Графы, деревья и сети
Для описания многих видов абстрактных данных в информатике вообще и в теории искусственного интеллекта, в частности, очень широко используется терминология, заимствованная из теории графов. Следующие определения приведены здесь для того, чтобы показать, как эти заимствованные термины трактуются при описании структурированных объектов, что несколько отличается от их трактовки в "родной" математической сфере.
Рис. 6.1.
Некоторые виды графов: а) обыкновенный граф; б) связный граф с петлей; в) обыкновенный
ориентированный граф — дерево
Определение 6.1. Если N— множество узлов, то любое подмножество NxN является обобщенным графом G. Если в парах подмножества NxN имеет значение порядок, то граф G является ориентированным.
На рис. 6.1 показаны разные типы графов. Обратите внимание на то, что граф не обязательно должен быть связным. Если задаться условием, что петли не допускаются, т.е. в каждой паре должны присутствовать разные узлы, то такой граф называется обыкновенным. Если на графе не допускаются не только петли, но и циклы (т.е. последовательность связей, в которой начальный и конечный узлы совпадают), то такой граф называется лесом.
Определение 6.2. Если G— обыкновенный граф, в котором имеется п узлов и п-1 связей и отсутствуют циклы, то такой граф является деревом.
Иными словами, дерево — это связный лес. Обычно один из узлов дерева является его корнем, например узел е на графе, представленном на рис. 6.1,в. Остальные узлы образуют ветвящуюся структуру "наследников" корневого узла, в которой отсутствуют циклы. Узлы, не имеющие наследников, являются терминальными, или "листьями" дерева, а остальные узлы называются промежуточными (нетерминальными).
В теории графов сетью называется взвешенный ориентированный граф, т.е. граф, в котором каждой связи сопоставлено определенное число. Обычно этими числами оценивается "стоимость" пути вдоль этой связи или длина связи, как на карте дорог. В каждом конкретном случае применения графа как формального средства описания проблемы эти числа могут трактоваться по-своему.
Следующее определение сети более близко к специфике задач искусственного интеллекта, которыми мы сейчас занимаемся.
Определение 6.3. Если L — это множество взвешенных связей, a N, как и ранее, множество узлов, то сеть — это любое подмножество NxLxN, в котором имеет значение порядок в триадах.
Связи в сети практически всегда являются ориентированными, поскольку отношения, представленные взвешенными связями, не должны быть симметричными.
Обыкновенные графы используются для представления взаимоотношений между объектами в пространстве или во времени. Можно использовать их и для представления более абстрактных причинно-следственных связей, как, например, связей между различными видами патологий в медицине (рис. 6.2). Доступ к такой информации связан в той или иной мере с использованием специальных средств прослеживания путей на графе, для которых разработаны самые различные алгоритмы (см., например, работу [Pearl, 1984]).

Рис. 6.2.
Участок сети причинно-следственных связей ([Pople, 1982P
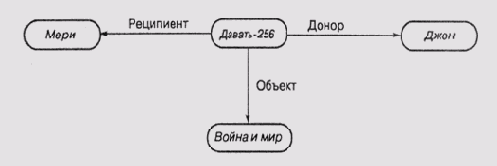
Семантические сети вначале использовались для представления смысла выражений естественного языка человека, откуда и появилось название этого класса сетей. Теперь же они используются в качестве структуры, пригодной для представления информации общего вида, — узлы представляют некоторые концепты (понятия), а связи — отношения между концептами. На рис. 6.4 представлены два фрагмента семантической сети. Первый фрагмент представляет глагол давать и показывает, что этот глагол может иметь три вида взаимодействия с остальными членами предложения: с донором, реципиентом и с объектом, который должен быть передан. Надписи в узлах, к которым подходят связи, соответствуют классу сущностей, которые могут выступать в качестве субъектов связи. Так, донор и реципиент, как правило, —люди, а то, что нужно передать, — вещь.

Рис. 6.3.
Обыкновенное дерево классификации болезней

a
б
Рис. 6.4.
Фрагменты семантической сети: а) представление глагола "давать ";
б) представление конкретного действия
Обычно узел давать-265 связывается с узлом давать связью, которая указывает, что давать-265 — это одна из конкретных реализаций концепта (в данном случае действия) давать. Такого рода специальные связи часто называют ISA-связями (связями типа "это есть...").
Термин ассоциативные сети лучше отражает характер использования такого рода формальных структур для тех задач, которые мы рассматриваем. Поскольку аппарат ассоциативных сетей все шире используется для моделирования объектов и их взаимосвязей в конкретных предметных областях, что необходимо для построения экспертных систем, ниже мы рассмотрим их более детально.
Ассоциативные сети
Систематические исследования методики использования сетей для представления знаний начались с исследования методов представления семантики естественного языка [Quillian, 1968]. Квиллиан предположил, что наша способность понимать язык может быть охарактеризована, хотя бы в принципе, некоторым множеством правил. Он предположил, что процесс восприятия текста включает в себя "создание некоторого рода мысленного символического представления". Исходя из этого, он занялся изучением вопроса, как смысл отдельных слов может быть сохранен в компьютере, чтобы компьютер смог использовать их по тому же принципу, что и человек. Квиллиан был не первым, кто обратил внимание на важность обобщенного, абстрактного знания для понимания естественного языка. Еще ранее к такому же заключению пришли исследователи, занимавшиеся проблемами машинного перевода. Но Квиллиан первым предложил использовать для моделирования человеческой памяти сетевые структуры, в которых узлы и связи между ними представляли бы концепты и отношения между концептами. Он же предложил работающую модель извлечения информации из памяти.
Если мы стремимся создать программу, устойчивую к модификации данных, т.е. сохраняющую работоспособность при множестве таких модификаций, то нам непременно понадобится какое-либо средство проверки целостности знаний. Это, в свою очередь, накладывает определенные ограничения на методы представления знаний: знания должны быть организованы таким образом, чтобы упростить проверку их целостности. Именно такая цель преследовалась при создании тех видов структуры представления знаний, которые мы будем рассматривать в этой главе.
Разделение видов узлов и когнитивная экономия
Два аспекта модели памяти, предложенной Квиллианом, оказали особенно существенное влияние на последующее развитие исследований в области применения систем семантических сетей.
Во-первых, он ввел разделение между видами узлов, представляющих концепты. Один вид узлов он назвал узлами-типами. Такой узел представляет концепт, связанный с конфигурацией других узлов, узлов-лексем. Конфигурация узлов-лексем образует определение концепта узла-типа. Это в определенной степени напоминает толковый словарь, в котором каждое понятие (элемент словаря) определяется другими понятиями, также присутствующими в этом словаре, причем их смысл толкуется с помощью еще каких-либо понятий в этом словаре. Таким образом, смысл узла-лексемы определяется ссылкой на соответствующие узлы-типы.
Например, можно определить смысл слова "машина" как конструкцию из связанных компонентов, которые передают усилие для выполнения некоторой работы. Это потребует присоединения узла-типа для слова "машина" к узлам-лексемам, представляющим слова "конструкция", "компонент" и т.д. Однако в дополнение к связям, сформированным для определения смысла, могут существовать и связи к другим узлам-лексемам, например "телетайп" или "офис". Эти связи представляют знание о том, что телетайпы являются одним из видов машин, которые используется в офисе.
Другое интересное свойство модели памяти получило наименование когнитивной экономии. Суть его поясним на примере. Если известно, что машина — это конструкция, состоящая из взаимодействующих деталей, а телетайп — это тоже машина, то можно сделать вывод, что телетайп — это тоже конструкция. Таким образом, нет смысла в явном виде хранить эту информацию, присоединяя ее к узлу "телетайп". Указывая, что этот узел сохраняет определенные свойства, заданные связями узла "машина", мы можем сэкономить память и сохранить при этом возможность извлечь всю необходимую информацию, если только будем способны построить правильную схему влияния одних узлов на другие.
Эта схема, которую в настоящее время принято называть схемой наследования свойств, получила широкое распространение в представлении знаний. Наследование свойств является типичным примером сохранения объема памяти за счет снижения производительности, которое должен учитывать разработчик схемы представления знаний. Мы увидим в дальнейшем, что такой подход влечет за собой появление множества нетривиальных проблем, в частности, если допустить возможность исключений в наследовании, т.е. существование таких узлов-лексем, которые не наследуют все свойства своего узла-типа. Кроме того, хотя смысл понятий полностью определен в пределах сети, но для каждого отдельного понятия он "размазывается", т.е. отдельные части определения связываются с разными узлами. В нашем примере определение понятия "телетайп" только частично хранится в соответствующем узле, а остальная часть определения находится в узле "машина".
Таким образом, помимо антагонизма "объем памяти/производительность", появляется еще и антагонизм между модульностью определения и разумностью этого определения с точки зрения пользователя. Тем не менее, если эта идея будет корректно реализована, программа всегда будет знать, как отыскать отдельные части определения некоторой сущности и собрать их воедино. Главное же преимущество состоит в том, что в узле можно хранить произвольное количество семантической информации, например данные о диапазонах значений свойств, которыми могут обладать узлы-лексемы определенного типа. В чистом виде такая организация памяти не практикуется при использовании формализмов вроде продукционных систем, поскольку придется выполнять трудоемкий анализ целостности информации в рабочей памяти либо с привлечением специальных правил, описывающих такую целостность, либо с помощью самих правил поиска решений. В любом случае это потребует значительных вычислительных ресурсов.
Анализ адекватности ассоциативных сетей
Основную операцию извлечения информации в той модели обработки, которая следует из предложенной Квиллианом модели памяти, можно охарактеризовать как распространяющуюся активность. Идея состоит в том, что если желательно знать, является ли телетайп машиной, то необходимо искать, т.е. распространить "активность" некоторого вида во всех направлениях — как от узла-типа " телетайп", так и от узла-типа "машина". Если где-то эти две волны встретятся, то таким образом будет установлено существование связи между этими двумя концептами, т.е. определен путь на графе от одного узла к другому. Такая распространяющаяся в разных направлениях активность реализуется передачей маркеров вдоль именованных связей. Мы еще раз вернемся к этой, на первый взгляд, простой, но довольно продуктивной идее при обсуждении нейронных сетей в главе 23.
Интересно отметить, что идеи Квиллиана не получили широкого распространения в качестве модели психологической организации и функционирования памяти человека. При проверке адекватности этой модели Коллинс и Квиллиан измеряли время, которое требовалось испытуемым для ответа на вопрос о принадлежности определенного понятия к некоторой категории и о его свойствах [Collins and Quillian, 1969]. Оказалось, что время, затрачиваемое на поиск ответа, действительно увеличивается по мере увеличения количества узлов в сети, описывающей связи между понятиями. Однако такая зависимость имела место только в отношении положительных ответов. Существовали определенные подозрения, что применение предложенной модели для случая отрицательных ответов натолкнется на определенные трудности. И последующие эксперименты, проведенные другими исследователями, эти подозрения подтвердили.
Тем не менее Квиллиан продолжал исследование возможности использования формализма сетей для представления знаний. Хотя современное представление об ассоциативных сетях во многом существенно отличается от первоначальной концепции и область их использования включает множество проблем, отличных от понимания смысла предложений естественного языка, многие базовые принципы унаследованы от пионерских работ Квиллиана, упомянутых выше.
Существует довольно обширный перечень проблем, при решении которых представление, базирующееся на формализме ассоциативных сетей, оказывается весьма полезным. В 1970-х годах было опубликовано множество работ, в которых анализировались различные виды такого формализма. Наиболее удачной из них, на наш взгляд, является работа Вудса [Woods, 1975]. Использование узлов и связей в сети для представления понятий и отношений между ними может показаться само собой разумеющимся, но опыт показал, что на этом пути неосторожного путника поджидает множество ловушек.
В различных вариантах спецификаций структуры сети далеко не всегда четко определяется смысл маркировки узлов. Так, если рассмотреть узел-тип, имеющий маркировку "телетайп", то часто бывает непонятно, представляет ли этот узел понятие "телетайп", или класс всех агрегатов типа "телетайп", или какой-либо конкретный телетайп. Аналогично, и узел-лексема также открыт для множества толкований — определенный телетайп, какой-то телетайп, произвольные телетайпы и т.д. Разные толкования влекут за собой и разный характер влияния этого узла на другие в сети, а это играет весьма важную роль в дальнейшем анализе.
Поиск пересечения неизбежно "тянет за собой" проблему преодоления комбинаторного взрыва, о которой шла речь в главе 2. Поэтому создается впечатление, что организация памяти в терминах множества узлов, для которых в качестве главного вида процесса извлечения используется распространяющаяся по всем направлениям активность, приведет к образованию системы с труднопредсказуемым поведением. Например, весьма вероятно, что при отрицательных ответах на запросы придется выполнить огромное количество элементарных действий, поскольку нужно убедиться, что не существует пересекающихся путей на графе сети между двумя заданными узлами.
Из сказанного выше ясно, что первоначальные виды формализмов ассоциативных сетей страдают минимум двумя недостатками.
Сети являются логически неадекватными, поскольку в них нельзя представить множество различий, представимых в логическом исчислении, например различие между определенным телетайпом, любым единственным телетайпом, всеми телетайпами, ни одним телетайпом и т.д. Смысл или значение, которые ассоциируются с узлами и связями в сети, часто сложным образом связаны с такими характеристиками системы, как способность к извлечению информации и анализу взаимовлияний. Такое смешение семантики с деталями реализации является результатом того, что сети одновременно являются и средством представления знаний, и средством извлечения из них нужной информации, и средством конструирования заключений, основанных на знаниях, причем везде используется один и тот же набор ассоциативных механизмов. Естественно, что при этом различия между тремя означенными сторонами модели представления смазываются, теряют четкость.
Сети являются эвристически неадекватными, поскольку поиск информации в ней сам по себе знаниями не управляется. Другими словами, этот механизм не предполагает наличия какого-либо знания о том, как искать нужную нам информацию в представленных знаниях. Эти два недостатка иногда "усиливают" друг друга самым неприятным образом. Например, если невозможно представить логическое отрицание или исключение (логическая неадекватность), это приведет к определенным "провалам" в знаниях, которые к тому же нельзя ликвидировать эвристически, прекратив поиск в этом направлении (эвристическая неадекватность).
Для разрешения описанных проблем предлагались самые разные формализмы и механизмы, но лишь немногие из них нашли широкое распространение. Например, многие системы, базирующиеся на сетевом представлении, были расширены и в результате получили множество свойств, характерных для чисто логических систем (см., например, [Schubert, 1976]). В других системах эвристики использовались таким образом, что с каждым узлом связывались процедуры, которые выполнялись, как только узел активизировался (см., например, [Levesque and Mylopoulos, 1979]). Как бы там ни было, но основной принцип организации памяти в терминах узлов и связей остается прежним, несмотря на использование всякого рода дополнительных структур, например "суперузлов" [Hendrix, 1979]. Образующиеся в результате системы часто плохо контролируются пользователем и, утрачивая при этом первоначальную простоту, мало что приобретают в смысле функциональных характеристик.
Представление типовых объектов и ситуаций
В этом разделе мы рассмотрим более простой механизм представления знаний, названный системой фреймов. Этот механизм появился в результате стремления объединить декларативные знания об объектах, о событиях и их свойствах и процедурные знания о методах извлечения информации и достижения целей. Предполагалось, что механизм фреймов поможет избежать ряда проблем, связанных с представлением на основе семантических сетей.
Основные понятия концепции фреймов
Становление теории систем фреймов во многом обязано ряду интуитивных предположений, касающихся механизмов психологической деятельности человека. В частности, предполагается, что представление понятий в мозге не требует строгого формулирования набора свойств, которыми должна обладать та или иная сущность, чтобы можно было рассматривать ее в качестве представителя определенной категории сущностей. Многие из тех категорий, которыми мы пользуемся, не имеют четкого определения, а базируются на довольно расплывчатых понятиях. Создается впечатление, что человек более всего обращает внимание на те бросающиеся в глаза свойства, которые ассоциируются с объектами, наиболее ярко представляющими свой класс.
Такие объекты были названы "прототипическими объектами", или прототипами. В частности, "прототипическая" птица, например воробей, может летать, а потому у нас есть основание полагать, что это — свойство всех птиц, хотя и существуют редкие виды птиц, которые этим свойством не обладают, например пингвины. Именно в этом смысле воробей является лучшим экземпляром категории "птицы", чем пингвин, поскольку он представляет более типические свойства объектов своего класса. Несмотря на существование видов птиц, являющихся исключением в своем классе, мы можем сформулировать обобщенное свойство объектов этого класса следующим образом: "птицы летают".
Теперь обратимся к объектам другого рода— математическим, например многоугольникам. По отношению к этой категории объектов у нас также имеется интуитивное представление о типичности. Например, рассматривая четырехугольники, представленные на рис. 6.5, вряд ли кто будет оспаривать утверждение, что "типичность" объектов увеличивается по мере перехода от фигур, расположенных слева, к фигурам, расположенным справа. Четырехугольник, не обладающий выпуклостью, кажется нам менее типическим, чем выпуклый, а прямоугольник кажется более типическим, чем выпуклый четырехугольник с различными внутренними углами, возможно потому, что площадь фигуры коррелируется в нашем сознании с длиной периметра, а эта связь лучше проявляется при равных значениях внутренних углов.
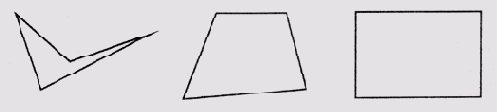
Рис. 6.5.
Изменение "типичности" прямоугольников разного вида
При решении практических проблем мы встречаемся с изобилием исключений из правил, а границы между разными классами оказываются очень размытыми. Системы фреймов оказываются полезными по той причине, что они дают нам в руки средства структурирования эвристических знаний, связанных с приложением правил и классификацией объектов. При использовании фреймов эвристические знания не "размазываются" по программному коду приложения, но и не собираются воедино в виде метазнаний, а распределяются между теми видами объектов, к которым они приложимы, и существуют на уровне управления в иерархии представления таких объектов.
Фреймы и графы
Минский в свой работе [Minsky, 1975] определил фрейм как "структуру данных для представления стереотипных ситуаций". Эту структуру он наполнил самой разнообразной информацией: об объектах и событиях, которые следует ожидать в этой" ситуации, и о том, как использовать информацию, имеющуюся во фрейме. Идея состояла в том, чтобы сконцентрировать все знания о данном классе объектов или событий в единой структуре данных, а не распределять их между множеством более мелких структур вроде логических формул или порождающих правил. Такие знания либо сосредоточены в самой структуре данных, либо доступны из этой структуры (например, хранятся в другой структуре, связанной с фреймом).
Таким образом, по существу, фрейм оказался тем средством, которое помогло связать декларативные и процедурные знания о некоторой сущности в структуру записей, которая состоит из слотов и наполнителей (filler). Слоты играют ту же роль, что и поля в записи, а наполнители — это значения, хранящиеся в полях. Однако, как будет сказано ниже, фреймы отличаются от привычных программных структур вроде записей в языке PASCAL.
Каждый фрейм имеет специальный слот, заполненный наименованием сущности, которую он представляет. Другие слоты заполнены значениями разнообразных атрибутов, ассоциирующихся с объектом. Это могут быть и процедуры, которые необходимо активизировать всякий раз, когда осуществляется доступ к фрейму или его обновление. Идея состоит в том, чтобы выполнение большей части вычислений, связанных с решением проблемы, явилось побочным эффектом передачи данных во фрейм или извлечения данных из него.
Фрейм также можно рассматривать как сложный узел в особого вида ассоциативной сети. Как правило, фреймы организованы в виде "ослабленной иерархии" (или "гетерархии"), в которой фреймы, расположенные ниже в сети, могут наследовать значения слотов разных фреймов, расположенных выше. (Гетерархия — это "запутанная иерархия", т.е. ациклический граф, в котором узлы могут иметь более одного предшественника.)
Фундаментальная идея состоит в том, что свойства и процедуры, ассоциированные с фреймами в виде свойств узлов, расположенных выше в системе фреймов, являются более или менее фиксированными, поскольку они представляют те вещи или понятия, которые в большинстве случаев являются истинными для интересующей нас сущности, в то время как фреймы более нижних уровней имеют слоты, которые должны быть заполнены наиболее динамической информацией, подверженной частым изменениям. Если такого рода динамическая информация отсутствует из-за неполноты наших знаний о наиболее вероятном состоянии дел, то слоты фреймов более нижних уровней заполняются данными, унаследованными от фреймов более верхних уровней, которые носят глобальный характер. Данные, которые передаются в процессе функционирования системы от посторонних источников знаний во фреймы нижних уровней, имеют более высокий приоритет, чем данные, унаследованные от фреймов более верхних уровней.
Среди связей в системе фреймов особо нужно выделить связи между экземплярами и классами и связи между классами и суперклассами. Узел Компьютер имеет связь с узлом Машина, которая представляет отношение "класс-суперкласс", а узел sol2, представляющий конкретный компьютер (тот, на котором я работаю), имеет связь с узлом Компьютер, которая представляет отношение "экземпляр-класс". Свойства и отношения, которые в типичной семантической сети кодируются маркировкой связей между узлами, теперь кодируются с помощью представления слот-заполнитель. Кроме того, со слотами может быть ассоциирована любая дополнительная информация, например процедуры вычисления значения этого слота в случае отсутствия явного его заполнения, процедуры обновления значения слота при изменении значения другого слота, ограничения на величины, хранящиеся в слотах, и т.д.
Значения по умолчанию и демоны
Представьте себя на некоторое время в роли агента по оценке недвижимости. Вы должны оценить примерную стоимость на рынке земельных участков, полной информацией о которых не располагаете. Большинство участков имеет, как правило, форму выпуклых прямоугольников, поэтому можно оценить стоимость участков, предполагая, что те, о которых идет речь, также имеют подобную форму, если только у вас нет конкретной информации об обратном.
Предположим, что граф на рис. 6.6 представляет знания о плоских геометрических фигурах, которые можно использовать для логических рассуждений о форме участков. Каждый узел на этом графе имеет связанную с ним структуру записей (фрейм), формат которой приведен ниже.
NAME (ИМЯ):
Number of sides (Количество сторон):
Length of sides (Длины сторон):
Size of Angles (Углы):
Area (Площадь):
Price (Цена):
Практически все слоты фрейма Многоугольник придется оставить незаполненными, поскольку ничего нельзя сказать о сторонах и углах типичного многоугольника. Однако для слота Количество сторон в качестве значения по умолчанию можно установить 4, поскольку подавляющее большинство земельных участков имеет форму четырехугольника. Таким образом, все земельные участки, информация о форме контура которых отсутствует, будут полагаться четырехугольными. Слот Площадь также нельзя заполнить, но известно, как вычислить площадь многоугольника, располагая другой информацией о нем. Любой n-сторонний многоугольник можно разбить на п-2 треугольника, вычислить их площади и затем просуммировать результаты. Программу, реализующую эту процедуру, можно подключить к слоту Площадь. Процедуры, подключенные к структуре данных и запускаемые на выполнение при появлении запроса или обновлении информации в структуре, иногда называют демонами. Те демоны, которые по запросу вычисляют некоторые значения, называются демонами по требованию (IF-NEEDED).
Полезно также иметь демон, который при заполнении слота Площадь сразу вычислял бы цену участка. Эта процедура относится к другому типу демонов — демонам добавления (IP-ADDED) — и подключается также к слоту Площадь. Теперь при обновлении или установке значения слота Площадь автоматически будет вычислена цена участка, а результат будет помещен в слот Цена.
Перейдем к следующему уровню в иерархии фреймов. Для фрейма Четырехугольник совершенно очевидно нужно установить значение 4 в слот Количество сторон. Это значение будет наследоваться фреймами на каждом из последующих уровней иерархии. Вычислять площадь и цену всех фигур, представленных фреймами последующих уровней, можно тем же способом, что и для многоугольника. Поэтому описанные выше демоны также могут быть унаследованы всеми последующими фреймами.
Но для четырехугольника можно примерно оценить площадь, даже не располагая информацией о значениях внутренних углов контура, а зная только длины сторон. Вполне приемлемые результаты можно получить с помощью следующего эвристического способа: среднюю длину стороны для одной пары противолежащих сторон умножить на среднюю длину стороны для другой пары. Этот метод даст существенную ошибку только для четырехугольников, не являющихся выпуклыми, а такое встречается очень редко.
Эта эвристика может быть реализована в виде демона по требованию, подсоединенного к слоту Площадь фрейма Четырехугольник. Такой демон должен выполнять следующее:
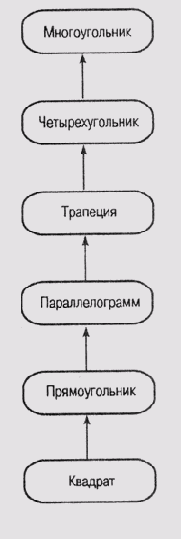
Рис. 6.6.
Иерархия плоских геометрических фигур
если имеется только информация о длинах сторон четырехугольника, то выполнять вычисление по приближенному эвристическому методу;
если отсутствует любая информация о параметрах четырехугольника, не выполнять никаких вычислений.
Фреймы, представляющие все последующие разновидности четырехугольников, наследуют значение из слота Количество сторон фрейма Четырехугольник. Но в каждом из этих фреймов можно реализовать свою процедуру вычисления площади, лучше учитывающую особенности именно данного вида фигур. Например, площадь трапеции можно вычислить как произведение высоты на среднюю длину оснований, а фреймы прямоугольника и квадрата могут унаследовать эту процедуру у параллелограмма, площадь которого равна произведению основания на высоту.
Этот простой пример демонстрирует, как, используя значения по умолчанию и демоны, можно заполнить слоты иерархической системы фреймов, причем этот механизм оказывается более удобным, чем тот, который используется в структурах записей языка PASCAL. Данные, процедуры и определения оформляются в виде единого пакета и образуют отдельный модуль для каждого фрейма, причем разные модули могут совместно использовать данные и процедуры, пользуясь механизмом наследования.
6.1.
Реализация фреймов и наследования в языке CLIPS
(defclass polygon (is-a USER)) (defclass quadrilateral (is-a polygon)) (defclass trapezium (is-a quadrilateral)) (defclass parallelogram (is-a trapezium)) (defclass rectangle (is-a parallelogram)) (defclass square (is-a rectangle))
Обратите внимание на то, что класс polygon (многоугольник) объявлен как подкласс класса USER, который является базовым для всех классов, объявленных пользователем. Отношение is-a (является), которое фигурирует во всех языках представления фреймов, обычно обладает свойством транзитивности: квадрат является прямоугольником, но квадрат также является и трапецией и т.д. Это отношение является антисимметричным, т.е. если квадрат является прямоугольником, то прямоугольник в общем случае не является квадратом.
Для того чтобы представить на языке CLIPS тот факт, что большинство многоугольников предположительно должно иметь четыре стороны, потребуются кое-какие дополнительные языковые конструкции. Нужно будет несколько изменить определение классов polygon и quadrilateral:
(defclass polygon (is-a USER)
(role abstract)
(slot no-of-sides (default 4))) (defclass quadrilateral (is-a polygon)
(role concrete))
Теперь polygon объявлен как абстрактный класс, т.е. класс, не способный самостоятельно порождать определенные объекты. Его подкласс quadrilateral и все последующие подклассы класса quadrilateral являются конкретными классами, т.е. эти классы могут порождать конкретные экземпляры (объекты классов). При определении класса polygon его слоту no-of-sides (количество сторон) назначено по умолчанию значение 4. Это отражает наше интуитивное предположение, что большинство многоугольников будет четырехугольниками. В терминологии систем фреймов такое значение по умолчанию называется фацетом слота no-of-sides.
После этого можно приступить к описанию демонов. Для этого нужно воспользоваться конструкцией defmessage-handler, которая имеется в CLIPS. (Подробно конструкция defmessage-handler также будет описана в следующей главе.)
(defmessage-handler polygon sides () ?self:no-of-sides)
Демон sides связан с классом polygon и попросту получает доступ к слоту no-of-sides того объекта, который его вызвал. Предположим, например, что определен конкретный участок, имеющий форму квадрата, причем ему присвоено наименование square-one.
(definstances geometry (square-one of square))
Система инициализируется командой (reset). Теперь можно активизировать демон, послав ему сообщение
(send [square-one] sides)
В ответ интерпретатор CLIPS выведет результат
Обратите внимание на то, что выражение ?self :no-of-sides вычисляется в контексте объекта square-one, которому было направлено сообщение и который в ответ на него активизировал демона. В этом выражении ?self является переменной и определяет объект, к слоту которого производится обращение, а двоеточие — это инфиксный оператор доступа к конкретному слоту.
Множественное наследование
В то определение понятия наследования, которое было дано в работах Квиллиана, концепция фреймов внесла определенные коррективы. В настоящее время является общепризнанным, что некоторый фрейм может наследовать информацию от множества предшественников в системе фреймов. В результате граф, представляющий связи между фреймами, стал больше походить на решетку, чем на дерево, поскольку каждый узел не обязательно имеет единственного предшественника. Очень часто система строится таким образом, что некоторые фреймы имеют несколько предшественников, хотя в подавляющем большинстве структур сохраняется единственность корня. Пример такой структуры представлен на рис. 6.7.
Новый узел Правильный многоугольник "не вписывается" в прежнюю классификацию, в которой за основу бралось количество сторон. Этот фрейм вводит в систему новый атрибут— "правильность" контура фигуры. Таким образом, появляется возможность передать таким фреймам, как Квадрат и Равносторонний треугольник, некоторые свойства, характерные именно для равносторонних фигур, использовав для этого механизм множественного наследования. Например, все равносторонние многоугольники имеют равные значения внутренних углов, и лучше всего хранить информацию об этом свойстве именно во фрейме Правильный многоугольник, как это следует из принципа когнитивной экономии.
Такая организация связей между фреймами не влечет за собой никаких проблем только до тех пор, пока информация, поступающая от различных источников наследования, не становится противоречивой. Но рассмотрим пример, представленный на рис. 6.8. (Он часто используется в специальной литературе и даже получил имя собственное — "Алмаз Никсона", по причинам, которые станут ясны далее.)
Положим, мы договорились считать по умолчанию, что квакеры — это пацифисты, т.е. в слоте пацифизм фрейма квакер "прописано" значение истина, и что республиканцы пацифистами не являются, т.е. в слоте пацифизм фрейма республиканец "прописано" значение ложь. Все это означает, что при отсутствии более полной информации о каком-либо конкретном республиканце или квакере предполагается, что он именно так относится к идеям пацифизма.
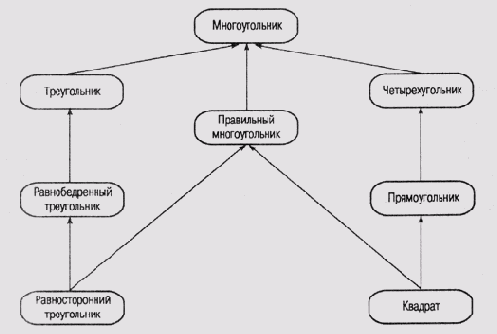
Рис. 6.7.
Гетерархическое представление множества геометрических фигур
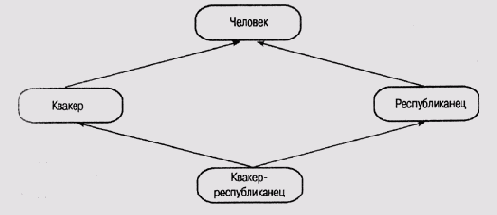
Рис. 6.8.
Конфликт при множественном наследовании свойств
Поскольку значения, предлагаемые по умолчанию, конфликтуют друг с другом, мы, используя только ранее введенную информацию, не можем ничего сказать о пацифизме Ричарда Никсона. В такой ситуации некоторые системы, использующие механизм наследования, отказываются давать однозначное заключение. Системы с таким поведением получили наименование скептических (см., например, [Horty et al, 1987]). Другие, обнаружив подобный конфликт, выносят заключение наудачу. За ними закрепилось определение доверчивые (см., например, [Touretzky, 1986]).
Трудно отдать предпочтение какой-либо из этих стратегий. Но в любом случае лучше заранее подумать о том, как избежать подобных конфликтов при внедрении систем фреймов. Например, можно оспорить мнение, что миролюбивый республиканец — явление более редкое, чем квакер, поддерживающий акции с применением силы, и либо установить определенный порядок анализа наследования от различных предшественников, либо не использовать в данном случае механизм наследственности и принудительно установить значение истина для слота пацифизм во фрейме квакер-республиканец. Есть и альтернативный вариант— подключить к слоту пацифизм во фрейме квакер-республиканец специальный демон по требованию, использующий "для устранения неоднозначности какие-либо "посторонние" знания, которыми мы не располагаем на стадии конструирования системы фреймов. Так, квакер-республиканец может не следовать идеям пацифизма в год выборов в соответствии с общей политикой своей партии, но в обычное время будет рассматриваться как пацифист, полагая, что квакерское воспитание пересиливает партийную дисциплину.
Следует отметить, что анализ сетей с наследованием оказывается проще, чем анализ систем фреймов, поскольку узлы в сети не нуждаются в слотах или подключенных процедурах. Неоднозначность в сети устанавливается путем анализа ее топологии. Для того чтобы в сети потенциально могла появиться неоднозначность, о которой идет речь, необходимо, чтобы набор узлов {А, В, С, ...} образовал ациклический граф со связями двух типов: положительные связи, которые означают, что А является элементом В, и отрицательные связи, которые означают, что А не является элементом В. Тогда мы сможем представить проблему выяснения глубины пацифистских взглядов Р. Никсона в виде сети рис. 6.9. Здесь пацифист — это узел со своими собственными правами, и отрицательный характер связи между ним и узлом республиканец показан засечкой на линии связи.
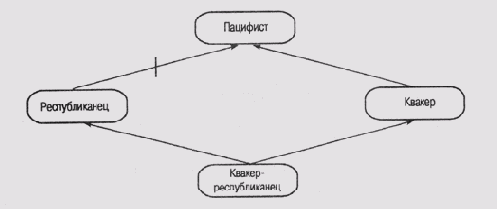
Рис. 6.9.
Представление "проблемы Никсона" в виде сети с наследованием
Сравнение сетей и фреймов
Подводя итог всему сказанному выше об ассоциативных сетях и фреймах, отметим, что в большинстве предлагаемых структур сетей не удалось дать четкий ответ на два важных вопроса.
Что же действительно стоит за узлами и связями в сети?
Как можно эффективно обрабатывать информацию, хранящуюся в такой структуре?
В большинстве последних исследований, касающихся представления знаний, предпочтение отдается фреймам. Такой подход дает вполне удовлетворительные ответы на сформулированные выше вопросы. Семантика узлов и связей четко прослеживается благодаря разделению узлов на узлы-типа и узлы-лексемы и ограничению количества связей. Эффективность обработки обеспечивается подключением к узлам специфических процедур, на которые возлагается вычисление значений переменных в ответ на запросы или при обновлении значений других свойств узла.
Использование фреймов в качестве основной структуры данных, хранящей информацию о типичных объектах и событиях, в настоящее время широко распространено в практике создания приложений искусственного интеллекта (см. об этом в главах 13 и 16). Большинство программных инструментальных средств, предназначенных для построения экспертных систем, обеспечивает тем или иным способом организацию базы знаний на основе фреймов (см. об этом подробнее в главах 17 и 18). Во многих случаях желательно оценить, какими возможностями обладает механизм представления гипотез с помощью фреймов в части использования таких данных, как совокупность симптомов или результатов наблюдений за поведением объектов. Сопоставление этих данных с информацией, хранящейся в слотах фреймов, предоставляет свидетельство в пользу гипотез, представленных фреймом, а также позволяет формулировать определенные предположения относительно других данных, например предположить существование дополнительных симптомов, присутствие или отсутствие которых сможет подтвердить (или опровергнуть) анализируемую гипотезу (см. об этом подробнее в главе 13).
Естественно, для того чтобы реализовать систему фреймов в виде, пригодном для работы с конечным пользователем, требуется разработать программную оболочку и средства пользовательского интерфейса. Хотя к слотам отдельных фреймов и могут быть подключены специальные процедуры, эти локальные модули не способны взять на себя все заботы об организации вычислительного процесса в системе. Необходимо иметь в той или иной форме специальный интерпретатор, который будет формировать и обрабатывать запросы и принимать решение, при каких условиях можно считать достигнутой цель, сформулированную в запросе. Поэтому чаще всего фреймы используются в сочетании с другими средствами представления знаний, в частности в сочетании с порождающими правилами. В следующей главе мы рассмотрим стиль программирования, который в определенной степени избавляет структурированные объекты от необходимости пользоваться внешними средствами контроля, поскольку позволяет объектам пересылать сообщения друг другу и инициировать таким образом более сложные вычисления.
Рекомендуемая литература
В двух сборниках [Bobrow and Collins, 1975] и [Findler, 1979] содержится подборка статей, которые дают достаточно полное представление об исследованиях, выполненных в то время, когда проблематика ассоциативных сетей вызывала наибольший интерес. Начинать изучение концепции фреймов следует с пионерской статьи Минского, опубликованной в сборнике [Winston, 1975], в которой даны исходные формулировки базовых понятий, таких как "типичность" и "значения по умолчанию". Другие понятия, связанные с этой концепцией, рассматриваются в работе Шенка и Абельсона [Schank and Abelson, 1977].
Турецкий рассмотрел некоторые теоретические вопросы построения сетей с наследованием и предложил весьма интересную процедуру формирования суждений при наличии исключений [Touretzky, 1986]. Среди более поздних работ, посвященных этим проблемам, следует отметить [Touretzky et al, 1987], [Horty et al., 1987] и [Selman and Levesque, 1989]. В последней статье показано, что предложенная Турецким процедура относится к классу NP-hard, т.е. для обширных сетей с большим количеством связей становится "вычислительно необозримой".
Позднее Томасон опубликовал обзор современных работ по сетям с наследованием [Thomason, 1992], а в двух работах Йена описана методика интеграции концепции сетей с наследованием в экспертные системы, основанные на порождающих правилах [Yen et al., 1991,a], [Yen et al, 1991, b].
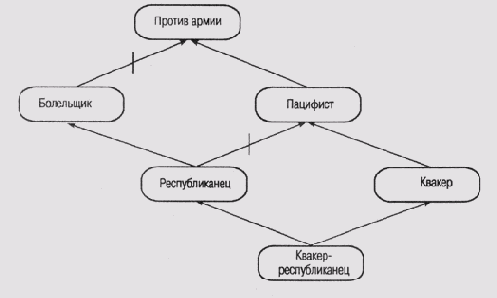
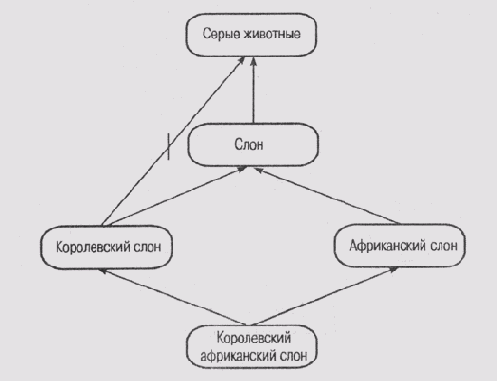
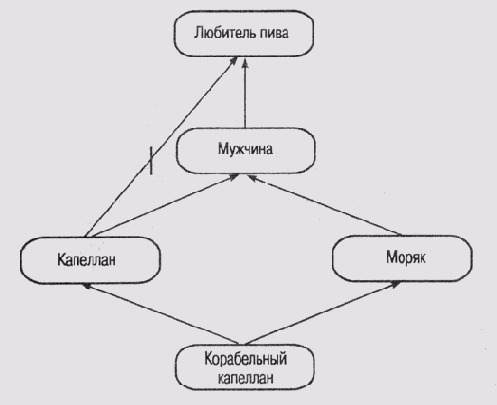
можно ли считать фреймы не1. Прочитайте статью Хейеса в сборнике [Brachman and Levesque, 1985]. Как вы думаете, можно ли считать фреймы не более чем средством реализации подмножества логики предикатов, или они позволяют смоделировать экстралогические свойства, присущие человеку, формулирующему суждения? 2. Неоднозначность, которую мы обнаружили в "проблеме Никсона", можно распространить каскадно и получить еще более замысловатые примеры. Один из них взят из работы [Touretzky et al., 1987] (рис. 6.10). Познакомьтесь с этой работой, а затем ответьте на следующие вопросы. I) К какому заключению придет доверчивый резонер, рассуждая об отношении квакера-ре спубликанца к армии? II) К какому заключению придет резонер-скептик? 3. Примеры сетей с наследованием, представленные на рис. 6.11 и 6.12, также взяты из работы [Touretzky et a/., 1987]. На этих рисунках представлены две топологически идентичные сети, которые отличаются только маркировкой узлов. На рис. 6.11 показано, что королевские слоны являются исключениями, поскольку не имеют серой окраски, а на рис. 6.12 показано, что капелланы являются исключениями, поскольку это мужчины, не склонные к употреблению пива.
Рис. 6.10.
Сеть с наследованием, в которой имеется каскад неоднозачностей
Рис. 6.11.
Проблема "королевского слона"
Рис. 6.12.
Проблема "корабельного капеллана " |