Байесовский классификатор и регрессионная модель в ORTD: практический пример

старший консультант отдела бизнес-анализа и хранилищ данных
Консалтинговая группа «Борлас» (Москва)
Источник:
I. Установка Oracle Real Time Decisions
дистрибутив Oracle Real Time Decisions с сайта Oracle
Разархивировать (Unzip) его, найти файл rtd_2.2_OC4J_win.zip и разархивировать его в папку, которая будет RTD_HOME (например: С:\Oracle\RTD)
Подключиться к SQL*Plus под SYSDBA и выполнить следующие команды. SQL>create user rtd identified by rtd; SQL>grant resource,connect to rtd;
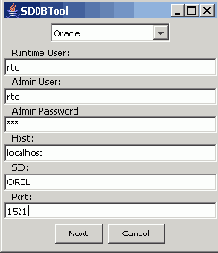
Установить схему с метаданными в rtd. Перейти в папку RTD_HOME/scripts и запустить SDDBTool.cmd
Ввести информацию и нажать кнопку Next
Выбрать Initialize.
Далее для установки необходимо, чтобы у вас был установлен OC4J. Его можно установить либо отдельно, либо он входит в состав Oracle Business Intelligence EE Basic Installation (BI_EE_HOME/oc4j_bi). Далее OC4J_HOME – папка, куда установлен OC4J.
Поскольку администрирование ORTD осуществляется в JConsole через JMX протокол, надо настроить его поддержку в OC4J.
Найти файл OC4J_HOME/bin/oc4j.cmd открыть его на редактирование, найти строку начинающуюся с :oc4j и добавить после нее следующий код:
set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote=true set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.port=12345 set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.authenticate=true set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.ssl=false
Для удобства настроим ORTD на отдельный порт 8080.
Найти файл OC4J_HOME/j2ee/home/config/default-web-site.xml, скопировать в его в ту же директорию с новыми именем rtd-web-site.xml. Затем в файле rtd-web-site.xml сделать следующие изменения и сохранить:
Заменить внутри тега <web-site> значение атрибута port на 8080Заменить внутри тега <web-site> значение атрибута display-name на OC4J 10g RTD Web SiteУдалить все теги <web-app>Заменить внутри тега <access-log> значение атрибута path на ../log/rtd-web-access.log
Скриншот 2
Найти файл OC4J_HOME/j2ee/home/config/server.xml открыть его на редактирование, добавить после строки <web-site default="true" path="./default-web-site.xml" />
строку <web-site default="true" path="./rtd-web-site.xml"
/>.
Найти (JAVA_HOME – папка с JDK, которая используется для запуска OC4J) JAVA_HOME/jre/lib/management/jmxremote.password (если такого файла нет, создать его скопировав из jmxremote.password.template) и раскомментировать строчки: monitorRole QED controlRole R&D
Зайти в свойства файла, далее Безопасность->Дополнительно->Разрешения. Убрать галку с «Наследовать от родительского объекта…». Удалить все разрешения кроме разрешения для владельца файла, которого можно найти на закладке Владелец.
Скриншот 3
Запустить OC4J сервер командой OC4J_HOME/bin/oc4j.cmd –start
Зайти в консоль управление OC4J по адресу http://oc4j_host:port/em (Для отдельного OC4J порт будет 8888, для Oracle BI EE порт будет 9704.) администратором.
Для корректной работы ORTD надо настроить JDBC источники в OC4J для схемы с метаданными.
Перейти на закладку Administration и затем в JDBC Resources. В разделе Connection Pools нажать на Create.
Ввести следующие значения, остальные оставить без изменения и нажать кнопку Apply
| Application | Default |
| Connection Pool Type | New Connection Pool |
| Name | RTDConnectionPool |
| Connection Factory Class | Oracle.jdbc.driver.OracleDriver |
| URL | Ваша строка соединения к базе данных |
| Username | rtd |
| Password (Use Cleartext Password) | rtd |
Скриншот 5
Нажать на копку Create в разделе Data Sources
Ввести следующие значение, остальные оставить без изменения и нажать кнопку Finish
| Application | Default |
| Data Source Type | Managed Data Source |
| Name | RTD_DS |
| JNDI Location | jdbc/SDDS (жестко прошито в ORTD) |
| Connection Pool | RTDConnectionPool |
Скриншот 7
Проверить, что созданные соединения, нажав на Test Connection.
Перейти по адресу http://oc4j_host:port/em и затем на закладку Applications.
Теперь можно «задеплоить» приложение ORTD на сервер.
Нажать на копку Deploy
Выбрать архив из RTD_HOME/package/RTD.ear и нажать Next.
Скриншот 8
Выбрать значения и нажать Next
| Application Name | OracleRTD |
| Parent Application | default |
| Bind Web Module to Site | rtd-web-site |
Нажать Deploy
Oracle Real Time Decisions доступен по адресу http://oc4_host:8080/ui
Создадим и настроим схему SURVEYS из статьи «Решения «растут» на деревьях» (Decisions Grow on Trees, by Ron Hardman). Кроме того, зарегистрируем ее в JDBC источниках в OC4J, чтобы мы могли работать с ней в Real Time Decisions.
II. Настройка схемы SURVEYS
Скачать файл .
Разархивировать его и перейти к папке, содержащей скрипт create_user.sql
Подключиться к SQL*Plus под SYSDBA и выполнить скрипт create_user.sql
Зайти в консоль управление OC4J по адресу http://oc4j_host:port/em администратором.
Настроим дополнительный JDBC источник для схемы Survyes.
Перейти на закладку Administration и затем в JDBC Resources. В разделе Connection Pools нажать на Create.
Ввести следующие значения, остальные оставить без изменения и нажать кнопку Apply
| Application | Default |
| Connection Pool Type | New Connection Pool |
| Name | SurveysConnectionPool |
| Connection Factory Class | oracle.jdbc.driver.OracleDriver |
| URL | Ваша строка соединения к базе данных |
| Username | surveys |
| Password (Use Cleartext Password) | surveys |
Нажать на копку Create в разделе Data Sources
Ввести следующие значение, остальные оставить без изменения и нажать кнопку Finish
| Application | Default |
| Data Source Type | Managed Data Source |
| Name | SURVYES_DS |
| JNDI Location | jdbc/SURVEYSDS |
| Connection Pool | SurveysConnectionPool |
Проверить, что созданные соединения, нажав на Test Connection.
Перейти в папку OC4J_HOME/j2ee/home/applications/OracleRTD Найти файл ./rtis/WEB-INF/web.xml и вставить в конец перед тегом </web-app> следующий текст
<resource-ref id="SURVEYSDS_RTIS">
<res-ref-name>SURVEYSDS</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
<res-sharing-scope>Unshareable</res-sharing-scope>
</resource-ref>
Аналогичным образом найти и изменить файл ./soap/WEB-INF/web.xml. Только в качестве id теперь будет SURVEYSDS_AxisПерейти в папку OC4J_HOME/j2ee/home/application-deployments/OracleRTD Найти файл ./rtis/WEB-INF/orion-web.xml и добавить после строки
<resource-ref-mapping name="SDDS" location="jdbc/SDDS" />
строку
<resource-ref-mapping name="SURVEYSDS" location="jdbc/SURVEYSDS" />
Аналогичным образом найти и изменить файл ./soap/WEB-INF/orion-web.xml.Перезапустить OC4J.
Итак, теперь, у нас есть полностью настроенный Oracle Real Time Decisions и мы можем приступить к созданию проекта.
Настройка Oracle Real Time Decisions осуществляется через стандартный инструмент Java JConsole, работающий через JMX протокол.
III. Настройка доступа в Oracle Real Time Decisions.
Открыть JAVA_HOME/bin/jconsole.exe
Если у вас запущен OC4J, то jconsole найдет его, и он будет в списке доступных соединений.

Нажать Connect
Из всех закладок самая важная для нас – это MBeans, поскольку MBeans и протокол JMX позволяют читать и устанавливать атрибуты, вызывать операции (методы) MBean, подписываться и получать нотификации.
Перейти на закладку MBeans и раскрыть в дереве OracleRTD.
Открыть SDClusterPropertyManager->SecurityManager
Включим поддержку аутентификации средствами самого Oracle Real Time Decisions.
Справа откроются свойста, поставить true в строке AuthenticationEnabled, проверить, что в строке AuthenticationProviderClass стоит com.sigmadynamics.server.security.DBAuthenticator
Скриншот 11
Создадим администратора
Выбрать в дереве, SDManagement->SecurityManager и затем справа закладку Operations.
В строке с кнопкой createUser вписать значения username – admin, description – admin, password – admin и нажать кнопку .
Скриншот 12
В строке с кнопкой assignPermission вписать userOrGroup – admin, permCode – 0 и нажать кнопку.
Скриншот 13
Вся разработка для Real Time Decisions ведется в Decision Studio, специальном инструменте, построенном на основе движка Eclipse.
IV. Создание проекта в Oracle Real Time Decisions
Открыть Decision Studio из RTD_HOME\eclipse\eclipse.exe. Начать новый проект,для этого выбрать в меню File > New > Inline Service Project.
Ввести название для проекта Surveys и выбираем Basic Template в качестве шаблона. (По умолчанию файлы с проектом располагаются в директории C:\Documents and Settings\WIN_USER\Oracle RTD Studio\Surveys)
Скриншот 14
Интерфейс Decision Studio устроен следующим образом.
Скриншот 15
Справа в Проводнике проекта появляется созданный нами проект Surveys. Открыть элемент Surveys > Service Metadata > Application. Это основной объект, в котором содержится вся информация о проекте. Ввести описание для проекта и перейти на закладку Permissions.
Скриншот 16
Для того, чтобы можно было заходить в проект из Decision Studion (Web-приложение для конечного пользователя, необходимо дать доступ пользователя к проекту.
В разделе User or Groups нажимаем Add и далее Select Server. В появившемся окне вводим имя хоста и номер порта, где установлен RTD, а также имя пользователя “admin” и пароль “admin”. Нажимаем Connect и возвращаемся обратно в окно добавления пользователей.
Нажать галочку Show Users и затем кнопку Get Names. В таблице появится созданный нами ранее пользователь admin. Выбрать его нажать OK.
Выбрать пользователя admin и нажать в столбец Granted напротив строк Deploy Service from Studio и Download Service. После этого все 4 строчки должны быть помечены.
Скриншот 17
На предыдущих шагах, мы настроили в OC4J и ORTD поддержку нашего источника данных Surveys Data Source.
Настроим источник информации для проекта. Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Data Sources и выбрать New SQL Data Source
Ввести название Surveys Data Source Справа откроется окно со свойствами, нажать кнопку Import.
Свойства сервера должны совпадать с настроенными нами ранее при импорте пользователя admin, нажать Next
Выбрать SURVEYSDS в качестве JDBC Data Source и таблицу CUSTOMER_SATISFACTION и нажать Finish. Все колонки таблицы появятся в Output. Перенести колонку Input Customer_Satisfaction_Id направо в input
Скриншот 18
К этому моменту мы создали новый проект, настроили доступ пользователя admin к нему, настроили источник данных из схемы Surveys. Теперь настроим основную логику работы.
Создадим сущность, описывающую событие, что конкретный продукт получил или положительную или отрицательную оценку.
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Entities и выбрать New Entity
Ввести название Satisfaction
Нажать на кнопку Import и выбрать в качестве источника Surveys Data Source
В таблице появится список полей из таблицы
Нажать кнопку Add Key, ввести Display Label – Id, Data Type – Integer. Созданный ключ появится в таблице с полями.
Скриншот 19
Перейти на закладку Mapping.
В таблице поля, которые были импортированы, автоматически настроены на источник Surveys Data Source. Созданное нами поле Id не имеет привязки к источнику. Нам надо привязать созданный нами атрибут на входные атрибуты.
В таблице Data Source Input Values нажать на поле в Input Value на поле CUSTOMER_SATISFACTION_ID.
Выбрать Attribute or variables и сущность Satisfaction, поле Id.
Выбрать File > Save All
Во всех проекта Real Time Decisions есть специальная сущность Session, которая создается при открытии новой сессии к серверу. Нам надо связать сущность Session с только что созданной сущностью Satisfaction
Открыть Surveys > Service Metadata > Entities > Session
Нажать Add Attribute, ввести название Satisfaction, выбрать Data Type – Other, затем Entity Types и Satisfaction
Нажать Select в около Session Keys from Dependent Entities и выбрать Session > Satisfaction > Id
Скриншот 20
Для построения анализа зависимостей оценки типа продукта, его версии и год обновления , надо создать группу возможных оценок продукта.
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices и выбрать New Choice Group, ввести название Feedback.
На закладке Choices Attributes нажать Add, ввести название code, Data Type – String
C помощью атрибута code, будем определять оценку, которую получает той или иной продукт. Создадим сами оценки.
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices > Feedback и выбрать New Choice
Ввести имя NEGATIVE, на закладке Attributes Values ввести значение в поле Attribute Value для атрибута code – NEGATIVE
Скриншот 21
Аналогичным образом, нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices > Feedback и выбрать New Choice
Ввести имя POSITIVE, на закладке Attributes Values ввести значение в поле Attribute Value для атрибута code – POSITIVE
Перейдем к созданию модели для поиска зависимостей между оценками продукта и его характеристиками.
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Models > Feedback и выбрать New Choice Model
Ввести название FeedbackAnalysis, на закладке Choice выбрать Choice Group – Feedback
Скриншот 22
Необходимо исключить саму оценку из анализа зависимостей.
На закладке Attributes в разделе Excluded Attributes нажать Select и выбрать Session > Satisfaction > Feedback
Теперь создадим простейший информатор, который будет добавлять новые прецеденты к модели анализа FeedbackAnalysis
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Integration Points > Informants и выбрать New Informant, ввести название Process
Для работы информатора надо выбрать Session Key и ввести логику его работы.
Нажать Select в Session Keys, выбрать Satisfaction / Id
Ввести 0 в поле Order, убрать галку с Force Session Close и перейти на закладку Logic
Скриншот 23
На закладке Logic вводится вся логика работы информатора. Логика пишется на языке Java. Список всех методов можно посмотреть в документации. Для обращения к созданным сущностям и объектам, используется стандартная нотация. Поскольку в Real Time Decisions есть сущность по умолчанию Session, то мы можем обратиться к ней всегда. Кроме того, на предыдущих шагах, мы связали Сущность Session c сущностью Satisfaction.
Ввести следующий код
Скриншот 24
Теперь создадим еще одного информатора, который будет закрывать сессию.
Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Integration Points > Informants и выбрать New Informant, ввести название End
Аналогичным образом выбрать Session Key – Satisfaction / Id
Поставить Order – 1 и галку Force Session Close, которая означает после отработки этого информатора сессия будет закрываться.
На закладке Logic ввести logInfo(“Close”);
Остается последний шаг, указать модели анализа выбора FeedbackAnalysis, где осуществляется добавление нового прецедента.
Открыть Surveys > Service Metadata > Models > FeedbackAnalysis
Перейти на закладку Learn Location, выбрать On Integration Point, нажать Select и выбрать Process.
Скриншот 25
Выбрать File > Save All
После того, как мы создали все необходимые структуры, для того чтобы их протестировать , необходимо «задеплоить» проект на сервер, для этого надо выбрать в меню Project > Deploy. Затем выбрать проект Survyes, ввести название Inline Service – Surveys, Deploymeny State – Development, отметить Terminate active sessions и нажать Deploy.
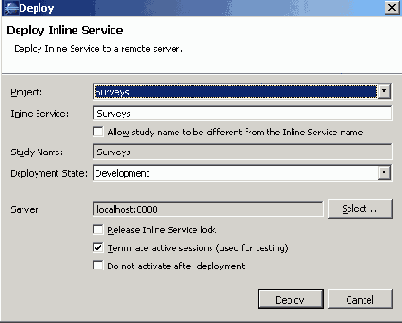
Если все было сделано правильно, то проект удачно «отдеплоится» на сервер и может приступать к тестированию. Если возникнут ошибки, то их список можно посмотреть, выбрав в меню Windows > Show View > Problems.
Для тестирования необходимо выбрать Windows > Show View > Test.
Скриншот 27
В Integration Point надо выбрать Process, тогда в таблице Request Inputs появится одно поле Id. Введем значение 25 и нажмем справа вверху на кнопку Execute Request. Сервер выполнит наш запрос и запишет результаты в лог. Откроем закладку Log.
Скриншот 28
Сервер сделает запрос к таблице CUSTOMER_SATISFACTION по указанному Id, возьмем все характеристики по продукту, и запишет в модель анализа FeedbackAnalysis положительный или отрицательный отзыв.
Для того, чтобы не перебирать руками все записи в таблице CUSTOMER_SATISFACTION, для построения модели анализа. В состав Oracle Real Time Decisions входит специальный инструмент для моделирования работы системы. Называется он Oracle RTD Load Generator и находится RTD_HOME/scripts/loadgen.cmd. Запустим его.
Постановка задачи
Рассмотрим бизнес ситуацию. Производитель предлагает два продукта, А и B. Относительно них имеется очень скудная информация, а именно тип продукта (PRODUCT), версия продукта (VERSION), время его последней модификации (LAST_UPGRADE_YEAR) и отзыв покупателей (FEEDBACK). Производитель хочет, во-первых, узнать как связаны отзывы покупателей с характеристиками продукта и, во-вторых, построить модель для прогнозирования будущих отзывов. В упоминаемой статье автор строит модель классификации на основе деревьев решений в Oracle Data Miner. Мы же попробуем построить Байесовскую модель в Oracle Real Time Decisions, c помощью которой мы сможем проанализировать входные данные.
V. Моделирование работы системы
Нажать Create new Load Generator Script
Перейти на закладку General и ввести следующую информацию
| Client Configuration File | RTD_HOME/client/clientHttpEndPoints.properties |
| Graphs Refresh Interval in Seconds | 1 |
| Inline Service | Surveys (мы указывали название, когда деплоили проект на сервер) |
| Random Number Generator Seed | -1 |
| Think Time | Fixed Global Think Time |
| Constant | 0 |
| Number of Concurrent Scripts to Run | 1 |
| Maximum Number of Scripts to Run | 4920 |
| Enable Logging | Убрать галку |
Перейти на закладку Variables, выбрать Script, нажать правую кнопку мыши и выбрать Add Variable
Ввести название var_Id, Contents – Integer Range, Minimum – 1, Maximum – 4920, Access Type – Sequential
Скриншот 29
Перейти на закладку Edit Script
Нажать правую кнопку мыши на белом фоне и выбрать Add Action
Ввести следующую информацию
| Type | Message |
| Integration Point | Process (Точное название, как он называется в проекте) |
| Inline Service | Surveys (мы указывали название, когда деплоили проект на сервер) |
| Is Asynchronous | Не отмечен |
В таблице Input Fields добавить новое поле, поставить галку на Session Key, Name – id, выбрать Variable - var_Id.
Скриншот 30
Аналогично добавить еще один шаг в скрипт, нажать правую кнопку мыши на белом фоне и выбрать Add Action
Ввести следующую информацию
| Type | Message |
| Integration Point | End (Точное название, как он называется в проекте) |
| Inline Service | Surveys (мы указывали название, когда деплоили проект на сервер) |
| Is Asynchronous | Не отмечен |
В таблице Input Fields добавить новое поле, поставить галку на Session Key, Name – id, выбрать Variable - var_Id
Можно сохранить настроенную конфигурацию в файл.
Построенная нам скрипт будет генерит последовательно id с 1 по 4920 и вызывать шаги Process и End, моделируя работу оператора, который вводит информацию об отзывах о продуктах.
Запустим выполнение построенного нами скрипта.
Скриншот 31
Если все было сделано правильно, то в поле Total Finished Scripts будет стоять 4920, а в поле Total Errors – 0. Это означает, что все запросы были успешно обработаны сервером Real Time Decisions.
VI. Просмотр результатов
Чтобы посмотреть результаты, надо зайти в Decision Center - приложение для среды J2EE, которое обеспечивает доступ к проекту через Web и позволяет бизнес пользователям просматривать и администрировать проекты, следить за работой всей системы, собирать статистику. На сегодняшний момент корректно Decision Center работает только с Internet Explorer.
Зайти по адресу http://oc4j_host:8080/ui, и ввести имя пользователя и пароль admin/admin
Выбрать Open Inline Service и далее Surveys
После этого открывается интерфейс Decision Center, слева отображается дерево объектов системы, которые можно анализировать.
Выбрать Surveys (Development) в дереве, затем справа выбрать Interactive Integration Map.
На Integration Map отображается вся информация о логике работы системы, в ней присутствуют все объекты взаимодействия: информаторы (Informants) и советчики (Advisors). В ней можно интерактивно выполнять тот или иной объект, указывая его входные параметры. В нашем тестовом проекте мы ввели только два информаторы Process, которые записывает очередную реакцию на продукт в модель FeedbackAnalysis и End, который закрывает сессию.
Скриншот 32
Выбрать Surveys > Decision Process > Feedback
Ветка Decision Process является для нас наиболее важной, потому что именно там, находится вся информация о построенной модели для анализа отзывов покупателей.
Выбрать закладку Performance
Скриншот 33
Мы увидим общую информацию по группе выборов Feedback, сколько было положительных и отрицательных отзывов.
Перейти на закладку Analysis
Скриншот 34
На этой закладке выводится общая информация по прогнозированию значений атрибутов. Мы видим, что наилучшие прогноз получается на негативных отзывах (NEGATIVE), причем наибольшую влияние на отзыв оказывает атрибуты LAST_UPGRADE_YEAR, VERSION, PRODUCT.
Перейти в дереве слева в NEGATIVE или POSITIVE и затем на закладку Analysis
На закладке Best-fit указаны атрибуты и их значения, которые наиболее сильно влияют на отзыв покупателя или наибольшим образом коррелированны с отзывом.
Скриншот 35
Для NEGATIVE мы видим, что наибольшая корреляция наблюдается с LAST_UPGRADE_YEAR = 1991, VERSION = 1 и PRODUCT = A (в порядке степени корреляции)
Скриншот 36
В то время как для POSITIVE наиболее характерно VERSION = 3, LAST_UPGRADE_YEAR = 2006 и PRODUCT = B (в порядке степени корреляции).
Перейти на закладку Drivers
Скриншот 37
Для NEGATIVE указано, качество предсказания 83%, причем по LAST_UPGRADE_YEAR качество, даже выше, чем вся модель – 85%.
Нажать на ссылку Satisfaction LAST_UPGRADE_YEAR
Скриншот 38
Получим, что негативные отзывы наиболее сильно коррелированны со следующими значениями атрибута LAST_UPGRADE_YEAR: 1999, 2001, 2002 (в порядке степени влияния).
Скриншот 39
Для позитивных отзывов получим следующее распределение по атрибуту LAST_UPGRADE_YEAR
Скриншот 40
Наиболее сильно коррелированные годы для POSITIVE: 2005,2006,2003,2004 (в порядке степени влияния).
Скриншот 41
Аналогичным образом, мы посмотреть результаты по атрибутам VERSION и PRODUCT.
В результате получаются следующие наиболее устойчивые кластеры NEGATIVE: LAST_UPGRADE_YEAR: 1999, 2001, 2002 VERSION: 1,2 PRODUCT: A POSITIVE: LAST_UPGRADE_YEAR: 2005, 2006, 2003, 2004 VERSION: 3 PRODUCT: B
Таким образом, мы получили следующие результаты: основное расщепление или ветвление осуществляет по атрибуту LAST_UPGRADE_YEAR, если он меньше 2003 года, то отзыв отрицательный, иначе он положительный. При этом если учитывать атрибуты VERSION и PRODUCT в анализе, то получается, что отрицательный отзыв получают продукт A с версиями 1 и 2, а положительный B с версиями 3.
специальный инструмент от компании Oracle,
Oracle Real Time Decisions (ORTD) – специальный инструмент от компании Oracle, предназначенный для автоматизации принятия решений в режиме реального времени (ранее об этом продукте была опубликована статья «Глубинный анализ данных в режиме реального времени: Oracle Real Time Decisions»). Он позволяет строить сложные прогностические модели, опираясь на анализ исторических и оперативных данных. Кроме мощного аналитического движка, ORTD предоставляет бизнес-пользователям и разработчикам полную инфраструктуру как для построения моделей, так и для их повседневного исполнения.
В статье «Решения «растут» на деревьях» (Decisions Grow on Trees, by Ron Hardman) описывается конкретный тип классификации данных, называемый деревья решений. Этот метод был не так давно реализован в продукте Oracle Data Miner (ODM). Результаты его работы легко воспринимаются визуально и могут быть легко объяснены в бизнес-терминах.
В этой статье мы хотели бы познакомить читателей с ORTD на практическом уровне. В ней описывается весь путь от установки и настройки ORTD и до создания проекта и получения практических результатов. В качестве бизнес задачи предлагается взять пример из уже упоминавшейся статьи «Решения «растут» на деревьях». Следует отметить, что в Real Time Decisions реализованы Байесовский классификатор и регрессионная модель, деревья решений в нем не реализованы. Мы построим небольшой тестовый проект в ORTD, целью которого будет продемонстрировать работу в ORTD и сравнить результаты работы Байесовского классификатора в Real Time Decisions, с деревьями решений в ODM.
Если посмотреть на результаты, которые
Если посмотреть на результаты, которые были получены в статье «Решения «растут» на деревьях» (Decisions Grow on Trees, by Ron Hardman) с полученными нами, то видно, что они совпадают. Отличия лишь в максимальной достоверности классификации и представлении самих результатов. В Data Mining Option была получена точность предсказания на уровне 90%. В Real Time Decisions максимальная точность была 83%. Связано это с тем, что в Real Time Decisions использовался Байесовский классификатор, а в Oracle Data Mining деревья решений, которые в данном случае оказались лучше. С точки зрения графической интерпретации результатов, в Oracle Data Miner они были представлены в виде иерархической группировки признаков и их значений (дерева решений). В Real Time Decisions они же были представлены в виде упорядоченных списков коррелированных признаков и их значений. Каждый вариант представления информации имеет свои достоинства и недостатки.
На данном примере очевидными становятся различия в применении Oracle Data Mining и Real Time Decisions. В Data Mining можно легко и быстро осуществить сложный и глубокий анализ на уровне базы данных, причем достоверность классификации будет выше. С другой стороны Real Time Decisions позволяет сроить менее глубокий анализ, но в режиме реального времени. В нашем случае в качестве он-лайн системы, которая генерила события выступал специальный инструмент LoadGen, но с тем же успехом можно подключить и любое бизнес приложение. Real Time Decisions в реальном времени будет пересчитывать модель и строить закономерности между признаками.
Bitmap-индекс или B*tree-индекс
Вивек Шарма, перевод:
Источник: сайт корпорации Oracle, раздел “Technical Articles Published by OTN”
(http://www.oracle.com/technology/pub/articles/sharma_indexes.html).
Понимание, как правильно применить каждый из индексов, может оказать существенное влияние на производительность.
Известная мудрость гласит, что bitmap-индексы более применимы для столбцов, имеющих мало различающихся значений — таких как ПОЛ, СЕМЕЙНОЕ_ПОЛОЖЕНИЕ и РОДСТВО. Однако, это предположение не всегда верно. В реальности применение bitmap-индекса всегда целесообразно в системах, в которых данные редко изменяются многими одновременно работающими задачами. Фактически, как я далее продемонстрирую в этой статье, bitmap-индекс для столбца со 100% уникальными значениями (этот столбец может быть первичным ключом) может быть также эффективен, как и индекс B*tree.
В этой статье я приведу несколько примеров, включающих решения оптимизатора, которые являются общими для обоих типов индексов для столбцов, как с низкой, так и с высокой селективностью. Эти примеры помогут администраторам БД понять, что использование bitmap-индексов в действительности зависит не от селективности, а от приложения.
A (для TEST_NORMAL)
На этом шаге мы создадим bitmap-индекс на таблицу TEST_NORMAL и затем проверим размер индекса, его фактор кластеризации, и размер таблицы. Затем мы выполним несколько запросов с предикатом равенства и зафиксируем количество операций ввода/вывода запросов, использующих этот bitmap-индекс.
SQL> create bitmap index normal_empno_bmx on test_normal(empno); Index created. Elapsed: 00:00:29.06
SQL> analyze table test_normal compute statistics for table for all indexes for all indexed columns; Table analyzed. Elapsed: 00:00:19.01
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3* where segment_name in ('TEST_NORMAL','NORMAL_EMPNO_BMX');
SEGMENT_NAME Size in MB ------------------------------------ --------------- TEST_NORMAL 50 NORMAL_EMPNO_BMX 28
Elapsed: 00:00:02.00 SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ------------------------------ --------------------------------- NORMAL_EMPNO_BMX 1000000
Elapsed: 00:00:00.00
Вы видите, что размер индекса 28MB и что фактор кластеризации равен количеству строк в таблице. Теперь выполним запросы с предикатом равенства по различным наборам значений:
SQL> set autotrace only SQL> select * from test_normal where empno=&empno; Enter value for empno: 1000 old 1: select * from test_normal where empno=&empno new 1: select * from test_normal where empno=1000
Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=34) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=4 Card=1 Bytes=34) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_EMPNO_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets 0 physical reads 0 redo size 515 bytes sent via SQL*Net to client 499 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
B (для TEST_NORMAL)
Теперь удалим этот bitmap-индекс и создадим B*tree индекс на столбец EMPNO. Как и раньше, проверим размер индекса и фактор кластеризации и выполним эти же запросы по тем же наборам значений, чтобы сравнить ввод/вывод.
SQL> drop index NORMAL_EMPNO_BMX; Index dropped.
SQL> create index normal_empno_idx on test_normal(empno); Index created.
SQL> analyze table test_normal compute statistics for table for all indexes for all indexed columns; Table analyzed.
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3 where segment_name in ('TEST_NORMAL','NORMAL_EMPNO_IDX');
SEGMENT_NAME Size in MB ---------------------------------- --------------- TEST_NORMAL 50 NORMAL_EMPNO_IDX 18
SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ---------------------------------- ---------------------------------- NORMAL_EMPNO_IDX 6210
Видно, что B*tree индекс меньше, чем bitmap-индекс на столбец EMPNO. Фактор кластеризации B*tree индекса существенно ближе к количеству блоков таблицы; поэтому B*tree индекс эффективен для запросов с диапазонным предикатом.
Теперь выполним эти же запросы по тому же набору значений, используя наш B*tree индекс.
SQL> set autot trace SQL> select * from test_normal where empno=&empno; Enter value for empno: 1000 old 1: select * from test_normal where empno=&empno new 1: select * from test_normal where empno=1000
Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=34) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=4 Card=1 Bytes=34) 2 1 INDEX (RANGE SCAN) OF 'NORMAL_EMPNO_IDX' (NON-UNIQUE) (Cost=3 Card=1)
Statistics ---------------------------------------------------------- 29 recursive calls 0 db block gets 5 consistent gets 0 physical reads 0 redo size 515 bytes sent via SQL*Net to client 499 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
Видно, что когда запросы выполнены по набору различающихся значений, число consistent gets и physical reads идентично для bitmap и B*tree индексов на 100% уникальном столбце.
| BITMAP | EMPNO | B*TREE | ||
| consistent gets | physical reads | consistent gets | physical reads | |
| 5 | 0 | 1000 | 5 | 0 |
| 5 | 2 | 2398 | 5 | 2 |
| 5 | 2 | 8545 | 5 | 2 |
| 5 | 2 | 98008 | 5 | 2 |
| 5 | 2 | 85342 | 5 | 2 |
| 5 | 2 | 128444 | 5 | 2 |
| 5 | 2 | 858 | 5 | 2 |
A (для TEST_RANDOM)
Теперь выполним такой же эксперимент над TEST_RANDOM:
SQL> create bitmap index random_empno_bmx on test_random(empno); Index created.
SQL> analyze table test_random compute statistics for table for all indexes for all indexed columns; Table analyzed.
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3* where segment_name in ('TEST_RANDOM','RANDOM_EMPNO_BMX');
SEGMENT_NAME Size in MB ------------------------------------ --------------- TEST_RANDOM 50 RANDOM_EMPNO_BMX 28
SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ------------------------------ --------------------------------- RANDOM_EMPNO_BMX 1000000
Опять статистика (размер и фактор кластеризации) идентична для этих индексов со статистикой по таблице TEST_NORMAL:
SQL> select * from test_random where empno=&empno; Enter value for empno: 1000 old 1: select * from test_random where empno=&empno new 1: select * from test_random where empno=1000
Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=34) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_RANDOM' (Cost=4 Card=1 Bytes=34) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP INDEX (SINGLE VALUE) OF 'RANDOM_EMPNO_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets 0 physical reads 0 redo size 515 bytes sent via SQL*Net to client 499 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
B (для TEST_RANDOM)
Теперь, на Шаге 1B (видимо, должно быть 2В – примечание перев.) удалим bitmap-индекс и создадим B*tree индекс на столбец EMPNO.
SQL> drop index RANDOM_EMPNO_BMX; Index dropped.
SQL> create index random_empno_idx on test_random(empno); Index created.
SQL> analyze table test_random compute statistics for table for all indexes for all indexed columns; Table analyzed.
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3 where segment_name in ('TEST_RANDOM','RANDOM_EMPNO_IDX');
SEGMENT_NAME Size in MB ---------------------------------- --------------- TEST_RANDOM 50 RANDOM_EMPNO_IDX 18
SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ---------------------------------- ---------------------------------- RANDOM_EMPNO_IDX 999830
Результат показывает, что размер индекса равен размеру этого индекса для таблицы TEST_NORMAL, но фактор кластеризации более близок к количеству строк, что делает этот индекс неэффективным для запросов с диапазонным предикатом (его мы увидим на Шаге 4). Этот фактор кластеризации не будет влиять на запросы с предикатом равенства, потому что строки имеют 100% различающихся значений и количество строк на значение равно 1.
Теперь выполним запросы с предикатом равенства и тем же самым набором значений.
SQL> select * from test_random where empno=&empno; Enter value for empno: 1000 old 1: select * from test_random where empno=&empno new 1: select * from test_random where empno=1000
Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=34) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_RANDOM' (Cost=4 Card=1 Bytes=34) 2 1 INDEX (RANGE SCAN) OF 'RANDOM_EMPNO_IDX' (NON-UNIQUE) (Cost=3 Card=1)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 5 consistent gets 0 physical reads 0 redo size 515 bytes sent via SQL*Net to client 499 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
Опять результаты полностью идентичны полученным на Шаге 1A и Шаге 1B. Распределение данных не повлияло на количество consistent gets и physical reads для уникального столбца.
A (для TEST_NORMAL)
На этом шаге мы создадим bitmap-индекс (как на Шаге 1A). Мы знаем размер и фактор кластеризации индекса, который равен количеству строк таблицы. Теперь выполним несколько запросов с диапазонными предикатами. SQL> select * from test_normal where empno between &range1 and &range2; Enter value for range1: 1 Enter value for range2: 2300 old 1: select * from test_normal where empno between &range1 and &range2 new 1: select * from test_normal where empno between 1 and 2300 2300 rows selected. Elapsed: 00:00:00.03
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=451 Card=2299 Bytes=78166) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=451 Card=2299 Bytes=78166) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP INDEX (RANGE SCAN) OF 'NORMAL_EMPNO_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 331 consistent gets 0 physical reads 0 redo size 111416 bytes sent via SQL*Net to client 2182 bytes received via SQL*Net from client 155 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2300 rows processed
B (для TEST_NORMAL)
На этом шаге выполним запросы по таблице TEST_NORMAL с B*tree индексом. SQL> select * from test_normal where empno between &range1 and &range2; Enter value for range1: 1 Enter value for range2: 2300 old 1: select * from test_normal where empno between &range1 and &range2 new 1: select * from test_normal where empno between 1 and 2300 2300 rows selected. Elapsed: 00:00:00.02
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=23 Card=2299 Bytes=78166) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=23 Card=2299 Bytes=78166) 2 1 INDEX (RANGE SCAN) OF 'NORMAL_EMPNO_IDX' (NON-UNIQUE) (Cost=8 Card=2299)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 329 consistent gets 15 physical reads 0 redo size 111416 bytes sent via SQL*Net to client 2182 bytes received via SQL*Net from client 155 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2300 rows processed
Когда эти запросы будут выполнены для различных наборов диапазонов, результаты, представленные ниже, покажут:
|
BITMAP |
EMPNO (Range) |
B*TREE |
||
|
consistent gets |
physical reads |
consistent gets |
physical reads |
|
|
331 |
0 |
1-2300 |
329 |
0 |
|
285 |
0 |
8-1980 |
283 |
0 |
|
346 |
19 |
1850-4250 |
344 |
16 |
|
427 |
31 |
28888-31850 |
424 |
28 |
|
371 |
27 |
82900-85478 |
367 |
23 |
|
2157 |
149 |
984888-1000000 |
2139 |
35 |
Как видите, количество consistent gets и physical reads обоих индексов опять почти идентичны. Последний диапазон (984888-1000000) возвратил целых 15,000 строк, т.е. наибольшее количество строк из всех извлеченных по остальным диапазонам. Поэтому, когда мы запросили full scan по таблице (указав хинт /*+ full(test_normal) */ ), количество consistent gets и physical reads было 7,239 и 5,663, соответственно.
A (для TEST_RANDOM)
На этом шаге мы выполним запросы с диапазонными предикатами по таблице TEST_RANDOM с bitmap-индексом и сверим последовательные consistent gets и physical reads. Здесь вы увидите влияние фактора кластеризации.
SQL>select * from test_random where empno between &range1 and &range2; Enter value for range1: 1 Enter value for range2: 2300 old 1: select * from test_random where empno between &range1 and &range2 new 1: select * from test_random where empno between 1 and 2300
2300 rows selected. Elapsed: 00:00:08.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=453 Card=2299 Bytes=78166) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_RANDOM' (Cost=453 Card=2299 Bytes=78166) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP INDEX (RANGE SCAN) OF 'RANDOM_EMPNO_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 2463 consistent gets 1200 physical reads 0 redo size 111416 bytes sent via SQL*Net to client 2182 bytes received via SQL*Net from client 155 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2300 rows processed
B (для TEST_RANDOM)
На этом шаге мы выполним запросы с диапазонным предикатом по таблице TEST_RANDOM с B*tree индексом. Повторю, что фактор кластеризации этого индекса был очень близок к количеству строк в таблице (и поэтому неэффективен). Ниже показано, что об этом сообщает оптимизатор:
SQL> select * from test_random where empno between &range1 and &range2; Enter value for range1: 1 Enter value for range2: 2300 old 1: select * from test_random where empno between &range1 and &range2 new 1: select * from test_random where empno between 1 and 2300 2300 rows selected. Elapsed: 00:00:03.04
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=613 Card=2299 Bytes=78166) 1 0 TABLE ACCESS (FULL) OF 'TEST_RANDOM' (Cost=613 Card=2299 Bytes=78166)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 6415 consistent gets 4910 physical reads 0 redo size 111416 bytes sent via SQL*Net to client 2182 bytes received via SQL*Net from client 155 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2300 rows processed
Оптимизатор предпочел full scan таблицы, а не использование индекса, потому что фактор кластеризации:
|
BITMAP |
EMPNO (Range) |
B*TREE |
||
|
consistent gets |
physical reads |
consistent gets |
physical reads |
|
|
2463 |
1200 |
1-2300 |
6415 |
4910 |
|
2114 |
31 |
8-1980 |
6389 |
4910 |
|
2572 |
1135 |
1850-4250 |
6418 |
4909 |
|
3173 |
1620 |
28888-31850 |
6456 |
4909 |
|
2762 |
1358 |
82900-85478 |
6431 |
4909 |
|
7254 |
3329 |
984888-1000000 |
7254 |
4909 |
Только для последнего диапазона (984888-1000000) оптимизатор предпочел full scan таблицы с bitmap-индексом, тогда как для всех остальных диапазонов он предпочел full scan таблицы с B*tree индексом. Это несоответствие образовалось вследствие фактора кластеризации: Оптимизатор не принимает во внимание значение фактора кластеризации, когда генерирует план выполнения с использованием bitmap-индекса, тогда как для B*tree индекса, он это делает. В этом сценарии bitmap-индекс выполняется более эффективно, чем B*tree индекс.
Нижеследующие шаги показывают более интересные детали об этих индексах.
A (для TEST_NORMAL)
Создаем bitmap-индекс на столбец SAL таблицы TEST_NORMAL. Этот столбец имеет нормальную селективность.
SQL> create bitmap index normal_sal_bmx on test_normal(sal); Index created.
SQL> analyze table test_normal compute statistics for table for all indexes for all indexed columns; Table analyzed.
Теперь давайте получим размер индекса и фактор кластеризации.
SQL>select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2* from user_segments 3* where segment_name in ('TEST_NORMAL','NORMAL_SAL_BMX');
SEGMENT_NAME Size in MB ------------------------------ -------------- TEST_NORMAL 50 NORMAL_SAL_BMX 4
SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ------------------------------ ---------------------------------- NORMAL_SAL_BMX 6001
Теперь запросы. Сначала выполним их с предикатом равенства:
SQL> set autot trace SQL> select * from test_normal where sal=&sal; Enter value for sal: 1869 old 1: select * from test_normal where sal=&sal new 1: select * from test_normal where sal=1869
164 rows selected. Elapsed: 00:00:00.08
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=39 Card=168 Bytes=4032) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=39 Card=168 Bytes=4032) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 165 consistent gets 0 physical reads 0 redo size 8461 bytes sent via SQL*Net to client 609 bytes received via SQL*Net from client 12 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 164 rows processed
И затем с диапазонными предикатами:
SQL> select * from test_normal where sal between &sal1 and &sal2; Enter value for sal1: 1500 Enter value for sal2: 2000 old 1: select * from test_normal where sal between &sal1 and &sal2 new 1: select * from test_normal where sal between 1500 and 2000
83743 rows selected. Elapsed: 00:00:05.00
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=601 Card=83376 Bytes=2001024) 1 0 TABLE ACCESS (FULL) OF 'TEST_NORMAL' (Cost=601 Card=83376 Bytes=2001024)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 11778 consistent gets 5850 physical reads 0 redo size 4123553 bytes sent via SQL*Net to client 61901 bytes received via SQL*Net from client 5584 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 83743 rows processed
Теперь удалим bitmap-индекс и создадим B*tree индекс на TEST_NORMAL.
SQL> create index normal_sal_idx on test_normal(sal); Index created.
SQL> analyze table test_normal compute statistics for table for all indexes for all indexed columns; Table analyzed.
Взгляните на размер индекса и фактор кластеризации.
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3 where segment_name in ('TEST_NORMAL','NORMAL_SAL_IDX');
SEGMENT_NAME Size in MB ------------------------------ --------------- TEST_NORMAL 50 NORMAL_SAL_IDX 17
SQL> select index_name, clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR ------------------------------ ---------------------------------- NORMAL_SAL_IDX 986778
Из полученных выше данных можно увидеть, что этот индекс больше, чем bitmap-индекс на тот же столбец. Фактор кластеризации также близок к количеству строк в таблице.
Теперь для тестов; сначала предикаты равенства:
SQL> set autot trace SQL> select * from test_normal where sal=&sal; Enter value for sal: 1869 old 1: select * from test_normal where sal=&sal new 1: select * from test_normal where sal=1869
164 rows selected. Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=169 Card=168 Bytes=4032) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=169 Card=168 Bytes=4032) 2 1 INDEX (RANGE SCAN) OF 'NORMAL_SAL_IDX' (NON-UNIQUE) (Cost=3 Card=168)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 177 consistent gets 0 physical reads 0 redo size 8461 bytes sent via SQL*Net to client 609 bytes received via SQL*Net from client 12 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 164 rows processed
...и затем диапазонные предикаты:
SQL> select * from test_normal where sal between &sal1 and &sal2; Enter value for sal1: 1500 Enter value for sal2: 2000 old 1: select * from test_normal where sal between &sal1 and &sal2 new 1: select * from test_normal where sal between 1500 and 2000
83743 rows selected. Elapsed: 00:00:04.03
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=601 Card=83376 Bytes =2001024) 1 0 TABLE ACCESS (FULL) OF 'TEST_NORMAL' (Cost=601 Card=83376 Bytes=2001024)
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 11778 consistent gets 3891 physical reads 0 redo size 4123553 bytes sent via SQL*Net to client 61901 bytes received via SQL*Net from client 5584 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 83743 rows processed
Когда запросы выполнены для различных наборов значений, результат, как показано ниже, показывает, что число consistent gets и physical reads совпадают.
| BITMAP | SAL (Equality) | B*TREE | Извлечено строк | ||
| consistent gets | physical reads | consistent gets | physical reads | ||
| 165 | 0 | 1869 | 177 | 164 | |
| 169 | 163 | 3548 | 181 | 167 | |
| 174 | 166 | 6500 | 187 | 172 | |
| 75 | 69 | 7000 | 81 | 73 | |
| 177 | 163 | 2500 | 190 | 175 |
| BITMAP | SAL (Range) | B*TREE | Извлечено строк | ||
| consistent gets | physical reads | consistent gets | physical reads | ||
| 11778 | 5850 | 1500-2000 | 11778 | 3891 | 83743 |
| 11765 | 5468 | 2000-2500 | 11765 | 3879 | 83328 |
| 11753 | 5471 | 2500-3000 | 11753 | 3884 | 83318 |
| 17309 | 5472 | 3000-4000 | 17309 | 3892 | 166999 |
| 39398 | 5454 | 4000-7000 | 39398 | 3973 | 500520 |
Для диапазонных предикатов оптимизатор предпочитает full scan таблицы для всех различных наборов значений — он не использует индексы вообще — в то время как для предикатов равенства оптимизатор использует индексы. И опять количество consistent gets и physical reads совпадает.
Поэтому можно сделать вывод, что для столбца с нормальной селективностью решения оптимизатора для двух типов индексов были одинаковые и нет существенных различий между вводом/выводом
добавление столбца GENDER)
Перед выполнением теста в отношении столбца с низкой селективностью, давайте добавим столбец GENDER в эту таблицу и выполним для него update со значениями M, F, и null. SQL> alter table test_normal add GENDER varchar2(1); Table altered.
SQL> select GENDER, count(*) from test_normal group by GENDER;
S COUNT(*) - ---------- F 333769 M 499921 166310
3 rows selected.
Размер bitmap-индекса по этому столбцу примерно 570KB, как показано ниже:
SQL> create bitmap index normal_GENDER_bmx on test_normal(GENDER); Index created. Elapsed: 00:00:02.08
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3 where segment_name in ('TEST_NORMAL','NORMAL_GENDER_BMX');
SEGMENT_NAME Size in MB ------------------------------ --------------- TEST_NORMAL 50 NORMAL_GENDER_BMX .5625
2 rows selected.
С другой стороны, B*tree индекс на этот столбец имеет размер 13MB, который намного больше, чем bitmap-индекс на этот столбец.
SQL> create index normal_GENDER_idx on test_normal(GENDER); Index created.
SQL> select substr(segment_name,1,30) segment_name, bytes/1024/1024 "Size in MB" 2 from user_segments 3 where segment_name in ('TEST_NORMAL','NORMAL_GENDER_IDX');
SEGMENT_NAME Size in MB ------------------------------ --------------- TEST_NORMAL 50 NORMAL_GENDER_IDX 13
2 rows selected.
Теперь, если выполнить запрос с предикатом равенства, оптимизатор не будет использовать индекс, ни bitmap, ни B*tree. А предпочтет full scan по таблице.
SQL> select * from test_normal where GENDER is null; 166310 rows selected. Elapsed: 00:00:06.08
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=601 Card=166310 Bytes=4157750) 1 0 TABLE ACCESS (FULL) OF 'TEST_NORMAL' (Cost=601 Card=166310 Bytes=4157750)
SQL> select * from test_normal where GENDER='M';
499921 rows selected.
Elapsed: 00:00:16.07
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=601 Card=499921 Bytes=12498025) 1 0 TABLE ACCESS (FULL) OF 'TEST_NORMAL' (Cost=601 Card=499921Bytes=12498025)
SQL>select * from test_normal where GENDER='F' /
333769 rows selected.
Elapsed: 00:00:12.02
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=601 Card=333769 Byte s=8344225) 1 0 TABLE ACCESS (FULL) OF 'TEST_NORMAL' (Cost=601 Card=333769 Bytes=8344225)
Сравнение индексов
Среди недостатков bitmap-индекса для уникального столбца есть потребность в достаточно большом пространстве (и поэтому Oracle не рекомендует его). Однако, размер bitmap-индекса зависит от селективности столбца, на котором он построен, а также от распределения данных. Поэтому bitmap-индекс на столбец ПОЛ будет меньше, чем B*tree-индекс на тот же самый столбец. С другой стороны, bitmap-индекс для EMPNO (кандидат в первичные ключи) будет намного больше, чем B*tree-индекс на этот же столбец. Однако, так как к системам поддержки принятия решений (decision-support systems - DSS) имеют доступ меньшее число пользователей, чем к системам обработки транзакций (transaction-processing systems - OLTP), то ресурсы – это не проблема для этих приложений.
Для иллюстрации этого, я создал две таблицы, TEST_NORMAL и TEST_RANDOM. В таблицу TEST_NORMAL добавил миллион строк с помощью PL/SQL-блока, а затем эти строки вставил в таблицу TEST_RANDOM в произвольном порядке:
Create table test_normal (empno number(10), ename varchar2(30), sal number(10));
Begin For i in 1..1000000 Loop Insert into test_normal values(i, dbms_random.string('U',30), dbms_random.value(1000,7000)); If mod(i, 10000) = 0 then Commit; End if; End loop; End; /
Create table test_random as select /*+ append */ * from test_normal order by dbms_random.random;
SQL> select count(*) "Total Rows" from test_normal;
Total Rows ---------- 1000000
Elapsed: 00:00:01.09
SQL> select count(distinct empno) "Distinct Values" from test_normal;
Distinct Values --------------- 1000000
Elapsed: 00:00:06.09 SQL> select count(*) "Total Rows" from test_random;
Total Rows ---------- 1000000
Elapsed: 00:00:03.05 SQL> select count(distinct empno) "Distinct Values" from test_random;
Distinct Values --------------- 1000000
Elapsed: 00:00:12.07
Заметьте, что таблица TEST_NORMAL заполнена последовательно, а таблица TEST_RANDOM создана с произвольным порядком записей и поэтому содержит неорганизованные данные. В этой таблице столбец EMPNO имеет 100% различных значений и является хорошим кандидатом в первичные ключи. Если определить этот столбец как первичный ключ, будет создан B*tree-индекс, а не bitmap-индекс, потому что Oracle не поддерживает bitmap-индексы для первичных ключей.
Чтобы проанализировать поведение этих индексов, выполним следующие шаги:
Для TEST_NORMAL:
Создаем bitmap-индекс для столбца EMPNO и выполняем несколько запросов с предикатом равенства. Создаем B* tree индекс для столбца EMPNO, выполняем несколько запросов с предикатом равенства и сравниваем операции логического и физического ввода/вывода этих запросов, выполняемые для извлечения результатов для этих наборов значений.
Для TEST_RANDOM:
То же самое что и Шаг 1A. То же самое что и Шаг 1B.
Для TEST_NORMAL:
То же самое что и Шаг 1A, только запросы выполняем с диапазоном предикатов. То же самое что и Шаг 1B, только запросы выполняем с диапазоном предикатов. Сравниваем статистику.
Для TEST_RANDOM:
То же самое что и Шаг 3A. То же самое что и Шаг 3B.
Для TEST_NORMAL:
Создаем bitmap-индекс для столбца SAL, и затем выполняем несколько запросов с предикатом равенства и несколько с диапазонным предикатом. Создаем B*tree индекс для столбца SAL, и затем выполняем несколько запросов с предикатом равенства и несколько с диапазонным предикатом (тот же набор значений, как на Шаге 5A). Сравниваем операции ввода/вывода запросов, выполняемые для извлечения результатов.
Добавляем столбец GENDER в обе таблицы, и выполним update этого столбца, установив три возможных значения: M для мужского пола, F для женского пола, и null, если пол не задан. Значения этого столбца устанавливаются по одному и тому же условию. Создаем bitmap-индекс для этого столбца, и затем выполняем несколько запросов с предикатом равенства. Создаем B*tree индекс для столбца GENDER, и затем выполняем несколько запросов с предикатом равенства. Сравниваем результаты с Шагом 7.
Шаги с 1 по 4 выполняются для столбца с высокой селективностью (100% различных значений), Шаг 5 для столбца со средней селективностью, а Шаги 7 и 8 с низкой селективностью.
когда мы поняли, как оптимизатор
Теперь, когда мы поняли, как оптимизатор реагирует на эти технические приемы, давайте проверим сценарий, который подробно демонстрирует наилучшее применение bitmap- и B*tree индексов.
Наряду с bitmap-индексом по столбцу GENDER, создадим еще один bitmap-индекс на столбец SAL и затем выполним несколько запросов. Запросы будут выполнены и с B*tree индексами на эти столбцы.
Из таблицы TEST_NORMAL потребуются номера сотрудников мужского пола, ежемесячная зарплата которых равна одному из следующих значений: 1000 1500 2000 2500 3000 3500 4000 4500
Итак:
SQL>select * from test_normal where sal in (1000,1500,2000,2500,3000,3500,4000,4500,5000) and GENDER='M';
Это обычный запрос к хранилищу данных, который, конечно, никогда не следует выполнять в OLTP-системе. Ниже показан результат с bitmap-индексом по обоим столбцам:
SQL>select * from test_normal where sal in (1000,1500,2000,2500,3000,3500,4000,4500,5000) and GENDER='M'; 1453 rows selected. Elapsed: 00:00:02.03
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=198 Card=754 Bytes=18850) 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'TEST_NORMAL' (Cost=198 Card=754 Bytes=18850) 2 1 BITMAP CONVERSION (TO ROWIDS) 3 2 BITMAP AND 4 3 BITMAP OR 5 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 6 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 7 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 8 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 9 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 10 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 11 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 12 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 13 4 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_SAL_BMX' 14 3 BITMAP INDEX (SINGLE VALUE) OF 'NORMAL_GENDER_BMX'
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 1353 consistent gets 920 physical reads 0 redo size 75604 bytes sent via SQL*Net to client 1555 bytes received via SQL*Net from client 98 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1453 rows processed
С другой стороны, B* tree индексы хорошо применимы для OLTP-приложений, в которых пользовательские запросы достаточно сложны (и хорошо оптимизированы перед промышленным применением), в отличие от ad hoc запросов, которые не такие частые и выполняются во время непиковых нагрузок. Так как данные часто обновляются и удаляются из OLTP-приложений, bitmap-индексы могут повлечь серьезные проблемы блокировки.
Данные, представленные здесь, достаточно прозрачны. Оба индекса имеют похожее назначение: возвратить результаты как можно быстрее. Однако ваш выбор, какой из них использовать, должен зависеть исключительно от типа приложения, а не от уровня селективности.
Вивек Шарма (vivek.l.sharma@accenture.com или vlsharma@hotmail.com) - Старший Oracle DBA индийской компании Accenture в Мумбае. Он имеет шестилетний опыт в технологиях Oracle и имеет статус Oracle Certified Professional. Вивек специализируется на настройке производительности и оптимизации SQL-PL/SQL.
Блокируются ли таблицы при работе с индексами на основе битовых карт?
Обратившись к рис. 2, можно увидеть, что запись индекса на основе B*-дерева
состоит из набора флагов, байта блокировки, и (в данном случае) двух столбцов данных. Эти два столбца, на самом деле, - проиндексированное значение и идентификатор строки, причем, для каждой строки в таблице имеется запись этого вида в индексе. (Если бы индекс был уникальным, содержимое каждой записи было бы таким же, но расположение немного отличалось бы).
В индексе на основе битовых карт каждая запись состоит из набора флагов, байта блокировки и (в данном случае) четырех столбцов данных. Эти четыре столбца, на самом деле, - проиндексированное значение, пара идентфикаторов строк и поток битов. Пара идентификаторов строк задает непрерывную часть таблицы, а поток битов говорит, какие строки в этом диапазоне идентификаторов строк содержат соответсвтующее значение.
Посмотрите, однако, на размер потока битов, - длина столбца в представленном примере составляет 3521 байт, или около 27000 битов. Около 12% составляют накладные расходы на контрольные суммы и т.п., поэтому эта запись может покрыть порядка 24000 строк таблицы. Но на всю запись имеется только один байт блокировки, тем самым, одна блокировка будет влиять на 24000 строк таблицы.
Вот откуда происходит сомнительное утверждение о блокировании всей таблицы, - если кажется, что изменение столбца ключа индекса на основе битовых карт вызывает блокирование всей таблицы, значит, вы экспериментировали со слишком маленькими таблицами.
Одна блокировка битовой карты может затрагивать тысячи строк, что, несомненно, плохо, но вся таблица не блокируется.
Что такое индекс на основе битовой карты?
Индексы создаются, чтобы сервер Oracle мог максимально эффективно находить запрошенные строки. Индексы на основе битовых карт - не исключение, однако стратегия, лежащая в основе этих индексов, очень отличается от стратегии, на которой базируются индексы на основе B*-дерева. Чтобы продемонстрировать это, мы начнем с изучения содержимого нескольких блоков.
Рассмотрим SQL-сценарий на рис. 1.
create table t1 nologging as select rownum id, mod(rownum,10) btree_col, mod(rownum,10) bitmap_col, rpad('x',200) padding from all_objects where rownum
Рисунок 1. Пример данных.
Обратите внимание, что столбцы btree_col и bitmap_col заданы так, что содержат идентичные данные, - числа от 0 до 9, повторяющиеся циклически.
В базе данных версии 9.2 с размером блока 8 Кбайт результирующая таблица займет 882 блока. Индекс на основе B*-дерева будет иметь 57 листовых блоков, а индекс на основе битовых карт - 10 листовых блоков.
Фрагмент листового блока индекса на основе B*-дерева
row#538[2016] flag: -----, lock: 0 col 0; len 2; (2): c1 02 col 1; len 6; (6): 00 40 c5 7d 00 09
row#538[2004] flag: -----, lock: 0 col 0; len 2; (2): c1 02 col 1; len 6; (6): 00 40 c5 7d 00 13
Фрагмент листового блока индекса на основе битовых карт
row#2[4495] flag: -----, lock: 0 col 0; len 2; (2): c1 03 col 1; len 6; (6): 00 40 c5 62 00 00 col 2; len 6; (6): 00 40 c7 38 00 1f col 3; len 3521; (3521): cb 02 08 20 80 fa 54 01 04 10 fb 53 20 80 00 02 fc 53 04 10 40 00 01 fa 53 02 08 20 fb 53 40 00 . . .
Рисунок 2. Блоки данных, сброшенные в символьном виде.
Понятно, что индекс на основе битовых карт несколько плотнее упакован, чем индекс на основе B*-дерева. Чтобы увидеть эту упаковку, можно сбросить блоки данных индекса в символьном виде с помощью команд типа:
alter system dump datafile x block y;
Результаты представлены на рис. 2. Учтите, однако, что информация, полученная в результате сброса блока в символьном виде, может иногда приводить к неверным выводам, поскольку часть ее - производная от данных, и порядок следования тоже изменен по отношению к реальному для ясности.
Общеизвестно, что...
Если провести простое исследование понимания разработчиками индексов на основе битовых карт, скорее всего, следующие комментарии окажутся наиболее типичными:
При наличии индексов на основе битовых карт, любое изменение ключевых столбцов в таблице полностью ее блокирует.
Индексы на основе битовых карт хорошо подходят для столбцов с небольшим количеством различных значений.
Доступ по индексам на основе битовых карт эффективнее полного просмотра таблицы, даже если по запросу возвращается существенная часть таблицы.
Третье утверждение, на самом деле, всего лишь следствие (возможно, не проверенное) второго. Причем, все три утверждения попадают в смутную зону между ложью и большим заблуждением.
Конечно, в этих утверждениях есть и небольшая доля правды, - достаточная, чтобы объяснить их происхождение.
Цель этой статьи - разобраться в структуре индексов на основе битовых карт, проверить истинность данных утверждений и попытаться выяснить преимущества индексов на основе битовых карт, а также какой ценой эти преимущества достигаются.
Понимание индексов на основе битовых карт
Джонатан Льюис,
Перевод
Индексы на основе битовых карт - великое благо для некоторых видов приложений, но об их устройстве, использовании и побочных эффектах распространено очень много неверной информации. В этой статье описывается структура индексов на основе битовых карт и делается попытка разъяснить, почему возникли некоторые из наиболее типичных заблуждений, связанных с ними.
Последствия блокировок битовых карт
Мы, однако, не должны останавливаться на этом этапе, поскольку результат очень легко поддается неверной интерпретации. Надо понять, какие действия приводят к установке критического байта блокировки, а также как в точности это влияет на тысячи соответствующих строк.
Можно продолжить исследование с помощью намного меньшей тестовой таблицы (см. Рис. 3). Мы создадим таблицу, а затем будем выполнять различные изменения разных строк этой таблицы.
Тестовые данные:
Создание структур данных для примера
create table t1 (id number, bit_col number);
insert into t1 values(0,1); insert into t1 values(1,1); insert into t1 values(2,2); insert into t1 values(3,3); insert into t1 values(4,4);
create bitmap index t1_bit on t1(bit_col);
Изменение одной строки
update t1 set bit_col = 2 where id = 1;
(0,1) битовая карта "откуда" (1,1) -> (1,2) заблокированная строка (2,2) битовая карта "куда" (3,3) (4,4)
Рисунок 3. Готовимcя к тестированию изменений.
Обратите внимание, что изменен проиндексированный столбец лишь одной строки таблицы. Если сбросить в символьном виде блоки индекса и таблицы, окажется, что байт блокировки установлен для одной строки таблицы, но заблокированы две
секции индекса на основе битовых карт. Это секция для близких строк с текущим значением 1 в проиндексированном столбце (секция, "откуда" убирается строка) и секция для близких строк со значением 2 (секция, "куда" переносится строка). (На самом деле, эти две секции битовых карт скопированы, и обе копии заблокированы).
Теперь осталось разобраться, насколько "агрессивно" блокирует сервер Oracle в данном случае.
Ответ может показаться несколько неожиданным для тех, кто мыслит категориями "индексы на основе битовых карт приводят к блокированию таблицы".
Вполне можно сделать следующие изменения (каждое - в отдельном тесте).
Изменить строку в секции "откуда", если это изменение не затрагивает столбец индекса на основе битовых карт.
update t1 set id = 5 where id = 0;
Изменить строку в секции "куда", если это изменение не затрагивает столбец индекса на основе битовых карт.
update t1 set id = 6 where bit_col = 2;
Эти тесты показывают, что можно изменять строку, входящую в заблокированную секцию битовой карты.
Конечно, конфликты блокирвок возможны, - например, ни один из следующих операторов не сможет изменить заблокированную строку таблицы, но их выполнение вызовет ожидание соответствующим сеансом снятия блокировки "TX" в режиме 4 (разделяемой блокировки)
update t1 set bit_col = 4
where id = 2; -- bit_col = 2
update t1 set bit_col = 2
where id = 3 -- bit_col = 3
Учтите, однако, что для возникновения проблемы необходимо выполнение двух условий. Во-первых, необходимо изменять проиндексированный столбец, а во-вторых, изменяемая строка должна покрываться ранее заблокированной секцией битовой карты, т.е. должна быть "сравнительно близко" от другой, изменяемой в настоящий момент, причем, конфликт может вызывать очень ограниченный набор значений (в нашем примере, 4).
Помните, что вполне можно, в нашем случае, изменять столбец, по которому создан индекс на основе битовых карт, в близкой строке, если ни исходное, ни новое значения не равны 1 или 2. Например:
update t1 set bit_col = 4 where bit_col = 3;
Итак, индексы на основе битовых карт НЕ вызывают блокирование таблицы. Если изменения не затрагивают проиндексированный столбец, наличие индексов на основе битовых карт не вызывает вообще никаких проблем. Даже если проиндексированные столбцы изменяются, можно создать набор не конфликтующих изменений.
Проблемы с битовыми картами
Конечно, при использовании битовых карт возникает ряд проблем, выходящих за рамки конфликтов при изменении.
Помните, что вставки и удаления из таблицы вызывают изменения всех ее индексов. С учетом большого количества строк, покрываемых одной записью индекса на основе битовых карт, при любом количестве одновременных вставок или удалений велика вероятность обращения к одним и тем же секциям индекса и, следовательно, массовых конфликтов доступа.
Более того, даже последовательное выполнение операторов ЯМД, затрагивающих индексы на основе битовых карт, может куда существеннее сказаться на производительности, чем можно было предположить.
Я уже подчеркивал, что простое изменение одной строки обычно приводит к копированию всей соответствующей секции битовой карты. Вернемся к Рис. 1 и вспомним, насколько большой может быть секция битовой карты. В этом примере она была размером 3500 байтов (в Oracle 9 максимальный размер составляет около половины блока). Можно обнаружить, что небольшое изменение данных может очень существенно повлиять на размер любого изменяемого вследствие этого индекса на основе битовых карт.
Может, вам и повезет, но, в общем случае, стоит исходить из предположения, что даже последовательные пакетные изменения будут выполняться эффективнее, если удалить индексы на основе битовых карт перед их выполнением, а затем пересоздать.
Размеры
Размер индексов и возможность максимальной буферизации необходимо, конечно, учитывать при определении стоимости, вот почему часто возникает вопрос, - насколько большим будет индекс на основе битовых карт?
В представленном выше примере я попытался воссоздать наихудший случай, максимально затруднив серверу Oracle получение преимуществ от сжатия.
В худшем случае, размер битовой карты в битах будет составлять:
количество различных возможных значений для столбца * количество строк, которое может поместиться
в блок по мнению сервера Oracle * количество блоков до отметки максимального уровня.
Добавьте около 10 процентов на информацию контрольных сумм и накладные расходы, и поделите на 8, чтобы получить размер в байтах.
К счастью, сервер Oracle позволяет предпринять ряд действий для сокращения размера индекса, наиболее действенным из которых является команда, сообщающая серверу, сколько в точности строк в блоке помещается в худшем случае для данной таблицы:
Alter table XXX minimize records_per_block;
Однако помимо информирования сервера Oracle с помощью этой команды, очень существенное влияние на размер индекса имеет кластеризация данных.
В примере я создал максимально разбросанные данные. Например, столбец town последовательно получает значения от 0 до 30. Если реструктурировать (по сути, отсортировать) данные так, что информация для всех городов с кодом 0 хранится вместе, а затем идется вся информация для городов с кодом 1, размер индекса можно сократить с 40 Мбайт практически до 7 Мбайт.
Это существенное сокращение размера - еще один повод пересмотреть утверждение о "небольшом количестве различных значений". Потенциальная выгода от наличия индекса на основе битовых карт зависит от кластеризации данных (как и потенциальная выгода от наличия индекса на основе B*-дерева, конечно же). При принятии решения о создании индексов на основе битовых карт, не сбрасывайте со счетов столбцы с "большим" количеством различных значений. Если каждое значение встречается "много" раз, и строки для каждого значения в достаточной степени кластеризованы, то индекс на основе битовых карт очень даже подходит. В таблице со 100 миллионами строк столбец, имеющий 10000 различных значений, может оказаться отличным кандидатом для создания по нему индекса на основе битовых карт.
Ссылки
--
Эта статья первоначально была опубликована на сайте , сетевом портале, посвященном проблемам различных СУБД и их решениям.
Джонатан Льюис () - независимый консультант с более чем 15-летним опытом работы с СУБД Oracle. Он специализируется на физическом проектировании баз данных и стратегиях использования возможностей СУБД Oracle, является автором книги "Practical Oracle 8I - Designing Efficient Databases", опубликованной издательсвом Addison-Wesley, а также одним из наиболее широко известных лекторов по Oracle в Великобритании. Подробнее об опубликованных им статьях, презентациях и семинарах можно узнать на сайте , где также поддерживается список ЧаВО The Co-operative Oracle Users' FAQ
по дискуссионным группам Usenet, связанным с СУБД Oracle.
Столбцы с небольшим количеством значений
Часто утверждается, что "индексы на основе битовых карт подходят для столбцов с небольшим количеством значений". Несколько точнее будет формулировка "с небольшим количеством различных значений". В любом случае, речь идет о столбцах, содержащих сравнительно мало различных значений.
Это утверждение, действительно, достаточно верное, - если его соответствующим образом уточнить и разъяснить. К сожалению, многие, в результате, думают, что индекс на основе битовых карт чудесным образом настолько эффективен, что его можно использовать для доступа к большим частям таблицы способом, не считающимся целесообразным при использовании индекса на основе B*-дерева.
Классическим примером применимости индекса на основе битовых карт является экстремальный случай столбца, представляющего пол. В этом столбце может быть всего два значения (или три, если включить требуемое стандартом ISO значение "n/a" - неизвестен). Мы будем чуть менее экстремальны и рассмотрим пример, основанный на странах, образующих Соединенное Королевство: Англия, Ирландия, Шотландия и Уэльс.
Пусть используются блоки размером 8 Кбайт и строки (весьма типичным) размером 200 байтов, что дает 40 строк в блоке. Вставим в таблицу несколько миллионов строк, обеспечив равномерно случайное распределение по странам. Таким образом, в среднем в каждом блоке будет по 10 строк для каждой страны.
Если использовать индекс на основе битовых карт для доступа ко всем строкам по Англии, придется (10 раз) последовательно прочитать каждый блок таблицы. Вне всякого сомнения, эффективнее будет выполнить полный просмотр таблицы, а не использовать такой индекс.
На самом деле, даже если расширить данные так, чтобы они включали информацию по 40 странам, все равно вполне вероятно получить по одной строке в каждом блоке таблицы. Вероятно, когда данные разрастутся до глобального масштаба (скажем, охватят 640 стран, чтобы строка для данной страны встречалась в среднем лишь в каждом 16-ом блоке), может оказаться дешевле обращаться к ним по индексу на основе битовых карт, а не путем полного просмотра таблицы. Но столбец, имеющий 640 различных значений, вряд ли, на первый взгляд, попадает под определение "с небольшим количеством различных значений".
Конечно, описательные выражения типа "небольшой", "маленький", "близкий к нулю" требуют определенного уточнения. Например, близко ли значение 10000 к нулю? Если сравнивать с десятью миллиардами, то да!
Не используйте неопределенные выражения вроде "небольшое количество". В большинстве случаев, при выборе индексов на основе битовых карт необходимо учитывать только два фактора. Во-первых, количество различных блоков в таблице, в которых может находиться типичное значение индекса - это основной фактор выбора отдельного индекса. Изменение структуры индекса с B*-дерева на набор битовых карт не сделает этот индекс в это отношении лучше чудесным образом. Во-вторых, используемый оптимизатором Oracle механизм комбинирования нескольких битовых индексов делает их действительно полезными.
Рассмотрим следующий пример, основанный на данных по примерно 64-миллионному населению Великобритании.
50 миллионов имеет карие глаза
35 миллионов - женщины
17 миллионов - темноволосые
1,8 миллиона живет в районе Бирмингема
1,2 миллиона имеет возраст 25 лет
750000 работает в Лондоне
Каждому критерию отдельно соответствует очень много людей, но сколько кареглазых темноволосых женщин в возрасте 25 лет живет в Бирмингеме и работает в Лондоне? Где-то пару десятков.
create table junk as select rownum id from all_objects where rownum
Рисунок 4. Моделируем население Великобритании.
Отдельный индекс (будь-то на основе B*-дерева или битовых карт) по любому из этих столбцов будет абсолютно бесполезен для выполнения такого запроса к таким данным в СУБД Oracle.
Многостолбцовый индекс на основе B*-дерева по соответствующим шести столбцам может существенно помочь, пока нас не заинтересуют мужчины ростом 180 см. с бородой вместо темноволосых и кареглазых женщин.
Можете поэкспериментировать (см. рис. 4), но понадобиться около 2,0 Гбайт места на диске и пару часов работы процессора с тактовой частотой порядка 500 МГц.
Из-за нехватки места я построил модель поменьше, эмулирующую население порядка 36 миллионов. Время построения и размеры объектов для компьютера с тактовой частотой процессора 600 МГц, ОС Win2000 и сервером Oracle версии 9.2.0.1 представлены в следующей таблице.
|
Объект |
Размер (Мбайт) |
Время построения (мин:сек) |
| T1 | 845 | 16:12 |
| I1 (sex) | 11 | 1:39 |
| I2 (eyes) | 16 | 1:43 |
| I2 (hair) | 37 | 2:17 |
| I4 (town) | 40 | 2:25 |
|
I5 (age) |
42 | 2:28 |
|
I6 (work) |
45 | 2:42 |
Обратите, в частности, внимание на суммарный объем индексов, - 191 Мбайт. Всего лишь один многостолбцовый индекс по тем же шести столбцам (даже с максимальным сжатием) займет минимум 430 Мбайт, а сколько процессорного времени потребуется на его построение, - я вообще не знаю, да и немногие системы позволят построить этот индекс в памяти, поскольку для этого требуется установить параметру sort_area_size значение около 900 Мбайт.
Итак, что же могут дать все эти битовые индексы? Рассмотрим запрос:
select count(facts) from t1 where eyes = 1 and sex = 1 and hair = 1 and town = 15 and age = 25 and work = 40;
На сокращенном наборе данных, который я подготовил, при вводе подсказки, требующей выполнения полного просмотра таблицы, запрос выполнялся одну минуту и 20 секунд (вернув ответ 8). Конечно, при реальном наборе фактических данных таблица была бы существенно больше, как и время выполнения.
При использовании полного шестистолбцового индекса объемом 430 Мбайт этот запрос выполнился бы, вероятно, за время, необходимое для выполнения около 10 физических чтений (один блок таблицы для каждой строки и пару дополнительных блоков индекса), - буквально за доли секунды.
При наличии заданных ранее битовых индексов запрос выполнялся пять секунд. Большая часть этого времени ушла на сканирования диапазонов индексов, требующие физического считывания блоков индекса в память. Фактический план выполнения представлен на рис. 5.
SORT (AGGREGATE) TABLE ACCESS (BY INDEX ROWID) OF T1 BITMAP CONVERSION (TO ROWIDS) BITMAP AND BITMAP INDEX (SINGLE VALUE) OF I6 BITMAP INDEX (SINGLE VALUE) OF I5 BITMAP INDEX (SINGLE VALUE) OF I4
Рисунок 5. План выполнения.
В этом плане выполнения запроса следует отметить два интересных момента. Во-первых, сервер Oracle проигнорировал три "худших" (т.е., наименее избирательных) индекса. Во-вторых, хотя время выполнения - заметное, но размеры индексов настолько малы, что имеет смысл подумать об их размещении в достаточно большом KEEP-пуле, buffer_pool_keep (в Oracle 9 его размер задается параметром db_keep_cache_size), чтобы избежать физических чтений. Этот вариант вряд ли подходит для нескольких многостолбцовых индексов на основе B*-дерева, поддерживающих такие же запросы.
Давайте подумаем о проигнорированных индексах, - в плане может использоваться практически любое количество индексов на основе битовых карт. Я видел случаи, когда сервер Oracle использовал более пяти таких индексов (это предел для способа доступа and_equal при использовании одностолбцовых индексов на основе B*-дерева).
Три оставшихся индекса были проигнорированы не из-за какого-то искусственного ограничения. Стоимостной оптимизатор сравнил стоимость чтения каждого дополнительного индекса с достигаемой дополнительной точностью, и не выбрал их. Так что, индексы на основе битовых карт по классическому столбцу (пол) обычно игнорируются, несмотря на противоположные утверждения. (Удалите конструкцию work = 40 из запроса и убедитесь, что индекс по столбцу sex в этом случае используется).
Конечно, такие индексы на основе битовых карт можно построить очень быстро, и места они займут немного, так что их можно создавать просто на всякий случай.
Об индексах на основе битовых
Об индексах на основе битовых карт есть несколько существенно ошибочных представлений. Некоторые из них могут приводить к отказу от использования этих индексов, когда они могут существенно помочь. Другие приводят к созданию абсолютно бесполезных битовых индексов.
К счастью, сделать серьезные ошибки при работе с индексами на основе битовых карт достаточно сложно. Но хорошее понимание того, как работает с ними сервер Oracle поможет получить от них максимальную пользу.
Надо запомнить следующие ключевые факты:
Если индекс на основе B*-дерева не является эффективным механизмом доступа к данным, маловероятно, что он станет намного эффективнее, если создавать индекс на основе битовых карт.
Индексы на основе битовых карт обычно создаются быстрее и могут занимать удивительно мало места.
Размер индекса на основе битовых карт существенно зависит от распределения данных.
Индексы на основе битовых карт обычно выбираются стоимостным оптимизатором, если для выполнения запроса можно использовать несколько таких индексов.
Изменения столбцов, входящих в индексы на основе битовых карт, а также вставки и удаления данных могут вызывать существенные конфликты блокировок.
Изменения столбцов, входящих в индексы на основе битовых карт, а также вставки и удаления данных могут весьма существенно "ухудшать" индексы.
Помните также, что оптимизатор улучшается в каждой версии Oracle. Граница между механизмами для индексов на основе B*-дерева и битовых карт существенно размывается за счет развития технологий сжатия индексов, просмотра индексов с пропуском (index skip scans), а также преобразования деревьев в битовые карты.
Блокируются ли таблицы при работе с индексами на основе битовых карт?
Обратившись к рис. 2, можно увидеть, что запись индекса на основе B*-дерева состоит из набора флагов, байта блокировки, и (в данном случае) двух столбцов данных. Эти два столбца, на самом деле, - проиндексированное значение и идентификатор строки, причем, для каждой строки в таблице имеется запись этого вида в индексе. (Если бы индекс был уникальным, содержимое каждой записи было бы таким же, но расположение немного отличалось бы).
В индексе на основе битовых карт каждая запись состоит из набора флагов, байта блокировки и (в данном случае) четырех столбцов данных. Эти четыре столбца, на самом деле, - проиндексированное значение, пара идентфикаторов строк и поток битов. Пара идентификаторов строк задает непрерывную часть таблицы, а поток битов говорит, какие строки в этом диапазоне идентификаторов строк содержат соответсвтующее значение.
Посмотрите, однако, на размер потока битов, - длина столбца в представленном примере составляет 3521 байт, или около 27000 битов. Около 12% составляют накладные расходы на контрольные суммы и т.п., поэтому эта запись может покрыть порядка 24000 строк таблицы. Но на всю запись имеется только один байт блокировки, тем самым, одна блокировка будет влиять на 24000 строк таблицы.
Вот откуда происходит сомнительное утверждение о блокировании всей таблицы, - если кажется, что изменение столбца ключа индекса на основе битовых карт вызывает блокирование всей таблицы, значит, вы экспериментировали со слишком маленькими таблицами.
Одна блокировка битовой карты может затрагивать тысячи строк, что, несомненно, плохо, но вся таблица не блокируется.
Что такое индекс на основе битовой карты?
Индексы создаются, чтобы сервер Oracle мог максимально эффективно находить запрошенные строки. Индексы на основе битовых карт - не исключение, однако стратегия, лежащая в основе этих индексов, очень отличается от стратегии, на которой базируются индексы на основе B*-дерева. Чтобы продемонстрировать это, мы начнем с изучения содержимого нескольких блоков.
Рассмотрим SQL-сценарий на рис. 1.
create table t1 nologging as select rownum id, mod(rownum,10) btree_col, mod(rownum,10) bitmap_col, rpad('x',200) padding from all_objects where rownum <= 30000;
create index t1_btree on t1(btree_col);
create bitmap index t1_bit on t1(bitmap_col);
Рисунок 1. Пример данных.
Обратите внимание, что столбцы btree_col и bitmap_col заданы так, что содержат идентичные данные, - числа от 0 до 9, повторяющиеся циклически.
В базе данных версии 9.2 с размером блока 8 Кбайт результирующая таблица займет 882 блока. Индекс на основе B*-дерева будет иметь 57 листовых блоков, а индекс на основе битовых карт - 10 листовых блоков. Фрагмент листового блока индекса на основе B*-дерева row#538[2016] flag: -----, lock: 0 col 0; len 2; (2): c1 02 col 1; len 6; (6): 00 40 c5 7d 00 09
row#538[2004] flag: -----, lock: 0 col 0; len 2; (2): c1 02 col 1; len 6; (6): 00 40 c5 7d 00 13
Фрагмент листового блока индекса на основе битовых карт row#2[4495] flag: -----, lock: 0 col 0; len 2; (2): c1 03 col 1; len 6; (6): 00 40 c5 62 00 00 col 2; len 6; (6): 00 40 c7 38 00 1f col 3; len 3521; (3521): cb 02 08 20 80 fa 54 01 04 10 fb 53 20 80 00 02 fc 53 04 10 40 00 01 fa 53 02 08 20 fb 53 40 00 . . .
Рисунок 2. Блоки данных, сброшенные в символьном виде.
Понятно, что индекс на основе битовых карт несколько плотнее упакован, чем индекс на основе B*-дерева. Чтобы увидеть эту упаковку, можно сбросить блоки данных индекса в символьном виде с помощью команд типа:
alter system dump datafile x block y;
Результаты представлены на рис. 2. Учтите, однако, что информация, полученная в результате сброса блока в символьном виде, может иногда приводить к неверным выводам, поскольку часть ее - производная от данных, и порядок следования тоже изменен по отношению к реальному для ясности.
Общеизвестно, что...
Если провести простое исследование понимания разработчиками индексов на основе битовых карт, скорее всего, следующие комментарии окажутся наиболее типичными:
При наличии индексов на основе битовых карт, любое изменение ключевых столбцов в таблице полностью ее блокирует. Индексы на основе битовых карт хорошо подходят для столбцов с небольшим количеством различных значений. Доступ по индексам на основе битовых карт эффективнее полного просмотра таблицы, даже если по запросу возвращается существенная часть таблицы.
Третье утверждение, на самом деле, всего лишь следствие (возможно, не проверенное) второго. Причем, все три утверждения попадают в смутную зону между ложью и большим заблуждением.
Конечно, в этих утверждениях есть и небольшая доля правды, - достаточная, чтобы объяснить их происхождение.
Цель этой статьи - разобраться в структуре индексов на основе битовых карт, проверить истинность данных утверждений и попытаться выяснить преимущества индексов на основе битовых карт, а также какой ценой эти преимущества достигаются.
Последствия блокировок битовых карт
Мы, однако, не должны останавливаться на этом этапе, поскольку результат очень легко поддается неверной интерпретации. Надо понять, какие действия приводят к установке критического байта блокировки, а также как в точности это влияет на тысячи соответствующих строк.
Можно продолжить исследование с помощью намного меньшей тестовой таблицы (см. Рис. 3). Мы создадим таблицу, а затем будем выполнять различные изменения разных строк этой таблицы.
Тестовые данные: Создание структур данных для примера create table t1 (id number, bit_col number);
insert into t1 values(0,1); insert into t1 values(1,1); insert into t1 values(2,2); insert into t1 values(3,3); insert into t1 values(4,4);
create bitmap index t1_bit on t1(bit_col);
Изменение одной строки update t1 set bit_col = 2 where id = 1;
(0,1) битовая карта "откуда" (1,1) -> (1,2) заблокированная строка (2,2) битовая карта "куда" (3,3) (4,4)
Рисунок 3. Готовимcя к тестированию изменений.
Обратите внимание, что изменен проиндексированный столбец лишь одной строки таблицы. Если сбросить в символьном виде блоки индекса и таблицы, окажется, что байт блокировки установлен для одной строки таблицы, но заблокированы две секции индекса на основе битовых карт. Это секция для близких строк с текущим значением 1 в проиндексированном столбце (секция, "откуда" убирается строка) и секция для близких строк со значением 2 (секция, "куда" переносится строка). (На самом деле, эти две секции битовых карт скопированы, и обе копии заблокированы).
Теперь осталось разобраться, насколько "агрессивно" блокирует сервер Oracle в данном случае.
Ответ может показаться несколько неожиданным для тех, кто мыслит категориями "индексы на основе битовых карт приводят к блокированию таблицы".
Вполне можно сделать следующие изменения (каждое - в отдельном тесте).
Изменить строку в секции "откуда", если это изменение не затрагивает столбец индекса на основе битовых карт.
update t1 set id = 5 where id = 0;
Изменить строку в секции "куда", если это изменение не затрагивает столбец индекса на основе битовых карт.
update t1 set id = 6 where bit_col = 2;
Эти тесты показывают, что можно изменять строку, входящую в заблокированную секцию битовой карты.
Конечно, конфликты блокирвок возможны, - например, ни один из следующих операторов не сможет изменить заблокированную строку таблицы, но их выполнение вызовет ожидание соответствующим сеансом снятия блокировки "TX" в режиме 4 (разделяемой блокировки)
update t1 set bit_col = 4
where id = 2; -- bit_col = 2
update t1 set bit_col = 2
where id = 3 -- bit_col = 3
Учтите, однако, что для возникновения проблемы необходимо выполнение двух условий. Во-первых, необходимо изменять проиндексированный столбец, а во-вторых, изменяемая строка должна покрываться ранее заблокированной секцией битовой карты, т.е. должна быть "сравнительно близко" от другой, изменяемой в настоящий момент, причем, конфликт может вызывать очень ограниченный набор значений (в нашем примере, 4).
Помните, что вполне можно, в нашем случае, изменять столбец, по которому создан индекс на основе битовых карт, в близкой строке, если ни исходное, ни новое значения не равны 1 или 2. Например:
update t1 set bit_col = 4 where bit_col = 3;
Итак, индексы на основе битовых карт НЕ вызывают блокирование таблицы. Если изменения не затрагивают проиндексированный столбец, наличие индексов на основе битовых карт не вызывает вообще никаких проблем. Даже если проиндексированные столбцы изменяются, можно создать набор не конфликтующих изменений.
Проблемы с битовыми картами
Конечно, при использовании битовых карт возникает ряд проблем, выходящих за рамки конфликтов при изменении.
Помните, что вставки и удаления из таблицы вызывают изменения всех ее индексов. С учетом большого количества строк, покрываемых одной записью индекса на основе битовых карт, при любом количестве одновременных вставок или удалений велика вероятность обращения к одним и тем же секциям индекса и, следовательно, массовых конфликтов доступа.
Более того, даже последовательное выполнение операторов ЯМД, затрагивающих индексы на основе битовых карт, может куда существеннее сказаться на производительности, чем можно было предположить.
Я уже подчеркивал, что простое изменение одной строки обычно приводит к копированию всей соответствующей секции битовой карты. Вернемся к Рис. 1 и вспомним, насколько большой может быть секция битовой карты. В этом примере она была размером 3500 байтов (в Oracle 9 максимальный размер составляет около половины блока). Можно обнаружить, что небольшое изменение данных может очень существенно повлиять на размер любого изменяемого вследствие этого индекса на основе битовых карт.
Может, вам и повезет, но, в общем случае, стоит исходить из предположения, что даже последовательные пакетные изменения будут выполняться эффективнее, если удалить индексы на основе битовых карт перед их выполнением, а затем пересоздать.
Разбираемся с индексами на основе битовых карт
Джонатан Льюис (Jonathan Lewis)
Перевод: , OpenXS Initiative
Индексы на основе битовых карт - великое благо для некоторых видов приложений, но об их устройстве, использовании и побочных эффектах распространено очень много неверной информации. В этой статье описывается структура индексов на основе битовых карт и делается попытка разъяснить, почему возникли некоторые из наиболее типичных заблуждений, связанных с ними.
Размеры
Размер индексов и возможность максимальной буферизации необходимо, конечно, учитывать при определении стоимости, вот почему часто возникает вопрос, - насколько большим будет индекс на основе битовых карт?
В представленном выше примере я попытался воссоздать наихудший случай, максимально затруднив серверу Oracle получение преимуществ от сжатия.
В худшем случае, размер битовой карты в битах будет составлять: количество различных возможных значений для столбца * количество строк, которое может поместиться в блок по
мнению сервера Oracle * количество блоков до отметки максимального уровня.
Добавьте около 10 процентов на информацию контрольных сумм и накладные расходы, и поделите на 8, чтобы получить размер в байтах.
К счастью, сервер Oracle позволяет предпринять ряд действий для сокращения размера индекса, наиболее действенным из которых является команда, сообщающая серверу, сколько в точности строк в блоке помещается в худшем случае для данной таблицы: Alter table XXX minimize records_per_block;
Однако помимо информирования сервера Oracle с помощью этой команды, очень существенное влияние на размер индекса имеет кластеризация данных.
В примере я создал максимально разбросанные данные. Например, столбец town последовательно получает значения от 0 до 30. Если реструктурировать (по сути, отсортировать) данные так, что информация для всех городов с кодом 0 хранится вместе, а затем идется вся информация для городов с кодом 1, размер индекса можно сократить с 40 Мбайт практически до 7 Мбайт.
Это существенное сокращение размера - еще один повод пересмотреть утверждение о "небольшом количестве различных значений". Потенциальная выгода от наличия индекса на основе битовых карт зависит от кластеризации данных (как и потенциальная выгода от наличия индекса на основе B*-дерева, конечно же). При принятии решения о создании индексов на основе битовых карт, не сбрасывайте со счетов столбцы с "большим" количеством различных значений. Если каждое значение встречается "много" раз, и строки для каждого значения в достаточной степени кластеризованы, то индекс на основе битовых карт очень даже подходит. В таблице со 100 миллионами строк столбец, имеющий 10000 различных значений, может оказаться отличным кандидатом для создания по нему индекса на основе битовых карт.
Столбцы с небольшим количеством значений
Часто утверждается, что "индексы на основе битовых карт подходят для столбцов с небольшим количеством значений". Несколько точнее будет формулировка "с небольшим количеством различных значений". В любом случае, речь идет о столбцах, содержащих сравнительно мало различных значений.
Это утверждение, действительно, достаточно верное, - если его соответствующим образом уточнить и разъяснить. К сожалению, многие, в результате, думают, что индекс на основе битовых карт чудесным образом настолько эффективен, что его можно использовать для доступа к большим частям таблицы способом, не считающимся целесообразным при использовании индекса на основе B*-дерева.
Классическим примером применимости индекса на основе битовых карт является экстремальный случай столбца, представляющего пол. В этом столбце может быть всего два значения (или три, если включить требуемое стандартом ISO значение "n/a" - неизвестен). Мы будем чуть менее экстремальны и рассмотрим пример, основанный на странах, образующих Соединенное Королевство: Англия, Ирландия, Шотландия и Уэльс.
Пусть используются блоки размером 8 Кбайт и строки (весьма типичным) размером 200 байтов, что дает 40 строк в блоке. Вставим в таблицу несколько миллионов строк, обеспечив равномерно случайное распределение по странам. Таким образом, в среднем в каждом блоке будет по 10 строк для каждой страны.
Если использовать индекс на основе битовых карт для доступа ко всем строкам по Англии, придется (10 раз) последовательно прочитать каждый блок таблицы. Вне всякого сомнения, эффективнее будет выполнить полный просмотр таблицы, а не использовать такой индекс.
На самом деле, даже если расширить данные так, чтобы они включали информацию по 40 странам, все равно вполне вероятно получить по одной строке в каждом блоке таблицы. Вероятно, когда данные разрастутся до глобального масштаба (скажем, охватят 640 стран, чтобы строка для данной страны встречалась в среднем лишь в каждом 16-ом блоке), может оказаться дешевле обращаться к ним по индексу на основе битовых карт, а не путем полного просмотра таблицы. Но столбец, имеющий 640 различных значений, вряд ли, на первый взгляд, попадает под определение "с небольшим количеством различных значений".
Конечно, описательные выражения типа "небольшой", "маленький", "близкий к нулю" требуют определенного уточнения. Например, близко ли значение 10000 к нулю? Если сравнивать с десятью миллиардами, то да!
Не используйте неопределенные выражения вроде "небольшое количество". В большинстве случаев, при выборе индексов на основе битовых карт необходимо учитывать только два фактора. Во-первых, количество различных блоков в таблице, в которых может находиться типичное значение индекса - это основной фактор выбора отдельного индекса. Изменение структуры индекса с B*-дерева на набор битовых карт не сделает этот индекс в это отношении лучше чудесным образом. Во-вторых, используемый оптимизатором Oracle механизм комбинирования нескольких битовых индексов делает их действительно полезными.
Рассмотрим следующий пример, основанный на данных по примерно 64-миллионному населению Великобритании.
50 миллионов имеет карие глаза 35 миллионов - женщины 17 миллионов - темноволосые 1,8 миллиона живет в районе Бирмингема 1, 2 миллиона имеет возраст 25 лет 750000 работает в Лондоне
Каждому критерию отдельно соответствует очень много людей, но сколько кареглазых темноволосых женщин в возрасте 25 лет живет в Бирмингеме и работает в Лондоне? Где-то пару десятков.
create table junk as select rownum id from all_objects where rownum <= 8000;
create table t1 nologging pctfree 0 as select /*+ ordered use_nl(v2) */ 'x' facts, mod(rownum,2) sex, mod(rownum,3) eyes, mod(rownum,7) hair, mod(rownum,31) town, mod(rownum,47) age, mod(rownum,79) work, from junk v1, junk v2;
create bitmap index i1 on t1(sex) nologging pctfree 0;
create bitmap index i2 on t1(eyes) nologging pctfree 0;
create bitmap index i3 on t1(hair) nologging pctfree 0;
create bitmap index i4 on t1(town) nologging pctfree 0;
create bitmap index i5 on t1(age) nologging pctfree 0;
create bitmap index i6 on t1(work) nologging pctfree 0;
analyze table t1 estimate statistics;
Рисунок 4. Моделируем население Великобритании.
Отдельный индекс (будь-то на основе B*-дерева или битовых карт) по любому из этих столбцов будет абсолютно бесполезен для выполнения такого запроса к таким данным в СУБД Oracle.
Многостолбцовый индекс на основе B*-дерева по соответствующим шести столбцам может существенно помочь, пока нас не заинтересуют мужчины ростом 180 см. с бородой вместо темноволосых и кареглазых женщин.
Можете поэкспериментировать (см. рис. 4), но понадобиться около 2,0 Гбайт места на диске и пару часов работы процессора с тактовой частотой порядка 500 МГц.
Из-за нехватки места я построил модель поменьше, эмулирующую население порядка 36 миллионов. Время построения и размеры объектов для компьютера с тактовой частотой процессора 600 МГц, ОС Win2000 и сервером Oracle версии 9.2.0.1 представлены в следующей таблице.
| Объект | Размер (Мбайт) | Время построения (мин:сек) |
| T1 | 845 | 16:12 |
| I1 (sex) | 11 | 1:39 |
| I2 (eyes) | 16 | 1:43 |
| I2 (hair) | 37 | 2:17 |
| I4 (town) | 40 | 2:25 |
| I5 (age) | 42 | 2:28 |
| I6 (work) | 45 | 2:42 |
Об индексах на основе битовых
Об индексах на основе битовых карт есть несколько существенно ошибочных представлений. Некоторые из них могут приводить к отказу от использования этих индексов, когда они могут существенно помочь. Другие приводят к созданию абсолютно бесполезных битовых индексов.
К счастью, сделать серьезные ошибки при работе с индексами на основе битовых карт достаточно сложно. Но хорошее понимание того, как работает с ними сервер Oracle поможет получить от них максимальную пользу.
Надо запомнить следующие ключевые факты:
Если индекс на основе B*-дерева не является эффективным механизмом доступа к данным, маловероятно, что он станет намного эффективнее, если создавать индекс на основе битовых карт. Индексы на основе битовых карт обычно создаются быстрее и могут занимать удивительно мало места. Размер индекса на основе битовых карт существенно зависит от распределения данных. Индексы на основе битовых карт обычно выбираются стоимостным оптимизатором, если для выполнения запроса можно использовать несколько таких индексов. Изменения столбцов, входящих в индексы на основе битовых карт, а также вставки и удаления данных могут вызывать существенные конфликты блокировок. Изменения столбцов, входящих в индексы на основе битовых карт, а также вставки и удаления данных могут весьма существенно "ухудшать" индексы.
Помните также, что оптимизатор улучшается в каждой версии Oracle. Граница между механизмами для индексов на основе B*-дерева и битовых карт существенно размывается за счет развития технологий сжатия индексов, просмотра индексов с пропуском (index skip scans), а также преобразования деревьев в битовые карты.
*Сылки:
Кэш результатов PL/SQL функций
Предположим, что вместо SQL-запроса существует PL/SQL-функция, которая возвращает значения. Это обычной прием: использовать функцию для возвращения значения, чтобы сделать код более модульным. Рассмотрим случай двух таблиц: CUSTOMERS, которая хранит информацию обо всех клиентах вместе с state_code. Другая таблица TAX_RATE хранит налоговую ставку каждого штата. Для получения налоговой ставки для клиента необходимо в запросе соединить таблицы. Поэтому, чтобы упростить задачу, можно написать функцию, показанную ниже, которая принимает ID клиента в качестве параметра и возвращает налоговую ставку в зависимости от state_code:
create or replace function get_tax_rate ( p_cust_id customers.cust_id%type ) return sales_tax_rate.tax_rate%type is l_ret sales_tax_rate.tax_rate%type; begin select tax_rate into l_ret from sales_tax_rate t, customers c where c.cust_id = p_cust_id and t.state_code = c.state_code; -- simulate some time consuming -- processing by sleeping for 1 sec dbms_lock.sleep (1); return l_ret; exception when NO_DATA_FOUND then return NULL; when others then raise; end; /
Выполним функцию несколько раз, как показано ниже. Не забудьте установить параметр timing в значение on, чтобы записать время выполнения в каждом случае.
SQL> select get_tax_rate(1) from dual;
GET_TAX_RATE(1) --------------- 6
1 row selected.
Elapsed: 00:00:01.23 SQL> select get_tax_rate(1) from dual;
GET_TAX_RATE(1) --------------- 6
1 row selected.
Elapsed: 00:00:01.17
Последовательно выдается примерно одинаковое время для каждого выполнения. (Я сознательно добавил оператор sleep, чтобы увеличить время выполнения функции; иначе значение бы возвращалось слишком быстро.) Если рассмотреть код, можно заметить, что функция, вероятно, будет возвращать одно и то же значение при каждом вызове. Клиент не часто меняет штат, и налоговая ставка для штата меняется редко, поэтому весьма вероятно, что для данного клиента налоговая ставка будет одинаковой при всех выполнениях функции. Ставка изменится только, если изменится налоговая ставка штата, или клиент переедет в другой штат. Итак, как насчет кэширования результатов этой функции?
База данных Oracle 11g позволяет сделать именно это. Разрешить кэширование результатов функции можно, просто добавив предложение result_cache. Но как насчет случая, когда в штате меняется налоговая ставка или когда клиент переезжает в другой штат? Есть возможность определить зависимость от базовых таблиц, так что любые данные, изменяемые в этих таблицах, будут вызывать недействительность и последующее перестроение кэша результатов функции. Вот та же функция с добавленным предложением result cache (выделено жирным шрифтом):
create or replace function get_tax_rate ( p_cust_id customers.cust_id%type ) return sales_tax_rate.tax_rate%type result_cache relies_on (sales_tax_rate, customers)
is l_ret sales_tax_rate.tax_rate%type; begin select tax_rate into l_ret from sales_tax_rate t, customers c where c.cust_id = p_cust_id and t.state_code = c.state_code; -- simulate some time consuming -- processing by sleeping for 1 sec dbms_lock.sleep (1); return l_ret; exception when NO_DATA_FOUND then return NULL; when others then raise; end; /
После этого изменения создайте и выполните функцию следующим образом:
SQL> select get_tax_rate(1) from dual;
GET_TAX_RATE(1) --------------- 6
1 row selected.
Elapsed: 00:00:01.21
Время выполнения - 1.21 секунды, как и раньше, но давайте посмотрим на следующее выполнение:
SQL> select get_tax_rate(1) from dual;
GET_TAX_RATE(1) --------------- 6
1 row selected.
Elapsed: 00:00:00.01
Время выполнения – всего лишь 0.01 секунды! Что произошло? Функция в первый раз нормально выполнилась за 1.21 секунду. Но важное отличие на этот раз состоит в том, что при её выполнении результат кэшировался. При последующих вызовах функция не выполняется, результат просто берется из кэша. Поэтому нет ожидания в 1 секунду, как это было в коде функции.
Кэширование выполнялось только для клиента с идентификатором (customer_id) равным 1. Что если попытаться выполнить функцию для другого клиента?
SQL> select get_tax_rate(&n) from dual; Enter value for n: 5 old 1: select get_tax_rate(&n) from dual new 1: select get_tax_rate(5) from dual
GET_TAX_RATE(5) --------------- 6
1 row selected.
Elapsed: 00:00:01.18 SQL> / Enter value for n: 5 old 1: select get_tax_rate(&n) from dual new 1: select get_tax_rate(5) from dual
GET_TAX_RATE(5) --------------- 6
1 row selected.
Elapsed: 00:00:00.00 SQL> / Enter value for n: 6 old 1: select get_tax_rate(&n) from dual new 1: select get_tax_rate(6) from dual
GET_TAX_RATE(6) --------------- 6
1 row selected.
Elapsed: 00:00:01.17
Как можно видеть, при первом выполнении с каждым значением параметра результат кэшируется. Последующие вызовы выбирают значение из кэша. Когда вы продолжаете выполнять функцию для каждого клиента, кэш увеличивается.
Обратите внимание на предложение "relies on" в коде функции. Оно говорит функции, что кэш зависит от двух таблиц: customers и tax_rate. Если данные в этих таблицах изменятся, кэш должен быть обновлен. Обновление происходит автоматически без вашего вмешательства. Если данные не менялись, кэш продолжает предоставлять кэшированные значения настолько быстро, насколько это возможно.
Если по каким-то причинам необходимо обойти кэш, можно вызвать процедуру поставляемого пакета DBMS_RESULT_CACHE:
SQL> exec dbms_result_cache.bypass(true);
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.01
SQL> select get_tax_rate(&n) from dual; Enter value for n: 6 old 1: select get_tax_rate(&n) from dual new 1: select get_tax_rate(6) from dual
GET_TAX_RATE(6) --------------- 6
1 row selected.
Elapsed: 00:00:01.18
Как видно из времени выполнения, кэш не использовался.
Кэш результатов SQL
Доступ к памяти намного быстрее, чем доступ к жестким дискам, и это, вероятно, будет иметь место в течение нескольких следующих лет, до тех пор, пока мы не увидим некоторых значительных улучшений в архитектуре жестких дисков. Этот факт дает повод для кэширования: процесса хранения данных в памяти вместо дисков. Кэширование – это общий принцип архитектуры базы данных Oracle, в котором пользователи считывают данные из буфера кэша вместо дисков, на которых располагается база данных.
Преимущества кэширования особенно заметны в случае с относительно маленькими таблицами, имеющими статические данные, например, справочными таблицами, такими как STATES, PRODUCT_CODES и так далее. Рассмотрим, однако, случай большой таблицы CUSTOMERS, которая хранит сведения о клиентах компании. Данные в ней относительно статичные, но не совсем: таблица меняется редко, когда клиенты добавляются или удаляются из списка. Кэширование, вероятно, имело бы здесь некоторый смысл. Но, если таблица будет как-то кэшироваться, как можно быть уверенным, что получишь верные данные, когда что-то изменится? В базе данных Oracle 11g есть ответ: использование кэша результатов SQL (SQL Result Cache). Рассмотрим следующий запрос. Запустим его, чтобы получить статистику выполнения и время отклика.
SQL> set autot on explain stat
select state_code, count(*), min(times_purchased), avg(times_purchased) from customers group by state_code /
Вот результаты:
ST COUNT(*) MIN(TIMES_PURCHASED) AVG(TIMES_PURCHASED) -- ---------- -------------------- -------------------- NJ 1 15 15 NY 994898 0 15.0052086 CT 5099 0 14.9466562 MO 1 25 25 FL 1 3 3
5 rows selected.
Elapsed: 00:00:02.57
Execution Plan ---------------------------------------------------------- Plan hash value: 1577413243
-------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 30 | 1846 (25)| 00:00:23 | | 1 | HASH GROUP BY | | 5 | 30 | 1846 (25)| 00:00:23 | | 2 | TABLE ACCESS FULL| CUSTOMERS | 1000K| 5859K| 1495 (7)| 00:00:18 | --------------------------------------------------------------------------------
Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 5136 consistent gets 5128 physical reads 0 redo size 760 bytes sent via SQL*Net to client 420 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 5 rows processed
Обратим внимание на следующие моменты:
План выполнения показывает, что выполнялся полный просмотр таблицы. Выполнено 5,136 согласованных чтений (consistent gets) (логических операций ввода/вывода).
Время выполнения - 2.57 секунд.
Поскольку таблица почти совсем не меняется, можно использовать подсказку, которая сохранит результаты запроса в кэше памяти: select /*+ result_cache */ state_code, count(*), min(times_purchased), avg(times_purchased) from customers group by state_code /
Запрос идентичен первому за исключением подсказки. Вот результат (второе выполнение этого запроса): ST COUNT(*) MIN(TIMES_PURCHASED) AVG(TIMES_PURCHASED) -- ---------- -------------------- -------------------- NJ 1 15 15 NY 994898 0 15.0052086 CT 5099 0 14.9466562 MO 1 25 25 FL 1 3 3
5 rows selected.
Elapsed: 00:00:00.01
Execution Plan ---------------------------------------------------------- Plan hash value: 1577413243
-------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 5 | 30 | 1846 (25)| 00:00:23 | | 1 | RESULT CACHE | gk69saf6h3ujx525twvvsnaytd | | | | | | 2 | HASH GROUP BY | | 5 | 30 | 1846 (25)| 00:00:23 | | 3 | TABLE ACCESS FULL| CUSTOMERS | 1000K| 5859K| 1495 (7)| 00:00:18 | --------------------------------------------------------------------------------------------------
Result Cache Information (identified by operation id): ------------------------------------------------------
1 - column-count=4; dependencies=(ARUP.CUSTOMERS); parameters=(nls); name="select /*+ result_cache */ state_code, count(*), min(times_purchased), avg(times_purchased) from customers group by state_c"
Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 0 consistent gets 0 physical reads 0 redo size 760 bytes sent via SQL*Net to client 420 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 5 rows processed
Обратите внимание на некоторые отличия от первого запроса:
Время ответа составляет теперь 0.01 секунду вместо почти 3 секунд. Согласованных чтений теперь 0; операции логического ввода/вывода не выполняются для этого запроса. (Действительно, при первом выполнении запроса с подсказкой количество логических операций ввода/вывода останется таким же (как и без подсказки – прим. переводчика), потому что база данных должна выполнить операции ввода/вывода, чтобы построить кэш. Последующие вызовы будут брать данные из кэша, не выполняя логического ввода/вывода). План выполнения (explain plan) показывает операцию RESULT CACHE. Примечание после плана выполнения показывает, какой тип кэширования выполнялся и над каким результатом.
Экономия времени поразительна: от 3 секунд до почти ничего! Это благодаря тому, что второй запрос, в котором мы использовали кэш, возвращает данные непосредственно из памяти базы данных (кэша результатов), а не после выполнения запроса.
Кэш результатов SQL – это новый кэш в SGA, подобный буферному кэшу или программной глобальной области. При выполнении запроса с подсказкой result_cache, Oracle выполняет запрос также как любой другой запрос, но результаты сохраняются в кэше результатов SQL. Последующие вызовы того же самого запроса не обращаются к таблице (или таблицам), а берут результаты из кэша. Размер кэша определяется несколькими параметрами инициализации:
| result_cache_max_size | Максимальный размер кэша (например, 5M для 5 MB). Если установить в 0, кэш результатов будет полностью выключен. |
| result_cache_max_result | пределяет процент от максимального размера кэша (result_cache_max_size), который может использоваться одним запросом. |
| result_cache_mode | Если задано значение FORCE, то все запросы кэшируются, если они умещаются в кэш. Значение по умолчанию MANUAL означает, что кэшируются только запросы с подсказкой. |
| result_cache_remote_expiration | Определяет количество минут, которое результат в кэше, который обращался к удаленному объекту, остается действительным. По умолчанию 0. |
Теперь логичный вопрос: что происходит, когда меняются строки таблицы? Получит ли запрос новое значение или старое? Действительно, давайте посмотрим, что происходит. Из другой сессии SQL*Plus изменим строку таблицы: SQL> update customers set times_purchased = 4 2 where state_code = 'FL';
1 row updated.
но не будем выполнять commit. Из первого окна, в котором мы запускали запрос в первый раз, запустим его снова. Используется еще кэшированный результат, поскольку изменения ещё не зафиксированы. Сессия, которая выполняет запрос, видит все ещё актуальную версию данных, и кэш всё ещё действителен.
Теперь в сессии, в которой выполнялось обновление, выполним commit и запустим запрос.
ST COUNT(*) MIN(TIMES_PURCHASED) AVG(TIMES_PURCHASED) -- ---------- -------------------- -------------------- NJ 1 15 15 NY 994898 0 15.0052086 CT 5099 0 14.9466562 MO 1 25 25 FL 1 4 4
Обратите внимание, что данные для FL изменили значение на 4 автоматически. Изменения в основной таблице просто сделали кэш недействительным, что привело к его динамическому обновлению при следующем запросе. Вы гарантировано получите правильные результаты вне зависимости от того, используется ли кэш результатов SQL или нет.
Кэширование и организация пула
Аруп Нанда, член-директор Oracle ACE
Oracle Magazine - Русское издание
Оригинал: Caching and Pooling, by Arup Nanda
Рассматривается, как повысить производительность, используя кэш результатов SQL, кэш PL/SQL функций, клиентские кэши и организацию постоянного пула соединений.
Клиентский кэш результатов запроса
Рассмотрим ситуацию, когда клиент должен вызывать одни и те же данные через медленное сетевое соединение. Хотя база данных может отправить результаты клиенту из кэша почти немедленно, результат должен еще добраться по проводам к клиенту, что увеличивает общее время выполнения. Существуют специализированные промежуточные оболочки, такие как Oracle Coherence для кэширования данных в Java, PHP и Ruby, но что если бы существовал общий способ кэширования данных на клиентском уровне?
База даных Oracle 11g предоставляет для этих целей клиентский кэш результатов запроса (Client Query Result Cache). Все клиентские стеки базы данных, которые используют драйверы OCI8 (C, C++, JDBC-OCI и так далее), могут использовать эту новую возможность, которая позволяет клиентам кэшировать результаты SQL-запросов локально, а не на сервере. В итоге клиентский кэш результатов запроса предоставляет следующие преимущества:
Освобождение разработчиков приложений от построения согласованного по процессам (consistent but per-process) кэша результатов SQL, разделяемого всеми сессиями
Расширение кэширования запроса на сервере до памяти на стороне клиента, путем использования более дешевой клиентской памяти и локального кэширования каждого рабочего набора приложения. Увеличение производительности за счет уменьшения обращений к серверу.
Повышение масштабируемости сервера за счет сбережения его ресурсов. Предложение прозрачного управления кэшем: управление памятью, параллельный доступ к наборам результатов и так далее. Поддерживаемая прозрачным образом согласованность кэша с изменениями на стороне сервера Предложение согласованности в среде RAC
Все, что нужно сделать, чтобы использовать эту возможность – это установить параметр инициализации:
CLIENT_RESULT_CACHE_SIZE = 1G
Этот параметр определяет клиентский кэш размером в 1 Гб, который является суммой кэшей на всех клиентах. (Это статический параметр, поэтому необходимо остановить базу данных, чтобы его установить.) Можно настроить кэши на каждом клиенте, определив другие параметры в файле SQLNET.ORA на стороне клиента:
| OCI_RESULT_CACHE_MAX_SIZE | Определяет размер кэша для этого конкретного клиента |
| OCI_RESULT_CACHE_MAX_RSET_SIZE | Определяет максимальный размер наборов результатов |
| OCI_RESULT_CACHE_MAX_RSET_ROWS | Похож на предыдущий, но определяет количество строк в наборах результатов |
select /*+ result_cache */ * from customers.
Подсказка указывает оператору, что необходимо кэшировать результат (другие параметры уже настроены).
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class CacheTest { private String jdbcURL = "jdbc:oracle:oci8:@PRONE3"; private Connection conn = null; public CacheTest( ) throws ClassNotFoundException { Class.forName("oracle.jdbc.driver.OracleDriver"); } public static void main(String[] args) throws ClassNotFoundException, SQLException { CacheTest check = new CacheTest(); check.dbconnect(); check.doSomething(); } public void dbconnect() throws SQLException { System.out.println("Connecting with URL="+jdbcURL+" as arup/arup"); try { conn = DriverManager.getConnection( jdbcURL, "arup" , "arup"); System.out.println("Connected to Database"); } catch (SQLException sqlEx) { System.out.println(" Error connecting to database : " + sqlEx.toString()); } } public void doSomething() throws SQLException { Statement stmt = null; ResultSet rset = null; try { stmt = conn.createStatement(); System.out.println("Created Statement object"); rset = stmt.executeQuery("select /*+ result_cache */ * from customers"); System.out.println("Retrieved ResultSet object"); if(rset.next()) System.out.println("Result:"+rset.getString(1)); } catch (SQLException sqlEx) { } finally { try { System.out.println("Closing Statment & ResultSet Objects"); if (rset != null) rset.close(); if (stmt != null) stmt.close(); if (conn != null) { System.out.println("Disconnecting..."); conn.close(); System.out.println("Disconnected from Database"); } } catch (Exception e) { } } } }
Сохраните файл как CacheTest.java и затем откомпилируйте код:
$ORACLE_HOME/jdk/bin/javac CacheTest.java
Теперь выполните откомпилированный класс:
$ORACLE_HOME/jdk/bin/java -classpath .:$ORACLE_HOME/jdbc/lib/ojdbc5.jar CacheTest Connecting with URL=jdbc:oracle:oci8:@PRONE3 as arup/ arup Connected to Database Created Statement object Retrieved ResultSet object Result :M Closing Statment & ResultSet Objects Disconnecting... Disconnected from Database
Выполните это несколько раз. После нескольких выполнений можно видеть, что клиент кэшировал значения с помощью динамических представлений, показанных ниже:
select * from client_result_cache_stats$ / select * from v$client_result_cache_stats /
Клиентский кэш результатов запроса очень подходит для справочных таблиц, которые обычно не меняются. (А если они изменятся, кэш обновится.) Он отличается от кэша результатов SQL, который располагается на сервере. Поскольку клиент кэширует результаты, у клиента нет необходимости обращаться к серверу, чтобы получить данные, что не только сберегает пропускную способность, но и циклы ЦПУ на сервере. Более подробную информацию можно найти в Oracle Call Interface Programmers Guide.
Организация пула постоянных соединений базы данных
В традиционной архитектуре клиент/сервер существует соответствие один к одному между пользовательской сессией и соединением базы данных. Однако в системе, основанной на Web, это может быть не так.
Основанные на Web системы являются «безстатусными» по своей природе: при обращении к странице устанавливается соединение с базой данных, а когда загрузка страницы завершена, соединение с базой данных разрывается. Позднее, когда пользователь вновь обратится к этой странице, будет установлено новое соединение, которое будет разорвано после достижения желаемого результата. Этот процесс избавляет от необходимости управлять большим количеством одновременных соединений.
Установления соединения достаточно дорого по своим накладным расходам, поэтому кэширование соединений является важным требованием в таких приложениях. В этой модели, когда странице необходимо соединение с базой данных, из пула выталкивается одно из уже установленных соединений. После того как работа сделана, Web сессия возвращает соединение обратно в пул.
Однако существуют проблемы с традиционной клиент/серверной организацией или организацией пула на среднем уровне:
Ограничение каждого пула одним узлом среднего уровня. Непомерное разрастание результатов пула в заранее размещенных серверах базы данных и чрезмерное расходование памяти сервера базы данных. Рабочая нагрузка распределена неравномерно между пулами.
Чтобы избежать этой проблемы база данных Oracle 11g предоставляет пул, расположенный на сервере, который называется пул постоянных соединений базы данных (Database Resident Connection Pool - DRCP).Этот пул доступен всем клиентам, которые используют OCI драйвера, включая C, C++, и PHP.
По умолчанию база данных Oracle 11g поставляется с уже установленным пулом соединений, но он отключен. Чтобы запустить его, нужно выполнить:
execute dbms_connection_pool.start_pool;
Теперь, чтобы вместо обычной сессии использовать соединения, хранящиеся в пуле, всё, что необходимо сделать, это добавить строку (SERVER=POOLED) в содержимое TNS, как показано ниже:
PRONE3_POOL = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = prolin3.proligence.com)(PORT = 1521)) (CONNECT_DATA = (SERVER = POOLED) (SID = PRONE3) ) )
Теперь клиенты могут подключаться к пулу соединений (connection pool), используя строку соединения PRONE3_POOL. Приложения будут взимодействовать с пулом, а не с сервером. Если используется стандартная строка соединения из файла TNSNAMES.ORA, следует применить фразу POOLED. К примеру в PHP, это выглядит так:
$c = oci_pconnect(‘myuser’,‘mypassword’,’prolin3.proligence.com/PRONE3:POOLED’);
или
$c = oci_pconnect(‘myuser’, ‘mypassword’,’PRONE3_POOLED’);
В вышеприведенном описании мы запускали пул по умолчанию, который поставляется с Oracle с опцией по умолчанию. Можно использовать процедуру CONFIGURE_POOL в стандартном пакете DBMS_CONNECTION_POOL:
| POOL_NAME | Имя пула. Используйте ‘’ (две одинарных кавычки для пула по умолчанию) |
| MINSIZE | Минимальное количество сессий, хранящихся в пуле |
| MAXSIZE | Максимальное количество сессий, хранящихся в пуле |
| INCRSIZE | Когда опрашиваемый сервер недоступен, пул создает заданное количество новых соединений |
| SESSION_CACHED_CURSORS | Включает кэширование курсоров сессии |
| INACTIVITY_TIMEOUT | Если сессия не используется в течение этого времени, то она отсоединяется |
| MAX_THINK_TIME | После того как клиент получил соединение из пула, он должен выполнить SQL оператор в течение этого времени, иначе клиент потеряет соединение |
| MAX_USE_SESSION | Максимальное количество раз, которое соединение может быть взято и помещено обратно в пул |
| MAX_LIFETIME_SESSIONE | Как долго сессия должна существовать |

Arup Nanda (arup@proligence.com) has been exclusively an Oracle DBA for more than 12 years with experiences spanning all areas of Oracle Database technology, and was named "DBA of the Year" by Oracle Magazine in 2003. Arup is a frequent speaker and writer in Oracle-related events and journals and an Oracle ACE Director. He co-authored four books, including RMAN Recipes for Oracle Database 11g: A Problem Solution Approach.
Отличия от материализованных представлений
Те, кто знаком с материализованными представлениями (MVs - МП) могут удивиться, чем эта функциональность (кэш результатов SQL) отличается от той (материализованных представлений). Ответ: многим. Внешне они кажутся похожими – оба каким-то образом сохраняют результаты и выдают ответы из этого сохраненного множества, но на этом сходство заканчивается. Материализованные представления хранят данные в памяти базы данных, а кэши результатов SQL – в оперативной памяти, они не используют дополнительное дисковое пространство и исчезают, когда экземпляр базы данных останавливается или исчерпывается пространство в кэше результатов.
Кроме того, МП статичны; когда данные в основных таблицах меняются, материализованные представления не знают об этом. До тех пор пока материализованные представления не будет обновлено, пользователи могут либо получать устаревшие данные, если параметр query_rewrite_integrity установлен в значение stale_tolerated, либо перенаправить базовый запрос к основным таблицам, что займет гораздо больше времени. При использовании же кэша результатов SQL нет необходимости явно обновлять кэш, он автоматически обновится при следующем выполнении запроса.
МП применяют гораздо более сложный ом алгоритм переписывания. Кэшированный результат повторно используется только тогда, если тот же самый запрос (или его фрагмент) выполняется вновь, после того как он был в первый раз помещен в кэш (и извлеченные данные не менялись). Переадресованные к МП запросы получают дополнительный выигрыш от того, что в них можно сворачивать данные из МП, выполнять соединения с таблицами или другими материализованными представлениями, а также применять дополнительные предикаты, что весьма желано в среде хранилищ данных.
Итак, МП и кэши результатов SQL не обязательно сопоставимы или взаимозаменяемы; каждый подход имеет свои собственные преимущества.
Подзапросы
Кэш результата SQL можно использовать в подзапросах. Рассмотрим следующий запрос: select prod_subcategory, revenue from ( select /*+ result_cache */ p.prod_category, p.prod_subcategory, sum(s.amount_sold) revenue from products p, sales s where s.prod_id = p.prod_id and s.time_id between to_date('01-jan-1990','dd-mon-yyyy') and to_date('31-dec-2007','dd-mon-yyyy') group by rollup(p.prod_category, p.prod_subcategory) ) where prod_category = 'software/other' /
В этом запросе кэширование выполняется в подзапросе во встроенном представлении. Таким образом, в то время как внутренний запрос остаётся таким же, внешний запрос может меняться, все ещё используя кэш.
Чтобы проверить, сколько памяти используется для кэша результатов SQL в базе данных, можно использовать стандартный пакет dbms_result_cache, как показано ниже:
SQL> set serveroutput on size 999999 SQL> execute dbms_result_cache.memory_report R e s u l t C a c h e M e m o r y R e p o r t [Parameters] Block Size = 1K bytes Maximum Cache Size = 2560K bytes (2560 blocks) Maximum Result Size = 128K bytes (128 blocks) [Memory] Total Memory = 126736 bytes [0.041% of the Shared Pool] ... Fixed Memory = 5132 bytes [0.002% of the Shared Pool] ... Dynamic Memory = 121604 bytes [0.040% of the Shared Pool] ....... Overhead = 88836 bytes ....... Cache Memory = 32K bytes (32 blocks) ........... Unused Memory = 21 blocks ........... Used Memory = 11 blocks ............... Dependencies = 4 blocks (4 count) ............... Results = 7 blocks ................... SQL = 5 blocks (4 count) ................... Invalid = 2 blocks (2 count)
PL/SQL procedure successfully completed.
Если необходимо по какой-то причине сбросить содержимое кэша (и кэш результатов, и кэш функций, описанный ниже) можно использовать:
begin dbms_result_cache.flush; end;
После выполнения вышеприведенного оператора при запуске исходного запроса к таблице CUSTOMERS с подсказкой result_cache, вы увидите, что запрос снова выполняется 3 секунды.
Конечно, после первого выполнения запроса результаты снова будут кэшированы и при последующих выполнениях значения будут снова выбираться из кэша результатов и, следовательно, запрос будет выполняться намного быстрее. Если необходимо сделать недействительным кэш только для одной таблицы, а не весь кэш целиком, можно использовать следующий оператор:
begin dbms_result_cache.invalidate('ARUP','CUSTOMERS'); end;
Существует несколько представлений словаря данных, которые показывают статистику кэша результатов SQL:
| V$RESULT_CACHE_STATISTICS | Показывает различные настройки, особенно использование памяти |
| V$RESULT_CACHE_MEMORY | Показывает различные участки памяти, которые составляют кэш результатов SQL |
| V$RESULT_CACHE_OBJECTS | Показывает объекты, которые составляют кэш результатов SQL |
| V$RESULT_CACHE_DEPENDENCY | Показывает зависимости между различными объектами, составляющими кэш результатов SQL |
Сравнение кэширования и пакетных переменных
Выполнять кэширование значений в памяти можно также, используя пакетные переменные: либо скалярный тип данных, либо PL/SQL коллекцию – для кэша результатов SQL, также как и для кэша PL/SQL-функции. Приложение может обращаться к переменной быстрее, чем к строке таблицы или функции. Переменные, хранящиеся в памяти, действуют в некотором смысле подобно кэшу, так какое же преимущество имеет кэш результатов SQL?
Различий много. После выполнения функции для клиента с cust_id = 5, из другой сессии выполните функцию для этого же клиента:
SQL> select get_tax_rate(&n) from dual 2 / Enter value for n: 5 old 1: select get_tax_rate(&n) from dual new 1: select get_tax_rate(5) from dual
GET_TAX_RATE(5) --------------- 6
1 row selected.
Elapsed: 00:00:00.00
Обратите внимание на время выполнения; оно означает, что результаты приходят из кэша, а не от выполнения функции. Итак, хотя даже эта функция и не кэшировалась в этой сессии, она все равно использовалась из кэша другой сессии, вызывавшей её.
Кэш существует для экземпляра база данных, не для сессии. Эта возможность сделать кэширование в одной сессии доступным всем другим очень отличается от использования пакетных переменных, хранящих в памяти значение, видимое только в этой сессии.
К тому же пакетные переменные ничего не знают об изменениях базовых таблиц. Их необходимо обновлять вручную, когда данные меняются; иначе приложения получат устаревшие данные. Кэш результатов SQL, как и кэш PL/SQL функций, автоматически обновляется, когда меняются данные базовых таблиц; пользовательского вмешательства не требуется.
Базы данных Oracle - статьи
GRID серверов БД является развитием кластерной архитектуры Oracle. Oracle Real Application Clusters (RAC) хорошо зарекомендовал себя во многих организациях. Если раньше для установки кластера требовалось установить поверх стандартной операционной системы дополнительное специализированное программное обеспечение третьих фирм, то теперь Oracle сам написал такое программное обеспечение (Clasterware) и поставляет его с версией 10G для любых платформ (а не только для Windows и Linux). Теперь установка кластера Oracle может производиться на стандартные операционные системы. Кроме того, Oracle поставляет в составе RAC кластерную файловую систему – Cluster File System. Это позволяет реализовать кластер не на сырых устройствах (Raw device), а на обычной ОС, где могут храниться и данные кластерной БД и программное обеспечение и другие файлы.
Для создания GRID серверов БД необходимо обеспечить возможность автоматического динамического подключения и отключения дополнительных вычислительных ресурсов сервера БД. Это делается на основе понятия “сервис”. Каждое приложение (например, CRM, ERP, кадры, зарплата и т д) можно рассматривать как сервис, работающий на нескольких узлах GRID. Администратор GRID может для каждого сервиса определить узлы GRID (кластера), на которых этот сервис запускается сразу при старте сервиса (так называемые PREFERED узлы) и узлы, которые этот сервис будет использовать дополнительно при определенных условиях (так называемые AVAILABLE узлы). На остальных узлах GRID этот сервис запускаться не может.
Oracle RAC 9.2 позволяет динамически (не останавливая работу приложения) подключать/отключать новые экземпляры (instance) Oracle. Эта технология используется и здесь. Администратор описывает правила (policy) “переползания” сервиса на дополнительные узлы. Например, сервис CRM приложения запустился на двух узлах GRID и работает с БД. Oracle постоянно измеряет нагрузку на узлы и если она превысит заданный в policy предел, то на одном из разрешенных дополнительных узлов автоматически запустится новый экземпляр Oracle, работающий с этой БД, для обслуживания этого сервиса. Часть сеансов пользователей автоматически “переползет” на новый узел. Тем самым вычислительный ресурс для сервиса увеличится.
При дальнейшем увеличении нагрузки будут запускаться новые экземпляры Oracle на AVAILABLE узлах. При снижении нагрузки узлы будут освобождаться и их смогут использовать другие сервисы (один и тот же узел может быть описан как дополнительный для нескольких сервисов).
В случае выхода из строя одного из обязательных или дополнительных узлов, обслуживающих сервис, также запускается экземпляр Oracle на новом дополнительном узле и вычислительный ресурс сервиса восстанавливается. Oracle постоянно измеряет загрузку узлов, поэтому вновь подключаемые пользователи направляются на наименее загруженные узлы, и уже работающие сеансы также перемещаются на менее загруженные узлы сервиса. Тем самым достигается балансировка загрузки узлов.
Администратор GRID может легко подключать новые компьютеры к GRID и добавлять их в список основных и дополнительных узлов сервиса. Можно создать несколько вариантов списков узлов и политик для сервисов и активизировать разные варианты в разные периоды времени (например, можно создать отдельный вариант для конца квартала). Администратор GRID, используя компоненту GRID Control Enterprise Manager, управлять сервисами (стартовать, останавливать, подключать узлы, конфигурировать узлы и т д). Добавление компьютерного узла в GRID серверов осуществляется путем всего лишь одного нажатия на клавишу мыши.
Перенос обычных приложений Oracle в среду GRID не требует их переписывания. Достаточно указать, что приложение работает не с конкретным узлом, а с сервисом. Например, при соединении клиента SCOTT с паролем TIGER с сервисом myservice надо просто написать в строке связи SCOTT/TIGER@//myVIP/myservice.
Базы данных Oracle - статьи
Ситуация с серверами приложений похожа на то, что мы видели с серверами БД. Уже в Oracle 9i мы могли организовать кластеры серверов приложений, т е транзакция, начавшаяся на одном сервере приложений, могла, в случае его остановки, продолжиться на других серверах приложений кластера. GRID Control Enterprise Manager позволяет добавлять новые узлы в кластер сервера приложений, управлять этими узлами и кластером, стартовать и останавливать эти узлы. При необходимости узлы могут быть исключены из кластера и отданы под другие нужды (web кэш, сервер БД и т д).
GRID Control позволяет управлять всеми компонентами сервера приложений (кэшем, инфраструктурой, J2EE, EJB и т д). Сервер приложений тесно связан с узлами сервера БД и при выходе из строя узла сервера БД, сервер приложения тут же узнает об этом и переключается на оставшиеся узлы (все это занимает несколько секунд).
Литература
Foster, C. Kesselman, S. Tuecke. The Anatomy of the Grid: Enabling Scalable Virtual Organizations. // International Journal. Supercomputer Applications, 15(3), 2001.
http://www.globus.org/research/papers.html
Foster, C. Kesselman, J. Nick, S. Tuecke, The Physiology of the Grid: An Open Grid Services Architecture for Distributed Systems Integration. // Open Grid Service Infrastructure WG, Global Grid Forum, June 22, 2002
http://www.globus.org/research/papers.html
Н Дубова. Учет и контроль для “коммунальных вычислений” // Открытые системы N1, 2003
П Анни. Этот GRID – неспроста... // Открытые системы N1, 2003
М Ривкин. Oracle Streams — универсальное средство обмена информацией //Byte, 2003, N 6
M Ривкин. Новые возможности Oracle 9.2 //Открытые системы, 2002, N 11
М. Ривкин. Распределенные СУБД // Мир ПК, 1993, N 5
http://mrivkin.narod.ru/oracle.html
Механизмы Oracle 10G для реализации коммерческой GRID
Все механизмы Oracle 10G для реализации коммерческой GRID мы разобъем на следующие группы (рис. 4):
Storage GRID – GRID хранения данных;
Database GRID – GRID серверов БД;
Application GRID – GRID серверов приложений;
Средства самонастройки узлов БД;
GRID Control – система управления GRID;
Средства для разделения информации между узлами GRID.
Рис 4. Архитектура Oracle GRID
ORACLE и коммерческая GRID
, http://mrivkin.narod.ru/
Эта статья о подходе компании Oracle к концепции GRID состоит из 2х частей. В первой части мы рассмотрим, что такое GRID, для чего она нужна и какие дает преимущества, почему именно сейчас пришло время GRID. Эта часть более описательная, менее техническая. А во второй части мы рассмотрим, какие механизмы предлагает Oracle для разработки и эксплуатации приложений в среде GRID, почему новая версия Oracle называется Oracle 10G (где G означает GRID), а также обсудим, чем идеальная концепция GRID отличается от реальности, от того, что можно использовать сегодня.
Термин GRID (переводится как решетка или как вычислительная сеть) только недавно начал входить в лексикон специалистов по информационным технологиям. Однако аналитики уже сейчас прогнозируют, что идея GRID может радикально изменить мир информационных технологий, точно также, как когда-то это сделал интернет. Еще несколько лет назад только специалисты говорили об интернет и Web, а сегодня дети и неподготовленные пользователи “лазают” в интернет, совершают покупки и платежи через интернет, узнают погоду, новости и курсы валют через интернет и т. д.
Сегодня, когда компания Oracle выпускает СУБД Oracle 10G, которая позволяет создавать и выполнять приложения в среде GRID, а основные производители компьютеров выпускают программное обеспечение и оборудование, позволяющее объединить компьютеры в GRID, мы можем говорить о наступлении эпохи GRID. А поскольку идея GRID прозрачна и всем понятна, а также позволяет экономить средства и более эффективно использовать имеющиеся вычислительные мощности, то понятно, что наступление эпохи GRID остановить нельзя.
Почему сейчас?
Почему же только сейчас IT компании начали активно говорить о GRID? Почему только сейчас компания Oracle выпускает первую в мире платформу для коммерческих GRID вычислений - Oracle 10G? Дело в том, что и общество и уровень развития техники и технологии только сейчас созрели для реализации и восприятия концепции GRID.
Во-первых, для того, чтобы связать множество компьютеров в единую GRID нужны хорошие сети передачи данных. Американский ученый Джон Гилдер писал “Когда сеть работает также быстро, как внутренние шины компьютера, машина расщепляется по сети на набор специализированных устройств”. Конечно, пропускная способность и скорость сетей еще недостаточны, но они очень быстро развиваются. Если число транзисторов компьютерного чипа удваивается каждые 18 месяцев, то скорость сети передачи данных удваивается всего за 9 месяцев. На рисунке 2, взятом из журнала Scientific American (январь 2001 г) видно, что скорость передачи данных по сетям растет экспоненциально.
Во-вторых, в мире появляется все более сложные задачи и накапливаются все большие объемы данных. И для решения этих суперзадач и обработки этих огромных массивов данных уже не годятся обычные компьютеры. Нужны суперкомпьютеры с очень высокой мощностью и таких компьютеров требуется все больше. Стоимость этих суперкомпьютеров очень высока, но их мощности очень быстро перестает хватать. В последнее время бурно развиваются такие области, как анализ данных, хранилища данных, извлечение знаний (DataMining). Уже не редкость базы данных размером в несколько терабайт. Даже в Москве мы знаем несколько организаций, имеющих терабайтные базы данных. И объем этих баз быстро растет. Сегодня СУБД Oracle 9i позволяет создавать базы размером 512 петабайт. Oracle 10G будет поддерживать базы данных размером в 8 экзобайт. По прогнозам аналитиков к 2015 г базы размером более 1000 петабайт станут обычным решением и будут содержать тексты, графику, видео, файлы и т д.
Рис. 2. Скорость улучшения характеристик различных элементов
(синий – сеть, красный – устройства хранения инф, коричневый – компьютерные чипы)
Третьей, очень важной причиной бурного развития концепции GRID сегодня является то, что она позволяет получить результат быстрее и дешевле. Действительно, запросив больший чем раньше вычислительный ресурс, мы можем реализовать более сложные и точные алгоритмы расчета и получать более точные результаты гораздо быстрее. Более эффективное использование оборудования и исключение простаивающего оборудования снизят стоимость эксплуатации и количество закупаемого и поддерживаемого оборудования.
GRID дает возможность объединить вычислительные ресурсы в единое множество и управлять этим множеством как единой системой, что снижает затраты на администрирование. Поскольку невозможно администрировать программное обеспечение на сотнях и тысячах компьютеров одновременно, компания Oracle в своем продукте Oracle 10G реализовала целую инфраструктуру самонастройки, самотестирования, самоконфигурации. Т. е необходимость сложного администрирования отдельных узлов отпадает и это тоже снижает затраты на администрирование. Управление всей GRID системой возможно с единого пульта.
Еще одним важным преимуществом GRID является то, что в качестве ее элементов можно использовать дешевые компьютеры и операционные системы. Так Oracle строит свои GRID для разработки на основе очень дешевых блэйд (Blade - лезвие) компьютеров с ОС Linux. Каждый такой блэйд-компьютер – это практически одна упрощенная плата. Она не содержит избыточных элементов (таких как графические адаптеры, звуковые адаптеры и т д). Однако из этих плат-компьютеров можно собирать блэйд-фермы – т е целые шкафы, состоящие из множества таких плат-компьютеров. Причем добавление таких новых компьютеров не намного сложнее, чем добавление книжек в книжную полку.
Четвертой причиной наступления GRID эпохи являются экономические реалии. Кризисы и замедление развития экономики заставляют компании более тщательно считать деньги и сокращать расходы и персонал. В первую очередь часто сокращаются расходы на IT. Поэтому GRID технологии, позволяющие экономить деньги на эксплуатации систем, сейчас очень популярны среди тех, кто умеет считать свои деньги.
Пятой причиной является то, что растет количество людей, знакомых с терминами GRID, виртуализация, вычисления как коммунальная услуга и т д. Увеличилось число публикаций, концепция достаточно понятна и уже сами заказчики и отделы IT требуют внедрения GRID технологий.
В качестве шестой причины можно отметить то, что уже разработаны стандарты GRID. Многие крупные фирмы – производители компьютеров и программного обеспечения участвуют в Global Grid Forum – некоммерческой организации, разрабатывающей стандарты построения GRID. Причем разрабатываются не только стандарты, но и инструментарий для реализации этих стандартов. Так сейчас приобрел большую популярность пакет Globus Toolkit и идет разработка новой версии GRID-архитектуры – OGSA (Open Grid Service Architecture).
В качестве седьмой причины следует отметить появление опыта реализации концепции GRID и реальных проектов, построенных на основе этой концепции. Первыми были такие проекты научной GRID, как SETI (поиск следов внеземных цивилизаций), проект поиска простых чисел, проект CERN (обработка результатов физических исследований). Сейчас реализуется множество новых GRID-проектов, например: TeraGrid, NASA Information Power Grid, US Grids center, Grid Electronic Art и т д.
И наконец последняя, но пожалуй наиболее важная причина бурного развития GRID сегодня – это то, что основные производители компьютеров и программного обеспечения начали промышленную реализацию и продажу продуктов, позволяющих строить GRID. Мы уже упоминали про блэйд-компьютеры, их выпускают различные производители. Компания HP начала продажу продукта HP Utility Data Center, который позволяет объединять в GRID компьютеры фирмы HP и управлять ими из единого центра [3]. Похожие решения есть и у компании SUN, это Sun One Grid Engine [4]. Очень много в области GRID делает компания IBM. Она даже создала в Монпелье (Франция) центр компетенции по решениям GRID.
Таким образом видно, что разработчикам и пользователям GRID-приложений не хватало только программного обеспечения, которое позволило бы обычным коммерческим информационно-управляющим приложениям работать в среде GRID. И теперь такое программное обеспечение появилось. Компания Oracle создала Oracle 10G (буква G как раз и означает GRID), который является платформой для реализации приложений в среде GRID. Причем Oracle 10G позволяет не только создавать новые приложения для GRID, но и перенести в среду GRID старые приложения, работающие на Oracle.
Если у Вас есть GRID на которой работают несколько приложений и каждое приложение использует свой набор компьютеров (например, несколько компьютеров – узлы кластера сервера БД, несколько компьютеров – узлы кластера сервера приложений, часть компьютеров используется как Web-кэши и т д), то Вы легко с единого пульта можете добавлять или удалять компьютеры в/из пула серверов, переместить часть компьютеров серверов приложений в пул серверов или кэши и т д. Т е Вы можете увеличивать мощность тех пулов, у которых сейчас нагрузка максимальна.
Некоторые производители блэйд-компьютеров, например, позволяют при перемещении компьютера в новый пул автоматически менять его программную среду и конфигурацию программного обеспечения, т е при перемещении в серверный пул на блэйде запустится еще один узел кластера Oracle, который подключится на лету к работающим узлам и разгрузит их.
Кстати, кластеры на основе блэйд-серверов и ОС Linux являются сегодня наиболее эффективными по критерию цена/производительность. Oracle 10G поддерживает быстрый обмен данными между серверами и между сервером и областью хранения данных используя технологию InfiniBand.
Что касается ОС, то Oracle отлично работает на Linux и компания Oracle совместно с компанией Red Hat модифицировала OC Red Hat Advanced Server так, что надежность и производительность этой связки сильно возросла.
Многие аналитики рассматривают сегодня концепцию GRID, как второй этап развития концепции интернет. Если первый этап – Web – был связан с презентационным слоем, т е позволял из любой части света обращаться к ресурсу и получать стандартные HTML представления страницы, то GRID связан с вычислительным слоем, поскольку позволит использовать любой вычислительный ресурс, включенный в GRID.
Выпускаемая компанией Oracle платформа для поддержки коммерческих GRID-приложений – Oracle 10G – использует как прежние преимущества Oracle – кластерные архитектуры, высокая надежность, масштабируемость, защита данных, хорошая работа в среде Linux, мощные средства разделения информации, такие как Oracle Streams [5], Distributed Database, Transported Tablespace [6], так и новые возможности. Среди них следует выделить такие важные для GRID вещи, как самоуправляемость и самонастройка, автоматическое управление виртуальной областью хранения данных (Automatic Storage Management), балансировка загрузки узлов кластера и выделение групп узлов под конкретные приложения, работа с внешними файлами ОС и таблицами БД в едином режиме, клонирование БД, управление патчами и конфигурациями и т д.
Кстати, для тех, кто разрабатывает приложения в среде Globus, пакет Oracle Globus Toolkit позволит использовать СУБД Oracle как ресурс в среде Globus. Компонента Globus Resource Information Service (GRIS) видит и контролирует ресурсы Oracle, а команды Globus позволяют выполнять PL/SQL-процедуры, специфицированные в Globus Resource Specification Language и использовать систему выполнения заданий и расписания (Oracle Scheduling).
Разделение информации в GRID
Информация хранится в GRID в базах данных и файлах. Множество узлов GRID должно иметь доступ к этой информации, поэтому необходимо организовать разделение информации между узлами. Существует три способа разделения информации:
централизация информации в единой БД;
работы с множеством самостоятельных независимых БД и файлов (федерирование);
временный вынос необходимой информации на узлы, где она будет обрабатываться (propelling);
Централизация информации – самый простой способ. Вся информация из различных источников собирается в одной БД Oracle и далее кластер Oracle прекрасно решает множество задач, работая с этой БД.
Работа с множеством самостоятельных БД тоже хорошо реализована в Oracle. Механизм работы с распределенными БД реализован в Oracle давно, причем узлы этой распределенной БД могут быть реализованы не только на основе СУБД Oracle, но и на основе других СУБД, с использованием шлюзов Oracle Gateway к этим СУБД. При этом каждая БД существует самостоятельно в своей части GRID, живет, обновляется, администрируется своими приложениями, но если необходимо в одном приложении работать с информацией из различных БД, то пользователь (или приложение) просто выполняет распределенный запрос к этой распределенной БД. Если какие-либо объекты данных (таблицы) переносятся из одной БД в другую или из централизованной БД разносятся по различным БД, то доступ к ним не требует переписывания запроса (приложения). Администратору БД достаточно лишь создать синонимы для перенесенных данных и приложение продолжит работу.
Согласованность работы с распределенной БД обеспечивается за счет реализации алгоритмов двухфазной фиксации изменений (2 phase commit), который Oracle реализует автоматически (при создании пользовательских приложений не надо заботиться о том, в единой или разных БД находятся объекты). Тем самым обеспечивается “прозрачность” работы с распределенной БД [7].
Oracle умеет распознавать распределенные запросы и оптимизировать их выполнение с учетом характеристик используемых узлов и БД. Если надо организовать работу с структурированным объектом (таблицей), части которого хранятся в различных БД, то с помощью оператора объединения UNION можно создать виртуальное представление всего объекта и работать с ним, а уж Oracle преобразует операции с объектом в операции с его частями в разных БД.
Работа с распределенной БД требует, чтобы в момент выполнения операций существовала хорошая связь со всеми используемыми БД. Если связь прервется, то запрос выполнен не будет. Кроме того, если БД сильно удалены друг от друга, необходимо иметь очень хорошие быстрые сети передачи данных для доступа к этим БД.
Поэтому часто используется механизм создания в каждой группе узлов GRID своей локальной БД, содержащей копии объектов основной БД. Для создания таких локальных БД надо обеспечить две вещи:
быстрый перенос части данных из одной БД в другую;
постоянную синхронизацию данных.
Быстрый перенос из одной БД в другую больших объемов данных можно осуществить в Oracle с помощью механизма транспортируемых табличных пространств
(Transportable tablespace). Вместо того, чтобы экспортировать данные из БД в файл, перемещать файл к другой БД, импортировать данные из файла в новую БД (а все это занимает очень много времени), мы можем просто скопировать (например, с помощью средств FTP) файлы операционной системы, которые образуют табличное пространство, содержащее необходимые нам большие объекты данных. Далее достаточно перенести с помощью экспорта-импорта из одной БД в другую лишь маленький объем метаинформации о перемещенном табличном пространстве. Механизм транспортируемых табличных пространств работает намного быстрее, чем экспорт-импорт.
Перемещаемые файлы можно, например, записать на СD диск и подключать к различным БД в виде набора открытых только на чтение таблиц (например, справочников). В Oracle 10G реализована возможность транспортировки табличных пространств между различными операционными системами. Например, мы можем со скоростью работы по FTP протоколу переместить большие таблицы из БД на Windows в БД на Linux или Unix. Это делается с помощью утилиты RMAN.
Для переноса небольших таблиц из БД в БД в Oracle 10G можно использовать новую утилиту Data Pump. Ее функциональность аналогична тому, что умели делать старые утилиты экспорта-импорта, но работает она намного быстрее. Так импорт данных выполняется в Data Pump в 20-30 раз быстрее, чем раньше, используется механизм распараллеливания вычислений, возможен рестарт работы утилиты с той точки, где она прервала свою работу. Data Pump позволяет выполнить прямой перенос данных из одной БД в другую без создания промежуточных файлов на диске.
Для синхронизации данных, хранящихся в различных БД, может использоваться как старый механизм репликации, так и новый, более универсальный механизм Oracle Streams
[5]. Streams позволяет разделять между узлами как сообщения (messaging), так и операции с БД на основе единого универсального механизма. Все заказанные изменения в исходной БД захватываются из журналов БД (это не нагружает эксплуатационную БД) и складируются в едином универсальном формате в области хранения (Stage). Все узлы, которым необходимо получить и применить эту информацию об изменениях, подписываются на получение информации об изменениях из области хранения. При появлении новой информации об изменениях в области хранения, подписавшиеся узлы получат нужную им информацию и смогут ее применить.
Захват и применение информации об изменениях могут быть легко сконфигурированы и далее выполняются автоматически. При захвате, перемещении и применении информации об изменениях, она может быть преобразована с помощью пользовательских процедур.
Единый универсальный механизм Oracle Streams позволяет реализовать репликацию нужных таблиц, передачу сообщений (Advanced Queuing), передачу извещений о событиях (Notification), оперативную подпитку хранилищ данных, упрощая конфигурирование и администрирование этих механизмов. В случае захвата информации обо всех изменениях в исходной БД и применения их к копии этой БД, мы можем реализовать механизм поддержания резервной БД (StandBy Database).
Механизм StandBy Database позволяет поддерживать в нескольких частях GRID копии одной и той же БД. Причем в случае логического StandBy эти копии могут использоваться для выполнения операций чтения к этим БД. Например, на них можно печатать отчеты, выполнять приложения, связанные с анализом данных, и т д.
Oracle Streams позволяет исключить дублирование информации, передаваемой по сети в разные узлы, обеспечить гибкую маршрутизацию потоков данных, гарантированную доставку изменений. С помощью Oracle Streams легко обеспечить двустороннюю репликацию данных и разрешение возникающих конфликтов репликации (имеются встроенные алгоритмы разрешения конфликтов).
Часто необходимо перенести данные из целевой БД в удаленную БД лишь на время, для их обработки там. Это позволяет сделать механизм Self Propelling, реализованный в Oracle 10G. Практически это объединение механизма транспортируемых табличных пространств и механизма Oracle Streams. С помощью всего одной команды можно организовать перенос информации в другую БД и запуск механизма ее синхронизации с копией в источнике. Таким образом мы можем вынести данные и их обработку на менее загруженные узлы GRID.
Механизм Self Propelling позволяет оперативно приблизить данные к месту их обработки, снизить нагрузку на сеть, уменьшить число проблем и ошибок, связанное с работой в среде распределенной БД.
В GRID часто информация может храниться не в БД, а в файлах операционной системы. Механизм Oracle External Table позволяет использовать средства работы с БД для работы с информацией файлов. Файлы определяются в словаре БД как внешние (external) таблицы и далее с ними можно работать на чтение (и на запись в Oracle 10G) как с обычными таблицами БД. Более того, можно выполнять операции, одновременно работающие с реляционными таблицами БД и информацией файлов операционной системы.
СУБД Oracle поддерживает тип данных Bfiles. Если Вы создадите в БД таблицу с колонкой типа Bfile, то в этой колонке будут храниться лишь ссылки на файлы операционной системы, а сами данные, помещаемые в эту колонку, будут храниться в файлах ОС. Это еще один механизм для работы с файлами операционной системы. Понятно, что и файлы ОС и их описания в словаре БД можно копировать и перемещать между узлами GRID, обеспечивая разделение информации.
Самонастройка СУБД
GRID подразумевает одновременную работу множества серверных узлов и баз данных. Если несколькими узлами администратор БД мог управлять вручную, используя графические средства администрирования, то десятками, сотнями и тысячами серверов БД управлять вручную невозможно. Поэтому Oracle встроил в сервер 10G целую инфраструктуру автоматической диагностики и самонастройки.
Во время работы сервера БД, Oracle автоматически собирает большой объем статистики о работе всех компонентов системы. Эта информация сохраняется в специальном хранилище в БД – автоматическом репозитории загрузки системы (AWR – Automatic Workload Repository). Собирается статистика о выполняемых операциях, ожиданиях, объектах БД и использовании пространства в БД, используемых ресурсах и т д. Сбор статистики не сильно нагружает экземпляр Oracle, а частоту записи собранной статистики в AWR можно регулировать (по умолчанию – запись осуществляется каждые 30 минут).
Собранная статистика анализируется компонентой ADDM (монитор автоматической диагностики БД). Она реализует опыт специалистов Oracle по настройке СУБД и в результате анализа выявляет проблемы производительности, доступа к данным, использования ресурсов и т д. ADDM может также выявлять проблемы, которые возникнут в будущем. Основой для работы ADDM является информация о времени выполнения тех или иных операций и времени ожидания. Выявив наиболее критичные моменты, ADDM детализирует эту информацию и выявляет суть и причины проблемы. Далее он либо автоматически перенастраивает СУБД (изменяет размеры областей памяти SGA, перенастраивает ввод/вывод и т д), либо формирует извещения (алерты), которые пересылает администратору. Администратор БД видит не только извещения, но и описание причин, вызвавших проблему, и предложения по исправлению проблемы. Если он согласен с этими предложениями, то ему достаточно подтвердить это и СУБД Oracle выполнит перенастройку. Т е часть проблем снимается в автоматическом режиме, а часть – в автоматизированном режиме.
Кроме того, в состав инфраструктуры настройки входит набор предустановленных программ анализа и фиксации проблем (Automatic Maintenance Tasks). Они могут запускаться по расписанию (ДБА регулирует частоту запуска) или по запросу администратора, анализировать накопленные за длительное время данные из AWR и выполнять более тонкие настройки СУБД, SQL и т д
Вся эта инфраструктура устанавливается и включается сразу же при установке сервера БД и информация о проблемах или потенциальных проблемах поступает к ДБА по мере ее возникновения (а не тогда, когда он сам решит настроить БД). Инфраструктура самодиагностики и самонастройки сильно снизила нагрузку на ДБА. Например, если раньше приходилось вручную управлять размерами областей памяти, анализировать использование этих областей и определять последствия изменения размеров, то теперь ДБА задает только общий размер оперативной памяти, отведенной экземпляру Oracle, и далее СУБД сама обеспечивает оптимальное использование памяти
Типы GRID-проектов
Сегодня можно выделить три типа GRID-проектов:
GRID на основе использования добровольно предоставляемого свободного ресурса персональных компьютеров (Desktop GRID); Научная GRID; GRID на основе выделения вычислительных ресурсов по требованию (Enterprise GRID);
Вначале появились проекты первого типа. Наиболее известными из них были проект SETI (поиск следов внеземных цивилизаций) и проект поиска новых простых чисел.
Для решения этих задач нужно было обеспечить огромный вычислительный ресурс и обработать большой объем слабо связанных данных. Проекты осуществлялись на добровольной основе. Все люди, желавшие участвовать в проекте, выкачивали на свой персональный компьютер небольшую программку и порцию данных. Далее эта программка работала в фоновом режиме на этом персональном компьютере, когда он простаивал (примерно так, как работает программа заставки на ПК) и обрабатывала эту порцию данных. Результат возвращался в единый центр. Такой подход позволил объединить для решения этих задач огромное число персональных компьютеров, обработать большой объем данных. Проект “Простые числа” позволил найти несколько новых простых чисел.
Недостатками проектов такого типа является то, что они не гарантируют достоверность и сроки получения результатов от личных персональных компьютеров, и то, что они пригодны только для решения очень специфических задач (большой объем независимых вычислений на слабо связанном массиве данных).
В последнее время появилось большое число реализаций проектов второго типа – научная GRID. Наиболее ярким примером такой GRID является проект, реализованный в европейском ядерном центре CERN. Там накопился огромный объем данных по результатам физических исследований и для его обработки также нужны были огромные вычислительные мощности, которых у CERN не было.
Были написаны специальные программы, которые устанавливались на многих серверах по всему миру. Эти программы могли работать с единой БД CERN. Поскольку данные в этой БД тоже были слабо связаны (разбиты на множество небольших по объему слабо связанных между собой групп), то каждый такой сервер выкачивал свою порцию данных, перерабатывал ее и возвращал в единую БД результат переработки.
Существует множество таких научных GRID-проектов. Многие из них были реализованы на базе СУБД Oracle. Далеко не полный перечень этих проектов можно видеть на рисунке 3.
Рис. 3.GRID-проекты на базе СУБД Oracle
Общим недостатком GRID-проектов первого и второго типов было то, что они не были предназначены для реализации стандартных информационно-управляющих систем предприятия (кадры, зарплата, управление производством, CRM и т д), требовали создания специализированного системного программного обеспечения для решения каждой новой задачи, были пригодны только для обработки специфических данных (массивы слабо связанных данных). Поэтому эти подходы не годились для создания GRID предприятия.
Третий тип GRID-проектов называют Enterprise GRID (GRID предприятия, коммерческая GRID). Он несколько сужает идеальную концепцию GRID, однако позволяет реализовать стандартные информационно-управляющие системы предприятия в GRID среде уже сегодня. Этот подход позволяет динамически выделять/забирать вычислительные ресурсы для решения задач предприятия, минимизировать перемещение данных между узлами, упростить администрирование систем. Примером платформы для реализации коммерческой GRID является Oracle 10G.
Управление GRID (GRID Control)
Для управления, конфигурирования, диагностики множества разнородных узлов, составляющих GRID, в составе стандартного средства управления Oracle Enterprise Manager (OEM) появилась компонента GRID Control. OEM позволяет управлять всеми компонентами GRID – серверами БД, серверами приложений, кэшами, Java машинами, устройствами хранения, сетевыми компонентами, RAC, Standby, распространением данных и т д.
Причем, поскольку индивидуально управлять каждой компонентой сложно, их можно объединить в группы. Например, группа серверов БД отдела или группа компонент, на которых работает приложение (она может включать и сервера БД и сервера приложений и кэши и т д). Для группы можно установить суммарные характеристики (например, работоспособность всех компонент, наличие проблем или аллертов в группе и т д). ДБА будет отслеживать не состояние отдельных объектов, а состояние групп объектов и проводить операции с группами. При желании можно спуститься и до уровня отдельного компонента группы (например, узла сервера БД).
Используя GRID Control, ДБА может анализировать работу приложения в целом и лишь потом переходить к анализу работы отдельных компонент. Например, если время отклика некоторых приложений или запросов превышает установленный предел, то ДБА может посмотреть, как это время распределяется между отдельными компонентами приложения (например, какой процент времени уходит на работу с сетью, выполнение компонент Java, выполнение доступа к БД (SQL) и т д). Найдя, таким образом, критическое место, ДБА может перейти на уровень анализа и настройки этого узкого места. Так, если основное время уходит на выполнение SQL, то можно перейти к настройке этого SQL оператора.
Одной из главных операций управления GRID является добавление/удаление и мониторинг загрузки элементов GRID. Компонента GRID Control позволяет с помощью мышки подключать к GRID и отключать от GRID диски, узлы сервера БД, узлы сервера приложений, Web кэши и т д. Всегда можно также посмотреть их состояние.
Если у нас есть очень большое число компьютеров, составляющих GRID, то трудно проконтролировать, какое системное и прикладное программное обеспечение стоит на этих узлах и как оно сконфигурировано. Oracle GRID Control включает компоненту для управления конфигурациями. Она периодически (по умолчанию 1 раз в сутки) опрашивает все узлы и собирает в БД информацию о конфигурации этих узлов. Собирается информация о версиях ОС на этих узлах, примененных патчах, установленных продуктах Oracle, их конфигурации, версиях и патчах. Эта информация накапливается и обновляется. На ее основе ДБА может проследить историю изменения конфигурации, легко узнать на каких узлах не применялись те или иные патчи, запросить информацию об узлах со старой версией программного обеспечения и т д.
Кроме того, всегда можно сравнить две конфигурации и выявить различия. Например, если один из узлов в результате изменения конфигурации стал работать хуже, то его всегда можно сравнить с хорошо работающим аналогом и выявить отличия в конфигурации. Можно создать эталонные конфигурации и сравнивать с ними. Можно эти эталонные конфигурации “клонировать” на другие узлы. Клонирование программного обеспечения и конфигураций выполняется быстро и просто и позволяет создать GRID однотипных узлов.
При сборе информации о конфигурации узлов, компонента Менеджер конфигурации анализирует эти конфигурации на предмет соблюдения правил Oracle. Если выявляется несоответствие (например, пользовательские объекты в System Tablespace или отключение дублирования управляющих файлов – Control File), то ДБА немедленно извещается об этом. Это позволяет снизить число проблем, которые могут возникнуть в будущем.
Улучшен и механизм применения патчей. Все патчи для разных продуктов, платформ и версий выкладываются в интернет (на сайт metalink). GRID Control может обратиться к этому сайту, проанализировать наличие еще не установленных патчей для тех платформ и версий, которые у Вас используются, и сообщить об этом. Далее, если ДБА “даст добро”, система управления патчами выгрузит их и применит к тем узлам, где это необходимо. Соответствующая информация о применении патчей отобразится и в БД конфигураций.
Поскольку в GRID работает множество пользователей, множество приложений, множество БД и серверов приложений, встает проблема управления правами доступа пользователей к этим ресурсам. GRID Control обеспечивает единый вход (Single Sign-On) для пользователей многих ресурсов. Понятие пользователя отделено от понятия Account (пользователь конкретной БД, конкретного сервера приложений м т д). Информация о пользователях GRID (Enterprise User) хранится в LDAP директории, где для пользователя определены его права для входа в различные компоненты GRID.
Когда система самонастройки сервера выявляет проблемы, требующие вмешательства ДБА, она посылает аллерты в компоненту GRID Control. Здесь ДБА, используя простой графический интерфейс, может узнать о возникновении проблем и исправить ситуацию. Мощная система советов и подсказок (Advisory Infrastructure) практически выполняет за ДБА работу по решению проблемы и часто ему остается лишь подтвердить свое согласие на внесение изменений в настройку.
Oracle GRID Control позволяет управлять ресурсами сервера, доступными пользователю. Oracle Resource Manager позволяет ограничить максимальное время выполнения запросов, степень использования процессоров, максимальное количество одновременных сеансов, степень распараллеливания при выполнении запросов и т д. Планы использования ресурсов (Resource Plan) можно быстро переключать (например, включать дневной или ночной план).
Управление хранением данных в GRID
Oracle 10G позволяет реализовать новый подход к управлению хранением данных. Функция ASM (Automatic Storage Manager) позволяет виртуализировать наборы дисков в единый виртуальный диск, возложить на Oracle функции менеджера файлов и томов. Теперь администратор должен только выполнить команду создания группы дисков (это и есть виртуальный диск) и добавлять вновь подключаемые к системе диски в группу (это тоже одна команда). Oracle сам работает с этой группой дисков (виртуальным диском), размещая на нем свои файлы и управляя ими. Также легко одной командой можно удалять диск из группы.
На самом деле Oracle разбивает все пространство этого виртуального диска на равные кусочки размером в 1 Мб и создает из этих кусочков виртуальные файлы БД, табличные пространства, тома и т д. Администратор БД еще может видеть такие знакомые ему элементы, как диски, файлы, хотя на самом деле это только логическое представление этих объектов. Oracle не только создает файлы БД на этом виртуальном диске. Он также обеспечивает на нем зеркалирование (mirroring) и расщепление (striping) данных. Это делается автоматически, без вмешательства администратора БД и позволяет, в случае сбоев блоков на диске, быстро автоматически восстанавливать испорченные блоки данных.
Еще одна важная оссобенность ASM, это то, что он автоматически балансирует загрузку дисков. Во время работы ASM измеряет нагрузку по вводу/выводу на различные физические диски и автоматически перемещает наиболее интенсивно используемые данные на наименее загруженные части виртуального диска. Т е работа по настройке ввода/вывода, требовавшая ранее больших усилий от администратора БД, теперь выполняется автоматически.
Если администратор БД решил увеличить размер дискового пространства для БД Oracle, он может просто подключить новый диск к системе и выполнить команду добавления этого диска в группу. После этого Oracle сам переместит часть данных на вновь появившееся пространство, чтобы сбалансировать нагрузку. Если администратор хочет отключить диск от системы, он выполняет соответствующую команду и Oracle перемещает все данные с этого диска на другие диски группы, после чего диск может быть отключен.
ASM частично подменяет файловую систему и кардинально снижает сложность управления хранением данных. Трудоемкость таких операций, как инсталляция БД, добавление/удаление дисков для хранения БД, перемещение данных, восстановление данных уменьшилась в несколько раз. А такие операции, как настройка ввода/вывода и управление пространством на дисках теперь выполняются автоматически.
Кроме того, в Oracle 10G реализована функция Flash Backup, которая позволяет на дешевых дисках (например, ATA) хранить копию эксплуатационной БД и автоматически обновлять ее (быстрый инкриментальный Backup) (например, это можно делать ночью). Это позволяет иметь под рукой на устройствах быстрого доступа версию БД, мало отстающую от эксплуатационной БД. В случае сбоя основной БД, восстановление на основе Flash Backup будет выполнено очень быстро и не потребует работы с лентами. Кстати, создание ленточных копий БД (или ее частей) в случае использования Flash Backup, можно производить на основе Flash Backup БД, не загружая основную БД (например, это можно делать 1 раз в неделю).
В чем же заключается идея или концепция GRID?
Термин GRID вычисления (Computing grid) появился по аналогии с термином Power grid (единая энергосистема). Т. е. его можно перевести как единая компьютерная система. Идея очень проста, понятна и давно описана писателями-фантастами. В мире существует множество компьютеров. Давайте объединим их в один большой суперкомпьютер невиданной мощности. Это даст нам огромное количество преимуществ. Сегодня одни компьютеры работают в половину своей мощности, в то время как другие компьютеры перегружены. В то время как в одних странах ночь и компьютеры простаивают, в других странах не хватает вычислительных ресурсов для решения важных и сложных задач. Для некоторых задач (таких как задачи предсказания погоды, моделирование физических процессов, астрофизика и т. д.) необходимы очень мощные компьютеры, которых пока еще не создали. Создание же суперкомпьютера, элементами которого являются обычные компьютеры, принадлежащие различным странам, организациям, людям, позволило бы решить эти проблемы.
Сегодняшняя реальность любой организации такова, что под любое новое коммерческое приложение покупается новый компьютер (компьютеры) и мы имеем множество слабо связанных вычислительных “островков”. Связывание их в единый “континент” даже в рамках одной организации позволило бы резко повысить эффективность использования оборудования и уменьшить количество компьютеров в организации. Имея такой суперкомпьютер неограниченной мощности, любой пользователь может в любое время и в любом месте попросить столько вычислительных ресурсов, сколько ему требуется (и сколько он может оплатить), решить свои задачи и освободить ресурс.
Очень часто в связи с концепцией GRID упоминают термин “computing utility” т е. коммунальная услуга, поскольку GRID позволяет получить вычислительные ресурсы также, как мы получаем другие коммунальные услуги, такие как электричество, газ вода и т д. Когда нам нужно электричество, мы просто находим розетку, включаем прибор и затем оплачиваем по счетчику потребленную электроэнергию. При этом мы не задумываемся о том, на каких ГЭС, ГРЭС, АЭС и т д. электроэнергия была выработана, по каким линиям ЛЭП шла и т д. Концепция GRID позволяет точно также получать и использовать вычислительные ресурсы.
Часто в связи с концепцией GRID также используют термин “виртуализация”. Действительно, в GRID мы работаем не с множеством мелких компьютеров, а с одним виртуальным суперкомпьютером, не с множеством дисков, на которых лежат наши файлы и базы данных, а с единой виртуальной областью хранения данных (огромным виртуальным диском), которая образуется из множества отдельных дисков.
Итак, с точки зрения пользователя GRID не важно, где размещаются данные и какой компьютер будет обрабатывать его запросы. Главное – это то, что пользователь потребовал информацию или выполнение вычислений и получил результат.
Рис. 1. GRID
Концепцию GRID описали в своих статьях “Анатомия GRID” и “Физиология GRID” [1, 2] американские ученые Фостер, Кессельман, Ник и Тукке. Они так определили термин Computing Grid в 1998 г.: “Вычислительная Grid – это программно-аппаратная инфраструктура, которая обеспечивает из любого места в мире надежный, согласованный и недорогой доступ к высокоэффективным вычислительным ресурсам”. Отметим слово “недорогой” в этом определении, поскольку появившаяся сегодня возможность использовать в качестве элементов GRID недорогие вычислительные элементы с недорогой операционной системой дала толчок развитию коммерческого использования GRID вычислений.
В 2000 г Фостер и Тукке определили GRID как “Скоординированное разделение ресурсов и решение проблем в динамической, многокомпонентной виртуальной организации ”, где виртуальная организация – это группа предприятий, объединяющих свои вычислительные ресурсы в единую GRID и совместно их использующая.
Однако еще задолго до появления первых работ по GRID один из основоположников интернет Лен Клейнрок (Len Kleinrock) предсказывал в 1969 г. “Мы, возможно, станем свидетелями распространения ‘computer utilities’ (вычислительных коммунальных услуг), которые, также как сегодня телефонные услуги будут доступны во всех домах и офисах по всей стране”. Прошло чуть меньше 30 лет и это предсказание начинает сбываться.
Мы не случайно приводим здесь классические определения концепции GRID. Конечно все вышеописанное – это идеальная картина. Надо различать идеальное понимание термина GRID и его реальную реализацию. Так сегодня невозможно еще создать единый мировой суперкомпьютер, но начать реализовывать эту концепцию в рамках организации уже возможно. Далее мы посмотрим, что из этих идеальных понятий реализуемо уже сегодня, а что может быть реализовано только в далеком будущем.
Если со стороны пользователя GRID все просто (попросил ресурс – получил его), то со стороны организаций, предоставляющих этот единый вычислительный ресурс, необходимо обеспечить ряд требований.
Необходимо обеспечить, что требования на выделение вычислительных ресурсов всегда удовлетворяются, а ресурсы полностью используются, т. е. не должно возникать ситуации, когда пользователь будет ждать выделения ресурса. Еще более сложная задача – это сделать информацию, необходимую для выполнения вычислений, доступной в то время, когда она необходима, и в том месте, где она необходима. Так если речь идет о быстрой переброске огромных баз данных в ту часть света, где есть свободные вычислительные мощности, то сегодня эта задача невыполнима. Скорость и пропускная способность сегодняшних сетей передачи данных этого не позволяет. Но в рамках предприятия и ограниченного числа файлов и баз данных решить эту задачу можно.
Необходимо также обеспечить постоянную доступность и работоспособность системы GRID. Выход из строя отдельных ее элементов не должен останавливать работу приложений. Некоторые решения в этой области, такие как серверный кластер - Real Application Cluster, кластеры серверов приложений, резервные базы данных и т. д. уже сегодня позволяют обеспечить высокую надежность [6].
Основная идея GRID – обеспечить эффективное использование составляющих ее ресурсов. Для этого оборудование и программное обеспечение GRID должно определять загруженность отдельных элементов GRID и балансировать нагрузки, направляя пользователей и приложения на менее загруженные узлы, подключая новые узлы и т. д.
Элементы GRID должны быть дешевыми и простыми, только это позволит оценить экономическую выгоду от внедрения GRID.
Как уже упоминалось выше, создать сегодня мировую коммерческую GRID мы еще не можем. Поэтому выделим три этапа построения GRID.
Самый простой этап – это GRID одного центра обработки данных (ЦОД). ЦОД предприятия уже сегодня может начать объединять свои компьютеры в единую GRID для того, чтобы потом предоставлять интегрированную коммунальную услугу внутри предприятия.
Следующим шагом будет объединение различных ЦОД предприятия в единую GRID уровня предприятия. А вот третьим этапом, который наступит не ранее чем через 10 лет, будет объединение GRID предприятий в единую GRID города, страны и т д. Здесь придется решать огромное количество организационных, правовых, финансовых вопросов. Например, вопросы защиты информации и взаиморасчетов между предприятиями могут сильно тормозить эту работу.
Концепция GRID и реальность
Итак, в этой статье мы рассмотрели концепцию GRID и попытки ее реализации компанией Oracle с помощью продукта Oracle 10G. Понятно, что 10G – только первый шаг на длинном пути реализации GRID-вычислений. Из статьи видно, что сегодняшние предложения по реализации GRID сильно отличаются от идеальной концепции и сужают ее, однако они позволяют уже сейчас начать пользоваться преимуществами GRID. Почему же реальность так далека от концепции? Дело в том, что многие идеи концепции пока еще неосуществимы в промышленном масштабе.
Идеальная GRID должна быть географически распределена (объединять компьютеры всего мира, независимо от расстояния между ними). К сожалению, сегодняшние сети передачи данных не позволяют это реализовать. Невозможно осуществить быструю и надежную работу американских серверов с БД, размещенными в России, так, как будто все они находятся в одном здании. Невозможно быстро перебрасывать большие объемы информации и огромные БД из Америки в Россию для выполнения вычислений, требующих дополнительного вычислительного ресурса.
Концепция GRID подразумевает объединение в единый вычислительный ресурс самых разных типов компьютеров с различными операционными системами. Сегодня большинство фирм-производителей программного обеспечения для GRID позволяет объединить в GRID только компьютеры одного типа (например, GRID HP серверов, GRID Intel компьютеров с Linux, GRID Blade ферм и т д). Конечно мы можем уже сегодня создать большую распределенную GRID, состоящую из однородных участков (например, участок Blade ферм с Linux и участок серверов Sun Solaris), но обмен данными между участками будет сложен, а объединение их в единый ресурс пока невозможно. Т е эта GRID будет состоять из нескольких слабо связанных между собой участков.
Еще одна проблема GRID – это смешивание двух разных понятий: GRID как единый суперкомпьютер и GRID как коммунальная услуга. Если первое пока невозможно, то элементы второго мы можем видеть уже сегодня.
Идею “заплати и получи нужный объем услуг” реализует сегодня услуга по аутсорсингу или хостингу приложений. Компьютеры, операционные системы, СУБД, услуги по администрированию, установке ПО, сопровождению, настройке приложений предоставляет компания, продающая услуги аутсорсинга. Пользователь лишь оплачивает услугу и через интернет или канал связи работает с приложением, не заботясь о том, где и как оно установлено. Кстати, Oracle имеет ряд механизмов для использования его в таком режиме (это, например, механизмы аутентификации, виртуальной частной БД (VPD), Connection Pooling, трехуровневая архитектура и т д). В России компания DataFort обеспечивает услуги по аутсорсингу приложений на Oracle.
Идею получения информации в любое время и из любого места в мире, тоже сегодня можно реализовать, используя интернет доступ к ресурсам. Действительно, работая с интернет-приложениями, мы можем в любое время и в любой части света выйти с компьютера, имеющего Web броузер, в интернет и работать с приложением. Конечно это пример разделения доступа (интернета), а не вычислительных ресурсов (это обеспечивает GRID), но идею доступа отовсюду реализует успешно.
Таким образом, понятно, что элементы однородной корпоративной GRID можно начать реализовывать уже сегодня, причем для экономии средств это лучше делать на основе дешевых Intel машин или Blade компьютеров.
Для реализации же идеальной концепции GRID придется еще решить огромное множество проблем (кроме выше перечисленных), и не факт, что некоторые из них разрешимы. Среди этих проблем хотелось бы упомянуть такие, как:
единая авторизация и аутентификация пользователей (если в рамках ЦОД и однородной GRID это осуществимо, то на глобальном уровне реализовать это более сложно;
создание единого пространства имен (единого для всего мира);
учет использования вычислительных ресурсов и принципы их оплаты. Пока эти вопросы проработаны слабо;
управление правами использования ресурсов, выдача привилегий, установка приоритетов. Даже в рамках одной организации решить эту проблему сложно, а уж в мировом масштабе и подавно;
защита “своих” данных на компьютерах GRID. Немногие организации допустят даже потенциальную возможность доступа через GRID к их конфиденциальной информации.
А ведь еще есть масса нерешенных юридических и политических вопросов объединения вычислительных ресурсов различных владельцев. Они тоже навряд-ли разрешимы в ближайшее время. Поэтому представляется очевидным, что сегодня наиболее актуально говорить о GRID ЦОД или предприятия, но даже такая GRID позволит получить ряд конкурентных преимуществ и сэкономить деньги.
