиков.
После открытия необходимого Вам файла SPSS выберите в меню Graphs (Графики) Boxplot... (Коробчатые диаграммы) Откроется диалоговое окно Boxplot (Коробчатая диаграмма) (см. рис. 22.38).
Вы можете выбрать простую или.кластеризованную диаграмму, причём данные могут быть представлены в виде категорий одной переменной или в виде разных переменных.
Простая диаграмма величины ошибки
22.7.1 Простая диаграмма величины ошибки
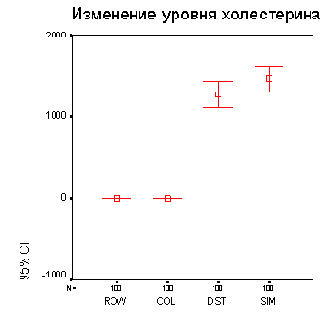
В рамках исследования гипертонии (файл hyper.sav) для четырёх разных возрастных категорий (переменная ak) мы хотим отобразить исходные показатели уровня холестерина (переменная chol0).
Откройте файл hyper.sav.
В диалоговом окне Error Bar (Столбики ошибок) щёлкните на области Simple (Простая) и оставьте опцию Summaries for groups of cases (Обработка категорий одной переменной), устанавливаемую по умолчанию.
Щелчком по выключателю Define (Определить) откройте соответствующее диалоговое окно (см. рис. 22.42).
В поле Category Axis: (Ось категорий) введите переменную ak, а в поле Variable: (Переменная) переменную chol0.
В группе Bars Represent (Значения столбцов) Вам предлагаются на выбор следующие варианты:
Доверительный интервал для среднего значения (по умолчанию равен 95 %)
Кластеризованная величина ошибки
22.7.2 Кластеризованная величина ошибки
Диаграммы величины ошибки можно объединять в группы при помощи дополнительных переменных.
Для этого в диалоговом окне Error Bar (Величина ошибки) щёлкните на области Clustered (Кластеризованная).
Столбики ошибок
22.7 Столбики ошибок
Если при помощи коробчатой диаграммы представляются медиана и оба квартиля, то диаграмма столбцов по величинам ошибки служит для отображения средних значений и характеристик рассеяния (стандартное отклонение, стандартная ошибка или доверительный интервал — по выбору).
После открытия необходимого Вам файла SPSS выберите в меню Graphs (Графики) Error Bar... (Столбики ошибок)
Откроется диалоговое окно Error Bar (Столбики ошибок).
Также как и для коробчатых диаграмм, Вы можете выбрать простую или кластеризованную диаграмму столбцов по величинам ошибки, причём данные могут быть представлены в виде отдельных категорий одной переменной или в виде разных переменных.
Простая диаграмма рассеяния
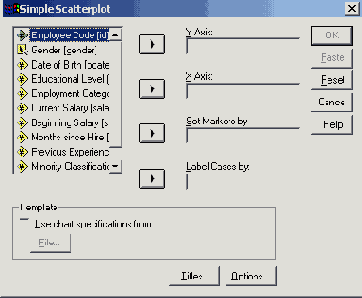
22.8.1 Простая диаграмма рассеяния
Откроите файл europa.sav.
В диалоговом окне Scatterplot (Диаграмма рассеяния) щёлкните на области Simple (Простая).
Щелчком по выключателю Define (Определить) откройте соответствующее диалоговое окно (см. рис. 22.46).
Мы хотим отобразить ожидаемую продолжительность жизни мужчин (переменная lem) в зависимости от урбанизации (процентного показателя доли городского населения, переменная sb).
Переменную lem из списка исходных переменных перенесите в поле оси Y, а переменную sb — в поле оси X.
Если Вы поместите какую-нибудь переменную в поле Set Markers by: (Установить маркеры для:), то согласно принадлежности к этой переменной отдельные точки значений на диаграмме будут представлены окрашенными в другой цвет или помечены при помощи какого-либо отличительного маркировочного символа.
Поместите переменную land в поле, предусмотренное для описания наблюдений (Label Cases by: (Метки наблюдений)). Значение этой переменной, соответствующее в приведенном примере сокращённому названию страны, будет размещено в диаграмме рассеяния вблизи соответствующей точки данных.
Матричные диаграммы рассеяния
22.8.2 Матричные диаграммы рассеяния
Этот метод применяется для отображения нескольких диаграмм рассеяния на одном графике.
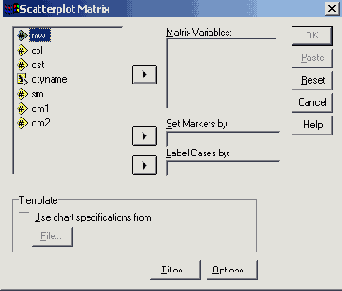
В диалоговом окне Scatterplot (Диаграмма рассеяния) щёлкните на области Matrix (Матрица).
Щелчком на выключателе Define (Определить) откройте соответствующее диалоговое окно.
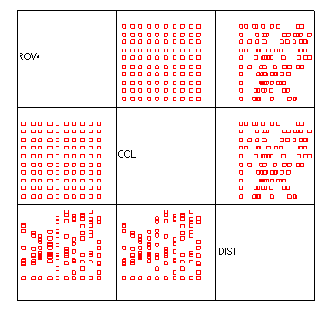
Переменные lem (ожидаемая продолжительность жизни мужчин), so (количество часов солнечной погоды в году) и nt (количество пасмурных дней в году) мы хотим попарно связать друг с другом.
Для этого переменные lem, so и nt поочерёдно перенесите в поле, предусмотренное для матричных переменных.
Начните построение диаграммы щелчком на ОК.
Число строк и столбцов в матричной диаграмме соответствует количеству переменных. Каждая ячейка является диаграммой рассеяния для одной пары переменных. Диагональные ячейки содержат метки переменных, находящихся в соответствующих ячейках матрицы (в данном примере метки являются слишком длинными).
Наложенные диаграммы рассеяния
22.8.3 Наложенные диаграммы рассеяния
В одном графике можно представить несколько диаграмм рассеяния.
Для этого в диалоговом окне Scatterplot (Диаграмма рассеяния) щёлкните на области Overlay (Наложение) и затем на кнопке Define (Определить).
В появившемся диалоговом окне могут быть заданы соответствующие X-Y-пары переменных, которые должны быть представлены вместе. Значения, принадлежащие соответствующей паре, на диаграмме будут отмечены одной определённой маркировкой.
Этот метод имеет смысл применять только тогда, когда речь идёт о переменных с одними и теми же областями значений.
Трёхмерные диаграммы рассеяния
22.8.4 Трёхмерные диаграммы рассеяния
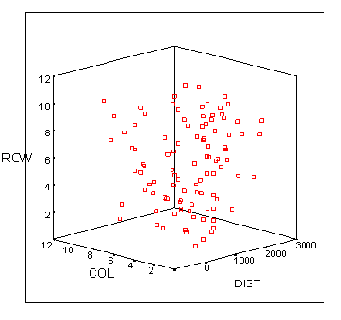
Эти диаграммы строятся на основании значений трёх переменных и поэтому включают три оси.
По оси у откладывается высоту положения точки
По оси х откладывается горизонтальное положение каждой точки
По оси z откладывается глубина положения каждой точки.
Отобразим переменную lem (средняя ожидаемая продолжительность жизни мужчин) на оси у, переменную sb (процентный показатель городского населения) на оси х и переменную so (количество часов солнечной погоды в году) на оси г.
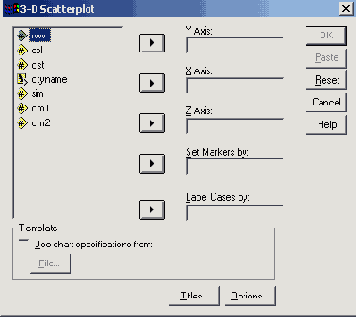
В диалоговом окне Scatterplot (Диаграмма рассеяния) щёлкните на области 3D (3-х мерная).
Щелчком по выключателю Define (Определить) откройте соответствующее диалоговое окно (см. рис. 22.51).
Перенесите поочерёдно переменные lem, sb и so из списка исходных переменных в поля принадлежащие осям у, х и z-
Начните построение диаграммы щелчком на ОК.
Диаграмма рассеяния
22.8 Диаграмма рассеяния
Диаграмма рассеяния в графическом виде отображает отношения между двумя переменными, которые как минимум относятся к интервальной шкале. Пример диаграммы рассеяния уже был представлен в главе 15.
Чтобы построить диаграмму рассеяния, после открытия необходимого Вам файла SPSS выберите в меню Graphs (Графики) Scatter... (Рассеяние)
Откроется диалоговое окно Scatterplot (Диаграмма рассеяния).
Имеются различные возможности построения диаграмм рассеяния. Для нижеследующих примеров взят файл europa.sav (можно сравнить с гл. 20), который содержит данные некоторых признаков для 28 европейских стран.
Гистограммы
22.9 Гистограммы
Гистограмма уже несколько раз рассматривалась в предыдущих главах.
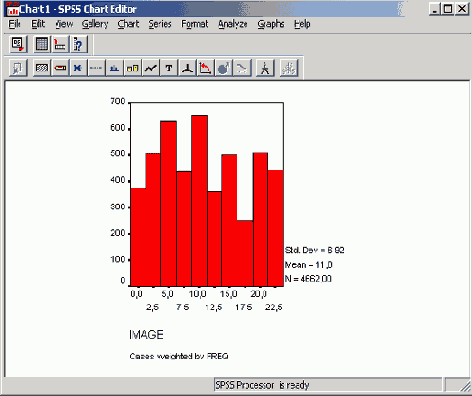
Чтобы построить гистограмму, после открытия необходимого Вам файла SPSS (к примеру, файла hyper.sav), выберите в меню Graphs (Графики) Histogram... (Гистограмма)
Откроется диалоговое окно Histogram (Гистограмма) (см. рис. 22.53).
С помощью гистограммы можно наглядно отобразить распределение переменных, относящихся по меньшей мере к интервальной шкале.
Откройте файл hyper.sav.
Поместите переменную chol0 в поле переменных и активируйте вывод кривой нормального распределения.
Начните построение гистограммы щелчком на ОК.
Диаграммы Парето
22.10 Диаграммы Парето
Диаграмма Парето представляет собой столбчатую диаграмму, в которой столбцы располагаются в порядке убывания, а дополнительная кривая может указывать на совокупную частоту для представленных категорий. При этом при суммировании отдельных столбцов по заданному правилу должна получаться некоторая итоговая величина, имеющая определенный смысл.
Чтобы построить диаграмму Парето, после открытия необходимого Вам файла SPSS, выберите в меню Graphs (Графики) Pareto... (Парето)
Откроется соответствующее диалоговое окно.
Вы можете построить простую или состыкованную диаграмму Парето, причём и здесь существует три варианта представления данных.
Для иллюстрации процесса построения этих диаграмм достаточно одного примера. В следующей таблице приведены данные текущих расходов семей западной Германии в 1992 году.
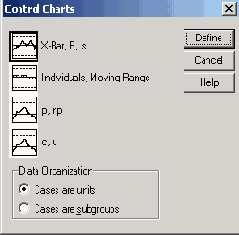
Контрольные карты
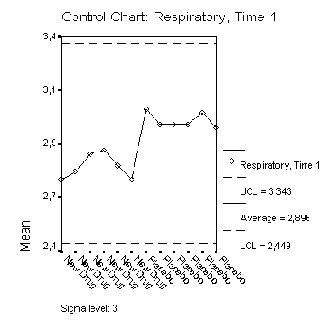
22.11 Контрольные карты
С помощью построения контрольных карт при наличии временной зависимости Вы можете проверить, лежат ли средние значения переменных в пределах области рассеяния, объясняемой действием случайных факторов, или же они выходят за пределы этой области. В общем случае подразделение данных может происходить не только по временным интервалам, а и посредством других подгрупп.
После открытия необходимого Вам файла SPSS выберите в меню Graphs (Графики) Control... (Контроль)
Откроется диалоговое окно Control Charts (Контрольные карты).
Диаграммы нормального распределения
22.12 Диаграммы нормального распределения
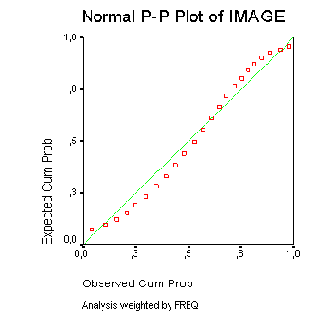
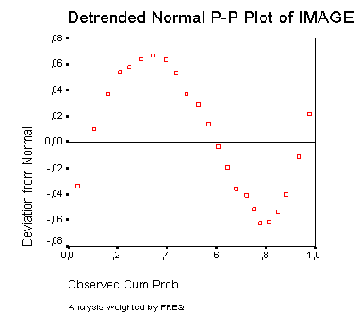
При проведении практически всех статистических тестов важную роль играет вопрос, подчиняются ли анализируемые данные нормальному распределению (для сравнения см. разд. 5.1.2). Проверку нормального распределения можно производить визуально, при помощи гистограммы (для пояснения см. разд. 22.9), однако лучше это осуществлять с использованием специального статистического теста, к примеру, теста Колмогорова-Смирнова (для получения подробной информации см. разд. 14.5). Ещё одну возможность анализа нормального распределения предоставляют диаграммы нормального распределения, которые в SPSS подразделяются на два вида:
Р-Р- нормальный вероятностный график
Q-Q-нормальный вероятностный график
В первом случае (Р-Р) в форме диаграммы рассеяния на графике отображается зависимость ожидаемых совокупных частот от фактических совокупных частот, а во втором случае (Q-Q) зависимость ожидаемой частоты от наблюдаемой частоты.
Построение диаграмм нормального распределения типа Q-Q можно производить и в рамках предварительного исследования данных. В таком варианте они уже были рассмотрены ранее (для получения подробной информации см. разд. 10.4.1). Поэтому здесь мы приведём пример, касающийся только диаграммы нормального распределения типа Р-Р.
Откройте файл hyper.sav и выберите в меню Graphs (Графики) Р-Р... (Р-Р-диаграммы) Откроется диалоговое окно Р-Р Plots (Р-Р-диаграммы).
Кривые ROC
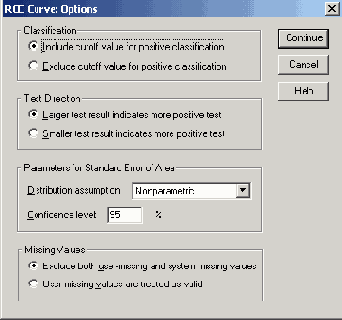
22.13 Кривые ROC
Понятие кривых ROC (Receiver Operating Characteristic — функциональные характеристики приемника) взято из методологии анализа качества приёма сигнала (Signal Detection Analysis). Теория, стоящая за этим анализом, Theorie of Signal Detectability (TSD — "Теория определимости сигнала"), хотя и происходит первоначально из электроники и электротехники, но может также быть применена в области медицины, для анализа взаимодействия чувствительности и представительности диагностического теста. Поясним это при помощи примера.
В разделе 16.4 (Бинарная логистическая регрессия) было показано, каким образом при помощи переменных, соответствующих результатам Т-типизации клеток, которые относятся к интервальной шкале, может быть спрогнозировано появление карциномы мочевого пузыря. Если вы посмотрите на обе группы (больных и здоровых), то заметите, что здоровые демонстрируют более высокие значения Т-типизации ячеек, а больные скорее более низкие значения. Поэтому можно попытаться найти граничное значение Т-типизации ячеек, которое будет чётко разделять обе группы больных и здоровых.
Это и было достигнуто при помощи метода бинарной логистической регрессии. Пройдём ещё раз тот путь, который мы проходили в главе 16.4.
Откройте файл hkarz.sav.
Выберите в меню Analyze... (Анализ) Regression. ..(Регрессия) Binary logistic... (Бинарная логистическая)
В диалоговом окне Logistic Regression (Логистическая регрессия) переменную gruppe (группа) поместите в поле зависимых переменных, а переменную tzell — в поле ковариций. Результаты теста LAI мы сначала не будем использовать в расчёте. При помощи выключателя Save... (Сохранить) организуйте сохранение прогнозируемой принадлежности к группе в виде дополнительной переменной. Начните расчёт нажатием ОК.
К исходному файлу данных добавилась переменная pgr_1. Если Вы построите таблицу сопряженности между переменной gruppe (группа) в качестве строчной переменной и переменной pgr_1 в качестве столбцовой переменной, то получите следующий результат (для сравнения см. рис. 16.7):
GRUPPE * Predicted group Crosstabulation
| (GRUPPE * Прогнозируемая группа таблица сопряженности) | ||||
| Count (Количество) | ||||
| Predicted group (Прогнозируемая группа) | Total (Сумма) | |||
| krank (Болен) | gesund (Здоров) | |||
| GRUPPE | krank (Болен) | 18 | 6 | 24 |
| gesund (Здоров) | 4 | 17 | 21 | |
| Total (Сумма) | 22 | 23 | 45 |
Среди 24 фактически больных 18 были верно расценены как больные (Rightly Positive (Верно положительный), RP), а 6 не верно отнесены к группе здоровых (Wrong Negative (Ложно отрицательный), WN). Из 21 фактически здорового человека 17 были верно отнесены к группе здоровых (Rightly Negative (Верно отрицательный), RN) и 4 не верно расценены больными (Wrong Positive (Ложно положительный), WP).
В качестве чувствительности теста выступает доля верно положительных предсказаний в суммарном количестве больных.
Временные диаграммы и графики последовательностей
22.14 Временные диаграммы и графики последовательностей
Посторонние временных рядов и графиков последовательностей происходит посредством выбора меню Graphs (Графики) Time Series... (Временной ряд) и Graphs (Графики) Sequence... (Последовательность)
соответственно. В связи с тем, что в модулях SPSS, рассматриваемых в этой книге, отсутствует анализ временных рядов, мы не будем подробно останавливаться на этой диаграмме. Информацию по этому вопросу Вы можете найти в книге этих же авторов: 'SPSS. Методы исследования рынка и мнений".
Основы редактирования графиков
22.15 Основы редактирования графиков
Для того, чтобы разобраться во всех возможностях, которые SPSS для Windows предоставляет для редактирования графиков, наверняка потребуется некоторое время.
Построение графиков происходит при помощи большого количества процедур меню статистик и из меню графиков. Все графики, построенные таким образом, попадают сразу в окно просмотра. Отсутствует промежуточное сохранение, существовавшее вплоть до 6-ой версии SPSS.
Даже при построении Ваших первых графиков (теперь в SPSS они, как правило, называются диаграммами) можно не беспокоиться об их внешнем виде, поскольку в силу вступают соответствующие установки по умолчанию. Если Вы к тому же добавили некоторые наименования (заголовок, подзаголовок, сноски), то такой вид уже будет вполне достаточен для того, чтобы графики можно было использовать в большинстве практических ситуаций.
Если Вы хотите придать графикам более наглядный и презентабельный вид или же существует необходимость произвести определённые корректировки (к примеру, если метки переменных слишком длинны), то график следует перенести в редактор диаграмм. Для этого в окне просмотра дважды щёлкните в любом месте в области диаграммы.
В редакторе диаграмм Вы сможете производить над графиком следующие действия:
корректировать (или изменить)
сохранить график в каком-либо другом графическом формате
сохранить как образец для других графиков и
копировать в буфер обмена Windows.
Обзор всего многообразия возможностей дополнительной обработки, которые предлагает Вам редактор диаграмм, приводится в разделе 22.16. В разделе 22.17 рассматриваются три типичных примера редактирования.
Редактор диаграмм
22.16 Редактор диаграмм
Для того, чтобы график можно было изменить (доработать, редактировать), он должен быть помещён в редактор диаграмм. Это происходит после двойного щелчка на какой-либо точке в области диаграммы, находящейся в окне просмотра. Тогда редактор диаграмм будет выглядеть так, как на рис. 22.67.
В верху редактора диаграмм присутствуют меню и две панели инструментов. Если Вы пройдётесь курсором по кнопкам панелей инструментов, не нажимая их, то сможете увидеть краткое описание кнопок. При помощи кнопок верхней панели инструментов, Вы можете получить информацию о диалоговых полях, которые Вы заполняли в последних построенных диаграммах, перейти в редактор данных, в нём перейти к нужному Вам наблюдению; а также получить информацию об отдельных переменных.
Кнопки, стоящие во второй панели инструментов, преимущественно служат для вызова форматирующих меню и будут рассмотрены в соответствующем разделе. Статистические, графические меню и меню помощи уже известны, и поэтому здесь они рассматриваться не будут.
Пример первый: изменение наименования осей
22.17.1 Пример первый: изменение наименования осей
Откройте в окне просмотра результатов файл balken.spo, в котором хранится график, изображённый на рис. 22.43.
Здесь необходимо изменить наименование вертикальной оси.
Двойным щелком перенесите график в редактор диаграмм и щелчком выделите наименование вертикальной оси.
После этого выберите в меню Chart (Диаграмма) Axis... (Ось)
В появляющемся окне Вам предлагается множество разнообразных возможностей редактирования оси.
Измените название оси на "Холестерин, исходный показатель" и покиньте диалоговое окно нажатием ОК.
В результате Вы увидите отредактированный график, который после закрытия редактора диаграмм будет отображён и в окне просмотра результатов.
Пример второй: редактирование круговой диаграммы
22.17.2 Пример второй: редактирование круговой диаграммы
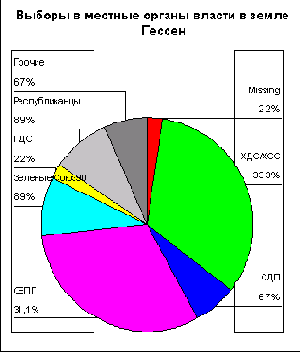
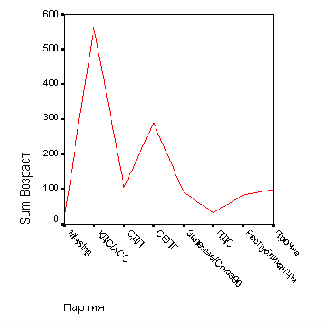
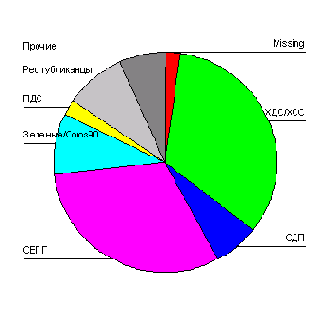
Откройте файл kreis.spo, в котором хранится круговая диаграмма, представленная на рис. 22.30. Эта диаграмма пока ещё не показывает результаты голосования в процентах.
Двойным щелком перенесите график в редактор диаграмм.
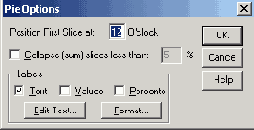
Щёлкните дважды на названии одной из представленных партий (к примеру, SPD или CDU).
Откроется диалоговое окно Pie Options (Параметры круговой диаграммы) (см. рис. 22.69).
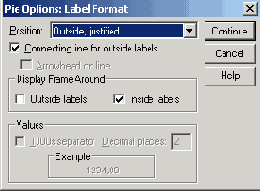
Поставьте маркер в поле Percents (Проценты) и щёлкните на кнопке Format... (Формат).
Откроется диалоговое окно Pie Options: Label Format (Параметры круговой диаграммы: Формат метки), представленное на рисунке 22.70.
Здесь Вам предоставляется возможность указать место нахождения численного значения переменной.
В группе Display Frame Around (Показать круговую рамку) активируйте опцию Outside labels (Метка снаружи).
Подтвердите нажатием Continue (Далее) и затем на ОК. Вы получите диаграмму, изображённую на рисунке 22.71.
Пример третий: нанесение регрессионных линий
22.17.3 Пример третий: нанесение регрессионных линий
В окне просмотра результатов откройте файл streumat.spo, в котором находится матричная диаграмма рассеяния, изображённая на рис. 22.50, и двойным щелком перенесите её в редактор диаграмм.
В списке меню редактора диаграмм выберите Chart (Диаграмма) Options... (Параметры)
Примеры редактирования графиков
22.17 Примеры редактирования графиков
Некоторые примеры редактирования графиков уже приводились в главах 4, 6 и 11. В этой главе мы рассмотрим ещё три дополнительных примера.
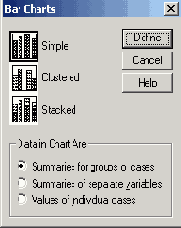
Диалоговое окно Bar Charts (Столбчатые диаграммы)
Диалоговое окно Bar Charts (Столбчатые диаграммы)
Диалоговое окно Define Simple...
Диалоговое окно Define Simple Bar: Summaries for groups of cases (Простая столбчатая диаграмма: Обработка категорий одной переменной)
Будет построен график, показанный на рисунке 22.4.
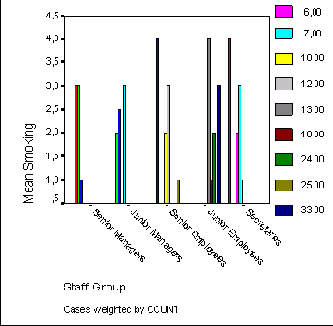
Теперь представим в графическом виде изменение среднего значения уровня сахара в крови (переменные bz0, bz1, bz6 и bz12), взятого из того же файла (hyper.sav).
В этот раз в диалоговом окне Ваг Charts (Столбчатые диаграммы) активируйте Summaries of separate variables (Обработка отдельных переменных); после нажатия выключателя Define (Определить) откроется соответствующее диалоговое окно (см. рис. 22.5).
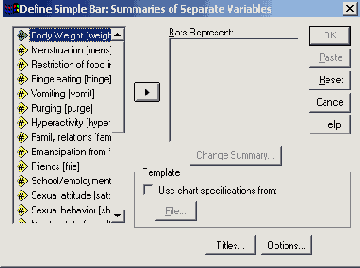
В поле Bars Represent (Значения столбцов) по очереди внесите переменные bz0, bz1, bz6 и bz12 и оставьте установленную по умолчанию функцию Mean of values (Средние значения).
Пройдя выключатель Titles... (Заголовок), введите заголовок диаграммы.
Щёлкните на ОК.
Диалоговое окно Define Simple...
Диалоговое окно Define Simple Bar: Summaries of separate variables (Построение простой столбчатой диаграммы: Обработка отдельных переменных)
Если Вы хотите выбрать функцию отличную от установленной по умолчанию Mean of values (Средние значения), щёлкните на одной из переменных в списке и затем на выключателе Change Summary...(Изменить метод обработки).
Откроется диалоговое окно с перечнем функций (см. рис. 22.7).
Это диалоговое окно появляется только для столбчатой, линейной, круговой диаграмм и диаграммы с областями, причём не каждая из находящихся здесь функций пригодна для всех видов диаграмм. Если для имеющихся данных Вы хотите отобразить медианы или другие процентили (сравните с гл. 6), то активируйте опцию Values are grouped midpoints (Значения являются сгруппированными средними точками).
В следующем примере рассматривается вопрос отображения готовых данных. Допустим, Вы взяли из некоторой газеты данные по 1993 году о добыче нефти в семи странах, входящих в ОРЕС и являющихся ведущими в этой отрасли.
Диалоговое окно Define Simple...
Диалоговое окно Define Simple Bar: Values of individual cases (Построение простой столбчатой диаграммы: Значения отдельных случаев)
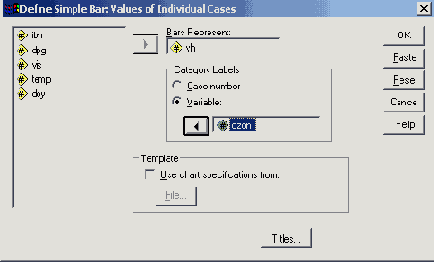
Пройдя выключатель Titles... (Заголовок), введите заголовок диаграммы и щёлкните на ОК.
График будет выглядеть так, как на рисунке 22.9.
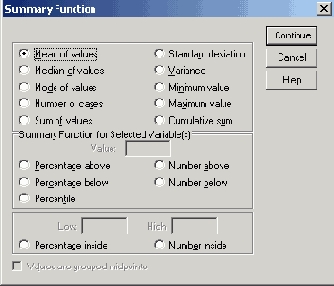
Диалоговое окно Summary Function (Обрабатывающая функция).
Диалоговое окно Summary Function (Обрабатывающая функция).
Стандартные графики
Глава 22. Стандартные графики
Стандартные графики 22.1 Столбчатые диаграммы 22.1.1 Простые столбчатые диаграммы 22.1.2 Кластеризованные столбчатые диаграммы 22.1.3 Состыкованные диаграммы 22.2 Линейчатые диаграммы 22.2.1 Простые линейчатые диаграммы 22.2.2 Сложные линейчатые диаграммы 22.2.3 Связанные линейчатые диаграммы 22.3 Диаграммы с областями 22.3.1 Простая диаграмма с областями 22.3.2 Состыкованные диаграммы с областями 22.4 Круговые диаграммы 22.5 Диаграммы максимальных и минимальных значений 22.5.1 Простые биржевые диаграммы — потолок-пол-закрытие 22.5.2 Кластеризованные диаграммы — максимум-минимум-закрытие 22.5.3 Линейчатые диаграммы разностей 22.5.4 Простые интервальные столбцы 22.5.5 Кластеризованные интервальные столбцы 22.6 Коробчатые диаграммы 22.6.1 Простые коробчатые диаграммы 22.6.2 Кластеризованные коробчатые диаграммы 22.7 Столбики ошибок 22.7.1 Простая диаграмма величины ошибки 22.7.2 Кластеризованная величина ошибки 22.8 Диаграмма рассеяния 22.8.1 Простая диаграмма рассеяния 22.8.2 Матричные диаграммы рассеяния 22.8.3 Наложенные диаграммы рассеяния 22.8.4 Трёхмерные диаграммы рассеяния 22.9 Гистограммы 22.10 Диаграммы Парето 22.11 Контрольные карты 22.12 Диаграммы нормального распределения 22.13 Кривые ROC 22.14 Временные диаграммы и графики последовательностей 22.15 Основы редактирования графиков 22.16 Редактор диаграмм 22.17 Примеры редактирования графиков 22.17.1 Пример первый: изменение наименования осей 22.17.2 Пример второй: редактирование круговой диаграммы 22.17.3 Пример третий: нанесение регрессионных линийМеню с вариантами графиков
Меню с вариантами графиков
Отображение средних значений, сумм или других показателей последовательных переменных (т.е. переменных, принадлежащих к интервальной шкале или к шкале отношений), отображение переменных, сгруппированных по категориям переменных с номинальной или порядковой шкалой или временной зависимости.
Для построения столбчатой диаграммы, после открытия соответствующего файла SPSS, выберите в меню Graphs (Графики) Ваг... (Столбчатые)
Откроется диалоговое окно Bar Charts (Столбчатые диаграммы) (см. рис. 22.2).
Вы можете выбрать между простой, кластеризованной (кластерной) и состыкованной столбчатыми диаграммами. Данные, отображаемые в этих диаграммах, могут быть заданы как категории одной переменной, как разные переменные или как значения отдельных наблюдений.
Простая столбчатая диаграмма (Категории одной переменной)
Простая столбчатая диаграмма (Категории одной переменной)
Будет построен график, приведенный на рисунке 22.6.
Следует отметить тот недостаток, что в этой диаграмме не полностью приведены метки значений и на вертикальной оси показана только ограниченная область от 103,5 до 106,0, из-за чего по ошибке можно сделать неверное заключение о сильном изменении уровня сахара. Вы можете подкорректировать эти ошибки в редакторе диаграмм.
Простая столбчатая диаграмма (Отдельные переменные)
Простая столбчатая диаграмма (Отдельные переменные)

|
Страна |
Млн.баррель/день |
|
Саудовская- Аравия |
8,0 |
|
Иран |
3,3 |
|
Венесуэла |
2,3 |
|
Объединённые Арабские Эмираты |
2,2 |
|
Нигерия |
1,8 |
|
Кувейт |
1,6 |
|
Ливия |
1,4 |
Представим эти данные в форме столбчатой диаграммы.
Откройте файл oel.sav.
В диалоговом окне Bar Charts (Столбчатые диаграммы) активируйте опцию Values of individual cases (Значения отдельных наблюдений).
После нажатия выключателя Define (Определить) откроется соответствующее диалоговое окно.
В поле Bars Represent (Значения столбцов) внесите переменную barrel; в группе Category Labels (Метки категорий) активируйте Variable: (Переменная) и внесите переменную land.
Простая столбчатая диаграмма (Значения отдельных случаев)
Простая столбчатая диаграмма (Значения отдельных случаев)
Диалоговое окно Define...
Рис. 22.10: Диалоговое окно Define Clustered Bar: Summaries for groups of cases (Построение группированной диаграммы: Обработка категорий одной переменной)
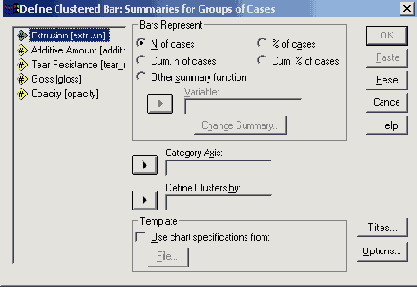
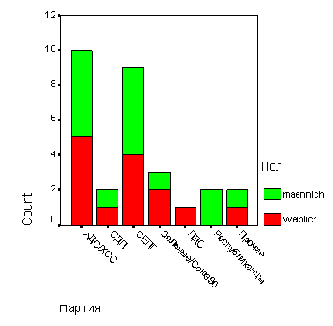
В поле Category Axis: (Ось категорий) введите переменную ak, в поле Define Clusters by: (Создать группы при помощи:) введите переменную med. Активируйте % of cases (% наблюдений).
Пройдя выключатель Titles... (Заголовок), введите заголовок для диаграммы и начните построение диаграммы щелчком на ОК (см. рис. 22.11).
В качестве примера графического представления готовых данных рассмотрим доли I рынка принадлежащие самым крупным изготовителям компьютеров в 1991 и 1992 годах:
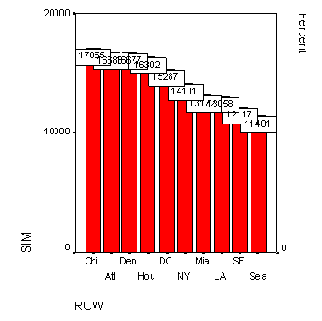
| Изготовитель | Доля рынка, % | |
| 1991 | 1992 | |
| IBM | 16,3 | 12,4 |
| Apple | 11,2 | 11,9 |
| Compaq | 6,0 | 6,6 |
| NEC | 6,4 | 5,1 |
| Dell | 1,7 | 3,5 |
Эти данные построчно сохранены в переменных firma (изготовитель), jahr (год) и anteil (доля) в файле pc.sav.
Откройте файл pc.sav и просмотрите его содержимое в редакторе данных.
В диалоговом окне Bar Charts (Столбчатые диаграммы) щёлкните на области Clustered (Кластеризованная) и активируйте устанавливаемую по умолчанию опцию Summaries for groups of cases (Обработка категорий одной переменной).
После щелчка на выключателе Define (Определить) в открывшемся диалоговом окне в поле Category Axis: (Ось категорий) введите переменную firma, а в поле Define Clusters by: (Определить группы по:) — переменную jahr. В группе Bars Represent (Значения столбцов) активируйте Other summary function (Другая обрабатывающая функция) и в появившееся поле введите переменную anteil; функцию Mean of values (Средние значения) можете оставить.
Пройдя выключатель Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Группированная столбчатая диаграмма
Рис. 22.11: Группированная столбчатая диаграмма
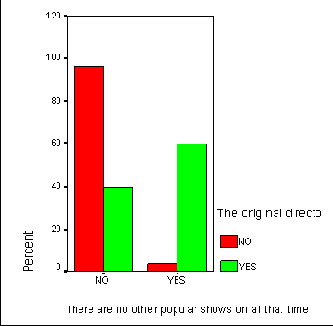
Группированная столбчатая диаграмма
Рис. 22,12: Группированная столбчатая диаграмма
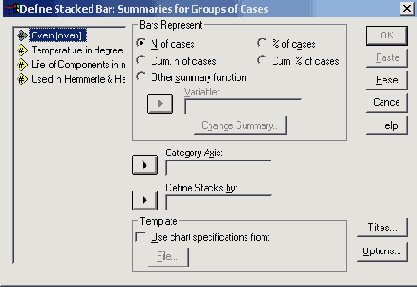
Диалоговое окно Define...
Рис. 22.13: Диалоговое окно Define Stacked Bar: Summaries for groups of cases (Построение штабельной диаграммы: Обработка категорий одной переменной)
Штабельная столбчатая диаграмма
Рис. 22.14: Штабельная столбчатая диаграмма
| Гол | Количество | |
| Запал | Восток | |
| 1985 | 586.155 | 227.648 |
| 1986 | 635.963 | 222.229 |
| 1987 | 642.010 | 225.959 |
| 1988 | 677.259 | 215.734 |
| 1989 | 681.537 | 198.922 |
| 1990 | 727.199 | 178.476 |
| 1991 | 722.250 | 107.769 |
| 1992 | 718.730 | 87.030 |
Откройте файл geburten.sav и просмотрите его содержимое в редакторе данных.
Эти данные построчно сохранены в переменных jahr (год), wo и anz (количество). Переменная wo при помощи кодировок 1 и 2 указывает на принадлежность к Западной или Восточной Германии.
В диалоговом окне Bar Charts (Столбчатые диаграммы) щёлкните на области Stacked (Состыкованная) и активируйте опцию Summaries for groups of cases (Обработка категорий одной переменной), устанавливаемую по умолчанию.
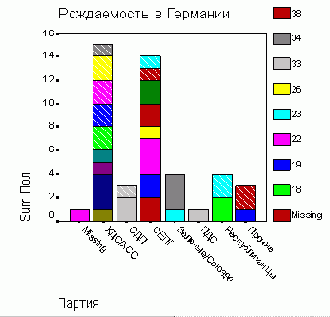
После щелчка на выключателе Define (Определить) в открывшемся диалоговом окне в поле Category Axis: (Ось категорий) введите переменную jahr, а в поле Define Stacks by: (Создать штабели при помощи:) — переменную wo. В группе Bars Represent (Значения столбцов) активируйте Other summary function (Другая обрабатывающая функция) и в появившееся поле введите переменную anz; вместо установленной по умолчанию функции Mean of values (Средние значения), пройдя выключатель Change Summary...(Изменить метод обработки) отметьте функцию суммы (Sum of values).
С помощью кнопки Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Штабельная столбчатая диаграмма
Рис. 22.15: Штабельная столбчатая диаграмма
Для построения линейной диаграммы после открытия соответствующего файла SPSS выберите в меню: Graphs (Графики) Line... (Линейчатые)
Откроется диалоговое окно Line Charts (Линейчатые диаграммы) (см. рис. 22.16).
Вы можете построить простую, сложную и связанную линейные диаграммы. Как и для столбчатых диаграмм данные, отображаемые в этих диаграммах, могут быть заданы как категории одной переменной, как разные переменные или как значения отдельных наблюдений.
Диалоговое окно Line Charts (Линейчатые диаграммы)
Рис. 22.16: Диалоговое окно Line Charts (Линейчатые диаграммы)
Диалоговое окно Define...
Рис. 22.17: Диалоговое окно Define Simple Line: Summaries for Groups of Cases (Построение простой линейчатой диаграммы: Обработка категорий одной переменной)
Линейчатая диаграмма
Рис. 22.18: Линейчатая диаграмма
Диалоговое окно Define...
Рис. 22.19: Диалоговое окно Define Multiple Line: Summaries of Separate Variables (Построение сложной линейчатой диаграммы: Обработка отдельных переменных)
Сложная линейчатая диаграмма
Рис. 22.20: Сложная линейчатая диаграмма

Построенная нами диаграмма будет соответствовать приведенной на рисунке 22.21.
Связанная линейчатая диаграмма
Рис. 22.21: Связанная линейчатая диаграмма
Диалоговое окно Area Charts (Диаграммы с областями)
Рис. 22.22: Диалоговое окно Area Charts (Диаграммы с областями)
Диалоговое окно Define...
Рис. 22.23: Диалоговое окно Define Simple Area: Summaries for Groups of Cases (Построение простой диаграммы с областями: Обработка категорий одной переменной)
Диаграмма с областями
Рис. 22.24: Диаграмма с областями
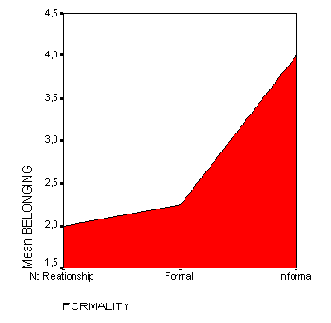
Следует отметить то, что начальной точкой отсчёта вертикальной оси является не ноль, а значение 3,6.
Диалоговое окно Define...
Рис. 22.25: Диалоговое окно Define Stacked Area: Summaries of Separate Variables (Построение штабельной диаграммы с областями: Обработка отдельных переменных)
Штабельная диаграмма с областями.
Рис. 22.26: Штабельная диаграмма с областями.

Диалоговое окно пе Charts (Круговые диаграммы)
Рис. 22.27: Диалоговое окно пе Charts (Круговые диаграммы)

Диалоговое окно Define...
Рис. 22.28: Диалоговое окно Define Pie: Summaries for Groups of Cases (Построение круговой диаграммы: Обработка категорий одной переменной)

В поле Define slices by: (Создать сектора при помощи:) введите переменную psyche.
Щёлкните на выключателе Options... (Параметры) и уберите маркер с опции Display groups defined by missing values (Пропущенные значения отображать как категории).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК (см. рис. 22.29).
Типичным примером применения круговой диаграммы является отображение процентных показателей голосов избирателей, проголосовавших за те или иные партии.
На местных выборах земли Гессен в 1993 году получилось следующее распределение голосов в процентах:
|
Партия |
ДОЛЯ ГОЛОСОВ (%) |
|
SPD |
36,4 |
|
CDU |
32,0 |
|
Gruene (Зелёные) |
11,0 |
|
Republikaner (Республиканцы) |
8,3 |
|
FPD |
5,1 |
|
Прочие |
7,2 |
Этот пример является примером с уже имеющимися (готовыми) данными.
Круговая диаграмма
Рис. 22.29: Круговая диаграмма
Откройте файл kommunal.sav, в котором в переменных р и рг построчно находятся необходимые для нас данные.
В диалоговом окне Pie Charts (Круговые диаграммы) опять оставьте опцию Summa-ries for groups of cases (Обработка категорий одной переменной), установленную по умолчанию.
После щелчка по выключателю Define (Определить) в поле Define slices by: (Создать сектора при помощи:) введите переменную р. Поставьте маркер возле Other summary function (Другая обрабатывающая функция) и в появившееся поле введите переменную рг. Используйте установленную по умолчанию опцию Sum of values (Сумма значений).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК (см. рис. 22.30).
В главе 22.17 мы придадим этой диаграмме более презентабельный вид.
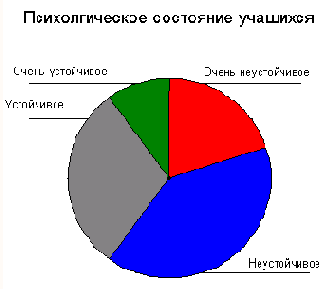
Круговая диаграмма
Рис. 22.30: Круговая диаграмма
Диалоговое окно Higli-Low Charts (Диаграммы максимума-минимума)
Рис. 22.31: Диалоговое окно Higli-Low Charts (Диаграммы максимума-минимума)
|
День |
Максимальная котировка |
Минимальная котировка |
Окончательная котировка |
|
1 |
164,35 |
161,48 |
162,33 |
|
2 |
166,12 |
163,03 |
164,12 |
|
3 |
167,84 |
164,75 |
165,97 |
|
4 |
167,79 |
163,93 |
166,13 |
|
5 |
171,14 |
/ 168,04 |
170,94 |
|
6 |
175,33 |
171,44 |
171,99 |
|
7 |
174,88 |
172,93 |
173,01 |
|
8 |
173,20 |
170,50 |
171,82 |
|
9 |
169,54 |
166,43 |
167,28 |
|
10 |
168,24 |
165,14 |
166,43 |
Эти данные построчно сохранены в четырёх переменных tag (день), hoch (максимум), tief (минимум) и ende (окончательная котировка) в файле aktien.sav.
Откройте файл aktien.sav и в диалоговом окне High-Low Charts (Диаграммы максимума-минимума) щёлкните на области Simple High-Low-Close (Простая диаграмма — потолок-пол-закрытие).
Установите метку возле опции Summaries of separate variables (Обработка отдельных переменных) и нажатием выключателя Define (Определить) откройте следующее диалоговое окно (см. рис. 22.32).
В поле Category Axis: (Ось категорий) введите переменную tag и в соответствующие поля введите переменные hoch (High), tief (Low) и ende (Close). Оставьте установленную по умолчанию функцию Mean of values (Средние значения).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок.
Начните построение диаграммы щелчком на ОК.
Диалоговое окно Define...
Рис. 22.32: Диалоговое окно Define Simple High-Low-Close: Summaries of Separate Variables (Построение простой диаграммы — потолок-пол-закрытие: Обработка отдельных переменных)
Простая диаграмма — потолок-пол-закрытие
Рис. 22.33: Простая диаграмма — потолок-пол-закрытие
Диалоговое окно Define...
Рис. 22.34: Диалоговое окно Define Difference Line: Summaries of Separate Variables (Построение линейчатой диаграммы разностей: Обработка отдельных переменных).
Линейчатая диаграмма разностей
Рис. 22.35: Линейчатая диаграмма разностей
Диалоговое окно Define...
Рис. 22.36: Диалоговое окно Define Simple Range Bar: Summaries of Separate Variables (Построение диаграммы с простыми интервальными столбцами: Обработка отдельных переменных)
Простые интервальные столбцы
Рис. 22.37: Простые интервальные столбцы
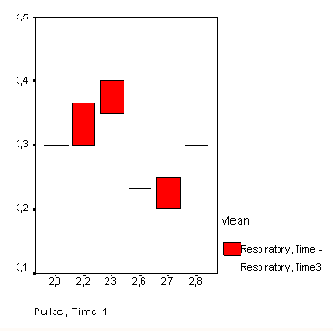
Диалоговое окно Boxplot (Коробчатая диаграмма)
Рис. 22.38: Диалоговое окно Boxplot (Коробчатая диаграмма)
Коробчатая диаграмма (категории одной переменной)
Рис. 22.39: Коробчатая диаграмма (категории одной переменной)
Коробчатая диаграмма (разные переменные)
Рис. 22.40: Коробчатая диаграмма (разные переменные)
Диалоговое окно Error Bar (Столбцы по величинам ошибки)
Рис. 22.41: Диалоговое окно Error Bar (Столбцы по величинам ошибки)
Диалоговое окно Define...
Рис. 22.42: Диалоговое окно Define Simple Error Bar: Summaries for Groups of Cases (Построение простой диаграммы величины ошибки: Обработка категорий одной переменной)
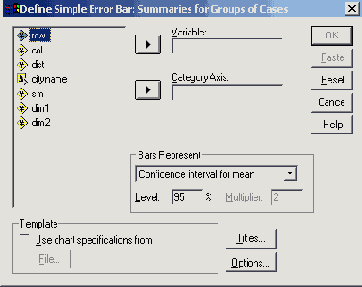
Стандартная ошибка (предустановленный множитель равен 2)
Стандартное отклонение (предустановленный множитель равен 2)
Выберите отображение простого стандартного отклонения (множитель равен 2).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Если необходимо отобразить изменение уровня холестерина с течением времени, то для построения графика необходимо использовать переменные chol0, chol1, chol6 и chol12.
Простая диаграмма величины ошибки (категории одной переменной)
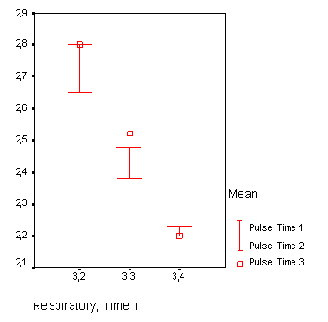
Рис. 22.43: Простая диаграмма величины ошибки (категории одной переменной)
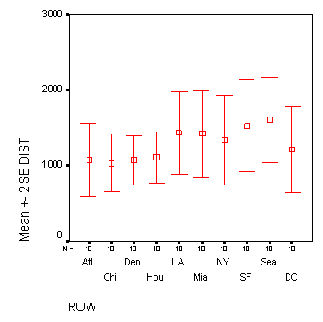
В диалоговом окне Error Bar (Столбики ошибок) вновь щёлкните на области Simple (Простая), но теперь поставьте маркер возле опции Summaries of separate variables (Обработка отдельных переменных).
Щелчком по выключателю Define (Определить) откройте следующее диалоговое окно, в котором по очереди введите переменные chol0, chol1, chol6 и chol12 в поле Error Bars (Значения столбцов ошибок). В этом случае выберите отображение 95 % -го доверительного интервала (который является установкой по умолчанию).
С помощью выключателя Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК (см. рис. 22.44).
Простая диаграмма величины ошибки (разные переменные)
Рис. 22.44: Простая диаграмма величины ошибки (разные переменные)
Метки значений на горизонтальной оси необходимо будет ещё подкорректировать.
Диалоговое окно Scatterplot (Диаграмма рассеяния)
Рис. 22.45: Диалоговое окно Scatterplot (Диаграмма рассеяния)

Диалоговое окно Simple Scatterplot (Простая диаграмма рассеяния)
Рис. 22.46: Диалоговое окно Simple Scatterplot (Простая диаграмма рассеяния)
Для этой цели щёлкните по выключателю Options... (Параметры) и в появившемся диалоговом окне активируйте опцию Display chart with case labels (Показать график с метками наблюдений).
Пройдя выключатель Titles... (Заголовок), введите подходящий заголовок и начните построение диаграммы щелчком на ОК.
Простая диаграмма рассеяния с метками случаев
Рис. 22.47: Простая диаграмма рассеяния с метками случаев

Большое количество меток наблюдений приводит к снижению наглядности графика, поэтому можно рекомендовать оставить их только для избранных точек.
В качестве альтернативы на вооружение можно взять обозначение метками только наиболее характерных точек.
Для этого постройте диаграмму заново.
Через выключатель параметров уберите маркер опции Display chart with case labels (Показать график с метками наблюдений).
Теперь метки на графике присутствовать не будут.
Двойным щелчком поместите график в редактор диаграмм.
Одним щелчком по символу выбора точек