Индуктивное обучение
Точное определение термину "обучение" дать довольно трудно, но большинство авторов сходятся во мнении, что это — качество адаптивной системы, которая способна совершенствовать свое поведение (умение справляться с проблемами), накапливая опыт, например опыт решения аналогичных задач [Simon, 1983]. Таким образом, обучение — это одновременно и способность, и действие. Любая программа обучения должна обеспечивать возможность сохранять и анализировать полученный опыт решения проблем, а также обладать способностью применять сделанные выводы для решения новых проблем.
В работе [Carbonell et al, 1983] представлена классификация программ обучения на основе используемой стратегии. Попросту говоря, использованная стратегия зависит от того, насколько глубоко может программа проникнуть в суть той информации, которую она получает в процессе обучения.
На одном конце спектра находятся программы, которые обучаются, непосредственно воспринимая новые знания, и не выполняют при этом никакого логического анализа. Обычно такую методику обучения называют rote learning ("зубрежка", а программы соответственно — "зубрилками"). Аналогов такой методике в обычной жизни не счесть. Самый знакомый всем — зазубривание таблицы умножения (или "Отче наш..."). На другом конце спектра обучающих программ находятся те, которые пользуются методикой unsupervised learning, т.е. обучение без преподавателя. Под этим подразумевается способность формулировать теоремы, которая имеет очевидную аналогию с образом мышления человека, делающего научное открытие на основе эмпирических фактов.
В этой главе мы рассмотрим методики, лежащие посередине между этими двумя крайностями. Они получили наименование супервизорного обучения (supervised learning). Программам, использующим такую методику, демонстрируются ряд примеров. Программа должна проанализировать набор свойств этих примеров и идентифицировать подходящие концепты. Свойства примеров известны и представлены парами "атрибут-значение". "Надзор" за процессом обучения заключается, главным образом, в подборе репрезентативных примеров, т.е. в формировании пространства атрибутов, над которым будет размышлять программа.
Наиболее общая форма задач, решаемых в такой системе обучения, получила наименовании индукции (induction). Таким образом, индуктивная программа обучения — это программа, способная к обучению на основе обобщения свойств предъявляемых ей примеров (экземпляров, образцов). В работе [Michalski, 1983, р. 83] дано такое определение процессу обучения:
"Эвристический поиск в пространстве символических описаний, сформированный применением различных правил вывода к исходным наблюдаемым проявлениям".
Символические описания представляют собой, как правило, обобщения, которые можно сделать на основе наблюдаемых проявлений. Такие обобщения являются формой логического заключения, т.е. они предполагают выполнение определенных, регламентируемых некоторыми правилами трансформаций символических описаний, которые представляют наблюдаемые проявления. Одна из форм индуктивного обучения предусматривает демонстрацию примеров двух типов — тех, которые соответствуют концепту (позитивные экземпляры), и тех, которые ему не соответствуют (негативные экземпляры). Задача программы обучения — выявить или сконструировать подходящий концепт, т.е. такой, который включал бы все позитивные экземпляры и не включал ни одного негативного. Такой тип обучения получил название обучение концептам (concept learning).
Рассмотрим набор данных, представленный в табл. 20.1.
Таблица
20.1. Обучающая выборка примеров
|
Экземпляр |
Страна-изготовитель |
Размер |
Старая модель |
Позитивный/
негативный |
||
|
Oldsmobile Cutlass |
США |
Большой |
Нет |
Негативный |
||
|
BMW 31 6 |
Германия |
Малый |
Нет |
Позитивный |
||
|
Thunderbird Raodster |
США |
Малый |
Да |
Негативный |
||
|
VW Cabriolet |
Германия |
Малый |
Нет |
Позитивный |
||
|
Rolls Royce Corniche |
Великобритания |
Большой |
Да |
Негативный |
||
|
Chevrolet Bel
Air |
США |
Малый |
Да |
Негативный |
||
Очень существенно предъявлять программе и позитивные, и негативные экземпляры. В первой из рассмотренных выше задач и BMW 316, и VW Cabriolet являются малыми автомобилями, поэтому если программе не представить в качестве негативного экземпляра Chevrolet Bel Air, то она может сделать вывод, что концепт Немецкий автомобиль совпадает с концептом Малый автомобиль. Аналогично, если во второй задаче не будет представлен негативный экземпляр Oldsmobile Cutlass, то программа может посчитать концепт Американский автомобиль старой марки совпадающим с более общим концептом Американский автомобиль.
С формальной точки зрения любое множество данных, в котором выделены положительные и отрицательные экземпляры, можно считать обучающей выборкой для индуктивной программы обучения. В обучающей выборке также нужно специфицировать некоторый набор атрибутов, имеющих отношение к обучаемым концептам, а запись каждого экземпляра должна содержать значения этих атрибутов. В табл. 20.1 представлены значения атрибутов обучающей выборки для концепта Немецкий автомобиль.
Другая задача обучения получила наименование обобщение дескрипторов (descriptive generalization). Формулируется задача следующим образом: программе обучения предъявляется набор экземпляров некоторого класса объектов (т.е. представляющих некоторый концепт), а программа должна сформировать описание, которое позволит идентифицировать (распознавать) любые объекты этого класса. Пусть, например, обучающая выборка имеет вид
{Cadillac Seville, Oldsmobile Cutlass, Lincoln Continental},
причем каждый экземпляр выборки имеет атрибуты размер, уровень комфорта и расход топлива. Тогда в результате выполнения задачи обобщения дескрипторов программа сформирует описание, представляющее набор значений дескрипторов, характерный для данного класса объектов:
{большой, комфортабельный, прожорливый}.
Отличие между задачами обучение концептам и обобщение дескрипторов состоит в следующем:
задача обучения концептам предполагает включение в обучающую выборку как позитивных, так и негативных экземпляров некоторого заранее заданного набора концептов, а в процессе выполнения задачи будет сформировано правило, позволяющее затем программе распознавать ранее неизвестные экземпляры концепта;
задача обобщения дескрипторов предполагает включение в обучающую выборку только экземпляров определенного класса, а в процессе выполнения задачи создается наиболее компактный вариант описания из всех, которые подходят к каждому из предъявленных экземпляров.
Обе задачи относятся к классу методик, который мы назвали супервизорным обучением, поскольку в распоряжении программы имеется и специально подготовленная обучающая выборка, и пространство атрибутов.
В следующем разделе мы рассмотрим две программы обучения, которые разработаны в связи с созданием экспертной системы DENDRAL. Первый вариант реализации программы обучения нельзя отнести ни к одной из перечисленных выше категорий, но второй вариант использовал методику, которую мы сейчас можем отнести к категории "индуктивное обучение". В оригинальном описании программы авторы назвали ее version space (пространство версий). Постановка задачи очень напоминает обучение концептам, поскольку предусматривает включение в обучающую выборку позитивных и негативных экземпляров концепта.
Интересно сравнить оба варианта системы и выяснить, как знания, специфичные для определенной предметной области (в данном случае, химии), могут быть использованы алгоритмом обучения, независящим от предметной области.
В разделе 20.3 описана современная программа индуктивного обучения, на примере которой будет продемонстрировано, как формируются правила для экспертных систем. В разделе 20.4 мы затронем вопрос настройки отдельных правил и набора связанных правил.
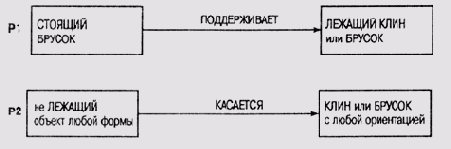
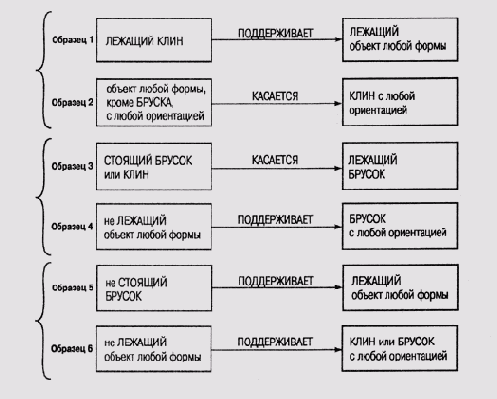
Система Meta-DENDRALВ рамках проекта DENDRAL, который был начат в Станфордском университете в 1965 году, была разработана первая система, продемонстрировавшая, что программа может успешно конкурировать с человеком-экспертом в определенной предметной области. Перед экспертной системой стояла задача определения молекулярной структуры неизвестного органического соединения. В экспертной системе использовался слегка модифицированный вариант метода порождения и проверки. Исходной информацией были показания масс-спектрометра, который бомбардировал образец соединения потоком электронов. В результате происходила перестройка структуры соединения и его компонентов. Перемещение отдельных атомов в структуре соединения соответствует отсоединению узла от одного подграфа и присоединению его к другому. Изменение структуры молекул соединения и улавливалось масс-спектрометром. Проблема состояла в том, что для любой сложной молекулы существует множество вариантов разделения на фрагменты, поскольку в результате бомбардировки могут разрываться разные связи в молекуле, а соответственно и перемещаться могут разные фрагменты молекулы. В этом смысле теория масс-спектрометрии являетсл неполной— мы можем говорить только о вероятности разрыва определенной связи, но никогда не можем точно предсказать, как разделится молекула на фрагменты. В рамках проекта DENDRAL была разработана программа CONGEN, которая формировала описание полной химической структуры, манипулируя символами, представляющими атомы и молекулы. В качестве входной информации эта программа получала формулу молекулы и набор ограничений, накладываемых на возможные взаимные связи между атомами. Результатом выполнения программы является список всех возможных комбинаций атомов в структуре молекулы с учетом заданных ограничений. В состав DENDRAL входят также программы, которые помогают пользователю отбрасывать одни гипотезы и ранжировать другие, используя знания о связях показаний масс-спектрометра со структурой молекул соединения. Например, программа MSPRUNE отсеивает те гипотезы-кандидаты, которые предполагают варианты фрагментации, не совпадающие с полученными от масс-спектрометра данными. Программа MSRANK ранжирует оставшиеся гипотезы-кандидаты в соответствии с тем, какая часть пиков масс-спектрограммы, предсказанных этой гипотезой, была действительно обнаружена в полученных экспериментально данных. Таким образом, в экспертной системе DENDRAL фактически реализована стратегия "формирование гипотез и их последующая проверка". Исходные данные служат для формирования некоторого пространства гипотез, которые предсказывают наличие и отсутствие определенных свойств масс-спектрограммы, а затем эти гипотезы сопоставляются с результатами экспериментов. Формирование и уточнение правилПрограмма Meta-DENDRAL формирует на основе рассуждений правила, которые затем используются программой DENDRAL в процессе определения молекулярной структуры неизвестного органического соединения. В первой версии программы Meta-DENDRAL гипотетические правила (гипотезы о правилах) формировались в процессе эвристического поиска, подобного тому, который использовался в самой программе DENDRAL. Другими словами, для формирования правил в этой версии использовалась та же стратегия, что и в системе, применяющей эти правила. Роль программы Meta-DENDRAL во всем комплексе состояла в хом, чтобы помочь химику выявить взаимосвязи между вариантами фрагментации молекул в процессе получения массового спектра и структурными характеристиками компонентов молекулы. Работая совместно, программа и химик решают, какие данные о структуре компонентов представляют интерес, а затем отыскивают спектрометрический процесс, который может объяснить появление таких данных. В результате формируются правила, связывающие структуру с масс-спектрограммой. Затем программа тестирует эти правила и при необходимости модифицирует их так же, как это сделал бы химик. Те правила масс-спектрометрии, которые химик использует для описания фрагментации молекулы, могут быть символически представлены в виде порождающих правил. Например, следующее правило расщепления позволяет представить в программе связь между определенной структурой молекулы и определенным процессом ее расщепления в процессе масс-спектрометрии. Здесь значком "-" представлена связь в молекуле, а значком "*" — место разрыва под воздействием бомбардировки электронами: N-C-C-C-> N-C*C-C. В левой части правила представлены характеристики структуры, а в правой — процесс расщепления при формировании массового спектра. Для обучения Meta-DENDRAL используется набор молекул, структура и массовый спектр которых известны. Для этого набора молекул формируются пары "структура-спектр", которые и включаются в обучающую выборку. Хочу обратить ваше внимание на следующее. Хотя "словарь" атомов в подграфах структуры молекулы и невелик, а "грамматика" конструирования подграфов проста, количество формируемых подграфов может быть довольно велико. Поэтому существует опасность экспоненциального взрыва. Учитывая потенциальную опасность экспоненциального взрыва, в Meta-DENDRAL (как, впрочем, и в DENDRAL) используется стратегия "планирование— формирование гипотез— проверка". Фаза планирования в Meta-DENDRAL выполняется программой INTSUM (сокращение от interpretation and summary — интерпретация и суммирование данных). Эта программа должна предложить набор простых процессов, которые можно включить в обучающую выборку. Процессы Выходная информация программы INTSUM передается программе эвристического поиска RULEGEN, которая играет в Meta-DENDRAL, ту же роль, что и программа CONGEN в DENDRAL. Но в отличие от CONGEN, она формирует не гипотезы о структурах молекул, а более общие гипотетические правила расщепления, которые, например, могут предполагать и множественные разрывы связей в молекулах. Эти правила должны охватывать все случаи, представленные в обучающей выборке, сформированной программой INTSUM. После того как будет сформировано множество гипотетических правил, в дело вступает программа RULEMOD, на которую возложено выполнение последней фазы процесса, — фазы тестирования и модификации правил. Разделение нагрузки между программами RULEGEN и RULEMOD следующее: программа RULEGEN выполняет сравнительно поверхностный поиск в пространстве правил и формирует при этом приблизительные и избыточные правила, а программа RULEMOD выполняет более глубокий поиск и уточняет набор гипотетических правил. Алгоритм работы программы RULEMOD и по сей день представляет определенный интерес, хотя со времени ее создания прошло более 30 лет. Задачи, которые решает эта программа, типичны для всех программ тонкой настройки правил. (1) Устранение избыточности. Данные, поступающие на вход программы (гипотетические правила), могут быть переопределены, т.е. несколько правил, сформированных на предыдущем этапе, объясняют одни и те же факты. Обычно в окончательный набор правил нужно включить только часть из них. При выполнении этой задачи также удаляются правила, которые вносят противоречие во всю совокупность или порождают некорректные предсказания. (2) Слияние правил. Иногда несколько правил, взятых в совокупности, объясняют сразу множество фактов, и эту совокупность имеет смысл объединить в одно, более общее правило, которое будет включать все позитивные свидетельства и не содержать ни одного негативного. Если удастся отыскать такое совокупное правило, то им заменяются в окончательном наборе все его исходные компоненты. (3) Специализация правила. Иногда оказывается, что слишком общее правило порождает некорректные предсказания, т.е. в его "зону охвата" попадают и негативные свидетельства. В таком случае нужно попытаться добавить в правило уточняющие компоненты, которые помогут исключить из "зоны охвата" правила негативные свидетельства, но сохранят охват всех позитивных свидетельств. В результате правило станет более специализированным. (4) Обобщение правила. Поскольку порождение правил выполняется на основе обучающей выборки ограниченного объема, то среди сформированных правил могут оказаться и такие, в которых специализация выходит за рамки разумного. Программа пытается сохранить только минимальный набор условий в левой части правила, необходимый для обеспечения корректности правила на данной тестовой выборке. (5) Отбор правил в окончательный набор. После обобщения и специализации правил в наборе вся совокупность может снова стать избыточной. Поэтому программа снова повторяет процедуру устранения избыточности, описанную в п. 1. Все описанные процедуры могут итеративно повторяться до тех пор, пока пользователь не будет удовлетворен сформированным набором правил. Единственное, что после этого еще остается сделать пользователю — присвоить правилам веса. Ниже в этой главе мы покажем, как на практике выполняется формирование набора правил. Качество правил, сформированных системой Meta-DENDRAL, проверялось на наборе структур, не включенных в обучающую выборку. Они также сравнивались с теми правилами, которые имеются в опубликованных источниках, и анализировались опытными специалистами по спектрометрии органических соединений. Программа успешно "открыла" опубликованные правила и, более того, нашла новые. Способность сформированных правил предсказать вид спектра соединений, ранее ей неизвестных, поразила специалистов. Однако ни DENDRAL, ни Meta-DENDRAL не стали коммерческими программными продуктами, хотя многие идеи, рожденные в процессе работы над этим проектом, и нашли широкое применение в компьютерной химии. Различные модули этих программ были включены в состав других программных комплексов, в частности в системы управления базой данных химических соединений [Feigenbaum and Buchanan, 1993]. Пространство версийВ этом разделе мы рассмотрим одну из методик обучения, которая получила в литературе наименование пространство версий (version space) [Mitchell, 1978], [Mitchell, 1982], [Mitchell, 1997]. Эта методика была реализована во второй версии системы Meta-DENDRAL. При выводе общего правила масс-спектрометрии из набора примеров, демонстрирующих, как определенные молекулы расщепляются на фрагменты, в этой версии Meta-DENDRAL интенсивно используется механизм обучения концептам, о котором мы рассказывали выше. В работе [Mitchell, 1978] так формулируется проблема обучения концептам. "Концепт можно представить как образец, который обладает свойствами, общими для всех экземпляров этого концепта. Задача состоит в том, чтобы при заданном языке описания образцов концептов и наличии обучающей выборки — наборе позитивных и негативных экземпляров целевого концепта и способе сопоставления данных из обучающей выборки и гипотез описания концепта — построить описание концепта, совместимого со всеми экземплярами в обучающей выборке". В этом контексте "совместимость" означает, что сформированное описание должно охватывать все позитивные экземпляры и не охватывать ни один негативный экземпляр. Для того чтобы "рассуждать" о правилах, касающихся масс-спектрометрии, система Meta-DENDRAL должна располагать языком представления концептов и отношений между ними в этой предметной области. В Meta-DENDRAL это объектно-ориентированный язык (см. главу 6), который описывает сеть с помощью узлов и связей между ними. Узлы представляют атомы в структуре молекулы, а связи — химические связи в молекуле. В этом языке некоторый экземпляр в обучающей выборке соответствует образцу в том случае, если сопоставимы все их узлы и связи и удовлетворяются все ограничения, специфицированные в описании образца. В контексте проблемы обучения концептам пространство версий есть не что иное, как способ представления всех описаний концептов, совместимых в оговоренном выше смысле со всеми экземплярами в обучающей выборке. Главное достоинство использованной Митчеллом (Mitchell) методики представления и обновления пространств версий состоит в том, что версии могут строиться последовательно одна за другой, не оглядываясь на ранее обработанные экземпляры или ранее отвергнутые гипотезы описаний концептов. Митчелл отыскал ключ к решению проблемы эффективного представления и обновления пространств версий, заметив, что пространство поиска допустимых описаний концептов является избыточным. В частности, он пришел к выводу, что можно выполнить частичное упорядочение образцов, сформированных описаниями концептов. Самым важным является отношение "более специфичный чем или равный", которое формулируется следующим образом. "Образец Р1 более специфичен или равен образцу Р2 (это записывается в форме Р2 =< Р2) тогда и только тогда, когда Р1 сопоставим с подмножеством всех образцов, с которыми сопоставим образец Р2". Рассмотрим следующий простой пример из обучающей программы для "мира блоков" [Winston, 1975, а]. На рис. 20.1 образец Р1 более специфичен, чем образец Р2, поскольку ограничения, специфицированные в образце Р1, удовлетворяются только в том случае, если удовлетворяются более слабые ограничения, специфицированные в образце Р2. Можно посмотреть на эту пару образцов и с другой точки зрения: если в некотором экземпляре удовлетворяются ограничения, специфицированные в образце Р1, то обязательно удовлетворяются и условия, специфицированные в образце Р2, но не наоборот.
Рис. 20.1.
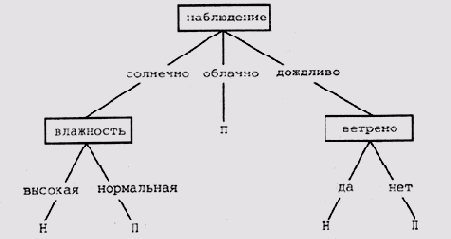
Отношения между образцами Программа должна понимать, что если В — это "брусок", то, значит, В — это одновременно и "объект произвольной формы", т.е. в программу должны быть заложены определенные критерии, которые помогут ей выделить категории сущностей, представленных узлами в языке описания структуры образцов. Программа должна знать, что если А "поддерживает" В, то, следовательно, А "касается" В в мире блоков, т.е. программа должна обладать способностью разобраться в избыточности отношений между объектами в предметной области. Программа должна понимать логический смысл таких терминов, как "не", "любой" и "или", и то как они влияют на ограничения или разрешения в процессе сопоставления образцов. Все эти знания необходимы программе для того, чтобы она смогла сопоставить образец Р1 с Р2, т.е. узлы и связи в одном образце с узлами и связями в другом, и выяснить, что любое ограничение, специфицированное в Р1, является более жестким, более специфичным, чем соответствующее ему ограничение в образце Р2. Если программа сможет во всем этом разобраться, то открывается путь к представлению пространств версий в терминах большей "специфичности" или большей "общности" образцов в этом пространстве. Тогда программа может рассматривать некоторое пространство версий как содержащее: множество максимально специфических образцов; множество максимально обобщенных образцов; все описания концептов, которые находятся между этими двумя крайними множествами. Все это в совокупности называется представлением пространств версий граничными множествами (boundary sets). Такое представление, во-первых, компактно, а во-вторых, легко обновляется. Оно компактно, поскольку не хранит в явном виде все описания концептов в данном пространстве. Его легко обновлять, так как определение нового пространства можно выполнить перемещением одной или обеих границ. Алгоритм отсеивания кандидатовПространство версий, как следует из приведенного описания, есть не что иное, как структура данных для представления множества описаний концептов. Однако термин "пространство версий" часто применяется и по отношению к технологии обучения, использующей при работе с этой структурой данных алгоритм, известный как алгоритм отсеивания кандидатов (candidate elimination). Этот алгоритм манипулирует с граничными множествами, представляющими определенное пространство версий. Выполнение алгоритма начинается с инициализации пространства версий — заполнения его множеством всех описаний концептов, совместимых с первым позитивным экземпляром в обучающей выборке. Другими словами, множество максимально специфических образцов (S) заполняется наиболее специфическими описаниями концептов, которые способен сформировать язык образцов, а множество максимально обобщенных образцов (G) заполняется наиболее обобщенными описаниями концептов. При анализе каждого последующего экземпляра в обучающей выборке множества S и G модифицируются таким образом, чтобы отсеять из пространства версий те описания концептов, которые несовместимы с анализируемым экземпляром. Таким образом, в процессе обучения границы монотонно "движутся" навстречу друг другу. Перемещение границы S в направлении большей общности можно рассматривать как выполнение поиска в ширину от специфических образцов к более общим. Цель поиска — сформировать новое граничное множество, которое будет обладать минимально достаточной общностью, чтобы "охватить" новый позитивный экземпляр обучающей выборки. Другими словами, граница 5 перемещается в том случае, если новый позитивный экземпляр в обучающей выборке не сопоставим ни с одним из образцов в множестве S. Точно так же и перемещение границы G в направлении большей специфичности можно рассматривать как поиск в ширину от более общих образцов к более специфичным. Цель такого поиска— сформировать новое граничное множество, которое будет обладать минимально достаточной спецификой, чтобы не "накрыть" очередной негативный экземпляр в обучающей выборке. Коррекция границы G происходит в том случае, когда программа обнаруживает, что очередной негативный экземпляр сопоставим с каким-либо образцом в G. В этом алгоритме нет никакой эвристики, поскольку ограничения четкие и тем самым гарантируется сходимость алгоритма. Монотонность поиска оказалась тем "золотым ключиком", с помощью которого удалось решить проблему комбинаторики обновления пространств. Технология пространства версий обладает множеством привлекательных свойств, которые стоят того, чтобы их здесь перечислить. Гарантируется совместимость всех описаний концептов со всеми экземплярами в обучающей выборке. Пространство поиска суммирует альтернативные интерпретации наблюдений. Результат не зависит от порядка обработки обучающей выборки. Каждый экземпляр в обучающей выборке анализируется только один раз. Не возникает необходимость возвращаться к однажды отвергнутой гипотезе. Тот факт, что пространство версий суммирует данные, означает, что его можно использовать в качестве базиса для формирования новых экземпляров для обучающей выборки, т.е. экземпляров, которые могли бы еще более сблизить границы. То, что программа анализирует каждый экземпляр только один раз, позволяет обойтись без сохранения ранее обработанных экземпляров. Следовательно, и время обучения пропорционально объему обучающей выборки, а не связано с количеством экземпляров в ней какой-либо показательной функцией. Поскольку отпадает необходимость в обратном прослеживании, эффективность процедуры должна быть довольно высокой. Наиболее серьезным "подводным камнем" в этой технологии является фактор ветвления в процессе частичного упорядочения образцов, который имеет тенденцию к комбинаторному росту по мере увеличения количества дизъюнктов в описаниях концептов. Сопоставление экземпляров с образцами в Meta-DENDRALДля описания экземпляров обучающей выборки в Meta-DENDRAL используется тот же язык, что и для описания образцов. Каждый образец представляет собой описание определенной цельной молекулы, причем основное внимание уделяется описанию компонентов. При сопоставлении экземпляров с образцами отыскивается цепочка связных отображений узлов образца и узлов экземпляра. Отображение X является связным, если оно является однозначным и допускающим вставку и если каждая пара узлов экземпляра Х(р1), Х(р2), соответствующая узлам образца р1 и р2, разделяет общую связь в том и только в том случае, если р1 и р2 также разделяют общую связь. Требуется также, чтобы значения характеристик каждого узла экземпляра Х(р) удовлетворяли ограничениям, определенным для соответствующего узла p образца. Теперь открывается возможность дать определение частичного упорядочения по Митчеллу, специфичное для той предметной области, в которой используется система Meta-DENDRAL. В этом определении будет использовано и приведенное выше определение связности. Строчными буквами будем обозначать узлы образца, а прописными — весь образец в целом. Образец Р1 является более специфическим или равным образцу Р2 в том и только в том случае, когда существует такое связанное отображение X узлов в Р2 на узлы в Р1, что для каждой пары узлов р2, Х(р2) ограничения на значения свойств, ассоциированные с Х(р2), являются более специфическими или равными ограничениям, ассоциированным с р2. Для того чтобы разобраться в существе этого определения, имеет смысл вновь вернуться к примеру из мира блоков, который мы рассматривали выше. В мире химических структур аналогами блоков являются атомы и "суператомы", а аналогами пространственных отношений между блоками, такими как "поддерживает" или "касается", — химические связи. Специфические знания из области химии могут быть двояко использованы алгоритмом отсеивания кандидатов. (1)Язык представления химических структур допускает такие языковые формы представления образцов, которые синтаксически отличны, но семантически эквивалентны, т.е. на этом языке один и тот же образец можно описать разными выражениями. Следовательно, для удаления избыточных образцов из граничных пространств версий требуется знание семантики образца, представленного в описании. Это не оказывает никакого влияния на полноту подхода, основанного на пространстве версий. (2) Для некоторых проблем граничные пространства версий могут вырасти и достичь достаточно большого объема. Следовательно, было бы очень полезно использовать какие-либо правила для сокращения объемов граничных пространств. Однако, если использовать для этого эвристические методы, нет уверенности, что программа сможет определить все описания концептов, совместимые с обучающей выборкой. Митчелл утверждает, что подход, основанный на пространстве версий, добавит новые возможности первоначальному варианту программы Meta-DENDRAL. Можно модифицировать существующий набор правил новой обучающей выборкой и при этом не повторять анализ ранее представленной выборки. Процесс обучения будет носить явно выраженный инкрементальный характер. Можно будет индивидуально решать для каждого правила, до какой степени имеет смысл его уточнять в процессе обучения. Новая стратегия формирования правил позволит избежать использования "поиска со спуском" в программе RULEGEN и сосредоточить в первую очередь внимание на наиболее интересных экземплярах в обучающей выборке. Метод анализа альтернативных версий каждого правила является более полным, чем операции обобщения и специализации в программе RULEMOD. Суммируя все сказанное выше, приходим к выводу, что использование подхода, основанного на пространствах версий, позволяет реализовать методику инкрементального обучения (обучения с последовательным наращиванием уровня полноты знаний). Стратегия отсеивания кандидатов может быть противопоставлена стратегии поиска в глубину или в ширину, поскольку она позволяет отыскать не единственное приемлемое описание концепта, как при выполнении поиска в глубину, или максимально специфические описания, как при поиске в ширину, а все описания концептов, совместимые с обучающей выборкой. Митчелл также специально акцентирует внимание на том, что ключевым вопросом применения такой технологии является разработка методов формирования обучающей выборки. Построение дерева решений и порождающих правилПравила являются не единственно возможным способом представления информации о концептах в виде пар- "атрибут-значение" для целей классификации. Альтернативный метод структурирования такой информации — использование дерева решения. Существуют эффективные алгоритмы конструирования таких деревьев из исходных данных. Мы обсудим их в разделе 20.3.1. За последние 30 лет создано довольно много систем обучения, в которых использована эта методика. Среди них системы CLS [Hunt et al., 1966], ID3 [Quinlan, 1979], ACLS [Paterson and Niblett, 1982], ASSISTANT [Kononenko et al., 1984] и IND [Buntine, 1990]. Система ACLS (развитие системы ID3) стала базовой для множества коммерческих экспертных систем, таких как Expert-Ease и RuleMaster, которые нашли широкое применение в промышленности. Несколько подробнее об алгоритме работы системы ID3 будет рассказано в разделе 20.3.2. Программный комплекс С4.5 [Quinlan, 1993] использует алгоритмы ЮЗ и включает программу C4.5Rules. Этот модуль формирует порождающие правила, используя в качестве входной информации описание дерева решений. Подробное описание этой программы имеется в технической литературе, а потому мы не будем останавливаться на ней в данной книге. В последней версии этой системы, С5.0, реализована еще более тесная интеграция форматов представления деревьев решений и правил. Структура дерева решенийДерево решений представляет один из способов разбиения множества данных на классы или категории. Корень дерева неявно содержит все классифицируемые данные, а листья — определенные классы после выполнения классификации. Промежуточные узлы дерева представляют пункты принятия решения о выборе или выполнения тестирующих процедур с атрибутами элементов данных, которые служат для дальнейшего разделения данных в этом узле. В работе [Quinlan, 1993] дерево решений определено как структура, которая состоит из узлов-листьев, каждый из которых представляет определенный класс; узлов принятия решений, специфицирующих определенные тестовые процедуры, которые должны быть выполнены по отношению к одному из значений атрибутов; из узла принятия решений выходят ветви, количество которых соответствует количеству возможных исходов тестирующей процедуры. Можно рассматривать дерево решений и с другой точки зрения: промежуточные узлы дерева соответствуют атрибутам классифицируемых объектов, а дуги — возможным альтернативным значениям этих атрибутов. Пример дерева представлен на рис. 20.2. На этом дереве промежуточные узлы представляют атрибуты наблюдение, влажность, ветрено. Листья дерева промаркированы одним из двух классов П или Н. Можно считать, что П соответствует классу позитивных экземпляров концепта, а Н — классу негативных. Например, П может представлять класс "выйти на прогулку", а Н — класс "сидеть дома". Хотя очевидно, что дерево решений является способом представления, отличным от порождающих правил, дереву можно сопоставить определенное правило классификации, которое дает для каждого объекта, обладающего соответствующим набором атрибутов (он представлен множеством промежуточных узлов дерева), решение, к какому из классов отнести этот объект (набор классов представлен множеством значений листьев дерева). В приведенном примере правило будет относить объекты к классу П или Н. Можно прямо транслировать дерево в правило, показанное ниже: если наблюдение = облачно v наблюдение = солнечно & влажность = нормально v наблюдение = дождливо & ветрено = нет то П
Рис. 20.2.
Дерево решений (заимствовано из [Quinlan, 1986, a]) if наблюдение = облачно then П if наблюдение = солнечно & влажность = нормально then П if наблюдение = дождливо & ветрено = нет then П Причина, по которой предпочтение иногда отдается деревьям решений, а не порождающим правилам, состоит в том, что существуют сравнительно простые алгоритмы построения дерева решений в процессе обработки обучающей выборки, причем построенные деревья могут быть использованы в дальнейшем для корректной классификации объектов, не представленных в обучающей выборке. Алгоритм системы ID3, который используется для построения дерева по обучающей выборке, мы рассмотрим в следующем разделе. Этот алгоритм достаточно эффективен с точки зрения количества вычислительных операций, поскольку объем вычислений растет линейно по отношению к размерности проблемы. В табл. 20.2 показана обучающая выборка, которая использовалась для формирования дерева на рис. 20.2. Таблица
20.2. Обучающая иыборка (заимствовано us [Quinlan, 1986,a])
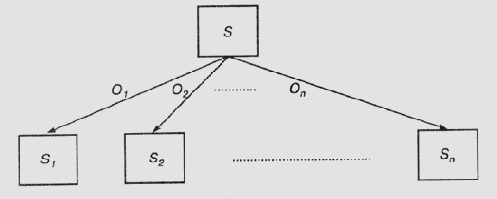
Алгоритм формирования дерева решений по обучающей выборкеНиже будет описан алгоритм формирования дерева решений по обучающей выборке, использованный в системе IDЗ. Задача, которую решает алгоритм, формулируется следующим образом. Задано: множество целевых непересекающихся классов {С1, С2, ..., Сk}; обучающая выборка S, в которой содержатся объекты более чем одного класса. Алгоритм использует последовательность тестовых процедур, с помощью которых множество 5 разделяется на подмножества, содержащие объекты только одного класса. Ключевой в алгоритме является процедура построения дерева решений, в котором нетерминальные узлы соответствуют тестовым процедурам, каждая из которых имеет дело с единственным атрибутом объектов из обучающей выборки. Как вы увидите ниже, весь фокус состоит в в выборе этих тестов. Пусть Т представляет любую тестовую процедуру, имеющую дело с одним из атрибутов, а {О1,O2,...,On} — множество допустимых выходных значений такой процедуры при ее применении к произвольному объекту х. Применение процедуры Т к объекту х будем обозначать как Т(х). Следовательно, процедура Т(х) разбивает множество S на составляющие {S1, S2, ..., Sn}, такие, что Si= {x|T(x) = Oi}. Такое разделение графически представлено на рис. 20.3.
Рис. 20.3.
Дерево разделения объектов обучающей выборки Квинлан (Quinlan) использует для этого заимствованное из теории информации понятие неопределенности. Неопределенность — это число, описывающее множество сообщений M= { m1, т2,..., тn}. Вероятность получения определенного сообщения mi из этого множества определим как р(тi). Объем информации, содержащейся в этом сообщении, будет в таком случае равен I(mi) = -logp(mi). Таким образом, объем информации в сообщении связан с вероятностью получения этого сообщения обратной монотонной зависимостью. Поскольку объем информации измеряется в битах, логарифм в этой формуле берется по основанию 2. Неопределенность множества сообщений U(M) является взвешенной суммой количества информации в каждом отдельном сообщении, причем в качестве весовых коэффициентов используются вероятности получения соответствующих сообщений: U(М) = -Sumip[(mi) logp(mi), i = 1,..., п.] Интуитивно ясно, что чем большую неожиданность представляет получение определенного сообщения из числа возможных, тем более оно информативно. Если все сообщения в множестве равновероятны, энтропия множества сообщений достигает максимума. Тот способ, который использует Квинлан, базируется на следующих предположениях. Корректное дерево решения, сформированное по обучающей выборке S, будет разделять объекты в той же пропорции, в какой они представлены в этой обучающей выборке. Для какого-либо объекта, который нужно классифицировать, тестирующую процедуру можно рассматривать как источник сообщений об этом объекте. Пусть Ni — количество объектов в S, принадлежащих классу Сi. Тогда вероятность того, что произвольный объект с, "выдернутый" из S, принадлежит классу Сi, можно оценить по формуле p(c~Ci) = Ni/|S|, а количество информации, которое несет такое сообщение, равно I(с ~ Сi) = -1оg2р(mi) (с ~ Сi) бит. Теперь рассмотрим энтропию множества целевых классов, считая их также множеством сообщений {С1 C2, ..., Ck}. Энтропия также может быть вычислена как взвешенная сумма количества информации в отдельных сообщениях, причем весовые коэффициенты можно определить, опираясь на "представительство" классов в обучающей выборке: U(M) = -Sumi=1...,k[ р(с ~ Ci)x I(с ~ Сi)] бит. Энтропия U(M) соответствует среднему количеству информации, которое необходимо для определения принадлежности произвольного объекта (с ~ S) какому-то классу до того, как выполнена хотя бы одна тестирующая процедура. После того как соответствующая тестирующая процедура Т выполнит разделение S на подмножества {S1, S2, ..., Sn}, энтропия будет определяться соотношением Uт(S) = -Sumi=1,...k(|S|/|Si|)х U(Si). Полученная оценка говорит нам, сколько информации еще необходимо после того, как выполнено разделение. Оценка формируется как сумма неопределенностей сформированных подмножеств, взвешенная в пропорции размеров этих подмножеств. Из этих рассуждений очевидно следует эвристика выбора очередного атрибута для тестирования, используемая в алгоритме, — нужно выбрать тот атрибут, который сулит наибольший прирост информации. Прирост информации GS(T) после выполнения процедуры тестирования Т по отношению к множеству 5 равен GS(7)=U(S)-Uт(S). Такую эвристику иногда называют "минимизацией энтропии", поскольку увеличивая прирост информации на каждом последующем тестировании, алгоритм тем самым уменьшает энтропию или меру беспорядка в множестве. Вернемся теперь к нашему примеру с погодой и посмотрим, как эти формулы интерпретируются в самом простом случае, когда множество целевых классов включает всего два элемента. Пусть р — это количество объектов класса П в множестве обучающей выборки S, а п — количество объектов класса Н в этом же множестве. Таким образом, произвольный объект принадлежит к классу П с вероятностью p / (p + п), а к классу Н с вероятностью n /(p + п). Ожидаемое количество информации в множестве сообщений М = {П, Н} равно U(M) = -p / (p + п) log2(p/(p + n )) - n / (p + n) 1оg2(n/(р + п)) Пусть тестирующая процедура Т, как и ранее, разделяет множество S на подмножества {S1, S2.....Sn}, и предположим, что каждый компонент S, содержит pi, объектов класса П и и, объектов класса Н. Тогда энтропия каждого подмножества Si будет равна U(Si) = -рi/(рi + ni) log2(pi/(pi + ni)) - n/(рi + ni) log2(ni/(pi +ni)) Ожидаемое количество информации в той части дерева, которая включает корневой узел, можно представить в виде взвешенной суммы: Uт(S) = -Sumi=1,...n((pi, + ni)/(р + n)) х U(Si) Отношение (р, + п,)/(р + п) соответствует весу каждой i-и ветви дерева, вроде того, которое показано на рис. 20.3. Это отношение показывает, какая часть всех объектов S принадлежит подмножеству S,. Ниже мы покажем, что в последней версии этого алгоритма, использованной в системе С4.5, Квинлан выбрал слегка отличающуюся эвристику. Использование меры прироста информации в том виде, в котором она определена чуть выше, приводит к тому, что предпочтение отдается тестирующим процедурам, имеющим наибольшее количество выходных значений {O1 O2,..., Оп}. Но несмотря на эту "загвоздку", описанный алгоритм успешно применялся при обработке достаточно внушительных обучающих выборок (см., например, [Quintan, 1983]). Сложность алгоритма зависит в основном от сложности процедуры выбора очередного теста для дальнейшего разделения обучающей выборки на все более мелкие подмножества, а последняя линейно зависит от произведения количества объектов в обучающей выборке на количество атрибутов, использованное для их представления. Кроме того, система может работать с зашумленными и неполными данными, хотя этот вопрос в данной книге мы и не рассматривали (читателей, интересующихся этим вопросом, я отсылаю к работе [Quinlan, 1986, b]). Простота и эффективность описанного алгоритма позволяет рассматривать его в качестве достойного соперника существующим процедурам извлечения знаний у экспертов в тех применениях, где возможно сформировать репрезентативную обучающую выборку. Но, в отличие от методики, использующей пространства версий, такой метод не может быть использован инкрементально, т.е. нельзя "дообучить" систему, представив ей новую обучающую выборку, без повторения обработки ранее просмотренных выборок. Рассмотренный алгоритм также не гарантирует, что сформированное дерево решений будет самым простым из возможных, поскольку использованная оценочная функция, базирующаяся на выводах теории информации, является только эвристикой. Но многочисленные эксперименты, проведенные с этим алгоритмом, показали, что формируемые им деревья решений довольно просты и позволяют прекрасно справиться с классификацией объектов, ранее неизвестных системе. Продолжение поиска "наилучшего решения" приведет к усложнению алгоритма, а как уже отмечалось в главе 14, для многих сложных проблем вполне достаточно найти не лучшее, а удовлетворительное решение. В состав программного комплекса С4.5, в котором используется описанный выше алгоритм, включен модуль C4.5Rules, формирующий из дерева решений набор порождающих правил. В этом модуле применяется эвристика отсечения, с помощью которой дерево решений упрощается. При этом, во-первых, формируемые правила становятся более понятными, а значит, упрощается сопровождение экспертной системы, а во-вторых, они меньше зависят от использованной обучающей выборки. Как уже упоминалось, в С4.5 также несколько модифицирован критерий отбора тестирующих процедур по сравнению с оригинальным алгоритмом, использованным в ID3. Недостатком эвристики, основанной на приросте количества информации, является то, что она отдает предпочтение процедурам с наибольшим количеством выходных значений {О1, O2, ..., Оn}. Возьмем, например, крайний случай, когда практически бесполезные тесты будут разделять исходную обучающую выборку на множество классов с единственным представителем в каждом. Это произойдет, если обучающую выборку с медицинскими данными пациентов классифицировать по именам пациентов. Для описанной эвристики именно такой вариант получит преимущество перед прочими, поскольку UT(S) будет равно нулю и, следовательно, разность Gs(T) = U(S) - UT(S) достигнет максимального значения. Для заданной тестирующей процедуры Т на множестве данных S, которая характеризуется приростом количества информации GS{T), мы теперь возьмем в качестве критерия отбора относительный прирост НS(Т), который определяется соотношением НS{Т) = GS(Т)/V(S), где V(S) = -Sumi=1,..., (|S|/|Si|) x log2(|S|/|Si|). Важно разобраться, в чем состоит отличие величины V(S) от U(S). Величина V(S) определяется множеством сообщений {О1, О2,...,Оn] или, что то же самое, множеством подмножеств {S1 S2,...,Sn}, ассоциированных с выходными значениями тестовой процедуры, а не с множеством классов {С1 C2,...,Ck}. Таким образом, при вычислении величины V(S) принимается во внимание множество выходных значений теста, а не множество классов. Новая эвристика состоит в том, что выбирается та тестирующая процедура, которая максимизирует определенную выше величину относительного прироста количества информации. Теперь те пустые тесты, о которых мы говорили чуть выше и которым прежний алгоритм отдал бы преимущество, окажутся в самом "хвосте", поскольку для них знаменатель будет равен log2(N), где N— количество элементов в обучающей выборке. Оригинальный алгоритм формирования дерева страдает еще одной "хворью" - он часто формирует сложное дерево, в котором фиксируются несущественные для задачи классификации отличия в элементах обучающей выборки. Один из способов справиться с этой проблемой — использовать правило "останова", которое прекращало бы процесс дальнейшего разделения ветвей дерева при выполнении определенного условия. Но оказалось, что сформулировать это условие не менее сложно, а потому Квинлан пошел по другому пути. Он решил "обрезать" дерево решений после того, как оно будет сформировано алгоритмом. Можно показать, что такое "обрезание" может привести к тому, что новое дерево будет обрабатывать обучающую выборку с ошибками, но с новыми данными оно обычно справляется лучше, чем полное дерево. Проблема "обрезания" довольно сложна и выходит за рамки данной книги. Читателям, которые заинтересуются ею, я рекомендую познакомиться с работами [Mingers, 1989, b] и [Mitchell, 1997], а подробное описание реализации этого процесса в С4.5 можно найти в [Quinlan, 1993, Chapter 4]. Для того чтобы сделать более понятным результат выполнения алгоритма, в системе С4.5 дерево решений преобразуется в набор порождающих правил. Мы уже ранее демонстрировали соответствие между отдельным путем на графе решений от корня к листу и порождающим правилом. Условия в правиле — это просто тестовые процедуры, выполняемые в промежуточных узлах дерева, а заключение правила — отнесение объекта к определенному классу. Однако строить набор правил перечислением всех возможных путей на графе — процесс весьма неэффективный. Некоторые тесты могут служить просто для того, чтобы разделить дерево и таким образом сузить пространство выбора до подмножества, которое в дальнейшем уточняется с помощью проверки других, более информативных атрибутов. Это происходит по той причине, что не все атрибуты имеют отношение ко всем классам объектов. Квинлан применил следующую стратегию формирования множества правил из дерева решений. (1) Сформировать начальный вариант множества правил, перечислив все пути от корня дерева к листьям. (2) Обобщить правила и при этом удалить из них те условия, которые представляются излишними. (3) Сгруппировать правила в подмножества в соответствии с тем, к каким классам они имеют отношение, а затем удалить из каждого подмножества те правила, которые не вносят ничего нового в определение соответствующего класса. (4) Упорядочить множества правил по классам и выбрать класс, который будет являться классом по умолчанию. Упорядочение правил, которое выполняется на шаге (4), можно рассматривать как примитивную форму механизма разрешения конфликтов (см. главу 5). Порядок классов внутри определенного подмножества теперь уже не будет иметь значения. Назначение класса по умолчанию можно считать своего рода правилом по умолчанию, которое действует в том случае, когда не подходит ни одно другое правило. Полученное в результате множество правил скорее всего не будет точно соответствовать исходному дереву решений, но разобраться в них будет значительно проще, чем в логике дерева решений. При необходимости эти правила можно будет затем уточнить вручную. Квинлан очень осторожно подошел к формулировке тех условий, при которых созданная им система С4.5 может быть использована как подходящий инструмент обучения, позволяющий ожидать удовлетворительных результатов. Подход, основанный на использовании дерева решений, можно применять для решения далеко не всех задач классификации. Определенные ограничения свойственны и тем конкретным алгоритмам, которые использованы в системе С4.5. Необходимым условием успешного применения этой системы является выполнение следующих требований. Перечень классов, с которыми в дальнейшем будет оперировать экспертная система, необходимо сформулировать заранее. Другими словами, алгоритмы, положенные в основу функционирования системы С4.5, не способны формировать перечень классов на основе группировки обучающей последовательности объектов. Кроме того, классы должны быть четко очерченными, а не "расплывчатыми" — некоторый объект либо принадлежит к данному классу, либо нет, никаких промежуточных состояний быть не может. И, кроме того, классы не должны перекрываться. Применяемые в системе методы обучения требуют использовать обучающие выборки большого объема. Чем больше объем выборки, тем лучше. При малой длине обучающей выборки на полученных в результате правилах будут сказываться индивидуальные особенности экземпляров в обучающей выборке, что может привести к неверной классификации незнакомых объектов. Методы "усечения" дерева решений, использованные в С4.5, будут работать некорректно, если длина обучающей выборки слишком мала и содержит нетипичные объекты классов. 4 Данные в обучающей выборке должны быть представлены в формате "атрибут-значение", т.е. каждый объект должен быть охарактеризован в терминах фиксированного набора атрибутов и их значений для данного объекта. Существуют методы обработки, которые позволяют справиться и с пропущенными атрибутами, — предполагается, что в таких случаях выход соответствующей тестирующей процедуры будет в вероятностном смысле распределен по закону, определенному на основе тех объектов, в которых такой атрибут определен. В тех областях применения, в которых можно использовать и подход, базирующийся на дереве решений, и обычные статистические методы, выбор первого дает определенные преимущества. Этот подход не требует знания никаких априорных статистических характеристик классифицируемого множества объектов, в частности функций распределения значений отдельных атрибутов (использование статистических методов зачастую основано на предположении о существовании нормального распределения значений атрибутов). Как показали эксперименты с экспертными системами классификации разных типов, те из них, в которых используются деревья решений, выигрывают по сравнению с другими по таким показателям, как точность классификации, устойчивость к возмущениям и скорость вычислений. Уточнение наборов правилПроблеме отладки и уточнения характеристик правил посвящено множество исследований. Ниже мы рассмотрим только пару примеров, которые позволят читателям понять суть этой проблемы, слегка "прикоснуться" к методам ее решения и послужат отправной точкой для более углубленного изучения этой темы. Несмотря на то что эта работа имеет теоретическую направленность, ее практическая ценность несомненна. Появление любого инструментального средства, которое поможет повысить производительность набора взвешенных правил в экспертной системе, будет только приветствоваться инженерами по знаниям. Если в нашем распоряжении имеется набор правил, сформированный по индукции программой обучения или извлеченный в процессе собеседования с экспертом, то нас, как правило, больше всего интересует следующее: "взнос" отдельных правил в результат; эффективность набора правил в целом и достоверность получаемого результата. В отношении отдельных правил наибольшую озабоченность вызывают характеристики "применимости": насколько часто правило применяется корректно, а насколько часто оно приводит к ошибочному заключению. В отношении набора правил в целом желательно знать, какова полнота набора, т.е. насколько этот набор позволяет охватить все возможные комбинации исходных данных, не является ли он избыточным, т.е. нет ли в нем правил, которые можно удалить без ущерба для качества результата. При этом нужно учитывать, что хотя само по себе "избыточное" правило может быть вполне корректным, удаление его из набора может положительно сказаться на производительности экспертной системы. В работе [Langlotz et al, 1986] представлен метод теории принятия решений, который позволяет уточнять характеристики отдельных правил. Если в спецификации правила имеются свойства, которые можно варьировать, например связанные с вероятностными характеристиками, очень полезно выяснить, как сказывается изменение этого параметра на результатах работы системы. В качестве иллюстрации авторы работы рассматривали простое правило системы MYCIN, которое "оппонирует" применению тетрациклина при лечении детей, поскольку этот препарат оказывает нежелательный побочный эффект на состояние зубов ребенка. ЕСЛИ 1) против инфекции предполагается применение тетрациклина; 2) возраст пациента (лет) менее 8, ТО есть серьезное основание полагать (0.8), что применение тетрациклина не рекомендуется против этой инфекции. Это правило содержит в себе возможность варьирования между воздействием на поразившую пациента инфекцию и риском отрицательного побочного эффекта. Ожидаемая полезность применения этого правила является функцией полезности результатов правила и вероятностей реального получения этих результатов. В теории принятия решений ожидаемая полезность (EU — expected utility) действия А, возможные результаты которого есть элементы множества {О1, О2, ...,Оn}, причем исходы характеризуются вероятностями р1,р2, ...,рn, выражается формулой EU(A) = Sumi[pi u(Oi) i=1,..,n.] В этой формуле и(Оi) означает оценку полезности отдельного варианта результата операции (исхода) Оi. Нас интересует, как будет меняться полезность действия, которое рекомендуется правилом, при изменении вероятностей рi и оценок полезности и(Оi). Если, например, инфекция, к которой имеет отношение это правило, устойчива против всех прочих препаратов, кроме тетрациклина, а вероятность побочного эффекта довольно мала, то значение EU(A) будет более высоким по сравнению с ситуацией, когда против инфекции можно применить и другие препараты, не имеющие побочных эффектов, а вероятность побочного эффекта от применения тетрациклина довольно высока. Авторы описывают применение методов анализа чувствительности, которые позволяют выявить зависимость между полезностью исходов и их вероятностями. Точка, в которой рекомендации альтернативных курсов лечения имеют равную полезность, представляет пороговое значение вероятности. Анализируя эти пороговые значения, можно определить, насколько далеко отстоит оценка вероятности в модели от того значения, при котором потребуется изменить принятое оптимальное решение. Усилия, затраченные на выполнение описанного анализа, окупаются тем, что инженер по знаниям и эксперт получают более точное обоснование рациональности применения того или иного правила. В частности, методы теории принятия решений позволяют определить в явном виде значения тех переменных, от которых зависит применимость отдельных правил. Это поможет инженеру по знаниям отыскать нежелательные взаимосвязи между правилами в наборе, включая и такие, которые являются результатом вероятностных зависимостей, рассмотренных нами в главе 9. В работе [Wilkins and Buchanan, 1986] основное внимание уделено комплексной отладке набора эвристических правил. Авторы работы утверждают, что поочередная (инкрементальная) модификация отдельных правил в процессе настройки и эксплуатации экспертной системы (например, как это делается в программе TEIRESIAS, описанной в главе 10) не гарантирует сходимости процесса к оптимальному набору правил. Они предостерегают против применения "универсальных стратегий" делать правила более общими или более специализированными в тех случаях, когда обнаруживаются неверные результаты работы системы в целом. Эвристические правила по самой своей природе являются приблизительными и их нельзя модифицировать только потому, что обнаружен отдельный неправильный результат. Фактически любое эвристическое правило представляет определенный компромисс между общностью и специализацией в терминах некоторой общей линии поведения, а потому вполне целесообразно уделить основное внимание именно этой линии поведения, а не вносить судорожно изменения в отдельные правила. Авторы дают определение оптимальному набору правил, как такому, который минимизирует вероятность получения неверных результатов. Предполагается, что отдельные правила в наборе соответствуют определенному стандарту качества, а главные усилия направляются на выбор в существующем наборе подмножества правил, наилучшего в определенном смысле. Процесс отбора такого оптимального подмножества формулируется как проблема минимизации двудольного графа (bipartite graph minimization problem), которая базируется на отображении множества вершин, представляющих объекты обучающей выборки, на множество вершин, представляющих исходное множество правил. Показано, что хотя в общем виде эта проблема относится к классу необозримых, но существует эвристический метод ее решения для конкретной постановки, связанной со спецификой экспертных систем. Предлагаемое решение в основном сводится к тому, чтобы минимизировать в наборе вредные взаимные связи между "хорошими" эвристическими правилами, которые сформированы индуктивными методами. Другая работа, имеющая отношение к проблематике настройки наборов порождающих правил, посвящена описанию системы LAS (Learning Apprentice System) [Smith et al, 1985]. LAS представляет собой интерактивный инструментальный комплекс для создания и настройки баз знаний. В системе частично автоматизирован процесс формирования эвристических правил на основании теории предметной области и отладки этих правил при возникновении каких-либо проблем с их применением в экспертной системе. Работа LAS базируется на формализме сетей зависимостей (они обсуждаются в главе 19), который используется для представления обоснования правил в терминах теории предметной области. Эти же структуры используются и для формирования пояснений при возникновении сбоев в работе системы. Разработки, упоминавшиеся в этой главе, демонстрируют возможность создания средств автоматизации формирования баз знаний. Хотя некоторые из них носят исследовательский характер, совершенно очевиден прогресс в этой области искусственного интеллекта, который позволяет надеяться, что в недалеком будущем будет устранено наиболее узкое место в создании экспертных систем — найдено эффективное решение задачи приобретения знаний. Подводя итог всему сказанному об исследованиях в области машинного обучения, отметим, что эти исследования обещают внести значительный вклад в теорию и практику не только экспертных систем, но и других проблем искусственного интеллекта. Рекомендуемая литератураКак отмечалось в самом начале этой главы, существует множество проблем, связанных с машинным обучением, о которых мы даже не упоминали в данной книге. Читателям, которые заинтересуются этой проблемой, я бы порекомендовал начинать знакомство с ней с обзоров [Michalski et al, 1983] и [Michalski et al., 1986] и работы [Winston, 1984, Chapter 11]. В этих статьях рассматриваются разнообразные виды машинного обучения, приложимые не только к экспертным системам. Множество статей на эту тему публикуется в журнале Artificial Intelligence. В частности, я рекомендую познакомиться со статьями [Winston, 1982J и [Lenat, 1982]. Классификация программ обучения, основанная на анализе базовых алгоритмов, представлена в работе [Bundy et al., 1984]. Но учтите, что эта статья предполагает предварительное знакомство с основными концепциями работы систем, анализируемых в ней. Сравнительные анализ существующих систем можно найти также в работах [O'Rourke, 1982] и [Dietterich and Michalski, 1983]. Из поздних работ я бы отметил статью [Buchanan and Wilkihs, 1993], в которой вы найдете много информации о современном состоянии проблемы извлечения знаний и машинного обучения. Довольно подробное описание системы С4.5 представлено в [Quintan, 1993], причем в описание включены и листинги программ. Пространство версий рассматривается в книге [Mitchell, 1997, Chapter 2].
|