Принципы организации систем с доской объявлений
В основу организации систем этого типа положена следующая идея [Corkill, 1991].
Представьте себе группу экспертов, которые сидят возле классной доски (или большой доски объявлений) и пытаются решить какую-либо проблему.
Каждый эксперт является специалистом в какой-то определенной области, имеющей отношение к решению проблемы.
Формулировка проблемы и исходные данные записаны на доске.
Эксперты пытливо вглядываются в то, что написано на доске, и каждый из них думает над тем, чем он может помочь в решении проблемы.
Если кто-либо из экспертов чувствует, что ему есть что сказать по этому поводу, он выполняет соответствующие вычисления и записывает результат все на той же доске.
Этот новый результат может позволить и другим экспертам внести определенный вклад в решение проблемы.
Процесс прекращается (а эксперты расходятся по домам), когда проблема будет решена.
Такая методика совместного решения проблем будет эффективна, если соблюдаются определенные соглашения, а именно:
все эксперты должны говорить на одном и том же языке, хотя при записи результатов на доске могут использоваться и разные схемы обозначений;
должен существовать какой-то протокол определения очередности "выступлений", который вступает в силу в ситуации, когда сразу несколько экспертов хватаются за мел и направляются к доске.
Эти соглашения есть не что иное, как уже знакомые нам по предыдущим главам схемы представления управления.
Если рассматривать работающую по такому принципу систему с точки зрения организации процесса вычислений, то в системе можно выделить следующие структурные компоненты. Знания о предметной области разделены между независимыми источниками знаний (KS— knowledge sources), которые работают под управлением планировщика (scheduler). Решение формируется в некоторой глобально доступной структуре, которую мы будем называть доской объявлений (blackboard). Таким образом, в этой системе все знания "как поступить" будут представлены не в виде единственного набора правил, а в виде набора программ. Каждый из компонентов этого набора может располагать собственным набором правил либо смесью правил и процедур.
Функции доски объявлений во многом сходны с функциями рабочей памяти в продукционных системах, но ее организационная структура значительно сложнее. Как правило, доска объявлений разделяется на несколько уровней описания, причем каждый уровень соответствует определенной степени детализации. Данные в пределах отдельных уровней доски объявлений представляют иерархии объектов или графы, т.е. структуры более сложные, чем векторы, которые использовались в рабочей памяти продукционных систем. В самых современных системах может быть даже несколько досок объявлений.
Источники знаний формируют объекты на доске объявлений, но это выполняется посредством планировщика. Обычно записи активизации источников знаний (knowledge source activation records) помещаются в специальный список выбора (agenda), откуда их извлекает планировщик. Источники знаний общаются между собой только через доску объявлений и не могут непосредственно передавать данные друг другу или запускать выполнение каких-либо процедур. Здесь есть определенная аналогия с организацией работы продукционных систем, в которых правила также не могут непосредственно активизировать друг друга: все должно проходить через рабочую память.
В этой главе будет представлен обзор становления архитектуры систем с доской объявлений и рассказано о том, как в настоящее время эта модель используется в качестве базовой при создании инструментальных систем общего назначения для проектирования экспертных систем. Принципы работы модели будут проиллюстрированы примерами, но основное внимание мы сосредоточим на общей архитектуре систем такого типа, а не на детальном описании отдельных моделей. В заключительном разделе будет рассказано о попытках повысить производительность системы с помощью методов параллельного поиска.
Системы HEARSAY, AGE и ОРМ
Архитектура на основе доски объявлений "выросла" из разработанной в конце 70-х годов системы распознавания речи HEARSAY [Erman et al., 1980]. Программирование компьютера с целью распознавания речи — это одна из наиболее сложных задач, за которые когда-либо брались специалисты в области искусственного интеллекта. Ее решение требует:
сложной обработки сигналов;
сопоставления физических характеристик звуковых сигналов с символическими элементами естественного языка;
выполнения поиска в большом пространстве возможных интерпретаций, в котором объединены эти разные по своей природе элементы.
Для решения этой проблемы была выбрана методика, основанная на выделении нескольких уровней абстракции описания анализируемых данных. Самым нижним является уровень физических акустических сигналов, на котором формируется звуковой спектр анализированных сигналов. На последующих уровнях информация проходит через напластование лингвистических абстракций со все более увеличивающимся уровнем общности понятий — фонемы, силлабы (созвучия), морфемы, слова, выражения и предложения.
Почему для HEARSAY-II выбрана такая архитектура
Приступая к разработке системы, ее создатели прекрасно понимали, что с каждым уровнем анализа связана отдельная отрасль знаний — анализ звуковых сигналов, фонетика, лексический анализ, грамматика, семантика, ораторское искусство. Ни одна из этих отраслей по отдельности не способна предоставить достаточно информации для того, чтобы решить проблему. Представим, например, что, пользуясь методами обработки акустических сигналов, мы смогли разложить исходный звук на фонемы. Но без дополнительной информации все равно не удастся выделить смысл выражений, подобных следующим: l scream (я восклицаю) и ice cream (мороженое) или please let us know (пожалуйста, дайте нам знать) и please lettuce no (пожалуйста,- без салата). Таким образом, хотя каждый отдельный вид (набор) знаний играет существенную роль в решении проблемы и каждый из них может быть представлен в программе более или менее независимо от остальных, автоматическое распознавание речи требует использования всех этих знаний совместно.
При распознавании речи исследователям приходится сталкиваться еще с одной проблемой, которую также можно отнести к числу ключевых, — проблемой неопределенности. Она проявляется на всех уровнях представления информации:
данные неполные и зашумлены;
отсутствует однозначное соответствие между данными на соседних уровнях; примером может служить соответствие между уровнями фонем и лексических единиц при анализе фраз / scream и ice cream;
важную роль играют лингвистический и смысловой контексты; интерпретация соседних элементов делает более или менее вероятными разные варианты интерпретации текущего сегмента.
Более традиционные подходы к распознаванию речи основаны на использовании статистических моделей из теории передачи информации для определения корреляционной связи между сегментами. Подход, базирующийся на знаниях, потребовал существенного пересмотра методов обработки неопределенности.
В работе [Erman et al., 1980] перечислены следующие требования, которым должна удовлетворять эффективно работающая система распознавания речи, основанная на знаниях.
(1) Из всех возможных последовательностей операций (частных решений) хотя бы одна должна приводить к корректной интерпретации.
(2) Процедура анализа имеющихся вариантов интерпретации должна давать корректному варианту более высокую оценку, чем другим конкурирующим вариантам. Другими словами, правильная интерпретация с учетом произношения должна быть оценена выше, чем другие варианты интерпретации, не учитывающие особенностей индивидуальной дикции.
(3) Вычислительные ресурсы (память и время вычислений), необходимые для отыскания правильной интерпретации, не должны превышать определенный порог. Система распознавания, которая через пару дней выдаст результат, пусть и правильный, и потребует памяти объемом несколько гигабайт, вряд ли кому-нибудь будет нужна.
В приведенном списке первое и третье требования в определенной мере противоречат друг другу. Для того чтобы корректное решение изначально присутствовало в пространстве гипотез, на стадии формирования гипотез поневоле приходится быть довольно расточительным, что при большом словаре может привести к комбинаторному взрыву элементов решений. Выход может быть найден только при использовании чрезвычайно остроумных эвристик. Таким образом, важнейшей предпосылкой достижения успеха в создании такой системы является разработка подходящей процедуры оценки вариантов (второе из перечисленных выше требований).
Использование источников знаний в HEARSAY-II
Для генерации, комбинирования и развития гипотез интерпретации в системе HEARSAY-II используется несколько источников знаний. Созданные гипотезы (интерпретации) разного уровня абстракции сохраняются на доске объявлений.
Каждый источник знаний можно считать в первом приближении набором пар "условие-действие", хотя они могут быть реализованы и в форме, отличной от порождающих правил (например, условия и действия могут быть в действительности произвольными процедурами). Поток управления в этой системе также отличается от потока управления в продукционных системах. Вместо того чтобы в каждом цикле интерпретатор анализировал выполнение условий, специфицированных в источниках знаний, источники знаний загодя объявляют об активизированных в них условиях, извещая, какой вид модификации данных будет влиять на выполнение этих условий. В результате система управляется прерываниями, а этот режим управления значительно эффективнее, чем режим циклического просмотра состояния, который является основным для продукционных экспертных систем. Такой режим напоминает использование демонов во фреймовых системах, где поток управления регулируется обновлением данных.
Источники знаний связываются с уровнями доски объявлений следующим образом. Условия, специфицированные в источнике знаний, будут удовлетворяться в результате обновления данных на определенном уровне доски объявлений. Источник знаний также может записывать данные в определенный уровень, причем не обязательно в тот же, который влияет на выполнение условий. Большинство источников знаний в системе HEARSAY-II организовано так, что они распознают данные на определенном уровне лингвистического анализа, а выполняемые ими операции относятся к следующему по порядку уровню. Например, некоторый источник активизируется данными на силлабическом уровне и формирует лексическую гипотезу на уровне слов.
В несколько упрощенном виде архитектура системы HEARSAY-II представлена на рис. 18.1. Стрелки, направленные от уровней доски объявлений к источникам знаний, указывают, данные какого уровня изменяют выполнение условий, специфицированных в источнике знаний. Стрелки в обратном направлении указывают, на какой уровень помещает данные тот или иной источник знаний. Ответвление от стрелки "действия" источника знаний к монитору доски объявлений означает, что изменение данных, выполненное одним источником знаний, фиксируется в мониторе и затем используется планировщиком для активизации другого источника знаний.
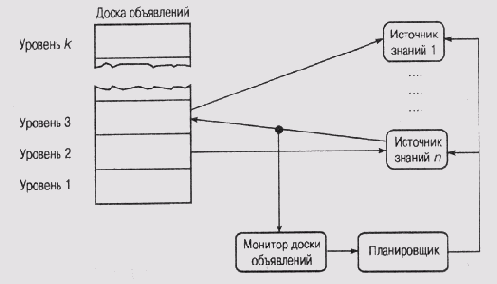
Рис. 18.1.
Упрощенная структурная схема системы HEARSAY-II
Система HEARSAY-III— оболочка для создания систем с доской объявлений
Система HEARSAY-III — это оболочка системы с доской объявлений, созданная на базе HEARSAY-II точно так же, как оболочка продукционной системы EMYCIN была создана на базе MYCIN [Erman et al, 1983]. В структуру HEARSAY-III, помимо источников знаний и доски объявлений, включена еще и реляционная база данных, с помощью которой выполняется обслуживание объектов доски объявлений и планирование. Это позволило существенно упростить механизм выбора записей активизации источников знаний. Язык управления базой данных АРЗ основан на языке InterLISP и позволяет программировать выполнение ряда функций оболочки [Goldman, 1978].
Структурные компоненты доски объявлений— это объекты языка АРЗ. Такой объектно-ориентированный подход упрощает представление и операции с данными и частными решениями.
Активизация источников знаний реализуется с помощью управляемых образцами демонов АРЗ (о демонах рассказано в главе 6).
АРЗ поддерживает и операции с базой данных контекстов (о контекстах см. в главе 17), а условия превращения контекста в "отравленный" представлены в виде ограничений языка. Контексты можно использовать для организации набора альтернативных способов продолжения вычислений.
Источник знаний в экспертной системе, создаваемой на базе оболочки HEARSAY-I1I, должен состоять из пускового образца (trigger), первичной программы (immediate code) и тела (body). Обнаружив соответствие между текущим содержимым доски объявлений и пусковым образцом, оболочка создает узел записи активизации для этого источника знаний и запускает на выполнение первичную программу. Спустя некоторое время запись активизации источника знаний выбирается планировщиком и тогда запускается на выполнение тело источника знаний, которое представляет собой программу на языке LISP. В состав HEARSAY-III входит простейший планировщик, который выполняет базовые функции планирования в экспертной системе: выбор очередной записи в списке актуальных и запуск на выполнение программного кода соответствующего источника знаний.
Пусковой образец имеет вид шаблона на языке АРЗ и представляет собой предикат, примитивами которого являются шаблоны фактов и произвольные предикаты языка LISP. Всякий раз, когда база данных модифицируется и оказывается, что текущие данные в ней сопоставимы со всеми шаблонами в образце, создается узел записи активизации, который хранит название источника знаний, пусковой контекст и значения переменных, полученные в результате сопоставления. При создании записи активизации выполняется первичная программа источника знаний. Эта программа, написанная на языке LISP, может связывать с узлом записи активизации некоторую информацию, которая позже может быть использована при выполнении тела источника. Первичная программа выполняется в пусковом контексте и в ней могут использоваться конкретизированные в этом контексте переменные образца. Значение, возвращаемое первичной программой после завершения, — это имя какого-либо из классов узлов доски объявлений. Затем запись активизации помещается на доску объявлений в качестве узла этого класса.
Некоторое время спустя базовый планировщик системы, который входит в состав оболочки HEARSAY-III, инициирует выполнение какой-либо операции с записью активизации. Как правило, это выполнение тела источника знаний в пусковом контексте с означенными переменными. Каждый сеанс выполнения тела источника знаний неделим — это аналог транзакции в системах управления базами данных. Сеанс продолжается до полного завершения и не может быть прерван для активизации любого другого источника знаний.
При проектировании прикладной экспертной системы на базе оболочки HEARSAY-III нужно самостоятельно разработать процедуру базового планировщика, которая будет вызываться оболочкой после запуска. Эта процедура может быть достаточно простой, поскольку большая часть знаний о планировании может быть включена в планирующие источники знаний. Например, базовый планировщик может представлять собой простейшую циклическую процедуру, которая извлекает первый элемент из очереди, организованной планирующими источниками знаний, и запускает его выполнение. Если обнаруживается, что очередь пуста, базовый планировщик завершает работу системы.
Основные достоинства среды HEARSAY-III — это, во-первых, использованный в ней режим управления, который предоставляет разработчикам прикладных экспертных систем большую свободу в выборе способов представления и применения эвристик отбора активизируемых записей источников знаний, а во-вторых, структуризация множества объектов доски объявлений.
Инструментальные среды AGE и ОРМ
Инструментальная среда AGE представляет собой набор заранее сформированных модулей — компонентов, из которых пользователь может создавать прикладную экспертную систему [Nii and Aiello, 1979]. Компонент— это набор переменных и функций на языке LISP, которые описывают как реальные, так и концептуальные объекты. Из компонентов можно "собирать" и продукционную экспертную систему, использующую стратегию обратной цепочки логического вывода, как в MYC1N, и систему на основе доски объявлений. Источник знаний в структуре с доской объявлений представляет собой помеченный набор порождающих правил, с которым связаны предусловия для его активизации. Эти предусловия специфицируют ситуации, в которых применимы правила из данного источника. По отношению к каждому источнику может быть использована как стратегия активизации единственного правила, так и стратегия параллельной активизации нескольких правил.
Описания концептуальных и реальных объектов, а также связей между ними могут иметь объектно-ориентированное представление, как это сделано в пакете UNITS, созданном в среде AGE [Stefik, 1979]. (Пакет UNITS является прототипом системы КЕЕ, о которой упоминалось в главе 17.) Правила в источниках знаний имеют доступ к управляющей информации на доске объявлений. В результате одни источники знаний могут манипулировать другими и всю конструкцию можно считать частью управляющей структуры.
Правила в источниках знаний могут быть активизированы в разных режимах применимости — когда выполняются все условия, специфицированные в левой части правила или когда выполняется только часть этих условий. Среда предоставляет пользователю (разработчику экспертной системы) определить, какой именно режим применимости следует использовать в отношении того или иного правила. В состав среды входит набор простых функций оценки (например, функция "все-условия-должны-быть-истинными"), которые пользователь может встраивать в проектируемую систему. В правой части правил специфицируются изменения, которые нужно внести в структуру гипотезы или в базу знаний. Возможные изменения разбиты на три группы (типа):
события— реальные изменения элементов гипотезы, связей или базы знаний; информация о таких изменениях немедленно помещается в список событий на доске объявлений и становится доступной другим источникам знаний;
предполагаемые изменения структуры гипотезы или базы знаний помещаются в список ожидаемых на доске объявлений; этот список также доступен другим источникам знаний как часть управляющей информации;
желательные изменения структуры гипотезы или базы знаний — цели; эти изменения помещаются в список целей.
Те изменения, которые вносятся правилами, можно связать с параметром, отражающим степень уверенности в импликации, которую необходимо вывести при условиях, указанных в левой части правила. Этот параметр конструктор экспертной системы должен выразить в тройках "атрибут-значение-вес" элемента гипотезы, задействованного при выполнении правила. Веса в правилах и значения параметров, присвоенные атрибуту гипотезы, должны быть каким-то образом объединены. В целях достижения максимальной гибкости среда AGE предлагает пользователю задать предпочтительный метод вычисления такой комбинированной оценки в виде функции, которая служит для корректировки весов. Пользователь может выбрать либо одну из встроенных в среду функций, либо разработать ее самостоятельно.
В работе [Aiello, 1983] описаны три варианта реализации экспертной системы PUFF с помощью среды AGE, в которых использованы разные модели структуры.
Экспертная система ОРМ [Hayes-Roth, 1985], предназначенная для планирования выполнения множества задач, представляет собой систему управления доской объявлений. В ней решение проблем из предметной области и управления объединены в едином цикле управления, причем не предусматривается использование какой-либо заранее запрограммированной стратегии управления. Выбор очередной операции выполняется на основании независимых суждений о том, какие операции желательны в текущей ситуации и какие возможны, причем при принятии решения используется комбинация множества управляющих эвристик. Основное назначение системы — планирование мероприятий. Программа использует четыре глобальных структуры данных.
(1) Доска объявлений, которая разбита на пять "панелей":
метапланирование (цели планирования);
абстракции планирования (решения о планировании);
база знаний;
план (выбранные действия);
исполнение (выбранные для выполнения записи активизации источников знаний).
(2) Список событий для хранения изменений, вносимых на доску объявлений.
(3) Карта соответствия, указывающая пункты проведения мероприятий.
(4) Список актуальных записей источников знаний.
Источники знаний содержат в своем составе и пусковые образцы, с помощью которых определяется соответствие источника знаний текущему узлу на доске объявлений, и программы проверки, с помощью которой выясняется, возможно ли применение определенной записи активизации в текущей ситуации. При планировании работы с источниками знаний предпочтение отдается тем записям активизации, которые влияют на текущий узел доски объявлений.
Хотя при разработке системы ОРМ предполагалось использовать ее как инструмент моделирования процесса принятия решений человеком, у нее есть несомненные достоинства и с точки зрения системной организации. Возможность интегрировать управляющие знания в однородную среду знаний открывает довольно интересные перспективы для реализации метауровневой архитектуры.
Среда с доской объявлений ВВ
В работе [Hayes-Roth et al, 1988] описана среда ВВ для построения экспертных систем, использующих модель доски объявлений с трехуровневой структурой. Система четко разделена на три уровня — прикладные программы, оболочки задач и архитектуры, — которые, несмотря на такое явное разделение, довольно тесно интегрированы. При разработке акцент сделан на те интеллектуальные системы, которые должны обладать способностью судить о собственном поведении, используя для этого знания о возникающих событиях, состояниях, действиях, которые можно предпринять, и отношениях, существующих между событиями, действиями и состояниями.
Уровни абстракции в среде ВВ
На верхнем уровне абстракции — уровне архитектуры — представлен набор базовых структур знаний (представляющих действия, события, состояния и т.п.) и механизм, который служит для отбора и реализации действий. Этот вид знаний обособлен не только от конкретной предметной области, но также независим и от метода решения отдельных задач и проблемы в целом. Идея состоит в том, что архитектура проектируемой системы должна обеспечивать поддержку решения разнообразных задач в множестве предметных областей (точно так же и способность человека мыслить не связана с какой-либо отдельной задачей или областью знаний). На этом же уровне представлены и способности рассуждать о поведении, обучаться и пояснять свои действия.
Оболочки задач — это следующий, более низкий уровень абстракции. На нем представлены промежуточные структуры знаний о действиях и событиях, касающихся определенной задачи, например о неисправностях в тестируемой системе или о конструкциях, удовлетворяющих определенным ограничениям. Методы, которые представлены на этом уровне, могут быть общими для нескольких родственных предметных областей. Здесь есть прямая аналогия с тем, как человек планирует свои действия в разных ситуациях, используя ограниченный набор опробованных стратегий. Примером такой оболочки может служить система ACCORD, которая решает задачу планирования сборки изделия из множества компонентов.
Наиболее специфический уровень — прикладной, на котором сконцентрированы структуры знаний о конкретных действиях в конкретных обстоятельствах и методы решения конкретных классов проблем. Примером системы, в которой используется этот уровень, являются PROTEAN — система вывода структуры протеинов при заданных ограничениях [Hayes-Roth et al, 1986] и SIGHTPLAN — система проектирования архитектурных планировок [Tommelein et al., 1988].
h1>
Системы ВВ1 и ACCORD
Перечисленные
выше особенности архитектуры среды ВВ можно проиллюстрировать на примере систем
ВВ 1 и ACCORD.
Как и в других
системах, использующих модель доски объявлений, в системе ВВ 1 источники знаний
активизируются событиями на связанном с этими источниками уровне доски объявлений,
в результате чего формируется запись активизации источника знаний [Johnson
and Hayes-Roth, 1986]. Собственно активизация источника знаний откладывается.
Запись активизации находится в списке заявок до тех пор, пока не будут выполнены
все предусловия, которые, как правило, связаны со свойствами объектов доски
объявлений. Но помимо доски объявлений и источников знаний предметной области,
система ВВ1 управляет также и источниками знаний управляющей доски объявлений.
Планировщик организует исполнение активизированных источников знаний обоих типов
— и предметной области и управления — в соответствии с планом, который динамически
корректируется компонентами управляющей доски объявлений. Результат активизации
источника знаний сказывается на состоянии уровня доски объявлений, подключенного
к его выходу, и таким образом активизируются другие источники знаний.
Основной цикл
работы ВВ1 состоит из следующих операций.
(1) Интерпретация
действия, предусмотренного очередной записью активизации источника знаний.
(2) Обновление
списка заявок — добавление в него новых записей, порожденных изменением
данных, вызванных предыдущей операцией, — и сортировка всех записей в списке
заявок в соответствии с текущим планом.
(3) Выбор
записи с наибольшим рейтингом.
ACCORD — это
язык для представления знаний, касающихся выполнения задач сборки многокомпонентных
объектов с соблюдением заданных ограничений. Метод сборки компонентов не предусматривает
какого-либо наперед заданного режима управления, но требует принятия множества
решений при конструировании отдельных узлов. Основной механизм представления
предполагает использование иерархии понятий — типов, представителей и экземпляров.
Типы определяют
родовые понятия и их роли, в отличие от того, как это делается в семантических
сетях с помощью связей типа IS-A (это есть). Представители — это конкретизированные
типы, а экземпляры — объекты, созданные при означивании представителей в определенном
контексте. Понятия могут иметь атрибуты и входить в определенные отношения с
другими понятиями. Здесь имеется определенная аналогия со связями типа IS-A
в семантических сетях.
Оболочка,
таким образом, предоставляет в распоряжение пользователя скелетные ветви иерархической
структуры объектов-компонентов, которые должны образовать единый ансамбль, контексты
их компоновки и ограничения, в которые эта компоновка должна "вписываться".
Например, ACCORD представляет следующие роли, независимые от предметной области:
arrangement (сборка), partial-arrangement (узел) и included-object (компонент).
Между ролями имеется отношение типа includes (включает). Среди ролей included-object
важное место отводится роли anchor (якорь), представляющей объект, положение
которого в общем ансамбле (сборке) должно быть фиксированно, и таким образом
определяет локальный контекст для узла. Ролью anchoree представлен объект included-object,
который имеет, как минимум, одно ограничение, связанное с его положением относительно
объекта anchor.
Система PROTEAN
Система PROTEAN
[Hayes-Roth et al., 1986] предназначалась для идентификации трехмерных
структур протеинов. Комбинаторные свойства пространства решений не позволяют
использовать методику исчерпывающего поиска, поэтому в программе реализована
стратегия последовательного уточнения на основе определенного плана управления.
При формировании
гипотез в системе PROTEAN локальные и глобальные ограничения используются в
комбинации. Локальные ограничения дают информацию о близости атомов в молекуле,
а глобальные — информацию о размерах молекулы и ее форме.
Вместо того
чтобы пытаться применить все ограничения к анализируемой молекуле в целом, в
системе PROTEAN успешно используется подход "разделяй и властвуй"
при определении частных решений, которые могут включать разные подмножества
элементов структуры протеина и разные подмножества ограничений.
Логический
вывод в системе PROTEAN двунаправленный и базируется на использовании доски
объявлений с четырьмя уровнями. Когда реализуется нисходящая стратегия (сверху
вниз), система использует гипотезы на одном уровне для определения положения
на другом, более низком; когда же реализуется восходящая стратегия (снизу вверх),
гипотезы на одном уровне используются в качестве ограничений для другого, более
верхнего.
Управляющие
знания в системе PROTEAN также разделены на разные уровни абстракции. Самый
верхний уровень определяет стратегию решения конкретной проблемы. На промежуточном
уровне система фиксирует отдельные этапы, необходимые для реализации общей стратегии,
а потому программа всегда может получить информацию о том, на какой стадии решения
она находится. Нижний уровень управления отвечает за ранжирование записей активизации
источников знаний.
Система PROTEAN
представляет для нас особый интерес тем, что она демонстрирует, как в рамках
архитектуры ВВ1 можно комбинировать независимые от предметной области механизмы
логического вывода и зависимые от предметной области знания об ограничениях.
Интеграция стратегий логического вывода
Джонсон и
Хейес-Рот обратили внимание на то, что рассуждения, ведомые целью, можно объединить
и с иерархическим планированием, и с выбором подходящего контекста в PROTEAN
[Johnson and Hayes-Roth, 1986]. Стратегию формирования суждений на основе
заданной цели нужно использовать в тех случаях, когда перед выполнением желаемой
операции нужно выполнить некоторые подготовительные процедуры. Например, в записях
активизации источников знаний, представляющих желаемые операции, могут быть
специфицированы определенные предварительные условия, и эти предусловия можно
трактовать как подцели, достижение которых будет способствовать активизации
указанных источников знаний.
Знания о целях
можно дифференцировать, различая причины, побуждающие нас сформировать ту или
иную цель. Причинами могут быть стремление
(1) выполнить
определенную операцию (например, активизировать определенный источник знаний,
представленный в записи активизации);
(2) установить
определенное состояние, которое будет способствовать удовлетворению предусловий
активизации;
(3) вызвать
определенное событие, которое поставит в очередь запись активизации источника
знаний с желаемой операцией.
Цели первого
типа представляют операции, которые приводят к удовлетворению предусловий.
Цели второго типа имеют отношение к ситуации, когда текущий контекст
не позволяет запустить на выполнение выбранную запись. В этом случае можно воспользоваться
родовым источником знаний, который в ВВ1 имеет наименование ЕпаЫе-Priority-Action.
Этот источник и активизируется в тех случаях, когда не удовлетворяются предусловия
в выбранной записи. Цели третьего типа имеют отношение к ситуации, когда
в списке выбора отсутствуют записи, которые могут привести к выполнению желаемой
операции. В этом случае потребуется вмешательство специального источника управляющих
знаний, способного отыскать среди прочих источников знаний такой, который содержит
в себе желаемую операцию. Создать условия для его активизации — это и есть цель
третьего типа.
Указанные
две стратегии могут работать совместно, устраняя препятствия для выполнения
желаемых операций.
Общая характеристика ВВ
Архитектура
ВВ, конечно, довольно сложная, но эта сложность оправдывается следующими ее
преимуществами по сравнению с более простыми системами.
В этой архитектуре
решена задача разделения управляющих знаний и знаний, специфичных для предметной
области. Источники родовых управляющих знаний могут без всякой модификации
использоваться в экспертных системах самого разнообразного назначения, хотя
источники знаний о предметной области при этом будут совершенно различными.
Эта архитектура предполагает
дифференциацию источников знаний каждого из указанных типов. Знания о предметной
области в системе ACCORD разделены на знания о действиях, событиях, состояниях,
объектах, их компоновках и роли объектов в компоновках. Управляющие знания
также разделены на знания о стратегии, предусловиях, эвристиках и т.д.
Эта архитектура позволяет
формировать пояснения поведения системы в терминах выполняемого плана.
Архитектура предполагает
широкое использование языков высокого уровня, подобных ACCORD.
Модули, которые входят
в состав среды, могут быть использованы повторно в множестве создаваемых на
ее основе прикладных экспертных систем.
Как это случалось
и с прежними разработками, выполненными в стенах Станфордского университета,
предлагаемый подход интересен не только с точки зрения теории построения систем
искусственного интеллекта, но имеет и большую практическую ценность.
Эффективность и гибкость модели с доской объявлений
Широкие функциональные
возможности и универсальность архитектуры на основе доски объявлений приводят
к увеличению объема вычислений, необходимых для ее реализации. Ниже мы рассмотрим
проблемы, возникающие при построении прикладных экспертных систем с такого рода
архитектурой.
Организация доски объявлений в системе GBB
В реальной
экспертной системе доска объявлений представляет собой ассоциативную память
для источников знаний. Вычислительные операции, связанные с манипуляцией данными
в этой памяти, отнимают львиную долю ресурсов всей системы. Поэтому понятно,
насколько важно использовать для работы с доской объявлений эффективные алгоритмы
доступа к данным и добавления новых данных. Хотя мы и не располагаем конкретными
данными об эффективности выполнения вычислений в современных системах с такой
архитектурой, но в разработанной в 70-х годах системе HEARSAY-II до половины
машинного времени уходило на организацию работы с доской объявлений, а уже оставшееся
время тратилось на собственно обработку информации от источников знаний.
В ранних системах
для повышения производительности операций с доской объявлений использовалось
разбиение ее на уровни или "панели", что позволяло сократить пространство
поиска, поскольку определенный источник знаний требовал просмотра только части
всей структуры данных.
Ниже мы несколько
подробнее рассмотрим современную систему, названную создателями GBB (Generic
Blackboard Builder). Ее можно рассматривать как типичного представителя нового
поколения систем с такой архитектурой.
Разделы доски
объявлений в GBB называются пространствами (spaces), причем они, в свою
очередь, разделены на размерности (dimensions), для доступа к которым
используется специальный атрибут индексации. Элементы структуры данных доски
объявлений "живут" в этих пространствах, причем оснащены собственными
атрибутами индексации, позволяющими реализовать множество различных методов
быстрого обращения к ним. Если пользоваться терминологией баз данных, то эти
индексы являются, по существу, ключами, хотя и довольно сложными.
Размерности,
используемые для дальнейшей структуризации пространств, могут быть упорядоченными
(ordered) или перечислимыми (enumerated). Индексы могут быть скалярными,
т.е. состоять из единственного элемента данных, или составными, состоящими
из множества компонентов. Скалярные индексы упорядоченных размерностей представляют
собой числа из некоторого диапазона, а составные индексы могут быть либо набором
меток, либо последовательностью, упорядоченной в соответствии с какой-либо другой
размерностью, например по времени.
В каждом цикле
выполнения программы отыскивается элемент в определенном пространстве доски
объявлений, сопоставимый с пусковым образцом источника знаний. Такой пусковой
образец в GBB чаще всего представляет собой не левую часть порождающего правила,
а шаблон, ссылающийся на элементы доски объявлений. При работе с размерностями
процесс извлечения элемента из доски объявлений состоит из четырех этапов.
(1) Первичное
извлечение. Выбирается множество всех элементов данного пространства доски
объявлений, которые "претендуют" на сопоставление с шаблоном. Каждое
пространство имеет карту элементов, с помощью которой можно определить, как
элементы хранятся в этом пространстве. Можно, конечно, хранить их и в виде последовательного
списка, но такой способ недостаточно эффективен. Элементы в упорядоченных размерностях
со скалярными индексами можно хранить в виде "пакетов", т.е. наборов,
имеющих индексы в определенном диапазоне, а элементы перечислимых размерностей,
имеющие составные индексы, — в виде хешированных таблиц.
(2)
Предварительная фильтрация. К элементам в отобранном множестве применяются
какие-либо процедуры предварительного отбора, позволяющие отсеять некоторые
из них еще до сопоставления с шаблоном.
(3) Фильтрация
по шаблону. Каждый элемент отобранного множества сравнивается с шаблоном
и проверяется, удовлетворяет ли он заданным в шаблоне ограничениям. В каждом
шаблоне специфицированы определенные критерии сопоставления— должен ли элемент
доски объявлений точно соответствовать шаблону, включать в себя шаблон или представлять
собой часть шаблона. Поскольку шаблоны могут включать и индексированные компоненты,
должны существовать правила, определяющие дисциплину сопоставления таких компонентов.
(4)
Постфильтрация. К каждому отобранному элементу доски объявлений применяются
дополнительные процедуры проверки. Этот этап необязателен, как, впрочем, и этап
предварительной фильтрации. В результате множество элементов-претендентов еще
более сужается.
Та схема обработки,
которую мы здесь представили, отображает процесс только в самых общих чертах.
В действительности все происходит значительно сложнее, но в этой книге мы не
будем останавливаться на всех деталях его реализации. Но уже и из этого описания
ясно, что уровень сложности обработки в системах с доской объявлений на порядок
выше, чем в системах с другой архитектурой, использующих в чистом виде представление
знаний в виде правил или объектов. Для того чтобы помочь пользователю справиться
с возросшей сложностью системы, в состав оболочки включено множество заготовок
типовых модулей, из которых пользователь может достаточно просто скомпоновать
прикладную экспертную систему.
Компоновка доски объявлений в среде ERASMUS
Практически
все компоненты системы с доской объявлений имеют ярко выраженную модульную структуру.
Это в равной мере относится и к структурам данных самой доски объявлений, и
к источникам знаний, и к средствам управления режимом работы системы. Например,
существует множество способов представления элементов данных доски объявлений,
в источниках знаний можно использовать множество разных форматов представления
знаний (порождающие правила, программный код на языке LISP и т.п.), по-разному
можно настраивать процесс активизации источников знаний, планирования выполнения
заявок.
Вслед за средами
разработки ВВ1 и GBB мы рассмотрим в этом разделе еще одну систему — ERASMUS,
которая разработана в компании Boeing на основе опыта, полученного при работе
с ранее созданной системой с доской объявлений ВВВ (Boeing Blackboard System).
Система ВВВ разрабатывалась в среде ВВ1, а элементы данных в ней представляли
собой объекты языка КЕЕ (см. об этом языке в главе 17). Система была задумана
как инструментальная среда, предоставляющая в распоряжение разработчика множество
самых различных средств, которые можно использовать в прикладной системе в разных
сочетаниях. Фактически ERASMUS является развитием ВВВ, причем при модернизации
преследовались следующие цели [Байт et al., 1989].
(1) Конфигурация
системы должна настраиваться пользователем.
(2) Должна
обеспечиваться максимально высокая производительность, возможная при заданной
конфигурации.
(3) Система
должна допускать наращивание.
(4) Система
должна поддерживать множество схем представления объектов доски объявлений.
Специалисты
фирмы Boeing пришли к выводу, что многие приложения, с которыми им приходится
иметь дело, достаточно хорошо вписываются в подход, который был использован
в среде ВВ1. По образу и подобию ВВ1 в фирме была разработана среда ВВВ, но
после нескольких лет ее эксплуатации сложилось мнение, что использованная в
ней схема представления и управления накладывает чрезмерные ограничения. Поэтому,
например, при создании на основе ВВВ системы планирования производства Phred
пришлось дополнительно разрабатывать механизм поддержки некоторых фаз решения
проблем, подобный описанному в главе 13. Оказалось также, что на некоторых фазах
процесса можно организовать более эффективное планирование активизации источников
знаний, допустив исполнение нескольких заявок. При работе с другой экспертной
системой, Cockpit Information Manager, оказалось, что нужно повысить скорость
поиска объектов на доске объявлений. Реализация элементов данных доски объявлений
в виде объектов языка КЕЕ не позволяет получить максимальную производительность
системы, хотя в системе GBB этого удалось достичь за счет использования изощренного
метода индексации при извлечении объектов из доски объявлений.
Разработчики
системы ERASMUS охарактеризовали ее как "генератор систем с доской объявлений",
хотя больше ей подходит характеристика "система с конфигурируемой архитектурой"
(configurable architecture). Возможность по-разному компоновать структуру системы,
создаваемой в этой среде, позволяет оптимально настроить ее архитектуру в соответствии
с характеристиками конкретного приложения.
Среда ERASMUS
поддерживает четыре опции конфигурации.
(1) Blackboard
(доска объявлений). Пользователь может выбрать одну из четырех структур данных
для доски объявлений в создаваемой системе, в том числе и формат, подобный GBB,
или на основе объектов языка КЕЕ.
(2) KS structure
(структура источника знаний). Источники знаний могут быть реализованы в формате
языка FLAVOR (см. об этом языке в главе 7), а записи активизации источников
знаний представляют собой экземпляры объектов этого языка. Пользователь может
специфицировать предусловия активизации источников знаний, условия устранения,
при выполнении которых запись активизации источника знаний удаляется из списка
выбора, фазы процесса решения проблемы и т.п.
(3) Control
(режим управления). Пользователь может выбрать режим управления, аналогичный
используемому в системе ВВ1, либо режим, ведомый эвристиками, назначающими веса
записям активизации источников знаний.
(4) Runtime
(опции времени выполнения). Эти опции позволяют пользователю выбрать механизм
формирования пояснений, трассировки и различные средства отладки, которые должны
быть включены в состав компонуемой прикладной экспертной системы.
Таким образом,
модульная организация систем с доской объявлений позволяет разработчикам гибко
варьировать структуру конкретной системы с такой архитектурой, добиваясь оптимального
соответствия между функциональными возможностями и производительностью системы.
Организация параллельных вычислений в системах CAGE и POLIGON
При анализе
работы систем с доской объявлений сам собой напрашивается вопрос, а нельзя ли,
учитывая наличие нескольких независимых источников знаний, общающихся друг с
другом через глобальную структуру данных, организовать их параллельную работу.
Очевидно, что параллелизм можно внедрить на разных уровнях систем с такой архитектурой:
на уровне активизации
источников знаний;
на уровне обработки
пускового образца и предусловий в процессе работы с отдельным
источником знаний;
на уровне выполнения
действий, предусмотренных записью активизации источника знаний.
Хотя процессам
первой группы параллелизм присущ по самой их природе, процессы двух других групп
могут включать и последовательно выполняемые шаги. Например, предусловия разных
правил могут использовать одни и те же переменные, а операции, специфицированные
разными активизированными правилами, могут потребовать соблюдения определенной
последовательности выполнения.
В Станфордском
университете в рамках проекта Advanced Architectures Project созданы два прототипа
систем с доской объявлений, в которых использованы разные методики организации
параллельной работы компонентов системы. Ниже мы приведем краткое описание этих
разработок. Более детально читатель может познакомиться с ними в работе [Nii
et al., 1988].
Система CAGE
[Aietlo, 1986] является модификацией описанной выше инструментальной
среды AGE и представляет собой мультипроцессорную вычислительную систему с общей
памятью. В язык программирования системы включены конструкции, позволяющие описать
параллельное выполнение некоторых фрагментов кода на уровне прикладной программы.
В проекте параллельное выполнение реализовано на трех уровнях системы.
Параллельная работа
источников знаний. Источники знаний могут параллельно работать с разными
сегментами структуры данных доски объявлений или может быть использован режим
конвейерной обработки, когда разные операции выполняются с разными сегментами
данных, которые по очереди извлекаются из конвейера.
Параллельная реализация
правил. Условия, специфицированные в разных правилах, могут анализироваться
параллельно. Действия, указанные в правых частях правил, могут быть реализованы
затем либо параллельно, либо поочередно.
Параллельный анализ
условий. Условия, специфицированные в одном и том же правиле, также могут
анализироваться параллельно.
Параллельная
обработка источников знаний может выполняться как в синхронном, так и в асинхронном
режимах. В первом приближении синхронизация нужна в том случае, когда выходные
данные множества параллельных этапов обработки буферизуются до тех пор, пока
не закончится выполнение всех параллельных процессов. Таким образом, передача
выходных данных на доску объявлений задерживается до тех пор, пока все активизированные
источники знаний не завершат свои операции. Пользователь также может задать
в программе, как должны быть реализованы действия, предусмотренные в активизированных
правилах, — параллельно или поочередно.
Эксперименты
с системой CAGE разочаровали ее создателей. В системе, насчитывающей восемь
процессоров, было достигнуто только двукратное повышение скорости вычислений
в режиме параллельной синхронной обработки источников знаний, а при использовании
четырех процессоров вообще не наблюдалось никакого изменения производительности.
В асинхронном режиме при использовании восьми процессоров удалось повысить быстродействие
менее чем в четыре раза. Эксперименты с использованием параллельной обработки
правил привели примерно к пятикратному повышению производительности системы,
состоящей из 16 процессоров.
Другая система,
POLIGON, была разработана "с чистого листа" на базе мультипроцессорного
вычислительного комплекса с распределенной памятью. В ней используется распараллеливание
задачи на множестве уровней. Эксперименты с этой системой дали значительно более
обнадеживающие результаты. Оказалось, что эффективность распараллеливания существенно
увеличивается по мере роста объема данных в источниках знаний и количества правил,
претендующих на активизацию.
Из сравнительного
анализа двух систем был сделан вывод, что попытка запаралле-лить обработку отдельных
этапов при сохранении режима централизованного управления всей системой (вариант
системы CAGE) не может привести к успеху, а использование децентрализованного
управления снижает возможности программного управления процессом логического
вывода. Таким образом, первые работы в направлении реализации параллельного
режима в системах с доской объявлений показали, что это задача далеко не тривиальная.
Параллелизм может оправдать себя только в тех областях применения, где возрастающая
сложность системы и значительное увеличение объема вычислений оправдываются
результатами работы экспертной системы.
Рекомендуемая
литература
Для
первого знакомства с принципами построения экспертных систем на основе доски
объявлений я бы рекомендовал прочесть обзорные работы [Nil, 1986, а, b]. Подборка
статей об исследованиях в этом направлении опубликована в сборнике [Englemore
and Morgan, 1988]. С точки зрения технологии экспертных систем особый интерес
представляют главы 5 и 6, в которых описаны некоторые ранние системы с такой
архитектурой, не рассмотренные в данной книге, глава 12, содержащая достаточно
подробное описание системы AGE, и глава 26, в которой кратко описана реализация
системы GBB.
Тем,
кто желает детальнее познакомиться с системами GBB и ERASMUS, я рекомендую работу
[Jagannathan et al., 1989]. Информация о проекте Advanced Architectures Project
и разработанных в его рамках системах CAGE и POLIGON опубликована в работе [Rice,
1989]. Прилагаемый к ней список публикаций результатов, полученных в ходе работы
над этим проектом, послужит хорошим путеводителем тем, кто захочет глубже с
ним познакомиться.
Среди
прочих работ, касающихся проблематики систем с доской объявлений, я бы выделил
книгу [Craig, 1995] и обзорную статью [Carver and Lesser, 1994].
использование разных вариантов архитектуры экспертных1. Что такое источник знаний в системе с доской объявлений? 2. Сравните использование разных вариантов архитектуры экспертных систем — продукционную систему и систему с доской объявлений. При каких условиях можно считать оправданным усложнение системы, использующей модель с доской объявлений. 3. В чем различие между системами с доской объявлений и многофункциональными инструментальными средами, описанными в главе 17. 4. Прочтите работу [Nil et al, 1988] и составьте краткий обзор характеристик систем CAGE и POLIGON. Особое внимание в этом обзоре уделите анализу отличий между методами принятия решений, использованными в каждой из систем, их достоинствам и недостаткам. 5. Подумайте над тем, как в рамках архитектуры систем с доской объявлений организовать систему планирования мероприятий, выполняющую те же функции, что и описанная в главе 15. Какие источники знаний целесообразно использовать в ней для формирования начального наброска плана, для его уточнения и для окончательной проверки совместимости всех этапов. 6. Придумайте задачу, при решении которой в полной мере могут проявиться достоинства структуры с доской объявлений. Какие источники знаний должны быть использованы в системе, предназначенной для решения этой задачи. Например, при расследовании происшествия, повлекшего за собой смерть пловца, пользовавшегося для плавания под водой дыхательным аппаратом, власти стараются рассмотреть множество аспектов происшествия, которые могут быть представлены в разных источниках знаний. Ниже приводится их примерный перечень. Условия, связанные с внешней средой: состояние воды; неблагоприятные течения; потенциальные ловушки; опасности, связанные с судоходством; опасности, исходящие от обитателей морских глубин. Нарушения в работе технических средств: пользование техническими средствами; обслуживание технических средств. Характеристика потерпевшего: опыт и тренировка; психологические проблемы; химические проблемы, например употребление наркотиков; физическое состояние. Подумайте над тем, как управлять применением знаний в приложении. Будут ли источники знаний функционировать независимо друг от друга, посылая в любое время сообщения доске объявлений, или будут активизироваться по очереди. Например, в описанной выше задаче расследования можно организовать режим поочередного использования источников знаний каждой из перечисленных категорий в заранее заданном порядке. |