Анализ трассировочных файлов
Полученные трассировочные файлы можно анализировать непосредственно. Форматы всех записей описаны в документации [], а сам процесс анализа неоднократно описывал, например, Том Кайт []. Тем не менее, обычно достаточно проанализировать намного меньший объем более удобно структурированной информации, которую можно получить по трассировочному файлу с помощью утилиты tkprof:
C:\oracle\admin\openxs\udump>tkprof openxs_ora_3532.trc 3532.tkp
Формат результатов и опции утилиты tkprof также подробно описаны в документации (см. []), но обычно полученный файл во многом понятен и без чтения документации. (В я перевел начальные комментарии на русский, чтобы представленные основные показатели были понятнее широкой аудитории.)
Листинг 2. Результат обработки трассировочного файла утилитой tkprof
TKPROF: Release 9.2.0.1.0 - Production on Нд. Квт 17 20:02:56 2005
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Trace file: openxs_ora_3532.trc Sort options: default
******************************************************************************** count = сколько раз была выполнена соотвествующая функция OCI cpu = процессорное время выполнения elapsed = реальное время выполнения disk = количество физических чтений блоков с диска query = количество блоков, полученных согласованным чтением current = количество блоков, полученных в текущем режиме (обычно - для измнения) rows = количество строк, обработанных вызовом fetch или execute ********************************************************************************
alter session set sql_trace = true
call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 0 0.00 0.00 0 0 0 0 Execute 1 0.00 0.03 0 0 0 0 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 1 0.00 0.03 0 0 0 0
Misses in library cache during parse: 0 Misses in library cache during execute: 1 Optimizer goal: CHOOSE Parsing user id: 59 ******************************************************************************** ... ********************************************************************************
select * from emp
call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.03 0.13 1 1 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 2 0.00 0.00 1 4 0 14 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 0.03 0.13 2 5 0 14
Misses in library cache during parse: 1 Optimizer goal: CHOOSE Parsing user id: 59
Rows Row Source Operation ------- --------------------------------------------------- 14 TABLE ACCESS FULL EMP
******************************************************************************** ...
Trace file: openxs_ora_3532.trc Trace file compatibility: 9.00.01 Sort options: default
1 session in tracefile. 3 user SQL statements in trace file. 12 internal SQL statements in trace file. 15 SQL statements in trace file. 13 unique SQL statements in trace file. 149 lines in trace file.
Для каждого выполненного SQL-оператора, выполненного пользователем или приложением (и рекурсивных SQL-операторов, выполненных при этом сервером) выдается его текст, статистическая информация о количестве анализов, выполнений, выборок результатов и т.п., реальный план выполнения, с количеством строк на выходе каждого шага выполнения и другая информация, в зависимости от уровня трассировки, версии Oracle и версии утилиты tkprof. В конце представлена итоговая информация - по какому трассировочному файлу построены результаты, сколько и каких операторов было выполнено, и т.п.
Важность полученной информации очевидна любому разработчику и администратору. Мы еще не раз подчекнем это далее, описывая историю развития средств трассировки SQL-операторов в Oracle.
Что еще можно включить в трассировочные файлы?
Поскольку средства трассировки корпорация Oracle создавала, прежде всего, для своих собственных целей - в качестве стредства отладки различных компонентов и средств сервера, содержимое трассировочных файлов не ограничивается информацией о ходе выполнения SQL-операторов. На самом деле, с помощью механизма событий, одним из которых является уже упоминавшееся событие 10046, можно включить выдачу в трассировочные файлы и другой важной информации.
Всего событий для трассировки и управления работой отдельных компонентов зарезервировано 1000. Краткую информацию о назначении каждого события можно получить, например, выполнив следующий PL/SQL-блок:
DECLARE err_msg VARCHAR2(120); BEGIN dbms_output.enable (1000000); FOR err_num IN 10000..10999 LOOP err_msg := SQLERRM (-err_num); IF err_msg NOT LIKE '%Message 'err_num' not found%' THEN dbms_output.put_line (err_msg); END IF; END LOOP; END; /
В серии статей о средствах трассировки я собираюсь рассмотреть еще результаты трассировки события 10053, позволяющие понять, почему стоимостной оптимизатор (CBO) выбрал тот или иной план.
Как найти нужный трассировочный файл
Как уже упоминалось, все трассировочные файлы пользовательских сеансов находятся в файловой системе компьютера, на котором работает сервер Oracle, в каталоге, заданном параметром инициализации
user_dump_dest. Если трассируется только один сеанс, обычно ему соответствует последний по времени создания трассировочный файл. При интенсивном использовании трассировки, однако, файлов в каталоге user_dump_dest может быть очень много, и найти файл, соответствующий исследуемому сеансу, может оказаться непросто.
Имя файла содержит идентификатор процесса Oracle, который его создал. Определить идентификатор этого процесса можно разными способами. В сеансе или приложении, в котором включалась трассировка, достаточно выполнить запрос:
select p.spid from v$process p, v$session s where p.addr = s.paddr and s.audsid = userenv('SESSIONID');
Для успешного выполнения этого запроса необходима привилегия SELECT на представления словаря данных v_$process и v_$session (v$process и v$session - это их общедоступные синонимы). Эту привилегию должен предоставить владелец словаря данных (пользователь sys):
SQL> connect sys/change_on_install as sysdba Connected. SQL> grant select on v_$process to scott;
Grant succeeded.
SQL> grant select on v_$session to scott;
Grant succeeded.
Можно включить в имя трассировочного файла любую строку для облегчения поиска (она будет добавлена перед расширением, .trc). Для этого перед включением трассировки надо выполнить:
alter session set tracefile_identifier='УникальнаяСтрока';
Для произвольного сеанса с идентификатором some_sid (который вы можете определять по различным критериям - по имени пользователя, имени компьютера, с которого подключилось приложение и т.д.) идентификатор серверного процесса получается похожим запросом:
select p.spid from v$process p, v$session s where p.addr = s.paddr and s.sid = some_sid;
Эти способы позволят определить единственный нужный трассировочный файл, если приложение подключено к выделенному серверу. Проблемы трассировки при работе с разделяемым сервером (в режиме MTS) рассматриваются далее.
Литература и другие источники информации
Oracle Insights: Tales of the Oak Table, Mogens N?rgaard, James Morle, Dave Ensor и др., Apress, 2004, ISBN 1-59059-387-1
Oracle9i Database Performance Tuning Guide and Reference
Статистическая информация уровня сегмента в событии 10046 Oracle 9.2
Том Кайт, "Oracle для професионалов", Книга 1, "Ахитектура и основные особенности", ООО "Диасофт ЮП", 2002, ISBN 5-93772-072-5.
Сайт технической поддержки пользователей Oracle .
Появление и развитие средств трассировки SQL-операторов в Oracle
Теперь позвольте отвлечься от практики и кратко пересказать историю создания и развития средств трассировки SQL-операторов. По ходу будут также рассмотрены основные воможности и особенности трассировки SQL-операторов в различных версиях СУБД Oracle. Мы также представим основные подходы к анализу полученной информации и проблемы, которые возникают при их интерпретации в различных версиях Oracle.
Расширенные средства трассировки SQL-операторов Oracle существуют сегодня потому, что, к счастью, проблемами производительности приложений Oracle занимались не только их конечные пользователи. Создатели ядра Oracle тоже вынуждены были решать эти проблемы, как в процессе поддержки пользователей, так и в ходе борьбы за первеноство в сравнительных тестах производительности различных СУБД, когда ими еще занимались. Процитирую Хуана Лоайзу (Juan Loaiza), разработчика архитектуры ядра Oracle в прошлом и вице-президента корпорации Oracle в настоящее время:
"Я всегда думал, что решение проблем производительности сводится к выяснению, на что уходит время в системе. Если можно точно понять, на что тратится время, то причина проблемы становится очевидной."
Все АБД и разработчики должны быть признательны Хуану и его команде - с помощью разработанных ими средств мы все может узнать, как ядро СУБД Oracle тратит время при выполнении запросов пользователей.
Большинство этих событий не описаны
Большинство этих событий не описаны в документации и должны использоваться только по рекомендации службы поддержки Oracle. Используйте их осторожно (как минимум, проверьте, что номер события указан правильно), только в тестовой среде и только если точно знаете, что делаете.
Также в трассировочные файлы можно сбросить текстовое представление (дамп) содержимого управляющего файла, любого блока и другую ценную информацию. Об этих возможностях я планирую рассказать в следующих статьях данной серии.
Различные способы включить трассировку
Параметр sql_trace можно установить в файле параметров инициализации для всех сеансов. На практике так делают редко, поскольку трассировка всех сеансов может заметно замедлить работу, да и общих объем созданных файлов может оказаться очень большим.
В современных версиях Oracle (например, 9.2) избирательно включить трассировку для сеанса можно несколькими способами.
Сеанс или приложение, которое необходимо трассировать, выполняет один из следующих операторов.
alter session set sql_trace=true;
Этот способ мы уже рассматривали. В трассировочный файл записывается базовая информация - какие операторы выполнялись и сколько времени потребовалось серверу на выполнение основных стадий обработки.
Сеанс или приложение, которое необходимо трассировать, выполняет оператор:
alter session set events '10046 trace name context forever, level уровень';
Так, с помощью установки события 10046, можно включить расширенную трассировку. В зависимости от указанного уровня, в трассировочный файл будет включаться дополнительная информация (см. далее). Чтобы завершить трассировку в этом случае надо выполнить:
alter session set events '10046 trace name context off';
АБД может включить и отключить трассировку любого сеанса с помощью процедур пакета dbms_system:
sys.dbms_system.set_sql_trace_in_session(SID, serial#, true); sys.dbms_system.set_ev(SID, serial#, 10046, уровень, '');
Значения SID и serial# можно получить из представления v$session, например:
select sid, serial# from v$session where username = 'SCOTT';
Допустимые уровни трассировки представлены ниже в .
Начиная с версии 8, можно включить и отключить трассировку любого сеанса с помощью процедур пакета dbms_support:
dbms_support.start_trace_in_session(SID, serial#, true, true) dbms_support.stop_trace_in_session(SID, serial#)
Наконец, можно автоматически включать трассировку для сеансов определенных пользователей, создав триггер на событие регистрации, например, следующего вида:
create or replace trigger logon_trigger after logon on database begin if ( user = '&1' ) then execute immediate 'ALTER SESSION SET EVENTS ''10046 TRACE NAME CONTEXT FOREVER, LEVEL &2'''; end if; end; /
При выполнении этого кода в SQL* Plus надо будет указать имя пользователя и требуемый уровень трассировки. Триггер можно отключить (alter trigger ... disable) сразу после успешного создания и включать (alter trigger ... enable), только когда нужна трассировка. В результате, без изменения кода приложения, можно обеспечить автоматическое включение трассировки для всех сеансов, подключающихся после включения триггера от имени указанного пользователя.
Таблица 1. Уровни трассировки SQL.
| 0 | Отключить трассировку |
| 1 | Базовая информация, как при установке sql_trace=true |
| 4 | Добавляется также информация о значениях связываемых переменных (bind variables) в SQL-операторах |
| 8 | Добавляется также информация о событиях ожидания (wait events) |
| 12 | Комбинация уровней 4 и 8 |
в СУБД Oracle средств трассировки
Использование заложенных в СУБД Oracle средств трассировки SQL-операторов позволяет избавиться от синдрома "черного ящика" при разработке и эксплуатации приложений. АБД и разработчики в любой момент могут получить исчерпывающую информацию о том, какие SQL-операторы выполнялись, сколько раз, с какими параметрами, и сколько времени потребовалось серверу на выполнение каждого из них. В данной статье мы рассмотрели, как практически использовать трассировку SQL, а также описали историю развития и возможности средств трассировки СУБД Oracle вплоть до версии 10g.
Надеюсь, эта статья подтолкнет многих разработчиков приложений Oracle к тому, чтобы задуматься над производительностью создаваемого кода и использовать в повседневной практике не только установки set timing on и set autotrace on в утилите SQL*Plus... (Надеюсь, вы иногда занимаетесь тестированием производительности приложений в условиях, близких к производственным?) Ваши пользователи достойны того, чтобы работать с эффективными приложениями, а СУБД Oracle уже давно дает вам достаточно средств, чтобы эту эффективность обеспечить. Причем, без всяких шаманских танцев с бубном.
Трассировка - практические аспекты
Начиная с версии 6, СУБД Oracle официально предоставляет воможность создавать на сервере трассировочные файлы, содержащие детальную информацию о ходе выполнения SQL-операторов тем или иным серверным процессом. Самым простым способом начать трассировку является выполнение в сеансе SQL*Plus или в приложении следующего SQL-оператора:
alter session set sql_trace=true;
С этого момента информация о выполнении этого и всех последующих SQL-операторов записывается в так называемый трассировочный файл (trace file). Это текстовый файл определенного формата, создаваемый в каталоге, который задается параметром инициализации user_dump_dest. Формат имен трассировочных файлов зависит от версии сервера (например, в версии 9.2.0.1 для Windows он по умолчанию имеет вид SID_ora_PID.trc, где SID - идентификатор экземпляра, а PID - идентификатор серверного процесса Oracle, который создал этот трассировочный файл). Ниже представлено типичное начало трассировочного файла.
Листинг 1. Начало типичного трассировочного файла.
Dump file c:\oracle\admin\openxs\udump\openxs_ora_3532.trc Sun Apr 17 17:26:14 2005 ORACLE V9.2.0.1.0 - Production vsnsta=0 vsnsql=12 vsnxtr=3 Windows 2000 Version 5.1 Service Pack 2, CPU type 586 Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production With the Partitioning, OLAP and Oracle Data Mining options JServer Release 9.2.0.1.0 - Production Windows 2000 Version 5.1 Service Pack 2, CPU type 586 Instance name: openxs
Redo thread mounted by this instance: 1
Oracle process number: 12
Windows thread id: 3532, image: ORACLE.EXE
*** 2005-04-17 17:26:14.000 *** SESSION ID:(9.500) 2005-04-17 17:26:14.000 APPNAME mod='SQL*Plus' mh=3669949024 act='' ah=4029777240 ===================== PARSING IN CURSOR #1 len=34 dep=0 uid=59 oct=42 lid=59 tim=16127574484 hv=32029095 ad='12f4863c' alter session set sql_trace = true END OF STMT EXEC #1:c=0,e=39642,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=16127528244 ...
Запись в трассировочный файл идет до тех пор, пока не завершится работа соответствующего серверного процесса или пока не будет выполнен оператор:
alter session set sql_trace=false;
Размер создаваемого трассировочного файла ограничивается параметром инициализации max_dump_file_size (по умолчанию - 5 Мбайт). При достижении этого объема запись в файл прекращается. Для трассировки реальных приложений, выполняющих десятки SQL-операторов, значение этого параметра надо существенно увеличить.
Чтобы генерируемая трассировочная информация была действительно полезной, необходимо установить значение параметра инициализации timed_statistics = true. В противном случае, время выполнения различных этапов обработки SQL-оператора регистрироваться не будет. Обычно этот параметр устанавливается даже в производственных системах, поскольку пока трассировка не ведется, его влияние минимально, а если уж она ведется, то чем больше информации будет собрано - тем лучше.
Трассировка в Oracle - прошлое и настоящее
Ведущий специалист-консультант ,
компания
Проект
в Oracle версии 5, выпущенной
Средства трассировки SQL-операторов появились в Oracle версии 5, выпущенной в 1986 году. Для включения и отключения трассировки использовались простые операторы:
select trace('sql',1) from dual ... select trace('sql',0) from dual
Вероятно, немногие знали о возможности трассировки SQL-операторов в Oracle версии 5, и еще меньше людей ее реально использовали. Сама корпорация Oracle во внутренних документах описывала эту возможность как не документированную, не поддерживаемую и явно не подлежащую переносу в версию 6.
По современным стандартам, функция trace версии 5 делала нет так уж много. Все, что вы могли получить в результате - поток секций PARSING IN CURSOR примерно такого вида:
===================== PARSING IN CURSOR 3: "select tab$pid,tab$rba,tab$tbl,tab$type,tab$sowner,tab$sname" " from sys.tables where tab$owner=:1 and tab$name=:2" ===================== PARSING IN CURSOR 4: "select idx$cky from indexes['1.f.1'] where idx$tbl=:1 and id" "x$cky is not null" ===================== PARSING IN CURSOR 1: "select * from dept " =====================
Кроме 'sql', были и другие параметры трассировки. С помощью функции trace пользователь Oracle мог получить информацию о планах выполнения, операциях сортировки и использовании памяти.
в документации возможностью, которую мог
В Oracle версии 6 трассировка SQL-операторов стала базовой, описанной в документации возможностью, которую мог использовать каждый. В версии 6 Oracle представил операторы, которые работают и в версиях 7, 8, 9 и 10:
alter session set sql_trace=true ... alter session set sql_trace=false
Установка sql_trace была существенным шагом вперед для всех занимающихся анализом производительности приложений. Она позволила получить последовательность SQL-операторов, выполненных приложением, а также оценить нагрузку на СУБД, которую они представляли. Необработанные результаты трассировки (см. ранее) выглядели весьма непонятно, но это не имело большого значения, поскольку корпорация Oracle предоставила средство обработки трассировочных файлов tkprof, которое выдавало информацию во вполне понятном виде. (См. ранее. получен на версии 9.2.0.1, но, хотя с версии 6 формат представления результатов немного изменился, по сути, выдаются те же данные.)
Теперь на лучших курсах по "настройке" Oracle, помимо использования магических коэффициентов (вроде процента попадания в буферный кеш), слушателей обучали интерпретации результатов tkprof. При этом предалаглись следующие весьма простые правила:
Надо уменьшать значения в столбце count. Т.е. надо сокращать количество обращений к СУБД. Наиболее действеным способом для этого будет изменение кода приложения.
Надо уменьшать значения в столбцах query и current (они получаются по значениям полей cr и cu в трассировочных файлах, соответственно). Другими словами, надо читать из буферного кеша как можно меньше блоков. Иногда для этого достаточно создать или удалить индекс, а иногда - переписать по-другому SQL-оператор.
Если сумма query + current сведена к минимуму, а в столбце disk - ненулевое значение, рекомендовалось увеличить буферный кеш. Т.е. избавиться от лишних "физических" чтений, но только после того, как избавились от всех лишних логических.
Конечно, к таким рекомендациям пришли не сразу. Многие советовали сначала сводить к нулю значения в столбце disk. Сейчас многим уже известно, что при этом мы провоцируем серьезную проблему производительности: SQL-оператор может находить все необходимые блоки данных в буферном кеше, но при этом быть ужасно неэффективным. Но во времена версии 6 об этом еще не задумывались.
Когда проблема была связана с неэффективными SQL-операторами, неудачной структурой схемы, недостающими индексами, избыточным анализом или неиспользованием возможностей сервера Oracle по обработке множеств, результаты трассировки позволяли выявить проблему. Но для решения некоторых проблем информации в трассировочных файлах было явно недостаточно. Стандартной трассировочной информации недостаточно, когда реальное время выполнения SQL-операторов существенно превосходит процессорное. Например, запрос выполняется 23 секунды, но процессорного времени для него потребовалось лишь 0,17. Что вы можете сказать по остальные 22,83 секунды? При использовании стандартной трассировочной информации ничего определенного сказать нельзя.
Конечно, незнание не мешает выдвигать гипотезы. Наиболее популярной гипотезой, "объясняющей" все проблемы производительности в те времена был ввод-вывод с диска. Это предположение было верно в некоторых случаях, но лишь в некоторых. Что, если проблема не связана с чрезмерной нагрузкой на процессор и с вводом-выводом с диска?
содержит пример, иллюстрирующий проблему. Простой оператор UPDATE изменяет строку по первичному ключу. Он затронул только одну строку (r=1), но выполнялся 10,56 секунды (e=1056). Куда ушло столько времени? Понятно, что не на вычисления, поскольку процессорного времени ушло всего около 0,02 секунды (c=2). Дисковый ввод-вывод тоже не при чем, поскольку, судя по данным трассировки, ядро при изменении не выполнило ни одной операции чтения ОС (p=0). Как узнать, почему это изменение выполнялось более 10 секунд?
Листинг 3. Трассировка уровня 1, показывающая, что общее время выполнения значительно превосходит процессорное
===================== PARSING IN CURSOR #1 len=31 dep=0 uid=73 oct=6 lid=73 tim=27139911 hv=1169598682 ad ='68f56dc8' update c set v1='y' where key=1 END OF STMT PARSE #1:c=0,e=902,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=27139911 EXEC #1:c=2,e=1056,p=0,cr=3,cu=3,mis=0,r=1,dep=0,og=4,tim=27140969
предоставила решение для продемонстрированной
Версия Oracle 7 предоставила решение для продемонстрированной выше проблемы. В версии 7, Oracle представил средства расширенной трассировки SQL-операторов. При включении расширенной трассировки (уровень 8 в табл. 1), ядро Oracle может сообщить, на что именно потрачено время. (Кстати, я начал практически работать с Oracle как раз версии 7.0.16 в 1994 году. Тогда меня подобные проблемы вообще не интересовали - важно было установить сервер и научиться компилировать код на Pro*C. Следующих 5-6 лет трассировку я так и не использовал...) Раньше предполагали, что время уходит на ввод-вывод с диска. Однако точно показывает, на что реально было затрачено время в ситуации, представленной ранее в : ядро Oracle ждало 4 раза, в итоге - около 10 секунд, событий enqueue. Другими словами, изменение было заблокировано - сеанс не мог установить блокировку.
Листинг 4. Трассировка уровня 8 показывает, на что ушло время
===================== PARSING IN CURSOR #1 len=31 dep=0 uid=73 oct=6 lid=73 tim=27139911 hv=1169598682 ad ='68f56dc8' update c set v1='y' where key=1 END OF STMT PARSE #1:c=0,e=902,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=27139911 WAIT #1: nam='enqueue' ela= 307 p1=1415053318 p2=393254 p3=35925 WAIT #1: nam='enqueue' ela= 307 p1=1415053318 p2=393254 p3=35925 WAIT #1: nam='enqueue' ela= 307 p1=1415053318 p2=393254 p3=35925 WAIT #1: nam='enqueue' ela= 132 p1=1415053318 p2=393254 p3=35925 EXEC #1:c=2,e=1056,p=0,cr=3,cu=3,mis=0,r=1,dep=0,og=4,tim=27140969 WAIT #1: nam='SQL*Net message to client' ela= 0 p1=1413697536 p2=1 p3=0
Можно было догадаться? Да. В конечном итоге, оператор UPDATE в Oracle может быть заблокирован. Но причина могла быть и в чем-то другом. На самом деле, скажем, в версии Oracle 7.3.4, это могло произойти по одной из 106 причин, поскольку в версии 7.3.4 трассировкой было охвачено 106 различных веток кода ядра Oracle.
Так что, при среднем "везении", вероятность угадать была около 1%. Но даже если бы вы и угадали, без средств расширенной трассировки вы бы не могли этого доказать. Можете угадать, что это была за блокировка и в каком режиме? Интерпретируя трассировочные данные (p1=1415053318) в соответствии со статьями Oracle Metalink, например, 55541.999 и 62354.1, можно точно сказать, что это исключительная блокировка TX.
Для включения расширенной трассировки в Oracle версии 7 как раз и появился уже представленный ранее оператор ALTER SESSION, устанавливающий событие 10046:
alter session set events '10046 trace name context forever, level 12' ... alter session set events '10046 trace name context off'
Поддерживаемые уровни трассировки были представлены ранее в .
С помощью этого оператора можно включить трассировку в приложении, создатели которого об этом позаботились. (А вы, господа, в нынешнем 2006 году, через 13 (!) лет после выхода версии 7, предоставляете возможность включения и отключения трассировки в своих приложениях? То-то же...). Хорошо, если доступен исходный код приложения - тогда вы сможете его дополнить... А если нет?
Можно, конечно, включить трассировку нужного уровня для всей системы с помощью оператора ALTER SYSTEM. Но от этого будет больше проблем, чем пользы. Диски могут оказаться забиты трассировочными файлами. А если места и хватит, большая часть информации окажется абсолютно бесполезной.
Стадартный пакет Oracle, DBMS_SYSTEM, позволяет действовать намного избирательнее. Упоминавшаяся выше (в разделе "Различные способы включить трассировку") процедура DBMS_SYSTEM.SET_EV позволяет АБД (пользователю sys) включить расширенную трассировку любого сеанса в системе:
dbms_system.set_ev(sid, serial, 10046, 12, ") ... dbms_system.set_ev(sid, serial, 10046, 0, ")
Однако процедура эта и по сей день (официально) не поддерживается. Причем, по соображениям, скорее, "политическим", чем техническим.
На первый взгляд, отказ от поддержки процедуры SET_EV выглядит вполне обоснованным. Привилегию на выполнение пакета DBMS_SYSTEM АБД в производственной системе никому предоставлять не должен - при этом пользователи получат слишком широкие права. Да и сам АБД, при неправильном использовании процедуры SET_EV, может нанести серьезный ущерб системе. Например, если указать вместо события 10046 событие 10004, будет сымитировано разрушение управляющего файла, а это вряд ли полезно в производственной среде... Тем не менее, на практике использование пакета
DBMS_SYSTEM зачастую более чем оправдано. Странно, что использование расширенной трассировки поддерживается официально уже много лет, а вот средства избирательного ее выключения - нет.
поддержка расширенной трассировки SQL
В Oracle версии 8 поддержка расширенной трассировки SQL была дополнена за счет добавления пакета dbms_support (см. файл $ORACLE_HOME/rdbms/admin/dbmssupp.sql). Он защищает пользователей от ужасных последствий ошибок при использовании процедуры dbms_system.set_ev. Этот пакет позволяет легко управлять трассировкой как в своем, так и в любом другом сеансе:
create or replace package dbms_support as
function package_version return varchar2; pragma restrict_references (package_version, WNDS, WNPS, RNPS);
function mysid return number; pragma restrict_references (mysid, WNDS, WNPS, RNPS);
procedure start_trace(waits IN boolean default TRUE, binds IN boolean default FALSE);
procedure stop_trace;
procedure start_trace_in_session(sid IN number, serial IN number, waits IN boolean default TRUE, binds IN boolean default FALSE);
procedure stop_trace_in_session(sid IN number, serial IN number);
end dbms_support; /
Проблема лишь в том, что в файле dbmssupp.sql в комментариях указано следующее:
Rem NOTES Rem This package should only be installed when requested by Oracle Rem Support. It is not documented in the server documentation. Rem It is to be used only as directed by Oracle Support.
Другими словами, он тоже не поддерживается; однако, статья 62294.1 на Metalink, по сути, поощряет использование пакета DBMS_SUPPORT.
В остальном, в версии 8 механизм расширенной трассировки SQL по сравнению с версией 7 не сильно изменился. Разве что, количество событий ожидания возросло до 215.
В средствах трассировки Oracle тоже иногда выявлялись ошибки. Тем не менее, при установке соответствующих пакетов исправлений, стредства трассировки SQL-операторов в Oracle 8 и 8i работают точно и надежно.
Теперь вместо одной сотой секунды
СУБД Oracle версии 9 внесла существенные дополнения в устоявшийся механизм трассировки:
Повышение точности регистрации времени. Теперь вместо одной сотой секунды (0,01) измерения ведутся с точность до микросекунды (0,000001). За счет большей точности измерения можно лучше разобраться с непродолжительными обращениями к СУБД и ожиданиями.
Возможность включения информации об ожиданиях в отчет tkprof. Наконец-то утилита tkprof начала обрабатывать расширенную информацию в трассировочных файлах (раньше приходилось анализировать их непосредственно).
Расширен спектр трассируемых действий. В версии 9.2.0.4 количество событий ожидания выросло до 399.
Учитывается статистика и время работы с каждым сегментом (источником строк). Это помогает определить, сколько времени уходит на работу с источником строк на каждом шаге плана выполнения. См. например мой перевод [].
Добавление статической информации уровня сегмента в версии 9.2.0.2 стало давно ожидаемым лучом света в темном царстве трассировочных файлов. Начиная с версии, сервер Oracle выдавал в трассировочный файл строки STAT при закрытии курсора. Именно по этим строкам утилита tkprof легко собирала реальный план выполнения, а также получала количество строк на выходе каждого шага. Однако проблемы производительности - это проблемы времени выполнения операций, а по количеству обработанных строк время определить, в общем случае, нельзя. Начиная с версии 9.2.0.2, строки STAT имеют вид:
STAT #1 id=5 cnt=23607 pid=4 pos=1 obj=0 op='NESTED LOOPS (cr=1750 r=156 w=0 time= 1900310 us)'
Обратите внимание, что после названия шага в круглых скобках идет новая статистическая информация.
Поле time=1900310 us в данном случае говорит, что на выполнение шага потребовалось 1,900310 секунды.
Время выполнения каждого шага плана - полезная информация. Правда, сначала для получения этой информации требовалось столько ресурсов, что использование трассировки SQL-операторов в версиях с 9.2.0.2 по 9.2.0.4 оказалось зачастую практически нереальным - на трассировку уходило раз в пять больше времени, чем в любой из прежних версий. Это была ошибка Oracle 3009359. К счастью, корпорация Oracle решила эту проблему в версии 9.2.0.5 (вот почему именно ее или более новые и рекомендуется использовать в производственной среде).
есть один архитектурный недостаток.
У средств трассировки версий 6/7/8/ 9 есть один архитектурный недостаток. Во времена версий 5 и 6, когда эти средства проектировались, большинство приложений имело архитектуру клиент-сервер. Каждое приложение организовывало один сеанс взаимодействия с сервером Oracle, который обслуживался одним выделенным серверным процессом, который и генерировал трассировочный файл. Достаточно было включить трассировку только для этого процесса, и мы могли получить всю необходимую информацию.
Однако с конца 1980-ых годов многое в архитектуре приложений Oracle изменилось. Появился Oracle Multi-Threaded Server (режим MTS), и это было лишь первое усложнение для механизма трассировки, поскольку операторы одного сеанса потенциально могли выполнять несколько разделяемых серверных процессов Oracle. В режиме MTS, трассировка одного пользовательского сеанса приводила к созданию нескольких трассировочных файлов, объединение информации из которых надо было делать вручную или с помощью специальных программных средств, используемых серьезными консалтинговыми компаниями. Трассировка в режиме MTS дает столько же полезные результаты, но вот правильно собрать их вместе обычно было нелегко.
Распараллеливание в Oracle еще более усложнило ситуацию: одно действие приложения может выполняться несколькими серверными процессами Oracle. Трассировка оператора со степенью распараллеливания n приведет к созданию одного трассировочного файла в каталоге user_dump_dest и еще до 2n трассировочных файлов в каталоге дампов фоновых процессов. Средства трассировки SQL (как стандартной, так и расширенной) прекрасно работают и при распараллеливании, но чтобы собрать информацию из нескольких трассировочных файлов придется потрудиться или использовать соответствующее программное обеспечение сторонних производителей.
Многоуровневые архитектуры усложнили задачи трассировки еще больше - к некоторым приложениям одновременно могут подключаться сотни тысяч пользователей. Сегодня одно действие конечного пользователя может отразиться в десятке трассировочных файлов на нескольких компьютерах. Но самая большая проблема состоит в том, что трассировкой можно управлять на уровне сеанса Oracle, и трассируя действия одного пользователя вы получаете в трассировочном файле информацию и о действиях многих других пользователей - тех, кто совместно использует один и тот же сеанс (или сеансы), скажем, из пула сервера приложений. И как теперь выделить информацию, касающуюся действий одного пользователя из всех этих данных, полученных при трассировке?
Появившаяся в версии 10 модель сквозной трассировки (end-to-end tracing) призвана решить эту проблему, причем, с обеспечением официальной поддержки всех используемых при этом средств. В версии 10 расширенная трассировка SQL-операторов наконец-то полностью описана в документации и поддерживается (а количество трассируемых событий возросло до 808 в версии 10.1.0.2.). Более того, трассировать в версии 10 теперь можно отдельные модули и действия (функциональные единицы) в сеансе.
Пакет dbms_monitor позволяет включать и отключать трассировку следующим образом:
dbms_monitor.serv_mod_act_trace_enable(service, module, action, true, true) ... dbms_monitor.serv_mod_act_trace_disable(service, module, action)
Кроме того, в версии 10 Oracle предлагает новое инструментальное средство, trcsess, позволяющее автоматически объединить все соответствующие трассировочные файлы, так, чтобы можно было получить линейных поток операторов, выполненных отдельным пользователем.
Конечно, идентифицировать функциональные единицы в подходящем для пакета dbms_monitor виде должно само приложение. Уже давно опытные разработчики приложений использовали для идентификации текущего состояния приложения соответствующие подпрограммы пакета dbms_application_info. Проблема при использовании пакета dbms_application_info была в том, что для установки каждого атрибута (модуля, действия) требовались отдельные вызовы, что отрицательно сказывалось на производительности приложений. Oracle в версии 10 внес изменения в Oracle Call Interface (OCI), позволяющие разработчику приложения включить идентифицирующую информацию в стандартные обращения к СУБД.
При корректной реализации, модель сквозной трассировки версии 10 - это именно то, чего все так долго ждали. Теперь можно ответить на вопрос: "Что именно потребовало столько времени?" для любого оператора в приложении, независимо от сложности ахитектуры системы, в которой оно работает.
что снабжение кода программы средствами
Общеизвестно, что снабжение кода программы средствами трассировки позволяет эффективно выполнять ее отладку и решать проблемы производительности. При наличии подробной информации о том, какие компоненты кода выполнялись, сколько раз, с какими параметрами и сколько времени на это потребовалось, выявление основных причин неэффективной работы из "искусства", которым якобы "владеют" избранные "шаманы", превращается в науку, инженерную дисциплину, которой вполне может овладеть любой администратор и разработчик.
Этой статьей я открываю серию публикаций, посвященных средствам трассировки СУБД Oracle. К счастью (а, может, и к сожалению для многих кандидатов в "шаманы"), эта СУБД с каждой версией расширяла предоставляемые возможности трассировки и теперь, в версии 10g, в ее ядре трассировкой охвачено около 99% кода... Цель данной серии статей состоит в том, чтобы представить наиболее важные для разработки успешных приложений средства трассировки Oracle.
Литература
| 1.обратно | Платформа для коммерческих сред Grid //Открытые системы, 2003, N 12 |
Новая версия СУБД Oracle - Oracle 11g
Марк Ривкин, Oracle СНГ

В октябре 2006 года в г Сан-Франциско на ежегодной конференции Oracle Open World президент компании Oracle Ларри Эллисон объявил о начале бетта тестирования новой версии флагманского продукта компании – СУБД Oracle 11g. Выход версии планируется в 2007 году. Она будет поддерживать много новых функций, обеспечит большее быстродействие, обеспечит более высокую защиту данных и надежность работы приложения.
Все новые возможности 11g можно разделить на несколько групп:
Развитие СУБД Oracle как платформы для GRID вычислений. С этой целью был реализован ряд новых возможностей в области обеспечения высокой надежности и устойчивости работы (High Availability), в области облегчения управления СУБД и повышения ее самоуправляемости, реализован ряд новых возможностей для ускорения работы системы
Управление информацией. С этой целью была улучшена работа со всеми типами данных (включая реализацию Native XML), реализован механизм эффективной работы с файлами, хранимыми в СУБД, а не в файловой системе (SecureFiles), а также реализованы механизмы для поддержки жизненного цикла информации – ILM (Information Lifecycle Management)
Разработка и тестирование приложений. С этой целью были реализованы новые подходы к разработке и модификации пользовательских приложений СУБД, позволяющие выполнять работы по модификации приложений СУБД без остановки их работы. Новые режимы работы Standby (резервной) базы позволят ее использовать для тестирования работы приложений, самой СУБД, отдельных SQL операторов и т д. Все это позволит значительно снизить время плановых простоев системы.
Новые советники (advisers)
В Oracle 11g появился ряд новых советников, упрощающих работу администратора БД. Это:
Partitioning Adviser
Reparing Adviser
Streams Performance Adviser
Space Management Adviser
Наиболее интересен Reparing Adviser. Дело в том, что при возникновении тяжелых сбоев в работе СУБД Oracle администратор оказывается в тяжелой ситуации. За короткое время он должен понять причину сбоя, выбрать и оценить способы восстановления. Для этого ему надо собрать и оценить большой объем информации. Все это в состоянии стресса. Как правило сам процесс восстановления БД после сбоя занимает 10-15% времени простоя, остальное время уходит на сбор и анализ информации.
Reparing Adviser позволяет решить эту проблему. При возникновении сбоя он сам соберет информацию, проанализирует ее с учетом конкретных условий эксплуатации (наличие бэкапов, резервной базы и т д.) и выдаст рекомендации по восстановлению после сбоя. Причем рекомендации будут учитывать реальную конфигурацию и будут проранжированы на основе анализа требуемого времени восстановления и планируемого объема потери данных. (Ведь иногда необходимо запустить систему срочно, не считаясь с потерей последних транзакций.)
Администратор должен выбрать способ лечения из предложенного списка и после чего Reparing Adviser выполнит восстановление БД. Для выбора наиболее эффективного способа лечения Reparing Advisor анализирует всю совокупность возникших ошибок и рекомендует только выполнимые варианты лечения проблемы.
Online Hot Patching
В Oracle 11g можно будет применять некоторые (в основном критичные и отладочные патчи) на ходу без остановки работы экземпляра Oracle c БД. Можно также будет включать/выключать, деинсталлировать специализированные патчи без остановки работы.
Пакетирование информации об инциденте для службы технической поддержки
При возникновении ошибок Oracle администратору необходимо понять их причину и найти способы исправления или обхода ошибки. Обычно эту информацию он находит на сайте metalink.com. Однако, если там решение не найдено, необходимо связаться со службой технической поддержки и отправить туда всю информацию об ошибке, предшествующих ей событиях, журналы, трассировочные файлы и т д. Не всегда этой информации достаточно для выявления причин ошибки и администратору приходится несколько раз связываться со службой технической поддержки, получать новые вопросы, уточнять информацию и т д. В результате на исправление ошибки уходит много времени.
В Oracle 11g эта работа будет автоматизирована. При возникновении той или иной ошибки Oracle знает, какая информация и какие файлы надо отправить в службу технической поддержки. Он создает для возникшего инцидента специальную папку и помещает туда всю необходимую для тех поддержки информацию, включая файлы трассировки и журналы, информацию о предшествующих инцидентах, информацию о проблемах с другим ПО (например, был сбой сервера приложений). Если надо, ДБА будет предложено добавить в эту папку дополнительную информацию. Администратор может контролировать состав пакета об инциденте через окно Support Workbench в OEM. Далее информация упаковывается и автоматически или вручную отправляется в службу технической поддержки.
Прочее
Среди прочих интересных возможностей Oracle 11g следует отметить:
возможность отката завершенных транзакций
возможность выполнения запроса в прошлое (Flashback query) для указанных таблиц на неограниченное время в прошлое – механизм Flashback Data Archive
два новых типа секционирования таблиц – Interval partitioning и Reference partitioning и возможность смешивать различные типы partitioning для таблицы (compsite partitioning)
кэширование результатов и промежуточных результатов запросов на сервере и на клиенте (Server Result Cache и OCI Client Result Cache)
сжатие данных для DSS и OLTP систем, сжатие и кодирование данных всего tablespace
поддержка семантических сетей (Semantic Web)
оптимизация работы RAC и DataGuard
повышение уровня самоуправляемости Oracle 11g
Развитие СУБД Oracle как платформы для GRID вычислений
Начиная с версии 10g компания Oracle позиционирует свою СУБД как платформу для GRID вычислений. Концепция GRID вычислений достаточно проста, понятна, гибка и позволяет экономить средства предприятия []. Поэтому в последнее время наблюдается постепенное внедрение этой архитектуры в IT инфраструктуру.
Вскоре ожидается появление первых GRID с более чем тысячью процессоров. Сегодня многие крупные информационные системы используют от 100 до 300 процессоров. Реализуются как малые кластеры, состоящие из нескольких больших SMP машин (например, 2 узла по 64 процессора или 4 узла по 32 процессора), так и большие кластеры, состоящие из множества мелких элементов (например, 32 узла по 4 процессора). Для российских заказчиков тестируются конфигурации с 1,5 сотней процессоров.
Кроме того, все большую популярность приобретают многоядерные процессоры. Сейчас большинство новых серверов имеет двух – четырех ядерные процессоры и это не предел. Поэтому эра систем с тысячами процессоров уже не за горами. Нужна платформа, позволяющая эффективно реализовывать приложения на этой инфраструктуре. Oracle предлагает в качестве такой платформы GRID на основе СУБД Oracle 11g.
Уже сегодня Oracle 10g позволяет объединить в кластер до 64 узлов. В Oracle 11g эта цифра удвоится. И каждый узел может иметь множество процессоров и ядер. Таким образом суммарная вычислительная мощность такой GRID может превысить вычислительную мощность серьезных mainframe машин. Кстати, уже сегодня Oracle использует для TPC тестов двухтеррабайтный буферный кэш, так что растет не только процессорная мощность GRID, но и ее суммарная память.
Одним из примеров удачного внедрения GRID технологии является хорошо известный многим Интернет магазин . Изначально хранилище данных было реализовано на основе нескольких SMP машин, но затем, с целью повышения мощности и снижения стоимости системы, ее решили перевести на платформу GRID. В качестве элементов GRID использовались четырехпроцессорные компьютеры с OC Linux, на которых был установлен Oracle 10g RAC и Oracle ASM. Архитектура системы представлена на рисунке 1.
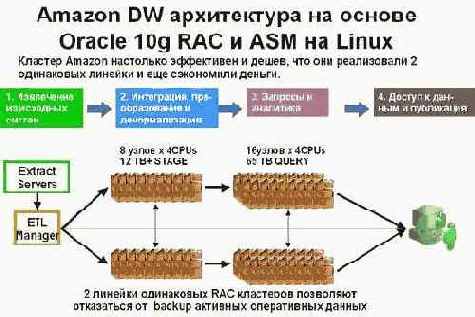
Рис.1.Хранилище данных
Система состоит из нескольких блоков:
извлечение данных из исходных систем
интеграция, преобразование и денормализация данных
блок обработки запросов и анализа данных
блок доступа к данным и публикации.
Извлечением данных занимаются так называемые extract серверы. Далее они передают данные в блок интеграции и преобразований. SMP машины блока интеграции и преобразований были заменены GRID из 8 узлов. Объем данных, хранимых на этом этапе – 12 терабайт. SMP машины блока обработки запросов и анализа были заменены на GRID из 16 узлов. Объем данных хранилища – 66 терабайт. Данные extract серверов поступают в первый GRID (это Stage область), после чего загружаются в хранилище на второй DRID.
После реализации такой линейки из 8+16=24 узлов выяснилось, что стоимость такой инфраструктуры, благодаря использованию дешевых элементов, более чем в 2 раза ниже стоимости предыдущей системы. Поэтому было принято решение реализовать вторую такую же линейку из 8+16 узлов, которая будет дублировать работу первой линейки. Теперь данные extract серверов поступают как на первую, так и на вторую линейку серверов и в компании всегда существует 2 одинаковые версии хранилища. Одна из них является основной, а на вторую можно переключиться в случае сбоя. Такая архитектура позволила отказаться от частого копирования активных оперативных данных. Причем суммарная стоимость такой продублированной архитектуры оказалась ниже стоимости старой системы.
Этот пример еще раз подчеркивает преимущества GRID вычислений, поэтому в версии Oracle 11g был реализован ряд изменений, улучшающих использование СУБД Oracle в GRID. Особое внимание было обращено на снижение времени простоя элементов GRID. Если раньше большинство производителей СУБД прилагало усилия к снижению времени простоя систем, возникающего из-за внезапных, незапланированных причин (поломка компьютера, сбой операционной системы или приложения, человеческие ошибки, катастрофы, потери файлов и т д.), то теперь Oracle сосредоточился на снижении времени плановых простоев.
Плановые остановки систем бывают связаны с патчированием или апгрейдом оборудования, операционных систем, СУБД, а также с исправлением или апгрейдом пользовательских приложений СУБД. Кроме того, операции по тестированию и настройке СУБД и приложений требуют либо остановки/замедления работы эксплуатационной системы, либо создания дополнительных копий БД на дополнительных компьютерах.
Список новых возможностей Oracle 11g для сохранения работоспособности приложений при внесении изменений изображен на рисунке 2.
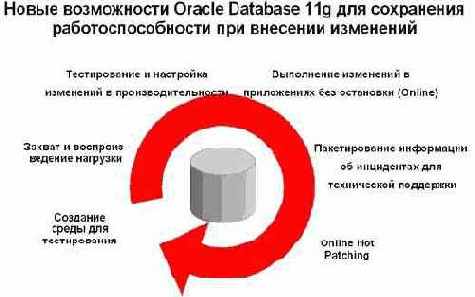
Рис. 2. Новые возможности Oracle 11g для сохранения работоспособности приложений
Коротко рассмотрим эти возможности.
Создание среды для тестирования
В Oracle 10g реализованы 2 варианта создания резервной базы – логический и физический standby. Физический standby работает быстро, но при использовании standby базы для операций чтения ее восстановление приостанавливается. Логический standby имеет ряд ограничений на типы данных, используемые в БД (например, нельзя использовать LOBs).
Поэтому в Oracle 11g реализовано 2 новых типа standby базы: Phisical Standby with Real-Time Query и Snapshot Standby. Phisical Standby with Real-Time Query похож на старый Физический standby, однако в то время, когда standby база открыта на чтение, она продолжает догонять основную БД (восстанавливается на физическом уровне). Т е одна и та же база может использоваться как для защиты от катастрофических сбоев, так и для разгрузки основной базы и для тестирования read only приложений. Так на ней можно печатать отчеты, выполнять бэкапы, заниматься аналитикой и Data Mining.
Snapshot Standby позволяет использовать резервную базу для тестирования новых приложений и настройки старых приложений. В то время, как snapshot standby база догоняет основную базу, на ней можно тестировать приложения, которые читают и меняют данные в БД. После возврата из режима Snapshot Standby в режим Phisical Standby, все изменения, сделанные тестируемым приложением, будут аннулированы.
Выполнение изменений в приложениях без их остановки
Большие важные приложения часто бывают недоступны в течение десятков часов из-за установки новых версий этих приложений. Oracle 11g вводит новое революционное решение, позволяющее выполнять смену версии приложения не останавливая работу этого приложения. Старая и новая версии приложения могут работать одновременно. На рисунке 3 приведен пример двух версий приложения. В старой версии было всего 2 колонки: имя и телефон. В новой версии имя, фамилия, код города и телефон хранятся и отображаются в отдельных колонках. Это потребовало как изменения структуры таблицы, так и изменения процедур, формирующих графический интерфейс. Оба приложения позволяют просматривать и модифицировать данные и могут какое-то время работать одновременно (пока старая версия не будет закрыта).

Рис 3.Пример двух версий приложения
Для реализации возможности одновременной работы старого и нового приложения в Oracle 11g были введены 3 новых понятия: редакция (Edition), Editioning View (редактируемое представление) и CrossEdition Trigger (межредакционный триггер).
Понятие редакции (Edition) обеспечивает существование в БД нескольких версий программных объектов, таких как PL/SQL функции и процедуры, триггеры, views, синонимы и т д. Скрипты патчей и апгрейдов могут вносить изменения в новую редакцию (группу объектов новой редакции), в то время как старая редакция не меняется. При этом изменения не видны пользователям старой редакции. После того, как все изменения завершены и новый код протестирован, можно активизировать новую редакцию. Т е новая версия всех объектов станет актуальной.
Понятие редакции не применимо к таблицам. Чтобы могли сосуществовать 2 версии одной таблицы используются Editioning Views. Т е мы создаем новую, измененную версию таблицы и “вешаем” над ней Editioning View, который прячет все изменения в структуре таблицы и представляет новую таблицу, как старую Editioning View создается в старой редакции и там не видны изменения структуры, которые видны в процедурам новой редакции. Т е старая редакция работает не с таблицей, а с Editioning View.
Для того, чтобы версии приложения могли сосуществовать и в них одновременно можно было изменять данные и видеть измененные данные, используются Editioning Triggers (межредакционные триггеры). При изменении данных в старом приложении они преобразуют изменения в новый формат и пишут их в новую таблицу и наоборот.
Кстати в Oracle 11g зависимые объекты не приобретают статус INVALID и не перекомпилируются при добавлении новых процедур и функций в пакет.
Захват и воспроизведение нагрузки
Для того, чтобы разобраться в том, что происходит с эксплуатационной базой во время ее работы, бывает полезно в более позднее время на тестовой базе воспроизвести точный сценарий работы эксплуатационной базы за определенный период времени. Это позволит не спеша разобраться с проблемами, настроить работу СУБД, оптимизировать работу критичных SQL операторов и т. д.
Функция Database Replay позволяет записать (как на видеомагнитофон) информации обо всем, что происходит с эксплуатационной СУБД, сохраняя информацию об одновременности выполнения операций. Далее эта “запись” проигрывается в реальном времени на тестовой БД или на Snapshot Standby БД, где ДБА может исследовать работу СУБД.
Другой режим – SQL Replay – позволяет захватить и записать всю информацию, связанную с отдельными SQL операторами. Захватывается не только текст этих SQL операторов, но и статистика выполнения, планы выполнения и т д. При воспроизведении записи на тестовой БД можно анализировать работу SQL, оптимизировать их работу, сравнивать статистику работы при различных значениях настроек и т д.
Например, воспроизведение записанных SQL операторов на тестовой БД с новой версией СУБД Oracle, позволит выявить SQL операции, производительность которых снизилась, и вызвать программу Tuning Advisor для их оптимизации с учетом возможностей новой версии СУБД. Для этого в Oracle Enterprise Manager (OEM) реализованы дополнительные экраны, где видны результаты сравнения производительности SQL.
Формат строки STAT
В файле трассировки события 10046 статистическая информация уровня сегмента выдается в строках STAT. Это - статистическая информация "источника строк", и дополнительная информация входит в общую информацию об операции доступа к источнику строк, в поле "op=". Вот два примера, один - из файла трассировки до 9.2, а другой - из файла трассировки 9.2.
Файл трассировки до версии 9.2:
STAT #5 id=1 cnt=1 pid=0 pos=0 obj=43135
op='TABLE ACCESS CLUSTER SEG$ '
Новый формат файла трассировки 9.2:
STAT #1 id=1 cnt=1 pid=0 pos=1 obj=0
op='SORT AGGREGATE (cr=167 r=4 w=0 time=31888 us)'
Обратите внимание на новую информацию, "(cr=167 r=4 w=0 time=31888 us)". Значение "cr=" соответствует количеству операций логического ввода-вывода consistent reads, значение "r=" - количеству физических чтений, значение "w=" - количеству физических записей, а значение "time=" определяет время выполнения и единицу измерения времени (например, us - микросекунды). Учтите, что логический ввод-вывод "current mode" (т.е. cu= в трассировочном файле) не выдается.
Статистическая информация уровня сегмента, по-видимому, выдается только для операций EXEC и FETCH. В контексте строк STAT для конкретного оператора, данные "накапливаются" ("roll-up") в иерархии плана выполнения, по крайней мере, в большинстве случаев . При интерпретации информации строка STAT
с ненулевым значением "obj=" идентифицирует статистическую информацию о доступе к соответствующему сегменту. Эти значения будут "накапливаться" по ходу плана выполнения, и обычно строки STAT с нулевыми значениями "obj=" будут суммировать статистическую информацию подчиненных источников строк.
Представление статистической информации
Итак, что же можно определить по этой информации? В трассировочных файлах версий до 9.2 типичная итоговая информация в строке STAT будет иметь вид (Release 8.1.7.2):
STATEMENT TEXT
select count(*) from dba_users
STATEMENT EXECUTION PLAN
Rows Row Source Operation ------- ----------------------------------------------- 1 SORT AGGREGATE 12,047 MERGE JOIN 12,048 SORT JOIN 12,047 NESTED LOOPS 12,048 NESTED LOOPS 12,048 NESTED LOOPS 12,048 MERGE JOIN 10 SORT JOIN 9 NESTED LOOPS 10 TABLE ACCESS FULL USER_ASTATUS_MAP 9 TABLE ACCESS BY INDEX ROWID PROFILE$ 162 INDEX RANGE SCAN (object id 43224) 12,056 SORT JOIN 12,047 TABLE ACCESS FULL USER$ 24,094 TABLE ACCESS CLUSTER TS$ 24,094 INDEX UNIQUE SCAN (object id 43126) 24,094 TABLE ACCESS CLUSTER TS$ 24,094 INDEX UNIQUE SCAN (object id 43126) 12,047 TABLE ACCESS BY INDEX ROWID PROFILE$ 216,846 INDEX RANGE SCAN (object id 43224) 12,047 SORT JOIN 7 TABLE ACCESS FULL PROFNAME$
Сейчас, в версии 9.2, информация имеет следующий вид (Release 9.2.0.2):
STATEMENT TEXT
select count(*) from dba_users
STATEMENT EXECUTION PLAN
Rows Row Source Operation ------- ------------------------------------------------- 1 SORT AGGREGATE (cr=167 r=4 w=0 time=31888 us) 36 MERGE JOIN (cr=167 r=4 w=0 time=31863 us) 36 SORT JOIN (cr=164 r=3 w=0 time=30441 us) 36 TABLE ACCESS BY INDEX ROWID PROFILE$
(cr=164 r=3 w=0 time=29994 us) 649 NESTED LOOPS (cr=163 r=3 w=0 time=25712 us) 36 NESTED LOOPS (cr=161 r=3 w=0 time=22979 us) 36 NESTED LOOPS (cr=87 r=3 w=0 time=21223 us) 36 MERGE JOIN (cr=13 r=3 w=0 time=19489 us) 9 SORT JOIN (cr=6 r=3 w=0 time=18519 us) 9 TABLE ACCESS BY INDEX ROWID PROFILE$
(cr=6 r=3 w=0 time=18313 us) 163 NESTED LOOPS (cr=5 r=2 w=0 time=11319 us) 9 TABLE ACCESS FULL USER_ASTATUS_MAP
(cr=3 r=1 w=0 time=1278 us) 153 INDEX RANGE SCAN I_PROFILE
(cr=2 r=1 w=0 time=9769 us) (object id 139) 36 SORT JOIN (cr=7 r=0 w=0 time=837 us) 36 TABLE ACCESS FULL USER$ (cr=7
r=0 w=0 time=420 us) 36 TABLE ACCESS CLUSTER TS$ (cr=74
r=0 w=0 time=1535 us) 36 INDEX UNIQUE SCAN I_TS# (cr=2
r=0 w=0 time=206 us) (object id 7) 36 TABLE ACCESS CLUSTER TS$ (cr=74
r=0 w=0 time=1563 us) 36 INDEX UNIQUE SCAN I_TS# (cr=2
r=0 w=0 time=145 us) (object id 7) 612 INDEX RANGE SCAN I_PROFILE (cr=2
r=0 w=0 time=1219 us) (object id 139) 36 SORT JOIN (cr=3 r=1 w=0 time=1283 us) 1 TABLE ACCESS FULL PROFNAME$ (cr=3
r=1 w=0 time=936 us)
На основе этой информации мы можем получить статистику по сегментам и определить вклад каждого сегмента в использование ресурсов на этапах EXEC и FETCH выполнения оператора. С учетом представленного выше примера, для каждого сегмента получаем следующую статистику:
Elapsed Object ID LIO (cr=) Physical Reads Physical Writes Time(sec) ------------ --------------- --------------- --------------- --------------- 94 2 1 0 0.011276 139 4 1 0 0.010988 16 144 0 0 0.002747 280 3 1 0 0.001278 95 3 1 0 0.000936 22 7 0 0 0.000420 7 4 0 0 0.000351 ------------ --------------- --------------- --------------- --------------- Total 167 4 0 0.027996
Эти итоговые данные были получены с помощью описанного ранее подхода. В строке STAT каждого оператора будет идентификатор (параметр id=) строки и идентификатор родительской строки (параметр pid=). Самая верхняя строка в иерархии будет иметь идентификатор 1 и идентификатор родительской строки, равный 0. Строки STAT с ненулевым значением "obj=" будут содержать статистическую информацию о доступе к соответствующему сегменту. Эти значения будут накапливаться по иерархии плана выполнения, и, обычно, строки STAT со значениями 0 у параметра "obj=" будут суммировать статистические показатели своих порожденных источников строк.
в предыдущем примере итоговую статистическую
Если сравнить полученную в предыдущем примере итоговую статистическую информацию по объектам с представленной ниже реальной статистической информацией уровня оператора, можно увидеть, что общее количество логических чтений для всех сегментов равно количеству логических чтений в ходе операций EXEC и FETCH при выполнении оператора. То же самое верно и для физических чтений. Это не всегда верно, но в итоговую информацию заведомо войдет подмножество соответствующих значений, которые будут не больше и, возможно, равны суммарным значениям в статистической информации для оператора.
STATEMENT STATISTICS
Action Count CPU Elapsed PIO Blks LIO Blks Consistent Current Rows ----- ----- --------- --------- -------- -------- ---------- ------- ------ PARSE 1 0.090000 0.142649 6 149 149 0 0 EXEC 1 0.000000 0.000465 0 0 0 0 0 FETCH 2 0.020000 0.031909 4 167 167 0 1 ------ --- ---------- --------- -------- -------- ---------- ------- ----- Total 4 0.110000 0.175023 10 316 316 0 1
Проверка реального времени выполнения (elapsed time) для статистической информации уровня сегмента представляет собой интересную проблему. Если посмотреть на реальное время выполнения операций EXEC и FETCH, и вычесть процессорное время (CPU), получаем значение 0.012374 секунды, или 12374 us. Если затем посмотреть на общее время выполнения в нашей статистике по сегментам, там можно увидеть значение 0.027996 секунды, или 27996 us, но, если вернуться и проанализировать общее время по всем источникам строк (т.е. time=31888 us), то получается немного меньше, чем общее время выполнения операций EXEC и FETCH, 0.032374 секунды, или 32374 us. В этом есть смысл, если учесть, что общее время выполнения в статистической информации уровня сегментов включает процессорное время (CPU time), необходимое для доступа к источнику строк (т.е. логического ввода-вывода), а не только время выполнения физического ввода-вывода. Следует также отметить, что в этом случае не было ввода-вывода "current mode", но подробнее об этом - в следующем примере.
Давайте рассмотрим еще пару примеров. Что произойдет, если есть логический ввод-вывод current mode
(т.е. cu= в операциях EXEC или FETCH), или в статистической информации на уровне оператора будут ненулевые значения и для EXEC, и для FETCH?
Следующий пример показывает использование ввода-вывода как consistent mode (cr=), так и current mode (cu=) в ходе операции EXEC при выполнении оператора. При изучении статистической информации уровня оператора и итогов по сегментам можно увидеть, что сервер Oracle на уровне сегмента сообщает только про ввод-вывод consistent mode. В этом примере ненулевые значения будут только в операциях EXEC, а в предыдущем примере они были только в операциях FETCH. Похоже, для операции PARSE статистическая информация уровня сегмента не выдается.
STATEMENT TEXT
delete from dependency$ where d_obj#=:1
STATEMENT STATISTICS
Action Count CPU Elapsed PIO Blks LIO Blks Consistent Current Rows ------- ----- ------- --------- -------- -------- ---------- ------- ---- PARSE 6 0.020000 0.012211 1 43 43 0 0 EXEC 6 0.010000 0.019214 3 38 16 22 4 FETCH 0 0.000000 0.000000 0 0 0 0 0 ------- ----- -------- --------- -------- -------- ---------- ------- ----- Total 12 0.030000 0.031425 4 81 59 22 4
STATEMENT EXECUTION PLAN
Rows Row Source Operation ------- -------------------------------------------------- 0 DELETE (cr=3 r=2 w=0 time=7656 us) 1 TABLE ACCESS BY INDEX ROWID DEPENDENCY$
(cr=3 r=0 w=0 time=63 us) 1 INDEX RANGE SCAN I_DEPENDENCY1
(cr=2 r=0 w=0 time=37 us) (object id 127) Elapsed Object ID LIO (cr=) Physical Reads Physical Writes Time(sec) ------------ --------------- --------------- --------------- --------------- 127 2 0 0 0.000037 96 1 0 0 0.000026 ------------ --------------- --------------- --------------- --------------- Total 3 0 0 0.000063
Третий, и последний, пример показывает, что выдаваемая статистическая информация не всегда соответствует предполагаемой. В этом примере обратите внимание, что в SQL-операторе использована конструкция "FOR UPDATE", и в источниках строк мы получаем ситуацию, когда информация не накапливается, как можно было ожидать.
STATEMENT STATISTICS
Action Count CPU Elapsed PIO Blks LIO Blks Consistent Current Rows ------- ----- ------- ---------- -------- -------- ---------- ------- ------ PARSE 1 0.000000 0.001438 0 0 0 0 0 EXEC 1 0.000000 0.000430 0 4 3 1 0 FETCH 2 0.000000 0.000143 0 3 3 0 1 ------- ----- -------- ---------- -------- -------- ---------- ------- ------ Total 4 0.000000 0.002011 0 7 6 1 1
STATEMENT TEXT
select mynum from andy where mynum = 99 for update
STATEMENT EXECUTION PLAN
Rows Row Source Operation ------- ------------------------------------------------- 1 FOR UPDATE (cr=3 r=0 w=0 time=113 us) 2 TABLE ACCESS FULL ANDY (cr=6 r=0 w=0 time=276 us)
Elapsed
Object ID LIO (cr=) Physical Reads Physical Writes Time(sec) ------------ --------------- --------------- --------------- --------------- 30536 6 0 0 0.000276 ------------ --------------- --------------- --------------- --------------- Total 6 0 0 0.000276
Обратите внимание, что теперь у нас есть ввод-вывод consistent read как для операции EXEC, так и для FETCH. Мы также выполнили один логический ввод-вывод current mode в ходе операции EXEC, который снова проигнорирован в статистической информации уровня сегмента.
Ссылки
Note: 39817.1, Interpreting Raw SQL_TRACE and DBMS_SUPPORT.START_TRACE output, Oracle Corporation, 14-AUG-1998
1 Поскольку статистическая информация уровня сегмента выдается в трассировке события 10046 любого уровня, она выдается и в простой трассировке SQL_TRACE.
2 Мы представим пример оператора SELECT ... FOR UPDATE, когда это неверно, но, конечно, могут быть и другие случаи.
Эта первоначально была опубликована на сайте . Перевод публикуется с разрешения автора.
by AppsDBA Consulting, All
,
Перевод
Версия 1.1
Copyright © 2003 by AppsDBA Consulting, All Rights Reserved.
в Oracle добавилась возможность получать
В версии 9.2 в Oracle добавилась возможность получать "статистическую информацию уровня сегмента". К словарю данных было добавлено несколько представлений v$, и для сбора соответствующей информации можно избирательно включать сбор статистики на уровне сегмента. Однако при выполнении трассировки с помощью события 10046 эта статистическая информация тоже выдается. По-видимому, хотя я и не нашел еще никакой определенной информации об этом, она появилась в наборе исправлений 9.2.0.2. Поскольку это- статистическая информация "источника строк" ("row source" statistics), она будет входить в строки STAT. Дополнительная информация - часть информации об операции доступа к источнику строк, а именно - поле "op=". В этой статье мы разберемся, как найти эту информацию и как ее можно использовать. В выдаваемых данных есть определенные рассогласования, но, в общем случае, эта статистическая информация уровня сегмента дает специалисту по анализу производительности дополнительную важную информацию для изучения времени выполнения транзакции и влияющих на него факторов.
Как было продемонстрировано, статистика уровня
Как было продемонстрировано, статистика уровня сегмента при трассировке с помощью события 10046 в версии 9.2 дает тому, кто занимается анализом производительности, важную дополнительную информацию, помогающую выявить, какие компоненты замедляют транзакцию. Надеюсь, эта информация вдохновит на дополнительные исследования и поможет понять эти статистические показатели, а также их применение при оптимизации времени выполнения операторов.
Автоматическое управление пространством отката транзакций
Для упрощения сопровождения сегментов отката в СУБД Oracle9i введено автоматическое управление пространством отката транзакций (Automatic Undo Management), которое позволяет серверу базы данных автоматически управлять выделением и сопровождением пространства отката транзакций для различных активных сеансов. Администраторам уже не нужно вручную создавать сегменты отката (rollback segments). Вместо этого, они могут просто создать табличное пространство отката (табличное пространство типа UNDO) и выделить для него достаточный объем дисковой памяти.
Первым преимуществом такого подхода является улучшение сопровождаемости. АБД больше не требуется назначать некоторым транзакциям конкретные сегменты отката или беспокоиться об их размере и количестве.
Другим преимуществом автоматического управления пространством отката транзакций является то, что существенно ограничивается возможность конкуренции за блоки для отката и блоки для согласованного чтения. Используя это средство, СУБД Oracle динамически регулирует количество сегментов отката (undo segments), удовлетворяющее потребностям текущей рабочей нагрузки. При необходимости она создает дополнительные сегменты отката (undo segments). В то же время, по мере необходимости сегменты отката переводятся в автономный или оперативный режимы, позволяя регулировать использование памяти в зависимости от текущей рабочей нагрузки. Все эти операции выполняются без вмешательства администратора. АБД только должен установить в параметре инициализации UNDO_MANAGEMEN (управление пространством отката транзакций) значение AUTO (автоматическое), а в параметре UNDO_RETENTION (сохранение информации в пространстве отката) – время выполнения самого продолжительного запроса, а также выделить достаточное пространство для табличного пространства отката. В Enterprise Manager для этого предусмотрено инструментальное средство определения размера табличного пространства отката в зависимости от времени сохранения сегментов отката.
Например, для конфигурирования сервера базы, в котором продолжительность выполнения запросов не превышает 30 минут, АБД может просто установить в параметре UNDO_RETENTION значение, равное 30 минутам. С помощью управления временем сохранения информации сегментов отката пользователи могут успешно выполнять продолжительные запросы без возникновения неприятной ошибки ORA-1555 (snapshot too old – моментальная копия слишком стара).
Конфигурация систем и баз данных
Перед созданием базы данных АБД должен принять ряд решений о конфигурировании системы. Правильно принятые решения могут в дальнейшем помочь избежать существенных проблем. В данную категорию попадают определение оптимальной конфигурации подсистемы хранения и выбор подходящего размера блоков базы данных. В данном разделе рассматриваются возможные проблемы и лучшие методы конфигурирования и создания баз данных.
Конфигурация внешней памяти
Оптимальное конфигурирование подсистемы хранения базы данных – очень важная задача в большинстве систем. Плохо сконфигурированная подсистема хранения может стать причиной возникновения узких мест ввода-вывода, которые могут существенно снизить скорость работы самой быстрой машины. Поэтому системные администраторы отдают должное конфигурированию внешней памяти и тратят на это очень много времени. Исторически конфигурирование систем хранения базировалось на глубоком понимании приложений базы данных, что приводило к необоснованному усложнению процесса конфигурирования, к уменьшению его управляемости. Альтернативой этого подхода является модель конфигурации внешней памяти SAME (Stripe and Mirror Everything – расщепление и зеркалирование всех данных), в которой предлагается лучший и более управляемый подход. Эта модель была разработана экспертами корпорации Oracle, проделавших значительную исследовательскую работу по определению оптимальной конфигурации внешней памяти систем баз данных Oracle. Модель базируется на четырех простых предложениях:
Расщепляйте все файлы по всем дискам с шириной полосы расщепления, равной 1 Мб. Зеркалируйте данные для обеспечения высокой доступности. Распределяйте данные по секциям, а не по дискам. Размещайте данные, к которым возможен частый доступ, на внешних половинах пространства дисков.
[Прим. науч. ред. А.П.Соколова. У модели SAME есть серьезные оппоненты. См. например,
http://www.oracle.com/ru/oramag/julyaugust2002/index.html?admin_adams.htm,
http://www.oracle.com/ru/oramag/julyaugust2002/index.html?easy_myth2.html. Вместе с тем, в данном разделе показано, что большинство высказанных замечаний может быть учтено при корректном использовании модели SAME.]
Расщепляйте все файлы по всем дискам с шириной полосы расщепления, равной 1 Мб.
Расщепление всех файлов по всем дискам обеспечивает полное использование пропускной способности всех доступных дисководов для любых операций ввода-ввода. Это позволяет равномерно распределить нагрузку по всем дисководам и устранить “горячие участки”. Параллельное выполнение операций и операций с интенсивным вводом-выводом не обязательно должно приводить к возникновению узких мест из-за дисковой конфигурации. Для реконфигурации дискового пространства могут потребоваться большие усилия, поэтому расщепление данных по всем дисководам представляет собой наиболее безопасный и оптимальный вариант. Другим преимуществом расщепления является простота сопровождения. Администраторам для уменьшения времени выполнения запросов с интенсивным обращением к дискам больше не нужно будет заниматься перемещением файлов (а это – нетривиальная задача администрирования). Наиболее простым способом расщепления является расщепление на уровне томов с помощью диспетчеров томов (volume managers). Диспетчеры томов позволяют выполнить расщепление данных по сотням дисков с незначительными накладными расходами ввода-вывода, поэтому в настоящее время они являются лучшим доступным средством для выполнения такой работы.
В результате реализации данного предложения появляется возможность конфигурирования подсистем хранения не только на основании размера базы данных, но и на требуемой пропускной способности ввода-вывода. Например, если общий размер базы данных – 100 гигабайтов с требуемой пропускной способностью – 2000 операций ввода-вывода в секунду, то система может быть сконфигурирована с использованием 20 дисководов размером 5 гигабайтов каждый или же – с 2 дисководами размером 50 гигабайтов каждый. Обе эти конфигурации обеспечивают требуемый объем данных, но только одна из них удовлетворяет требованию пропускной способности ввода-вывода. Таким образом, подсистемы хранения можно конфигурировать, исходя как из требуемого объема данных, так и требуемой пропускной способности ввода-вывода.
Рекомендация использовать размер полосы расщепления (stripe size), равный одному мегабайту, основана на скорости передачи данных и пропускной способности современных дисководов. Чем меньше размер полосы расщепления, тем больше времени тратится на подвод дисковых головок (по сравнению со временем фактической передачи данных). Ниже в таблице 1 показаны результаты наших измерений скоростей передачи данных при различных размерах полосы расщепления. Для этого исследования использовались диспетчер томов Veritas VxVM и подсистема хранения EMC Symmetrix. Как показано в таблице, размер полосы расщепления, равный одному мегабайту, обеспечивает приемлемую пропускную способность, большие размеры полосы дают только незначительные улучшения. Однако, учитывая современные тенденции совершенствования технологии производства дисков, можно предположить, что размер полосы расщепления нужно будет постепенно увеличивать.
Таблица 1. Время передачи данных для различных размеров полосы расщепления.
| Размер полосы расщепления | Время позиционирования головок | Время передачи данных | % времени передачи данных |
| 16 K | 10 мсек | 1 мсек | 10% |
| 64 K | 10 мсек | 3 мсек | 23% |
| 256 K | 10 мсек | 12 мсек | 55% |
| 1 M | 10 мсек | 50 мсек | 83% |
| 2 M | 10 мсек | 100 мсек | 91% |
Зеркалируйте данные для обеспечения высокой доступности.
Зеркалирование данных на уровне подсистем хранения является лучшим способом предотвращения потери данных. В таких системах данные могут пропасть только в случае одновременного сбоя нескольких дисков, что, учитывая высокую надежность современных дисководов, мало вероятно. Кроме зеркалирования дисков следует также использовать средства мультиплексирования СУБД Oracle. Использование этих средств, однако, ограничено только журнальными и управляющими файлами. Хорошая практическая рекомендация: мультиплексируйте зеркалированные журнальные и управляющие файлы, поскольку мультиплексированные файлы менее подвержены физическому разрушению данных.
(Прим. науч. ред. А.П.Соколова В документации Oracle "мультиплексирование" и "зеркалирование" – разные термины ("При зеркалировании файлов СУБД Oracle выполняет операцию записи один раз, а операционная система выполняет эту же операцию на нескольких дисках, при мультиплексировании СУБД Oracle записывает одни и те же данные в несколько файлов". – Сервер Oracle9i. Концепции резервирования и восстановления). Однако в документации они часто используются и как синонимы.)
Распределяйте данные по секциям, а не по дискам.
Иногда требуется разделять или секционировать весь набор данных. Например, АБД может захотеть разделить данные только для чтения и записываемые данные по разным томам. В таких случаях следует размещать секции по всем дискам, а потом объединять и расщеплять их для формирования отдельных логических томов. Логическое разделение файлов данных не компрометирует никаких достоинств методологии SAME.
Размещайте данные, к которым возможен частый доступ, на внешних половинах пространства дисков.
Скорость передачи данных для различных частей поверхности дисков различна – для внешних секторов она выше чем для внутренних. Кроме того, во внешних частях дисков можно размещать больше данных. Поэтому файлы данных с более частым доступом следует размещать на внешних половинах пространства дисков. Журнальные файлы и архивные журнальные файлы, к которым возможен частый доступ при выполнении операций обновления, также следует размещать на внешних половинах пространства дисков. Подобная работа по распределению файлов может привести к дополнительной нагрузке на АБД, поэтому может быть принято простое решение – оставлять внутреннюю часть дисков пустой. Это не настолько расточительное решение, как может показаться, так как более 60% емкости дика размещается на его внешней половине (из-за его круглой формы). Кроме того, современные тенденции увеличения емкости дисководов делают это предложение достаточно жизнеспособным.
Основное достоинство модели SAME заключается в том, что она существенно упрощает конфигурацию системы хранения и подходит для всех режимов рабочей нагрузки. Она одинаково хорошо работает в OLTP-системах, хранилищах данных и при обработке пакетных заданий. Она устраняет "горячие участки ввода-вывода и максимизирует пропускную способность. Наконец, модель SAME не связана с каким-либо технологическим решением управления хранением, доступным сегодня на рынке, и может быть реализована с использованием современных технологий. Более подробно о методологии SAME см. технический документ корпорации Oracle "Optimal Storage Configuration Made Easy" (оптимальная конфигурация внешней памяти, сделанная просто) по адресу
http://otn.oracle.com/deploy/performance/content.html.
Локально управляемые табличные пространства
Локально управляемые табличные пространства (locally managed tablespaces) работают лучше табличных пространств, управляемых с помощью словаря данных (dictionary managed tablespaces), их легче сопровождать и они устраняют проблемы, связанные с фрагментацией пространства. Для выполнения операций, типа выделение и освобождение пространства, в них используются битовые карты, которые хранятся в заголовках файлов данных и, в отличии от табличных пространств, управляемых с помощью словаря данных, и при работе с ними не нужно конкурировать за централизованные ресурсы. Это устраняет необходимость выполнения многих рекурсивных операций, которые иногда требуются для табличных пространств, управляемых с помощью словаря данных, таких, как выделение нового экстента.
В локально управляемых табличных пространствах для управления экстентами предлагается два режима: Auto Allocate (автоматическое выделение) и Uniform (выделение экстентов одинакового размера). В режиме Auto Allocate СУБД Oracle определяет размер каждого выделяемого экстента без вмешательства АБД, тогда как в режиме Uniform АБД указывает размер всех экстентов, выделяемых в данном табличном пространстве. Мы рекомендуем использовать режим Auto Allocate, поскольку, несмотря на то, что в этом режиме у объектов могут появиться множественные экстенты, пользователям не нужно об этом беспокоиться, так как локально управляемые табличные пространства могут поддерживать большое количество экстентов (свыше 1000 для каждого объекта), причем без заметного влияния на производительность. Поэтому мы полагаем, что АБД не будут беспокоиться о размере экстентов и использовать режим Auto Allocate.
В СУБД Oracle9i пользователи могут перемещать табличные пространства, управляемые с помощью словаря данных, в локально управляемые табличные пространства с помощью процедуры PL/SQL DBMS_SPACE_ADMINISTRATION.TABLESPACE_MIGRATE_TO_LOCAL. Это позволяет осуществлять переход с более ранних версий СУБД Oracle и использовать преимущества локально управляемых табличных пространств. Начиная с СУБД Oracle9i Release 2 все табличные пространства (исключая табличное пространство SYSTEM) по умолчанию создаются как локально управляемые табличные пространства.
Лучшие практические методы администрирования СУБД Oracle9i
Мугес А. Миньяс, Корпорация Oracle
Оригинал: Oracle9i Database Administration Best Practices, by Mughees A. Minhas, Server Technologies, Oracle Corporation,
OracleWorld, Copenhagen, Denmark, 24-27 June 2002
Метод создания базы данных
Процесс создания баз данных, их уничтожения и изменения структуры можно упростить с помощью графического инструментального средства конфигурирования Oracle Database Configuration Assistant (DBCA). В режиме адаптации к требованиям пользователей (custom) DBCA позволяет подключать различные опции СУБД (такие, как Spatial – обработка пространственных данных, OLAP-сервисы и т.п.), определять размерные параметры, местонахождение архивных и других файлов, атрибуты хранения, а также, в конце процесса создания базы данных, вручную выполнять все штатные SQL-скрипты. DBCA выполняет все требуемые шаги с минимальным вводом информации и устраняет необходимость детального планирования параметров и структуры базы данных. Более того, DBCA также выдает рекомендации о конкретных установках параметров базы данных в зависимости от введенной информации и, таким образом, помогает АБД принять правильные решения по выбору оптимальной конфигурации базы данных. DBCA можно использовать как для создания баз данных в режиме работы с одним экземпляром СУБД, так и для создания или добавления экземпляров в среде Oracle Real Application Cluster.
В СУБД Oracle9i в DBCA введено понятие шаблонов баз данных (database templates), которое существенно упрощает сопровождение баз данных. Шаблоны баз данных – это новый механизм хранения определений баз данных в XML-формате. В определения включаются все характеристики баз данных, такие, как параметры инициализации, журнальных файлов и т.п.; они могут использоваться для создания идентичных баз данных как в локальных машинах, так и в удаленных. Существует два вида шаблонов: для создания только структур баз данных и для создания структур совместно с данными. Эта функциональная возможность позволяет АБД создавать новые базы данных с помощью предопределенных шаблонов или создавать по существующей базе данных новые шаблоны для их последующего использования. В результате, с помощью этого нового мощного средства существующие базы данных можно "клонировать" с данными или без данных. Шаблоны можно сохранять и повторно использовать для развертывания новых баз данных.
Используя предопределенные шаблоны, DBCA можно запускать в пакетном (silent) режиме и автоматически создавать базы данных или связанные с ними приложения. Это означает, что запуск заданий создания баз данных можно осуществлять с помощью планировщика заданий ОС без какого-либо вмешательства АБД. Все эти возможности делают DBCA очень мощным средством, которое мы рекомендуем для создания баз данных и экземпляров СУБД Oracle.
Настройка кеша буферов.
Некоторые структуры оперативной памяти СУБД, такие, как кеш буферов, существенно влияют на производительность СУБД. Несмотря на то, что утилита StatsPack раскрывает тайны процесса настройки, важность хорошо настроенного кеша буферов заслуживает более строгого метода. С этой целью в СУБД Oracle9i введен механизм консультативной справки по кешу буферов (Buffer Cache Advisory). Эта справка выдается по результатам внутреннего моделирования, основанного на текущей рабочей нагрузке. Справка предсказывает частоту неудачных обращений к кешу для различных размеров кеша буферов в диапазоне от 10% до 200% текущего размера кеша. Эти предсказания публикуются через новое представление V$DB_CACHE_ADVICE, которое можно использовать для определения оптимального размера кеша буферов при существующей рабочей нагрузке. В Oracle Enterprise Manager имеется удобное средство, которое интерпретирует данные представления V$DB_CACHE_ADVICE (см. рис. 3). Обеспечивая детерминированный способ определения размера кеша буферов, СУБД Oracle9i берет на себя работу по предсказанию конфигурации кеша буферов.
Рис 3. Консультативная справка по кешу буферов.
АБД должны использовать эту консультативную справку для настройки кеша буферов. Все консультативные справки, включая консультативную справку по кешу буферов, и сбор статистических данных в СУБД Oracle9i Release 2 управляются с помощью одного параметра STATISTICS_LEVEL (уровень сбора статистических данных). У него может быть три возможных значения: BASIC (базовый), TYPICAL (типовой) и ALL (все). Значение по умолчанию – TYPICAL. Значения TYPICAL и ALL позволяют включать в сервере механизмы создания консультативных справок: Buffer Cache Advisory (кеш буферов), Shared Pool Advisory (разделяемый пул), PGA Advisory (программная глобальная область) и MTTR Advisory (ожидаемое среднее время восстановления). При этом оказывается незначительное влияние на производительность, связанное со сбором данных и моделированием кеша. Однако выгоды от надлежащим образом настроенной памяти намного перевешивают эти накладные расходы.
Настройка памяти для выполнения операторов SQL.
Производительность выполнения сложных долго работающих запросов, типичных в DSS-среде, существенно зависит от размера памяти, доступной в программной глобальной области (PGA, Program Global Area). В СУБД Oracle8i администраторы устанавливают размер PGA, тщательно настраивая ряд параметров инициализации, таких, как SORT_AREA_SIZE, HASH_AREA_SIZE, BITMAP_MERGE_AREA_SIZE, CREATE_BITMAP_AREA_SIZE и т.д. В СУБД Oracle9i появилась опция полностью автоматического управления памятью PGA. Администраторам нужно просто указать максимальный объем памяти PGA, доступной экземпляру СУБД. Для этого используется новый параметр инициализации PGA_AGGREGATE_TARGET (суммарная память PGA). Сервер базы данных автоматически некоторым интеллектуальным способом распределяет эту память между различными активными запросами так, чтобы обеспечить максимальную производительность и наиболее эффективно использовать память. Кроме того, СУБД Oracle9i может сама адаптироваться к изменению рабочей нагрузки, таким образом ресурсы используются эффективно независимо от нагрузки на систему. Объем памяти PGA, доступной экземпляру, можно изменять динамически, изменяя значение параметра PGA_AGGREGATE_TARGET. Это позволяет оперативно добавлять или отнимать память PGA у активного экземпляра. АБД должны использовать данную опцию и не пытаться настраивать PGA вручную, поскольку машина базы данных лучше оснащена средствами определения потребностей в памяти для выполнения операторов SQL. Это относится как к повышению пропускной способности систем с большим количеством пользователей, так и к уменьшению времени ответа при выполнении запросов.
С этой самонастраивающейся PGA единственная остающаяся задача для АБД состоит в том, чтобы установить надлежащим образом значение параметра PGA_AGGREGATE_TARGET. Это очень просто делать с помощью новой консультативной справки по размеру PGA (PGA Advisory), введенной в СУБД Oracle9i Release 2. Как и консультативная справка по кешу буферов эта справка использует внутреннее моделирование для предсказания оптимального размера PGA при текущей рабочей нагрузке. В представлении V$PGA_TARGET_ADVICE содержатся результаты этого моделирования, показывающие надлежащее значение параметра PGA_AGGREGATE_TARGET. В Oracle Enterprise Manager имеется очень простое средство графической визуализации этого моделирования (см. рис. 5).
Рис. 5. Консультативная справка по PGA.
Средство автоматического управления памятью для выполнения операторов SQL включается установкой в файле инициализации значения в параметре PGA_AGGREGATE_TARGET, в противном случае сервер базы данных вернется в режим ручного управления памятью PGA. Для включения механизма создания консультативной справки по PGA необходимо в параметре инициализации STATISTICS_LEVEL установить значение TYPICAL или ALL.
Несмотря на то что повышение производительности наиболее значительным будет в DSS-среде с большой рабочей нагрузкой, это средство будет также полезно и в OLTP-среде. В большинстве OLTP-приложений требуется регулярно подготавливать сложные отчеты, производительность их подготовки может быть повышена благодаря автоматической настройке рабочих областей PGA. Следовательно, АБД должны использовать это средство совместно с консультативной справкой по PGA независимо от характера нагрузки на их системы.
Настройка разделяемого пула.
Разделяемый пул, так же как и кеш буферов, представляет собой важную структуру оперативной памяти, которую необходимо тщательно настраивать для обеспечения высокой производительности сервера базы данных. Влияние настройки разделяемого пула на время реакции СУБД Oracle идентично настройке кеша буферов – облегчайте настройку, используя консультативные справки, которые основаны на внутреннем моделировании рабочей нагрузки. Статистические данные консультативной справки по разделяемому пулу (Shared Pool Advisory) позволяют отслеживать использование библиотечного кеша в памяти разделяемого пула и предсказывать изменение общего времени разбора на уровне экземпляра для различных размеров разделяемого пула. Два новых представления, V$SHARED_POOL_ADVICE и V$LIBRARY_CACHE_MEMORY содержат информацию для определения, сколько памяти используется для библиотечного кеша, сколько памяти закреплено в настоящее время, сколько объектов в LRU-списке разделяемого пула, а также сколько времени может быть потеряно или сэкономлено при изменении размера разделяемого пула. Представление V$SHARED_POOL_ADVICE содержит информацию о расчетной экономии времени разбора для различных размеров разделяемого пула. Эти размеры варьируются в пределах от 50% до 200% текущего размера разделяемого пула с равными интервалами изменения. В Oracle Enterprise Manager имеется средство графической визуализации этого моделирования, с которым проще работать, чем с представлением V$SHARED_POOL_ADVICE через интерфейс командной строки (см. рис. 4).
Рис. 4. Консультативная справка по разделяемому пулу.

Консультативная справка по разделяемому пулу также управляется с помощью параметра STATISTICS_LEVEL. Когда в параметре установлены значения TYPICAL или ALL, механизм создания этой справки включается, для его отключения следует установить значение BASIC. Как отмечено ранее, с помощью параметра STATISTICS_LEVEL выполняется управление сбором статистических данных для всех консультативных справок. Установка в нем значения BASIC отключит все справки.
Общая методология
Оптимизация производительности – это не одноразовая задача, а постоянный процесс. Для эффективной настройки систем баз данных требуются хорошие методы и инструментальные средства. В комплексный процесс оптимизации производительности должны входить следующие шаги:
Регулярный сбор полного набора статистических показателей операционной системы, экземпляров СУБД и приложений.
АБД всегда должны иметь набор статистических показателей, собранных в конкретный момент времени, которые они должны использовать как базовый набор для сравнения. Когда они будут пытаться определить причину деградации производительности или пытаться повысить производительность, сравнение текущих статистических показателей с базовыми статистическими показателями поможет АБД быстро определить главную область приложения усилий. Это даже более важно в случае перехода на новую версию СУБД. Статистические показатели всегда следует собирать перед и после перехода на новую версию СУБД, что может позволить АБД в случае неожидаемого поведения системы определить, настолько быстро, насколько возможно, причину проблемы. Для этих целей в СУБД Oracle предусмотрена утилита StatsPack. StatsPack – это инструментальное средство для комплексного диагностирования проблем производительности на уровне СУБД и приложений. Эта утилита может быть настроена для снятия "моментальных копий" данных производительности и сохранения их в постоянных таблицах базы данных. Пользователь может задать интервал снятия моментальных копий, т.е. частоту сбора данных, а также количество собираемых статистических показателей. Более подробно об инсталляции и использовании утилиты StatsPack см. в технических документах "Diagnosing Performance Using StatsPack, Part I and II" (диагностирование производительности с помощью пакета StatsPack, части I и II) (http://otn.Oracle.com/deploy/performance/content.html).
Определение проблемных областей.
Главная цель сбора статистических показателей – определить проблемы производительности сервера базы данных. Утилита StatsPack выдает легкочитаемый отчет, который указывает на потенциальные области проблем производительности. Итоговая страница типового отчета утилиты StatsPack показана на рис. 2. Этот отчет наиболее полезен, когда для сравнения с текущими показателями производительности системы имеются базовые показатели, поскольку это позволяет АБД обнаружить, что действительно изменилось в системе. Например, если бы процент использования разделяемого пула существенно увеличился, это указало бы на возможное использование в приложениях литеральных значений, приводящее к дополнительному разбору операторов SQL и, следовательно, к замедлению работы системы.
Рис. 2. На первой странице типового отчета утилиты StatsPack на первом плане размещаются ключевые данные о системе.

Определение потенциальных решений.
Как только проблемные области будут идентифицированы, определение потенциальных решений будет относительно простой задачей. Например предположим, на шаге (ii) мы обнаружили, что причиной появления узких мест в системе является использование в хранимых процедурах литеральных значений. Очевидным решением этой проблемы является замена в хранимых процедурах литеральных значений на переменные связывания. Если приложение очень большое, такое, как большинство ERP-приложений, это решение может оказаться нежизнеспособным. В таком случае лучшим решением было бы включение принудительного разделение курсоров с помощью установки параметра инициализации CURSOR_SHARING=FORCE. Таким способом следует наметить в общих чертах одно или более решений для каждой идентифицированной проблемной области.
Реализация решений.
Золотое правило настройки системы – одновременное внесение одного изменения, а затем измерение возникших различий. Давайте предположим, что на шаге (ii) мы идентифицировали несколько проблемных областей, а на следующем шаге определили потенциальные способы решения проблем. Рекомендуемое правило заключается в реализации каждого способа по отдельности, а затем в измерении его влияния на систему. Однако требования к времени простоя системы могут не позволить воспользоваться таким правилом. В этом случае нужно попытаться реализовать только такой набор способов, которые можно проверить независимо. Повторение процесса.
Как только способ решения проблем реализован, его необходимо проверить. Проверку следует осуществлять на уровне пользовательского восприятия производительности, а также повторением шага (i) и сбора дополнительных статистических показателей, позволяющих оценить, имеет ли данный способ желательное влияние или нет. Кроме того, если нагрузка на систему со временем изменяется или модифицируются приложения, весь процесс настройки следует повторить.
Общие причины проблем производительности
Итак, мы обсудили лучшие практические методы оптимизации производительности, давайте сейчас рассмотрим методы, использование которых приводит к возникновению проблем производительности. Наша рекомендация здесь очень простая: "избегайте их".
Плохое управление соединениями.
Приложение соединяется и отсоединяется от базы данных при каждом взаимодействии с ней. Это – обычная проблема программного обеспечения промежуточного слоя в серверах приложений. Эта ошибка снижает производительность более чем на два порядка, а также полностью отсутствует масштабируемость. Возможное решение – трехзвенная архитектура, когда пользователи или клиенты соединяются со средним звеном, который имеет постоянные соединения с базой данных. Таким образом, одно постоянное соединение с базой данных может быть использовано разными пользователями. Плохое совместное использование курсоров.
Отсутствие разделения курсоров приводит к многократным разборам. Если не используются переменные связывания, то выполняется полный разбор (hard parsing) всех операторов SQL. Это имеет существенное отрицательное влияние на производительность. В курсорах, которые открываются и повторно используются много раз, следует использовать переменные связывания. Для больших приложений, в которых не используются переменные связывания, разделение курсоров можно включить принудительно, установив параметр инициализации CURSOR_SHARING=FORCE. Неправильное конфигурирование ввода-вывода.
На многих установках базы данных неудачно размещаются на доступных дисках. На других установках неправильно задается количество дисков, так как диски конфигурируются по дисковому пространству, а не по пропускной способности ввода-вывода. Этой проблемы можно избежать, используя методологию SAME, которая была рассмотрена в начале этой статьи. Проблемы конфигурирования журнала базы данных.
На многих установках слишком мало журнальных файлов и размер их слишком мал. Небольшие журнальные файлы являются причиной частых переключений журнальных файлов, которые могут существенно нагрузить кеш буферов и систему ввода-вывода. Если журнальных файлов слишком мало, процесс архивирования может не справляться со своей работой и работа сервера базы данных будет приостанавливаться. Общее правило: базы данных должны иметь по крайней мере 3 журнальных группы с двумя журнальными файлами в каждой. Нехватка списков свободных блоков, групп списков свободных блоков и сегментов отката.
В кеше буферов может возникать сериализация блоков данных из-за нехватки списков свободных блоков (free lists), групп списков свободных блоков (free list groups), участков транзакций (INITRANS) или сегментов отката (rollback segments). Особенно часто это возникает в приложениях, часто выполняющих операции вставки данных в базу данных с большим размером блоков (от 8Kб до 16Kб). Этой проблемы легко избежать, используя опцию автоматического управления пространством сегментов (Automatic Segment Space Management) вместе с опцией автоматического управления откатом (Automatic Undo Management). Длительные полные просмотры таблиц.
Длительные полные просмотры таблиц в операциях большого объема или в интерактивных операциях, выполняемых в оперативном режиме, могут указывать на неудовлетворительное проектирование транзакций, отсутствие индексов или плохую оптимизацию операторов SQL. Длительные полные просмотры таблиц по своей природе являются операциями, интенсивными по вводу-выводу и немасштабируемыми при увеличении количества пользователей. В пакете настройки (tuning pack) Enterprise Manager предлагается мощный инструмент, SQL-анализатор (SQL Analyze), для обнаружения и оптимизации операторов SQL, интенсивно потребляющих ресурсы. Это – хороший способ решения проблем оптимизации операторов SQL. Дисковые сортировки.
Дисковые сортировки, в противоположность сортировкам в оперативной памяти, могут в операциях, выполняемых в оперативном режиме, указывать на неудовлетворительное проектирование транзакций, отсутствие индексов, неоптимальное конфигурирование PGA или плохую оптимизацию операторов SQL. Дисковые сортировки по своей природе являются операциями, интенсивными по вводу-выводу и немасштабируемыми. Эту проблему можно устранить, выделяя память PGA достаточного размера и используя опцию автоматической настройки PGA (Automatic PGA Tuning), рассмотренную выше. Большие объемы рекурсивных операций SQL.
Большие объемы рекурсивных операций SQL, выполняемых в схеме SYS, могут указывать, что имеют место действия по управлению пространством, такие, как выделение экстентов. Эти действия немасштабируемы и влияют на время реакции системы. Обычно это возникает при использовании табличных пространств, управляемых с помощью словаря данных, (dictionary managed tablespaces). В таких случаях повышению производительности может помочь использование локально управляемых табличных пространств (locally managed tablespaces), существенно уменьшающих объемы рекурсивных операций SQL. Ошибки схем и оптимизатор.
Во многих случаях в приложении используются чрезмерные ресурсы из-за того, что схема, которой принадлежат ресурсы, была неправильно перенесена из среды разработки или из более старой среды промышленной эксплуатации. Примеры: отсутствие индексов или некорректные статистические данные. Эти ошибки могут привести к появлению неоптимальных планов выполнения и низкой производительности интерактивной работы пользователей. При переносе приложений с известной производительностью для поддержи стабильности планов экспортируйте статистические данные схемы с помощью пакета DBMS_STATS. Более того, набор параметров оптимизатора, установленный в файле параметров инициализации, может привести к изменению испытанных оптимальных планов выполнения. По этим причинам для обеспечения устойчивой производительности статистическими данными схемы и параметрами оптимизатора следует управлять вместе как группой. Использование нестандартных параметров инициализации.
Они могли быть установлены на основании плохого совета, неправильного предположения или предшествующей потребности. В частности, параметры, связанные со счетчиком циклических запросов защелок (spin_count ) и недокументированными возможностями оптимизатора, могут привести к возникновению большого количества проблем, которые могут потребовать значительного исследования.
Оптимизация производительности
Плохо настроенная система – это только небольшой шаг, чтобы система стала недоступной. Настройка системы баз данных должна обеспечивать приемлемую производительность, поэтому настройка имеет у АБД высший приоритет. В СУБД Oracle9i появилось несколько новых функциональных возможностей, облегчающих настройку. Марк Шейман (Mark Shaiman), старший научный аналитик компании META Group, подтверждает: “Хотя СУБД Oracle всегда обладала существенными функциональными возможностями, в общем, для достижения оптимальной производительности требовались различные "настройки". В СУБД Oracle9i автоматизированы многие вспомогательные процессы, позволяющие АБД облегчить сопровождение и обеспечить "дружественность по отношению к пользователям" ”. В этом разделе мы обсудим ряд хороших практических методов в свете новых возможностей СУБД Oracle9i.
Планирование восстановления экземпляра
Работа систем может аварийно завершаться по разным причинам, например, из-за прекращения подачи электроэнергии. В этом случае после перезапуска экземпляра СУБД и до открытия базы данных для пользователей будет выполняться восстановление экземпляра. Цель восстановления экземпляра – восстановление физического содержимого базы данных в транзакционно согласованное состояние. Поэтому во время восстановления должны применяться все сделанные зафиксированными транзакциями изменения, которые находились в кеше буферов и не были записаны на диск до сбоя, а затем выполняется откат всех записанных на диск изменений, сделанных незафиксированными транзакциями. Восстановление экземпляра выполняется внутренними механизмами СУБД Oracle и не требует вмешательства администратора. Единственный аспект, о котором должен заботиться АБД – продолжительность выполнения восстановления; это легко контролируется настройкой в файле инициализации параметра FAST_START_MTTR_TARGET (MTTR – mean time to recover, среднее время восстановления). В системах, в которых размер кеша буферов составляет много гигабайтов, восстановление экземпляра может быть очень длительным с совершенно не предсказуемым временем восстановления. Для АБД оба эти свойства мало допустимы. Новая опция быстрого восстановления с предсказуемым временем (Fast-Start Time-Based Recovery) в СУБД Oracle9i позволяет АБД задавать среднее время восстановления экземпляра (в секундах) с помощью установки значения в параметре FAST_START_MTTR_TARGET. Эта опция реализуется ограничением количества "грязных" буферов и количества журнальных записей, сгенерированных после последней контрольной точки. Для обеспечения заданного времени восстановления сервер базы данных по существу регулирует скорость выполнения контрольных точек.
Если в параметре FAST_START_MTTR_TARGET установлено слишком низкое значение, сервер базы данных будет писать на диск очень часто, и это может привести к снижению скорости работы системы. Поэтому этот параметр необходимо настраивать так, чтобы сервер не выполнял чрезмерное количество контрольных точек, но при этом время восстановления оставалось бы в приемлемых пределах. С этой целью в СУБД Oracle9i Release 2 введена новая консультативная справка по MTTR (MTTR Advisory). Эта справка позволяет экземпляру оценивать (в процентах) изменение количества записей на диск, которое могло бы произойти при других значениях в параметре FAST_START_MTTR_TARGET. Используя оценку, полученную при типичной рабочей нагрузке на экземпляр, вы можете определить влияние повышения или понижения значения в данном параметре. Значения консультативной справки по MTTR содержатся в представлении V$MTTR_TARGET_ADVICE. Это представление имеет пять строк, которые показывают предполагаемую дисковую активность при различных значениях в параметре FAST_START_MTTR_TARGET: текущее значение; приблизительно десятая часть текущего значения; приблизительно половина текущего значения; приблизительно полтора текущего значения и приблизительно двойное текущее значение. В Enterprise Manager можно получить графическое представление консультативной справки по MTTR (см. рис. 6).
Теперь АБД имеют инструментарий для управления временем восстановления экземпляра и могут это делать без компрометирования производительности системы. Они должны использовать этот инструментарий, поскольку он позволяет сделать время восстановления экземпляра предсказуемым, а также дает ручки настройки этого времени в соответствии с их потребностями.
Рис. 6. Консультативная справка по MTTR.
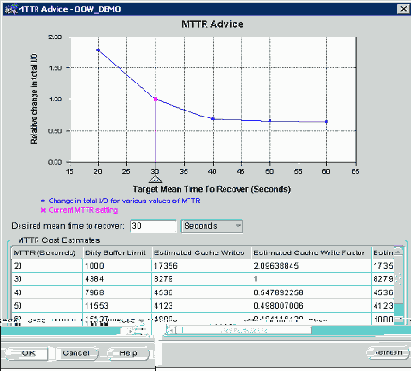
Размер блоков базы данных
Одно из первых решений, которое должен принять АБД при создании базы данных в СУБД Oracle, заключается в выборе размера блоков базы данных. Это делается во время создания базы данных установкой значения параметра инициализации DB_BLOCK_SIZE. Этот параметр может иметь значения 2К, 4К, 8К, 16К или 32К байтов. Как правило, размер блоков базы данных должен быть кратным размеру блоков операционной системы. Большой размер блоков базы данных повышает эффективность физического и логического ввода-вывода. Однако, если размер блоков слишком велик, то в каждом блоке можно будет размещать много логических записей, что в OLTP-среде может привести к возникновению конкуренции за блоки. Другой отрицательной стороной использования очень большого размера блоков является то, что при индексном доступе, когда извлекается только одна строка данных, без всякой необходимости читается много лишних данных. Таким образом, достоинства использования большого размера блоков следует балансировать с недостатками их использования. Размеры блоков 4Кб и 8Кб подходят для большинства сред (4Кб более подходит для OLTP-систем, а 8Кб – для DSS-систем).
Если во время создания базы данных выбран неподходящий размер блоков, в СУБД Oracle9i ситуацию можно исправить. Для этого нужно сначала создать новые табличные пространства с надлежащим размером блоков (в операторе создания используется предложение BLOCKSIZE). Затем, с помощью средств СУБД Oracle для оперативной реорганизации можно перенести объекты в эти новые табличные пространства (без остановки экземпляра СУБД). Для таких реорганизаций можно использовать графические средства инструментария Oracle Enterprise Manager. Следует заметить, табличное пространство SYSTEM нельзя реорганизовать оперативно, поэтому размер блоков этого табличного пространства можно изменить только путем повторного создания базы данных. Хорошая практическая рекомендация: во время создания базы данных постараться принимать верные решения и выбрать надлежащий размер блоков базы данных.
Резервирование и восстановление
Просто говоря, здесь могут происходить плохие дела. Может быть полный отказ систем, файлы могут ошибочно удаляться, могут происходить сбои носителя. АБД, у которого нет обоснованной стратегии резервирования и восстановления для разрешения таких ситуаций, должен иметь под рукой свое резюме о поступлении на работу. В этом разделе мы кратко рассмотрим некоторые процедуры и практические методы, которые помогут АБД сохранить свою работу.
У бизнеса должна быть стратегия восстановления после катастроф, которые приводят к потере данных. В настоящее время только 45% компаний из списка крупнейших компаний мира (Fortune 500) имеют формальные стратегии для своей защиты от бедственной потери данных. Только 12% из этих стратегий рассматриваются на корпоративном уровне ("Calculating the Cost of Downtime" (вычисление стоимости времени простоя), Анжела Карр (Angela Karr), Advanstar Communications). При разработке формальной стратегии АБД должны планировать потерю данных из-за неожиданных отказов, причинами которых могут быть аппаратные или программные сбои, человеческие ошибки, природные явления и т.д. Для каждого из таких возможных событий АБД должны иметь план действий. В некоторых случаях может потребоваться восстановление носителя, в других будет достаточно восстановления экземпляра. Для обеих этих ситуаций АБД должны иметь планы действий. Мы рассмотрим их в этом разделе ниже. В конце концов, администратор базы данных и системный администратор должны документировать среду базы данных и стратегии восстановления, чтобы при возникновении сбоя АБД мог диагностировать проблему и немедленно заняться ее решением.
Сопровождение пространства и объектов
В СУБД Oracle9i для облегчения сопровождения различных объектов базы данных и повышения производительности работы с ними сделан ряд усовершенствований. Карл Бутнер (Karl Buttner), президент компании "170 Systems", приветствуя новые средства СУБД Oracle9i, заявляет: "усовершенствованные средства администрирования и управления базами данных позволяют нашим заказчикам снизить их административные и эксплуатационные издержки, повышая при этом доступность и производительность своих систем". Одним из наиболее значительных усовершенствований в сфере сопровождения СУБД Oracle9i является появление опции Automatic Undo Management (автоматическое управление пространством отката транзакций) которая позволяет устранить необходимость вручную сопровождать сегменты отката. Коме того, улучшено управление табличными пространствами и сегментами, которое при соответствующем использовании позволяет существенно снизить объем работы АБД.
Сопровождение сегментов
Другим вопросом, интересующим АБД, является сопровождение пространства для объектов базы данных. Начиная с СУБД Oracle9i, АБД получают возможность сопровождения пространства для объектов автоматически с помощью опции Automatic Segment Space Management (автоматическое управление пространством сегментов). Она упрощает задачи администрирования пространства и устраняет многие задачи оптимизации производительности, связанные с управлением пространством. Она облегчает сопровождение свободного пространства в таблицах и индексах, повышает уровень использования пространства и обеспечивает существенно лучшие "коробочные" производительность и масштабируемость.
До СУБД Oracle9i администрирование управления пространством осуществлялось с помощью структур данных, называемых FREELISTS (списки свободных блоков). С помощью FREELISTS СУБД следила за блоками объектов, в которых имелось достаточное свободное пространство для вставки новых строк. АБД при создании объектов определял для объектов количество списков свободных блоков и количество групп списков свободных блоков (FREELIST GROUPS), а на уровне таблиц использовался параметр PCTUSED (процент использованного пространства), с помощью которого осуществлялось управление размещением и удалением блоков из списков свободных блоков.
Новый механизм, введенный в СУБД Oracle9i, делает управление пространством в объектах полностью прозрачным, используя для этого битовые карты, позволяющие отслеживать использование пространства в каждом блоке данных, выделенном объекту. Состояние битовой карты показывает, сколько в данном блоке данных имеется свободного пространства (например, >75%, от 50% до 75%, от 25% to 50% или <25%), а также, является ли оно сформатированным или нет. Эта новая реализация освобождает АБД от необходимости ручного управления пространством в объектах. Другим преимуществом механизма автоматического управления пространством сегментов является повышение использования пространства в блоках данных. Причина заключается в том, что битовые карты по сравнению с FREELISTS намного лучше приспособлены для отслеживания и управления свободным пространством на уровне блоков данных. Это делает возможным улучшение повторного использования доступного свободного пространства, особенно для объектов со строками переменного размера. Кроме того, механизм Automatic Segment Space Management существенно повышает производительность конкурентных DML-операций, так как различные части битовой карты могут быть использоваться одновременно, устраняя сериализацию при поиске достаточного свободного пространства.
Улучшение производительности и сопровождаемости, обеспечиваемое механизмом Automatic Segment Space Management особенно заметно в среде Real Application Cluster. Ниже, на рис. 1, показаны результаты внутреннего тестирования, проведенного в СУБД Oracle для сравнения производительности при автоматическом и ручном управлении пространством в сегментах. Этот тест проводился в среде Real Application Cluster в двух узлах (каждый узел имел 6 x 336 Мгц ЦП, 4 Гбайта ОП), при этом в таблицу вставлялось около 3 миллионов строк. Механизм Automatic Segment Space Management обеспечил, по сравнению с оптимально настроенным ручным режимом (8 FREELIST GROUPS, 20 FREELISTS), повышение производительности более чем на 35%.
Рис. 1. Механизм Automatic Segment Space Management обеспечивает лучшую производительность.
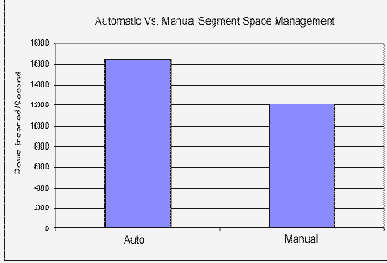
Надписи на рисунке:
Automatic Vs. Manual Segment Space Management – автоматическое управление пространством сегментов по сравнению с ручным; Rows Inserted/Second – строки, вставленные в секунду; Auto – автоматическое; Manual – ручное.
Механизм Automatic Segment Space Management доступен только в локально управляемых табличных пространствах (locally managed tablespaces). В операторе CREATE TABLESPACE (создать табличное пространство) появилось новое предложение SEGMENT SPACE MANAGEMENT (управление пространством сегментов), которое имеет два параметра: AUTO (автоматическое) и MANUAL (ручное). Параметр AUTO позволяет использовать механизм Automatic Segment Space Management, а в режиме MANUAL для управления свободным пространством в объектах по-прежнему будут использоваться списки свободных блоков.
Ссылки
J. Loaiza. Optimal Storage Configuration Made Easy, http://otn.oracle.com/deploy/performance/index.htm
S. Kumar. Server Manageability: DBA’s Mantra for a Good Night’s Sleep. G. Wood, C. Dialeris. Diagnosing Performance Using StatsPack, http://otn.oracle.com/deploy/performance/index.htm
Oracle White Paper: Oracle Performance Improvement Method, http://otn.oracle.com/deploy/performance/index.htm
T. Lahiri, et al. Fast-Start: Quick Fault Recovery in Oracle, http://web06-02.us.oracle.com/deploy/availability/techlisting.html
T. Bednar. Database Backup and Recovery: Strategies and Best Practices. Oracle9i DBAs Guide, Release 1 (9.0.1) (Прим. пер. Имеется также русский перевод: Сервер Oracle9i. Руководство администратора. Выпуск 2 (9.2). Его можно заказать в
http://www.rdtex.ru/.) Oracle9i Database Performance Guide and Reference, Release 1 (9.0.1) Oracle9i Database Concepts, Release 1 (9.0.1) (Прим. пер. Имеется также русский перевод: Сервер Oracle9i. Основные концепции. Выпуск 2 (9.2). Его можно заказать в http://www.rdtex.ru/.) Oracle9i Performance Methods, Release 1 (9.0.1) Oracle Technology Network, http://otn.oracle.com
Стратегия резервирования
Восстановление носителя требуется всегда, когда теряются данные. Наиболее общие причины потери данных: сбои носителя и человеческие ошибки. Для того чтобы можно было восстанавливать носитель, сервер базы данных должен функционировать в режиме ARCHIVELOG (архивирование журнала). Его легко включить с помощью оператора ALTER DATABASE. Затем АБД должны выбрать метод резервирования. В прошлом АБД писали свои собственные скрипты для резервирования базы данных. Сейчас делать это уже нецелесообразно, так как утилита Recovery Manager (диспетчер восстановления) лучше оснащена для управления резервированием. Утилита Recovery Manager имеет вариант с интерфейсом командной стоки, а также вариант с графическим интерфейсом, встроенным в Enterprise Manager. Утилита Recovery Manager позволяет пользователям специфицировать все их требования резервирования, например, полное оперативное резервирование базы данных на ленту, автономное резервирование всей базы данных на диск и т.п. Более того, использование средств планирования в Enterprise Manager позволяет запускать задания создания резервных копий в заданное время, как регулярно, так и по потребности. Хорошая практическая рекомендация: вместе с резервными копиями файлов данных базы данных создавать резервную копию управляющего файла. Резервную копию управляющего файла, как минимум, необходимо создавать при изменении структуры базы данных.
Для тех администраторов, которым требуются также файлы систем резервирования, корпорация Oracle инициировала, совместно с поставщиками систем управления носителями, программу решения проблем резервирования (Backup Solution Program, http://otn.oracle.com/deploy/availability). Участники этой программы – сторонние поставщики, инструментальные средства которых обеспечивают комплексное решение вопросов резервирования как системных файлов, так и файлов базы данных Oracle. Это лучше использования для управления резервированием двух отдельных инструментов, Recovery Manager или Enterprise Manager для файлов базы данных Oracle и отдельного инструмента для системных файлов.
Как обсуждалось ранее, журнальные файлы следует мультиплексировать. Это означает, что каждая журнальная группа будет иметь два журнальных файла или элемента. Настоятельно рекомендуется, чтобы задание создания резервных копий резервировало по крайней мере два элемента каждой журнальной группы. Это подчеркивает важность журнальных файлов, поскольку если во время восстановления возникнут проблемы с архивными журнальными файлами из-за их физического повреждения или человеческой ошибки, то полное восстановление базы данных будет невозможным, и это приведет к потере некоторых данных. Вероятность такого происшествия существенно уменьшается, если есть запасная резервная копия. Заметим, АБД не должны создавать резервную копию журнального файла, а затем резервировать ее еще один раз. Вместо этого они должны резервировать два зеркальных журнальных файла по отдельности, так чтобы в случае повреждения одного из них для восстановления был доступен второй журнальный файл. Если обе копии являются копиями одного и того же архивного журнального файла, то мы не защищаем себя от повреждений журнала.
Стратегия восстановления
АБД должны моделировать сценарии потери данных и тестировать свои планы восстановления. К сожалению, большинство АБД не тестируют свои стратегии резервирования и восстановления. Проведение испытаний плана восстановления помогает проверить процессы на месте, а также держит администраторов в курсе проблем и ловушек восстановления. Четыре основные причины потери данных: сбои носителя, человеческие ошибки, повреждение блоков данных и стихийные бедствия. План восстановления необходимо разрабатывать с учетом каждого случая.
Сбой носителя.
Обычный пример сбоя носителя – разрушение дисковых головок, которое приводит к потере всех файлов базы данных, размещенных на диске. Для полного отказа диска уязвимы все файлы, связанные с базой данных, включая файлы данных, управляющие файлы, оперативные и архивные журнальные файлы. Восстановление после сбоя носителя включает в себя копирование всех неисправных файлов из резервной копии, а затем их восстановление. В наихудшем случае может потребоваться копирование и восстановление всей базы данных. Сбой носителя – первостепенная задача стратегии резервирования и восстановления, поскольку во время восстановления обычно требуется копировать некоторые или все файлы базы данных, а затем применять для их восстановления журнальные файлы. Человеческая ошибка.
Пользователи могут непредумышленно удалять данные или уничтожать таблицы. Хороший способ минимизации последствий таких ситуаций – предоставлять пользователям только такие привилегии базы данных, которые им безусловно необходимы. Но человеческие ошибки будут по-прежнему возникать и АБД должны быть готовы к работе над ними. Создание логических резервных копий или экспорт таблиц – хороший способ справляться со случайными уничтожениями таблиц. Ретроспективный запрос (Flashback Query), новое средство, введенное в СУБД Oracle9i, очень хорошо подходит для восстановления после случайных удалений или вставок. Последним средством, к которому можно прибегнуть, является копирование из резервной копии и восстановление всего табличного пространства, содержащее объекты, на которые подействовала человеческая ошибка. Существуют различные методы восстановления после человеческих ошибок, и все они должны быть протестированы. Повреждение блоков данных.
Неисправная аппаратура или ошибка операционной системы могут быть причиной повреждения блоков данных, в результате которого их формат не будет распознаваться СУБД Oracle или их содержимое будет внутренне несогласованным. В СУБД Oracle имеется средство восстановления носителя на уровне блоков (Block Media Recovery), которое копирует и восстанавливает только поврежденные блоки, и не требует восстановления всего файла данных. Это уменьшает среднее время восстановления (MTTR, Mean Time to Recovery), так как копируются и восстанавливаются только те блоки, которые требуется восстановить, а испорченные файлы данных остаются в оперативном режиме. Стихийные бедствия.
Землетрясения и наводнения могут привести к полному разрушению оборудования информационного центра. В таких случаях требуется копирование из резервных копий и восстановление на альтернативных установках. Это неизбежно влечет за собой необходимость поддержки резервных копий не только на основной установке, но и на альтернативной. "Внешнее" копирование и восстановление следует тщательно тестировать и планировать по времени, чтобы бизнес мог выдержать такие стихийные бедствия без компрометирования своих соглашений об уровнях сервиса.
Тщательно тестируя и документируя свой план восстановления, АБД могут существенно ограничить неожидаемые перерывы в работе и повысить доступность систем баз данных.
Временные табличные пространства
В СУБД Oracle для выполнения различных операций сортировки создаются временные сегменты. Использование постоянных табличных пространств для таких сегментов ведет к излишним накладным расходам по управлению пространством, аналогичным расходам по управлению пространством для постоянных данных. Хорошей практикой в таких случаях является использование специального типа табличного пространства, которое называется Temporary Tablespace (временное табличное пространство). Во временном табличном пространстве выделение пространства осуществляется посредством выборки экстентов из пула в SGA, снижая, таким образом, конкуренцию множественных операций сортировки, уменьшая накладные расходы и устраняя множественные операции управления пространством. Во временном табличном пространстве все операции сортировки разделяют один и тот же сегмент сортировки данного табличного пространства. Ясно, что это представляет собой наиболее эффективный способ работы с временными сегментами, как с точки зрения использования системных ресурсов, так и производительности системы баз данных.
Временные табличные пространства могут управляться как локально, так и с помощью словаря данных. После обсуждения преимуществ использования локально управляемых табличных пространств понятно, что предпочтительно создавать локально управляемое временное табличное пространство. Локально управляемые временные табличные пространства не требуют резервирования и могут использоваться как в базах данных только для чтения, так и в резервных базах данных. Следует отметить, оператор создания таких табличных пространств отличается от операторов создания других табличных пространств: CREATE TEMPORARY TABLESPACE <имя> TEMPFILE <имя_файла> SIZE <размер_файла> EXTENT MANAGEMENT LOCAL.
В СУБД Oracle9i АБД могут для всей базы данных устанавливать Default Temporary Tablespace (временное табличное пространство по умолчанию). Это делается с помощью предложения DEFAULT TEMPORARY TABLESPACE операторов CREATE DATABASE или ALTER DATABASE. Использование опции "временное табличное пространство по умолчанию" гарантирует, что всем пользователям будет назначаться временное табличное пространство. Это обеспечивает выполнение всех дисковых сортировок во временном табличном пространстве, а не в табличном пространстве SYSTEM, которое ошибочно может быть использовано для выполнения сортировок. Кроме того, опция "временное табличное пространство по умолчанию" гарантирует, что постоянные и временные объекты не будут совместно использовать одно и то же табличное пространство – еще одна хорошая практическая рекомендация.
СУБД Oracle всегда отличалась богатейшими
СУБД Oracle всегда отличалась богатейшими функциональными возможностями и средствами, состав и количество которых увеличиваются в каждом новом выпуске СУБД. Это помогает пользователям сделать систему базы данных более надежной, мощной и эффективной, но этот рост функциональных возможностей СУБД также оказывает непосредственное влияние и на методы администрирования СУБД. Для того чтобы воспользоваться преимуществами новых функциональных возможностей, АБД должны пересматривать используемые методы администрирования и приводить их в соответствие с каждой новой версией программного обеспечения. В этой работе в общих чертах представлен ряд практических методов, которые могут помочь АБД воспользоваться новыми функциональными возможностями СУБД Oracle9i для повышения надежности, доступности, сопровождаемости и производительности систем баз данных. Мы отдаем себе отчет, что каждый заказчик имеет уникальную систему базы данных, поэтому предлагаемые практические методы должны учитывать это. В данной работе мы делаем акцент на обобщенных методах администрирования, независимых от платформ и среды, но в то же время важных для хорошего сопровождения СУБД. Рассматриваемые методы можно разделить на четыре категории:
Конфигурация систем и баз данных. Сопровождение пространства и объектов. Оптимизация производительности. Резервирование и восстановление.
Подробное обсуждение каждой категории приведено ниже.
инфраструктур как стратегического императива. Учитывая,
Бизнес пришел к оценке своих ИТ- инфраструктур как стратегического императива. Учитывая, что системы управления базами данных являются ядром ИТ-инфраструктуры, их надежность и доступность имеют принципиальную важность для бизнеса. В этой работе мы наметили в общих чертах некоторые ключевые практические методы в области конфигурирования систем баз данных, их производительности, управления и восстановления, которые существенно повышают надежность и доступность баз данных, а также уменьшают для бизнеса эксплуатационные и административные расходы. Даже минимальное время простоя системы базы данных становится недопустимым для увеличивающегося числа компаний, кроме того, в связи с ростом мощности систем баз данных и расширением их функциональных возможностей, нагрузка на корпоративных АБД в недавнем прошлом росла экспоненциально. Мы надеемся, что эта работа устранит часть этой нагрузки и в то же самое время повысит эффективность их систем баз данных.