12.1.
Инструментальные средства и задачи, решаемые экспертной системой
В своей статье
[Clancey, 1985] Кленси отметил, что хотя языки, базирующиеся на правилах,
такие как EMYCIN, и не учитывают многих свойств предложенной им модели эвристической
классификации, все же они являются достаточно подходящими инструментами для
задач классификации, в частности задач диагностики. Хотя вразрез с рекомендациями
Кленси ни система MYCIN, ни системы, базирующиеся на EMYCIN, не содержат специфических
средств таксономии симптомов или признаков неисправностей, тот факт, что решения
могут быть заранее пронумерованы, означает, что можно применить обратную стратегию
построения суждений, т.е. строить логическую цепочку от абстрактных категорий
решений к подходящим данным через промежуточный этап абстрагирования данных.
Этот этап неявно включен в используемые правила. Тот факт, что выводы из набора
правил индексируются в терминах медицинских параметров, на которые они ссылаются,
позволяет без особого труда реализовать стратегию рассуждения от цели к средствам.
Ранее мы уже
упоминали о таких особенностях MYCIN, как отказ от обратного прослеживания в
пользу деструктивной модификации рабочей памяти и использование стратегии исчерпывающего
поиска.
Эти две особенности
MYCIN тесно увязаны. Нет необходимости использовать обратное прослеживание,
поскольку мы неотступно следуем за множеством независимых свидетельств и на
заключительной стадии ранжируем гипотезы. Если бы не использовалась стратегия
достаточно исчерпывающего поиска, то потребовалось бы выполнять в той или иной
форме обратное прослеживание, как это было показано в главе 2. Процесс обратного
прослеживания требует больших затрат вычислительных ресурсов системы, так как
приходится сохранять информацию о предыдущих этапах вычислений, к которым, возможно,
придется еще возвращаться. Большой объем пространства состояний, в котором ведется
поиск, требует значительных ресурсов памяти. На практике при этом используется
механизм постраничного обмена между оперативной и дисковой памятью, что отрицательно
сказывается на производительности системы в целом. Однако значительные вычислительные
ресурсы отвлекаются на активизацию каждого потенциально подходящего правила,
от чего приходится отказываться в некоторых системах. Во многих системах используется
методика восхождение на гору, в которой принятие решения об использовании
некоторого правила не может быть пересмотрено или отменено (см. главу 2). Иногда
при этом может потребоваться использование локального обратного отслеживания
(подробнее об этом — в главе 14 и в Приложении).
Такой простой
режим управления редко используется при решении проблем конструирования. Проблемы
проектирования и формирования конфигураций, как правило, требуют использования
средств, характеризующихся наличием множества альтернативных способов решения,
причем эти способы отнюдь не равноценны по качеству результата. Довольно часто
приходится сталкиваться с ситуацией, когда отсутствует хорошая оценочная функция,
которую можно было бы применить при поиске в пространстве состояний. Это объясняется
тем, что качество проектирования определяется не только изолированными свойствами
проектируемой конструкции и ее компонентов, но и глобальными параметрами, которые
можно оценить только после завершения проектирования конечного продукта. Например,
при решении задачи рациональной расстановки мебели в помещениях нужно принимать
во внимание необходимость удовлетворения определенных ограничений и пожеланий:
желательно письменный стол ставить вблизи окна, книжный шкаф размещать недалеко
от письменного стола, диван ставить против телевизора и т.д. Но сформированные
решения могут удовлетворять одним пожеланиям (ограничениям) и не удовлетворять
другим, поскольку нужно удовлетворить какие-либо важные глобальные ограничения
— оставить свободным проход через комнаты или обеспечить единообразную расстановку
мебели.
В главах 14
и 15 мы еще познакомимся с дополнительными стратегиями управления поиском, которые
приходится использовать в задачах конструирования. Сюда входят:
стратегия наименьшего
принуждения (least commitment) — стремление отложить на будущее, насколько
это возможно, принятие решений, ограничивающих свободу последующего выбора;
стратегия предложения
и исправления (propose and revise) — стремление устранить нарушение сформулированных
ограничений, как только такое нарушение обнаруживается;
различные виды обратного
прослеживания, когда при обнаружении нарушения определенных условий пересматриваются
только что принятые решения и выполняется откат в предшествующее состояние.
Отображение
таких методов на множество типов решаемых задач — предмет дальнейших исследований.
Как бы там
ни было, но для выбора подходящих инструментальных средств построения экспертных
систем существенную роль играет идентификация уровня задач анализа, которая
базируется на используемых методах решения проблем. Этот уровень, как правило,
располагается между более высокими концептуальным и эпистемологическим уровнями
и более низкими логическим и уровнем реализации, о которых шла речь в главе
10. Если не выполнить такую идентификацию, появляется опасность утраты обобщенных
связей между типами задач и структурами логического вывода и языками представления
знаний.
12.2.
Эвристическая классификация в системах MUD и MORE
В этом разделе
мы проанализируем последствия применения методики анализа, предложенной Кленси,
к процессу приобретения знаний. Сначала будет рассмотрена экспертная система
MUD, которая ориентирована на решение задач геологоразведки, в частности бурения
скважин. Эта система является хорошим примером весьма эффективного использования
метода эвристической классификации. Затем для этой системы будет описан прототип
системы извлечения знаний, названный MORE, в котором стратегия приобретения
знаний связывается с используемыми методами решения проблем.
Как и в системе
MYCIN, в MOD процесс приобретения знаний в основном ориентирован на установление
отображения множества данных на множество решений. Однако в системе MYCIN другие
виды знаний, например иерархические отношения между данными и абстрактными категориями
решений, эвристики раскрытия пространства состояний и т.п., представлены в наборе
правил только неявным образом. Подход, использованный при создании MUD и MORE,
делает эти знания более явными, и в этом смысле существует определенное сходство
между этими системами и системой OPAL (см. главу 10). И там, и здесь используется
промежуточное представление, которое играет роль модели предметной области.
Модель предметной области выполнения буровых работ
Система MUD
[Kahn and McDermott, 1984] предназначена для консультирования инженеров
при проведении буровых работ на газонаполненных и текучих пластах. Основываясь
на описании свойств пластов, система анализирует проблемы, возникающие при таком
бурении, и предлагает способы их преодоления. Изменение свойств пластов, такое
как внезапное увеличение вязкости в процессе бурения, может возникать вследствие
самых различных факторов, например повышения температуры или давления или неправильной
рецептуры смеси химических добавок.
Система MUD
реализована с помощью языка описания порождающих правил OPS5 (предшественника
CLIPS). Правила связывают изменения свойств пластов (абстрактные категории данных)
с возможными причинами этих изменений (абстрактные категории решений). Ниже
приведено одно из таких правил в переводе на "человеческий" язык.
ЕСЛИ:
(1) обнаружено
уменьшение плотности пласта и
(2) обнаружено
повышение вязкости,
ТО:
есть умеренные
(7) основания предполагать, что имеется приток воды.
В формулировке
таких правил числа в скобках — коэффициенты уверенности, которые при "сцеплении"
правил комбинируются таким же способом, как и в системе MYCIN (подробнее об
этом см. в главе 3). Таким образом, для того, чтобы определить достоверность
предположения о проникновении воды, нужно принять во внимание все правила, которые
"порождают" свидетельства за и против этой гипотезы. Мера доверия
(или недоверия), связанная с каждым свидетельством, определяется способом, описанным
в главе 9, а коэффициент уверенности в достоверности гипотезы является разностью
между мерами доверия и недоверия.
Опыт, приобретенный
Каном в процессе работы над этой системой, показал, что эксперты часто затрудняются
сформулировать правила, приемлемые для подхода на основе эвристической классификации.
Формат правила далеко не всегда соответствует способу мышления, привычному для
экспертов, и способу обмена знаниями, принятыми в их среде. Определенные сложности
вызывает и назначение коэффициентов уверенности в констатирующей части новых
правил. При этом обычно приходится пересматривать сформулированные ранее правила
и сравнивать имеющиеся в них значения коэффициентов. Очень часто эксперты используют
коэффициенты уверенности для частичного упорядочения в отношении определенного
"заключения. Бучанан и Шортлифф [Buchanan and Shortliffe, 1984, Chapter
7] также отмечали, что экспертам иногда для правильной формулировки правил
нужно располагать довольно подробной информацией о режиме применения правил
и распространении значений коэффициентов уверенности в процессе их "сцепления".
При проектировании
программ эвристической классификации, таких как MUD или MYCIN, процесс уточнения
правил является, по существу, шестиэтапным.
(1) Эксперт
сообщает инженеру по знаниям, какие правила нужно добавить или изменить.
(2) Инженер
по знаниям вносит изменения в базу знаний системы.
(3) Инженер
по знаниям запускает на выполнение программу, вводит данные, которые ранее уже
обрабатывались прежним набором правил, и проверяет таким образом полноту нового
набора.
(4) Если при
обработке новым набором правил ранее проверенных исходных данных возникают какие-либо
проблемы, инженер по знаниям обсуждает способы их преодоления с экспертом и
далее повторяется этап 1.
(5) Эксперт
запускает систему и вводит новый вариант данных.
(6) Если при
обработке нового варианта не возникает никаких проблем, можно считать очередной
сеанс внесения изменений в правила завершенным. В противном случае повторяется
вся процедура начиная с 1-го этапа.
Как было показано
в главе 10, именно такой базовый алгоритм внесения изменений в базу знаний используется
в системе MYCIN, а для повышения эффективности выполнения отдельных этапов применяются
разнообразные инструментальные средства, в частности язык сокращенного описания
правил из состава оболочки EMYCIN, библиотека тестовых наборов данных, средства
выполнения тестовых примеров в пакетном режиме и т.п.
Кан и его
коллеги пошли по другому пути [Kahn et al, 1985], [Kahn, 1988]. Они применили
программу извлечения знаний MORE, которая использует для обновления базы знаний
MUD как знания о предметной области, так и знания о стратегии решения проблем.
Как и OPAL, программа MORE располагает моделью предметной области, в которой
представлены основные отношения между базовыми концепциями. Эти знания используются
для организации опроса экспертов, обнаружения ошибок при назначении коэффициентов
доверия и для генерации правил, на основании которых выполняется эвристическая
классификация.
В программе
MORE модель предметной области состоит из следующих компонентов:
симптомы, т.е.
явления, которые можно наблюдать в процессе проведения диагноза; появление
этих явлений и должна объяснить система;
атрибуты, которые
являются средством детализации симптомов, например резкое возрастание или
снижение значения какого-либо параметра;
события, которые являются
возможным следствием симптомов и таким образом могут рассматриваться в качестве
гипотез;
фоновые условия,
позволяющие судить о большей или меньшей вероятности наличия связи между
обнаруженными симптомами и теми или иными гипотетическими причинами их появления;
тестовые процедуры,
которые можно использовать для обнаружения наличия или отсутствия упомянутых
выше фоновых условий;
условия выполнения
тестовых процедур, способные повлиять на точность результатов тестирования.
Эти знания
организованы в виде сети, в которой явно обозначены связи между симптомами и
возможными причинами их появления, а также связи между условиями и теми состояниями
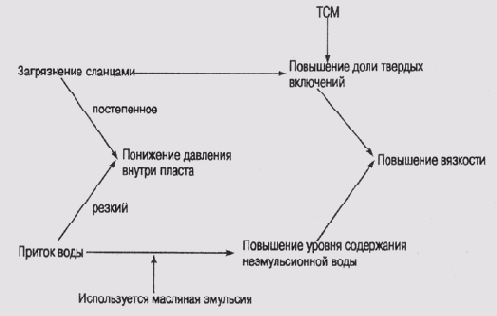
или событиями, на которые эти условия могут повлиять. На рис. 12.1 представлен
фрагмент сети представления модели предметной области, в которой используется
система MUD.
Загрязнение
сланцами и приток воды — это гипотезы, объясняющие появление четырех
симптомов: понижение давления внутри пласта, повышение доли твердых включений,
повышение уровня содержания неэмульсионной воды и повышение вязкости.
Все они являются свойствами вязких и жидких пластов, на которых может сказаться
загрязнение теми или иными компонентами при выполнении буровых работ. Обратите
внимание, что на этой схеме некоторые линии причинно-следственных связей параметризиро-ваны
степенью влияния на симптом. ТСМ— это тест синевы метилена, который проверяет
повышение количества твердых включений в вязких пластах, а используется масляная
эмульсия — фоновое условие, которое может сказаться на связи между притоком
воды и повышением уровня содержания неэмульсионной воды.
Рис. 12.1.
Фрагмент модели предметной области, которая используется в программе MORE
12.1.
Диагностические правила в М U D
Ниже
приведены некоторые диагностические правила для той предметной области, на которую
ориентирована система MUD. Правила, реализованные в виде программы на языке
CLIPS, описывают те же причинно-следственные связи, что и на рис. 12.1. Если
вы запустите эту программу на выполнение и ответите на оба вопроса утвердительно,
то программа придет к заключению, что возможны два варианта объяснения наличия
указанных симптомов— и загрязнение сланцами, и приток воды. Если на один из
вопросов ответить отрицательно, то программа отдаст предпочтение одной из гипотез.
;;
ШАБЛОНЫ (deftamplate symptom
(field
datum (type SYMBOL))
(field
change (type SYMBOL))
(field
degree (type SYMBOL) (default NIL))
)
(deftamplate
hypothesis
(field
object (type SYMBOL))
(field
event (type SYMBOL))
(field
status (type SYMBOL) (default NIL))
(deftemplate
testing
(field
name (type SYMBOL))
(field
for (type SYMBOL))
(field
status (type SYMBOL) (default NIL)) )
;;
ФАКТЫ
(deffacts
mud
a(symptom
(datum viscosity)
(change increase))
(symptom
(datum density)
(change
decrease) (degree gradual))
(testing
(name МВТ)
(for low-SG-solids))
(testing
(name oil-mud)
(for
unemulsified-water))
)
;;
ПРАВИЛА
;;
Правило обратного вывода, принимающее во внимание
;;
вязкость (viscosity).
(defrule
viscosity (symptom
(datum
viscosity) (change increase))
=>
(assert
(hypothesis (object low-SG-water)
(event increase))) (assert (hypothesis
(object
unemulsified-water) (event increase)))
)
;;
Правила обратного вывода, принимающие во внимание
;; плотность (density). (defrule density :
(symptom
(datum density)
(change
decrease) (degree gradual))
=>
(assert
(hypothesis (object shale)
(event
contamination)))
)
(defrule
density
(symptom
(datum density) (change decrease)
(degree
rapid)) =>
(assert
(hypothesis (object water) (event influx»)
)
;;
Свидетельства в пользу загрязнения сланцами
(shale contamination) (defrule shale ?effect
<- (hypothesis (object low-SG-water)
(event
increase)
(status
yes)) => (assert (hypothesis
(object
shale) (event contamination)
(status
yes)))
(modify
?effect (status done)) )
;;
Свидетельства в пользу притока воды (water influx)
(defrule
water ?effect <- (hypothesis
(object
unemulsified-water)
(event
increase) (status yes)) =>
(assert
(hypothesis (object water)
(event
influx)
(status
yes))) (modify ?effect
(status
done))
)
;;
Поиск теста гипотезы (defrule peek-test
(hypothesis
(object ?obj) (event ? change))
?operator
<- (testing (name ?name)
(for
?obj) (status NIL)) =>
(printout
t
crlf
"Is
there " ?obj " " ?change " according to the "
?name
" test? "
;;
"Существует " ?obj " " ?change " в соответствии с "
,
;;
" тестом " ?name " ? "
)
;; (modify ?operator (status (read)))
)
;;
Применить результат теста к гипотезе.
{defrule poke-test
?cause
<- (hypothesis (object ?obj)
(event ?change))
?operator
<- (testing (name ?name)
(for
?obj) (status yes))
=>
(modify
?cause (status yes)
(modify
?operator (status done))
)
;
; Вывести активную гипотезу.
(defrule
show-and-tell
(hypothesis
(object ?obj)
(event
?ev) (status yes))
=>
(printout
t
crlf
?obj
" " ?ev "is a possibility. " t crlf
;; ?obj " " ?ev " является вероятной. "
)
Стратегии
приобретения знаний
Кан и его
коллеги атаковали проблему извлечения знаний с двух направлений. С одной стороны,
в процессе проектирования системы MUD они совершенствовали методику опроса экспертов
инженерами по знаниям. С другой стороны — проанализировали используемую методику
в терминах метода решения проблем с помощью эвристической классификации, который
используется в MUD. В результате были выделены восемь вариантов стратегий извлечения
знаний, которые перечислены ниже. Каждый из вариантов стратегии используется
программой MORE для подтверждения или опровержения гипотез в процессе диагностирования.
Дифференциация. Поиск
симптомов, позволяющих разделить гипотезы, например симптомов, которые могут
иметь единственную причину. Такое взаимно однозначное соответствие между симптомом
и явлением, его вызвавшим, в медицинской литературе называется патогенетической
(pathognomic) ассоциацией.
Частотное упорядочение
условий. Определение тех фоновых условий, которые влияют на степень правдоподобности
конкретных гипотез. Если подходить к задачам диагноза с точки зрения теории
принятия решения, то степень поддержки конкретной гипотезы об источнике неисправности,
которую вносит определенное свидетельство (симптом), зависит от априорной
вероятности этой неисправности.
Отчетливость симптомов.
Идентификация тех свойств симптомов, которые могут являться индикаторами
лежащих в глубине причин появления этих симптомов. Так, в схеме на рис. 12.1
видно, что резкое повышение плотности пласта является довольно отчетливым
индикатором наличия притока воды.
Установление связи
между симптомами и условиями. Отыскание таких условий, при которых можно
рассчитывать на то, что разные симптомы проявятся сами по себе при данной
неисправности. Такие ожидания могут служить для опровержения гипотез, если
они не получили подтверждения.
Разделение пути.
Попытка найти такие промежуточные события между гипотезами о причинах
неисправности и вероятными симптомами, которые имеют более высокую условную
вероятность, чем сами симптомы. Если такие промежуточные события не фиксируются
в процессе диагностирования, то это может служить более серьезным доводом
против данной гипотезы, чем отсутствие симптома.
Дифференциация путей.
Как и в случае разделения пути, анализируется "траектория" причинно-следственных
связей между симптомами и неисправностями. В процессе этого анализа стараются
выявить такие промежуточные события, которые позволят провести разделение
неисправностей, имеющих одинаковые симптомы.
Дифференциация тестирования.
Определение степени доверия к результатам тестирования. Свидетельство,
как правило, является результатом тестирования, а последнее может быть охарактеризовано
различными значениями степени достоверности.
Установление связи
между тестированием и условиями его проведения. Определение фоновых условий,
которые могут сказаться на степени достоверности результатов тестирования.
Такая информация влияет на оценку результатов текущих наблюдений для анализируемого
случая.
Извлечение
знаний с помощью программы MORE начинается с получения от эксперта знаний о
базовых неисправностях (патологиях) и связанных с ними симптомах. Затем программа
избирательно активизирует указанные выше стратегии приобретения знаний, базируясь
на тех знаниях, которые приобретены на предыдущих стадиях. Чтобы понять механизм
выбора стратегий, рассмотрим процесс приобретения знаний с помощью MORE более
подробно.
В той предметной
области, на которую ориентирована программа MORE, существуют три типа порождающих
правил.
Диагностические
правила описывают соответствие между симптомами и гипотезами. Правила
такого типа имеются во многих экспертных системах — MYCIN, ONCOCIN, MUD и
т.п.
Правила оценки степени
достоверности симптомов. С помощью этих правил выполняется неявная качественная
оценка абстрактных категорий данных в пространстве симптомов, которая опирается
на уровень достоверности результатов тестирования при различных фоновых условиях.
Правила оценки степени
правдоподобности гипотез позволяют провести неявную качественную оценку
абстрактных категорий решений в пространстве гипотез. При этом оценивается
априорная вероятность гипотез при различных фоновых условиях.
Отличительной
чертой диагностических правил, которые используются в системе MUD, является
наличие двух коэффициентов доверия — положительного и отрицательного.
Положительный коэффициент отображает степень поддержки заключения данным
правилом при соблюдении сформулированных в нем условий, а отрицательный— степень
"опровержения" заключения данным правилом, если сформулированные в
правиле условия не соблюдаются. В правилах, относящихся к двум
другим группам, используется только один коэффициент. В правилах оценки степени
достоверности симптомов значение коэффициента несет информацию об изменении
степени достоверности определенного симптома, которое вносится данным правилом.
В правилах оценки степени правдоподобности гипотез значение коэффициента определяет
изменение степени правдоподобия гипотезы, которое вносится при выполнении условий,
специфицированных в данном правиле.
Программа
MORE работает с двумя видами моделей — моделью событий и моделью правил.
Модель событий охватывает симптомы, гипотезы и условия и связи между ними,
как показано на рис. 12.1. В MORE это представление используется для формирования
порождающих правил, в отличие от программы OPAL, в которой правила формируются
на основании модели предметной области.
Если быть
точным, то программа MORE генерирует целое семейство диагностических
правил по одному на каждую гипотезу. Например, прямо из модели событий MUD программа
MORE может сформировать следующее диагностическое правило:
[Правило 1]
ЕСЛИ обнаружено
повышение уровня хлоридов,
ТО существует
солевое загрязнение.
Но это правило
является слишком общим. Ему нужно дать качественную оценку, например с помощью
стратегии отчетливости симптомов. Эта оценка позволит учесть эффект влияния
фоновых условий на степень важности симптома. Таким образом, в семейство правил
солевое загрязнение может быть добавлено следующее правило:
[Правило 2]
ЕСЛИ обнаружено
повышение уровня хлоридов и пласт недостаточно насыщен,
ТО существует
солевое загрязнение.
Программа
MORE работает с семействами правил следующим образом. Когда программа "изучает"
новые условия, имеющие отношение к некоторой гипотезе, она создает новое правило
с единственным условием в левой части и добавляет его в семейство правил этой
гипотезы. Если же новое условие имеет отношение и к другим правилам, ранее включенным
в это же семейство, то в них также добавляется это условие. (Если новое условие
не совместимо с другими, указанными в одном из правил семейства, то такое правило
не изменяется.) Правила, в которые добавляется новое условие, называются составными
правилами (constituent rules). О них мы поговорим в следующем разделе, когда
будем рассматривать коэффициенты уверенности.
Приведенный
пример применения стратегии отчетливости симптомов показывает, как с
помощью той или иной стратегии извлечения знаний выполняется уточнение сформулированных
правил. Стратегия отчетливости симптомов используется тогда, когда в
семействе не оказывается правил с отчетливо выраженным положительным коэффициентом
доверия. Приведенное выше исходное правило было слишком общим, а потому ему
нельзя было назначить высокий коэффициент доверия. Поскольку на начальном этапе
это правило является единственным в семействе, для его уточнения и активизируется
стратегия отчетливости симптомов. Чаще всего, после того как формулируются
другие правила семейства, в которых специфицируются различные фоновые условия,
такие общие правила удаляются из семейства. Такое удаление можно рассматривать
как стремление отдавать предпочтение специализированным правилам, а не более
общим, на чем основаны некоторые стратегии разрешения конфликтов.
Стратегия
установление связи между симптомами и условиями используется в том случае,
если в семействе отсутствуют правила с отчетливо выраженным отрицательным
коэффициентом доверия. В таких случаях программа MORE предпринимает попытку
выявить те фоновые условия, которые позволяют более отчетливо проявиться симптому
какой-либо определенной гипотезы. Знание условий, при которых повышается вероятность
проявления симптома, позволяет компоненту решения задач отбрасывать часть гипотез,
для которых наиболее показательные симптомы отсутствуют.
Другие стратегии
— дифференциация, дифференциация путей и разделение пути — используются
для создания новых семейств правил. Стратегия дифференциации задейст-вуется
в тех случаях, когда программа обнаруживает пару гипотез, не имеющих отличающихся
симптомов. В этом случае на схеме модели событий, аналогичной приведенной на
рис. 12.1, возникает ситуация, когда для пары гипотез Н1 и
H2 не оказывается ни одного симптома, который имел бы связь с Н1
но не имел связи с H2, или наоборот. Используя стратегию
дифференциации, программа MORE пытается выяснить у эксперта, какой еще
симптом можно добавить в набор и с его помощью устранить неоднозначность. Этот
новый симптом добавляется затем в модель событий и связывается с определенными
гипотезами. Таким образом модель уточняется до тех пор, пока не появится возможность
сформировать отдельные семейства правил для гипотез Н1 и H2
Стратегия
дифференциации путей выбирается в том случае, если в модели событий некоторый
симптом оказывается связан с двумя разными гипотезами. В этой ситуации программа
MORE пытается выяснить у эксперта, существует ли какое-либо промежуточное событие,
которое, с одной стороны, может послужить причиной появления такого симптома,
а с другой, может возникнуть только в том случае, когда правдоподобна одна из
"конкурирующих" гипотез и неправдоподобна другая. Включение такого
события в модель поможет разделить существующие объяснения появления такого
симптома, а соответственно и уточнить связанные с ними правила.
К стратегии
разделения пути программа обращается в том случае, если в семействе правил
некоторой гипотезы обнаруживается отсутствие правила, которое связало бы высокое
значение отрицательного коэффициента доверия с отсутствием какого-либо
симптома. В этой ситуации программа MORE пытается выяснить у эксперта, существует
ли какое-либо промежуточное событие, причиной которого могла бы быть данная
гипотеза. Если такое событие существует, то тот факт, что оно не наблюдается,
может с большей очевидностью свидетельствовать против данной гипотезы,
чем тот факт, что симптом не наблюдается. В результате можно создать новое семейство
правил для гипотезы.
Остальные
стратегии — частотное упорядочение условий, дифференциация тестирования и
установление связи между тестированием и условиями его проведения — активизируются
в случаях, когда в семействе обнаруживается отсутствие правил с достаточно высоким
или достаточно низким значением положительного или отрицательного коэффициента
доверия. В таком случае правила нельзя считать достаточно информативными для
решения проблемы классификации. Получение от эксперта информации о новых тестовых
процедурах и условиях их выполнения, а также оценок априорной вероятности гипотез
при различных фоновых условиях позволит либо увеличить, либо уменьшить коэффициенты
в правилах, связывающих симптомы и гипотезы. Информация первого типа используется
для корректировки правил оценки степени достоверности симптомов, а информация
второго типа — для корректировки правил оценки степени правдоподобности гипотез.
Использование коэффициентов уверенности в программе MORE
Выше уже не
раз обращалось внимание на тот факт, что эксперты зачастую испытывают серьезные
затруднения при назначении коэффициентов уверенности конкретным правилам. Прежде
чем назначить коэффициент новому правилу, эксперты любят просмотреть уже сформулированные
и сравнить установленные в них значения с тем, которое планируется присвоить
новому правилу. Они стараются добиться взаимной увязки всех сформулированных
правил как в отношении степени важности отдельных свидетельств, так и в отношении
"крепости" ассоциативных связей между свидетельствами и гипотезами.
Как помочь эксперту решить эту задачу?
Определенную
помощь в этом эксперту может оказать программа MORE, которая формирует предположительные
значения коэффициентов, основываясь на ранее введенных правилах, и предлагает
их эксперту. Если введенное экспертом значение игнорирует предложенные программой,
то выводится предупреждающее сообщение для инженера по знаниям, в котором программа
приводит свои соображения относительно обнаруженного противоречия. После этого
пользователь имеет возможность воспользоваться набором опций и устранить противоречие
между параметрами нового правила и ранее созданных.
Программа
MORE формирует предположительные значения коэффициентов следующим образом.
Предположим,
что неисправность D проявляется в виде симптома S1 а появление
симптома S1 влечет за собой и появление симптома S2.
В таком случае программа MORE предполагает, что отрицательный коэффициент
уверенности, назначенный правилу, которое связывает симптом S1 с
гипотезой D, будет больше или равен отрицательному коэффициенту, назначенному
правилу, которое связывает симптом S2 с гипотезой D. В
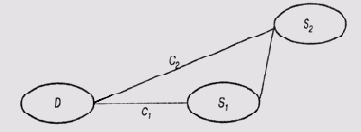
схеме модели событий на рис. 12.2 ожидается, что С1=> С2.
Здесь коэффициентом С, оценивается связь между симптомом S1 и гипотезой
D, а коэффициентом С2 — связь между симптомом S2
и гипотезой D.
Почему предполагается
такое соотношение между значениями коэффициентов, интуитивно понятно. Если отсутствие
симптома S1 является более веским аргументом против гипотезы
D, то отсутствие симптома S2 не меняет положения дел.
Если вновь вернуться к модели событий на рис. 12.1, то отрицательная связь между
притоком воды и повышением уровня содержания неэмульсионной воды должна
быть более "сильной", чем связь между притоком воды и повышением
вязкости.
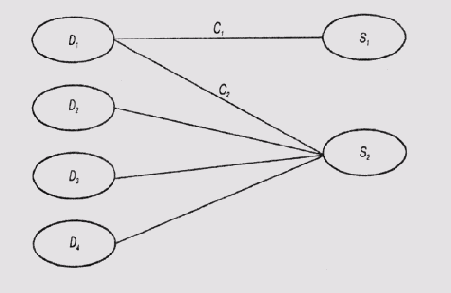
Диагностическая
значимость симптома является величиной, обратной количеству гипотез, в которых
учитывается наличие этого симптома. В модели событий, схема которой представлена
на рис. 12.3, программа MORE предполагает, что С1 > С2,
поскольку появление симптома S1 может быть вызвано только
неисправностью (гипотезой) D1, a появление симптома S2
может быть вызвано и другими неисправностями.
Рис. 12.2.
Отрицательные коэффициенты достоверности в цепочке причинно-следственной связи
Рис. 12.3.
Положительные коэффициенты достоверности в случае множественной связи симптома
с гипотезами
Программа
MORE также оценивает и отношения между значениями коэффициентов в правилах одного
семейства (т.е. в правилах, делающих одинаковое заключение или, что то же самое,
относящихся к одной и той же гипотезе). Например, если в семейство правил добавляется
новое условие проявления симптома, которое увеличивает условную достоверность
симптома, это скажется на тех правилах, которые имеют большие отрицательные
значения коэффициентов, чем составные правила. (Напомним, что составными называются
правила, расширенные при добавлении нового условия.) Рациональность этих предположений
заключается в том, что чем больше мы рассчитываем на появление определенного
симптома при данной гипотезе (при данной неисправности), тем сильнее будет наше
недоверие к этой гипотезе при отсутствии такого симптома.
Каждое из
таких предположений основано на стремлении сохранить взаимную согласованность
коэффициентов в правилах одного семейства.
Опыт эксплуатации системы MORE
В одной из
своих ранних работ, посвященных созданию системы MYCIN, Шортлифф обратил внимание
на необходимость разработки такого механизма извлечения знаний, который помогал
бы эксперту назначать порождающим правилам коэффициенты уверенности [Shortliffe,
1976]. В сборнике [Buchanan and Shortliffe, 1984, Chapter 10, Section
5] собрано множество статей, в которых обсуждается ряд вопросов, связанных
с этой проблемой. В этих статьях, в частности, обсуждается, как добавлять новые
правила в существующий набор и как модифицировать ранее сформулированные правила.
Тот подход,
который использован в программе MORE, достаточно прозрачен и понятен. Но в этой
программе совершенно не затрагивается вопрос о независимости значений коэффициентов,
который был в свое время поднят Шортлиффом. В главе 6 мы видели, что применение
теоремы Байеса требует, чтобы свидетельства в пользу гипотез были независимыми,
если мы собираемся комбинировать их параметры с помощью простой мультипликативной
схемы.
Шортлифф предложил
сгруппировать зависимые свидетельства в одном правиле, а не распределять их
по множеству и рассматривать такую группу свидетельств в качестве "суперсимптома".
Оценку весомости этого суперсимптома можно сделать на основе аппроксимации конъюнкции
весов индивидуальных свидетельств. В программе MORE это предложение не реализовано,
но в ней имеется вся необходимая для этого информация, представленная в модели
событий. Анализ функционирования системы подтвердил предположение, что при нарушении
независимости свидетельств коэффициенты уверенности отклоняются в значительно
большем диапазоне, чем вероятности (см. об этом в [Buchanan and Shortliffe,
1984, Chapter 11, Section 5]).
Кан обратил
внимание на другие проблемы, обнаруженные при эксплуатации прототипа системы
MORE.
Пользователи предпочли
бы, чтобы программа MORE использовала каким-то образом модель событий для
формирования предположительных значений коэффициентов и задавала меньше вопросов
общего характера.
Такие концептуальные
понятия, как гипотезы и симптомы, с трудом воспринимаются экспертами
в большинстве предметных областей, связанных с промышленным производством,
чьи знания очень важны для систем, ориентированных на диагностику неисправностей.
Стандартный алфавитно-цифровой
интерфейс общения эксперта с системой показал свою полную непригодность даже
для выполнения экспериментов с прототипом системы.
Последнее
замечание еще раз подтверждает важность хорошо продуманного и удобного интерфейса
для успешного внедрения экспертной системы. До тех пор, пока пользователь будет
лишен возможности легко интерпретировать то, что он видит на экране, быстро
отыскивать необходимую ему информацию, он не сможет понять, что именно делает
система.
Привычный
для всех современных пользователей графический интерфейс значительно повышает
производительность работы с системой на всех стадиях ее развития.
Другой ряд
проблем связан с тем, что программа MORE реализована на языке OPS5, а модель
событий описывается в терминах сложных векторов, размещаемых в рабочей памяти.
Такое представление плохо подходит для представления знаний о причинно-следственных
отношениях, а потому при описании, модификации и сопровождении модели событий
разработчикам пришлось столкнуться с большими сложностями. Здесь скорее подошло
бы представление в виде структурированных объектов, которое было описано в главе
6.
За время,
прошедшее после создания программы MORE, на свет появилось еще множество других
программ извлечения знаний для последующего использования в экспертных системах,
выполняющих эвристическую классификацию. Одна из таких программ — TDE — будет
представлена в следующей главе.
Совершенствование стратегий
Работа инженера
по знаниям отнюдь не заканчивается после того, как эвристические знания будут
представлены в виде исходного набора порождающих правил. И исследователи, и
практики давно пришли к выводу, что процесс дальнейшего совершенствования базы
знаний не уступает по сложности процессу создания ее первой версии. Существует
довольно большой круг проблем, связанных как с обслуживанием большого набора
правил, так и с дальнейшим уточнением их на базе опыта, полученного в процессе
эксплуатации системы.
Только часть
из этих проблем может быть решена с помощью таких инструментальных средств извлечения
знаний, как система MORE. Создается впечатление, что некоторые аспекты этих
проблем являются следствием применения подхода, базирующегося на правилах, а
потому требуется определенное переосмысление способов организации набора правил.
В этом разделе мы попытаемся провести краткий обзор существующих на сегодняшний
день мнений на этот счет.
Уроки проекта GUIDON
В своей работе
[Clancey, 1983] Кленси раскритиковал использование неструктурированного
набора порождающих правил в экспертных системах, основываясь в основном на опыте
адаптации системы MYCIN для учебных целей в ходе выполнения проекта GUIDON.
Описание этого проекта можно найти в работе [Clancey, 1987, а]. Главный
аргумент Кленси состоит в том, что единообразный синтаксис правил в виде выражений
"если... то" скрывает тот факт, что такие правила часто выполняют
совершенно различные функции и соответственно должны конструироваться по-разному.
При нынешней постановке вопроса определенные структурные и стратегические решения,
касающиеся представления знаний о предметной области, присутствуют в наборе
правил неявно, а потому недоступны для коррекции или анализа в явном виде.
Мы уже видели,
что порождающие правила в обобщенной форме могут быть интерпретированы следующим
образом: если предпосылки Р1 и ... и Рт верны,
то выполнить действия Q1 и ... и Qn
Порядок перечисления
предпосылок Рi не имеет значения, поскольку Р1 ^ P2 эквивалентно
P2^P1 в любой стандартной логике. Однако порядок перечисления предпосылок влияет
на процедурную интерпретацию таких правил, поскольку он материализуется в логическом
программировании. Различные варианты упорядочения в совокупности могут породить
совершенно различные виды пространства поиска, которые будут анализироваться
по-разному, как мы это уже видели в главе 8. Аналогично, порядок применения
правил для достижения определенной цели будет влиять на порядок формирования
подцелей. Можно с уверенностью утверждать, что такой механизм разрешения конфликтов,
при котором первыми будут выполняться наиболее предпочтительные правила, в большинстве
случаев позволит намного сократить процесс поиска.
Проблема состоит
в том, что критерии, по которым можно было бы упорядочить правила и логические
фразы, представлены в наборе правил в неявном виде. Знания о том, какое правило
следует применить первым и в каком порядке анализировать члены совокупности
предпосылок в правиле, являются, по существу, метазнаниями, т.е. знаниями
о том, как применять знания. Вряд ли кто-нибудь будет спорить с тем, что такие
знания имеют важнейшее значение для правильного функционирования экспертной
системы, а получить их от эксперта и представить в удобном виде в программе
чрезвычайно трудно.
Кленси утверждал,
что система, основанная на правилах, нуждается в эпистемологической оболочке,
которая каким-то образом придает смысл специфическим знаниям о предметной области.
Другими словами, правила логического вывода, имеющие отношение к определенной
предметной области, часто оказываются неявно включены в более абстрактные знания.
Лучший способ объяснить эту мысль -- воспользоваться примером, описанным Кленси.
Рассмотрим следующее правило:
ЕСЛИ: 1) заражение
— менингит,
2) доступны
только косвенные свидетельства,
3) тип инфекции
— бактериальный,
4) пациент
принимает кортикостероиды,
ТО: имеются
основания предполагать наличие таких микроорганизмов e.coli (.4)
klebsiella-pneumoniae
(.2) или pseudomonas-aeruginosa (.1).
Порядок перечисления
предпосылок (конъюнктов) в этом правиле исключительно важен. Обычно стараются
сначала сформулировать гипотезу относительно природы инфекции (предпосылка 1),
а затем решать, являются ли свидетельства, относящиеся к этой гипотезе, косвенными
или нет (предпосылка 2). Бактериальный менингит— это подкласс, отличный от вирусного
менингита, и, следовательно, предпосылку 3 можно рассматривать как уточнение
предпосылки 1. И наконец, решение отложить проверку предпосылки 4 можно, вероятно,
отнести к категории стратегических. Если сделать эту последнюю предпосылку первой
в правиле, то пространство поиска будет иметь совершенно другой вид, причем
возможным следствием такого изменения будет отбрасывание всех последующих проверок,
если эта даст отрицательный результат.
Процесс представления
знаний приводит к тому, что знания становятся явными, но порождающие системы
оставляют множество общих принципов управления поиском представленными в неявном
виде. Возможно, этим и объясняется тот факт, что добавление или удаление правил
из существующего набора иногда дает совершенно неожиданный эффект. Декларативная
интерпретация правил на "человеческом" языке подводит нас к одному
выводу, а процедурная интерпретация этих же правил в системе может дать совершенно
иной результат.
Кленси предложил
довольно привлекательную методику анализа разных видов знаний, выполнение которого
может быть возложено на эпистемологическую оболочку системы, основанной на правилах.
Предлагается выделить такие компоненты знаний: структурные, стратегические и
поддерживающие.
Структурные знания
состоят из абстрактных категорий разных уровней, посредством которых представляются
знания о предметной области. Таксономия — это, возможно, один из самых очевидных
примеров источника таких знаний, которые обычно явно представляются в виде
порождающих правил. Знание, что менингит — это заражение, которое может быть
острым либо хроническим, бактериальным или вирусным и т.д., неявно представляется
в предпосылках многих правил.
Стратегические знания
— это знания о том, как выбрать порядок применения методов или выбора
подцелей, который минимизировал бы объем работы, необходимый для поиска' в
пространстве решений. Например, правило, которое гласит, что пациент, склонный
к определенной патологии (например, алкоголик), может с большей вероятностью
иметь необычную этиологию, должно побудить эксперта первым делом обратить
внимание на менее обычные причины заражения. Такие знания обычно используются
в сочетании со структурными знаниями. Например, такая эвристика может быть
связана скорее с бактериальным менингитом, чем с вирусным.
Поддерживающие знания
— - это знания, которые содержатся в причинно-следственной модели предметной
области и которые объясняют, почему в этой предметной области имеют место
определенные необычные явления. Так, в системе MYCIN имеется правило, которое
связывает употребление стероидов с наличием грамотрицательных микроорганизмов
в форме палочек, которые могут вызвать бактериальный менингит. В основе этого
правила лежит тот факт, что стероиды ослабляют иммунную систему. К тому же
такие знания увязываются со структурными знаниями, касающимися классификации
заболеваний и классификации микроорганизмов.
Очевидно,
что большая часть таких фундаментальных знаний не представлена в явном виде
в порождающих правилах. Структурные знания лучше всего представляются в форме
составных объектов данных, таких как фреймы, но некоторая часть управляющей
информации может быть представлена в процедурном виде. Поддерживающие знания,
как правило, включаются в сопроводительную документацию к программе, но они
должны быть доступны и для программы, формирующей объяснения сделанных заключений.
Попытка "втиснуть" разнородные знания в единый формат представления
отрицательно сказывается на ясности и прозрачности системы для пользователя,
но, тем не менее, позволяет весьма изобретательно использовать эффект от рационального
выбора способа упорядочения правил и предпосылок.
Структура задач в системе NEOMYCIN
Опыт, полученный
в ходе работы над системой GUIDON, был использован Кленси при разработке более
сложной модели выполнения диагностирования, которая получила название NEOMYCIN.
При создании базы медицинских знаний для этой консультационной системы была
использована доработанная обучающая программа GUIDON2. Главные отличия системы
NEOMYCIN от MYCIN состоят в следующем.
Использованная в системе
процедура вывода суждений наиболее четко отделена от содержимого порождающих
правил, как об этом было сказано в предыдущем разделе при описании программы
GUIDON.
Процедура вывода суждений
может использовать как прямую, так и обратную цепочку логического вывода.
Таким образом,
поток данных и управляющей информации в программе NEOMYCIN в большей степени
независим от порождающих правил и механизма их интерпретации, чем в системе
MYCIN, которая тратила большую часть рабочего времени на выполнение исчерпывающего
нисходящего поиска. MYCIN задавала пользователю вопросы и собирала необходимую
информацию в том случае, когда не находила такого правила, которое можно было
бы применить для формирования заключения, связанного с некоторым фактом. В этом
смысле MYCIN очень напоминала те системы логического программирования, в которых
использовалась технология "спроси у пользователя". Работая с пользователем
в интерактивном режиме, программа накапливала факты, недостающие для выполнения
доказательства. Процесс функционирования NEOMYCIN, напротив, лучше всего может
быть представлен как обработка множества разнообразных гипотез и тестов, среди
которых отыскивается наиболее предпочтительная гипотеза и сравнивается с конкурентами.
Следовательно, вопросы, которые система задает пользователю, диктуются желанием
выбрать между альтернативными предложениями, а не просто собрать факты для проведения
единственной линии суждений, которая может завершиться успехом или неудачей.
Кленси утверждает,
что поведение NEOMICYN ближе к модели поведения человека при диагностировании,
чем поведение MYCIN.
Например,
клиницисты обычно стараются определить диапазон возможных заболеваний, которыми
может страдать пациент, на основе ограниченного набора анализов. По Кленси такое
поведение можно рассматривать как стремление "ограничить пространство гипотез".
Одна из стратегий, используемых для этого, называется "сгруппируй и раздели",
т.е. задавшись какой-либо начальной гипотезой, правдоподобной при имеющихся
данных, врач сначала пытается собрать все другие гипотезы, учитывающие те же
признаки и симптомы, а затем разделить их на те, которые подходят к данному
случаю, и те, которые должны быть отброшены.
Стратегия
диагностирования в системе NEOMYCIN может быть представлена в виде дерева задач,
в котором задачей верхнего уровня является КОНСУЛЬТАЦИЯ, в которую в виде подзадач
входят ИДЕНТИФИКАЦИЯ ПРОБЛЕМЫ и СБОР ИНФОРМАЦИИ. Именно эта иерархия задач определяет
направление потока управления, а не неявная иерархия концептуальных правил,
прослеживаемая с помощью методики построения обратной цепочки рассуждений. В
дополнение к задаче "сгруппируй и раздели" существуют еще две стратегии,
которые помогают сформировать пространство гипотез: "попробуй и уточни"
и "задай обобщенные вопросы". Первая предполагает достаточно детальное
исследование определенной гипотезы, а вторая служит для сбора фоновой информации
(например, можно запросить у пользователя, не беременна ли пациентка, не перенес
ли пациент недавно хирургическую операцию).
Обеим задачам
— и "сгруппируй и раздели", и "попробуй и уточни" — отводится
свое место в контексте сложной иерархии патологий. Стратегия "сгруппируй
и раздели" включает анализ той части иерархии, которая находится выше первоначальной
гипотезы, и таким образом предпринимается попытка отыскать в этой части конкурирующие
гипотезы. Стратегия "попробуй и уточни" включает анализ той части
иерархии, которая находится ниже первоначальной гипотезы, и таким образом предпринимается
попытка дальнейшего уточнения диагноза.
В следующей
главе мы проанализируем весь процесс формирования гипотез и их тестирования
в иерархии альтернатив. Здесь же важно обратить внимание на принцип представления
в программе стратегии формирования логического вывода явно в структуре задач.
Те результаты, которые получил Кленси при разработке конкретной интеллектуальной
обучающей системы, могут быть с успехом распространены и на весь класс экспертных
систем.
Независимо
от того, всеми ли будет одобрена предложенная Кленси методика анализа, можно
с уверенностью заявить, что она открыла новые направления в исследованиях в
области экспертных систем. Точно так же, как задачи, выполняемые экспертными
системами, нуждаются в той или иной форме онтологического анализа, который помогает
систематизировать объекты и отношения между ними в конкретной предметной области,
они нуждаются и в эпистемологическом анализе видов знаний о способах решения
проблем в этой области, которыми обладает эксперт. Эти знания в совокупности
со знаниями о том, на какой стадии процесса логического вывода их следует применять,
как правило, слишком обширны. Поэтому для их представления недостаточно какого-то
одно формализма (например, порождающих правил) и одного режима управления (например,
построения обратной цепочки вывода).
Один из подходов
к построению экспертных систем (как, впрочем, и любых других программ) — спросить
себя, как распределить "сложность" между компонентами проекта. Существуют
два крайних варианта — спроектировать конструкцию с достаточно богатыми возможностями,
которую можно было бы относительно легко реализовать, или спроектировать простую
конструкцию, но сосредоточить главные усилия на стадии кодирования. Это пример
реализации принципа "бесплатных ленчей не бывает" в отношении программного
обеспечения. Ресурсы, сэкономленные на одном уровне, непременно придется растратить
на другом.
Рекомендуемая
литература
В
дополнение к системам, описанным в этой главе, читателям рекомендуется познакомиться
с системой MOLE [Eshelman and McDermott, 1986], [Eshelman et al., 1987], [Eshelman,
1988]. Это интересная оболочка для построения экспертных систем, решающих проблему
классификации. Она более интеллектуальная, а следовательно, и более сложная
для понимания, чем MORE, а потому мы не рассматривали ее в данной книге. Особенностью
этой системы является разделение между категориями накрывающих знаний {covering
knowledge) — знаний, относящихся к сопоставлению данных и гипотез, и дифференцирующих
знаний (differentiating knowledge) — знаний, которые позволяют сделать выбор
между конкурирующими гипотезами. Это разделение используется для структурирования
процесса извлечения знаний и уточнения сформированной базы знаний.
Подробное
обсуждение вопросов эвристической классификации и эпистемологического анализа
в системах, основанных на правилах, можно найти в работах [Clancey, 1993,а]
к [Clancey, 1993,b].
в системах, основанных на правилах,
1. Почему
в системах, основанных на правилах, сложно выполнять обратное прослеживание
на большую глубину?
2. Перечислите
шесть основных этапов проектирования систем, основанных на знаниях.
3. В чем разница
между стратегиями частотного упорядочения условий и установления связи
между симптомами и условиями в системе MORE?
4. Говорят,
что правила ожидаемости гипотез в системе MORE "неявно квалифицируют абстрактные
категории решений в пространстве гипотез". Что под этим понимается?
5. В чем заключается
значение фоновых условий в модели, используемой в MORE?
6. В чем состоит
отличие между моделями событий и правил в системе MORE?
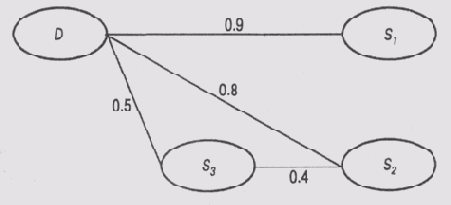
7. Какая ошибка
допущена при назначении коэффициентов уверенности на схеме модели событий, представленной
на рис. 12.4? На этой схеме D — это неисправность, а
S1,S2
и S3 -СИМПТОМЫ.
Рис. 12.4.
Модель событий
8. Какая ошибка
допущена при назначении коэффициентов уверенности на схеме модели событий, представленной
на рис. 12.5? На этой схеме Di — это неисправности, а Si
— симптомы.
Рис. 12.5.
Модель событий
9. Рассмотрите
CLIPS-программу, представленную во врезке 12.1.
I) Добавьте
в программу новые правила, соответствующие представленным ниже
IF: there
is an increase in chlorides, and
the drilling
fluid is undersaturated, THEN: there is salt contamination.
IF: there
is salt contamination
THEN: there
is an increase in viscosity.
ЕСЛИ: обнаружено
повышение уровня хлоридов и
пласт недостаточно
насыщен, ТО: существует солевое загрязнение.
ЕСЛИ: существует
солевое загрязнение,
ТО: повышается
вязкость.
II) Назначьте
значения коэффициентов уверенности дугам, соединяющим узлы на схеме рис. 12.1.
Включите также коэффициенты, связывающие процедуры анализа и результаты проведения
анализа. При установке значений коэффициентов соблюдайте ограничения, описанные
в разделе 12.2.3. Значения всех коэффициентов могут быть положительными.
III) После
этого измените определения шаблонов в тексте программы таким образом, чтобы
и гипотезы, и тесты имели соответствующие атрибуты.
IV) Измените
в программе правила таким образом, чтобы в них был реализован механизм распространения
коэффициентов уверенности по мере формирования гипотез и выполнения тестирующих
процедур. Комбинирование коэффициентов должно выполняться в соответствии с формулой
Z
= X+Y-XY,
где Z— новое
значение коэффициента уверенности, полученного на основании значений X и
Y, связанных с симптомами. Таким образом, если программа приходит к заключению
increase in low-specific-gravity solids (повышение доли твердых включений) исходя
из симптома increase in viscosity (повышение вязкости), который характеризуется
коэффициентом уверенности X, и результатов теста МВТ (тест синевы метилена),
которые характеризуются коэффициентом Y, то с помощью приведенной выше
формулы можно получить значение коэффициента Z, характеризующее степень достоверности
заключения.
V) Запустите
программу на выполнение и проверьте, как она будет реагировать на разные варианты
ответов на вопросы.
10. Приведенная
ниже модель диагностики взята из руководства владельца автомобиля BMW 320.
I) Представьте
приведенные ниже инструкции по поиску неисправностей в виде модели предметной
области, которая используется в системе MORE (см. рис. 12.1).
Симптом
Причины
Двигатель не
заводится
На стартер не
подается ток
Разряжена аккумуляторная
батарея
Поврежден провод,
подключенный к одной из клемм батареи
Поврежден соленоид
стартера
Плохой контакт
с "массой"
На стартер подается
ток
Заклинило шестерню
стартера
Поврежден двигатель
стартера
Двигатель проворачивается,
но не запускается
Нет искры между
электродами свечи
Загрязнены контакты
прерывателя Наличие влаги в распределителе
Неправильно подключены
контакты прерывателя
Поврежден конденсатор
(модель прежних лет выпуска)
Поврежден ключ
прерывателя
Повреждена катушка
(модель прежних лет выпуска)
Нет топлива в
жиклере карбюратора
Нет топлива в
баке Паровая пробка в системе подачи топлива
(в жаркое время
года)
Засорен жиклер
Неисправен бензонасос
Двигатель заглох
и вновь не
заводится
Заливает карбюратор
Заедание игольчатого
клапана
Поврежден поплавок
Неправильно установлен
уровень поплавка
Нет топлива в
жиклере карбюратора
Нет топлива в
баке Вода попала в систему подачи топлива
Замечания
в круглых скобках в столбце "Причины" следует рассматривать как фоновые
условия в системе MORE.
II) Постройте
на основе этой инструкции набор порождающих правил и разработайте соответствующую
CLIPS-программу. Фоновые условия должны вводиться пользователем в ответ на запросы
программы.