Общая характеристика инструментальных средств для построения экспертных систем
При разработке практически всех инструментальных средств за основу принимается методология автоматизации проектирования на базе использования прототипов. По отношению к программному обеспечению термин прототип означает "работающую модель программы, которая функционально эквивалентна подмножеству конечного продукта" [Schach, 1993]. Идея состоит в том, чтобы на ранней стадии работы над проектом разработать упрощенную версию конечной программы, которая могла бы послужить доказательством продуктивности основных идей, положенных в основание проекта. Прототип должен быть способен решать какую-либо из нетривиальных задач, характерных для заданной области применения. На основе анализа опыта работы с прототипом разработчики могут уточнить требования к системе в целом и ее Основным функциональным характеристикам. Работоспособность прототипа может послужить очевидным доказательством возможности решения проблем с помощью создаваемой системы еще до того, как на ее разработку будут потрачены значительные средства.
После всестороннего анализа прототип откладывается в сторону и начинается разработка рабочей версии программы, которая должна решать весь комплекс задач, определенных в спецификации проекта. Процесс разработки экспертной системы, как правило, состоит из последовательности отдельных этапов, на которых наращиваются возможности системы, причем каждый из этапов подразделяется на фазы проектирования, реализации, компоновки и тестирования. В результате после каждого этапа наращивания возможностей в распоряжении пользователя имеется система, которая способна справляться со все более сложными вариантами проблемы.
Такая методика проектирования несколько отличается от методики разработки программ других видов. При создании большинства программных продуктов чаще используется другая модель процесса— сначала разрабатывается спецификация продукта, затем выполняется планирование, проектирование компонентов, их реализация, компоновка комплекса и тестирование конечного варианта. Тот факт, что при разработке экспертных систем есть возможность сначала построить и всесторонне испытать прототип, позволяет избежать множества переделок в процессе создания рабочей версии системы. Но технология последовательного наращивания функциональных возможностей таит в себе и проблему интеграции новых функций с реализованными в предыдущих вариантах. Инструментальные средства разработки экспертных систем и создавались, в первую очередь, с целью преодоления возникающих при этом сложностей на основе модульного представления знаний, которое мы уже обсуждали в главах 5-8.
По своему назначению и функциональным возможностям инструментальные программы, применяемые при проектировании экспертных систем, можно разделить на четыре достаточно больших категории.
(1) Оболочки экспертных систем (expert system shells). Системы этого типа создаются, как правило, на основе какой-нибудь экспертной системы, достаточно хорошо зарекомендовавшей себя на практике. При создании оболочки из системы-прототипа удаляются компоненты, слишком специфичные для области ее непосредственного применения, и оставляются те, которые не имеют узкой специализации. Примером может служить система EMYCIN, созданная на основе прошедшей длительную "обкатку" системы MYCIN. В EMYCIN сохранен интерпретатор и все базовые структуры данных — таблицы знаний и связанный с ними механизм индексации. Оболочка дополнена специальным языком, улучшающим читабельность программ, и средствами поддержки библиотеки типовых случаев и заключений, выполненных по ним экспертной системой. Дальнейшим развитием оболочки EMYCIN явились системы S.1 и М.4, в которых механизм построения цепочки обратных рассуждений, заимствованный в EMYCIN, объединен с фреймоподобной структурой данных и дополнительными средствами управления ходом рассуждений.
(2) Языки программирования высокого уровня. Инструментальные средства этой категории избавляют разработчика от необходимости углубляться в детали реализации системы — способы эффективного распределения памяти, низкоуровневые процедуры доступа и манипулирования данными. Одним из наиболее известных представителей таких языков является OPS5, о котором уже шла речь в главах 5, 14. Этот язык прост в изучении и предоставляет программисту гораздо более широкие возможности, чем типичные специализированные оболочки. Следует отметить, что большинство подобных языков так и не было доведено до уровня коммерческого продукта и представляет собой скорее инструмент для исследователей.
(3) Среда программирования, поддерживающая несколько парадигм (multiple-paradigm programming environment). Средства этой категории включают несколько программных модулей, что позволяет пользователю комбинировать в процессе разработки экспертной системы разные стили программирования. Среди первых проектов такого рода была исследовательская программа LOOP, которая допускала использование двух типов представления знаний: базирующегося на системе правил и объектно-ориентированного (см. об этой программе в главе 5). На основе этой архитектуры во второй половине 1980-х годов было разработано несколько коммерческих программных продуктов, из которых наибольшую известность получили KEE, KnowledgeCraft и ART. Эти программы предоставляют в распоряжение квалифицированного пользователя множество опций и для последующих разработок, таких как КАРРА и CLIPS, и стали своего рода стандартом. Однако освоить эти языки программистам далеко не так просто, как языки, отнесенные нами к предыдущей категории.
(4) Дополнительные модули. Средства этой категории представляют собой автономные программные модули, предназначенные для выполнения специфических задач в рамках выбранной архитектуры системы решения проблем. Хорошим примером здесь может служить упоминавшийся в главе 15 модуль работы с семантической сетью, использованный в системе VT. Этот модуль позволяет отслеживать связи между значениями ранее установленных и новых параметров проектирования в процессе работы над проектом. Подобные модули управления семантической сетью можно использовать для распространения внесенных изменений на все компоненты системы.
В последующих разделах этой главы мы более подробно рассмотрим перечисленные выше категории.
Оболочки экспертных систем
Класс программ, которые мы называем оболочкой экспертной системы, создавался с целью позволить непрограммистам воспользоваться результатами работы программистов, решавших аналогичные проблемы. Так, программа EMYCIN [van Melle, 1981] позволяет использовать архитектуру системы MYCIN в приложении к другим областям медицины (напомним, что программа MYCIN была ориентирована только на заболевания крови). На базе EMYCIN были разработаны экспертные системы как для медицины (например, система PUFF для диагностики легочных заболеваний), так и для других областей знаний, например программа структурного анализа SACON.
Совершенно очевидно, что оболочки являются программами, ориентированными на достаточно узкий класс задач, хотя и более широкий, чем та программа, на основе которой была создана та или иная оболочка. Автор системы EMYCIN Ван Мелле (van Melle) одним из первых подчеркнул, что оболочки отнюдь не являются универсальной архитектурой для решения проблем. Разработанная им система EMYCIN ориентирована на те проблемы диагностирования с большими объемами данных, которые поддаются решению с помощью дедуктивного подхода в предположении, что пространство диагностических категорий стационарно. Кленси (Clancey) назвал класс подобных проблем "проблемами эвристической классификации" (см. главы 11 и 12). Однако этот подход значительно меньше подходит для решения проблем конструирования, т.е. объединения отдельных элементов в единый комплекс с учетом заданных ограничений (см. о методах решения таких проблем в главах 14 и 15).
К сожалению, нельзя слишком доверять рекомендациям о возможности использования оболочки для решения конкретных проблем. Дело в том, что мы еще не имеем настолько четкого представления о классификации задач, решаемых экспертными системами, чтобы можно было точно представить, к какому именно классу следует отнести конкретную систему. Классификации задач, пригодных для решения экспертными системами, посвящено довольно много работ, из которых следует отметить сборник [Hayes-Roth et al, 1983] и статью [Chandrasekaran, 1984]. Может создаться впечатление, что отличить задачу классификации от задачи конструирования можно и "невооруженным глазом", но это впечатление обманчиво. Множество проблем допускает решение разными способами. Например, в том подходе к задаче диагностирования, который использован в системе INTRN1ST, применяются методы, свойственные решению задач конструирования (см. об этом в главе 13). Сложные проблемы зачастую требуют применения комбинированных методов, в которых просматриваются черты, свойственные обоим подходам.
Мы еще остановимся на общем подходе к выбору инструментальных средств для построения конкретных экспертных систем ниже, в разделе 17.4. Но если речь идет конкретно об оболочках, то уже сейчас нужно отметить, что большинство коммерческих продуктов этого типа подходит только для тех проблем, в которых пространство поиска невелико. Как правило, в них применяется метод исчерпывающего поиска с построением обратной цепочки вывода и ограниченными возможностями управления процессом. Но некоторые современные оболочки, например М.4, как утверждают их создатели, могут применяться для решения широкого круга задач, поскольку они поддерживают множество функций представления знаний и управления, включая и моделирование прямой цепочки логического вывода, процедуры, передачу сообщений и т.п.
Простота языков представления знаний, применяемых в большинстве оболочек, является, с одной стороны, достоинством, а с другой — недостатком такого рода систем. На это обратила внимание Эйкинс в критическом замечании по поводу реализации экспертной системы PUFF на базе оболочки EMYCIN [Aikins, 1983].
Использованный в EMYCIN формализм порождающих правил затрудняет разделение разных видов знаний— эвристических, управляющих, знаний об ожидаемых значениях параметров. Мы уже отмечали в главе 12. что способноть системы дифференцировать виды знаний рассматривается многими исследователями как одно из главных условий обеспечения ее "прозрачности" для пользователя
Недостаточная структурированность набора порождающих правил в EMYCIN также затрудняет и восприятие новых знаний, поскольку добавление в базу знаний нового правила требует внесения изменений в различные компоненты системы. Например, нужно вносить изменения в таблицы знаний, содержащие информацию о медицинских параметрах. Это одна из проблем, решением которой гордятся создатели системы TEIRESIAS (см. главу 10).
Основным методом формирования суждений в EMYCIN является построение обратной цепочки вывода. При этом используется множество правил мета- и объектного уровня. В результате очень сложно формировать исчерпывающее и понятное для пользователя пояснение. Как отмечал Кленси ([Clancey, 1983])те решения, которые принимаются на этапе программирования правил, в частности касающиеся порядка и количества выражений в антецедентной части, могут разительным образом повлиять на путь поиска в пространстве решений в процессе функционирования системы (см. об этом в главе 12).
Другое критическое замечание Эйкинс касается не столько конкретной системы PUFF или EMYCIN, сколько функциональных возможностей систем, базирующихся на правилах, в общем, а следовательно, и всех оболочек, в которых порождающие правила используются в качестве основного языка представления знаний. Значительная часть экс-пертности — это знания о типовых случаях, т.е. довольно часто встречающихся в предметной области. Эксперты легко распознают известные типовые случаи и способны без особого труда классифицировать их в терминах идеальных прототипов даже при наличии определенных "помех" или неполных данных. Они интуитивно различают подходящие случаю или необычные значения исходных данных и принимают адекватное решение о том, как поступить в дальнейшем при решении проблемы. Такие знания практически невозможно представить в экспертной системе, если пользоваться только правилами в форме "условие-действие". Для этого потребуется значительно более сложный формализм, который сведет на нет одно из главных достоинств использования порождающих правил в качестве основного средства принятия решений.
Последнее замечание по поводу использования оболочек касается механизма обработки неопределенности. Такие оболочки, как М.1, уже включают в себя определенный формальный механизм работы с неопределенностью, например основанный на использовании коэффициентов уверенности. Однако большинство, если не все использованные в оболочках механизмы такого рода, не согласуются с выводами теории вероятностей и обладают свойствами, которые с трудом поддаются анализу. Конечно, конкретному методу обработки неопределенности при решении конкретной задачи в данной предметной области можно дать прагматическое обоснование, как поступил, например, Шортлифф (Shortliffe) по отношению к схеме обработки коэффициентов уверенности в системе MYCIN. Но вряд ли оправданно распространять этот аппарат на другие области применения, встроив его в оболочку.
По сравнению с первыми разработками современные оболочки более гибкие, по крайней мере, в том, что без особого труда могут быть интегрированы в большинство операционных сред, доступных на рынке программного обеспечения, и оснащены достаточно развитыми средствами пользовательского интерфейса. Так, оболочка МЛ может функционировать под управлением любой из операционных систем, используемых в персональных компьютерах, подключаться к базам данных, иметь средства для включения фрагментов программного кода на языках С, Visual BASIC и Visual C++. Оболочка поддерживает индивидуальную настройку пользовательского интерфейса и возможность формирования пояснений при ответах на вопрос "почему" в том же стиле, что и система-прародитель MYCIN.
Языки программирования высокого уровня
Языки высокого уровня являются в руках опытного программиста прекрасным средством быстрого создания прототипа экспертной системы, позволяют обеспечить гибкость процесса разработки при одновременном снижении материальных затрат и сокращении сроков выполнения проекта. Как правило, среда разработки таких языков обеспечивает совмещение интерфейса разработки и времени выполнения, что позволяет совместить вставку, редактирование и тестирование фрагментов программного кода. Но пользовательский интерфейс такой среды уступает интерфейсу оболочек по части "дружественности", что, правда, не мешает опытному программисту быстро ее освоить.
Языки описания порождающих правил, объектно-ориентированные языки и процедурные дедуктивные системы предоставляют проектировщику экспертных систем значительно большую свободу действий, чем оболочки. Особенно это касается программирования процедур управления и обработки неопределенности. Как отмечалось выше, обычно оболочка имеет встроенный режим управления и методы обработки неопределенности, которые не могут быть затем изменены в процессе построения на ее основе конкретной экспертной системы. Та гибкость, которую предоставляют программисту языки высокого уровня, особенно важна при создании экспериментальных систем, в которых заранее выбрать оптимальный режим управления вряд ли возможно.
Языки описания порождающих правил
Но, естественно, возможности языков высокого уровня также не беспредельны — каждый из них имеет свои ограничения. Например, в языке OPS5 возможности динамической памяти ограничены размещением векторов в рабочей памяти, что не позволяет строить в ней рекурсивные структуры данных, такие как графы или деревья. При разработке системы MORE (о ней речь шла в главе 12) из-за этого возникли серьезные сложности [Kahn, 1988]. Некоторые типы структур управления ходом выполнения, например рекурсивные и итерационные циклы, также с трудом реализуются в этом языке. В общем, это та цена, которую приходится платить за относительную простоту программного кода на языке OPS5 и эффективность его выполнения.
В ранних моделях систем, основанных на порождающих правилах, до 90% времени работы уходило на выполнение операций сопоставления условий. Но позднее Форджи обратил внимание на возможные источники низкой эффективности такого упрощенного подхода [Forgy, 1982]. Алгоритм сопоставления RETE, предложенный Форджи и реализованный в языках описания порождающих правил семейства OPS, базируется на двух наблюдениях.
В левых частях порождающих правил, которые размещаются в рабочей памяти, часто встречаются повторяющиеся условия. Если одно и то же условие встречалось в N правилах, то при прежнем упрощенном подходе выполнялось N операций сопоставления. Это пример внутрицикловой итерации (within-cycle iteration).
Простейший подход при сопоставлении условий предполагает просмотр в каждом цикле всех элементов рабочей памяти, хотя содержимое рабочей памяти от цикла к циклу изменяется очень мало. Форджи назвал это межцикловой итерацией (between-cycle iteration).
Предложенный Форджи алгоритм значительно снижает количество внутрицикловых итераций за счет использования сети сортировки, имеющей древовидную структуру. Выражения в левой части порождающих правил компилируются и включаются в эту сеть, а алгоритм сопоставления довольно просто определяет конфликтующее множество, просматривая состояние сети в текущем цикле. Количество межцикловых итераций сокращается за счет обработки множества лексем, которые являются индикаторами удовлетворения условий, размещенных в рабочей памяти. Это множество лексем отображает изменения, происходящие в рабочей памяти от цикла к циклу, и таким образом позволяет выявить те условия, которые подлежат проверке. Поскольку никаких других процессов управления, кроме цикла распознавание-действие, в системе не существует, то обработать полученное в результате конфликтующее множество не представляет особого труда. Механизм разрешения конфликтов выполняет это, не обращая внимания на другие аспекты текущего контекста вычислений.
Совершенно очевидно, что попытка использовать рекурсивные структуры данных потребует серьезного усложнения описанного процесса обработки правил. Точно так же и изменение режима управления приведет к тому, что механизм разрешения конфликтов вынужден будет анализировать дополнительную информацию. Разработчики языков, подобных OPS, всегда вынуждены искать компромисс между мощностью выразительных средств языка и эффективностью выполнения программного кода. До сих пор в среде исследователей предметом оживленных дискуссий является вопрос о том, удалось ли разработчикам OPS5 найти такой компромисс. Разработанные позже языки КЕЕ, КАРРА и CLIPS унаследовали от OPS5 синтаксис и механизм активизации правил. Все эти языки используют различные версии алгоритма RETE при формировании множества конфликтующих правил.
Преодоление недостатков программирования порождающих правил лежит не на пути усложнения существующих языков программирования, а скорее на пути объединения их с другими парадигмами программирования, позволяющими использовать рекурсивные структуры данных и управления. Примером такого объединения может служить комбинирование порождающих правил и фреймов, что позволяет сопоставлять условия, специфицированные в правилах, с содержимым слотов фреймов (см. главу 13). Для решения проблем управления в последнее время все чаще используется включение наборов правил в более мощную.вычислительную среду, которая позволяет работать со списками заявок и с множеством источников знаний (подробнее об этом — в главе 18).
Объектно-ориентированные языки
В главе 12 мы уже обращали ваше внимание на то, что формат правил хорошо согласуется с представлением знаний в форме "при выполнении условий Сь ..., С„ выполнить действие А", но менее подходит для описания сложных объектов и отношений между ними. Языки объектно-ориентированного программирования предоставляют в распоряжение программиста альтернативную программную среду для организации знаний в терминах декларативного представления объектов предметной области. Все, связанное с процедурной стороной решения проблем, распределяется между этими объектами, которые в таком случае располагают собственными процедурами и могут общаться друг с другом посредством протоколов передачи сообщений.
Другим приятным аспектом объектно-ориентированного программирования является возможность использования таких стилей представления знаний, которые не встречаются в исчислении предикатов и в порождающих правилах. Вместо "размывания" знаний об объекте предметной области между множеством правил или аксиом, на которые они ссылаются, эти знания концентрируются в едином месте — в программном описании объекта. Эта концентрация является виртуальной в том смысле, что нет необходимости, чтобы вся информация об объекте предметной области хранилась в соответствующем ему программном объекте, но любая команда или запрос к этому объекту может быть реализована только через посылку сообщения этому объекту.
В реальном мире вещей существует множество систем, в которых обмен энергией или информацией может быть представлен через обмен сообщениями между их компьютерными представлениями, и такая связь с технологией моделирования является очень важным достоинством данного подхода (см., например, [McArthur et al, 1986]). Не вызывает сомнений, что моделирование является одним из мощнейших средств решения проблем и что, рассматривая процесс логических рассуждений в контексте сложной системы, его иногда понять значительно легче, чем в контексте применения правил. Объектно-ориентированное программирование интегрирует символические вычисления в операционную среду, базирующуюся на средствах графического интерфейса, — меню, пиктограммы и т.п. Хотя само по себе оснащение экспертной системы этими средствами и не решает проблему ее прозрачности для пользователя, в руках умелого программиста они позволяют лучше представить пользователю процессы, происходящие в системе (см., например, [Richer andClancey, 1985]).
Основная сложность в использовании средств объектно-ориентированного программирования — уяснить для себя, что именно должен представлять программный объект по отношению к предметной области. В ранних версиях объектно-ориентированных языков, которые были предназначены в основном для разработки программ моделирования, такая проблема не возникала — программные объекты представляли объекты моделируемой системы. Например, при моделировании производственной линии отдельные программные объекты представляли те или иные механизмы этой линии, а сообщения между программными объектами — информационные, энергетические и материальные потоки. Задача программиста серьезно облегчалась тем, что существовало достаточно очевидное соответствие между программными и реальными объектами.
Но для того чтобы внедрить объектно-ориентированный стиль в проектирование экспертных систем, нужно задуматься над тем, как соотнести программные объекты с абстрактными понятиями и категориями предметной области. Объекты должны представлять факты и цели, наборы правил или отдельные гипотезы. Поэтому далеко не очевидно, какими сообщениями должны обмениваться такие объекты и какой смысл должен вкладываться в эти сообщения.
Многое зависит от того, на каком уровне абстракции будет использоваться объектно-ориентированный механизм. Если объекты представляют собой низкоуровневую реализацию определенной схемы формирования суждений, то отпадает необходимость в использовании каких бы то ни было эпистемологических последовательностей. Если же объекты будут видимы и для эксперта в процессе разработки и совершенствования системы, и для пользователя во время эксплуатации системы, то схема отображения понятий и категорий на программные объекты должна быть тщательно продумана.
Языки логического программирования экспертных систем
Критически оценивая первый опыт применения инструментальных средств типа оболочек при проектировании экспертных систем, в частности опыт использования EMYCIN, многие исследователи полагали, что более перспективным является альтернативный подход, основанный на логическом программировании (см., например, [Kowalski, 1982]). Например, предполагалось, что порождающие экспертные системы, аналогичные MYCIN, могут быть довольно просто реализованы на языке PROLOG [Clark and McCabe, 1982]. Правила можно представить в виде фраз Хорна (см. об этом в главе 8), в которых головной (позитивный) литерал соответствует заключению, а прочие (негативные) литералы будут соответствовать условиям.
Встроенный в PROLOG режим управления приблизительно соответствует стратегии обратного логического вывода, которая используется в системах, подобных MYCIN. Таблицы знаний и другие данные можно представить с помощью утверждений. Рекурсивные структуры данных — графы и деревья — можно организовать с помощью фраз языка PROLOG, которые содержат комплексные термы. Языковые средства PROLOG позволят программисту разработать собственный механизм обработки неопределенности, причем не исключается и использование коэффициентов уверенности.
С практической точки зрения, пользуясь языком PROLOG, программист в качестве "бесплатного приложения" получает в свое распоряжение следующие возможности:
индексированную базу данных фраз, которые можно использовать для представления правил, процедур или данных;
универсальный механизм сопоставления, который позволяет выполнять сопоставление данных и шаблонов, включающих переменные, и возвращать подстановку, которая может обеспечить их совпадение;
стратегию управления (поиск в глубину — depth-first search), основанную на правилах нисходящего поиска (фразы, которые размещены в базе данных ближе к "голове", обрабатываются первыми) и вычислении слева направо (подцели обрабатываются в том порядке, в котором они перечислены в списке).
Действительно, дедуктивную порождающую систему довольно ПРОСТО эмулировать на языке PROLOG. Можно без особого труда разработать и простой интерпретатор, реализующий стратегию построения прямой цепочки вывода. Модификация рабочей памяти выполняется операторами assert и retract, которые добавляют или удаляют формулы из базы данных. Вы уже знаете из главы 11, как можно организовать локальное управление ходом процесса в системе, основанной на фреймах, как организовать обработку значений по умолчанию и исключений, хотя эти методы и не вписываются в стандартную логику.
Успешный опыт применения идей логического программирования, в частности создание программы МЕСНО (см. главу 11), продемонстрировал ряд явных отклонений от синтаксиса исчисления предикатов первого порядка и его процедурной интерпретации в стандартной версии PROLOG. Некоторые семантические и синтаксические ограничения в программах МЕСНО и PLANNER до сих пор не преодолены в системах, базирующихся на языках логического программирования.
Многофункциональные
программные среды
Многофункциональные
программные среды позволяют опытному программисту экспериментировать при решении
новых классов проблем, выбирая подходящие сочетания различных методов, представленных
в имеющемся модульном наборе. Поскольку не существует единственного универсального
языка представления знаний для произвольной экспертной системы, у разработчиков
возникает желание объединить несколько различных схем представления, особенно
на этапе создания прототипа. Хотя исчерпывающей теории таких гибридных систем
и не существует, эксперименты с разными схемами представления и логического
вывода показали, что каждая из них имеет свои слабые стороны. Поэтому понятно
желание объединить разные методики таким образом, чтобы достоинства одних компенсировали
слабости других.Мы уже не раз обращали ваше внимание на то, что порождающие правила позволяют представить в программе эмпирически выявленные связи между условиями и действиями, между наблюдениями и гипотезами, но они значительно хуже подходят для представления отношений между объектами предметной области, включая и такие важнейшие, как отношения множество/элемент или множество/подмножество. Структурированные объекты, например фреймы, оказываются более удобным средством для хранения и манипулирования описаниями объектов предметной области, но применение таких знаний требует включения в программу фрагментов программного кода (например, на языке LISP), которые затем трудно анализировать. Рациональное зерно в первых попытках свести вместе стили, основанные на правилах и фреймах, состояло в том, чтобы объединить способность представлять объекты, характерные для фреймов, с возможностями связывать условия и действия с помощью порождающих правил.
Одной из первых многофункциональных сред искусственного интеллекта является LOOPS [Bobrow and Steflk, 1983], в которой в рамках единой архитектуры обмена сообщениями были объединены четыре парадигмы программирования, перечисленные ниже.
Процедурно-ориентированное программирование. Эта парадигма была представлена языком LISP, в котором активным компонентом являются процедуры, а пассивным — данные, несмотря на то, что в LISP процедуры сами по себе также являются данными, поскольку имеют вид списков. В рамках единой среды процедуры могут быть использованы для обработки внешних данных, в частности изменения значений общедоступных переменных.
Программирование, ориентированное на правила. Эта парадигма аналогична предыдущей, но роль процедур играют правила "условие-действие". В среде LOOPS наборы правил сами по себе являются объектами, которые можно рекурсивно вкладывать один в другой. Таким образом, часть "действие" одного правила, в свою очередь, может активизировать подчиненный набор правил. С множествами правил связываются управляющие компоненты, с помощью которых в простейшей форме выполняется разрешение конфликтов.
Объектно-ориентированное программирование. Структурированные объекты обладают свойствами и процедур, и данных, причем побочные эффекты обычно локализуются в пределах объекта. Обработка поступающих сообщений приводит к передаче данных или изменению их значений, но все манипуляции данными выполняются под управлением того компонента, который обратился к объекту. При этом вызывающий объект совершенно не интересует, как хранятся данные и как они модифицируются внутри объекта.
Программирование, ориентированное на данные. Доступ к данным и обновление данных запускает определенные процедуры, причем не имеет значения, почему изменен компонент данных, — то ли это результат побочного эффекта, то ли результат действия других процедур. С переменными, в которых хранятся значения данных, связываются определенные процедуры, подобно тому, как это делается в слотах фрейма, причем такие переменные часто называют активными величинами. В таких приложениях, как моделирование, этот стиль программирования оказывается довольно продуктивным, поскольку позволяет распространить эффект изменения какого-либо компонента на прочие, с ним связанные.
В рамках основной объектно-ориентированной парадигмы модули среды, поддерживающие разные стили программирования, можно комбинировать. Обычно условия в порождающих правилах и логические фразы связываются со значениями слотов структурированных объектов, а правила модифицируют значения этих слотов. Именно такой стиль объединения парадигм в настоящее время реализован в языке CLIPS.
В системах КЕЕ и LOOPS поведение объектов описывается в терминах множества порождающих правил, как это сделала Эйкинс (Aikins) в системе CENTAUR (см. об этой системе в главах 13 и 16). В средах КЕЕ и Knowledge Craft к перечисленным выше парадигмам добавлено и логическое программирование в стиле языка PROLOG. Новая версия КЕЕ, известная под названием КАРРА-РС, предоставляет в распоряжение программиста еще более широкий набор стилей для комбинирования правил, объектов и процедур.
17.1.
CUPS как многофункциональная среда программирования
для определения стандартных функций используется синтаксис, подобный LISP (сведения о LISP вы найдете в главе 4);
предоставляет в распоряжение разработчика родовые функции, аналогичные мультиметодам CLOS (см. главу 7);
располагает встроенным объектно-ориентированным языком COOL, который, в отличие от CLOS, включает и средства поддержки обмена сообщениями.
Обращение к стандартным функциям допускается включать в правую часть правил и в этом случае они выполняются так, как если бы являлись компонентом действий, специфицированных в правиле. Функции вызываются либо с целью получить побочный эффект, либо для использования явно возвращаемого функцией результата, который может быть сохранен с помощью оператора присваивания. Для работы с переменными в этом случае используется тот же синтаксис, что и в языке описания правил. Например, можно определить функцию between (X, Y, 2), оперирующую с целыми переменными. Эта функция будет проверять выполнение неравенств X[Y[Z:
(deffunction between (?lb ?value ?ub)
(and (<= ?lb ?value) (<=?value ?ub))),
Родовые функций (generic function) в CLIPS играют ту же роль, что и перегружаемые операторы в языке C++. Они обеспечивают возможность выполнять обработку разными методами последовательностей данных различного типа. Например, для конкатенации двух строковых значений оператором + можно следующим образом перегрузить этот оператор:
(defmethod + ((?a STRING) (?b STRING)) (art-cat ?a ?b)}
Тогда результатом вычисления выражения
(+ "dog" "fish") будет "dogfish".
В такой функции можно смешивать ограниченные и неограниченные параметры, причем ограничение может касаться типов данных на произвольном уровне обобщения, например числовых данных, целых, положительных целых чисел и т.д.
Вычисление родовых функций выполняется под "надзором" родового алгоритма диспетчирования (generic dispatch algorithm), который формирует индексированный список подходящих методов. Методы из этого списка затем вызываются соответственно уровню ограничений, указанному для параметров при обращении к функции. Алгоритм также принимает во внимание любые управляющие программные конструкции, представленные явно в тексте программы метода, например call-next-method или override-next-method.
Механизм передачи сообщений реализован по тому же способу, что и в языках SmallTalk и LOOPS, и требует, чтобы программист разработал свой обработчик сообщений для каждого отдельного класса. Диспетчер сообщений работает так? же, как в исполняющей системе языка CLOS, и различает обработчики типов primary, around, before и after.
В программе на языке CLIPS можно вызывать и функции, написанные на языке С, хотя это и выполняется несколько необычно. Исполняющая система CLIPS может выступать в качестве внедренного приложения, т.е. программа на CLIPS может быть скомпилирована и скомпонована с программой на языке С, которая будет вызывать CLIPS-фрагменты как подпрограммы. Это позволяет внедрять функции искусственного интеллекта в компоненты больших программных комплексов.
Дополнительные модули
Под дополнительными модулями понимаются те полезные программы, которые можно выполнять вместе с приложением. Как правило, такие программы реализуют некоторые специальные функции, как бы "снимая их с полки", причем для обращения к таким функциям не требуется что-либо программировать в основном приложении или заниматься его индивидуальной настройкой. Одним из примеров такого рода дополнительного модуля может служить программный пакет Simkit из комплекта среды КЕЕ. Этот пакет позволяет оснастить экспертную систему методами моделирования.
Другой функцией, которая поддерживается дополнительными модулями сред КЕЕ и ART, является механизм обработки множества различных контекстов логических рассуждений. В первом приближении можно считать, что контексты формируются теми ветвями в пространстве поиска, которые допускают использование более чем одного оператора. Рассмотрим представленный ниже сценарий, в котором имеются два правила, в каждом из которых условная часть удовлетворяется в текущем контексте рассуждений.
[Правило 1]
ЕСЛИ: сегодня рабочий день И
нет признаков недомогания, ТО: посетить занятия по информатике.
[Правило 2]
ЕСЛИ: сегодня рабочий день И
погода прекрасна, ТО: покататься на яхте.
В большинстве систем, основанных на порождающих правилах, выбор того единственного правила, которое будет активизировано, зависит от реализуемой стратегии разрешения конфликтов. Но в некоторых приложениях предпочтительным вариантом будет разделить текущий контекст на два разных, в одном из которых будет активизировано правило 1, а в другом — правило 2 (рис. 17.1). В каждом из этих контекстов будет сделано разное заключение, однако можно так организовать процесс, чтобы в каждый контекст была включена и информация из родительского контекста. Тогда в обоих контекстах будет учитываться, что сегодня понедельник и за окном прекрасная погода.
Теперь можно раздельно обрабатывать каждый контекст, причем в процессе дальнейшей обработки не исключено и аналогичное повторное разделение контекстов. В результате будет сформировано несколько вариантов решения проблемы.
Но можно в процессе обработки попасть в такую ситуацию, которая расценивается как неудача процесса вывода, например нарушение исходных ограничений. В нашем примере такой неудачей может быть заключение о том, что экзамен по информатике будет провален вследствие выполнения правила
[Правило 3]
ЕСЛИ: не посещать занятия по информатике, ТО: экзамен по информатике будет провален
Получение такого заключения должно было бы привести к тому, что линию рассуждений, порожденную, правилом 2, следует исключить из рассмотрения. Говорят, что соответствующий контекст отравлен. Как правило, удаляется вся цепочка рассуждений, вплоть до последнего "размножения" контекстов. Таким образом, контексты, выделенные утолщенными прямоугольниками на рис. 17.1, должны быть исключены из рассмотрения, и останется только одна цепочка, в соответствии с которой будет сделан вывод о необходимости посетить занятия по информатике, несмотря на все соблазны.
Таким образом, множество контекстов соответствует альтернативным вариантам решений или альтернативным предположениям на разных стадиях процесса логического вывода. Проблема обработки множества предположений и зависимостей между ними достаточна сложна и выделена в отдельное направление исследований, получившее наименование обработки правдоподобия (truth maintenance) или обработки причинности (reason maintenance). Детальнее мы остановимся на этом вопросе в главе 19, где будут рассмотрены альтернативные варианты организации вычислений.
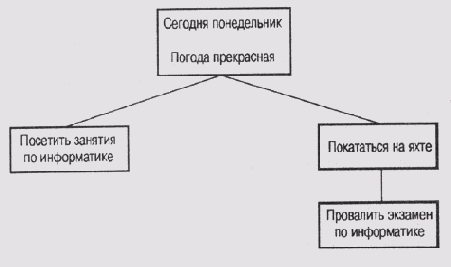
Рис. 17.1.
Пример множества контекстов
Мы постарались дать вам общее представление о возможностях инструментальных средств, применяемых при разработке и эксплуатации экспертных систем, не вдаваясь в подробности реализации разных моделей таких средств. В следующем разделе основное внимание будет уделено выбору подходящих средств, обучению методике работы с ними и внедрению этих средств в практику проектирования систем. Вы увидите, что каждая из этих фаз сопряжена со множеством проблем, но некоторых из них при рациональном подходе можно избежать.
17.2.
Логический вывод в разных контекстах
;; ШАБЛОНЫ
;; Fact представляет собой субъект с определенными ;; свойствами.
;; Поле "world" несет информацию о контексте, (deftemplate fact
(field subj (type SYMBOL))
(field attr (type SYMBOL))
(field world (type INTEGER))
)
;; Act представляет действие с объектом.
;; Поле "world" несет информацию о контексте.
(deftemplate act
(field action (type SYMBOL))
(field object (type SYMBOL)) (field world (type INTEGER))
)
;; Context имеет статус либо OK ,
;; либо NG (no good - плохой).
(def template context
(field id (type INTEGER)) (field status (type SYMBOL))
)
;; Модель мира в исходном состоянии. (def facts model
(context (id 1) (status OK))
(fact (subj weather) (attr sunny) (world 1))
)
; ; ПРАВИЛА
; ; Если дождя нет,
;; создать новый контекст, в котором можно
;; пропустить занятия.
(def rule skip
(fact (subj weather) (attr ?W&~rainy) (world ?C)) =>
(assert (act (action skip) (object class)
(world (+ ?C 1)))) (assert (context ((id (+ ?C 1)) (status OK)))
)
;; Если пропустить занятия,
;; то на экзамене вас ждет провал.
(defrule fail
(act (action skip) (object class) (world ?W)) =>
(assert (act (action fail) (object exam) (world (?W)))
)
;; Если контекст содержит действие fail, ;; пометить его маркером NG. (defrule poison
(act (action fail) (world ?W)) .
?C <- (context (id ?W) (status OK)) =>
(modify ?C (status NG))
)
Как только контекст будет помечен маркером NG, с ним можно будет выполнять операции, предусмотренные для отравленного контекста, например удалить все связанные с ним факты и действия (см. упр. 8 в конце главы).
Использование инструментальных средств
Хотя на этапе внедрения экспертной системы возникает очень много сложностей, до сих пор не предпринималось попытки их каким-либо образом систематизировать. В этом разделе мы ставили перед собой задачу познакомить пользователя с проблемами, наиболее часто возникающими при внедрении, и тем, как их избежать, как выбрать подходящие инструментальные средства для инженерии знаний, как организовать освоение и использование этих средств на практике. Возможно, приведенный ниже материал покажется вам в определенной мере противоречивым, но мы старались представить в нем как можно более широкий спектр существующих на сей счет мнений.
Характерные сложности и способы их избежать
В своей книге Уотерман перечисляет следующие "ловушки", поджидающие разработчика экспертной системы на этапе внедрения, и дает рекомендации, как их избежать [Waterman, 1986, Chapter 19].
Знания, касающиеся предметной области, слишком тесно переплетены с остальной частью программы. В частности, невозможно разделить эти знания и знания общего применения, касающиеся способов поиска в пространстве решений. Уотерман предполагает, что этого можно достичь, положив в основу организации базы знаний набор правил, хотя из замечаний, сделанных Кленси и Эйкинс, следует, что такая организация отнюдь не гарантирует достижение ожидаемого результата.
Та база знаний, которая сформировалась после извлечения и представления сотен правил в процессе опроса экспертов, может оказаться все-таки настолько неполной, что не позволит решить и простую задачу, поскольку в ней отсутствуют фундаментальные концепты предметной области или эти концепты представлены с ошибками. Уотерман рекомендует последовательно наращивать объем базы знаний, причем начинать с фундаментальных понятий. Это позволит еще на ранних стадиях разработки обнаружить указанную проблему. Он советует выполнять тестирование на каждом этапе разработки, используя для этого подходящие инструментальные средства инженерии знаний.
Среда разработки не располагает встроенными средствами формирования функций пояснения экспертной системы, а добавление таких функций в уже спроектированную систему — задача не из легких. Уотерман советует позаботиться о прозрачности экспертной системы с первых же шагов ее разработки. Это очень ценный совет, поскольку без хорошего "окна", через которое можно заглянуть в "машинный зал" программы, даже ее создатель не сможет понять, что же она на самом деле делает.
Система содержит чрезмерно большое количество слишком специфических правил. Это, во-первых, приводит в замедлению работы системы, а во-вторых, затрудняет управление ею. Уотерман рекомендует объединять, где только возможно, мелкие правила в более общие. Как мы видели в разделе 17.2, это не что иное, как стремление найти компромисс между более мощными правилами и правилами, более понятными.
В следующих трех разделах мы остановимся на важных и сложных вопросах, которые следуют из представленного ниже перечня.
Как подобрать подходящий инструментарий для проектирования экспертной системы?
Насколько в действительности такие средства просты в обращении?
Что такое "хороший стиль программирования" в выбранной среде разработки?
Ответы на эти вопросы оттодь не очевидны, но любой разработчик экспертных систем не избежит необходимости отыскать их. Тот поход, которым я воспользовался при поиске этих ответов, базируется частично на авторитетном мнении ведущих специалистов в этой области, а частично на анализе имеющегося опыта проектирования. В конце главы будут приведены некоторые полезные рекомендации, почерпнутые из литературы.
Выбор подходящего инструментария для разработки экспертной системы
В работе [Hayes-Roth et al, 1983, Chapter 1] собраны рекомендации по выбору подходящих инструментальных средств построения экспертной системы. В основу рекомендаций положено сопоставление характеристик задач, решаемых проектируемой экспертной системой, и необходимых функциональных возможностей инструментального комплекса.
Общность. Выбрать инструмент со степенью общности, не превышающей той, которая необходима для решения данной задачи. Например, если для данной задачи сложный механизм управления не является жизненно необходимым, использовать его не только расточительно, но и нежелательно.
Выбор. Выбор инструментария должен определяться в первую очередь характеристиками задачи, решаемой экспертной системой, а не другими привходящими обстоятельствами, например тем, что какой-то инструмент уже есть под рукой или знаком вам лучше остальных. Авторы цитируемой работы затем развили свою мысль, опираясь на классификацию экспертных систем, о которой речь пойдет ниже.
Быстрота. Если успех проекта зависит от срока разработки, то следует выбирать инструментальную среду со встроенными средствами формирования пояснений и развитым пользовательским интерфейсом. Разработка интерфейса — одна из наиболее трудоемких стадий проектирования системы, и чем большую часть этой работы можно переложить на среду разработки, тем быстрее будет завершен проект.
Испытание. Постарайтесь как можно быстрее провести испытания новой для вас инструментальной среды. Без сомнения, это полезный совет, однако открытым остается вопрос о том, как определить степень совершенства инструмента по результатам испытаний.
Важнейшим для выбора инструментальной среды является вопрос о способе определения характеристик проблемы, решаемой проектируемой экспертной системой. Этот вопрос обсуждается в работе [Stefik et al, 1983], где предлагается схема анализа, основанная на свойствах пространства поиска решения. Я позволил себе несколько обобщить предлагаемые авторами работы категории проблем и свел 11 Категорий к четырем, хотя основные принципы классификации остались прежними.
(1) Малое пространство решений, надежные данные и знания. Предполагается, что количество альтернатив, которые следует принимать во внимание при поиске решения, невелико и что все данные достоверны, а истинность правил не вызывает сомнений. В таком случае возможно выполнять исчерпывающий поиск в пространстве решений и при необходимости организовать возврат с прослеживанием в обратном порядке. Для решения проблем этой группы можно воспользоваться готовыми решениями, т.е. ранее созданной оболочкой на базе экспертной системы, решавшей аналогичную проблему в другой предметной области. Распространено мнение, что такой подход позволяет получить удовлетворительное, а не оптимальное решение проблемы, т.е. достаточно хорошее, а не лучшее решение. Учтите, что попытка отыскать оптимальное решение неизбежно сопряжена с перебором нескольких вариантов, что таит в себе опасность "комбинаторного взрыва".
(2) Ненадежные данные или знания. Если данные и/или знания ненадежны, т.е. существует опасность, что вводимые в систему данные недостоверны, а правила в базе знаний неоднозначны, то в экспертной системе нужно комбинировать информацию от нескольких источников и использовать в какой-либо форме логику неточных рассуждений. Авторы цитируемой работы весьма мудро решили воздержаться от конкретных рекомендаций, какой именно формализм неточных рассуждений следует выбрать, но круг кандидатов в любом случае довольно ограничен — формализм коэффициентов уверенности (см. главу 3) или нечеткой логики (см. главу 9). Обсуждение альтернативных методов, таких как использование функций доверия (belief function) и обновляемых оценок по Байесу (Bayesian belief updating), мы отложим до главы 21.
(3) Большое, но факторизуемое пространство решений. В литературе можно найти два варианта толкования термина "факторизуемый". Пространство поиска можно назвать факторизуемым, если существует "правило исключения", которое помогает уменьшить размер пространства на ранней стадии решения проблемы [Stefik et al, 1983, p. 99]. Есть и другое определение — пространство поиска является факторизуемым, если возможно разделить его на несколько независимых подпространств, которые можно обрабатывать по отдельности, причем для разных подпространств могут быть использованы и разные множества правил или отдельные подмножества одного и того же множества правил [Nilsson, 1980, р. 37]. Обычно такое разбиение выполняется на уровне решаемой проблемы, т.е. большая общая проблема разбивается на несколько более мелких. Успех в достижении главной цели, таким образом, оценивается по совокупности успехов в достижении более или менее независимых подцелей. .Если система потерпит неудачу в достижении одной из подцелей, то это будет означать неудачу и решения проблемы в целом. В любом случае для решения проблем такого класса наиболее предпочтительным является метод порождения и проверки (generate-and-test). Этот метод позволяет "обрезать" ветви, уводящие нас от решения, и разделить большое пространство решений на подпространства.
(4) Большое нефакторизуемое пространство решений. Пространство решений может оказаться и нефакторизуемым, в каком бы смысле мы не трактовали этот термин. Очень часто оказывается, что проблема проектирования допускает выработку частного решения какого-либо компонента только в контексте всего проекта. При сборке головоломки нельзя предсказать, найдено ли верное решение, пока последний элемент мозаики не станет на свое место. Общий подход к работе в большом пространстве поиска состоит в том, чтобы последовательно рассматривать его на разных уровнях абстракции, т.е. использовать варианты описания пространства с разным уровнем учета деталей. Решение проблемы таким методом часто называют нисходящим уточнением (top-down refinement) (см. об этом в главе 14). Применение метода нисходящего уточнения требует исключить, по возможности, обратное прослеживание между уровнями, реализация которого требует значительных вычислительных ресурсов. Но это срабатывает только в случае, если между уровнями нет тесного взаимодействия. Как было показано в главе 15, эффективной стратегией решения такого рода задач является стратегия наименьшего принуждения (least commitment), подкрепленная адекватным механизмом разрешения конфликтов.
В книге [Hayes-Roth et al, 1983] проблема выбора инструментальных средств представлена в терминах схемы рис. 17.2. Выяснив характеристики проблемы, решаемой проектируемой экспертной системой, можно определиться со свойствами пространства решений, которые перечислены выше. Затем они рассматриваются совместно с предполагаемыми характеристиками разрабатываемой системы — характеристиками порождающих правил, прямой цепочки вывода или возможностями формирования пояснений, — и вырабатываются желаемые характеристики инструментальной среды. Последние и позволяют подобрать нужную модель инструментальной среды. Нужно сказать, что все это прекрасно выглядит на картинке, но очень сложно реализуется на практике, хотя вряд ли кто-нибудь будет спорить с тем, что такой подход более логичен, чем какой-либо другой. Как показывает практика, большинство разработчиков явно или неявно следует именно такому подходу при создании экспертных систем.
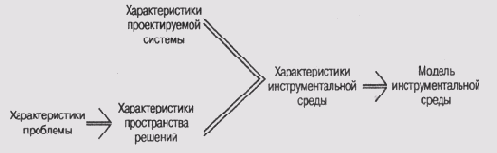
Рис. 17.2.
Схема выбора инструментальной среды проектирования экспертной системы
Эта среда предоставляет в распоряжение разработчика большее разнообразие парадигм программирования, чем какая-либо другая.
Среда оснащена лучшими средствами интерфейса и более развитыми средствами редактирования.
Поддержка этой среды со стороны фирмы-производителя организована лучше, чем у ее конкурентов.
Проанализировав возможные варианты, разработчики остановились на выборе в качестве основного инструментального средства компонента COTS среды КЕЕ.
При выборе инструментальной среды немаловажное значение имеет и то, насколько проста среда в обращении и как быстро проектировщики экспертной системы смогут овладеть методикой работы в этой среде, какую поддержку в этом готова оказать им фирма-изготовитель среды, и, конечно же, цена этого программного продукта.
Практическое освоение инструментальных средств
В рекламном проспекте множества программных средств для проектирования экспертных систем можно встретить утверждение, что данным инструментом "может успешно пользоваться даже непрограммист" или программист, малознакомый с технологиями искусственного интеллекта. В этом разделе мы попытаемся критически рассмотреть, насколько справедливы подобные утверждения, основываясь на имеющихся обзорах и опубликованных сведениях об опыте работы с такого рода программами. Имеющиеся в нашем распоряжении данные свидетельствуют, что, как правило, овладение типовыми инструментальными средствами проектирования экспертных систем не легче, чем овладение новым языком программирования. Даже опытный программист на начальном этапе освоения такой программы допускает ошибки, свойственные только студентам-новичкам, приступившим к изучению обычного программирования.
В работе [Ward and Sleeman, 1987] представлены результаты мониторинга процесса изучения опытными программистами методики работы с оболочкой для проектирования экспертных систем S.1 [Teknowledge, 1985]. Прародителем S.1 является известная система EMYCIN, а дальнейшим развитием — система М.4. Базы знаний в S.1 содержат множество объектов разного назначения — управляющие выражения, классы, типы классов, порождающие правила, иерархии значений и функций. Таким образом, выбранная для S.1 архитектура, с одной стороны, позволила расширить возможности, которыми обладала система EMYCIN, а с другой — весьма усложнила саму систему. Это замечание еще более справедливо в отношении системы М.4 (см. врезку 17.3).
Среда S.1 поддерживает четыре режима работы:
подготовка и редактирование базы знаний;
использование базы знаний для выполнения консультации, т.е. прогон программы;
выявление и устранение ошибок на стадии компиляции;
выявление и устранение ошибок на стадии выполнения.
Как показал опрос, программисты с трудом осваивают методику совместного использования этих режимов в процессе проектирования экспертной системы, хотя все они имеют большой опыт работы и владеют такими распространенными навыками, как работа с файлами, компилирование файлов, выполнение программ, поиск и устранение ошибок. Те сообщения об ошибках, которые формируются инструментальной средой, несут информации не больше, чем стандартные сообщения об ошибках в большинстве компиляторов обычных языков программирования. По этим сообщениям трудно отличить место возникновения ошибки от места в программном коде, в котором эта ошибка проявилась. Учитывая, что разработка базы данных ведется в режиме постепенного наращивания ее объема (а такая стратегия рекомендуется всеми авторитетными специалистами), переключение с режима на режим в среде разработки должно выполняться как можно проще, поскольку инженеру по знаниям приходится выполнять итеративные процедуры пополнения базы знаний значительно чаще, чем обычному программисту выполнять расширение функций программы.
Анализ опыта освоения этой инструментальной среды также показал, что если программисты отдают предпочтение простейшей стратегии отладки (эта стратегия включает этапы ввода данных, обращения к системе с запросом о значении какого-либо параметра на основе анализа небольшого множества правил и вывода результата), то они сталкиваются с рядом проблем, касающихся методов представления информации и управления поиском. По мере увеличения сложности проектируемой системы — увеличение объема базы знаний, включение в рассмотрение неопределенностей разного рода, включение в алгоритм работы системы дополнительных режимов — стратегия проектирования требует все более тщательной предварительной подготовки. Авторы обзора [Ward and Sleeman, 1987] пришли к выводу, что хотя освоение системы S.1 и не сложнее освоения нового языка программирования уровня PASCAL, но утверждать, что эта система проще, тоже нельзя.
Утверждение, что эту систему могут освоить люди, не имеющие навыков программирования, "не нашло подтверждения на практике", а если уж говорить совсем откровенно, то это не более чем рекламный трюк. Мой собственный опыт наблюдения за аспирантами, которые пользовались такого рода инструментальными системами, полностью согласуется с этими выводами.
В своих аналитических заметках Робинсон [Robinson, 1987] обращает внимание на то, что выбор инструментальной среды разработки экспертной системы представляет собой достаточно сложную задачу по следующим причинам:
большинство развитых сред разработки настолько дороги, что покупать их для проведения сравнительного анализа перед выбором подходящего не по средствам разработчикам;
время, необходимое для освоения навыков работы с системой и выявления ее сильных и слабых сторон, также слишком велико, а потому редко кто может себе позволить проводить сравнение конкурирующих моделей на практике;
терминология, которую применяют в документации изготовители разных систем, существенно отличается, причем это относится даже к понятиям и технологиям, ставшим стандартными в области искусственного интеллекта. Поэтому проводить сопоставление разных моделей по тем сведениям, которые публикуются в технической документации, также достаточно трудно.
Последнее замечание справедливо в отношении большинства программных продуктов, предлагающихся на рынке. Когда же речь идет о программных средствах, связанных с областью искусственного интеллекта, то новизна и необычность терминологии еще более усугубляет проблему. Уже давно в среде специалистов бытует мнение, что сравнение конкурирующих систем одного класса можно выполнять только после тщательного изучения их на практике.
17.3.
Правила и процедуры в инструментальной среде М.4
If recommended type = bolt and
recommended length = LENGTH and
recommended diameter = DIAMETER and
recommended thread_pitch = PITCH and
fastener(bolt, LENGTH, DIAMETER, PITCH) = BOLT then recommended fastener = BOLT
Построение прямой цепочки логического вывода моделируется конструкциями whenfound и whencached, которые выполняют функции демонов (см. главу 6). Например, оператор whencached разрешает выполнение определенного действия при установке значения определенного элемента данных. Выполнение такого действия, как правило, включает вызов процедуры, причем на его характер накладывается меньше ограничений, чем на характер действия, специфицированного в правой части порождающего правила в CLIPS. Например, в приведенном ниже фрагменте утверждается, что обнаружен самолет в определенной точке LOC в момент времени TIME, как только при считывании показаний сенсора в момент времени TIME обнаруживается наличие реактивного двигателя или пропеллера, и эти показания согласуются с аналогичными показаниями соседнего сенсора в предыдущий момент времени.
whencached (sensor_reading ( SENSOR, TIME) = SIGNATURE) = ((signature-type (SIGNATURE) = jet or
signature-type (SIGNATURE) = prop) and TIME -1 = PREVIOUS and cached ( sensor jreading) OTHER, PREVIOUS = SIGNATURE)
and
neighbor (SENSOR) = OTHER and location (SENSOR) = LOC and do ( set plane_detected ( LOC , TIME ) ) ) .
Насколько этот фрагмент программы читабелен, судить вам.
Процедуры в М.4 имеют синтаксис, весьма напоминающий синтаксис языка программирования С или PASCAL. Например, ниже приведен текст простой процедуры.
procedure ( determine_and_display recs ( FAULT ) ) =
{
f ind_recomendations( FAULT) ;
LIST := listof( recommendations (FAULT) };
COUNT := 1;
while (LIST == [ITEM | REST])
{
display ([COUNT, ". ", ITEM, nl]); COUNT := COUNT + 1; LIST := REST;
)
В этом фрагменте конструкция LIST == [ITEM (REST] заимствована из языка PROLOG. Она разделяет список LIST на головной элемент ITEM и хвост REST. Читатель может судить по этому фрагменту, насколько просто в среде М.4 программировать процедуры.
Стиль программирования
В литературе о программировании задач общего назначения часто обсуждается понятие "стиль программирования". Существует огромное множество книг о том, как писать программы, и кажется, что в них можно найти рекомендации на все случаи жизни.
Но эти рекомендации слабо соотносятся со спецификой программирования задач искусственного интеллекта и, в частности, систем, основанных на знаниях. Тот массив программ на языке LISP, который накопился за многолетнюю практику применения этого языка в программировании задач искусственного интеллекта, повергнет в ужас любого студента, проштудировавшего классические труды по структурному программированию. В программах зачастую используются нестандартные способы управления последовательностью выполнения операторов, непредусмотренное никакими канонами динамическое связывание переменных и совершенно "безответственные" манипуляции со структурами данных, такими как списки свойств. Но в последние годы ситуация здесь значительно улучшилась (с точки зрения приверженцев строго структурированного стиля оформления текста программы). Чтобы убедиться в этом, сравните, например, обзоры [Winston and Horn, 1983] и [Winston and Horn, 1981]. Как бы там ни было, но написать хорошую программу на языке LISP — это искусство, которым владеют единицы, хотя тексты большинства самых лучших программ искусственного интеллекта можно демонстрировать студентам в качестве наглядного пособия, как не надо писать программы.
Но, к сожалению, более чем 25-летний опыт совершенствования стиля программирования на LISP не востребуется разработчиками новых языков и инструментальных сред. Для меня, например, остается загадкой, что же представляет собой хороший стиль программирования по отношению к языку (и среде) КЕЕ. Мне приходилось наблюдать, как инженеры по знаниям, много лет проработавшие с языками структурного программирования, буквально падали в обморок от мешанины подключения процедур, комбинированных методов и активных значений в КЕЕ-программах. Это не следует рассматривать как серьезную критику в адрес функциональных возможностей языка, а скорее как констатацию того факта, что любые сложные инструментальные средства нуждаются в адекватной методологии пользования ими. Единственным исключением, на мой взгляд, является язык OPS5, о методике использования которого написана прекрасная книга [Brownston et al, 1985].
Некоторые максимы разработки экспертных систем
Чтобы не заканчивать эту главу на такой печальной ноте, я решил включить в последний раздел избранные максимы о построении экспертных систем, почерпнутые из классической работы Бучанана [Buchanan et al., 1983]. Следование им избавит проектировщика экспертных систем от опасности "наступить на грабли", многократно "опробованной" его коллегами. Другим прекрасным источником умных мыслей по тому же поводу может служить книга Преро [Ргегаи, 1990].
Нежизнеспособность некоторых проектов закладывается еще на самых ранних стадиях работы над ними. Приведенные ниже рекомендации помогут избежать этого.
Задача, которую предполагается решать с помощью проектируемой системы, должна быть вполне под силу эксперту-человеку.
Задача должна быть четко сформулирована.
Уже на первой стадии работы над системой подумайте над тем, как она будет совершенствоваться.
Особенно важно с самого начала очертить границы, которых должна достичь система в процессе эволюции. Для этого весьма полезно четко определить, что система не сможет делать. Лучше создать систему, которая сможет надежно решать ограниченную задачу, чем систему, претендующую на решение широкого класса задач, но дающую верное решение лишь время от времени. Конечно, надежность системы, т.е. степень ее правоты, можно оценить, только располагая соответствующим критерием этой самой правоты.
Тщательно отработайте поведение системы на наборе репрезентативных частных случаев и организуйте библиотеку таких случаев для проектируемой системы.
Отделите те знания, которые специфичны для определенной предметной области, от знаний, касающихся общей методики решения проблем. Старайтесь, насколько это возможно, упростить машину логического вывода в системе.
Убедитесь, что те примеры, которыми вы располагаете на этапе проектирования, репрезентативны. С самого начала постарайтесь либо самостоятельно разработать, либо заимствовать программный код, который упростит опробование принятых проектных концепций на этих примерах. Большую помощь в этом может оказать программная среда, которая позволяет подробно документировать сеанс работы с такой экспериментальной системой, включая и фиксацию всех вводимых пользователем данных. Проблема разделения различных видов знаний довольно подробно освещалась в главах 10, 11 и 16.
В отношении формулировки правил авторы упомянутых работ советуют следующее.
Если правило выглядит большим, то так оно и есть.
Если несколько правил очень похожи друг на друга, обратите внимание на те концепты проблемной области, на которых они базируются.
Как и при программировании задач общего назначения, следуйте золотому правилу "краткость — залог надежности". Наличие избыточности почти всегда является признаком того, что возможна какая-то упрощающая абстракция.
У Преро вы встретите и рекомендации, касающиеся этапа реализации экспертной системы. Ниже приведены некоторые из них.
Группируйте правила в отдельные множества.
В системе COMPASS все правила разделены на 18 групп. Только семь из них относятся действительно к процессу решения проблем, т.е. к тому, чем в обычной "бескомпьютерной" жизни занимается эксперт, а остальные обеспечивают выполнение функций поддержки, сбора данных и т.п. В системе используются также демоны, которые расширяют возможности выполнения действий, в частности организуя передачу сообщений между объектами (см. о демонах в главе 6).
Постарайтесь на самых ранних стадиях разработать систему соглашений об оформлении программы. Это придаст ей единообразный вид.
Как уже отмечалось выше, многие программисты, попав в ситуацию, когда можно использовать множество парадигм программирования, забывают о необходимости (или желательности) разрабатывать структурированный программный код. Единственный способ избежать этого — стараться реализовать похожие функции похожими методами во всех компонентах программного кода и оформлять их в едином стиле. Тогда, увидев в каком-либо модуле такой фрагмент кода, программист сможет легко распознать применяемый в данном фрагменте метод или подход. Особенно важно следовать этой рекомендации при разработке отдельных модулей базы данных или индивидуальных баз данных.
Пожертвуйте производительностью программы, если это сделает ее более понятной (в том числе и в смысле читабельности программного кода) и упростит сопровождение.
Программисты часто состязаются друг с другом, кто придумает более "сжатый" код, разобраться в котором постороннему зачастую просто невозможно. От такого кода в подавляющем большинстве экспертных систем нет никакого проку, поскольку в интерактивных консультирующих системах все равно большая часть времени уходит на диалог с пользователем и обращение к базам данных.
Бучанан также останавливается на проблеме разработки системы-прототипа, называя его условно системой Mark I. Он советует заняться разработкой такого прототипа, как только станут понятными два-три типовых примера (типовых задачи) для проектируемой экспертной системы. Однако действительным самородком в наборе советов является следующий.
Как только встанет вопрос о разработке второго прототипа, выбросите первый в мусорную корзину.
Многие проекты "пошли ко дну" лишь потому, что их авторы не могли избавиться от приверженности к первому варианту реализации собственных идей. В связи с этим возникает и такой вопрос, а когда имеет смысл прекратить отработку первого прототипа. Программисты часто впадают в состояние бесконечного "вылизывания" программного кода, которому все равно уже уготовано место на свалке. Конечно, при разработке второго прототипа нужно учитывать опыт создания первого, но опыт, а не программный код.
Процесс проектирования экспертной системы неразрывно связан с экспериментированием.
Этот принцип не утратил своей актуальности и на сегодняшний день. Тех, кто, прочитав какую-нибудь брошюру под броским названием "Экспертная система за NN часов", доверят ее проектирование первому встречному, ожидает горькое разочарование. Разработка приложения, которое будет успешно работать, требует настойчивости и терпения профессионального программиста, привлечения к работе опытного эксперта в своей области и определенного уровня принуждения со стороны руководства.
Рекомендуемая литература
Каталог экспертных систем, разработанных в 70-х — начале 80-х годов, опубликован в книге [Waterman, 1986, Chapters 27-28]. К сожалению, сейчас этот материал уже устарел. Критический анализ некоторых инструментальных средств для инженерии знаний, разработанных в 80-х годах, можно найти в работе [Laurent et al, 1986]. Обзор современных средств разработки экспертных систем и используемых при этом методологий, в который включены как системы, базирующиеся на правилах, так и более современные, базирующиеся на прецедентах (case-based), и объектно-ориентированные, приведен в работе [Harmon and Hall, 1993].
Читатели могут и самостоятельно сравнить характеристики имеющихся на рынке систем подобного назначения, заглянув на Web-сайты фирм Intellicorp, Teknowledge и Inference Corp. Немало полезной информации можно найти и в разделах FAQ (часто задаваемые вопросы) многочисленных групп новостей, имеющих отношение к проблематике искусственного интеллекта. Перечень ftp-серверов таких разделов можно найти по адресу http://hps.elte/hu/ai-faq.html. Но я не могу гарантировать, что представленная на них информация будет полной и злободневной.
сравнительный анализ возможностей инструментальных средств1. Проведите сравнительный анализ возможностей инструментальных средств разных классов — оболочек, языков программирования высокого уровня и многофункциональных сред— применительно к проектированию экспертных систем для задач классификации и проектирования. 2. Почему бывает желательно строить рассуждения в разных контекстах и почему некоторые контексты оказываются "отравленными"? 3. Насколько сказываются на конечном варианте проектируемой экспертной системы характеристики начального прототипа? 4. Критически проанализируйте характеристики той инструментальной среды разработки экспертных систем, с которой вы лучше всего знакомы. Анализ должен включать следующие моменты: I) детальное рассмотрение функциональных возможностей среды, наиболее привлекательных с вашей точки зрения; каким образом эти возможности облегчают проектирование? II) детальное рассмотрение тех характеристик среды, которые вы считаете неудачными; почему, на ваш взгляд, эти характеристики затрудняют работу? III) перечень дополнительных возможностей, которые, по-вашему, имеет смысл реализовать в этой среде разработки. В последнем разделе анализа выделите те дополнительные функции, которые довольно легко встроить в имеющийся вариант, и те, которые потребуют его значительной переделки или приведут к снижению производительности существующего варианта. 5. Попробуйте сформулировать рекомендации, касающиеся инженерии знаний, основываясь на собственном опыте, например на опыте выполнения упражнений из предыдущих глав этой книги. (Только не нужно приводить вариации Законов Мерфи.) 6. Постарайтесь задокументировать процесс освоения новой для вас инструментальной среды. Попробуйте классифицировать те трудности, с которыми вам довелось столкнуться. Например, можно начать с выделения проблем следующих видов. Проблема управления режимами работы среды — насколько болезненным был процесс освоения пользовательского интерфейса таких компонентов, как редактор, отладчик, интерпретатор и т.п. Проблемы освоения синтаксиса языка — как быстро вы освоились с правилами расстановки скобок, знаков препинания и т.п. Концептуальные проблемы. Сложности в освоении процедурных или декларативных конструкций. Например, методики работы с демонами, контекстами и т.п. 7. В этом примере демонстрируется, как в языке CLIPS организована интеграция правил и объектов. Основной механизм взаимодействия правил и объектов состоит в том, что действия, специфицированные в правилах, посылают сообщения экземпляру класса. Предположим, например, что мы имеем дело с экспертной системой, которая дает пользователю советы, касающиеся покупки музыкальных инструментов. Пусть это будет гитара, причем ее характеристики представлены содержимым слотов. Тогда в этой экспертной системе должны быть правила, подобные приведенному ниже. (defrule describe-guitar (option ?guitar) => (send (symbol-to-instance-name ?guitar) show) ) В этом правиле show — метод класса guitar, который выводит на экран содержимое слота экземпляра класса в нужном формате. Определение класса guitar может иметь следующий вид: (defclass guitar (is-a USER) (slot make) (slot model) (slot wood) (slot pickups)) Метод show этого класса можно представить следующим образом: (definessage-handler guitar show () (printout t "The " ?self:make " " ?self:model " is a " ?self:wood " guitar with " ?selfspickups " pickups.") ;; ?self:make " " ?self:model " это " ;; ?self:wood " гитара с " ;; ?self:pickups " звукоснимателем.") ) Для экземпляра этого класса (GibSG of guitar (make Gibson) (model SG) (wood mahogany) (pickups humbucking) ) метод выведет сообщение "The Gibson SG is a mahogany guitar with humbucking pickups." Включите подобную функцию в одну из программ-советчиков, которые предлагалось разработать в упражнениях предыдущих глав, в частности в упр. 7 главы 14 и в упр. 4 главы 16. 8. Разработайте два правила, которые будут удалять все действия и факты, связанные с "отравленным" контекстом, в примере, представленном в разделе 17.3.5. Почему таких правил должно быть два? |