Анализ эффективности
В данном разделе исследуется влияние сжатых объектов на производительность выполнения запросов. Если данные хранятся в сжатых таблицах, производительность выполнения запросов к ним может существенно возрасти. Как было описано в разделе об экономии пространства, количество блоков, требуемое для хранения данных в сжатых таблицах, может быть существенно меньше чем в несжатых таблицах. Таким образом, запросы к сжатым таблицам читают меньше блоков базы данных, что непосредственно повышает производительность выполнения операций чтения в запросах.
Чтобы показать выгоды от сжатия данных для запросов в схеме типа "звезда", мы будем анализировать производительность выполнения 3 запросов типа "звезда", которые также были получены из пользовательской среды примера, рассмотренного в предыдущем разделе. Чтобы показать выгоды от сжатия данных для запросов в нормализованной схеме, мы будем анализировать запросы эталонного теста TPC-H, используя недавно опубликованные результаты теста "TPC-H 100 GB". Полное описание эталонного теста доступно на сайте TPC (www.tpc.org). Заметим, данные об общем затраченном времени "сжатых" прогонов теста извлекаются из опубликованных результатов эталонного теста TPC-H [1], а данные о "несжатых" прогонах получаются во время выполнения фазы настройки теста. В тесте TPC-H выполняется набор из 22 бизнес-запросов, спроектированных для демонстрации функциональных возможностей системы, в некотором смысле представляющих сложные приложения бизнес-анализа [2]. Обсуждение всех 22 запросов далеко выходит за рамки данной работы. Поэтому мы ограничимся обсуждением запросов 1, 6 и 15.
Функционирование механизма сжатия таблиц
СУБД Oracle9i Release2 сжимает данные, устраняя дубликаты значений в блоках базы данных. В алгоритме используется метод сжатия информации без потерь на основе словаря (lossless dictionary-based compression technique) [4]. Сжатые данные, хранимые в блоках базы данных, являются самодостаточными (self-contained). То есть, вся информация, необходимая для восстановления исходных данных в блоке, находится в самом этом блоке. Алгоритм решает, исходя из длины столбца и количества экземпляров значений, будет ли для конкретного столбца создаваться вход в таблице идентификаторов (словаре). Сжимаются только целые столбцы или последовательности столбцов. Все экземпляры таких значений заменяются короткой ссылкой на таблицу идентификаторов. Для коротких значений и значений с небольшим количеством экземпляров входы в таблице идентификаторов не создаются. Чтобы добиться оптимальной производительности, столбцы в блоке могут быть переупорядочены. Тем не менее, это прозрачно для пользователей.
По сравнению с другими методами сжатия, в которых для сжатия целой таблицы используется фиксированное количество входов в таблице идентификаторов, обычно 256, реализация механизма сжатия в СУБД Oracle имеет много преимуществ. Во-первых, чтобы получить оптимальные результаты сжатия, в СУБД Oracle количество входов в таблице идентификаторов выбирается системой на уровне блоков во время загрузки данных. Во-вторых, входы в таблице идентификаторов создаются системой и для них не требуется пользовательская настройка. В-третьих, в СУБД Oracle алгоритм сжатия динамически адаптируется к изменениям распределения данных без компрометации механизма сжатия. Следовательно, для создания сжатой таблицы нужно только включить в определение таблицы ключевое слово COMPRESS.
На рис. 1 показаны различия между хранением данных в сжатом блоке по сравнению с несжатым блоком. Исключая таблицу идентификаторов в начале блока, сжатые блоки базы данных очень похожи на обычные блоки базы данных. Модификации кода, сделанные в СУБД Oracle для реализации механизма сжатия, были существенно локализованы. Были модифицированы только те части кода, которые имеют дело с форматированием блока и доступом к строкам и столбцам. В результате, сжатые блоки полностью прозрачны для пользователей базы данных и любых приложений, а все средства и функции СУБД, которые работают с обычными блоками базы данных, также работают и со сжатыми блоками базы данных.
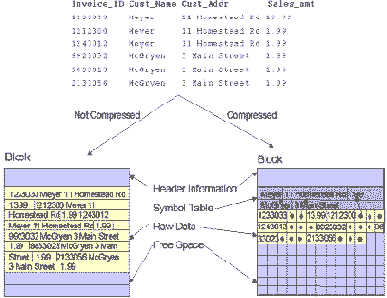
Рис. 1. Сжатый блок по сравнению с несжатым блоком
Надписи на рисунке:
· Not Compressed - несжатый;
· Compressed - сжатый;
· Block - блок;
· Header Information - информация заголовка;
· Symbol Table - таблица идентификаторов;
· Raw Data - данные строк;
· Free Space - свободное пространство.
СУБД Oracle9i Release2 сжимает данные, устраняя дубликаты значений в блоках базы данных. В алгоритме используется метод сжатия информации без потерь на основе словаря (lossless dictionary-based compression technique) [4]. Сжатые данные, хранимые в блоках базы данных, являются самодостаточными (self-contained). То есть, вся информация, необходимая для восстановления исходных данных в блоке, находится в самом этом блоке. Алгоритм решает, исходя из длины столбца и количества экземпляров значений, будет ли для конкретного столбца создаваться вход в таблице идентификаторов (словаре). Сжимаются только целые столбцы или последовательности столбцов. Все экземпляры таких значений заменяются короткой ссылкой на таблицу идентификаторов. Для коротких значений и значений с небольшим количеством экземпляров входы в таблице идентификаторов не создаются. Чтобы добиться оптимальной производительности, столбцы в блоке могут быть переупорядочены. Тем не менее, это прозрачно для пользователей.
По сравнению с другими методами сжатия, в которых для сжатия целой таблицы используется фиксированное количество входов в таблице идентификаторов, обычно 256, реализация механизма сжатия в СУБД Oracle имеет много преимуществ. Во-первых, чтобы получить оптимальные результаты сжатия, в СУБД Oracle количество входов в таблице идентификаторов выбирается системой на уровне блоков во время загрузки данных. Во-вторых, входы в таблице идентификаторов создаются системой и для них не требуется пользовательская настройка. В-третьих, в СУБД Oracle алгоритм сжатия динамически адаптируется к изменениям распределения данных без компрометации механизма сжатия. Следовательно, для создания сжатой таблицы нужно только включить в определение таблицы ключевое слово COMPRESS.
На рис. 1 показаны различия между хранением данных в сжатом блоке по сравнению с несжатым блоком. Исключая таблицу идентификаторов в начале блока, сжатые блоки базы данных очень похожи на обычные блоки базы данных. Модификации кода, сделанные в СУБД Oracle для реализации механизма сжатия, были существенно локализованы. Были модифицированы только те части кода, которые имеют дело с форматированием блока и доступом к строкам и столбцам. В результате, сжатые блоки полностью прозрачны для пользователей базы данных и любых приложений, а все средства и функции СУБД, которые работают с обычными блоками базы данных, также работают и со сжатыми блоками базы данных.
Рис. 1. Сжатый блок по сравнению с несжатым блоком
Надписи на рисунке:
· Not Compressed - несжатый;
· Compressed - сжатый;
· Block - блок;
· Header Information - информация заголовка;
· Symbol Table - таблица идентификаторов;
· Raw Data - данные строк;
· Free Space - свободное пространство.
Экономия пространства в результате сжатия
Сжатие таблиц может привести к существенному уменьшению потребности в дисковом пространстве и кеше буферов для таблиц базы данных. Для сжатия данных на уровне блоков алгоритм сжатия использует избыточность данных, поэтому, чем выше избыточность данных в одном блоке, тем больше будут выгоды от сжатия. Хотя может быть и избыточность данных в совокупности блоков, такие данные не могут быть использованы для их дальнейшего сжатия.
Если таблица определена как "сжатая" (compressed), она будет использовать меньше блоков данных на диске, уменьшая, следовательно, потребности в дисковом пространстве. Данные из сжатой таблицы читаются в сжатом формате, и они восстанавливаются только во время доступа к ним. Поскольку данные кешируются в своем сжатом формате, то существенно больше данных может быть размещено в одном и том же объеме кеша буферов (см. рис. 4).
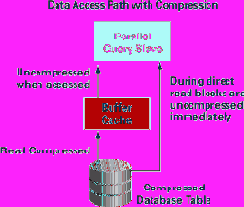
Рис. 4. Пути доступа к сжатым данным
Надписи на рисунке:
· Data Access Path with Compression - пути доступа к сжатым данным;
· Parallel Query Slave - подчиненный процесс параллельного запроса;
· Uncompressed when accessed - восстановление сжатых данных при доступе к ним;
· During direct read blocks are uncompressed immediately - во время прямого чтения блоки восстанавливаются немедленно;
· Buffer Cache - кеш буферов;
· Read compressed - чтение в сжатом формате;
· Compressed Database Table - сжатая таблица базы данных.
Перед измерением экономии пространства в результате сжатия двух наших демонстрационных схем мы определим коэффициент сжатия и экономию пространства. Коэффициент сжатия (КС) таблицы определяется как отношение количества блоков, требуемых для хранения несжатого объекта, к количеству блоков, требуемых для сжатого варианта:
КС = #несжатых_блоков/#сжатых_блоков
Следовательно, экономия пространства (ЭП) определяется следующим образом:
ЭП = ((#несжатых_блоков-#сжатых_блоков)/#несжатых_блоков)х100
Коэффициент сжатия главным образом зависит от содержимого данных на уровне блоков. Неповторяемые поля (поля с высокой кардинальностью), такие, как первичные ключи, не могут быть сжатыми, тогда как поля с очень низкой кардинальностью могут сжиматься очень хорошо. С другой стороны, более длинные поля позволяют получить больший коэффициент сжатия, поскольку экономия пространства будет большей, чем для более коротких полей. Кроме того, если в последовательности столбцов содержится одно и то же содержимое, алгоритм сжатия объединяет эти столбцы в элементе многостолбцового сжатия, что дает еще более лучшие результаты сжатия.
Таблица идентификаторов, в которой содержатся значения полей с множественными экземплярами, автоматически генерируется СУБД Oracle для каждого блока. В большинстве случаев большие размеры блоков позволяют увеличить коэффициент сжатия таблиц базы данных, поскольку с одной таблицей идентификаторов может быть связано большее количество значений столбцов.
Сортировка данных перед их загрузкой может дополнительно увеличить коэффициент сжатия. Чем больше полей с одинаковым содержимым сосредотачивается в каждом блоке, тем более эффективно работает алгоритм сжатия. Если вы знаете, что одно или несколько полей объекта базы данных имеют одинаковые значения - на это указывает небольшое количество уникальных значений сортировка данных по этим полям, вероятно, приведет к увеличению коэффициента сжатия. Тем не менее, сортировка по полям с очень низкой кардинальностью не обязательно приведет к большому увеличению коэффициента сжатия. В результате низкой кардинальности этого поля строки с одинаковыми значениями уже могут иметь высокую концентрацию в каждом блоке. Следовательно, лучшие результаты могут быть достигнуты сортировкой по полям, которые как длинные, так и имеют среднюю кардинальность.
Конфигурация тестируемых схем (типа "звезда" и нормализованная)
В моделях схем, проектируемых для хранилищ данных, существует большое разнообразие способов размещения объектов схем. Одна из моделей схем для хранилищ данных - схема типа "звезда" (star schema). Другая схема - схема в третьей нормальной форме (3NF-схема, third normal form schema). Кроме того, некоторые схемы хранилищ данных не являются ни схемами типа "звезда", ни 3NF-схемами, они имеют свойства обеих схем; такие схемы представляются гибридными моделями схем.
СУБД Oracle9i разработана для поддержки всех схем хранилищ данных наиболее эффективным способом. Некоторые средства могут быть специфическими для одной модели схем (такие, как преобразования запросов типа "звезда", специфические для схем типа "звезда"). Тем не менее, подавляющее большинство средств для хранилищ данных в СУБД Oracle в равной степени применимы для схем типа "звезда", 3NF-схем и гибридных. Основные функциональные возможности для хранилищ данных, такие, как секционирование (включая загрузку данных методом "скользящее окно" - rolling window load technique), параллелизм, материализованные представления и аналитический SQL, реализованы для всех моделей схем. (Прим. ред. С методом "скользящее окно" можно ознакомиться по [5].)
Определение, какую модель схемы следует использовать для хранилища данных, должно быть основано на требованиях и предпочтениях конкретной команды проектировщиков хранилища данных. Сравнение достоинств альтернативных моделей схем выходит за рамки данной работы. Вместо этого, в этой работе для иллюстрации сжатия для различных схем используются примеры схемы типа "звезда" и нормализованной схемы.
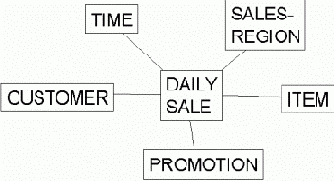
На рис. 2 показан пример схемы типа "звезда", подчеркивающий типичную структуру "звезда", в которой таблица фактов DAILY_ SALES (продажи) - центр "звезда", окруженный таблицами измерений: TIME (время), CUSTOMER (клиент), SALES REGION (регион продаж), ITEM (продукт) и PROMOTION (продвижение). Существует две таблицы итогов, определенные на таблице DAILY_SALES (дневные продажи): WEEKLY_SALES (продажи за неделю) и SALES_AGGR (агрегирование продаж). В таблице WEEKLY_SALES агрегируются продажи из таблицы DAILY_SALES по продуктам и клиентам за каждую неделю. Таблица SALES_AGGR строится на таблице DAILY_SALES с дальнейшим агрегированием по регионам продаж.
В моделях схем, проектируемых для хранилищ данных, существует большое разнообразие способов размещения объектов схем. Одна из моделей схем для хранилищ данных - схема типа "звезда" (star schema). Другая схема - схема в третьей нормальной форме (3NF-схема, third normal form schema). Кроме того, некоторые схемы хранилищ данных не являются ни схемами типа "звезда", ни 3NF-схемами, они имеют свойства обеих схем; такие схемы представляются гибридными моделями схем.
СУБД Oracle9i разработана для поддержки всех схем хранилищ данных наиболее эффективным способом. Некоторые средства могут быть специфическими для одной модели схем (такие, как преобразования запросов типа "звезда", специфические для схем типа "звезда"). Тем не менее, подавляющее большинство средств для хранилищ данных в СУБД Oracle в равной степени применимы для схем типа "звезда", 3NF-схем и гибридных. Основные функциональные возможности для хранилищ данных, такие, как секционирование (включая загрузку данных методом "скользящее окно" - rolling window load technique), параллелизм, материализованные представления и аналитический SQL, реализованы для всех моделей схем. (Прим. ред. С методом "скользящее окно" можно ознакомиться по [5].)
Определение, какую модель схемы следует использовать для хранилища данных, должно быть основано на требованиях и предпочтениях конкретной команды проектировщиков хранилища данных. Сравнение достоинств альтернативных моделей схем выходит за рамки данной работы. Вместо этого, в этой работе для иллюстрации сжатия для различных схем используются примеры схемы типа "звезда" и нормализованной схемы.
На рис. 2 показан пример схемы типа "звезда", подчеркивающий типичную структуру "звезда", в которой таблица фактов DAILY_ SALES (продажи) - центр "звезда", окруженный таблицами измерений: TIME (время), CUSTOMER (клиент), SALES REGION (регион продаж), ITEM (продукт) и PROMOTION (продвижение). Существует две таблицы итогов, определенные на таблице DAILY_SALES (дневные продажи): WEEKLY_SALES (продажи за неделю) и SALES_AGGR (агрегирование продаж). В таблице WEEKLY_SALES агрегируются продажи из таблицы DAILY_SALES по продуктам и клиентам за каждую неделю. Таблица SALES_AGGR строится на таблице DAILY_SALES с дальнейшим агрегированием по регионам продаж.
Рис. 2. Типичная схема типа "звезда"
В нашем втором примере мы показываем сжатие для различного типа нормализованных схем на примере стандартных эталонных тестов (benchmark) для оценки среды поддержки принятия решений TPC-H/TPC-R. (Прим. ред. О тестах TPC см. например, [6].) Схема этих тестов состоит из восьми базовых таблиц, моделирующих хранилище данных типичной среды розничной торговли (см. рис. 3). Таблицы, такие, как PART, SUPPLIER, PARTSUPP и CUSTOMER, содержат относительно статичную информацию о продуктах, которые типичная компания розничной торговли покупает у своих поставщиков (supplier) и продает своим клиентам (customer). Объем этих таблиц составляет примерно 15% от общего объема базы данных. Объем двух самых больших таблиц, LINEITEM и ORDERS, составляет примерно 85% от общего объема базы данных. Они содержат данные об отдельных сделках. В отличие от предыдущего примера эта схема не организована как схема типа "звезда", в ней используется нормализованный [3] подход.

Рис. 3. Нормализованные схемы эталонных тестов TPC-H и TPC-R
Рис. 2. Типичная схема типа "звезда"
В нашем втором примере мы показываем сжатие для различного типа нормализованных схем на примере стандартных эталонных тестов (benchmark) для оценки среды поддержки принятия решений TPC-H/TPC-R. (Прим. ред. О тестах TPC см. например, [6].) Схема этих тестов состоит из восьми базовых таблиц, моделирующих хранилище данных типичной среды розничной торговли (см. рис. 3). Таблицы, такие, как PART, SUPPLIER, PARTSUPP и CUSTOMER, содержат относительно статичную информацию о продуктах, которые типичная компания розничной торговли покупает у своих поставщиков (supplier) и продает своим клиентам (customer). Объем этих таблиц составляет примерно 15% от общего объема базы данных. Объем двух самых больших таблиц, LINEITEM и ORDERS, составляет примерно 85% от общего объема базы данных. Они содержат данные об отдельных сделках. В отличие от предыдущего примера эта схема не организована как схема типа "звезда", в ней используется нормализованный [3] подход.
Рис. 3. Нормализованные схемы эталонных тестов TPC-H и TPC-R
Лучшие практические методы
Сжатие таблиц лучше всего использовать в условиях рабочих нагрузок с интенсивным выполнением операций чтения, преобладающих в приложениях поддержки принятия решений. Рекомендуется сжимать большие таблицы, такие, как таблицы фактов и материализованные представления схем типа "звезда" и таблицы схем в третьей нормальной форме (3NF-схемы), в которых содержатся транзактные данные. Не рекомендуется сжимать небольшие таблицы, такие, как измерения схем типа "звезда", поскольку они незначительно влияют на общую экономию пространства.
Можно сжимать некоторые или все секции секционированных таблиц. Например, в больших хранилищах данных, в которых данные обычно секционированы, можно для максимизации использования пространства сжимать секции, к которым нет частого доступа. Если однако секция модифицируется ETL-процессом (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных), то следует оценивать накладные расходы сжатия.
Для увеличения коэффициента сжатия данные таблиц перед их сжатием могут быть отсортированы. Тем не менее, во многих случаях, как обсуждалось ранее, данные приложений поддержки принятия решений кластеризуются естественным образом, следовательно, очень хорошие коэффициенты сжатия получаются без дополнительных усилий. Дополнительные рекомендации по использованию нового механизма сжатия в СУБД Oracle можно найти на веб-сайте Oracle Technology Network ().
Кроме того, в большинстве случаев большие размеры блоков повышают коэффициент сжатия таблицы базы данных, так как с одной и той же таблицей идентификаторов может быть связано больше значений столбцов.
Нормализованная схема (эталонные тесты TPC-H и TPC-R)
В нормализованных схемах для эталонных тестов TPC-H и TPC-R доминируют две таблицы: LINEITEM и ORDERS. Эти таблицы, в которых хранится информация о заказах, похожи на таблицы фактов в схеме типа "звезда", и они содержат приблизительно 75% всех данных. Сжатие таблицы LINEITEM - наибольшее, с коэффициентом сжатия, равным примерно 1.6, тогда как таблица ORDERS сжимается с коэффициентом сжатия, равным примерно 1.2 (см. рис. 5). Это означает, что для сжатых вариантов таблиц LINEITEM и ORDERS требуется приблизительно 60 и 80 процентов от объема несжатых таблиц. Общий коэффициент сжатия для базы данных эталонного теста TPC-H равен примерно1.4, что приводит к экономии пространства, приблизительно равной 29%.
Обсуждение производительности выполнения запросов типа "звезда"
(Прим. ред. В данном разделе автор вводит два нетрадиционных для документации Oracle термина: probe table и build table. Происхождение этих терминов можно пояснить, например, следующей фразой из [8] "Hash join uses the smaller input to build a hash table and the larger to probe it" - в хеш-соединениях меньшие по объему данные используются для построения хеш-таблицы, а большие для ее зондирования. Мы будем переводить эти термины как первичная таблица [для построения хеш-таблицы] и вторичная таблица [хеш-соединения] соответственно.
Мы выполняли описанные выше запросы в несжатой схеме, а затем - в сжатой схеме. На рис. 9 показаны интервалы общего затраченного времени в секундах (Elapsed Time [s]) и коэффициенты повышения производительности для обоих прогонов всех трех запросов типа "звезда" (Q1, Q2 и Q3). Коэффициент повышения производительности вычисляется по следующей формуле:
где ElaрsedTimeSpeedup - коэффициент повышения производительности, elapsedTime_non_compressed - общее затраченное время в несжатой схеме, elapsedTime_compressed - общее затраченное время в сжатой схеме.
Каждая пара столбиков показывает интервалы общего затраченного времени для одного запроса. Первый столбик показывает общее затраченное время при выполнении данного запроса в несжатой (non-compressed) схеме, а второй - в сжатой (compressed) схеме. Коэффициент повышения производительности показан в процентах для каждой пары столбиков. Для запроса 1 общее затраченное время уменьшилось на 13%, для запроса 2 - на 15% и для запроса 3 - на 11%. Общее затраченное время на выполнение всех 17 пользовательских запросов уменьшилось на 16.5%.
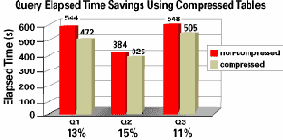
Рис. 9. Экономия общего затраченного времени при выполнении запросов к сжатым таблицам
Повышение производительности выполнения запросов типа "звезда" к сжатой схеме типа "звезда" происходит в результате ускорения доступа к таблицам фактов или таблицам итогов во время второй фазы выполнения запросов. Чем больше коэффициент сжатия, тем большим будет уменьшение общего затраченного времени. Тем не менее, по коэффициенту сжатия невозможно вычислить коэффициент повышения производительности, поскольку последний зависит от количества и заполненности блоков, обрабатываемых запросом. Более того, повышение производительности выполнения запросов зависит от быстродействия подсистемы ввода-вывода. Чем слабее подсистема ввода-вывода, тем больше будет выгод от сжатия.
На рис. 11 показаны интервалы общего затраченного времени в секундах (Elapsed Time [s]) и коэффициенты повышения производительности выполнения трех запросов к сжатым таблицам в эталонном тесте TPC-H (Q1, Q6 и Q15). Этот рисунок организован так же как и рис. 9. Он показывает, что запрос 1 к сжатой таблице LINEITEM выполняется с относительно небольшим замедлением, которое, вполне возможно, находится в границах погрешности измерений. С другой стороны, запросы 6 и 15 выполняются существенно быстрее. Запрос 6 ускоряется на 35%, а запрос 15 - на 38%.
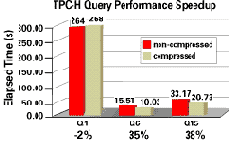
Рис. 11. Экономия общего затраченного времени при выполнении запросов к сжатым таблицам
Суммарный коэффициент повышения производительности вычисляется по следующей формуле:
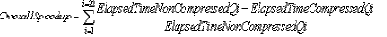
где OverallSpeedup - суммарный коэффициент повышения производительности, ElapsedTime_non_compressedQi - общее затраченное время для i-го запроса к несжатой схеме, ElapsedTime_compressedQi - общее затраченное время для i-го запроса к сжатой схеме.
Суммарный коэффициент повышения производительности выполнения всех 22 запросов к сжатым таблицам по сравнению с запросами к несжатым таблицам в эталонном тесте TPC-H равен приблизительно 10%. Общее затраченное время на тест вставки данных rf1 (Прим. ред. rf - refresh function (функция обновления данных), см. спецификацию стандарта TPC-H [9]) увеличилось приблизительно на 3.9%, тогда как общее затраченное время на тест удаления rf2 уменьшилось приблизительно на 17%. Основная метрика теста TPC-H, QphH@100GB (Прим. ред. QphH - Query-per-Hour Performance Metric, метрика количества запросов, обрабатываемых тестируемой системой в течение часа) увеличилась приблизительно на 10%. При выполнении некоторых запросов мы наблюдали незначительное увеличение потребляемого времени центрального процессора. Как было продемонстрировано в разделе об экономии пространства, данные теста TPC-H сжимаются с коэффициентом сжатия, равным только 1.2 для таблицы ORDERS и 1.6 для таблицы LINEITEM. Запросы же к сжатой базе данных выполняют на 27% меньше обращений к дискам.
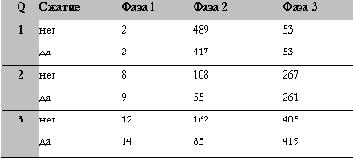
Рис. 10. Детальное распределение интервалов времени по различным фазам выполнения запросов типа "звезда"
На рис. 10 показано распределение интервалов общего затраченного времени выполнения по различным фазам выполнения запросов. Первая фаза выполнения запроса 1 включает в себя доступ к двум битовым индексам (по измерениям CUSTOMER и TIME) и объединение результатов доступа с помощью операции AND. Общее затраченное время выполнения этой фазы приблизительно равно двум секундам независимо от вида схемы, так как эти операции не обращаются к каким-либо сжатым таблицам. Во второй фазе таблица фактов DAILY_SALES соединяется с измерением ITEM (используется хеш-соединение). Большая часть времени выполнения этой фазы затрачивается на просмотр вторичной таблицы хеш-соединения DAILY_SALES, поскольку первичная таблица, используемая для построения хеш-таблицы, ITEM, имеет очень маленький размер. В третьей фазе результирующий набор, полученный во второй фазе, соединяется с двумя измерениями TIME и CUSTOMER. Так же как и в первой фазе, затраченное время выполнения этой фазы приблизительно равно 53 секундам независимо от вида схемы. Небольшие различия во временах выполнения фаз 1 и 3 для "сжатых" и "несжатых" запросов находятся в границах погрешности измерений. Для выполнения запроса 1 к сжатым таблицам требуется приблизительно 472 секунды, а к несжатым таблицам - 544 секунды, общее затраченное время выполнения уменьшилось на 72 секунды или на 13%.
В этом запросе единственным шагом, в котором используются сжатые таблицы, что приводит к изменению поведения во время исполнения, является обращение к таблице фактов DAILY_SALES. В запросах 2 и 3 - это обращение к таблице итогов WEEKLY_SALES. На рис. 10 для всех трех запросов показаны интервалы времени доступа к битовым индексам (фаза 1), первого повторного соединения (фаза 2), в котором происходит обращение к таблице фактов или таблице итогов, и оставшихся повторных соединений с измерениями (фаза 3).
Только при первом повторном соединении (соединении с таблицей фактов или таблицей итогов) постоянно видны различия в общем затраченном времени выполнения запросов в случае обращения к сжатым таблицам. В запросе 2, например, разница для этого соединения составляет приблизительно 53 секунды (17%), тогда как при выполнении повторных соединений с другими измерениями особых изменений общего затраченного времени не видно. К таблице фактов, как вторичной таблице в этом хеш-соединении, осуществляется индексный доступ для зондирования квалифицированных строк в измерении CUSTOMER (использованном как первичная таблица). Уменьшение общего затраченного времени для этого хеш-соединения за счет сжатия таблиц ограничивается преимущественно вторичной таблицей. В общем, за счет сжатия больше выгод от операций с большим временем ввода-вывода, чем от операций с небольшим временем ввода-вывода. Следовательно, чем менее ограничивающие предикаты по битовому индексу используются в первой фазе, тем больше квалифицируется строк таблицы фактов или таблицы итогов, что приводит к большей выгоде от сжатия.
С первого взгляда небольшое уменьшение общего затраченного времени, равное 11%, кажется несогласующимся с большим коэффициентом сжатия таблицы фактов, равным 2.9 (67% экономии пространства). Примите во внимание, что вторая фаза занимает примерно 90% времени выполнения запроса, а экономия пространства, равная 67%, должна была бы уменьшить общее затраченное время приблизительно на 60%. Действительно, это было бы так, если бы читаемые строки объединялись в последовательных блоках. Например, если операция обращается к 5 строкам в 5 разных блоках, размещенных в несжатой таблице с большими промежутками, то независимо от величины коэффициента сжатия, эти 5 строк при сжатии таблицы, вероятно не попадут в один и тот же блок. Следовательно, даже из сжатой таблицы этот запрос будет читать 5 блоков Вот почему операции, в которых не проявляется свойство локальности ссылок, получают меньше выгод от сжатия. Это можно показать, подсчитав количество блоков, необходимых для чтения из сжатой и несжатой таблиц. При доступе к таблице фактов DAILY_SALES запрос 1 читает примерно 92115 блоков в сжатом случае и 94137 блоков в несжатом, разница равна только 2022 блокам или приблизительно 8.15%. Это показывает, что строки, читаемые запросом 1, размещены в таблице с большими промежутками, то есть свойство локальности ссылок отсутствует и, следовательно от сжатия получается меньше выгод (аналогичное поведение наблюдается и у запросов 1 и 2).
Общее затраченное время выполнения запроса номер 1 увеличилось приблизительно на 2%. Это можно объяснить незначительным увеличением использования процессора, а также тем фактом, что этот запрос требует интенсивной работы процессора. Общие затраты при запросе к сжатым таблицам увеличиваются приблизительно на 2%. При выполнении запроса нет свободного времени процессора, поэтому общее затраченное время выполнения запроса увеличивается примерно на тот же объем времени, что и время процессора. Большое уменьшение использования диска, равное приблизительно 38%, очень мало влияет на этот запрос, так как для него дисковая подсистема не является узким местом.
Производительность выполнения запроса номер 6 увеличивается приблизительно на 35%. В этом запросе интенсивно выполняются операции ввода-вывода, поэтому доступное время процессора не используется. Следовательно, повышение нагрузки на процессор может быть легко компенсировано без деградации производительности системы.
Так же как и запрос номер 6, запрос номер 15 выгадывает от сжатия таблиц, показывая 38% повышения производительности. В этом запросе не используется некоторое доступное время процессора, что приводит к уменьшению общего затраченного времени выполнения запроса приблизительно на 8%. Этот запрос больше выгадывает от сжатия, читая из сжатой базы данных на 42% меньше данных по сравнению с несжатой базой данных.
Использование сжатых таблиц в тесте TPC-H в нашей системной конфигурации уменьшает общее затраченное время выполнения большинства запросов. Но повышает общее затраченное время выполнения оставшихся запросов. Запросы с интенсивными операциями ввода-вывода имеют прямую выгоду от сжатия, поскольку в них уменьшается среднее потребление ресурсов, которые ограничивают повышение производительности системы (то есть "узких мест"), а именно, дисковой подсистемы. Запросы с интенсивным потреблением времени процессора также получают выгоду от меньшей нагрузки на дисковую подсистему. Тем не менее, накладные расходы доступа к сжатым таблицам могут "вредить" общему затраченному времени выполнения этих запросов.
Почему схема типа "звезда" сжимается лучше нормализованной схемы эталонного теста TPC-H
В двух предыдущих разделах мы рассмотрели коэффициенты сжатия и экономию пространства, которые могут быть получены в реальных схемах: схеме типа "звезда" и нормализованной схеме эталонного теста TPC-H. При сжатии всех таблиц фактов и таблиц итогов коэффициент сжатия для схемы типа "звезда" оказался приблизительно равным 3.1, что позволило сэкономить примерно 67% пространства. То есть, пространство, занимаемое базой данных на диске, сократилось в результате сжатия более чем на половину. С другой стороны, для нормализованной схемы, в которой сжимались две самые большие таблицы, эквивалентные таблицам фактов в хранилище данных, коэффициент сжатия оказался приблизительно равным только 1.4, а экономия пространства - 29%.
Коэффициент сжатия таблиц зависит от избыточности данных в этих таблицах. Данные сжимаются за счет устранения дубликатов значений в каждом блоке базы данных. Более высокая избыточность данных обычно позволяет получить более высокий коэффициент сжатия. Для таблицы, в которой содержится большое количество столбцов с небольшим количеством различающихся значений (на это указывает представление словаря данных DBA_TAB_COL_STATISTICS), автоматически не следует получение высокого коэффициента сжатия. Это скорее зависит от распределения данных и средней длины каждого конкретного столбца. Очевидно, распределение данных определяет количество потенциальных различающихся значений, а средняя длина столбца - количество записей, хранимых в одном блоке.

Рис. 6. Сжатие таблиц схемы типа "звезда" и схемы тестов TPC-H/R
Внимательное рассмотрение количества различающихся значений в двух столбцах (ADDRESS, REGION_ID) таблицы DAILY_SALES схемы типа "звезда" и в двух столбцах (COMMENT, DISCOUNT) таблицы LINEITEM схемы тестов TPC-H/R, объясняет, почему данные нашего примера схемы типа "звезда" сжимаются лучше данных базы данных тестов TPC-H/R. Для каждого столбца на рис. 6 показано общее количество строк в таблице, общее количество различающихся значений, среднее количество строк в блоке (берется из представления словаря данных DBA_TAB_COL_STATISTICS), вычисленное количество различающихся значений в блоке и измеренное среднее количество различающихся значений в блоке (была исследована репрезентативная выборка из блоков). При вычислении количества различающихся значений в блоке мы предполагаем равномерное распределение строк. То есть, вычисленное количество различающихся значений в блоке равно среднему количеству строк в блоке, если общее количество различающихся значений больше количества строк в блоке, в противном случае, оно равно общему количеству различающихся значений. Рассмотрим следующую равномерно распределенную последовательность номеров {1,2,…5}, которая представляет собой строки, состоящие из одного столбца, значением которого является номер:
В двух предыдущих разделах мы рассмотрели коэффициенты сжатия и экономию пространства, которые могут быть получены в реальных схемах: схеме типа "звезда" и нормализованной схеме эталонного теста TPC-H. При сжатии всех таблиц фактов и таблиц итогов коэффициент сжатия для схемы типа "звезда" оказался приблизительно равным 3.1, что позволило сэкономить примерно 67% пространства. То есть, пространство, занимаемое базой данных на диске, сократилось в результате сжатия более чем на половину. С другой стороны, для нормализованной схемы, в которой сжимались две самые большие таблицы, эквивалентные таблицам фактов в хранилище данных, коэффициент сжатия оказался приблизительно равным только 1.4, а экономия пространства - 29%.
Коэффициент сжатия таблиц зависит от избыточности данных в этих таблицах. Данные сжимаются за счет устранения дубликатов значений в каждом блоке базы данных. Более высокая избыточность данных обычно позволяет получить более высокий коэффициент сжатия. Для таблицы, в которой содержится большое количество столбцов с небольшим количеством различающихся значений (на это указывает представление словаря данных DBA_TAB_COL_STATISTICS), автоматически не следует получение высокого коэффициента сжатия. Это скорее зависит от распределения данных и средней длины каждого конкретного столбца. Очевидно, распределение данных определяет количество потенциальных различающихся значений, а средняя длина столбца - количество записей, хранимых в одном блоке.
Рис. 6. Сжатие таблиц схемы типа "звезда" и схемы тестов TPC-H/R
Внимательное рассмотрение количества различающихся значений в двух столбцах (ADDRESS, REGION_ID) таблицы DAILY_SALES схемы типа "звезда" и в двух столбцах (COMMENT, DISCOUNT) таблицы LINEITEM схемы тестов TPC-H/R, объясняет, почему данные нашего примера схемы типа "звезда" сжимаются лучше данных базы данных тестов TPC-H/R. Для каждого столбца на рис. 6 показано общее количество строк в таблице, общее количество различающихся значений, среднее количество строк в блоке (берется из представления словаря данных DBA_TAB_COL_STATISTICS), вычисленное количество различающихся значений в блоке и измеренное среднее количество различающихся значений в блоке (была исследована репрезентативная выборка из блоков). При вычислении количества различающихся значений в блоке мы предполагаем равномерное распределение строк. То есть, вычисленное количество различающихся значений в блоке равно среднему количеству строк в блоке, если общее количество различающихся значений больше количества строк в блоке, в противном случае, оно равно общему количеству различающихся значений. Рассмотрим следующую равномерно распределенную последовательность номеров {1,2,…5}, которая представляет собой строки, состоящие из одного столбца, значением которого является номер:
Предположим далее, что среднее количество строк в блоке (Block) равно 4. Тогда отображение строк на блоки будет выглядеть следующим образом:
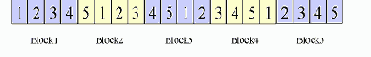
Как видно, в каждом блоке содержится 4 различающихся значения. Впрочем, данная последовательность была выбрана для демонстрации равномерного распределения данных, она не является общим случаем. Читатель может проверить, что разные последовательности могут приводить к уменьшению количества различающихся значений в блоке.
Для столбцов схемы типа "звезда" измеренное среднее количество различающихся значений существенно меньше вычисленного количества различающихся значений. Это указывает на то, что данные являются не равномерно распределенными, а кластеризованными. Это очень распространенное явление для таблиц фактов и таблиц итогов в хранилищах данных; почти в каждой среде хранилища данных при периодическом обновлении данных происходит какое-то группирование или сортировка новых данных. Например, ETL-процесс (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных.), собирающий новую информацию для таблицы фактов из различных источников, должен перед вставкой данных в таблицу фактов сравнивать и агрегировать их, то есть, сортировать данные. Аналогичная кластеризация данных происходит, естественно, и в таблицах итогов, которая выполняется с помощью группирования данных или специализированных OLAP-операций, таких, как операции суперагрегатного группирования rollup и cube.
С другой стороны, в схемах эталонных тестов TPC-H и TPC-R действительное количество различающихся значений в блоке совпадает с вычисленным количеством различающихся значений в блоке, что указывает на строгое равномерное распределение данных. В действительности, генератор данных эталонных тестов TPC-H и TPC-R критиковался за генерацию нормально распределенных данных.
Если данные не кластеризуются, как в случае тестов TPC-H и TPC-R, сортировка данных перед их загрузкой может существенно увеличить сжатие. Выбор столбцов для включения в сортировку зависит от их кардинальности и средней длины. В общем, длинные столбцы обеспечивают большее сжатие по сравнению с короткими столбцами. Что касается кардинальности, то оказалось, что сортировка по столбцам с очень низкой кардинальностью, таким, как GENDER (пол) или MARITAL STATUS (семейное положение), менее эффективна по сравнении с сортировкой по столбцам со средней кардинальностью. Оптимальными столбцами для сортировки представляются те, у которых кардинальность на уровне таблицы равна количеству строк в блоке. Сортировка по столбцам, кардинальность которых меньше количества строк в блоке, менее эффективна, поскольку значения столбца уже имеют большую избыточность. Сортировка по столбцам с каким-либо столбцом с более высокой кардинальностью также приводит к более высокому уровню увеличения сжатия.
Предположим далее, что среднее количество строк в блоке (Block) равно 4. Тогда отображение строк на блоки будет выглядеть следующим образом:
Как видно, в каждом блоке содержится 4 различающихся значения. Впрочем, данная последовательность была выбрана для демонстрации равномерного распределения данных, она не является общим случаем. Читатель может проверить, что разные последовательности могут приводить к уменьшению количества различающихся значений в блоке.
Для столбцов схемы типа "звезда" измеренное среднее количество различающихся значений существенно меньше вычисленного количества различающихся значений. Это указывает на то, что данные являются не равномерно распределенными, а кластеризованными. Это очень распространенное явление для таблиц фактов и таблиц итогов в хранилищах данных; почти в каждой среде хранилища данных при периодическом обновлении данных происходит какое-то группирование или сортировка новых данных. Например, ETL-процесс (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных.), собирающий новую информацию для таблицы фактов из различных источников, должен перед вставкой данных в таблицу фактов сравнивать и агрегировать их, то есть, сортировать данные. Аналогичная кластеризация данных происходит, естественно, и в таблицах итогов, которая выполняется с помощью группирования данных или специализированных OLAP-операций, таких, как операции суперагрегатного группирования rollup и cube.
С другой стороны, в схемах эталонных тестов TPC-H и TPC-R действительное количество различающихся значений в блоке совпадает с вычисленным количеством различающихся значений в блоке, что указывает на строгое равномерное распределение данных. В действительности, генератор данных эталонных тестов TPC-H и TPC-R критиковался за генерацию нормально распределенных данных.
Если данные не кластеризуются, как в случае тестов TPC-H и TPC-R, сортировка данных перед их загрузкой может существенно увеличить сжатие. Выбор столбцов для включения в сортировку зависит от их кардинальности и средней длины. В общем, длинные столбцы обеспечивают большее сжатие по сравнению с короткими столбцами. Что касается кардинальности, то оказалось, что сортировка по столбцам с очень низкой кардинальностью, таким, как GENDER (пол) или MARITAL STATUS (семейное положение), менее эффективна по сравнении с сортировкой по столбцам со средней кардинальностью. Оптимальными столбцами для сортировки представляются те, у которых кардинальность на уровне таблицы равна количеству строк в блоке. Сортировка по столбцам, кардинальность которых меньше количества строк в блоке, менее эффективна, поскольку значения столбца уже имеют большую избыточность. Сортировка по столбцам с каким-либо столбцом с более высокой кардинальностью также приводит к более высокому уровню увеличения сжатия.
В данной работе анализируется эффективность
В данной работе анализируется эффективность механизма сжатия данных, появившегося в СУБД Oracle9i, на примере сжатия таблиц схемы типа "звезда" и нормализованной схемы эталонных тестов TPC-H и TPC-R (то есть, типичных схем в системах поддержки принятия решений). Подчеркнем, сжатие данных, в результате которого может быть достигнута значительная экономия дискового пространства и пространства кеша буферов, не является самоцелью. Современные цены за "мегабайт" дисковой или оперативной памяти делают этот вопрос неактуальным. Главное здесь - повышение общей пропускной способности и уменьшение времени реакции больших систем.
Вместе с тем, следует отметить, этот механизм может быть эффективным и в традиционных интерактивных системах с интенсивным выполнением операций чтения данных с диска. Поскольку сжатие таблиц позволяет уменьшить их размер, это приводит к пропорциональному уменьшению времени, требуемому для резервирования и восстановления базы данных. Кроме того, сжатие таблиц будет несомненно эффективным при работе с табличными пространствами только для чтения (READ ONLY). И все это достигается без каких-либо изменений в приложениях, то есть, этим может заниматься администратор базы данных без привлечения разработчиков приложений.
Данная работа была также с незначительными изменениями опубликована как технический документ (white paper) корпорации Oracle - http://otn.oracle.com / products / bi / pdf / o9ir2_compression_performance_twp.pdf. Некоторые опечатки и ошибки в переводимом документе исправлены по данной публикации. Кроме того, на основании данного документа Микел Посс в соавторстве с Германом Баером (Hermann Baer) опубликовал в Oracle Magazine статью "Decision Speed: Table Compression In Action" (скорость принятия решений: сжатие таблиц на практике) - http://otn.oracle.com / oramag / webcolumns / 2003 / techarticles / poess_tablecomp.htm.
Дополнительно об оптимизации производительности в хранилищах данных можно прочитать в техническом документе "Data Warehouse Performance Enhancements with Oracle9i", An Oracle White Paper, April 2001, http://otn.oracle.com / products / Oracle9i / pdf / o9i_dwperfcomp_dwflow.pdf.
Примеры запросов типа "звезда"
В запросах к схеме типа "звезда" используется функциональное средство СУБД Oracle для преобразования запросов типа "звезда" (star transformation). Это преобразование является мощным методом оптимизации запросов типа "звезда", основанном на неявном переписывании исходного текста запроса. Оптимизатор по стоимости СУБД Oracle выбирает преобразование запросов типа "звезда", когда это целесообразно. Преобразование осуществляется с целью эффективного выполнения запросов. СУБД Oracle обрабатывает такие запросы, используя три фазы. Во время первой фазы Oracle обращается ко всем битовым индексам по измерениям, для которых в запросе заданы предикаты. Затем результирующие битовые вектора объединяется с помощью операций над множествами (AND или OR) в зависимости от логики запроса. В этот шаг входит преобразование окончательного битового вектора в идентификаторы строк. Во время второй фазы с помощью этого набора идентификаторов строк из таблицы фактов извлекаются точно те строки, которые необходимы, и выполняется соединение с первым измерением. Во время третьей фазы этот результирующий набор соединяется с таблицами измерений для извлечения детальных данных, необходимых для завершения запроса. Если базовая схема является схемой типа "снежинка" (snowflake schema), то во время этой фазы также выполняется соединение таблиц измерений. Важно отметить, что конечному пользователю никогда не нужно знать какие-либо детали преобразования запросов типа "звезда".
Схема типа "звезда"
Таблицы фактов и таблицы итогов обычно являются самыми большими таблицами в схеме типа "звезда", занимая 70% или даже больше общего пространства базы данных. Напротив, таблицы измерений имеют очень маленький размер. Следовательно, сжатие таблиц измерений не приводит к большой общей экономии дискового пространства и его нужно рассматривать только при работе с очень большими измерениями. Поэтому мы для нашей конфигурации тестовых схем сжимаем только таблицы фактов и материализованные представления.
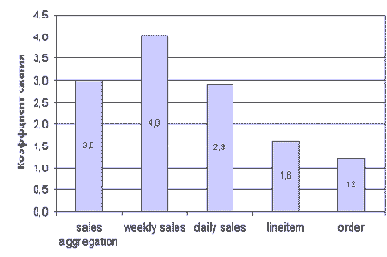
Рис. 5. Коэффициенты сжатия для схемы типа "звезда" и нормализованной схемы
Рис. 5 иллюстрирует, как хорошо сжимаются данные схемы типа "звезда" и нормализованной схемы. Коэффициенты сжатия для таблицы фактов DAILY SALES и таблицы итогов WEEKLY SALES в схеме типа "звезда" варьируются от 2.9 до 4.0, что приводит к экономии пространства от 67 до 75 процентов. То есть, для сжатого варианта таблицы WEEKLY SALES требуется только 25% дискового пространства и пространства кеша буферов по сравнению с ее несжатым аналогом, тогда как для сжатых вариантов таблиц DAILY SALES и SALES AGGREGATION требуется только 33% ресурсов по сравнению с их несжатыми аналогами. Общая экономия пространства базы данных при сжатии только таблиц фактов, достигнутая на схеме заказчика типа "звезда" приблизительно составляет 67% с коэффициентом сжатия, равным примерно 3.1.
Ссылки
[1] TPC-H 100 GB published 07/15/02 by HP/Oracle on Alpha Server ES45 and Oracle 9iR2 Executive Summary:
FDR
.
[2] Oracle9i Data Warehousing Guide Release 2 (9.2) Part Number A96520-01.
[3] Date C.J. "An Introduction to Database Systems", Reading, Mass., Addision Wesley Verlag, 1981. (Прим. ред. Имеется русский перевод: Дейт К. "Введение в системы баз данных". 6-е изд. - М: Вильямс, 1999.
[4] Ziv J. and Lempel A. "A Universal Algorithm for Sequential Data Compression'', IEEE Transactions on Information Theory, Vol. 23, pp. 337--342, 1977.
Ссылки к примечаниям редакторов русского перевода
[5] Ла Планте Брайан "Турбопривод для витрин данных" - Oracle Magazine/Russian Edition, #7/2000, http://www.olap.ru/basic/news/m001015886.asp. [6] Черняк Л. "Снова о тестах TPC" - Открытые системы, #11/2000, http://www.osp.ru/os/2000/11/034.htm. [7] Query Optimization in Oracle9i, An Oracle White Paper, February 2002, http://otn.oracle.com / products / bi / pdf / o9i_optimization_twp.pd. [8] Questions and Answers. SQL Optimization - http://www.ixora.com.au/q+a/sqlopt.htm. [9] "TPC BENCHMARK™H (Decision Support)", Standard Specification, Revision 2.0.0 - Transaction Processing Performance Council (TPC), http://www.tpc.org/tpch/spec/tpch2.0.0.pdf.
СЖАТИЕ ТАБЛИЦ В СУБД Oracle9i RELEASE 2: АНАЛИЗ ЭФФЕКТИВНОСТИ
, ,
компания
Источник: OracleWorld, San Francisco, California, 10-14 November 2002 (http://www.oracle.com/pls/oow/oow_user.show_public?p_event=13&p_type=session&p_session_id=38383 )
(Table Compression in Oracle9i Release 2: A Performance Analysis, By Meikel Poess, Oracle Corporation)
в СУБД Oracle 9i Release
Сжатие таблиц (Table Compression) - новое средство, введенное в СУБД Oracle 9i Release 2, может быть использовано для сжатия целых таблиц, секций таблиц и материализованных представлений. Оно радикально уменьшает потребности в дисковом пространстве и кеше буферов и, во многих случаях, повышает производительность выполнения запросов, особенно в системах с интенсивным вводом-выводом. Сжатие ориентировано на приложения поддержки принятия решений и OLAP-приложения, но и в других областях могут быть также получены большие выгоды. После объяснения работы механизма сжатия таблиц в данной работе вводятся два типа схем, обычно используемых в системах поддержки принятия решений (как в OLAP-системах, так и в хранилищах данных), а именно, схемы типа "звезда" и нормализованные схемы. С помощью этих схем в двух основных разделах данной работы анализируется, как сжатие таблиц может привести к огромной экономии пространства, и исследуется влияние сжатия таблиц на запросы.
Стоимость дисковых подсистем может составлять
Стоимость дисковых подсистем может составлять очень большую часть стоимости создания и сопровождения больших хранилищ данных. СУБД Oracle9i Release 2 помогает уменьшить эту стоимость с помощью сжатия данных, хранимых в базе данных Oracle, и это делается без типичной проблемы выбора между экономией пространства и временем доступа к данным.
Коэффициент сжатия, которого можно достигнуть, зависит от данных и их распределения. В наших тестах, рассмотренных выше, были показаны коэффициенты сжатия от 1.2 до 4.0 (от 17% до 67% экономии пространства). Тем не менее, наблюдались и более высокие коэффициенты сжатия. Например, сжатие детализированных данных разговоров большой телекоммуникационной компании дало в результате коэффициент сжатия, равный 12 (92% экономии пространства). Среди результатов пользовательских тестов это был самый высокий достигнутый коэффициент сжатия. Коэффициент сжатия, равный 5 (80% экономии пространства) был достигнут на агрегированных данных о продажах различным клиентам в различных отраслях промышленности.
Анализируя запросы к схеме типа "звезда" и 3NF-схеме, мы показали, что сжатие таблицы может привести к значительному повышению производительности выполнения запроса. Более всего это характеризуется уменьшением дискового ввода-вывода и незначительным временем восстановления данных, требуемым для доступа к данным сжатых таблиц.
Выполнение запросов к схеме типа "звезда" и 3NF-схеме в значительной степени различается. В запросах к схеме типа "звезда" большая часть времени выполнения затрачивается на доступ к битовым индексам и последующее соединение квалифицированных строк таблицы фактов с таблицами измерений. Поэтому сжатие таблиц на доступ к битовым индексам не влияет. Наоборот, в запросах к 3NF-схеме интенсивно выполняются операции хеш-соединения возможно очень большой части базы данных. Эти операции получают очень большую выгоду, так как с диска читается меньше данных.
Пример запросов к схеме типа "звезда" показывает повышение производительности приблизительно на 12-16%, что приводит к общему повышению производительности выполнения всех 17 запросов приблизительно на 16.5%. С другой стороны, повышение производительности запросов в эталонном тесте TPC-H достигает 38%. Общее повышение производительности всех запросов в тесте TPC-H достигает 10%.
Сжатие таблиц в СУБД Oracle9i Release 2 существенно уменьшает потребности в дисковом пространстве и кеше буферов. Для этого не требуются какие-либо изменения в приложениях.
Запрос номер 1 в эталонном тесте TPC-H
В запросе номер 1 вычисляются множественные агрегированные и итоговые данные, при этом читается и обрабатывается свыше 95% строк самой большой таблицы базы данных. Сканируется только одна эта таблица и получается очень маленький результирующий набор. Поскольку этот запрос выполняет много функций агрегации данных, обычно он требует интенсивной работы процессора.
Запрос номер 6 в эталонном тесте TPC-H
Запрос номер 6 обращается только к большой таблице фактов (LINEITEM), выбирая из нее приблизительно 12% строк и возвращая один столбец ответа. Он выполняет совсем немного функций агрегации, что делает его хорошим кандидатом для создания нагрузки на подсистему ввода-вывода.
Запрос номер 15 в эталонном тесте TPC-H
Из этой таблицы (1/28 таблицы LINEITEM - данные за 3 месяца) осуществляется выборка по дате и агрегирование по поставщику (Supplier). В результирующем наборе после первого шага агрегирования содержатся данные почти о всех поставщиках. Сам запрос возвращает строку о поставщике, имеющем максимальный доход. Этот запрос возвращает одну строку.
Первый запрос вычисляет итоговую сумму
Первый запрос вычисляет итоговую сумму продаж конкретных продуктов за конкретные месяцы 1998 и 1999 годов по конкретным округам. Эти результаты группируются по годам, месяцам, типам округов и продуктам. Полный SQL-оператор можно найти в приложении; на рис. 7 показаны план выполнения оператора и время, затраченное на различных шагах процесса выполнения, как для несжатой таблицы фактов DAILY_SALES, так и для сжатой.

Рис. 7. План выполнения и время, затраченное на различных фазах выполнения запроса типа "звезда" номер 1
Надписи на рисунке:
Elapsed Times - интервалы общего затраченного времени;
Compressed - сжатая;
Not Compressed - несжатая;
NL - nested loop, соединение типа "вложенный цикл";
HJ - hash join, хеш-соединение;
Customer - клиент;
Time - время;
Item - продукт;
Local Index Rowid - идентификатор строки из локального индекса;
Sales Fact Table - таблица фактов по продажам;
Bitmap AND - битовая операция AND;
Bitmap merge - слияние битовых векторов;
Items-Dimension - измерение Items (продукты);
Time-Dimension - измерение Time (время) .
Оптимизатор СУБД Oracle распознает, что этот запрос - запроса типа "звезда" и преобразует его так, как это было описано выше. Доступ к таблице фактов осуществляется через путь доступа по битовому индексу, базирующемуся на битовой операции AND двух битовых индексов измерений TIME и ITEM. По этим битовым индексам Oracle может эффективно вычислить все квалифицированные идентификаторы строк таблицы DAILY_SALES. Поскольку в таблице фактов содержатся только ссылки на таблицы измерений, а не на их детальные данные, измерения нужно повторно соединять с таблицей фактов. (Прим. ред. Термин повторное соединение ("join back", "join-back", "joinback") определяется в техническом документе [7] следующим образом: "With the transformed SQL, this query is effectively processed in two main phases. In the first phase, all of the necessary rows are retrieved from the fact table using the bitmap indexes… In the second phase of the query (the 'join-back' phase), the dimension tables are joined back to the data set from the first phase." (После преобразования этого SQL-оператора обработка запроса эффективно разбивается на две основные фазы. Во время первой фазы из таблицы фактов с помощью битовых индексов извлекаются все необходимые строки… Во время второй фазы (фазы "повторного соединения") таблицы измерений повторно соединяются с набором данных, полученным в первой фазе.).) Это делается последующими операциями соединения с таблицами ITEM и TIME. В список выборки включены детальные данные из таблицы CUSTOMER, поэтому нам также нужно выполнить соединение с измерением CUSTOMER. Кроме того, в плане выполнения показано время, затраченное на определенных шагах процесса выполнения для сжатой и несжатой таблицы фактов соответственно.
SELECT T.year, T.month, C.district, I.name, SUM(sales) FROM customers C, daily_sales S, items I, time T WHERE S.item_nr=I.item_nr AND S.addr_id=C.addr_id AND S.date=T.date AND T.year in (1998, 1999) AND T.month in (1-05-1998, 1-06-1998, … …, 1-03-1999) AND C.district in ('CO', 'CA') AND I.group = 'classic' AND I.item = 'blue gravave' GROUP BY T.year, T.month, C.district, I.name;
Второй запрос вычисляет сумму объемов
Второй запрос вычисляет сумму объемов продаж, проведенных в первые пять месяцев 1998 и 1999 годов для всех клиентов из Чикаго в конкретных регионах продаж. Результирующий набор группируется по фамилиям клиентов, названиям округов, номерам регионов продаж, годам и месяцам. В отличие от запроса 1 в этом запросе используется материализованное представление WEEKLY_SALES в котором содержатся данные о продажах, агрегированные на уровне недель. Этот SQL-оператор можно найти в приложении. План выполнения запроса и время, затраченное на определенные операции, показаны на рис. 8.
Этот запрос также преобразовывается функциональным средством оптимизатора СУБД Oracle для преобразования запросов типа "звезда".
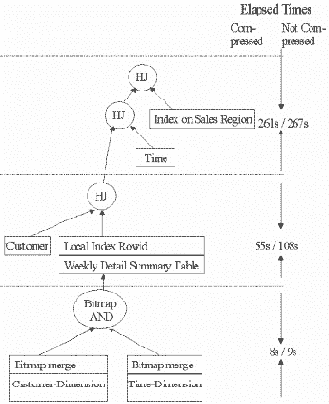
Рис. 8. План выполнения запроса типа "звезда" номер 2
Надписи на рисунке:
Elapsed Times - интервалы общего затраченного времени;
Compressed - сжатая ;
Not Compressed - несжатая;
HJ - hash join, хеш-соединение;
Index on Sales Region - индекс по регионам продаж;
Time - время;
Customer - клиент;
Local Index Rowid - идентификатор строки из локального индекса;
Weekly Detail Summary Table - таблица итогов продаж по неделям;
Bitmap AND - битовая операция AND;
Bitmap merge - слияние битовых векторов;
Customer-Dimension - измерение Items (продукты);
Time-Dimension - измерение Time (время).
SELECT C.district, C.name, T.year, T.month, R.region_number, SUM(sales) FROM customers C, time T weekly_sales S, sales_region R WHERE S.region_id=R.region_id AND S.addr_id=C.addr_id AND S.date=T.date AND T.year in (1998, 1999) AND T.month in (1,2,3,4,5) AND C_district = 'Chicago' AND R.region_number in ('234','4565','111','1') GROUP BY C.district, C.name, T.year, T.month, R.region_number;
вариант запроса номер 2. Вместо
Третий запрос - вариант запроса номер 2. Вместо вычисления суммы объемов продаж, проведенных в первые пять месяцев 1998 и 1999 годов, он вычисляет объем продаж за полные два года, 1998 и 1999. План выполнения этого запроса совпадает с планом запроса 2 и явно не показан.
Запросы в эталонном тесте TPC-H
В этом разделе кратко описаны три запроса в эталонном тесте TPC-H, которые мы будем анализировать в следующих разделах.
Чередование
Если для одного объекта применяются два (или более) преобразования, основанные на стоимости, таких что одно преобразование применимо только после применения другого, то, чтобы оптимизатор выявил оптимальный план, эти преобразования должны чередоваться.
Например, в некоторых случаях должны чередоваться устранение вложенности подзапросов и слияние представлений, так как устранение могло бы повысить оценочную стоимость запроса; однако преобразование "слияние представлений", применяемое к представлению, образованному в процессе устранения вложенности, может привести к оптимальному плану Это означает, что для этого запроса следует выполнять устранение вложенности, а образованное таким образом представление должно сливаться. В запросе Q10 агрегатный подзапрос преобразуется устранением вложенности в представление с группировкой. Это преобразование может приводить к менее оптимальному плану (то есть, Q1 может быть дешевле, чем Q10). Однако когда в Q10 выполняется слияние представлений, это приводит к Q11, план выполнения которого может быть менее дорогим, чем планы запросов Q1 и Q10. При отсутствии чередования преобразований слияния представлений и устранения вложенности к Q1 не будет применено преобразование устранения вложенности, и будет выбран неоптимальный план.
Факторизация соединений
Факторизация соединений (Join Factorization) применяется для запросов с UNION/UNION ALL, где ветви UNION ALL содержат общие соединяемые таблицы. Эти соединяемые таблицы вытягиваются во внешний блок, и блок запроса с UNION ALL превращается в представление, с которым соединяются вытянутые таблицы. Такая факторизация предотвращает многократный доступ к общим таблицам. С использованием факторизации соединений запрос Q14 может быть преобразован в запрос Q15.
Q14
SELECT e.first_name, e.last_name, job_id, d.departament_name, l.city FROM employees e, departaments d, locations l WHERE e.dept_id = d.dept_id and d.location_id = l.location_id UNION ALL SELECT e.first_name, e.last_name, j.job_id, d.departament_name, l.city FROM employees e, job_history j, departaments d, locations l WHERE e.emp_id = j.emp_id and j.dept_id = d.dept_id and d.location_id = l.location_id;
Q15
SELECT V.first_name, V.last_name, V.job_id, d.departament_name, l.city FROM departaments d, locations l, (SELECT e.first_name, e.last_name e.job_id, e.dept_id FROM employees e UNION ALL SELECT e.first_name, e.last_name j.job_id, j.dept_id FROM employees e, job_history j WHERE e.emp_id = j.emp_id) V WHERE d.dept_id = V.dept_id and d.location_id = l.location_id;
Интересно, что имеется множество случаев, когда общие таблицы можно факторизовать, но соответствующие предикаты соединения вытянуть невозможно. В таких случаях предикаты соединения можно оставить внутри представления с UNION ALL, которое затем соединяется на основе техники, описанной в п. 2.2.3 "проталкивание предикатов соединения". Это преобразование будет доступно в следующей версии Oracle.
Исследование производительности
Мы провели эксперименты для изучения эффективности преобразований запросов, основанных на оценке стоимости. Чтобы опираться на реалистичную рабочую нагрузку, мы исследовали запросы, производимые Oracle Applications. Его схема содержит около 14 000 таблиц, представляющих приложения кадровой службы (human resources), финансовые приложения (financial), приложения приема заявок (order entry), CRM, управления цепочкой поставок (supply chain) и т.д. Базы данных большинства приложений имеют сильно нормализованные схемы.
Рабочая нагрузка (workload) содержала 241 000 запросов, произведенных Oracle Applications. Количество таблиц в запросах варьируется между 1 и 159, в среднем — 8 таблиц на запрос. Следует подчеркнуть, что большую часть запросов этой рабочей нагрузки составляют запросы типа SPJ. Так что только у малой части — около 8% — этих запросов имеются подзапросы, раздел GROUP BY, раздел SELECT DISTINCT или представления с UNION ALL, которые являются предметом преобразований, основанных на оценке стоимости, которые использовались в этих экспериментах.
Эвристические преобразования
Традиционные преобразования на основе эвристик выполняются с целью раннего выполнения операций селекции и проекции, удаления избыточных операций, минимизации числа блоков запроса.
Минимизация числа блоков запроса путем слияния их с другими блоками запроса снимает ограничения с множества перестановок операций соединения, которые могут быть сгенерированы, позволяя, таким образом, переупорядочивать большее число таблиц [16]. Традиционный реляционный оптимизатор генерирует только "левоглубинное" (left-deep) (линейное) дерево выполнения; таким образом, можно утверждать, что он никогда не сможет сгенерировать план, эквивалентный плану с "кустистым" (bushy) деревом, генерируемым в случае отсутствия преобразований. Несмотря на это, считается, что значительную часть деревьев соединений с низкой стоимостью обработки можно найти в пространстве левоглубинных деревьев [5].
Как правило, минимизация количества блоков запроса оказывается хорошей эвристикой до тех пор, пока не требуется применение, дублирование или изменение расположения операций DISTINCT или GROUP BY. В Oracle многие преобразования руководствуются эвристиками, которые мы называем императивными правилами, так как они всегда приводят к применению преобразований, если они допустимы. Здесь мы кратко описываем некоторые из этих преобразований.
Кеширование
Некоторые расчеты оптимизатора являются очень дорогостоящими, и они могут быть повторно использоваться, даже если блок запроса изменяется некоторым преобразованием. Например, в Oracle для оценки мощности некоторых таблиц (в частности, для таблиц, для которых не была собрана статистика оптимизатора, и таблиц с несколькимим, возможно, коррелирующими, предикатами фильтрации) производится динамический отбор образцов (dynamic sampling). Соответствующие вычисления являются дорогостоящими, и если однотабличные предикаты не изменяются при преобразовании, результат может быть использован повторно. Результаты этого вычисления и других дорогостоящих вычислений оптимизатора сохраняются в кэше на протяжении нескольких вызовов оптимизатора.
Методы поиска в пространстве состояний
Фундаментальный вопрос, связанный с преобразованиями, которые основаны на оценке стоимости, заключается в том, приведут ли эти преобразования к комбинаторно быстрому росту альтернатив, которые необходимо оценивать, и обеспечат ли они баланс между стоимостью оптимизации и стоимостью выполнения.
Источник многочисленных альтернатив — сами разнообразные преобразования, а также множество объектов (например, блоки запроса, таблицы, ребра соединений, предикаты и т.д.), к которым каждое преобразование может применяться. Если есть N объектов, к которым может применяться преобразование T, то применением T потенциально можно образовать 2N возможных альтернативных комбинаций. В общем случае, если есть M преобразований T1, T2, ..., TM, которые могут применяться к N объектам, то существует (1 + M)N возможных альтернативных комбинаций.
Например, для запроса Q1 нужно рассмотреть 4 альтернативы: без устранения вложенности, с устранением вложенности только первого подзапроса (QS1), с устранением вложенности только второго подзапроса (QS2) или с устранением вложенности обоих подзапросов. Мы обозначаем состояние как массив бит, где n-ый бит показывает, является ли n-ый объект (например, подзапрос) преобразованным (значение 1) или нет (значение 0). Например, состояние (0,1) говорит об устранении вложенности только второго подзапроса. Если есть M преобразований, применяемых к N объектам, состояние представляется матрицей из M×N бит.
Чтобы справиться с проблемой комбинаторно быстрого роста в случае перестановок соединения, было предложено использовать рандомизированные алгоритмы, такие как имитация отжига (Simulated Annealing), генетический поиск (Genetic Search), итерационное уточнение (Iterative Improvement), поиск с запретами (Tabu Search) [20], [21], [11]. Общая идея всех этих стратегий заключается в выполнении квазислучайных блужданий в пространстве поиска, начиная с исходного состояния и пытаясь достичь локального минимума низкой стоимости. Конечно, эти стратегии не гарантируют, что может быть достигнут глобальный минимум — наилучшее преобразование, так как во время блужданий посещается только малая часть пространства состояний. Тем не менее, они имеют практическую значимость, так как качество решения обычно улучшается с длительностью поиска.
Сложность преобразований, основанных на оценке стоимости, определяется количеством альтернативных комбинаций или пространством состояний, которое экспоненциально растет с количеством преобразуемых объектов. Если количество преобразуемых объектов мало, может стать осуществимой техника полного перебора преобразований с исчерпывающим поиском в пространстве состояний. Для ограничения потенциального роста времени оптимизации мы используем несколько различных методов перебора пространства состояний.
Исчерпывающий поиск (Exhaustive Search). При исчерпывающем поиске рассматриваются все возможные 2N состояний пространства состояний N объектов. Например, в запросе Q1 мы рассматриваем 4 состояния: (0,0), (0,1), (1,0) и (1,1). Этот поиск гарантирует нахождение наилучшего решения.
Итерационное уточнение (Iterative Improvement). Метод итерационного уточнения используется для сокращения пространства поиска. Главная идея этого метода состоит в том, что мы начинаем с некоторого исходного состояния и продвигаемся к следующему соседнему состоянию, используя некоторый метод, направленный на поиск локального минимума за счет постоянного выбора нисходящего направления движения; мы повторяем этот поиск локального минимума, начиная с другого исходного состояния в следующей итерации. Алгоритм останавливается, если новые состояния более не находятся, или было достигнуто некоторое условие завершения (например, максимальное количество состояний). Количество состояний, перебираемых этой техникой, лежит в пределах от N до 2N.
Линейный поиск (Linear Search). Основная идея этого метода поиска основана на подходе динамического программирования, в котором предполагается, что для запроса, состоящего из нескольких объектов, достаточно проанализировать на предмет преобразования только некоторый поднабор этих объектов, а затем расширить это дополнительными преобразованиями других объектов. Другими словами, если стоимость (1,0) меньше, чем стоимость (0,0), и стоимость (1,1) меньше, чем стоимость (1,0), то можно надежно предположить, что стоимость (1,1) — самая низкая для всевозможных преобразований, и, следовательно, нет необходимости оценивать стоимость (0,1). Как можно видеть, это может существенно сократить пространство поиска. Этот метод анализирует N + 1 состояний. Линейный поиск работает лучше всего, если преобразования различных элементов независимы одно от другого.
Двухпроходной поиск (Two-pass Search). Двухпроходный поиск — самый дешевый метод поиска, в котором анализируется 2 состояния. Сравниваем стоимость плана выполнения полностью непреобразованного запроса (т.е. состояние (0,0,...)) со стоимостью плана запроса, в котором преобразованы все объекты (т.е. состояние (1,1,...)).
Инфраструктура преобразований, основанных на оценке стоимости, автоматически решает, какой метод поиска следует использовать, основываясь на количестве объектов, которые преобразуются в блоке запроса, характеристиках преобразований и общей сложности запроса. Например, если в блоке запроса содержится небольшое число подзапросов, мы используем для устранения вложенности подзапросов исчерпывающий поиск, а если число подзапросов превышает некоторое фиксированное пороговое значение, мы используем линейный поиск. Если общее число элементов в запросе, подлежащих преобразованию (например, представлений с group-by, подзапросов, вложенность которых можно устранить) превышает некоторое пороговое значение, то мы используем для всех преобразований запроса двухпроходный поиск.
Основные компоненты
В преобразованиях, основанных на стоимости, логические преобразования и физическая оптимизация объединяются для генерации оптимального плана выполнения. Это поясняется на рис. 1.
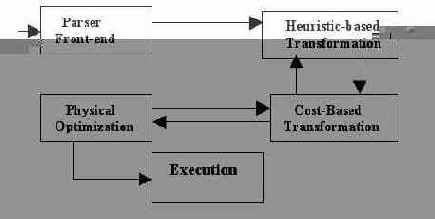
Рис. 1. Обработка запроса в Oracle
Можно считать, что логическое преобразование имеет два отдельных компонента: преобразования, основанные на эвристике и на стоимости. Инфраструктура (framework) преобразований, основанных на оценке стоимости, включает в себя следующее:
алгоритмы преобразований, переводящие полное или частичное дерево запроса в семантически эквивалентную форму;
пространство состояний различных преобразований;
алгоритмы поиска в пространстве состояний;
возможность глубокого копирования (deep copy) блоков запроса и их составных частей;
техника оценки стоимости (физический оптимизатор);
директивы преобразований и аннотации стоимости.
К разных элементам дерева запроса применяются разные преобразования. Например, к подзапросам и представлениям применяются устранение вложенности и слияние представлений соответственно, к узлам графа соединения применяется размещение группировки. К дорогостоящим предикатам применяется преобразование "вытягивание предиката".
Во время оптимизации дерево запроса обходится в восходящем стиле. Различные варианты использования одного или более преобразований элементов дерева запроса образуют различные состояния пространства состояний преобразования. Перед применением отдельного состояния и оценкой его стоимости путем вызова физического оптимизатора выполняется глубкое копирование (частичного) дерева запроса. Для применения каждого состояния обычно требуются различные копии (частичного) дерева запроса. Выбирается состояние преобразования, порождающее наиболее оптимальный план (т.е. наилучшее состояние), и директивы наилучшего состояния передаются исходному дереву запроса, которое преобразовывается в соответствии с этими директивами.
В Oracle преобразования обычно применяются последовательно, то есть каждое преобразование применяется ко всему дереву запроса, затем применяется другое преобразование, и так далее. Для некоторых преобразований соблюдается следующая последовательность их применения:
общая факторизация подвыражений (common sub-expression factorization),
слияние представлений "селекция-проекция-соединение" (SPJ view merging), устранение соединений (join elimination),
устранение вложенности подзапросов (subquery unnesting), слияние представлений с группировкой (group-by (distinct) view merging),
упрощение группировки (group pruning), перемещение предикатов (predicate move around), преобразование операций над множествами в соединения (set operator into join),
размещение группировки (group-by placement), вытягивание предиката (predicate pullup), факторизация соединений (join factorization), преобразование дизъюнкции в объединение (disjunction into union-all), преобразование "звезда" (star transformation), и проталкивание предикатов соединения (join predicate pushdown).
Однако имеются случаи, когда последовательность преобразований не соблюдается. Преобразования могут образовывать конструкции, которые могут повлечь за собой повторение других преобразований, например, преобразование операций над множествами в соединения может образовать SPJ-представление (селекция-проекция-соединение), и, следовательно, могут снова применяться слияние представлений SPJ и проталкивание предикатов фильтрации (filter predicate pushdown). Некоторые преобразования взаимодействуют друг с другом и должны рассматриваться вместе, чтобы можно было принять правильное решение, основанное на оценке стоимости; это обсуждается в подразделе 3.3.
Перемещение предикатов фильтрации
При перемещении предикатов фильтрации (Filter Predicate Move Around) дешевые предикаты сдвигаются в блоки запросов представления для выполнения более ранней фильтрации. Преобразование перемещения предикатов фильтрации выполняется на основе императивных эвристик, поскольку оно может сделать доступными новые пути доступа и уменьшить размер данных, обрабатываемых позднее более дорогостоящими операциями, такими как соединения и группировки.
Предикаты фильтрации могут вытягиваться наверх (pull up), перемещаться в сторону (move across) и проталкиваться вниз (push down) на любой уровень. Интересным расширением [9] является наша возможность проталкивания предикатов фильтрации сквозь раздел PARTITION BY оконных функций стандарта ANSI и разделенное внешнее соединение ANSI, а также сквозь подраздел DIMENSION BY раздела SQL MODEL [25], [26]. Еще одной техникой, уникальной для нашей системы, является проталкивание предикатов сквозь агрегат оконной функции перед вычислением агрегатов [26]. Сейчас она применяется только внутри раздела SQL MODEL, но в следующей версии будет обобщена на оконнные функции, присутствующие в списке SELECT блока запроса. Пусть, например, имеется таблица accounts (act-id, time, balance), в которой в динамике по времени регистрируются текущие остатки на счетах. Рассмотрим встраиваемое представление, рассчитывающее скользящий средний остаток, и внешний запрос, выбирающий его за 12 месяцев для счета'ORCL':
Q7
SELECT acct-id, time, ravg FROM (SELECT acct-id, time, AVG(balance) over (PBY acct-id OBY time RANGE BEETWEN UNBOUNDED PROCEEDING AND CURRENT ROW) ravg FROM accounts) WHERE acct-id='ORCL' AND time <= 12;
В этом запросе предикаты над acct-id и time можно протолкнуть внутрь представления.
Q8
SELECT acct-id, time, ravg FROM (SELECT acct-id, time, AVG(balance) over (PBY acct-id OBY time RANGE BEETWEN UNBOUNDED PROCEEDING AND CURRENT ROW) ravg FROM accounts WHERE acct-id='ORCL' AND time <= 12);
Проталкивание предикатов сквозь PARTITION BY (PBY) можно выполнять всегда. Для проталкивания сквозь ORDER BY (OPBY) требуется анализ [26] затрагиваемого диапазона оконной функции.
Повторное использование аннотаций стоимости поддеревьев запроса
Полная повторная оптимизация каждого преобразованного запроса является дорогостоящей и во многих случаях излишней. Каждое преобразование влияет на несколько известных блоков запроса, и только эти блоки запроса и блок запроса, содержащий их в дереве запроса, требуется повторно оптимизировать. Другими словами, мы можем повторно использовать результаты (которые мы называем аннотациями стоимости) оптимизации двух эквивалентных поддеревьев запроса. Для сложных запросов, содержащих несколько подзапросов или представлений, это может сэкономить значительную часть времени.
Рассмотрим запрос Q1. Используя стратегию исчерпывающего поиска в пространстве состояний, мы оптимизировали бы четыре варианта запроса. Каждый вариант содержит три блока запроса (два внутренних блока запроса и внешний блок запроса QO), так что в целом мы оптимизировали бы двенадцать блоков запроса. Этот процесс сведен в табл. 1. T(Q) обозначает преобразованную версию блока запроса Q.
Таблица 1. Повторное использование и пространство состояний
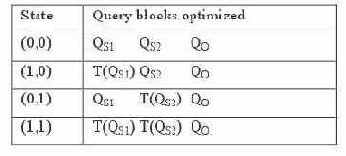
Заметим, что каждый из блоков запроса QS1, QS2, T(QS1) и T(QS2) оптимизируется дважды. Вместо повторной оптимизации каждого из них мы можем повторно использовать информацию о стоимости. Следовательно, мы можем избежать оптимизации четырех из двенадцати блоков запроса. Подзапросы и соответствующие встроенные представления сами могли бы содержать представления и вложенные подзапросы, что привело бы к еще более существенной экономии.
Преобразование операций над множествами в соединения
Операции над множествами MINUS и INTERSECT преобразуются в антисоединение и внутреннее/полусоединение соответственно, что позволяет, тем самым, использовать различные методы и порядки соединений. Однако в семантике операций над множествами и соединений существуют различия: и в INTERSECT, и в MINUS значения null считаются совпадающими, тогда как в соединениях и антисоединениях – нет. Кроме того, MINUS и INTERSECT — операции над множествами и, следовательно, возвращают результирующий набор без дубликатов. Должно быть принято решение, основанное на оценке стоимости, относительно того, следует ли удалять дубликаты во входных или выходных данных соединений; эта проблема аналогична размещению операции DISTINCT (Distinct Placement).
Преобразование, основанное на оценке стоимости
В этом эксперименте мы использовали собственное инструментальное средство для изучения планов выполнения всех 241 000 запросов с выключенным и включенным преобразованием, основанным на оценке стоимости. Из них только для около 19 000 запросов были применимы преобразования, основанные на оценке стоимости. Если преобразования, основанные на оценке стоимости, были выключены, устранение вложенности подзапросов, слияние представлений с группировкой и проталкивание предикатов соединения применялись на основе эвристических правил; в подразделе 2.2. мы описали эвристические правила, используемые для устранения вложенности подзапросов.
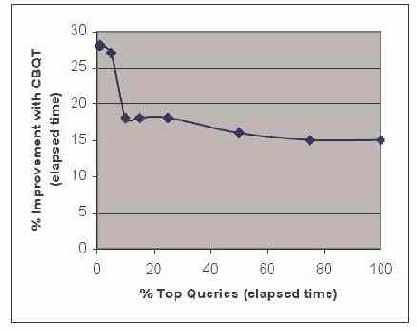
Рис. 2. Относительное повышение производительности за счет преобразований, основанных на оценке стоимости (Cost-Based Query Transformation, CBQT), как функция первых N% наиболее дорогостоящих запросов
Планы выполнения 5 910 запросов (т.е. 2,45% рабочей нагрузки) изменились; отметим, что для некоторых запросов, для которых не было обнаружено различий в плане выполнения, решения, основанные на оценке стоимости и эвристиках, могли быть одинаковы. Затем мы измеряли время оптимизации и выполнения запросов, для которых имелись различия в планах выполнения. В среднем при использовании преобразований, основанных на оценке стоимости, общее время исполнения (оптимизация + выполнение) этих запросов улучшилось на 20%. У небольшой части (18%) запросов, затронутых преобразованиями, производительность упала на 40%. На рис. 2 представлено повышение производительности после преобразований на основе оценки стоимости как функция от первых N наиболее долго выполняющихся запросов.
Первые N определяются как N наиболее долго выполняющихся запросов при отсутствии преобразований, основанных на оценке стоимости. Например, первые 5% наиболее долго выполняющихся запросов показали заметное повышение производительности на 27%; первые 25% показали повышение производительности на 18% и так далее. У первых 20 запросов за счет использования преобразований, основанных на оценке стоимости, производительность в среднем повысилась на 250%. Стоит заметить, что имелся один аномальный запрос, общее время исполнения которого после выполнении преобразований, основанных на оценке стоимости, уменьшилось в 214 раз. Этот запрос не учтен на рис. 2. Отметим, что преобразование, основанное на стоимости, в основном улучшает те запросы, которые являются более дорогостоящими (например, первые 5% из самых дорогостоящих выигрывают от преобразований больше, чем первые 25%).
Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 40%.
Преобразование "размещение группировки"
В еще одном эксперименте на основе преобразования "размещение группировки" (Group-By Placement, GBP) мы сравнивали рабочую нагрузку с запросами, подвергнутыми и не подвергнутыми преобразованию GBP; в Oracle преобразование GBP никогда не применяется на основе эвристик. В этом эксперименте было затронуто более 2000 запросов. После применения GBP производительность в среднем повысилась на 21%. Хотя для некоторых запросов она ухудшилась, у 9 запросов повысилась более чем на 200% , а у двух запросов — более чем на 1000%.
Преобразование запросов, основанное на стоимости
Рафи Ахмед, Эллисон Ли, Эндрю Витковски, Динеш Дас, Хонг Су, Мохамед Зэйд, Тьерри Крюейнс
Перевод
Под ред.
Оригинал: / Rafi Ahmed, Allison Lee, Andrew Witkowski, Dinesh Das, Hong Su, Mohamed Zait, Thierry Cruanes // Proceedings of the 32nd international conference on Very large data base, 2006, pp. 1026 — 1036
Преобразования, основанные на оценке стоимости
Здесь мы кратко остановимся на некоторых из преобразований, которые выполняются в Oracle на основе оценки стоимости.
Преобразования в Oracle
В Oracle выполняется множество преобразований запросов, некоторые из них основываются на оценке затрат, а другие — на эвристиках. В этом подразделе мы обсудим несколько преобразований обеих категорий и выясним, почему для некоторых преобразований требуются решения на основе оценки стоимости, а для других — нет. Следует отметить, что это только подмножество преобразований, выполняемых в Oracle.
Большинство наших обсуждений сосредоточено на деревьях запросов, которые отличаются от алгебраических деревьев операций тем, что дерево запроса позволяет сохранить всю декларативность языка SQL. Дерево запроса превращается в дерево операций после физической оптимизации.
Производительность оптимизации
Описанная техника преобразований, основанная на оценке стоимости, может быть дорогостоящей с точки зрения как времени оптимизации, так и потребления памяти оптимизатором. Копирование структур запроса приводит к постоянному потреблению памяти, а для оптимизации каждого преобразуемого запроса требуется время. Мы обсудим несколько методов снижения влияния преобразований, основанных на оценку стоимости, на производительность оптимизации.
Проталкивание предикатов соединения
В этом преобразовании (Join Predicate Pushdown) предикаты соединения проталкиваются внутрь представления. Проталкиваемые предикаты соединения, оказавшись внутри представления, действуют подобно корреляции, тем самым, делая доступными новые пути доступа. Проталкивание предикатов соединения позволяет соединять представление с внешними таблицами методом вложенных циклов на основе индексного доступа, недоступного обычным представлениям, которые могут соединяться только методами хэш-соединения или сортировки-слияния. Преобразование накладывает такой частичный порядок на соединяемые таблицы, что таблицы, к которым присоединяется представление (посредством проталкиваемых предикатов), должны предшествовать представлению, а представление должно соединяться методом вложенных циклов.
В качестве дополнительной оптимизации после проталкивания предикатов соединения может удаляться операция GROUP BY, если в запросе имеются эквисоединения для всех элементов раздела GROUP BY, и все эти предикаты соединения пригодны для проталкивания. Это возможно, потому что корреляция по условию равенства действует как группировка по значениям соответствующих столбцов. Похожая оптимизация возможна и для представлений с операцией DISTINCT, как показано в запросе Q13.
Рассмотрим следующий запрос, возвращающий информацию о сотрудниках и их истории работы (job history) для сотрудников (employees), которые работают в отделениях (departaments), расположенных в Великобритании (U.K.) или США (U.S.):
Q12
SELECT e1.employee_name, j.job_title, e2.employee_name as mgr_name FROM employees e1, job_history j, employees e2, (SELECT DISTINCT dept_id FROM departments d, locations l WHERE d.loc_id = l.loc_id and l.county_id IN ('U.K.','U.S.')) V WHERE e1.emp_id = j.emp_id and j.start_date > '19980101' and e1.mgr_id = e2.emp_id and e1.dept_id = V.dept_id;
Запрос Q12 преобразуется на основе проталкивания предиката соединения в запрос Q13. Это преобразование позволяет нам удалить из представления дорогостоящую операцию DISTINCT. Внутреннее (inner) соединение преобразуется в полусоединение (semi) (этого не видно по запросу), которое налагает частичный порядок соединения, когда e1 должно предшествовать V.
Q13
SELECT e1.employee_name, j.job_title, e2. employee_name as mgr_name FROM employees e1, job_history j, employees e2, (SELECT dept_id FROM departments d, locations l WHERE d.loc_id = l.loc_id and l.county_id IN ('U.K.','U.S.') and e1.dept_id = d.dept_id) V WHERE e1.emp_id = j.emp_id and j.start_date > '19980101' and e1.mgr_id = e2.emp_id;
В Q13 для соединения представления V может быть использован метод вложенных циклов; это может быть достаточно эффективно, если на d.dept_id имеется индекс, и количество кортежей внешнего запроса сравнительно мало. Тем не менее, для определения того, какой из запросов Q12 и Q13 даст более оптимальный план выполнения, требуется решение, основанное на оценке стоимости.
В Oracle проталкивание предикатов соединения может применяться как к сливаемым (например, с DISTINCT и GROUP BY), так и к несливаемым (например, с объединением или анти-/полу-/внешним соединением) представлениям.
Противопоставление
Если два или более преобразования, основанные на стоимости, применяются к одному объекту таким образом, что это препятствуют их последовательному применению, они должны использоваться поодиночке, чтобы оптимизатор мог выявить наиболее оптимальный план. Это сравнение двух или более преобразований, основанных на стоимости, называется противопоставлением (juxtaposition).
Если к некоторому представлению могут применяться преобразования "слияние представлений" и "проталкивание предикатов соединения", то они должны противопоставляться друг другу, а оптимизатор должен выбирать один из трех вариантов. Рассмотрим пример проталкивания предикатов соединения, приведенный в Q13. Представление с distinct из Q12 может сливаться, что приведет к образованию следующего запроса:
Q18
SELECT DV.employee_name, DV.job_title, DV.mgr_name FROM (SELECT DISTINCT e1.emp_id, e2.emp_id, j.rowid, e1.employee_name, j.job_title, e2.employee_name as mgr_name FROM employees e1, job_history j, employees e2, departaments d, locations l WHERE d.loc_id = l.loc_id and l.country_id in ('UK','US') and e1.dept_id = d.dept_id and e1.emp_id = j.emp_id and j.start_date > '19980101' and e1.mgr_id = e2.emp_id) DV;
Заметим, что в этом слиянии представления операция DISTINCT вытянута, и ключи внешних таблиц добавлены к новому представлению, которое содержит все таблицы исходного запроса Q12.
Будут оценены стоимости запросов Q12, Q13 и Q18, и наименьшая оценка определит, будет (если да, то какое из трех) или нет применяться преобразование к исходному запросу.
Размещение группировки
Преобразование "проталкивание группировки" [1], [24] (Group-By Pushdown) проталкивает операцию GROUP BY внутрь последовательности соединений запроса, приводя, тем самым, к раннему выполнению операции GROUP BY. Раннее выполнение GROUP BY может привести к значительному сокращению числа строк, к которым применяется несколько операций GROUP BY, а также количества строк, используемых позднее в соединениях; следовательно, может улучшиться общая производительность запроса.
Размещение группировки (Group-By Placement) также может позволить вытянуть операцию GROUP BY за пределы последовательности соединений, что мы называем слиянием представления с группировкой. Запрос с GROUP BY может подвергаться различным видам преобразований размещения группировки в зависимости от его графа соединения и таблиц, на которые существуют ссылки в агрегатных функциях. В Oracle преобразование "размещение группировки" ("проталкивание группировки") порождает одно или несколько представлений с группировкой.
Сначала оптимизатор Oracle выполняет слияние представлений с группировками ("вытягивание группировки", Group-By Pullup), за которым далее следует преобразование "проталкивание группировки", не затрагивающее те запросы, которые подверглись слиянию представлений с группировками. Общее преобразование "размещение группировки" будет доступно в следующей версии Oracle.
Родственные работы
В системе перезаписи запросов, основанной на правилах, можно исчерпывающим образом перебрать преобразования кустистого дерева [15] и оценить итоговые планы; это приводит к экспоненциальному росту количества планов и может быть непригодно для коммерческих оптимизаторов. В [19] была предпринята попытка объединения преобразований в двухфазную оптимизацию; во время генерации плана оптимизатор предлагает преобразование, пробует его применить, и переписанный запрос заново оптимизируется и оценивается. В [6] также предлагалось понятие перезаписи, чувствительной к стоимости. Однако в этих работах отсутствует систематическое применение различных возможных преобразований.
Как показано в [10], [22], [4] и [16], в запросах с подзапросами без агрегатов может быть устранена вложенность. В нашей системе поддерживаются почти все предлагавшиеся виды методов устранения вложенности. По нашему опыту, устранение вложенности подзапросов, которое приводит к порождению представления, не всегда обеспечивает более эффективный план.
Аналогично методам устранения вложенности SPJ-подзапросов, активно изучались и методы устранения подзапросов с агрегатами ([22], [7], [10] и [14]). В [22] представлена ранняя работа по преобразованиям, в которых агрегаты из вложенных подзапросов вытягиваются в дереве операций в позицию, предшествующую соединению. В ранних версиях нашей системы (версия 8.1) применялсяи аналогичный алгоритм. Преобразование инициировалось эвристическим образом на фазе преобразования запроса.
В [7], [1], [23] и [24] демонстрировались преобразования, в которых агрегаты проталкивались в позицию, предшествующую соединению. В [1] определяется жадная (greedy) и консервативная эвристика, применяемая во время перебора порядка соединений, в которой группировка помещается перед сканированием таблицы, если это приводит к более дешевому сканированию или соединению. В [2] определялось аналогичное преобразование вытягивания и проталкивания агрегатов, но, кроме того, демонстрировалось, как можно выполнять это преобразование на основе оценки стоимости; также обеспечивались две эвристики для контроля расширения пространства поиска. В нашей системе с самого начала использовались другие эвристики.
Методы проталкивания предикатов к одиночным отношениям сквозь представления с агрегатами и оконными функциями известны на протяжении долгого времени. В [9] предлагался метод, обобщающий эти подходы путем вытягивания предикатов вверх по дереву запроса, а затем проталкиванием их вниз, что приводит к тому, что при сканировании базовых таблиц становится возможно применить большее число однотабличных предикатов.
В [12] и [13] описывается преобразование магических множеств (magic set), которое добавляет новые представления к дорогостоящим блокам запроса с целью уменьшения объема обрабатываемых данных. В [19] эта работа расширяется методами выбора способа магической перезаписи на основе оценки стоимости. Предлагались два метода: первый (очень практичный) реализует преобразование в рамках существующего оптимизатора DB2, а второй основывается на алгебраических преобразованиях для оптимизации, основанной на правилах.
Внешние соединения некоммутативны с внутренними соединениями, и это ограничивает оптимизатор при выборе порядка соединений. Эта проблема изучается в [22], [18] и [3], где было показано, что для некоторых запросов внешнее соединение может коммутировать с внутренними соединениями за счет введения понятия обобщенного внешнего соединения. В [17] определяется каноническая абстракция внешнего соединения, которая позволяет оптимизатору использовать различные порядки соединений среди таблиц, соединяемых внешним и внутренним образом.
Слияние представлений c группировкой и устранением дубликатов
Слияние представлений с группировкой (Group-by View Merging, group-by pull-up) позволяет слить представление, содержащее операцию GROUP BY (или DISTINCT), с его внешним блоком запроса. Это позволяет оптимизатору рассматривать дополнительные порядки соединения и пути доступа и откладывать вычисление агрегатов до тех пор, пока не будут выполнены соединения. Отложенное вычисление агрегатов может как повысить, так и понизить производительность в зависимости от характеристик данных, таких как сокращение набора данных, для которого выполнялось агрегирование. Рассмотрим запрос Q11, который получается путем слияния представления с GROUP BY в запросе Q10:
Q11
SELECT e1.employee_name, j.job_title FROM employees e1, job_history j, employees e2 WHERE e1.emp_id = j.emp_id and j.start_date > '19980101' and e2.dept_id = e1.dept_id and e1_dept_id IN (SELECT dept_id FROM departaments d, locations l WHERE d.loc_id = l.loc_id and l.country_id = 'US') GROUP BY e2.dept_id, e1.emp_id, j.rowid, e1.employee_name, j.job_title, e1.salary HAVING e1.salary > AVG (e2.salary);
В непреобразованном запросе Q10 требуется, чтобы агрегация выполнялась на всей таблице employees. В преобразованнм запросе Q11 выполняются соединения двух таблиц employees и таблицы job_history, и применяется фильтрация вторым подзапросом до того, как выполняется агрегация. Если соединения и фильтры существенно уменьшают размер данных, которые агрегируются, то в результате может получиться улучшенный план выполнения. С другой стороны, ранняя агрегация уменьшает размер данных, которые обрабатываются операциями соединения, и агрегация в представлении с GROUP BY, возможно, должна будет выполняться на меньшем наборе данных. Эти соображения являются основанием того, почему решение должно быть основано на оценке стоимости. В запросах, выполняющих агрегацию последней, мы также учитываем возможность преобразования запроса для выполнения ранней агрегации (имеется в виду преобразование "размещение группировки" (group-by placement), которое мы описываем ниже).
Список литературы
[1] Chaudhuri S., Shim K. Including Group-By in Query Optimization. In Proc. of VLDB. Santiago, 1994.
[2] Chaudhuri S., Shim K. Query Optimization with Aggregate Views. In Proc. of EDBT. Avignon, 1996.
[3] Galindo-Legaria C.A., et al. Outerjoin simplification and reordering for query optimization. TODS, 1997.
[4] Ganski R.A., Wong H.K.T. Optimization of Nested SQL Queries Revisited. Proc. of ACM SIGMOD, 1987.
[5] Garcia-Molina H., Ullman J.D., Widom J. Database System Implementation. Precent Hall, 2000.
[6] Graefe G., Mckenna W.J. The Volcano optimizer generator: Extensibility and Efficient Search. Proceedings of the 19 International Conf. on Data Engineering, 1993.
[7] Gupta A., Harinarayan V., Quass D. Aggregate-Query Processing in Data Warehousing Environments, In Proc. of 21 VLDB, 1995.
[8] Hellerstein J.M., Stonebraker M. Predicate migration: Optimizing Queries with Expensive Predicates. Proc. of ACM SIGMOD, Washington DC, 1993.
[9] Levy A.Y., Mumick I.S., Sagiv Y. Query Optimization by Predicate Move-Around. In Proc. of VLDB. Santiago, 1994.
[10] Kim W. On Optimizing an SQL-Like Nested Query. ACM TODS, 1982.
[11] Morzy T., Matysiak M., Salza S. Tabu Search Optimization of Large Join Queries. EDBT, 1994.
[12] Mumick I.S., Finkelstain S., Pirahesh H., Ramakrishnan R. Magic is Relevant. Proc. of ACM SIGMOD, 1990.
[13] Mumick I.S., Pirahesh H., Ramakrishnan R. Implementation of Magic Sets in Relational Database Systems. Proc. of ACM SIGMOD, 1994.
[14] Muralikrishna M. Improved Unnesting Algorithms for Join Aggregate SQL Queries. In Proc. of VLDB. Vancouver, 1992.
[15] Pellenkoft A., Galindo-Legaria C.A., Kersen M. The Complexity of the Transformation-Based Join Enumeration. In Proc. of VLDB. Athens, 1997.
[16] Rao J., Pirahesh J., Zuzarte C. Cannonical Abstractios for Outerjoin Optimization. Proc. of ACM SIGMOD, 2004.
[17] Pirahesh J., Hellerstein J.M., Hasan W. Extensible Rule Based Query Rewrite Optimizations in Starburst. Proc. of ACM SIGMOD, 1992.
[18] Rosenthal A., Cesar A., Galindo-Legaria C.A. Query Graphs, Implementing Trees, and Freely-reorderable Outerjoins. Proc. of ACM SIGMOD, 1990.
[19] Seshadri P., et al. Cost-Based Optimization for Magic Algebra and Implementation. Proc. of ACM SIGMOD, 1996.
[20] Swami A., Gupta A. Optimization of Large Join Queries. Proc. of ACM SIGMOD, 1988.
[21] Swami A. Optimization of Large Join Queries: Combining Heuristics and Combinatorial Techniques. Proc. of ACM SIGMOD, 1989.
[22] Dayal, U. Of Nests and Trees: A Unified Approach to Processing Queries That Contain Nested Subqueries, Aggregates and Quantifiers. In Proc. of VLDB, 1987.
[23] Yan W.P., Larson A.P. Performing Group By Before Join. IEEE ICDE, 1994.
[24] Yan, W.P., Larson A.P. Eager aggregation and lazy aggregation. In Proc. of VLDB Conference, Zurich, 1995.
[25] Witkowski A., et al. Spreadsheets in RDBMS for OLAP. Proc. of ACM SIGMOD, 2003.
[26] Witkowski A., et al. Spreadsheets in RDBMS for OLAP. ACM TODS, 2005.
Стоимостное прекращение
При оценке любого состояния, если стоимость дерева запроса или любой его составной части превосходит стоимость наилучшего состояния, найденного к этому времени, физическая оптимизация этого состояния прекращается, и оптимизатор переходит к анализу следующего состояния.
Управление памятью
В Oracle структуры запроса и структуры оптимизатора, испольуемые для оценки стоимости и принятия решений, обычно не освобождаются до конца оптимизации. Для выполнения преобразований, основанных на оценке стоимости, создается много копий структур запроса, и для оптимизации вариантов преобразования запроса создается много структур оптимизатора. Следовательно, в инфраструктуре преобразований, основанных на стоимости, мы должны управлять памятью более разумно. Структуры запроса и структуры, используемые оптимизатором для принятия решений, освобождаются, когда принимается решение о выполнении каждого преобразования. Отметим, что память, занимаемая аннотациями стоимости оптимизатора, освобождаться не может, поскольку, как описывалось ранее, они использоваться повторно.
Упрощение группировки
Упрощение группировки (Group Pruning) — еще одно императивное преобразование, которое удаляет из представлений группы, не требующиеся во внешних блоках запроса. Например, рассмотрим запрос Q9:
Q9
SELECT sum_sal, country_id, state_id, city_id FROM (SELECT SUM (e.salary) sum_sal, l.country_id, l_state_id, l.city_id FROM employees e, departaments d locations l WHERE e.dept_id = d.dept_id and d.location_id = l.location_id GROUP BY ROLLUP (counrty_id, state_id, city_id)) WHERE city_id = 'San Francisco';
В приведенном выше запросе внешний предикат на city_id фильтрует группы (country_id) и (country_id, state_id). Преобразование может быть выполнено на основе как предикатов на столбцах раздела GROUP BY, так и функций группировки. Это преобразование выполняется после перемещения упрощающих предикатов фильтрации в непосредственную близость к запросу с GROUP BY.
Заметим, что здесь мы используем нестандартную нотацию полусоединения (semijoin) T1.C S= T2.C, где T1 и T2 — левая и правая таблица полусоединения соответственно.
Устранение соединений
Метод устранения соединения (Join Elimination) удаляет таблицу из запроса, если имеются такие ограничения на столбцы соединения этой таблицы, что устранение соединения не влияет на результаты запроса. Рассмотрим следующие два запроса Q4 и Q5, которые выбирают некоторую информацию о сотрудниках (employees):
Q4
SELECT e.name, e.salary FROM employees e, departaments d WHERE e.dept_id = d.dept_id;
Так как dept_id в таблице employees является внешним ключом, ссылающимся на первичный ключ таблицы departaments, соединение с departaments из Q4 можно устранить.
В запросе Q5 столбец соединения в правой таблице внешнего соединений уникален. Так как внешнее соединение содержит все кортежи левой таблицы, а эквисоединение (equi-join) с уникальными столбцами не порождает дубликаты, таблицу departaments можно исключить.
Q5
SELECT e.name, e.salary FROM employees e left outer join departaments d on e.dept_id = d.dept_id;
Применение преобразования устранения соединений к Q4 и Q5 приводит к порождению запроса Q6. Если в Q4 e.dept_id может содержать неопределенные значения, в раздел WHERE Q6 должен быть добавлен предикат e.dept_id is not null.
Q6
SELECT e.name, e.salary FROM employees e;
Очевидно, что устранение избыточного соединения улучшит производительность запроса, и поэтому устранение соединений всегда выполняется Oracle, если это допустимо.
Устранение вложенности и проталкивание предикатов соединения
Мы хотели оценить влияние двух преобразований запросов: устранение вложенности подзапросов (поскольку это преобразование активно исследовалось в литературе и применимо для запросов нашей рабочей нагрузки) и проталкивание предикатов соединения (так как это относительно новая техника, которая вносит корреляцию, и, следовательно, оказывает действие, противоположное действию первого преобразования).
Рис. 3. Относительное повышение производительности за счет устранения вложенности подзапросов как функция первых N% наиболее дорогостоящих запросов
Мы провели эксперименты, в которых сравнили время выполнения запросов с полным отсутствием устранения вложенности со временем выполнения запросов, подвергнутых преобразованию устранения вложенности на основе оценки стоимости. Этот эксперимент затронул 12 279 запросов, то есть 5% всей рабочей нагрузки. В среднем использование преобразования устранение вложенности привело к повышению производительности примерно на 387%. Производительность небольшой части затронутых запросов (15%) ухудшилась на 50%. На рис. 3 представлены данные о повышении производительности после выполнения преобразования как функция от первых N наиболее долго выполняющихся запросов. Первые N определяются по-прежнему. Например, для первых 5% наиболее долго выполняющихся запросов было получено заметное повышение производительности на 460%. Для первых 25% повышение производительности составило 350%.
Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 31%. Отметим, что от данного преобразования в большей степени выигрывают дорогостоящие запросы.
Мы провели третий набор экспериментов, в котором сравнили производительность запросов с полным отсутствием проталкивания предикатов соединения (Join Predicate Pushdown, JPPD) с производительностью запросов, для которых выполнялось это преобразование на основе оценок стоимости. Преобразование JPPD затронуло 1797 запросов, то есть 0,75% всей рабочей нагрузки.
В среднем использование преобразования JPPD повысило производительность примерно на 387%. Производительность небольшой части затронутых запросов (11%) снизилась на 15%. На рис. 4 представлены данные о повышении производительности после выполнения преобразования как функция от первых N наиболее долго выполняющихся запросов, где первые N определяются так же, как и ранее. Например, для первых 5% наиболее долго выполняющихся запросов было получено повышение производительности на 15%. Для первых 25% повышение производительности составило 23%. В этих экспериментах ухудшение производительности, наблюдавшееся у некоторых запросов, как правило, было связано с неправильной оценкой стоимости.

Рис. 4. Относительное повышение производительности за счет применения JPPD как функция первых N% наиболее дорогостоящих запросов
Заметим, что в отличие от преобразования устранения вложенности, от JPPD в большей степени выигрывают менее дорогостоящие запросы. Например, первые 80% наиболее дорогостоящих запросов выигрывают больше, чем первые 5%. Платой за сокращение времени выполнения запросов явилось время оптимизации, которое увеличилось на 7%.
Устранение вложенности подзапросов
Устранение вложенности подзапросов (Subquery Unnesting) — важное преобразование, которое обычно реализовывается коммерческими СУБД. Подзапрос с неустраненной вложенностью вычисляется несколько раз с использованием семантики кортежной итерации (tuple iteration semantics, TIS), что подобно выполнению соединения методом вложенных циклов, и, следовательно, при этом не может быть учтено множество эффективных путей доступа и последовательностей соединения.
Оптимизатор Oracle может устранить вложенность почти всех типов подзапросов за исключением подзапросов, в которых имеется корреляция не с предком, в которых корреляция проявляется в дизъюнкции, а также некоторых подзапросов с квантором ALL и составным условием с корреляцией, включающим имена столбцов, в которых допускаются неопределенные значения. Существует две основных категории методов устранения вложенности: первая категория включает методы, основанные на порождении встраиваемых представлений (inline view), вторая — методы, основанные на слиянии подзапроса с его внешним запросом. В Oracle методы первой категории применяются на основе оценки стоимости, тогда как методы второй категории используются императивным образом.
Рассмотрим следующий запрос, возвращающий информацию об отделах для отделов (departments), сотрудники (employees) которых получают высокую зарплату:
Q2
SELECT d.dept_name, d.budget FROM departaments d WHERE EXISTS (SELECT 1 FROM employees e WHERE d.dept_id = e.dept_id AND e.salary > 200000);
Этот запрос преобразуется в следующий эквивалентный запрос:
Q3
SELECT d.dept_name, d.budget FROM departaments d, employees e WHERE d.dept_id S= e.dept_id AND e.salary > 200000;
Преобразование, сливающее подзапрос с внешним запросом, в общем случае позволяет использовать дополнительные способы и последовательности выполнения операций соединения. В рассматриваемом примере Oracle может использовать для полусоединения (semijoin) методы вложенных циклов, хеширования или сортировки со слиянием. Реализация в Oracle антисоединения (antijoin) и полусоединения обладает свойством "остановись-на-первом-совпадении" (stop-at-the-first-match). Механизм выполнения Oracle кэширует результаты анти- и полусоединения для кортежей левой таблицы; это кэширование может быть весьма полезно, если в соединяемых столбцах левой таблицы имеется большое число дубликатов.
Полусоединение, как и антисоединение, и левое внешнее соединение ( left outerjoin) является некоммутативным соединением и навязывает частичный порядок соединения таблиц, то есть в рассматриваемом примере в последовательности соединения таблица departaments должна предшествовать таблице employees. Но мы можем преобразовать это полусоединение во внутреннее (inner) соединение, применяя к выбранным строкам employees операцию сортировки с удалением дубликатов и смягчая ограничение частичного порядка соединений [22]. Это позволяет оптимизатору допускать возможность обоих порядков соединения — (d semijoin e) и (distinct(e) join d).
Вложенность подзапросов с ALL, в столбцах условий которых не допускаются неопределенные значения, и подзапросов с NOT EXISTS, как правило, может устраняться с использованием антисоединения. В следующей версии Oracle будет иметься еще один вариант антисоединения — антисоединение с учетом возможности появления неопределенных значений (null-aware antijoin), для которого будут допустимы столбцы с неопределенными значениями в связывающих условиях подзапросов с ALL.
Влияние на пространство состояний
Чередование и противопоставление преобразований вызывают увеличение числа анализируемых состояний. В принципе, мы могли бы принимать во внимание дополнительное состояние для каждого подзапроса, который мы рассматриваем на предмет устранения вложенности. В некоторых случаях состояния, которые мы могли бы учесть, являются состояниями, которые мы могли бы обследовать позже даже без чередования или противопоставления. Если мы выбираем устранение вложенности подзапроса, поскольку оно приводит к более дешевому плану запроса, то нет необходимости чередовать его со слиянием представлений; мы проанализируем слияние представлений обычным последовательным способом. Подобным же образом, если мы выбираем не применять слияние представлений, поскольку оно приводит к более дорогому плану запроса, то нет необходимости противопоставлять его проталкиванию предикатов соединения; мы проанализируем проталкивание предикатов соединения позже обычным последовательным способом. Это частично смягчает последствия расширения пространства поиска по причине чередования и противопоставления.
Внесение дизъюнкции в объединение
Если предикаты фильтрации или соединения появляются в дизъюнкции, запрос может быть развернут в запрос с UNION ALL, в котором каждая ветвь содержит один из предикатов дизъюнкции. В отсутствие такого преобразования дизъюнктивный предикат применяется в качестве заключительного фильтра (post-filter) результата, который может быть декартовым произведением.
Заметим, что SELECT DISTINCT — это частный случай операции группировки.
В некоторых случаях anti-/semi-/outer-соединяемые представления могут, на самом деле, сливаться, особенно, если они содержат единственную таблицу.
Rownum — это конструкция Oracle, позволяющая пользователям указать максимальное количество кортежей, которые должны выдаваться запросом.
Время оптимизации
Одной из основных проблем преобразований, основанных на оценке стоимости, является увеличение времени оптимизации. Мы отмечали, что в экспериментах, описанных в предыдущих разделах, время оптимизации увеличивалось. В табл. 2 мы представили время оптимизации и число состояний для различных стратегий поиска в пространстве состояний (подраздел 3.2) для одного запроса, подвергавшегося преобразованию устранения вложенности. В этом запросе имелось 3 основных таблицы и 4 подзапроса, каждый из которых содержал 3 базовых таблицы и являлся подзапросом с NOT IN, EXISTS или NOT EXISTS. Для всех подзапросов допускалось преобразование устранения вложенности.
Увеличение времени оптимизации для различных стратегий поиска по сравнению с эвристическим режимом (то есть без преобразований, основанных на оценке стоимости) не является значительным из-за повторного использования аннотаций стоимости поддеревьев запроса.
Таблица 2. Увеличение времени оптимизации для различных методов поиска в пространстве состояний
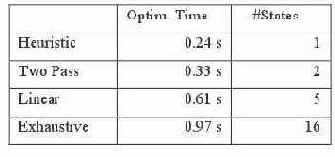
Такие запросы становятся все более
Современные СУБД выполняют сложные SQL-запросы, включающие вложенные подзапросы с функциями агрегации, UNION/UNION ALL, DISTINCT, представления с группировкой и т.д. Такие запросы становятся все более значимыми в системах поддержки принятия решений (DSS) и интерактивной аналитической обработки (OLAP). Для оптимизации таких запросов была предложена перезапись запроса в виде эвристического преобразования. Однако существует много возможных вариантов преобразования даже для простых SQL-выражений в зависимости от того, как и какие преобразования применяются. Дополнительные сложности создает взаимодействие двух или более преобразований друг с другом.
В традиционных СУБД оптимизация запросов, как правило, состоит из двух этапов обработки: этапов логической и физической оптимизации. На этапе логической оптимизации заданный запрос переписывается (обычно на основе эвристик или правил) в эквивалентную, но потенциально более декларативную или оптимальную форму. Традиционный физический оптимизатор работает в рамках одного блока запроса, который оперирует множеством базовых таблиц с применением ограничения, проекции и соединения. На этапе физической оптимизации выбираются методы доступа, последовательность соединений и методы соединений для генерации эффективного плана выполнения запроса.
Преобразования запроса реализуются либо как система перезаписи [16], управляемая эвристическими правилами, либо как расширения генератора планов внутри физического оптимизатора [2, 6, 19]. Первый подход универсален, но не масштабируется на сложные коммерческие системы, а второй легко применим только для нескольких избранных преобразований. В этой работе аргументированно обсуждается новый подход с методическим обеспечением расчета стоимости преобразований без необходимости модификации физического оптимизатора.
Некоторые эвристические правила являются неотъемлемой частью преобразований, которые применяются на этапе логической оптимизации. В разд. 2 мы перечисляем несколько преобразований, которые применяются в Oracle на основе эвристических правил. Однако остается большой класс преобразований, которые не подчиняются полностью эвристическим правилам и могут приводить к неоптимальным планам выполнения, если решение по использованию таких преобразований не основывалось на оценке затрат.
Мы обосновываем эти проблемы несколькими примерами разд. 2. Рассмотрим здесь только один простой запрос, который получает информацию о сотрудниках (employees) и должностях (job), занимаемых ими позднее 1998, для сотрудников, имеющих зарплату выше средней в своих департаментах (departments), которые расположены (locations) в США.
Q1
SELECT e1.employee_name, j.job_title FROM employees e1, job_history j WHERE e1.emp_id = j.emp_id and j.start_date > '19980101' and e1.salary > (SELECT AVG (e2.salary) FROM employees e2 WHERE e2.dept_id = e1.dept_id) and e1_dept_id IN (SELECT dept_id FROM departments d, locations l WHERE d.loc_id = l.loc_id and l.country_id = 'US');
В этом запросе можно устранить вложенность обоих подзапросов за счет введения встраиваемых (inline) представлений (производных таблиц), и впоследствии оба представления могут быть слиты. Это дает нам многочисленные альтернативы преобразования этого запроса — устранение вложенности (нуля или более) подзапросов и последующее слияние (нуля или более) представлений. Интересно, что, как мы увидим в разд. 2, могут иметься и другие преобразования, которые могли бы стать применимыми к этому запросу. Нет ясного эвристического правила для определения того, какое из преобразований ведет к лучшему плану выполнения, т.к. здесь играет роль множество факторов (например, соотношение размеров участвующих таблиц, селективность предикатов, существование индексов на локальных столбцах предикатов корреляции и т.д.).
Вытягивание предиката
Преобразование "вытягивание предиката" (Predicate Pullup) фильтрации вытягивает дорогостоящие предикаты фильтрации из представления в запрос, содержащий это представление. В настоящее время предикат считается дорогостоящим, если он содержит процедурные функции SQL, определяемые пользователем операции или подзапросы. Преобразование "вытягивание предиката" в настоящее время принимается во внимание, только если в запросе, содержащем представление, указан предикат rownum, и в представлении имеется блокирующая операция.
Рассмотрим следующий запрос, содержащий представление с двумя дорогостоящими предикатами:
Q16
SELECT * FROM (SELECT document_id FROM product_docs WHERE containts(summary,'optimizer',1) > 0 AND containts(full_text,'execution',2) > 0 ORDER BY create_date) V WHERE rownum <= 20;
Поскольку в представлении имеются два дорогостоящих предиката, существуют три способа, которыми может быть выполнено преобразование вытягивания предиката, один из которых приведен ниже:
Q17
SELECT * FROM (SELECT document_id, value(r) as vr FROM product_docs WHERE containts(full_text,'execution',2) > 0 ORDER BY create_date) V WHERE containts(summary,'optimizer',1) > 0 AND rownum <= 20;
Выполнение поздней проверки дорогостоящих предикатов на значительно сокращенном наборе данных может, в некоторых случаях, улучшить производительность запроса. Если предикаты отфильтровывают очень мало строк, то мы можем избежать выполнения дорогостоящего предиката на полном наборе данных. Сокращение объема данных происходит из-за наличия предиката rownum в запросе, содержащем представление. Это преобразование действует противоположным образом по отношению к распространенному методу оптимизации проталкивания в представление предиката фильтрации. Поэтому в Oracle решение о вытягивании предикатов принимается на основе оценки стоимости.
В этой статье описаны два
В этой статье описаны два основных результата.[5] Во-первых, предлагается применимое на практике решение для интеграции различных преобразований внутри инфраструктуры, основанной на оценке стоимости. У этой схемы имеется возможность моделировать большинство преобразований и их возможных взаимодействий, позволяя, тем самым, оптимизатору выбирать наиболее оптимальный вариант запроса. Второй результат состоит в том, что мы предлагаем алгоритмы поиска в пространстве состояний контролирования возможного комбинаторного взрыва преобразований, основанных на оценке стоимости. Мы также обсуждаем некоторые преобразования (например, проталкивание предикатов соединения и факторизация соединений), которые в литературе ранее не обсуждались.
Мы обнаружили, что для значительного числа разновидностей OLTP-запросов критичным является хорошо изученное преобразование устранения вложенности подзапросов. Общее время исполнения запросов, к которым применимо это преобразование, сокращается на 387%. Преобразование проталкивания предикатов соединения сокращает время исполнения на 23%. Для преобразования "расположение группировки" мы обнаружили сокращение времени исполнения на 21%. Что касается преобразований устранения вложенности подзапросов, слияния представлений с группировкой и проталкивания предикатов соединения, наши эксперименты показали, что преобразования, основанные на оценке стоимости, обеспечивают производительность, на 20% более высокую, чем преобразования, основанные на эвристиках.
Введение
Современные промышленные СУБД позволяют хранить в своих базах данные одновременно многих пользователей, и поэтому желание защитить собственные данные от постороннего глаза вполне понятно. Некоторым решениям этого вопроса в Oracle были посвящены ранее публиковавшиеся статьи , , и . Однако эти решения Oracle не позволяют закрыть проблему конфиденциальности полностью.
Дело в том, что СУБД Oracle, так же как и другие промышленные системы, построена по принципу суперпользователя, который всегда способен прочитать все данные любого пользователя. Суперпользователем в Oracle является SYS. У него есть полномочие («привилегия») SELECT ANY TABLE, а значит он может прочитать данные всех таблиц в БД. У него есть привилегия ALTER USER, а значит он может временно подменить любому пользователю пароль, войти в систему под чужим именем и работать неотличимо от оригинала, так что никакой аудит не обнаружит несанкционированный доступ. Тем самым сотрудник, которыму предоставлено право работать под именем SYS, должен быть крайне доверенным лицом в организации, где используется БД под Oracle. Но можно ли снизить риск утечки собственных данных через суперпользователя?
Ответ лежит вовне Oracle. Если перед помещением данных в БД их зашифровать, суперпользователь, хотя и прочтет, что хранится в БД, но ничего не поймет. Сделать это можно в клиентской программе, однако для сложного приложения организационно удобнее шифровать централизованнно, на сервере. Для этой цели можно воспользоваться двумя пакетами, специально предназначенных в Oracle для работы с шифрованными данными. Примеры такой работы приводятся далее.
Oracle10: шифруем данные
Владимир Пржиялковский
Преподаватель технологий Oracle
| Уж давно я тайну эту Хороню в груди своей И бесчувственному свету Не открою тайны сей ... |
К. Прутков, «Путник»
Пакет DBMS_CRYPTO
В версии 10 в состав системных пакетов включен (в перспективе – на замену DBMS_OBFUSCATION_TOOLKIT) более функциональный пакет DBMS_CRYPTO, позволяющий шифровать данные других типов (не RAW и VARCHAR2, а RAW, CLOB и BLOB) и другими алгоритмами (не только DES, 3DES, но еще и AES, и RC4, и 3DES_2KEY плюс алгоритмы хеширования плюс параметризация этих алгоритмов). Он построен по иной технике, когда для шифрования используются всего две общие функции ENCRYPT и DECRYPT, а ссылка на конкретный алгоритм передается параметром. Вот как с помощью DBMS_CRYPTO может выглядеть DES-шифрование той же строки тем же ключом, что и выше:
DECLARE input_string VARCHAR2(255) := 'Morgen, morgen, nur nicht heute'; raw_input RAW(4000);
key_string VARCHAR2(8) := 'MagicKey'; raw_key RAW(16);
encrypted_raw RAW(4000); encrypted_string VARCHAR2(4000);
decrypted_raw RAW(4000); decrypted_string VARCHAR2(4000);
BEGIN DBMS_OUTPUT.PUT_LINE(input_string);
raw_input := UTL_I18N.STRING_TO_RAW (input_string, 'AL32UTF8');
raw_key := UTL_RAW.CAST_TO_RAW(CONVERT(key_string, 'AL32UTF8'));
encrypted_raw := DBMS_CRYPTO.ENCRYPT ( TYP => DBMS_CRYPTO.DES_CBC_PKCS5 ,SRC => raw_input ,KEY => raw_key );
decrypted_raw := DBMS_CRYPTO.DECRYPT ( TYP => DBMS_CRYPTO.DES_CBC_PKCS5 ,SRC => encrypted_raw ,KEY => raw_key );
decrypted_string := UTL_I18N.RAW_TO_CHAR (decrypted_raw, 'AL32UTF8');
DBMS_OUTPUT.PUT_LINE(decrypted_string); END; /
(Чтобы пример проработал, нужно будет выполнить от имени SYS:
GRANT EXECUTE ON DBMS_CRYPTO TO PUBLIC;
Скорее всего разработчики забыли вставить это предложение в сценарий заведения пакета и в будущих выпусках СУБД этого нам делать не придется).
Здесь технология не требует искусственного удлиннения строки до нужной кратности, но зато необходимо предъявлять параметры в формате RAW и в кодировке AL32UTF8, что тоже приводит к усложнению текста.
Константа DBMS_CRYPTO.DES_CBC_PKCS5 выше есть сумма трех констант ENCRYPT_DES (алгоритм шифрования, размер ключа), CHAIN_CBC (размер блоков, на которые в процессе шифрования будет разбиваться исходная строка) и PAD_PKCS5 (схема дополнения строки до требуемой кратности). В этом легко удостовериться:
SQL> EXEC DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.ENCRYPT_DES) 1
PL/SQL procedure successfully completed.
SQL> EXEC DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.CHAIN_CBC) 256
PL/SQL procedure successfully completed.
SQL> EXEC DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.PAD_PKCS5) 4096
PL/SQL procedure successfully completed.
SQL> SELECT 1 + 256 + 4096 FROM DUAL;
1+256+4096 ---------- 4353
SQL> EXEC DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.DES_CBC_PKCS5) 4353
PL/SQL procedure successfully completed.
Чтобы в точности воспроизвести пример с DBMS_OBFUSCATION_TOOLKIT выше, нужно будет дополнять шифруемую строку нулями, и тогда вместо
TYP => DBMS_CRYPTO.DES_CBC_PKCS5
указать
TYP => DBMS_CRYPTO.ENCRYPT_DES + DBMS_CRYPTO.CHAIN_CBC + DBMS_CRYPTO.PAD_ZERO
Упражнение Проверить, что алгоритм DES реализован в обоих пакетах идентично, зашифровав строку процедурой DESENCRYPT пакета DBMS_OBFUSCATION_TOOLKIT, а расшифровав функцией DECRYPT пакета DBMS_CRYPTO.
Тем не менее, современная технология не рекомендует на практике дополнять строку нулями, а советует пользоваться схемой дополнения PKCS5.
Пример указания алгоритма шифрования AES ключом в 128 разрядов:
TYP => DBMS_CRYPTO.ENCRYPT_AES128 + DBMS_CRYPTO.CHAIN_CBC + DBMS_CRYPTO.PAD_PKCS5
Прочие возможности пакета DBMS_CRYPTO приведены в документации.
Пакет DBMS_OBFUSCATION_TOOLKIT
Начиная с версии 8.1.6 с Oracle поставляется пакет для шифрования и расшифровки методом DES под названием DBMS_OBFUSCATION_TOOLKIT. Процедурой DESENCRYPT этого пакета можно с помощью ключа зашифровать текстовую строку, а процедурой DESDECRYPT расшифровать.
Пример в SQL*Plus:
SET SERVEROUTPUT ON
DECLARE input_string VARCHAR2(4000) := 'Morgen, morgen, nur nicht heute';
work_string VARCHAR2(4000);
encrypted_string VARCHAR2(4000);
decrypted_string VARCHAR2(4000);
BEGIN DBMS_OUTPUT.PUT_LINE(input_string);
work_string := RPAD ( input_string , (TRUNC(LENGTH(input_string) / 8) + 1 ) * 8 , CHR(0) );
DBMS_OBFUSCATION_TOOLKIT.DESENCRYPT ( input_string => work_string , key_string => 'MagicKey' , encrypted_string => encrypted_string );
DBMS_OBFUSCATION_TOOLKIT.DESDECRYPT ( input_string => encrypted_string ,key_string => 'MagicKey' ,decrypted_string => work_string );
decrypted_string := RTRIM(work_string, CHR(0));
DBMS_OUTPUT.PUT_LINE(decrypted_string); END; /
Для шифрования использован восьмибайтовый ключ MagicKey. Так как алгоритм DES работает только со строками, кратными 8 байтам, мы вынуждены искусственно удлиннять входную строку. Для общего случая в качестве дополняющего символа наиболее естественным выглядит CHR(0), хотя в конкретных ситуациях он может и оказаться неприемлемым. В следующем разделе предложено более современное решение проблемы дополняющего символа.
В этом же пакете имеются аналогичные процедуры для более стойкого алгоритма 3DES, а также для получения свертки текста по алгоритму MD5, что можно использовать для гарантии целостности данных (защита от несанкционированной подмены).
Сценарий заведения пакета в БД находится в rdbms\admin\catobtk.sql.