Иерархическая модель
Первые иерархические и сетевые СУБД были созданы в начале 60-х годов. Причиной послужила необходимость управления миллионами записей (связанных друг с другом иерархическим образом), например при информационной поддержке лунного проекта Аполлон. Среди реализуемых на практике СУБД этого типа преобладает система IMS (Information Management System компании IBM) (На данный момент это самая распространенная СУБД из всех данного типа). Применяются и другие иерархические системы: TDMS (Time-Shared Date Management System) компании Development Corporation; Mark IV Multi - Access Retrieval System компании Control Data Corporation; System - 2000 разработки SAS-Institute.
Отношения в иерархической модели данных организованы в виде совокупностей деревьев, где дерево - структура данных, в которой тип сегмента потомка связан только с одним типом сегмента предка. Графически: Предок - точка на конце стрелки, а Потомок - точка на острие стрелки. В базах данных определено, что точки - это типы записей, а стрелки представляют отношения один - к - одному или один - ко - многим.
К ограничения иерархической модели данных можно отнести:
Отсутствует явное разделение логических и физических характеристик модели; Для представления неиерархических отношений данных требуются дополнительные манипуляции; Непредвиденные запросы могут требовать реорганизации базы данных.
Ядро системы управления реляционной базой данных (RDBMS).
Две важные части архитектуры RDBMS - ядро, которое является программным обеспечением, и словарь данных, который состоит из структур данных системного уровня, используемых ядром, управляющим базой данных.
RDBMS можно рассматривать как операционную систему (или подсистему), разработанную специально для управления доступом к данным; ее основные функции - хранение, выборка и обеспечение безопасности данных. Подобно операционной системе, СУБД Oracle управляет доступом одновременно работающих пользователей базы данных к некоторому набору ресурсов. Подсистемы RDBMS очень схожи с соответствующими подсистемами ОС и сильно интегрированы с предоставляемыми базовой ОС сервисными функциями доступа на машинном уровне к таким ресурсам, как память, центральный процессор, устройства и файловые структуры.
RDBMS поддерживают собственный список авторизованных пользователей и их привилегий; управляют кэшем памяти и страничным обменом; управляют блокировкой разделяемых ресурсов; принимают и планируют выполнение запросов пользователя; управляют использованием табличного пространства.
На рис.31. показаны основные подсистемы ядра Oracle, управляющего базой данных.

Рис.31. Структура ядра СУБД Oracle.
Итак, база данных - собрание данных, между которыми существуют (смысловые) связи. Физическое расположение и реализация базы данных прозрачны для прикладных программ; физическую базу данных можно перемещать и реорганизовывать и это не окажет влияния на работоспособность программ.
Физически база данных Oracle - не более чем набор файлов где-то на диске. Расположение этих файлов несущественно для функционирования (хотя важно для производительности) базы данных.
Логически база данных - это множество пользовательских разделов Oracle, каждый из которых идентифицируется именем пользователя (с паролем), уникальным в данной БД. На рис.29. показана архитектура Oracle.
Существуют три основные группы файлов на диске, составляющие базу данных.
Файлы базы данных Управляющие файлы Журнальные файлы
Наиболее важные из них - файлы базы данных, где располагаются собственно данные. Управляющие и журнальные файлы поддерживают функционирование архитектуры. Для доступа к данным БД все три набора файлов должны присутствовать, быть открытыми и доступными Oracle. Если эти файлы отсутствуют, обратиться к базе данных нельзя, и администратор базы данных должен будет восстанавливать часть или всю БД, используя файлы резервных копий (если их сделали!). Все эти файлы двоичные.
После инсталляции СУБД (об этапах установки подробно написано в [ ]) администратор имеет возможность войти в СУБД используя учетные записи SYS или SYSTEM, с парролем: master или manager, для создание учетных записей других пользовтаелей, при этом пароли учетных записей SYS и SYSTEM необходимо сразу же изменить.
Для работы с файлами базы данных на машине должны существовать системные процессы Oracle и один (или больше) пользовательский процесс.
Системные процессы Oracle (их называют фоновыми) обеспечивают функционирование пользовательских процессов - выполняют функции, которые иначе пришлось бы выполнять пользовательским процессам непосредственно.
Дополнительно к фоновым процессам Oracle в простейшем случае на одно подключение к базе данных должен существовать один пользовательский процесс. Пользователь должен подключиться к базе данных прежде чем он сможет обратиться к какому-либо объекту. Если один пользователь регистрируется в Oracle, используя SQL*Plus, другой пользователь выбирает Oracle Forms, а еще один пользователь открывает электронную таблицу Excel, значит имеется три пользовательских процесса для работы с этой базой данных - по одному для каждого подключения.
Oracle использует память системы (как реальную, так и виртуальную) для выполнения пользовательских процессов и самого программного обеспечения СУБД, и для кэширования объектов данных. Существуют две главные области памяти Oracle:
разделяемая память, которая используется всеми процессами, работающими с базой данных, локальная память для каждого пользовательского процесса.
Системная память.
Системная память. Oracle для всей базы данных называется SGA (system global агеа - системная глобальная область или shared global агеа - разделяемая глобальная область). Данные и управляющие структуры в SGA являются разделяемыми, и все фоновые процессы Oracle и пользовательские процессы могут к ним обращаться.
Память пользовательского процесса. Для каждого подключения к базе данных Oracle выделяет PGA (process global агеа - глобальную область процесса или program global агеа - глобальную область программы) в памяти машины и, кроме того, - PGA для фоновых процессов. Эта область памяти содержит данные и управляющую информацию одного процесса и между процессами не разделяется.
Особенности функционирования АИС на платформе Sun.
Solaris - это современная операционная система UNIX клона. Примечательно, что она, опережая свое время, позволяет работать с 64-разрядными прикладными программами и имеет собственные расширения, которые помогают ей выдерживать высокие пользовательские нагрузки Web-узлов с интенсивным обменом информацией. В Solaris также предусмотрены замечательные возможности применения серверных прикладных программ и средств разработки сторонних производителей.

Рис.23. Функциональная схема информационной системы на базе Solaris
Ключевой момент для понимания различий между платформами Linux, Microsoft и Sun - способ, которым серверные программы каждой из них обрабатывают большое число подключений. Обычно это делается в многопотоковом режиме. Многопотоковый режим возникает, когда прикладная программа (также называемая процессом) содержит множество небольших блоков исполняемого кода, работающих независимо друг от друга и, возможно, одновременно на разных процессорах. Эти потоки могут совместно пользоваться ресурсами и представляют собой способ организации программы, позволяющий одновременно выполнять несколько задач.
Модель потоков Solaris весьма сложна. Она состоит из потоков на уровне ядра (kthreads) - реальных объектов, передаваемых отдельному процессору; потоков на пользовательском уровне и промежуточной структуры, называемой облегченным (lightweight) процессом. Это позволяет тонко управлять структурой прикладной программы и реализации в ней прикладной многозадачности.
Преимущества электронного документооборота
К основным преимуществам электронного документооборота можно отнести следующие:
Полный контроль за перемещением и эволюцией документа, регламентация доступа и способ работы пользователей с различными документами и их отдельными частями. Уменьшение расходов на управление за счет высвобождения (на 90% и более) людских ресурсов, занятых различными видами обработки бумажных документов, снижение бюрократической волокиты за счет маршрутизированного перемещения документов и жесткого контроля за порядком и сроками прохождения документов. Быстрое создание новых документов из уже существующих. Поддержка одновременной работы многих пользователей с одним и тем же документом, предотвращение его потери или порчи. Сокращение времени поиска нужных документов.
Использование АИС может рассматриваться в качестве базы для общего совершенствования управления предприятием. При этом управление предприятием реализует следующие основные функции:
обслуживание клиентов; разработка продукции; учет и контроль за деятельностью предприятия; финансовое обеспечение деятельности предприятия и т.д.
Сетевая модель.
Сети - естественный способ представления отношений между объектами. Они широко применяются в математике, исследованиях операций, химии, физике, социологии и других областях знаний. Сети обычно могут быть представлены математической структурой, которая называется направленным графом. Направленный граф имеет простую структуру. Он состоит из точек или узлов,соединенных стрелками или ребрами. В контексте моделей данных узлы можно представлять как типы записей данных, а ребра представляют отношения один-к -одному или один-ко-многим. Структура графа делает возможными простые представления иерархических отношений (таких, как генеалогические данные) .
Сетевая модель данных - это представление данных сетевыми структурами типов записей и связанных отношениями мощности один-к-одному или один-ко-многим. В конце 60-х конференция по языкам систем данных (Conference on Data Systems Languages, CODASYL) поручила подгруппе, названной Database Task Group (DTBG), разработать стандарты систем управления базами данных. На DTBG оказывала сильное влияние архитектура, использованная в одной из самых первых СУБД, Iategrated Data Store (IDS), созданной ранее компанией General Electric.Это привело к тому, что была рекомендована сетевая модель.
Документы Database Task Group (DTBG) (группа для разработки стандартов систем управления базами данных) от 1971 года остается основной формулировкой сетевой модели, на него ссылаются как на модель CODASYL DTBG. Она послужила основой для разработки сетевых систем управления базами данных нескольких производителей. IDS (Honeywell) и IDMS (Computer Associates) - две наиболее известных коммерческих реализации. В сетевой модели существует две основные структуры данных: типы записей и наборы:
Тип записей. Совокупность логически связанных элементов данных. Набор. В модели DTBG отношение один-ко-многим между двумя типами записей. Простая сеть. Структура данных, в которой все бинарные отношения имеют мощность один-ко-многим. Сложная сеть. Структура данных, в которой одно или несколько бинарных отношений имеют мощность многие-ко-многим. Тип записи связи. Формальная запись, созданная для того, чтобы преобразовать сложную сеть в эквивалентную ей простую сеть.
В модели DBTG возможны только простые сети, в которых все отношения имеют мощность один-к-одному или один-ко-многим. Сложные сети, включающие одно или несколько отношений многие-ко-многим, не могут быть напрямую реализованы в модели DBTG. Следствием возможности создания искусственных формальных записей является необходимость дополнительного объема памяти и обработки, однако при этом модель данных имеет простую сетевую форму и удовлетворяет требованиям DBTG.
Типы обрабатываемых данных
Типы данных обрабатываемых СУБД Oracle представлены в таблице.
Таблица 2. Типы обрабатываемых данных.
| Тип данных | Описание |
| СНАR(size) | Символьная строка фиксированной длины, имеющая максимальную длину size символов. Длина по умолчанию 1, максимальная -255. |
| СНАRАСТЕR(size) | То же, что и CHAR. |
| DATE | Правильные даты в интервале от 1 января 4712 года до н.э. до 31 декабря 4712 года. |
| LONG | Символьные данные переменной длины до 2 Гигабайт. |
| LONG RAW | Двоичные данные переменной длины вплоть до 2 Гигабайт или 231-1. |
| MLSLABEL | Используется в Trusted ORACLE. |
| NUMBER(p,s) | Число, имеющее p значащих цифр и масштаб s. р может быть от 1 до 38. s может принимать значения от -84 до 127. |
| RAW(size) | Двоичные данные длиной size байт. Максимальное значение для size - 2000 байт. Параметр те для RAW обязателен. |
| RAW MLSLABEL | Используется в Trusted ORACLE. |
| ROWID | Значения псевдостолбца ROWID. |
| VARCHAR2(size) | Символьная строка переменной длины, имеющая максимальную длину size символов. Длина по умолчанию 1, максимальная - 2000. |
| VARCHAR(size) | То же что и VARCHAR2. |
Извлекать данные можно также и из псевдостолбцов (табл.3), которые похожи на столбцы таблиц, но их значения нельзя изменять при помощи операторов DML.
Таблица 3. Псевдостолбцы.
| Название столбца | Возвращаемое значение |
| sequence.CURRVAL | Текущее значение sequence в данном сеансе (sequence.NEXTVAL должен быть выбран). |
| sequence.NEXTVAL | Следующее значение sequence в текущем сеансе. |
| [table.]LEVEL | 1 - для корня дерева, 2 - для узлов второго уровня и так далее. Используется в операторе SELECT в иерархических запросах. |
| [table.]ROWID | Значение, которое идентифицируют строку в таблице table уникальным образом. Значения псевдостолбца ROWID имеют тип данных ROWID, а не NUMBER и не CHAR. |
| ROWNUM | Порядковый номер строки среди других строк, выбираемых запросом. ORACLE выбирает строки в произвольном порядке и приписывает значения ROWNUM, прежде чем строки будут отсортированы предложением ORDER BY. |
Требования к именам объектов базы данных
должны иметь длину от 1 до 30 бант, за исключением имен баз данных, длина которых ограничена 8 байтами; не могут содержать кавычек; не могут совпадать с именами других объектов.
Имена, которые всегда заключены в двойные кавычки, могут нарушать, приведенные ниже правила. В противном случае, имена
должны начинаться с букв A-Z; могут содержать только символы A-Z, 0-9, _, $ и #; не могут дублировать зарезервированные слова SQL.
Различие между прописными и строчными буквами учитывается только в именах, заключенных о двойные кавычки.
Операции и их приоритеты
Арифметические операции
Ограничительные условия, поддерживающие целостность базы данных
Как следует из определения ссылочной целостности при наличии в ссылочных полях двух таблиц различного представления данных происходит нарушение ссылочной целостности, такое нарушение делает информацию в базе данных недостоверной. Чтобы предотвратить потерю ссылочной целостности, используется механизм каскадных изменений (который чаще врего реализуется специальными объектами СУБД - триггерами). Данный механизм состоит в следующей последовательсности действий:
при изменении поля связи в записи родительской таблицы следует синхронно изменить значения полей связи в соответствующих записях дочерней таблицы; при удалении записи в родительской таблицы следует удалить соответствующие записи и в доцерней таблице.
Поцесс нормализации
Нормализация -
процесс приведения реляционных таблиц к стандартному виду. В базе данных могут присутствовать такие проблемы как:
Избыточность данных.Повторение данных в базе данных. Аномалия обновления. Противоречивость данных, вызванная их избыточностью и частичным обновлением. Аномалия удаления. Непреднамеренная потеря данных, вызванная удалением других данных. Аномалия ввода. Невозможность ввести данные в таблицу, вызванная отсутствием других данных.
Для решения этих проблем применяют разбиение таблиц - разделение таблицы на несколько таблиц. Для того чтобы это сделать пользуются нормальными формами или правилами структурирования таблиц.
Первая нормальная форма
Реляционная таблица находится в первой нормальной форме (1НФ), если значения в таблице являются атомарными для каждого атрибута таблицы, т.е. такими значениями, которые не являются множеством значений или повторяющейся группой. В определении Кодда реляционной модели уже заложено, что реляционные таблицы находились в 1НФ,
Вторая нормальная форма.
Реляционная таблица находится во второй нормальной форме (2НФ), если никакие неключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, 2НФ может оказаться нарушена только в том случае, когда ключ составной.
Функциональная зависимость.Значение атрибута в кортеже однозначно определяет значение другого атрибута в кортеже.
Более формально можно определить функциональную зависимость следующим образом: если А и В - атрибуты в таблице В, то запись ФЗ (функциональную зависимость): А - " В обозначает, что если два кортежа в таблице В имеют одно и то же значение атрибута А, то они имеют одно и то же значение атрибута В. Это определение такжеприменимо,если А и В - множества столбцов, а не просто отдельные столбцы.
Атрибут в левой части ФЗ называется детерминантом, так как его значение определяет значение атрибута в правой части. Ключ таблицы является детерминантом, так как его значение однозначно определяет значение каждого атрибута таблицы.
Процесс разбиения на две 2НФ-таблицы состоит из следующих шагов:
Создается новая таблица, атрибутами которой будут атрибуты исходной таблицы, входящие в противоречащую правилу ФЗ. Детерминант ФЗ становится ключом новой таблицы. Атрибут, стоящий в правой части ФЗ, исключается из исходной таблицы. Если более одной ФЗ нарушают 2НФ, то шаги 1 и 2 повторяются для каждой такой ФЗ. Если один и тот же детерминант входит в несколько ФЗ, то все функционально зависящие от него атрибуты помещаются в качестве неключевых атрибутов в таблицу, ключом которой будет детерминант.
Третья нормальная форма
Реляционная таблица имеет третью нормальную форму (ЗНФ), если для любой ФЗ: Х - У Х является ключом. Заметим, что любая таблица, удовлетворяющая ЗНФ, также удовлетворяет и 2НФ. Однако обратное неверно.
Критерийнормальной формы Бойса-Кодда (НФБК) утверждает, что таблица удовлетворяет ЗНФ, если в ней нет транзитивных зависимостей. Транзитивная зависимость возникает, если неключевой атрибут функционально зависит от одного или более неключевых атрибутов. То есть этот критерий учитывает следующие два случая:
Неключевой атрибут зависит от ключевого атрибута, входящего в составной ключ (критерий нарушения 2НФ). Ключевой атрибут, входящий в составной ключ, зависит от неключевого атрибута.
Таким образом, если таблица удовлетворяет НФБК, то она также удовлетворяет ЗНФ в смысле транзитивных зависимостей и 2НФ.
Четвертая нормальная форма
Таблица имеет четвертую нормальную форму (4НФ), если она имеет ЗНФ и не содержит многозначных зависимостей. Поскольку проблема многозначных зависимостей возникает в связи с многозначными атрибутами, то мы можем решить проблему, поместив каждый многозначный атрибут в свою собственную таблицу вместе с ключом, от которого атрибут зависит.
Пятая нормальная форма.
Пятая нормальная форма (5НФ) была предложена для того, чтобы исключить аномалии, связанные с особым типом ограничительных условий, называемых совместными зависимостями. Эти зависимости имеют в основном теоретический интерес и сомнительную практическую ценность. Следовательно, пятая нормальная форма в действительности не имеет практического применения.
Нормальная форма область/ключ.
Таблица имеет нормальную форму область/ключ (НФОК), если любое ограничительное условие в таблице является следствием определений областей и ключей. Однако не был дан общий метод приведения таблицы к НФОК.
В качестве примера, рассмотрим структуру реляционной базы данных, описывающей "отношения" пациентов и докторов в произвольной клинике (область приложения примера выбрана из-за того, что в сертификационных тестах Oracle аналогичные примеры встречаются очень часто). Пусть существует некая клиника, основные характеристики которой описываются в таблице CLINICS, в данной клинике работают доктора, основные характеристики которых описывает таблица DOCTORS. Данные пациентов клиники хранятся в таблице PATIENTS. Взаимосвязи между таблицами представлены на рис.10. (Для упрощения предполагается, что у доктора может быть несколько пациентов, которые не являются пациентами других докторов, для реализации реальной картины, когда один пациент может относиться к нескольким разным докторам, между таблицами DOCTORS и PATIENTS необходимо включить дополнительную связывающую таблицу).

Рис.10. Диаграмма, иллюстрирующая отношения таблиц АИС.
| № | Наименование столбца | Описание |
| Таблица CLINICS | ||
| 1 | CS_NNN | Индекс |
| 2 | CS_REG_NUMBER | Регистрационный номер |
| 3 | CS_CITY_NNN | Ссылка на справочник городов и регионов |
| 4 | CS_NAME | Наименование клиники |
| 5 | CS_ADDRESS | Адрес клиники |
| 6 | CS_PHONE_NUMBER | Номер телефона |
| 7 | CS_TYPE | Профиль клиники |
| Таблица DOCTORS | ||
| 1 | DC_NNN | Индекс |
| 2 | DC_NAME | Ф.И.О. доктора |
| 3 | DC_CS_NNN | Ссылка на таблицу CLINICS |
| 4 | DC_DIPLOM_NUMBER | Номер диплома |
| 5 | DC_SPECIALTY_NNN | Ссылка на справочник специальностей |
| 6 | DC_SHTAT_NNN | Ссылка на штатное расписание |
| 7 | DC_CALENDAR_NNN | Ссылка на расписание приема |
| Таблица PATIENTS | ||
| 1 | PT_NNN | Индекс |
| 2 | PT_REG_NUMBER | Регистрационный номер |
| 3 | PT_NAME | Ф.И.О. пациента |
| 4 | PT_ADDRESS | Адрес пациента |
| 5 | PT_POLIS_NUMBER | Номер полиса |
| 6 | PT_PHONE_NUMBER | Номер телефона |
| 7 | PT_BIRTHDATE | Дата рождения |
| 8 | PT_FIRST_VISIT | Дата первого визита |
| 9 | PT_LAST_VISIT | Дата последнего визита |
| 10 | PL_PT_NNN | Ссылка на таблицу платежей |
| Таблица PAYMENTS | ||
| PL_NNN | Индекс | |
| PL_ACCOUNT_NUMBER | Номер расчетного счета | |
| PL_PAY_NNN | Ссылка на таблицу расчетов |
Представленная структура, конечно, не обладает функциональной полнотой с точки зрения проектирования АИС клиники, с ее помощью мы лишь рассмотрим различные типы отношений в реляционных СУБД.
Перед тем, как перейти к рассмотрению вопросов стандартизации и целостности данных в РСУБД несколько рекомендаций по выбору наименований таблиц и полей. Внимательно взглянув на описание таблиц можно заметить, что генерация наименований таблиц и столбцов подчиняется некоторой синтаксической конструкции, которая в общем виде может быть представлена следующим образом:
Для таблиц: <Псевдоним АИС>_<Псевдоним модуля АИС>_:_<Псевдоним подмодуля>_<Имя таблицы>
Например, если бы мы разрабатывали АИС клиники c сокращенным названием CSL, то все таблицы входящие в данную систему было бы целесообразно называть CSL_<имя модуля>_<имя таблицы>.
Для столбцов: <Псевдоним таблицы>_<имя столбца>.
Например, как показано на рис.10. Регистрационный номер пациента храниться в поле PT_REG_NUMBER, таблицы PATIENTS, имеющий псевдоним PT.
Конечно, использование этих не хитрых правил не является обязательным, но позволяет значительно облегчить читаемость разработанной информационной структуру. Предположите, как было бы все, если бы поля таблиц назывались P111, P112 и т.п., а ведь такие вещи встречаются практически очень часто, например в FoxPro 2.6.
Перейдем к рассмотрению вопросов стандартизации и обеспечения ссылочной целостности реляционных таблиц.
Преобразование функциональной модели в реляционную.
В разделе 1.3. нами были рассмотрены основные этапы разработки автоматизированной информационной системы, в разделе 1.3.1 мы разработали функциональную модель АИС, теперь, после того как мы рассмотрели основные оложения терии баз данных, пришло время заняться непосредственно формализацией выделенных бизнес-процессов, операций и т.п. Результатом первого этапа проектирования АИС является функциональная модель системы содержащая множество объектов (процессов, операций), их атрибутов.
Объектное множество с атрибутами может быть преобразовано в реляционную таблицу с именем объектного множества в качестве имени таблицы и атрибутами объектного множества в качестве атрибутов таблицы. Если некоторый набор этих атрибутов может быть использован в качестве ключа таблицы, то он выбирается ключом таблицы. В противном случае мы добавляем к таблице атрибут, значения которого будут однозначно определять объекты-элементы исходного объектного множества, и который, таким образом, может служить ключом таблицы.
Модели информационного пространства предприятия.
Комплексная автоматизация этих функции требует создания единого информационного пространства предприятия, в котором сотрудники и руководство могут осуществлять свою деятельность, руководствуясь едиными правилами представления и обработки информации в документном и бездокументном виде.
Для этого в рамках предприятия требуется создать единую информационную систему по управлению информацией или единую систему управления документами, включающую возможности:
удаленной работы, когда члены одного коллектива могут работать в разных комнатах здания или в разных зданиях; доступа к информации, когда разные пользователи должны иметь доступ к одним и тем же данным без потерь в производительности и независимо от своего местоположения в сети; средств коммуникации, например: электронная почта, факс, печать документов; сохранения целостности данных в общей базе данных; полнотекстового и реквизитного поиска информации; открытость системы, когда пользователи должны иметь доступ к привычным средствам создания документов и к уже существующим документам, созданным в других системах; защищенность информации; удобства настройки на конкретные задачи пользователей; масштабируемости системы для поддержки роста организаций и защиты вложенных инвестиций и т.д.
Начальным этапом создания такой системы является построение модели предметной области или другими словами модели документооборота для конкретного бизнеса и позиционировать в ней свое предприятие.
Определенные ранее направления автоматизации документооборота: поддержка фактографической информации, возможность работы с полнотекстовыми документами, поддержка регламента прохождения документов, определяют трехмерное пространство свойств, где по некоторой траектории движется любой программный продукт данного класса, проходя различные стадии в своем развитии (рис.2.).
Первая ось (F) характеризует уровень организации хранения фактографической информации, которая привязана к специфике конкретного рода деятельности компании или организации. Например: при закупке материальных ценностей происходит оформление товарно-сопроводительных документов (накладных, приемо-передаточных актов, приходных складских ордеров и т.д.), регистрируемых в качестве операционных документов, атрибутика которых очень важна для принятия управленческих решений. Информация из операционных документов используется при сложной аналитической и синтетической обработке, и, в частном случае, может быть получена пользователем через систему отчетов.
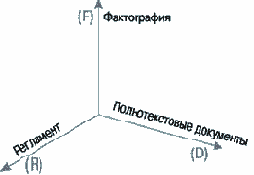
Рис.2. Трехмерное пространство свойств.
Вторая ось (D) - полнотекстовые документы, отражает необходимость организации взаимодействия: формирование и передача товаров, услуг или информации как внутри корпорации, так и вне ее. В этих документах наряду с фактографической информацией содержится слабо структурированная информация, не подлежащая автоматизированной аналитической обработке, такая, например, как форс-мажерные факторы и порядок предъявления претензий при нарушении условий договора. Все взаимоотношения между субъектами бизнеса сопровождаются документами, которые становятся осязаемым отражением результата взаимодействия.
Третья ось (R) вносит в пространство документооборота третье измерение - регламент процессов прохождения документов, а именно: описание того какие процедуры, когда и как должны выполняться. Основа для позиционирования относительно данной оси - набор формальных признаков (атрибутов) и перечень выполнения операций.
Точка в пространстве (F, D, R) определяет состояние системы документооборота и имеет координаты (f,d,r), где f,d и r принадлежат множествам F,D и R, соответственно. Положение этой точки зависит от уровня развития и стадии внедрения системы документооборота на предприятии, а также от его специфики и самих масштабов бизнеса.
Представив модель документооборота именно таким образом, можно, например, зная текущее положение дел с организацией делопроизводства на каждом конкретном предприятии, четко представить, в каких направлениях нужно двигаться дальше, чего недостает в текущий момент и каким образом органично использовать уже существующие системы автоматизации. Например, в одном из московских банков был накоплен большой массив фактографических данных, для обработки которых использовалась современная СУБД, развернутая на мощных, отказоустойчивых серверах - все, казалось бы, должно быть отлично. Однако при работе с внутренними документами наблюдалось дублирование информации: возникали ситуации, когда "никто вроде бы и не виноват", а банк время от времени лишается выгодных клиентов. Причина в том, что точка, отражающая положение системы документооборота для этой организации, имела достаточно большие координаты по оси "F" и, возможно, по оси "D", однако значение координаты по оси "R" было близко к нулю. Конкретным решением в этом случае может быть рассмотрение вопроса о внедрении системы управления регламентом. При этом не надо пока заботится о СУБД (ось "F") или электронных архивах (ось "D") - речь идет только об изменении значения координат по оси "R".
В общем случае, как уже отмечалось, процесс автоматизации делопроизводства на предприятии можно представить в виде кривой в трехмерном пространстве координат F,D,R. Причем, чем круче эта кривая, тем быстрее идет процесс модернизации, а чем больше значения всех трех координат - тем выше уровень автоматизации на корпорации и, как следствие, тем меньше у нее проблем с организацией своей собственной деятельности.
Работоспособна ли данная модель для задания пространства развития неавтоматизированной системы управления документооборотом? Да. Единственно, что в этом случае решается задача не облегчения рутинного труда по перемещению документов, их поиску и регистрации, а упорядочения всей системы документооборота. Новое качество, с которым сегодня ассоциируется возросший интерес к системам электронного документооборота, связано с использованием инструментальных систем, предназначенных для хранения, регистрации, поиска документов, а также для управления регламентом. Чаще ошибочно под новым качеством сегодня понимается простое внедрение отличной от ранее используемой технологии работы с документами, например локальной сети вместо дискет, переносимых с одного компьютера на другой. Вряд ли в этом случае уместно говорить о новом качестве управления предприятием. Кстати, уже упомянутый пример ручной работы режимных служб "почтовых ящиков", прекрасно вписывается в предложенную модель документооборота, а точка, отражающая его состояние, будет иметь координаты (1,1,1) - все равномерно, единственное, что отсутствует - компьютеризация.
Эволюция модели.
Рассмотренная модель документооборота не является застывшим образованием, данным нам в ощущениях - прежде чем сформировалось современное представление о контурах этой модели, она претерпела три основные фазы своей эволюции, две из которых представлены на рис.3., а третья на рис.2.
Фаза первая - фактографическая. Начало любой деятельности знаменуется обычно периодом накопления первичной информации, имеющей жесткую структуру и атрибутику. Условно эту фазу можно представить в виде одной единственной оси.
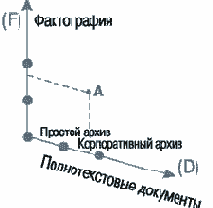
Рис.3. Эволюция бизнес - моделей документооборота.
Точка на этой оси - это текущее состояние системы документооборота организации. Движение по оси вверх характеризует накопление фактографической информации и начиная с определенного момента которого можно отметить второй этап первой фазы - возникновение понятия "операция". Документ теперь представляется как некоторый привязанный к бизнес - процессам предприятия агрегат из имеющихся характеристик (атрибутов). На этом этапе начинается процесс возникновения неравенства между ранее равноправными документами, в частности, документ-основание, а дальнейшее движение по оси приобретает все более операционный оттенок. После возникновения привязки к конкретным бизнес - процессам дальнейшая эволюция документооборота в одномерном пространстве уже невозможна - необходим новый качественный скачок к новой фазе.
Фаза вторая - полнотекстовая. Расширение организации и увеличение круга решаемых задач требуют использования полнотекстовых документов, включающих уже не только тексты, но и любые другие способы представления: графики, таблицы, видео и т.п виды конструкторско-технологической документации. Возникает новая ось - полнотекстовые или, лучше, мультимедийные документы, а точка в новом, уже двумерном, пространстве характеризует систему документооборота предприятия, где кроме фактографической базы документов имеются уже хранилища и архивы информации.
Хранилища позволяют накапливать документы в различных форматах, предполагают наличие их структуризации и возможностей поиска. Если на предприятии уже используется автоматизация, то хранилище - это не что иное, как электронный архив. Движение по оси "полнотекстовые документы" предполагает наращивание атрибутивных возможностей: разграничение доступа, расширение средств поиска, иерархию хранения, классификация. Здесь же возникают такие понятия как электронная подпись, шифрование и т.п.
На данной оси также имеются свои этапы - с определенного момента развития хранилища можно уже говорить не об индивидуальном, а о корпоративном архиве, обслуживающем деятельность рабочих групп. Точка на плоскости эволюции, достигнутой во второй фазе, характеризует систему документооборота, позволяющую отображать фактографическую информацию в виде полнотекстовых документов, имеющих необходимое количество атрибутов. Доступ к этим документам может быть осуществлен по маршруту любого уровня сложности с соблюдением различных уровней конфиденциальности. Если, например, говорить о точке "А", то соответствующее ей состояние системы документооборота позволяет осуществлять синхронизацию работы различных рабочих групп сотрудников корпорации, расположенных на различных площадках. Система для этой точки предполагает также структурирование информации по уровням управления и наличие средств репликации данных. Однако, как только речь пошла о корпорации, двумерного пространства для соответствующей ей системы документооборота опять становится недостаточно - необходим новый скачок к очередной фазе.
Фаза третья - регламентирующая. Нормальный документооборот в масштабах корпорации невозможен без решения вопросов согласования или соблюдения регламента работы. Если ранее, на второй фазе (плоскость) негласно присутствовал лишь один, простейший регламент (нулевая точка) - каждый сотрудник имел доступ к архиву или его части, либо в папку каждому работнику помещалось индивидуальное задание (иначе говоря, было известно только, что документ существует), то сейчас этого недостаточно. Требуется уже интегральная оценка. Необходим, например, контроль за тем, как работник выполнил задание, или как продвигается документ в условиях нелинейного процесса своего согласования (например согласования пакета конструкторско-технологической документации на сборочную единицу).
Третья ось в пространстве документооборота предприятия, как и две другие имеет свое деление на этапы. Первоначальный этап движения по оси характеризуется наличием упрощенного регламента, отображаемого появлением атрибутов, отвечающих за регламент, например: "оплатить до", "действителен для". Количественное накопление атрибутов и расширение возможностей по управлению регламента сопровождается постепенным переходом ко второму этапу, отличительная черта которого - появление системы, специально предназначенной для отслеживания процесса соблюдения регламента. При дальнейшем движении вдоль этой оси можно говорить о появлении единой системы управления проектом. Теперь документ в системе "документооборота" становится вторичным - первична цель бизнеса, сам процесс реализации бизнес - процедур, оставляющий после себя документы.
Оси "F" и "D" определяют специфику деятельности организации, регламентируемую положением третьей координаты (R) пространства модели документооборота. При этом модель не зависит от технологии обработки документов, принятой на предприятии - все решает только цель деятельности, будь то государственная организация, торговая компания и промышленная фирма. В общем случае можно выделить три типа организаций:
Банк и торговая компания: приобретение, наценка, продажа, получение прибыли - главный объект деятельности; бюджетная организация: основная деятельность - формирование документов; промышленное предприятие: закупка сырья, переработка, создание нового продукта, реализация, получение прибыли. Цель деятельности - операция.
Если задачей организации является формирование документов, например мэрия, суд или министерство, то ее позиция в модели будет занимать достаточно высокое положение относительно осей "F" и "D". Кстати, сегодня наибольшей популярностью пользуются именно приложения, ориентированные на автоматизацию деятельности государственных и правительственных административных структур - основная цель которых и состоит в подготовке документов. Однако если рассматривать деятельность коммерческого банка или фирмы задача которой - производство операций, материальных ценностей , то здесь уже все три координаты должны иметь сбалансированные значения.
Рассмотрим в качестве примера основные шаги при разработки функциональной модели типовой АБС. Среди архитектур реализации АБС на сегодня выделят АБС пяти поколений: первые были предназначены для решения задач автоматизации бухгалтерских операций, АБС второго и третьего поколений также реализовывали элементы автоматизированного документооброта, АБС четвертого поколения строились по классической схеме трехзвенной клиент-серверной архитектуры и имели модульную структуру, реализующую концепции docflow. АБС пятого поколения являются информационными системы реилизующими полнофункциональную модель workflow - автоматизации бизнесс-процессов (рис.4,5).
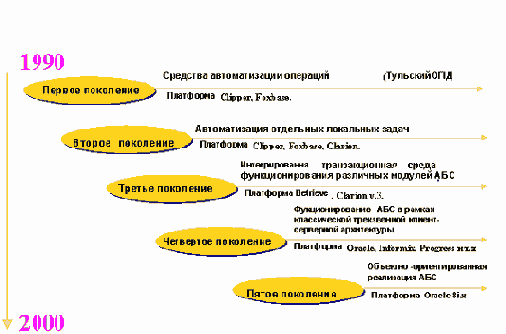
Рис.4. Поколения АБС и их характеристики.

Рис.5.приницпы реализации интеллектуальной инфраструктуры банка.
Схема функциональных бизнес-потоков типовой АБС четвертого поколения представлена на рис.6., а функциональная схема технологических потоков операций на рис.7.

Рис.6. Функциональная схема типовой АБС 4-го поколения.

Рис.7. Функциональная схема технологических потоков операций.
Назначения большинства модулей АБС (рис.6) достаточны понятны, едиснтвенное следует уточнить, что под интернет-банкингом понимает автоматизированная система реализующая технологии busines-to-customers (клиентское обслуживание, включая электронные платежы физических лиц) и bisnes-to-bisnes (обеспечение работы дистрибьюторско-дилерской сети корпораций в режиме on-line коммерции).
Разработав функциональную схему бизнес-потоков, структурировав ее в соотвествии с модульным принципом построения любой системы управления и выделив базовые технологические потоки операций на каждом из уровне модульности (итог: перечень документов и операций обрабатываемых на конкретном рабочем месте, маршруты их движения, контроля и управления), можно приступать к следующему этапу проектирования информационной системы.
Непроцедурный доступ к данным (SQL).
Характерной чертой RDBMS является способность обработки данных как множества; файловые системы и СУБД с другими моделями обрабатывают данные способом "запись-за-записью". С RDBMS можно общаться, используя структурированный язык запросов (Structured Query Language - SQL). SQL - непроцедурный язык, который разработан специально для операций доступа к нормализованным структурам реляционных баз данных. Основное различие между SQL и традиционными языками программирования состоит в том, что операторы SQL указывают, какие операции с данными должны выполниться, а не способ их выполнения.
Особенности функционирования АИС на платформе Microsoft.

Рис.24. Функциональная схема информационной системы на платформе Windows NT.
Microsoft Windows NT Server
Windows NT 4 Server и Internet Information Server (IIS) являются исключительно коммерческой web-платформой, разработанной компанией Microsoft. Данная ОС имеет удобный интуитивно понятный интерфейс взаимодействия с пользователем, что делает её довольно привлекательной для использования. Windows NT 4 Server оснащена службой балансировки нагрузки (Windows NT Load Balancing Services), которая позволяет создавать группу серверов и распределять нагрузку между ними. Пользователи при этом видят только один IP-адрес и полагают, что существует только один сервер. Однако служба Load Balancing Services - это неполноценная кластерная система, поэтому она не способна обеспечить такое высокое быстродействие, как настоящий кластер. Windows NT не может работать с мощными аппаратными и программными средствами кластеров, в том числе с собственной службой Microsoft Cluster Service, продуктами серии Infinity компании IBM и продуктами NonStop производства Compaq. У Microsoft есть продукты всех этапов разработки для Web, однако обычно их заменяют изделиями других фирм. Пакет Allaire ColdFusion 4.0, как среда разработки для Web, - отличный пример этого.
Netscape Enterprise на платформе Windows NT
Netscape Enterprise в среде Windows NT представляет собой Web-сервер, ориентированный на большие нагрузки. Для него имеется множество моделей программирования. Например, помимо общепринятых моделей разработки HTML и CGI в продукте Netscape предусмотрены возможности работы с JavaScript на стороне сервера. Почти все функции сервера Netscape для Solaris работают и на платформе Windows NT.
При тестировании на производительность IIS показал неплохие результаты. Скорость при работе IIS достигнута за счет хорошо организованной обработкой файлового ввода-вывода. Дополняет обработку сообщений в Windows NT возможность асинхронного ввода-вывода, позволяющая обрабатывать запрос одновременно с выполнением операций ввода-вывода в файл или ЛВС. Подобная функция имеется в Solaris, но до сих пор не полностью реализована в Linux. По результатам теста IIS проигрывает SWW при обработке статических страниц, а Netscape Enterprise на платформе NT оказался менее производительным во всех режимах, чем на платформе Solaris.
Реляционная модель.
В 1970-1971 годах Е.Ф.Кодд опубликовал две статьи, в которых ввел реляционную модель данных и реляционные языки обработки данных - реляционную алгебру и реляционное исчисление.
Реляционная алгебра Процедурный язык обработки реляционных таблиц. Реляционное исчисление Непроцедурный язык создания запросов.
Все существующие к тому времени подходы к связыванию записей из разных файлов использовали физические указатели или адреса на диске. В своей работе Кодд продемонстрировал, что такие базы данных существенно ограничивают число типов манипуляций данными. Более того, они очень чувствительны к изменениям в физическом окружении. Когда в компьютерной системе устанавливался новый накопитель или изменялись адреса хранения данных, требовалось дополнительное преобразование файлов. Если к формату записи в файле добавлялись новые поля, то физические адреса всех записей файла изменялись. То есть такие базы данных не позволяли манипулировать данными так, как это позволяла бы логическая структура. Все эти проблемы преодолела
Особенности функционирования АИС на основе Linux.

Рис.25. Функциональная схема информационной системы на платформе Linux.
Все больше растет популярность Linux и её респектабельность как платформы разработки для Web и корпоративных сред. Linux характеризуется рядом преимуществ, таких как широкое сообщество разработчиков открытого кода, поддержка многих моделей комплектующих, и, главная особенность состоит в том, что Linux полностью бесплатная ОС. Linux является разновидностью Unix и изначально создавалась для работы в сетях. В каждой новой версии Linux появляются некоторые усовершенствования, направленные на повышение масштабируемости и производительности серверных прикладных программ.
Apache и Stronghold
Для тестов в среде Linux был использован Stronghold Web Server 2.4.1 компании C2Net. Stronghold - это сервер с возможностями применения технологии SSL, в основе которого лежит Web-сервер Apache. Сервер Stronghold обладает всеми преимуществами Apache, в том числе мощными средствами обеспечения работы с виртуальными базовыми машинами (способность одного web-сервера обслуживать несколько машин одновременно).
Платформа Stronghold, подобно Linux, имеет заслуженную репутацию надежной и стабильной системы. Но Stronghold - и, следовательно, Apache - не оптимизированы для многопроцессорных сред. Поэтому Web-узлы, основанные на серверах Apache, лучше масштабировать путем добавления серверов, а не процессоров.
Напротив, IIS и Netscape Enterprise имеют многопотоковую архитектуру, которая масштабируется на несколько процессоров одного сервера. При испытаниях на многопроцессорных станциях они, как правило, обгоняли Stronghold.
Apache позволяет тонко настраивать ряд параметров (такие как число процессов, доступных клиентам). Для Apache, как и для других серверов, есть механизм работы сервлетам (Apache Jserv). Механизм работы с сервлетами встраивается в Apache в виде модуля и работает с любой совместимой с JDK 1.1 виртуальной Java-машиной. По производительности дуэт Apache-Linux оказался оптимальным для однопроцессорных систем. По обработке статических страниц он немного уступал SWW и IIS, а по стабильности работы превосходил серверы на платформеWindows NT.
Linux - это функциональность UNIX + пользовательско-ориентированный интерфейс Windows-систем. Большая часть поддерживаемого Linux оборудования - это то, что пользователи реально у себя имеют. Как в результате оказалось - большая часть популярной периферии для 80386/80486 поддерживается (действительно, Linux поддерживает оборудование, которое в ряде случаев не поддерживают некоторые коммерческие UNIX). Хотя некоторые достаточно экзотические устройства пока не поддерживаются.
Важным вопросом при создании АИС является обеспечение жизнестойкости и надежности работы информационных серверов. В качестве иллюстрации эффективности платформы приведем расчет параметров для сервера с 25000 посетителей в день []. Подсчет загрузки: 24ч*60мин*60 сек=86400 секунд в сутках, если каждый посетитель берет с сервера по 10 документов (*.html + графика) то при равномерном распределении загрузки получается 3 обращения к серверу в секунду. Реальное распределение трафика носит характер кривой Гаусса либо синусоиды (в зависимости от содержания сервера), в максимумах которых загрузка достигает 10-20 обр/с. Для нормальной работы такому серверу необходимо около 400 Mb RAM, при хорошей настройке - не менее 200.
При правильной конфигурации сервера не рекомендуется использовать swap. все должно помещаться в оперативной памяти (имеется ввиду, что у сервера swap-область быть должна, но она обязана быть пустой). Для предотвращения перегрузок рекомендуется пользоваться несколькими правилами, снижающими загрузку сервера. Придерживаясь этих правил можно съэкономить около 30% ресурсов сервера.
Для статической информации всегда ставить last-modified в атрибут выдачу CGI-скриптов - документ без временного штампа не сохраняется в локальном кэше, и постоянно перезаписывается при просмотре. CGI программы хранить в любом каталоге кроме /CGI-BIN/, т.к. proxy-серверы не кэшируют файлы, находящиеся в этих каталогах, и каждый раз вынуждены обращаться к вам на сервер. Устанавливать поле last-modified у русского apache с автоматическим определением кодировки, чтобы на proxy-серверах не оставались файлы в некорректной кодировке. Не применять авторедирект по чарсету в русском apache. Не использовать фреймы, т.к. вместо одного файла появляется минимум 3. Не использовать анимированные *.gif, т.к. некоторые NN обращаются к серверу перед каждым циклом. 404 код не делать cgi-скриптом, 404 код не делать "красивым" - с графическими изображениями и указаниями на прочие разделы, т.к. сошедший с ума робот собирает невероятное количество 404 ошибок, зацикливаясь в них на веки. Создать на сервере файл robot.txt, т.к. это самый запрашиваемый документ на сервере, и иначе порождает массу 404 (см. п. 7). А также разумные роботы слушаются запретов в этом файле, что уменьшает нагрузку на сервер. Не ставить баннеры наверху страницы, т.к. баннер сверху отнимает 1-2 реквеста из 4-х и в итоге грузится вперед тормозя ваши сайтовые картинки. При вызове баннера не обращаться каждый раз к CGI, а подставлять вместо случайного числа любое число, что можно сделать, например, получив дату на JavaScript. Вызывать баннеры программами на Си, т.к. Perl работает медленнее. На одной машине должен размещаться только информационный сервер, не одновременно с почтой и др. сервисами.
На сегодня архитектура Internet/Intranet, в том числе и на платформе LINUX, уже используется при построении корпоративных ИС для решения задач автоматизации управления банками, управления проектированием, управления ТП, АСУ ТП, электронной коммерции, оперативной информации по курсу валют и акций и т.п.
Процедурное расширение языка SQL - PL/SQL.
Oracle Server - полнофункциональная реляционная СУБД, которая идеально подходит для архитектур клиент/сервер и интернет/интранет. Особенности внутренней архитектуры Oracle ориентированы на обеспечение готовности, максимальной пропускной способности, безопасности и эффективного использования ресурсов.
Oracle также присущи черты, связанные с используемым языком программирования, которые способствуют ускорению разработки и улучшению эффективности серверной части приложений:
Один из основных компонентов Oracle Server - его процессор PL/SQL. (PL - Procedural Language - процедурный язык.)
PL/SQL - язык Oracle четвертого поколения, объединяющий структурированные элементы процедурного языка программирования с языком SQL, разработанный специально для организации вычислений в среде клиент/сервер. Он позволяет передать на сервер программный блок PL/SQL, содержаший логику приложения, как оператор SQL, одним запросом. Используя PL/SQL, можно значительно уменьшить объем обработки в клиентской части приложения и нагрузку на сеть. Например, может понадобиться выполнить различные наборы операторов SQL в зависимости от результата некоторого запроса. Запрос, последующие операторы SQL и операторы условного управления могут быть включены в один блок PL/SQL и пересланы серверу за одно обращение к сети.
При этом вся логика приложений делится на клиентскую и серверную части. Серверная часть может быть релаизована в виде функций, хранимых процедур и пакетов.
Функции. Часть логики приложения ориентированной на выполнение конкретного комплекса операций на сервере, результат которых возвращается в виде значения функции. Откомпилированные функции и их исходные тексты содержатся в базе данных.
Хранимые процедуры. Часть логики приложения, особенно нуждающаяся в доступе к базе данных, может храниться там, где она обрабатывается (на сервере). Хранимые процедуры не возвращают значения результата, обеспечивают удобный и эффективный механизм безопасности. Откомпилированные хранимые процедуры и их исходные тексты содержатся в базе данных.
Пакеты. Часть логики приложений: фукций и пакетов, предназначеных для решениях задач в рамках одного модуля (подсистемы) АИС.
Триггеры базы данных. Можно использовать триггеры, чтобы организовать сложный контроль целостности, выполнять протоколирование (аудит) и другие функции безопасности, реализовать в приложениях выдачу предупреждений и мониторинг.
Декларативная целостность. Ограничения активизируются сервером всякий раз, когда записи вставляются, обновляются или удаляются. В дополнение к ограничениям ссылочной целостности, которые проверяют соответствие первичного и внешнего ключей, можно также накладывать ограничения на значения, содержащиеся в столбцах таблицы. Поддержка целостности на сервере уменьшает размер кода клиентской части, необходимого для проверки допустимости данных, и увеличивает устойчивость бизнес- модели, определенной в базе данных.
Список, зарезервированных слов PL/SQL
Выводы.
Координаты точки, характеризующей сбалансированную систему документооборота (бизнес - модель функционирования предприятия), должны иметь ненулевые значения, а в идеале быть примерно одинаковы - соответствовать друг другу. Главное не автоматизация как таковая, а оптимизация потоков документов и интегральность - даже самая прекрасная программа автоматизации документооборота окажется напрасным вложением средств, если модель одномерная или плоская.
Нет большого смысла говорить о жизненном цикле документов без связи с основными бизнес-процессами предприятия. Система автоматизации документооборота, функционирующая в отрыве от всех слоев, будет мертва, мало того, она может нанести вред: запутать и без того неуправляемые бизнес - процессы, отвлечь персонал от выполнения основной работы ради поддержания системы автоматизации документооборота, по сути дела, ничего не автоматизирующего. И, как следствие, раздувание штатного расписания и дискредитация самой идеи автоматизации делопроизводства. Знакомая ситуация - все работники заняты, работа кипит, однако если рассмотреть две разные фирмы имеющие равный доход, занимающиеся одним бизнесом, то штат сотрудников у одной из них будет вдвое больше, чем у другой. При создании или внедрении АИС необходимо всегда помнить, что компьютер или комплект программных средств типа workflow - это только голый инструмент, неумелое использование которого чаще всего влечет за собой только вред, а не долгожданное облегчение и освобождение от внутрикорпоративных проблем по управлению.
Системные объекты базы данных.
Словарь данных. Первыми таблицами, создаваемыми в любой базе данных, являются системные таблицы, или словарь данных Oracle. Системные таблицы хранят информацию о структуре базы данных и объектов внутри нее, и Oracle обращается к ним, когда нуждается в информации о базе данных или когда выполняет оператор DDL (Data Definition Language - язык определения данных) либо оператор DML (Data Manipulation Language - язык манипулирования данными). Эти таблицы никогда непосредственно не обновляются, однако обновление в них происходит в фоновом режиме всякий раз, когда выполняется оператор DDL. Главные таблицы словаря данных содержат нормализованную информацию, которая является довольно трудной для восприятия человеком, так что в Oracle предусмотрен набор представлений, выдающих информацию главных системных таблиц в более понятном виде. Oracle запрашивает информацию из таблиц словаря данных для синтаксического разбора любого оператора SQL. Информация кэшируется в области словаря данных разделяемого пула в SGA.
Сегменты отката. Когда данные в Oracle изменяются, изменение должно быть или подтверждено, или отменено. Если изменение отменяется ("откатывается назад"), содержимое блоков данных восстанавливается в исходное состояние, существовавшее до изменения. Сегменты отката - это системные объекты, которые поддерживают этот процесс. Всякий раз, когда осуществляются какие-либо изменения в таблицах приложения или в системных таблицах, в сегмент отката автоматически помещается предыдущая версия изменяемых данных, так что старая версия данных всегда доступна, если требуется отказ. Другие пользователи при необходимости чтения данных, в то время как изменение не завершено, всегда имеют доступ к прежней версии из сегмента отката. Им предоставляется непротиворечивая по чтению версия данных. После того как изменение фиксируется, доступной становится измененная версия данных. Сегменты отката получают внешнюю память таким же образом, как другие сегменты - экстентами. Сегменту отката, однако, нужно первоначально распределить минимум два экстента.
Временные сегменты используют пространство в файлах базы данных, чтобы создать временную рабочую область для промежуточных стадий обработки SQL и для больших операций сортировки. Oracle создает временные сегменты в процессе работы и они автоматически удаляются, когда фоновый процесс SMON больше в них не нуждается. Если требуется только небольшая рабочая область, Oracle не создает временного сегмента, но вместо этого как временная рабочая область используется часть памяти PGA (глобальная область программы). Администратор базы данных может определять, в каких табличных пространствах будут располагаться временные сегменты для различных пользователей.
Сегмент начальной загрузки (или кэш-сегмент) - специальный тип объекта в базе данных, выполняющий начальную загрузку кэша словаря данных в область разделяемого пула SGA. Oracle использует кэш-сегмент только при запуске экземпляра и не обращается к нему вплоть до рестарта экземпляра. Сегмент необходим, чтобы выполнить начальную загрузку кэша словаря данных, после чего занимаемая им память освобождается.
Словарь данных.
Фундаментальное различие между RDBMS и другими БД и файловыми системами заключается в способе доступа к данным. RDBMS позволяет обращаться к физическим данным в более абстрактной, логической форме, обеспечивая легкость и гибкость при разработке кода приложения. Программы, использующие RDBMS, обращаются к данным через "машину" базы данных без непосредственной зависимости от фактического источника данных, изолируя приложение от деталей "нижележащих" физических структур данных. RDBMS сама заботится о том, где поле хранится в базе данных. Такая независимость данных возможна благодаря словарю данных RDBMS, который хранит метаданные (данные о данных) для всех объектов, расположенных в базе данных.
Словарь данных Oracle - множество таблиц и объектов базы данных, которое хранится в специальной области базы данных и ведется исключительно ядром Oracle. Словарь данных содержит информацию об объектах базы данных, пользователях и событиях. К этой информации можно обратиться с помощью представлений словаря данных. Как показано на рис.31, запросы чтения или обновления базы данных обрабатываются ядром Oracle с использованием информации из словаря данных.
Информация в словаре данных предназначена для подтверждения существования объектов, обеспечения доступа к ним и описания фактического физического расположения в памяти.
RDBMS не только обеспечивает размещение данных, но также определяет оптимальный путь доступа для хранения или выборки данных. Oracle использует сложные алгоритмы, которые позволяют выбирать информацию с наибольшей производительностью, исходя из критерия скорейшего получения первых строк результата или критерия минимального времени выполнения запроса в целом.
Представления словаря данных
Словарь данных содержит информацию об объектах базы данных, пользователях и событиях. К этой информации можно обратиться с помощью представления словаря данных:
ALL_OBJECTS
| ALL_SNAPSHOTS | Все моментальные копии, доступные пользователю. |
| ALL_SOURCE | Исходный текст объектов, доступных пользователю. |
| ALL_SYNONYMS | Все синонимы, доступные пользователю. |
| ALL_TABLES | Описание таблиц, доступных пользователю. |
| ALL_TAB_COLUMNS | Столбцы всех таблиц, представлений и кластеров, доступных пол. |
| ALL_TAB_COMMENTS | Комментарии к таблицам и представлениям, доступным пользователю. |
| ALL_TAB_PRIVS | Привилегии на объекты, которые получил пользователь непосредственно, через роль или как PUBLIC. |
| ALL_TAB_PRIVS_MADE | Привилегии пользователя и привилегии на его объекты. |
| ALL_TAB_PRIVS_RECD | Привилегии на объекты, которые получил пользователь непосредственно, через роль или как PUBLIC. |
| ALL_TRIGGERS | Триггеры, доступные пользователю. |
| ALL_TRIGGER_COLS | Использование столбцов в пользовательских триггерах, в триггерах для его таблиц или во всех триггкрах, если он имеет привелегию CREATE ANY TRIGGER. |
| ALL_USERS | Информация о всех пользователях базы данных. |
| ALL_VIEWS | Текст представлений, доступных пользователю. |
| AUDIT_ACTIONS | Коды типов аудиторских действий. |
| CAT | Синоним для USER_CATALOG. |
| CLU | Синоним для USER_CLUSTERS. |
| CODE_PIECES | Используется для создания представлений _OBJECT_SIZE. |
| CODE_SIZE | Используется для создания представлений _OBJECT_SIZE. |
| COLS | Синоним для USER_TAB_COLUMNS. |
| COLUMN_PRIVILEGES | Привилегии на столбцы, которые принадлежат пользователю, которые он выдал или получил непосредственно, через роль или как пользователь PUBLIC. |
| DBA_2PC_NEIGHBORS | Информация от вновь поступивших и отработанных запросов задержанных транзакций. |
| DBA_2PC_PENDING | Информация о транзакциях, в которых произошел сбой во время фазы подготовки. |
| DBA_AUDIT_EXISTS | Журнал записей протокола, созданных командой AUDIT EXISTS. |
| DBA_AUDIT_OBJECT | Журнал протокола команд над объектами. Создается в файле CATAUDIT.SQL. |
| DBA_AUDIT_SESSION | Журнал протокола команд входа и выхода из ORACLE. |
| DBA_AUDIT_STATEMENT | Синоним для USER_AUDIT_STATEMENT. |
| DBA_AUDIT_TRAIL | Журнал протокола всей системы. |
| DBA_BLOCKERS | Все сеансы, которые держат блокировки, которых ожидает кто-то другой. |
| DBA_CATALOG | Все таблицы, представления, синонимы и последовательности, принадлежащие пользователю. |
| DBA_CLUSTERS | Описание всех кластеров. |
| DBA_CLU_COLUMNS | Соответствие столбцов таблиц столбцам кластера. |
| DBA_COL_COMMENTS | Комментарии к столбцам всех таблиц и представлений. |
| DBA_COL_PRIVS | Привилегии на все столбцы базы данных. |
| DBA_CONSTRAINTS | Определения правил целостности для всех таблиц базы данных. |
| DBA_CONS_COLUMNS | Информация о столбцах в определениях правила целостности, созданных пользователем. |
| DBA_DATA_FILES | Файлы базы данных. |
| DBA_DB_LINKS | Все связи базы данных. |
| DBA_DDL_LOCKS | Все блокировки DDL в базе данных и все связанные с ними запросы к блокировкам DML. |
| DBA_DEPENDENCIES | Зависимости (от) всех объектов базы данных. |
| DBA_DML_LOCKS | Все блокировки DML в базе данных и все связанные с ними запросы к блокировкам DML. |
| DBA_ERRORS | Текущие ошибки для всех хранимых объектов. |
| DBA_EXP_FILES | Описание экспортных файлов. |
| DBA_EXP_OBJECTS | Объекты, которые экспортировались. |
| DBA_EXP_VERSION | Номер версии последнего экспорта. |
| DBA_EXTENTS | Экстенты всех сегментов базы данных. |
| DBA_FREE_SPACE | Свободные экстенты в табличных пространствах, доступных пользователю. |
| DBA_INDEXES | Описание индексов, доступных пользователю. |
| DBA_IND_COLUMNS | Столбцы индексов пользователь или его индексированных таблиц. |
| DBA_LOCKS | Все блокировки и задержки в базе данных, а также все поступающие на них запросы. |
| DBA_OBJECTS | Все объекты базы данных. |
| DBA_OBJECT_SIZE | Размер объектов PL/SQL базы данных. |
| DBA_OBJ_AUDIT_OPTS | Параметры аудиторства для всех таблиц и представлений. |
| DBA_PRIV_AUDIT_OPTS | Параметры аудиторства для привилегий. |
| DBA_ROLES | Все роли в базе данных. |
| DBA_ROLE_PRIVS | Роли, выданные пользователям или другим ролям. |
| DBA_ROLLBACK_SEGS | Описание сегментов отката базы данных. |
| DBA_SEGMENTS | Распределение пространства для всех сегментов базы данных. |
| DBA_SEQUENCES | Описание всех последовательностей в базе данных. |
| DBA_SNAPSHOTS | Все моментальные копии в базе данных. |
| DBA_SNAPSHOT_LOGS | Все журналы моментальных копий в базе данных. |
| DBA_SOURCE | Исходный текст всех хранимых объектов. |
| DBA_STMT_AUDIT_OPTS | Параметры системного аудиторства. |
| DBA_SYNONYMS | Все синонимы в базе данных. |
| DBA_SYS_PRIVS | Системные привилегии, выданные пользователям или ролям. |
| DBA_TABLES | Описание всех таблиц базы данных. |
| DBA_TABLESPACES | Описание всех табличных пространств в базе данных. |
| DBA_TAB_COLUMNS | Столбцы всех таблиц, представлений и кластеров. |
| DBA_TAB_COMMENTS | Комментарии к таблицам и представлениям базы данных. |
| DBA_TAB_PRIVS | Привилегии на объекты всей базы данных. |
| DBA_TRIGGERS | Описание всех триггеров базы данных. |
| DBA_TRIGGERS_COLS | Использование столбцов в пользовательских триггерах или в триггерах для его таблиц. |
| DBA_TS_QUOTAS | Квоты всех пользователей в табличном пространстве. |
| DBA_USERS | Информация о всех пользователях базы данных. |
| DBA_VIEWS | Текст всех представлений базы данных. |
| DBA_WAITERS | Все сеансы, ожидающие или владеющие блокировками. |
| DBMS_ALERT_INFO | Таблица регистрируемых сигналов тревоги. |
| DBMS_LOCK_ALLOCATED | Таблица пользовательских блокировок. |
| DEPTREE | Дерево зависимости объектов. |
| DICT | Синоним для DICTIONARY. |
| DICTIONARY | Описание таблиц и представлений словаря данных. |
| DICT_COLUMNS | Описание столбцов таблиц и представлений словаря данных. |
| ERROR_SIZE | Используется для создания представлений _OBJECT_SIZE. |
| GLOBAL_NAME | Содержит одну строку с глобальным именем текущей базы данных. |
| IDEPTREE | Отсортированный, сформатированный вариант DEPTREE. |
| IND | Синоним для USER_INDEXES. |
| INDEX_HISTOGRAM | Содержит статистику команды ANALYZE INDEX VALIDATE STRUCTURE. |
| INDEX_STATS | Содержит статистику команды ANALYZE INDEX VALIDATE STRUCTURE. |
| LOADER_COL_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_CONSTRAINT_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_INDCOL_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_IND_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_PARAM_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_TAB_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| LOADER_TRIGGER_INFO | Представление SQL*LOADER, используемое для прямой загрузки. |
| OBJ | Синоним для USER_OBJECTS. |
| PARSED_PIECES | Используется для создания представлений _OBJECT_SIZE. |
| PARSED_SIZE | Используется для создания представлений _OBJECT_SIZE. |
| PUBLIC_DEPENDENCY | Зависимости между объектами. |
| RESOURCE_COST | Стоимость каждого ресурса. |
| ROLE_ROLE_PRIVS | Информация о ролях, назначенных другим ролям. |
| ROLE_SYS_PRIVS | Информация о системных привилегиях, назначенных ролям. |
| ROLE-TAB-PRIVS | Информация об объектных привилегиях, назначенных ролям. |
| SEQ | Синоним для USER_SEQUENCES. |
| SESSION-PRIVS | Привилегии, которые пользователь имеет в настоящий момент. |
| SESSION-ROLES | Роли, включенные для пользователя в настоящий момент. |
| SOURCE-SIZE | Используется для создания представлений -OBJECT_SIZE. |
| STMT_AUDIT_OPTION_MAP | Таблица описания кодов типов параметров протоколирования. |
| SYN | Синоним для USE_SYNONYMS. |
| SYSTEM_PRIVILEGE_MAP | Таблица описания кодов системных привилегий. |
| TABLE_PRIVILEGES | Привилегии на объекты, к которым пользователь получил привилегии, выдал, для которых он является владельцем или привилегия выдана пользователю PUBLIC. |
| TABS | Синоним для USER_TABLES. |
| USER_AUDIT_OBJECT | Записи протокольного журнала для команд обращающихся к объекту. |
| USER_AUDIT_.SESSION | Записи протокольного журнала о входах и выходах в систему. |
| USER_AUDIT_STATEMENT | Записи протокольного журнала о следующих командах: GRANT, REVOKE, AUDIT, NOAUDIT и ALTER SYSTEM. |
| USER_AUDIT_TRAIL | Записи протокольного журнала относящиеся к пользователю. |
| USER_CATALOG | Все таблицы, представления, синонимы и последовательности, принадлежащее пользователю. |
| USER_CLUSTERS | Описание кластеров пользователя. |
| USER_CLU_COLUMNS | Соответствие столбцов таблиц столбцам кластера. |
| USER_COL_COMMENTS | Комментарии к столбцам пользовательских таблиц и представлений. |
| USER_COL_PR1VS | Привилегии на столбцы, для которых пользователь является владельцем, выдал или получил привилегии. |
| USER_COL_PRIVS_MADE | Привилегии на столбцы, для которых пользователь является владельцем. |
| USER_COL_PRIVS_RECD | Привилегии на столбцы, для которых пользователь является владельцем, выдал или получил привилегии. |
| USER_CONSTRAINTS | Определения правил целостности для таблиц пользователя. |
| USER_CONS_COLUMNS | Информация о столбцах в определениях правила целостности, созданных пользователем. |
| USER.DB_LINKS | Связи базы данных, принадлежащие пользователю. |
| USER_DEPENDENCIES | Зависимости объектов пользователя. |
| USER_ERRORS | Текущие ошибки для всех объектов, принадлежащих пользователю. |
| USER_EXTENTS | Экстенты сегментов, выделенные объектам, принадлежащим пользователю. |
| USER_FREE_SPACE | Свободные экстенты в табличных пространствах, доступных пользователю |
| USER_INDEXES | Описание индексов, доступных пользователю |
| USER_IND_COLUMNS | Столбцы индексов пользователь или его индексированных таблиц. |
| USER_OBJECTS | Объекты, принадлежащие пользователю. |
| USER_OBJECT_SIZE | Размер объектов PL/SQL, принадлежащих пользователю. |
| USER_OBJ_AUDIT_OPTS | Параметры аудиторства для пользовательских таблиц и представлении. |
| USER_RESOURCE_LIMITS | Ограничения на ресурсы, доступные текущему пользователю. |
| USER_ROLE_PRIVS | Роли, выданные текущему пользователю. |
| USER_SEGMENTS | Распределение пространства для сегментов объектов пользователя. |
| USER_SEQUENCES | Описание последовательностей, созданных пользователем. |
| USER_SNAPSHOTS | Все моментальные копии, доступные пользователю. |
| USER_SNAPSHOT_LOGS | Все журналы моментальных копий, принадлежащие пользователю. |
| V$ACCESS | Заблокированные на текущий момент объекты и сеансы, в которых они используются. |
| V$ARCHIVE | Информация о журналах архива для каждого потока системы базы данных. . |
| V$BACKUP | Статус сброса всех ON-LINE баз данных. |
| V$BGPROCESS | Описание фоновых процессов. |
| V$CIRCUIT | Информация о виртуальных цепях. |
| V$DATABASE | Информация из контрольного файла о базе данных. |
| V$DATAFILE | Информация из контрольного файла о файлах базы данных. |
| V$DBFILE | Информация о всех файлах базы данных. |
| V$DB-OBJECT-CACHE | Объекты базы данных, находящиеся в библиотечном кеше. |
| V$DISPATCHER | Информация о процессах диспетчера. |
| V$ENABLEDPRIVS | Включенные привилегии. |
| V$F1LESTAT | Информация о статистике ввода/вывода в файл. |
| V$FIXED-TABLE | Все таблицы, представления и производные та |
| V$INSTANCE | блицы в базе данных. |
| V$INSTANCE | Статус текущего экземпляра |
| V$ LATCH | Число задержек каждого типа. (Строки этой таблицы однозначно соответствуют строкам таблицы V$ATCHHOLDER) |
| V$LATCHHOLDER | Информация о владельцах задержек. |
| V$LATCHNAME | Закодированные имена задержек из таблицы V$ATCH. |
| V$LIBRARYCACHE | Статистика по управлению буферами библиотечной памяти. |
| V$LICENSE | Параметры лицензии. |
| V$ADCSTAT | Статистика SQL*Loader при выполнении прямой загрузки. |
| V$LOADTSTAT | Статистика SQL* Loader при выполнении прямой загрузки. |
| V$LOCK | Блокировки и ресурсы. |
| V$LOG | Информация о журнальном файле. |
| V$LOGFILE | Информация о журнальных файлах. |
| V$LOGHIST | Информация об истории журнального файла. |
| V$LOG-HISTORY | Информация об истории журнального файла. |
| U$NLS-PARAMETERS | Текущие значения параметров NLS. |
| V$OPEN-CURSOR | Открытые пользователями курсоры. |
| V$PARAMETER | Информация о текущих значениях параметров. |
| V$PROCESS | Информация о всех активных процессах. |
| V$QUEUE | Информация об очереди мульти-серверных сообщений. |
| V$RECOVERY-LOG | Журнальные файлы, необходимые для полного восстановления базы данных. |
| V$RECOVER-FILE | Статус файлов, которые нужно восстанавливать. |
| V$REQD1ST | Гистограмма времен обращения, разделенная на 12 столбцов или периодов времени. |
| V$RESOURCE | Информация о ресурсах. |
| V$ROLLNAME | Имена всех активных сегментов отката. |
| V$ROLLSTAT | Статистика для всех активных сегментов отката. |
| V$ROWCACHE | Статистика активности словаря данных. (Одна строка для каждого буфера памяти) |
| V$SECONDARY | Представление Trusted ORACLE, u котором перечислены вторичнее смонтированные базы данных. |
| V$SESS10N | Информация о текущих сеансах. |
| V$SESS10N-WA1T | Список ресурсов или событий, которых ожидает текущий сеанс. |
| V$SESSTAT | Статистика для текущих сеансов. |
| V$SGA | Суммарная информация об SGA. |
| V$SHARED-SERVER | Информация о вcex разделяемых процессах сервера. |
| V$SQLAREA | Статистика о разделяемых буферах памяти курсора. Одна строка для каждого курсора. |
| V$SQLTEXT | Текст команд SQL, находящихся в разделенных курсорах SGA. |
| V$STATNAME | Раскодированные имена для статистик .из таблицы V$SESSTAT. |
| V$SYSLABEL | Представление Trusted ORACLE, в котором перечислены системные метки. |
| V$SYSSTAT | Текущие значения статистик из таблицы V$SESSTAT. |
| V$THREAD | Информация о потоках, содержащихся п контрольном файле. |
| V$TIMER | Текущее время в сотых долях секунды. |
| V$TRANSACTION | Информация о транзакциях. |
| V$TYPE-SIZE | Размеры различных компонентов базы данных. |
| V$VERSION | Имена версии компонентов библиотеки ядра ORACLE. |
| V$WAITSTAT | Статистика содержимого блока. Обновляется только при включенной временной статистики. |
Специальные таблицы
Таблица CHAINED_ROWS
Список сцепленных строк таблицы или кластера, использованного в команде ANALYZE.
| Столбец | Тип данных |
| OWNER-NAME | VARCHAR2 |
| TABLE-NAME | VARCHAR2 |
| CLUSTER-NAME | VARCHAR2 |
| HEAD_ROWID | ROWID |
| TIMESTAMP | DATE |
Таблица EXCEPTIONS
Эта таблица используется для определения строк, нарушающих правила целостности, если правила целостности включены.
| Столбец | Тип данных |
| HEAD.ROWID | ROWID |
| OWNER | VARCHAR2 |
| TABLE-NAME | VARCHAR2 |
| CONSTRAINT | VARCHAR2 |
PLAN_TABLE
Эта таблица может заполняться командой EXPLAIN PLAN для того, чтобы описать план выполнения оператора SQL.
| Столбец | Тип данных |
| STATEMENT.ID | VARCHAR2 |
| TIMESTAMP | DATE |
| REMARKS | VARCHAR2 |
| OPERATION | VARCHAR2 |
| OPTIONS | VARCHAR |
| OBJECT_NODE | VARCHAR2 |
| OBJECT_OWNER | VARCHAR2 |
| OBJECT.NAME | VARCHAR |
| OBJECT_INSTANCE | NUMBER |
| OBJECT_TYPE | VARCHAR2 |
| SEARCH_COLUMNS | NUMBER |
| ID | NUMBER |
| PARENT.ID | NUMBER |
| POSITION | NUMBER |
| OTHER | LONG |
Архитектуры реализации корпоративных информационных систем.
При построении корпоративных информационных сетей, как правило, используются две базовые архитектуры: Клиент-сервер и Интернет/Интранет. В чем же преимущества и недостатки использования каждой из данных архитектур и когда их применение оправдано? Найти ответы на эти вопросы мы постараемся в данном разделе.
Одной из самых распространенных на сегодня архитектур построения корпоративных информационных систем является архитектура КЛИЕНТ-СЕРВЕР.
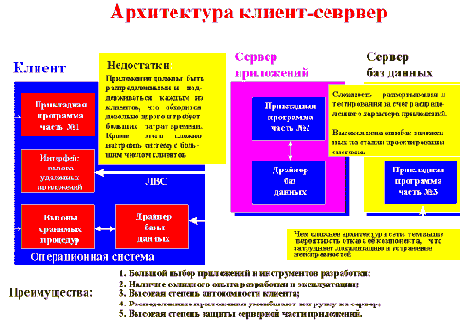
Рис.12. Компоненты архитектуры Клиент-сервер и их свойства.
В реализованной по данной архитектуре информационной сети клиенту предоставлен широкий спектр приложений и инструментов разработки, которые ориентированы на максимальное использование вычислительных возможностей клиентских рабочих мест, используя ресурсы сервера в основном для хранения и обмена документами, а также для выхода во внешнюю среду. Для тех программных систем, которые имеют разделение на клиентскую и серверную части, применение данной архитектуры позволяет лучше защитить серверную часть приложений, при этом, предоставляя возможность приложениям либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним. Средством (инструментарием) для реализации клиентских модулей для ОС Windows в данном случае является, как правило, Delpfi.
Однако при этом частые обращения клиента к серверу снижают производительность работы сети, кроме этого приходится решать вопросы безопасной работы в сети, так как приложения и данные распределены между различными клиентами. Распределенный характер построения системы обуславливает сложность ее настройки и сопровождения. Чем сложнее структура сети, построенной по архитектуре КЛИЕНТ-СЕРВЕР, тем выше вероятность отказа любого из ее компонентов.
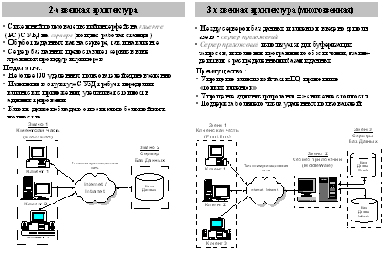
Рис.13. Сравнительные характеристики двух- и трехзвенной архитектуры клиент-сервер.
В последнее время все большее развитие получает архитектура Интернет/Интранет. В основе реализации корпоративных информационных систем на базе данной архитектуры лежит принцип "открытой архитектуры", что во многом определяет независимость реализации корпоративной системы от конкретного производителя. Все программное обеспечение таких систем реализуется в виде аплетов или сервлетов (программ написанных на языке JAVA) или в виде cgi модулей (программ написанных как правило на Perl или С).
Основными экономическими преимуществами данной архитектуры являются:
относительно низкие затраты на внедрение и эксплуатацию; высокая способность к интеграции существующих гетерогенных информационных ресурсов корпораций; повышение уровня эффективности использования оборудования (сохранение инвестиций). прикладные программные средства доступны с любого рабочего места, имеющего соответствующие права доступа; минимальный состав программно-технических средств на клиентском рабочем месте (теоретически необходима лишь программа просмотра - броузер и общесистемное ПО); минимальные затраты на настройку и сопровождение клиентских рабочих мест, что позволяет реализовывать системы с тысячами пользователей (причем многие из которых могут работать за удаленными терминалами).
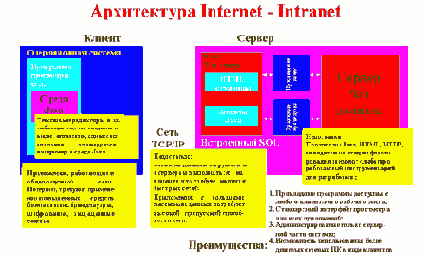
Рис.14 Компоненты архитектуры Интернет-Интранет и их свойства.
В общем случае АИС, реализованная с использованием данной архитектуры включает Web-узлы с интерактивным информационным наполнением, реализованных при помощи технологий Java, JavaBeans и JavaScript, взаимодействующих с предметной базой данных, с одной стороны, и с клиентским местом с другой. База данных, в свою очередь, является источником информации для интерактивных приложений реального времени.
По запросу клиента WEB узел осуществляет следующие операции (рис.7):
Отправляет ASCII коды HTML страниц (или VRML документов), включающие при необходимости элементы javaScript; Отсылает двоичный код запрошенного ресурса (изображения, адио-, видеофайла, архива и т.п.); Отсылает байт коды JAVA апплетов. Принимает конкретную информацию от пользователя (результат заполнения активной формы, или статистическую информацию запрошенную CGI скриптом); Осуществляет заполнение базы данных; Принимает сообщения от пользователя и регламентирует доступ к ресурсам Web узла на основе анализа принятой информации (проверка паролей и т.п.); Принимает информацию от пользователя и в зависимости от нее динамически формирует HTML страницы, либо VRML документы, обращаясь, при необходимости, к базам данных и существующим на WEB узле HTML страницам и VRML документам.
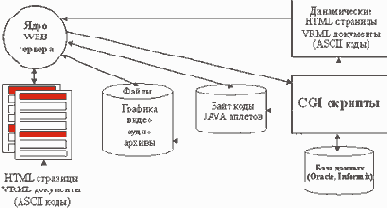
Рис.15. Информационные взаимосвязи компонентов WEB узла
После того, как клиент получил ответ WEB сервера, он осуществляет следующие операции:
визуализирует HTML страницу либо VRML документ в окне броузера; интерпретирует команды JavaScript, модифицирует образ HTML страницы и т.п.; интерпретируя байт коды JAVA апплетов, позволяет загружать и выполнять активные приложения; ведет диалог с пользователем, заполняющим формы, и создает новые запросы к WEB серверу; с помощью утилит воспроизводит коды аудио и видео файлов, поддерживает мультимедийные средства; обеспечивает моделирование виртуальной реальности просматривая VRML документы.
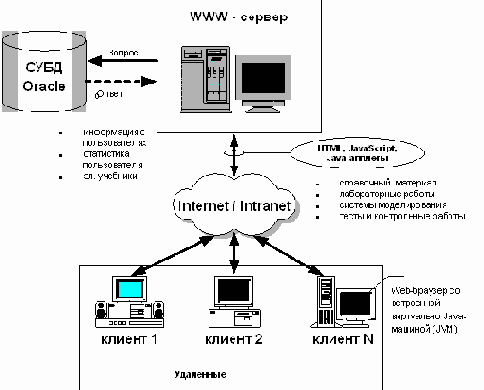
Рис.16. Функциональная схема интерактивного взаимодействия пользователей в архитектуре интернет/интранет.
Перечисленные задачи WEB клиента обеспечиваются возможностями броузера и специализированным программным обеспечением (утилитами), размещенными на рабочей станции клиента. Следует отметить и тот факт, что жестких стандартов на построение WEB клиента пока нет и его компонентный состав может различаться.
На сегодняшний день известны и широко применяются три основных технологии создания интерактивного взаимодействия с пользователем в Web. Первый путь заключается в использовании Стандартного Интерфейса Шлюза (Commom Gateway Interface) - CGI. Второй - включение JavaScript - сценариев в тело Web-страниц. И наконец самый мощный, предоставляющий практически неограниченные возможности способ - применение технологии Java (ипользование Java-аплетов).
CGI
- это механизм для выбора, обработки и форматирования информации. Возможность взаимодействия, обеспечиваемая CGI, предоставляется во многих формах, но в основном это динамический доступ к информации, содержащейся в базах данных. Например, многие узлы применяют CGI для того, чтобы пользователи могли запрашивать базы данных и получать ответы в виде динамически сформированных Web-страниц (рис.17).
Имеются в виду узлы, предоставляющие доступ к базам данных, средствам поиска, и даже информационные системы, предающие сообщения в ответ на ввод пользователя. Все эти узлы используют CGI, чтобы принять ввод пользователя и передать его с сервера Web базе данных. База данных обрабатывает запрос и возвращает ответ серверу, который в свою очередь пересылает его опять броузеру для отображения. Без СGI база данных этого не смогла бы. Данный интерфейс можно считать посредником между броузером, сервером и любой информацией которая должна передаваться между ними.
В отличии от HTML, CGI не является языком описания документов. Собственно, это и не язык вообще; это стандарт. Он просто определяет, как серверы Web передают информацию, используя приложения, исполняемые на сервере. Это способ расширения возможностей сервера Web без преобразования при этом его самого. Подобно тому как броузер Web обращается к вспомогательным приложениям для обработки информации, которую он не понимает, CGI предоставляет серверу Web возможность преложить работу на другие приложения, такие как базы данных и средства поиска.
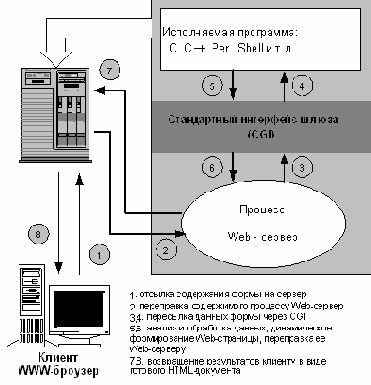
Рис.17. Схема взаимодействия между броузером, сервером и сценарием CGI
При написании программы шлюза (которая может конвертировать ввод из одной системы в другую) CGI позволяет использовать почти любой язык программирования. Способность использовать при написании программы шлюза любой язык, даже язык сценариев, чрезвычайно важна. Самыми популярными языками являются shell, Perl, C и С++. Сценарием традиционно называют программу, которая выполняется с помощью интерпретатора, выполняющего каждую строку программы по мере ее считывания.
Последовательность действий при взаимодействии клиента с программой запущенной на Web-сервере можно сформулировать как следующая последовательность шагов.
Броузер принимает введенную пользователем информацию, как правило с помощью форы. Броузер помещает введенную пользователем информацию в URL, указывающий имя и местоположение сценария CGI, который требуется ввести в действие. Броузер подключается к серверу Web и запрашивает URL. Сервер определяет, что URL должен ввести в действие сценарий CGI, и запускает указанный сценарий. Сценарий CGI выполняется, обрабатывая все передаваемые ему данные. Сценарий CGI динамически формирует Web-страницу и возвращает результат серверу. Сервер возвращает результат клиенту. Броузер отображает результат пользователю
Это является упрощенной схемой взаимодействия между броузером, сервером и сценарием CGI. Наибольшую популярность CGI - сценарии нашли при использовании в качестве обработчиков форм, средства доступа к базам данных, средства осуществления локального и глобального поиска, шлюзовых протоколов.
Наибольшей мощью в реализации клиентского программного обеспечения обладают аплеты - программы написанные на языке JAVA. В узком смысле слова Java - это объектно-ориентированный язык, напоминающий C++, но более простой для освоения и использования. В более широком смысле Java - это целая технология программирования, изначально рассчитанная на интеграцию с Web-сервисом, то есть на использование в сетевой среде. Поскольку Web-навигаторы существуют практически для всех аппаратно-программных платформ, Java-среда должна быть как можно более мобильной, в идеале полностью независимой от платформы.
С целью решения перечисленных проблем были приняты, помимо интеграции с Web-навигатором, два других важнейших постулата.
Была специфицирована виртуальная Java-машина (JVM), на которой должны выполняться (интерпретироваться) Java-программы. Определены архитектура, представление элементов данных и система команд Java-машины. Исходные Java-тексты транслируются в коды этой машины. Тем самым, при появлении новой аппаратно-программной платформы в портировании будет нуждаться только Java-машина; все программы, написанные на Java, пойдут без изменений. Определено, что при редактировании внешних связей Java-программы и при работе Web-навигатора прозрачным для пользователя образом может осуществляться поиск необходимых объектов не только на локальной машине, но и на других компьютерах, доступных по сети (в частности, на WWW-сервере). Найденные объекты загружаются, а их методы выполняются затем на машине пользователя.
Несомненно, между двумя сформулированными положениями существует тесная связь. В компилируемой среде трудно абстрагироваться от аппаратных особенностей компьютера, как трудно (хотя и можно) реализовать прозрачную динамическую загрузку по сети. С другой стороны, прием объектов извне требует повышенной осторожности при работе с ними, а, значит, и со всеми Java-программами. Принимать необходимые меры безопасности проще всего в интерпретируемой, а не компилируемой среде. Вообще, мобильность, динамизм и безопасность - спутники интерпретатора, а не компилятора.
Принятые решения делают Java-среду идеальным средством разработки интерактивных клиентских компонентов (апплетов) Web-систем. Особо отметим прозрачную для пользователя динамическую загрузку объектов по сети. Из этого вытекает такое важнейшее достоинство, как нулевая стоимость администрирования клиентских систем, написанных на Java. Достаточно обновить версию объекта на сервере, после чего клиент автоматически получит именно ее, а не старый вариант. Без этого реальная работа с развитой сетевой инфраструктурой практически невозможна.

Рис.18. Java технологии при реализации АИС.
Стандартный реляционный доступ к данным очень важен для программ на Java, потому что Java-апплеты по природе своей не являются монолитными, самодостаточными программами. Будучи модульными, апплеты должны получать информацию из хранилищ данных, обрабатывать ее и записывать обратно для последующей обработки другими апплетами. Монолитные программы могут себе позволить иметь собственные схемы обработки данных, но Java-апплеты, пересекающие границы операционных систем и компьютерных сетей, нуждаются в опубликовании открытых схем доступа к данным.
Интерфейс JDBC (Java Database Connectivity - связанность баз данных Java) является первой попыткой реализации доступа к данным из программ Java, не зависящего от платформы и базы данных. В версии JDK 1.1 JDBC является составной частью основного Java API.
JDBC - это набор реляционных объектов и методов взаимодействия с источниками данных. Программа на языке Java открывает связь с таблицей, создает объект оператор, передает через него операторы SQL системе управления базой данных получает результаты и служебную информацию о них. В типичном случае файлы .class JDBC и апплет/приложение на языке Java находятся на компьютере клиенте. Хотя они могут быть загружены из сети, для минимизации задержек во время выполнения лучше иметь классы JDBC у клиента. Система управления базой данных (CУБД) и источник данных обычно расположены на удаленном сервере.
На рисунке 19 показаны различные варианты реализаций связи JDBC с базой данных. Апплет/приложение взаимодействует с JDBC в системе клиента, драйвер отвечает за обмен информацией с базой данных через сеть.
Классы JDBC находятся в пакете java.sql.*. Все программы Java используют объекты и методы из этого пакета для чтения и записи в источник данных. Программе, использующей JDBC, требуется драйвер к источнику данных, с которым она будет взаимодействовать. Этот драйвер может быть написан на другом (не Java) языке программирования, или он может являться программой на языке Java, которая общается с сервером, используя RPC (Remote Procedure Call) - удаленный вызов процедур или HTTP. Обе схемы приведены на рис.19. Драйвер JDBC может быть библиотекой на другом (не Java), как программа сопряжения ODBC - JDBC, или классом Java, который общается через сеть с сервером базы данных, используя RPC или HTTP.
Допускается, что приложение будет иметь дело с несколькими источниками данных, возможно, с неоднородными. По этой причине у JDBC есть диспетчер драйверов, чьи обязанность заключаются в управлении драйверами и предоставлении программе списка загруженных драйверов.
Хотя словосочетание "База данных" входит в расшифровку аббревиатуры JDBC, форма, содержание и расположение данных не интересуют программу Java, использующую JDBC, поскольку существует драйвер к этим данным.
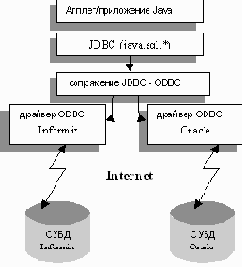

Рис.19 Варианты реализации связи JDBC с базой данных
Что без должной оценки возможностей
При этом совсем неважно, как планируется или уже реализован документооборот: вручную или путем автоматизации с помощью мощных западных либо отечественных пакетов - всегда на первом месте должна быть четкая стратегия, направленная на упорядочение бизнес - процессов. Иначе говоря, прежде чем что-то делать, неплохо было бы ответить на вопрос, кому и почему выгодно выполнять те или иные процессы, имеющие место на предприятии.
CREATE FUNCTION
Создает автономную хранимую функцию.



CREATE PACKAGE
Создает спецификацию для хранимого пакета.


CREATE PACKAGE BODY
Создает тело хранимого пакета.

img src="oracle_pr77.gif" border=0 WIDTH=461 height=26>
CREATE PROCEDURE
Создает автономную хранимую процедуру



Приведем примеры реализации пакетов, функций и процедур.
/* ******Пакет обработки ошибок ********************* */ create or replace package app_err as /* Получение текста аварийного завершения */ function get_err return varchar2; /* Установка текста аварийного завершения */ procedure set_err ( error_text in varchar2); /* Установка текста аварийного завершения и само завершение */ procedure raise_err ( error_text in varchar2); end app_err; create or replace package body app_err as app_err_text varchar2(32767); /* *********************************************************** */ function get_err return varchar2 is A varchar (32767); Begin A := app_err_text; app_err_text := null; Return ( A ); End; /* *********************************************************** */ procedure set_err(error_text in varchar2) is Begin app_err_text := error_text; End; /* ************************************************************** */ procedure raise_err ( error_text in varchar2) is Begin app_err_text := error_text; raise_application_error (-20000, error_text); End; end app_err; /* ** Функция осуществляющая расшифровку пароля пользователя в БД ** */ create or replace function password return varchar2 is name varchar2(23); pass varchar2(23); begin select ORANAME, CRYPT_PASSWORD into name, pass from USERS where USER_ORANAME = user; pass := encrypt( pass, name ); return( pass ); end; /*Удаляется публичный синоним*/ drop public synonym password; /*Создается публичный синоним*/ create public synonym password for password; /* устанавливаем привелегии*/ grant all on password to admin;
DROP PUBLIC DATABASE LINK. cluster_clause::= contects_clause::= EXPLAIN PLAN
Описывает каждый шаг плана выполнения оператора SQL и помещает (если задано) это описание в указанную таблицу

ROLLBACK (управление транзакцией)
Отменяет все изменения, сделанные до контрольной точки. Отменяет все изменения, произведенные в текущей транзакции, если контрольная точка не задана.

Функция
- объект базы данных обеспечивающий выполнение конкретных действий над параметрами функции и возвращающая результат такой обработки.
Для создания функций, процедур, пакетов базы данных используются следующие команды:
Хаос
.
Когда на Западе, а теперь и в России схлынула первая волна увлечения системами автоматизации документооборота, оказалось,
Исследование архитектур программно-технологической реализации АИС
В настоящее время существует множество архитектур, служащих для разработки информационных систем, ядром которых является СУБД. Клиент в типичной конфигурации клиент/сервер - это автоматизированное рабочее место, использующее графический интерфейс (Graphical User Interface - GUI), обычно Microsoft Windows, Macintosh.
Сервер же, в основном, предназначен для хранения, передачи и распределения информации между клиентами. В клиент/серверной конфигурации программные средства имеют разделение на клиентскую и серверную часть, однако, частые обращения клиента к серверу снижают производительность работы сети и обуславливают сложность настройки системы.
Рассмотрим варианты распределения функций СУБД в клиент/серверной системы. СУБД выполняет три основные функции:
доступ к данным; предоставление данных; бизнес - функции.
Сервер СУБД может быть реализован на различных платформах, под управлением операционных систем UNIX, NetWare, Windows NT, OS/2 и др.
До появления технологии клиент/сервер большинство приложений функционировало на одной ЭВМ. Одна система отвечала не только за всю обработку данных, но также и за выполнение логики приложения. Кроме того, та же система обрабатывала весь обмен с каждым терминалом; все нажатия клавиш и элементы отображения обслуживались тем же процессором, который обрабатывал запросы к базе данных и логику приложения.
Oracle предоставляет такие возможности, как хранимые процедуры, поддержка ограничений целостности, функции, определяемые пользователем, триггеры базы данных и ряд других. Все это позволяет приложению хранить большое количество бизнес-правил (или семантику модели данных) на уровне базы данных. В результате приложение освобождается для выполнения более тонких задач обработки. Как показано на рис.28, такая СУБД намного более устойчива.
Программные продукты Oracle охватывают все основные компоненты архитектуры клиент/сервер, показанной на рис. 29:
1)полнофункциональный высокопроизводительный сервер RDBMS (система управления реляционной базой данных), масштабируемый от портативных ЭВМ до мэйнфреймов;
средства для разработки и запуска клиентских приложений, поддерживающие несколько сред GUI; программный компонент для организации связи между БД на различных ЭВМ, который обеспечивает эффективную и безопасную связь с помощью широкого набора сетевых протоколов.

Рис. 33. Взаимодействие основных компонентов в архитектуре Oracle.
Oracle использует память системы (как реальную, так и виртуальную) для выполнения пользовательских процессов и самого программного обеспечения СУБД, и для кэширования объектов данных. В простой конфигурации Oracle файлы базы данных, структуры памяти, фоновые и пользовательские процессы располагаются на одной машине без использования сети. Однако, намного чаще встречается конфигурация, когда БД расположена на машине-сервере, а инструментальные средства Oracle - на другой машине (например, РС с Microsoft Windows). При такой клиент/серверной конфигурации машины связываются посредством некоторого сетевого программного обеспечения, которое позволяет двум машинам поддерживать связь. Для организации взаимодействия клиент/сервер или сервер-сервер необходимо использовать программный продукт Oracle SQL*Net, который позволяет СУБД Oracle взаимодействовать с сетевым протоколом. SQL*Net и поддерживает большинство сетевых протоколов для локальных вычислительных сетей (таких как TCP/IP, IPX/SPX) и для мэйнфреймов (например, SNA). По существу, SQL*Net является промежуточной программной прослойкой между Oracle и сетевым ПО, обеспечивающей связь между клиентской машиной Oracle (на которой работает, например, SQL*Plus) и сервером базы данных или между серверами баз данных. Опции SQL*Net позволяют одной машине работать с одним сетевым протоколом, сообщаясь с другой машиной, работающей с другим протоколом.

Рис. 34. SQL*NET как средство обеспечения взаимодействия между СУБД и сетью.
В зависимости от размеров, таблицы (и других объектов) всех учетных разделов пользователей могут, очевидно, размещаться в одном файле базы данных, но это - не лучшее решение, так как оно не способствует гибкости структуры базы данных для управления доступом к различным пользовательским разделам, размещения базы данных на различных дисководах или резервного копирования и восстановления части базы данных. В СУБД Oracle предусмотрены привилегии системного уровня, резервное копирование и поддержка национальных языков. Все это позволяет сделать вывод о целесообразности разработки интерактивной информационной системы патентного обеспечения технологического проектирования на основе СУБД Oracle.
Исследование моделей информационного представления данных в современных СУБД.
Исследование различным методов ис средств представления и управления данными в информационных системах проведем на примере интерактивной базы данных патентного обеспечения (ПО) конструкторско-технологического проектирования (КТП). Патент - это документ, свидетельствующий о праве изобретателя на его изобретение. Для стандартизации и облегчения поиска информации были введены различные классификации патентов: (Национальная Классификация Патентов (НКИ), Универсальная Десятичная Классификация (УДК), Международная Классификация Изобретений (МКИ)). Все эти классификации призваны служить инструментом для упорядоченного хранения патентных документов, что облегчает доступ к содержащейся в них информации, быть основой для избирательного распределения информации среди потребителей патентной информации и для получения систематических данных в области промышленного соответствия, что в свою очередь, определяет уровень развития различных областей техники.
Классификации патентов имеют сложную структуру, и для поиска необходимой информации может потребоваться много времени. Возможна организация поиска по всем имеющимся классификациям изобретений, но пока, в качестве примера, мы рассмотрим только Международную Классификацию Изобретений, которая являясь средством для единообразного в международном масштабе классифицирования патентных документов, представляет собой эффективный инструмент для патентных ведомств и других потребителей, осуществляющих поиск патентных документов с целью установления новизны и оценки вклада изобретения в заявленное техническое решение (включая оценку технической прогрессивности и полезности или результата).
Международная Классификация Изобретений (МКИ) имеет иерархическую структуру (представленную на рис.1) и состоит из следующих отделов: 1 - Раздел, 2 - Класс, 3 - Подкласс, 4 - Группа, 5 - Подгруппа. Иерархическая структура классификации МКИ представлена на рис.31.

Рис. 31. Иерархическая структура классификации МКИ - как основа АИс патентного обеспечения КТП.
Логическая модель
Переход от функциональной модели к логической осуществляется с помощью реляционных методов, при этом иерархическая структура функциональной модели реализуется с использованием отношений один - ко -многим и рекурсивных рис. 27. Реализацией данной логической модели является совокупностью таблиц, объединенных в единый модуль - патентную информационную базу данных ( PIB - Patent Information dateBase).
Ядром логической модели является таблица PIB_MKI (МКИ), связывающая таблицы PIB_PART (Раздел), PIB_CLASS (Класс), PIB_SUBCLASS (Подкласс), PIB_GROUP (Группа), PIB_SUB-GROUP (Подгруппа) в единую структуру, определяющую реализацию Международной Классификации Изобретений (МКИ) винформационной системе патентного обеспечения технологического проектирования. Таблица PIB_MKI (МКИ) в свою очередь связана с таблицей PIB_PATENT (Патент), отвечающей за связь с таблицами PIB_GRATHDOC (Графические документы) и PIB_UDK (УДК).Таблица PIB_UDK (УДК) реализует Универсальную Десятичную Классификацию (УДК). Структура таблиц модуля PIB представлена в таблице1.
Таблица 1. Информационно-логическая Структура модуля Международной Классификации Изобретений.
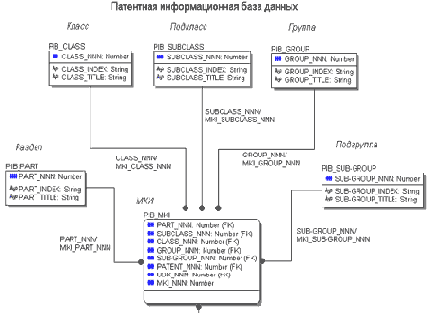
img src="oracle_pr35.gif" border=0 WIDTH=424 height=208>
Рис 32. Логическая модель
Язык манипуляции данными (ЯМД)
Язык манипуляции данными (ЯМД) обеспечивает эффективные команды манипуляции сетевой системой базы данных. ЯМД позволяет пользователям выполнять над базой данных операции в целях получения информации, создания отчетов, а также обновления и изменения содержимого записей.
Основные команды ЯМД можно классифицировать следующим образом: команды передвижения, команды извлечения, команды обновления записей, команды обновления наборов.
Табл.2. Основные типы команд ЯМД.
№
Заключение
Процесс преобразования функциональной модели в реляционную включает создание реляционной таблицы для каждого объектного множества модели. Атрибуты объектного множества становятся атрибутами реляционной таблицы. Если в функциональной модели существует ключевой атрибут, то он может использоваться в качестве ключа реляционной таблицы. В противном случае ключевой атрибут таблицы может быть создан аналитиком. Однако, лучше всего, если такой атрибут естественным образом возникает из моделируемого приложения. Отношения один-к-одному и один-ко-многим преобразуются в реляционную модель путем превращения их в атрибуты соответствующей таблицы. Отношения многие-ко-многим соответствуют многозначным атрибутам и преобразуются в четвертую нормальную форму путем создания ключа из двух столбцов, соответствующих ключам двух объектных множеств, участвующих в отношении. Конкретизирующие множества преобразуются путем создания отдельных реляционных таблиц, ключи которых совпадают с ключами обобщающих объектных множеств. Рекурсивные отношения также можно смоделировать, создав новое смысловое имя атрибута, обозначающее отношение.
Этапы разработки автоматизированных информационных систем.
Итак, мы выбрали метод, которым будем руководствоваться при проектировании автоматизированной информационной системы. Теперь нам необходимо спланировать комплекс работ по созданию нашей системы в соответствии с типовыми этапами разработки АИС, краткая характеристика которых приведена в табл.1., а последовательность трансформации бизнес модели в объекты базы данных на рис.1.
Таблица 1.Этапы проектирования АИС и их характеристики.
№
бизнес - модели
Метод решения: Функциональное моделирование.
Результат:
1.Концептуальная модель АИС, состоящая из описания предметной области, ресурсов и потоков данных, перечень требований и ограничений к технической реализации АИС.
2.Аппаратно-технический состав создаваемой АИС.
разработка логической модели
бизнес -процессов.
Метод решения: Разработка диаграммы "сущность-связь" (ER (Entity-Reationship) - CASE- диаграммы).
Результат: Разработанное информационное обеспечение АИС: схемы и структуры данных для всех уровней модульности АИС, документация по логической структуре АИС, сгенерированные скрипты для создания объектов БД.
обеспечения, разработка
программного обеспечения АИС.
Метод решения: Разработка программного кода с использованием выбранного инструментария.
Результат: Работоспособная АИС.
4
Результат: Оптимальный состав и эффективное функционирование АИС.
Комплект документации: разработчика, администратора, пользователя.
Результат: Наращиваемость и безизбыточный состав гибкой, масштабируемой АИС

Рис.1. Последовательность трансформации бизнес-модели в объекты БД и приложения.
Этапы выполнения работы: Разработка
Таблица пользователей ASUKTP_USER
| USER_NNN | Ф.И.О. пользователя | Ораклическое имя | Ссылка на подразделение | Ссылка на должность | Паспортные данные |
Справочник подразделений ASUKTP_PODR
| PODR_NNN | Наименование подразделения | Ссылка на подразделение высшего уровня | Контактная информация |
Штатное расписание
| SHTAT_NNN | Наименование должности | Ссылка на подразделение | Оклад по должности |
Таблица управления проектами
| PROEKT_NNN | Наименование проекта | Описание проекта | Ссылка на руководителя |
Таблица схемотехнических документов
| SHEMA_NNN | Наименование документа | Описание документа | Ссылка на NNN проекта | Ссылка на разработчика | имя файла чертежа |
5. Таблица конструкторских документов по сборочным единицам
| K_SBED_NNN | Наименование сборочной единицы | Описание | Ссылка на NNN проекта | Ссылка на разработчика (подразделение) | имя файла чертежа |
6. Таблица конструкторских документов по деталям
| K_DETAL_NNN | Наименование детали | Описание | Ссылка на NNN сборочной единицы | Ссылка на разработчика (подразделение) | имя файла чертежа |
7. Таблица графических документов
| GRAFDOC_NNN | Наименование файла | Дата создания | Тип файла (расширение) | Ссылка на разработчика (подразделение) | Описание |
8. Таблица технологических документов по сборочным единицам
| T_SBED_NNN | Ссылка на наименование СБ единицы | Описание | Ссылка на NNN проекта | Ссылка на разработчика (подразделение) | имя файла чертежа |
9. Таблица технологических документов по деталям
| T_DETAL_NNN | Ссылка на наименование детали | Описание | Ссылка на NNN тех док. По сборочной единицы | Ссылка на разработчика (подразделение) | имя файла чертежа |
Таблица управления производственным процессом
| TP_CONTROL_NNN | Ссылка на техпроцесс | Ссылка на операцию | Ссылка на NNN проекта | Ссылка на разработчика | Отметка о выполнении |
11. Справочник техпроцессов
| TP_SPR_NNN | Наименование ТП | Описание |
12. Таблица операций техпроцессов
| TP_OPER_NNN | Ссылка на NNN техпроцесса | Описание операции | Ссылка на справочник оборудования | Ссылка на подразделение | Комментарии |
Здесь представлены только бозовае таблицы АСУ КТП, в зависимости от вашего варианта (разрабатываемого модуля) перечень дополнительных таблиц, для конкретного модуля) должен быть создан на этапе проектирования структуры БД модуля АСУ КТП (этап 3).
Таблица управления проектами ASU_PROEKT_CONTROL
PROEKT_NNN
PROEKT_NUMBER
PROEKT_COMMENT
PROEKT_USER_NNN
Классификация моделей построения баз данных
В зависимости от архитектуры СУБД делятся на локальные и распределенные СУБД. Все части локальной СУБД размещаются на одном компьютере, а распределенной на нескольких. За несколько десятилетий последовательно появлялись системы (СУБД), основанные на трех базовых моделях данных: иерархической, сетевой и реляционной. Основные определения теории баз знаний и баз данных представлены в таблице 1.
Табл.1. Основные определения
№
Дополнения к таблице 1.
Процедурные
Декларативные
Каузальные
Неточные
Знания, отвечающие на вопрос "Как решать поставленную задачу?"
Знания, не содержащие в явном виде процедуры решения задач.
Знания о причинно-следственных связях между объектами предметной области
Знания отличающиеся неполнотой или противоречивостью.
В СУБД
В СУБЗ
Данные + Алгоритм = Программа решения задачи
Знания + Стратегия вывода = Решение проблемы.
Продукционная
Фреймовая
Семантическая сеть
Знания представленные в формате "ЕСЛИ-ТО"
Знания представленные в виде набора взаимосвязанный фреймов.
Граф, вершины которого соответствуют объектам или понятиям, а дуги определяют отношения между вершинами.
Фрейм
Фрейм прототип
Конкретный фрейм
Это фрейм у которого значения слотов не определены.
Это фрейм прототип с конкретными значениями.
обработки запроса
(Intraquery parallelism).
обработка запросов
(interquery parallelism)
(Isolation level).
Database Connectivity).
Database Connectivity).
analytical processing).
(Object Linking and
Embedding Database).
(Join).
query language).
(Stored procedure).
(Transaction).
(Trigger).
Команды управления привилегиями и ролями REVOKE (системные привилегии и роли )
Отменяет системные привилегии и роли, ранее предоставленные пользователям и ролям. Действие, обратное команде GRANT (системные привилегии и роли ) .

КРАТКОЕ ПРАКТИЧЕСКОЕ РУКОВОДСТВО РАЗРАБОТЧИКА ИНФОРМАЦИОННЫХ СИСТЕМ НА БАЗЕ СУБД ORACLE
h2>
>>
Литература
DiasoftInfo / Корпоративный журнал компании DIASOFT. - М. 1999 г. Материалы аналитической компании СПЛАН. Е.Голенцова Три основных вопроса СУД. ОАО "Весть". 1998. А. Громов Управление бизнес-процессами на основе технологии Workflow// Открытые системы , №1. 1997. Р. Майкл Oracle 7.3. Энциклопедия пользователя: Пер с англ. - К.: Издательство "Диасофт". 1997. - 832 с. Фаронов В.В., Шумаков П.В. Delphi 4. Руководство разработчика баз данных - М.: "Нолидж", 1999. - 560 с., ил. С.Урман Oracle 8. Программирование на языке PL/SQL - М.: Изд-во ЛОРИ, 1999. - 607 с. К. Луни Oracle 8. Настольная книга администратора. - М.: Изд-во ЛОРИ, 1999. - 500 с. С.Бобровски Oracle 8. Архитектура. - М.: Изд-во ЛОРИ, 1999. - 207 с. Г.Хансен, Д.Хансен Базы данных: разработка и управление: Пер. с англ. - М.: ЗАО "Издательство БИНОМ", 1999. - 704 с.: ил. С.Дунаев Доступ к базам данных и техника работы в сети. Практические приемы современного программирования. - М.: ДИАЛОГ-МИФИ, 1999 - 416 с. Р.Петерсен Linux: руководство по операционной системе: в 2 т: Пер с англ. - 2-е изд., перераб. и доп. - К. Издательская группа BHV, 1998. Власов А.И. Технология создания WEB узлов / Конспект лекций - М.: УЦ ОАО Газпром, 1999. - 102 с. Власов А.И., Овчинников Е.М. Банковские и корпоративные автоматизированные информационные системы, принципы, средства и системы документооборота коммерческого банка / Конспект лекций. - М.: Учебный Центр ОАО Газпром, 1999. - 107 с. Овчинников Е.М. Корпоративные информационные системы и технологии / Конспект лекций - М.: Учебный Центр ОАО Газпром, 1999. - 78 с. Материалы периодической печати: Компьютерпресс, "Мир ПК", "Интернет", "Мир интернет", Byte Россия, PC magazine (RE). http://www.oracle.ru http://www.diasoft.ru http://www.vest.msk.ru http://info.iu4.bmstu.ru http://cdl.iu4.bsmtu.ru http://www.microsoft.com http://www.ibm.com http://www.citforum.ru Материалы выставок Comtec, NetCom, UnixExpo, Информатика и др. Материалы 3-го, 4-го и пятого форумов разработчиков АБС.
|
Метод "снизу-вверх".
Менталитет российских программистов сформировался именно в крупных вычислительных центрах (ВЦ), основной целью которых было не создание тиражируемых продуктов, а обслуживание сотрудников конкретного учреждения. Этот подход во многом сохранялся и при автоматизации и сегодня. В условиях постоянно изменяющихся законодательства, правил ведения производственной, финансово-хозяйственной деятельности и бухгалтерского учета руководителю удобно иметь рядом посредника между спущенной сверху новой инструкцией и компьютером. С другой стороны, программистов, зараженных "вирусом самодеятельности", оказалось предостаточно, тем более что за такую работу предлагалось вполне приличное вознаграждение.
Создавая свои отделы и управления автоматизации, предприятия и банки пытались обустроиться своими силами. Однако периодическое "перетряхивание" инструкций, сложности, связанные с разными представлениями пользователей об одних и тех же данных, непрерывная работа программистов по удовлетворению все новых и новых пожеланий отдельных работников и как следствие - недовольство руководителей своими программистами несколько остудило пыл как тех, так и других. Итак, первый подход сводился к проектированию
Метод "сверху-вниз".
Быстрый рост числа акционерных и частных предприятий и банков позволил некоторым компаниям увидеть здесь будущий рынок и инвестировать средства в создание программного аппарата для этого растущего рынка. Из всего спектра проблем разработчики выделили наиболее заметные: автоматизацию ведения бухгалтерского аналитического учета и технологических процессов (для банков это в основном - расчетно-кассовое обслуживание, для промышленных предприятий - автоматизация процессов проектирования и производства, имеется в виду не конкретных станков и т.п., а информационных потоков). Учитывая тот факт, что ядром АИС безусловно является аппарат, обеспечивающий автоматизированное ведение аналитического учета, большинство фирм начали с детальной проработки данной проблемы. Системы были спроектированы "сверху", т.е. в предположении что одна программа должна удовлетворять потребности всех пользователей.
Сама идея использования "одной программы для всех" резко ограничила возможности разработчиков в структуре информационных множеств базы данных, использовании вариантов экранных форм, алгоритмов расчета и, следовательно, лишила возможности принципиально расширить круг решаемых задач - автоматизировать повседневную деятельность каждого работника. Заложенные "сверху" жесткие рамки ("общие для всех") ограничивали возможности таких систем по ведению глубокого, часто специфического аналитического и производственно - технологического учета. Работники проводили эту работу вручную, а результаты вводили в компьютер. При этом интерфейс каждого рабочего места не мог быть определен функциями, возложенными на пользователя, и принятой технологией работы. Стало очевидно, что для успешной реализации задачи полной автоматизации банка следует изменить идеологию построения АИС.
Методы проектирования информационных систем
Индустрия разработки автоматизированных информационных систем управления родилась в 50-х - 60-х годах и к концу века приобрела вполне законченные формы. Материалы данного руководства являются обобщением цикла лекций по Автоматизированным Банковским Системам (АБС) и Автоматизированным системам управления конструкторско-технологическим проектированием (АСУ КТП), читаемым в МГТУ им.Н.Э.Баумана. Не смотря на имеющиеся различия в реализации функциональных модулей данных систем, общие подходы к их разработки во многом схожи, что позволило нам объединить вопросы их проектирования в рамках одного издания.
На рынке автоматизированных систем для крупных корпораций и финансово-промышленных групп на сегодня можно выделить два основных субъекта: это ранок автоматизированных банковских систем (АБС) и рынок корпоративных информационных систем промышленных предприятий. Не смотря на сильную взаимосвязь этих двух рынков систем автоматизации, предлагаемые на них решения пока еще не достаточно интегрированы между собой, чего следует ожидать в недалеком будущем.
В дальнейшем под Автоматизированной Банковской Системой (АБС) будем понимать комплекс аппаратно-программных средств реализующих мультивалютную информационную систему, обеспечивающую современные финансовые и управленческие технологии в режиме реального времени при транзакционной обработке данных.
Под Автоматизированной Информационной Системой промышленного предприятия (АСУ КТП) будем понимать комплекс аппаратно-программных средств реализующих мультикомпонентную информационную систему, обеспечивающую современное управление процессами принятия решений, проектирования, производства и сбыта в режиме реального времени при транзакционной обработке данных.
Как вы видите, оба определения достаточно схожи. На сегодня существования нескольких методов построения автоматизированных информационных систем (АИС), среди которых можно выделить следующие:
Netscape на платформе Solaris
Netscape Enterprise Server 3.61 - Web-сервер, избранный для реализации большинства крупных узлов на основе Solaris, в том числе и корпорации Sun. Инструментальные средства фирмы Netscape, а также предлагаемые независимыми производителями, способствуют разработке сложных прикладных программ для Web с помощью сценариев на языках JavaScript, CORBA, Java.
Еще одна важнейшая система, стоящая за добротными программами для Web на серверах Netscape, - сервер прикладных программ Netscape Application Server (NAS). Сервер NAS - среда программирования для объектов на языках C++ и Java - обеспечивает масштабируемость и устойчивость к сбоям прикладных программ. В NAS имеются инструменты для создания многоуровневых программ, объединяющих HTML и запросы к базам данных на серверах NAS.
Операции над множествами в операторах SELECT
Операция
Операция
столбцов из таблицы или представления.
Пример 5. Показать всех врачей с кодом специальности равным 111 и работающих в подразделении №2.
SELECT dc_name FROM doctors WHERE dc_speciality_nnn = 111 AND dc_shtat_nnn = 2 ORDER BY dc_name; Пример 6. Показать всех пациентов врача Иванова А. А. SELECT pt.pt_name FROM patients pt ,doctors dc WHERE dc.dc_nnn = pt.pt_dc_nnn AND dc.dc_name = 'ИВАНОВ А. А.' ORDER BY pt.pt_name;
На этом примере остановимся подробнее: Первое - здесь впервые появились в запросе псевдонимы таблиц (pt, dc), это очень важный элемент , так как может оказаться, что по нерадивости у Вас в обоих таблицах имеются одинаковые наименования столбцов и тогда для обращения к ним потребуется использование псевдонимов таблиц. Второе - Делая запрос к нескольким таблицам необходимо использовать джойны (dc.dc_nnn = pt.pt_nnn), т.е. явно задавать те поля, которые определяют отношения между таблицами, причем чесло джойнов равняется N-1, где N - число таблиц в запросе. Третье - выборка данных по условию dc.dc_name = 'ИВАНОВ А. А.' накладывает очень жесткие требования на правильность ввода данных (они могут быть набиты маленькими буквами, через несколько пробелов и т.п.), не учет этих особенностей приведет к тому, что некоторая нужная информация не будет выбрана. Чтобы избежать этого лучше в условиях использовать числовые поля, например личный номер врача (если он имеется БД).О принципах написание SELECT можно написать несколько томов, мы здесь изложили только несколько, с нашей точки зрения, важных особенностей, более подробную информацию по синтаксису можно всегда найти в справочной литературе.
DELETE
Удаляет строки из таблицы или из базовой таблицы представления, удовлетворяющие условию WHERE. Удаляет все строки, если условие WHERE не задано.

Пример:
Удаляем все записи из таблицы Праздничных дней.delete from prazdniki;
ОПЕРАТОРЫ СОЗДАНИЯ ОБЪЕКТОВ БД.
Перед тем как работать с данными с БД ее надо создать, для этих целей используется специальная группа операторов, предназначенных для создания объектов базы данных, все операторы данной группы начинаются с ключевого слова CREATE.
CREATE DATABASE
Создает базу данных. Задает и определяет максимальное число экземпляров файлов данных и журнальных файлов, устанавливает режим архивирования.


Filespec (файлы данных)::=

Filespec (журнальные файлы)::=

-- Скрипт создания БД CLINICS spool clinic.log connect internal startup nomount pfile=/oracle/dbs/initclinic.ora -- создаем базу данных с именем clinics create database "clinics" maxinstances 1 maxlogfiles 10 character set "RU8PC866" national character set "RU8PC866" datafile '/oracle/db/system01.dbf' size 100M logfile '/oracle/db/lo g01.dbf' size 1M, '/oracle/db/log02.dbf' size 1M; disconnect spool off
CREATE TABLESPASE
Создает в базе данных область для хранения таблиц, сегментов и индексов, определяет файлы базы данных, параметры хранения по умолчанию и режим табличного пространства (автономный или оперативный).

CREATE USER
Создает пользователя базы данных. (синтаксис команды приведен упрощенно, за дополнительной информацией обратитесь к документации).
CREATE ROLE


CREATE SCHEMA
Создает несколько таблиц и представлений и предоставляет некоторые привилегии в одной транзакции.

CREATE TABLE
Создает новую таблицу БД, определяя ее столбцы, правила целостности и параметры хранения.

Пример:
| create table | DOCTORS( |
| DC_NNN | NUMBER(12,0) |
| , DC_DC_NNN | NUMBER(12,0) |
| , DC_NAME | VARCHAR2(255) |
| , DC_CS_NNN | NUMBER(12,0) |
| , DC_DIPLOMA_NUMBER | NUMBER(12,0) |
| , DC_SPECIALTY_NNN | NUMBER(12,0) |
| , DC_SHAT_NNN | NUMBER(12,0) |
| , DC_CALENDAR | NUMBER(12,0) |
) tablespace users;
CREATE SYNONYM
Создает синоним для таблицы, представления, последовательности, хранимой процедуры или функции, пакетной процедуры, моментальной копии или другого синонима.

Пример: Сначала удаляем публичный синоним для таблицы DOCTORS, а потом его заново создаем.
drop public synonym DOCTORS; create public synonym DOCTORS for DOCTORS;
CREATE INDEX
Создает индекс для заданных столбцов таблицы или кластера.



Пример:
create UNIQUE index I_DOCTORS on DOCTORS ( DC_NNN ) tablespace users;
CREATE TRIGGER
Создает триггер базы данных.

CREATE SEQUENCE
Создает новую последовательность для генерации первичных ключей.


Пример:
create sequence S_DOCTORS;
Пример: Приведем полный текст скрипта для создания триггера для таблицы DOCTORS, который будет следить за автоматическим увеличением значения поля DC_NNN на единицу при добавлении каждой новой записи в таблицу DOCTORS, что потребует от нас использование и такой конструкции - как сиквенс (генератор последовательностей).
-- Сначала удаляем предыдущие изменения в базе (если конечно они были сделаны) drop sequence S_DOCTORS; drop trigger tr_DC_NNN; drop public synonym DOCTORS; -- создаем таблицу -- назначаем права доступа -- создаем публичный синоним CREATE PUBLIC SYNONYM DOCTORS FOR DOCTORS; -- создаем сиквенс и устанавливаем его начальное значение в единицу create sequence S_DOCTORS start with 1; -- создаем индексы create unique index i_dc_nnn on doctors(dc_nnn); create index i_dc_name on doctors(dc_name); -- создаем триггер create trigger tr_dc_nnn before insert on doctors for each row begin select dc_nnn.nextval into :new.dc_nnn from dual; end; /
Oraclepr_12.shtml
Функции
Числовые функции
Функция
Символьные функции
Символьные функции, возвращающие символьные значения:
Функция 1
Символьные функции, возвращающие числовые значения
Групповые функции
Oraclepr_18.shtml
Таблица схемотехнических документов ASU_SHEMA_DOCS
Уникальный ключ
SHEMA_NNN
SHAMA_NAME
SHEMA_COMMENT
SHEMA_PR_NNN
SHEMA_USER_NNN
SHEMA_GRAPH
Таблица конструкторских документов по сборочным единицам ASU_KONSTR_DOCS
Уникальный ключ
KDOCS_NNN
KDOCS_NAME
KDOCS_COMMENT
KDOCS_PR_NNN
KDOCS_USER_NNN
KDOCS_GRAPH
Таблица пользователей ASU_USER
Уникальный ключ
USER_NNN
USER_FIO
USER_ORANAME
USER_PODR_NNN
USER_SHTAT_NNN
USER_PASPORT
Ориентация на профессиональные СУБД - "За" и "Против"
По материалам периодической печати [1,2] можно судить, что 1998 год стал годом перехода к внедрению АБС четвертого поколения, основой которых, в свою очередь, является ориентация на профессиональные СУБД. Что же это дает и зачем все это нужно:
Оптимизированный многопользовательский режим работы с развитой системой транзакционной обработки, что обеспечивает многочисленным пользователям возможность работы с базой данных, не мешая друг другу. Надежные средства защиты информации (учитывая стандартную трехзвенную архитектуру защиты на уровне сети - на уровне сервера БД - на уровне клиентской ОС). Эффективные инструменты для разграничения доступа к БД. Поддержка широкого диапазона аппаратно - программных платформ. Реализация распределенной обработки данных. Возможность построения гетерогенных и распределенных сетей. Развитые средства управления, контроля, мониторинга и администрирования сервера БД. Поддержка таких эффективных инструментариев, как: словари данных, триггеры, функции, процедуры, пакеты и т.п.
Все выше перечисленное обусловило широкое распространение решений на базе профессиональных СУБД в крупных коммерческих банках и промышленных корпорациях. По экспертным оценкам по числу установок лидируют СУБД Oracle, Informix, Sybase. Несмотря на это в большинстве средних и малых банках и предприятиях по-прежнему, ориентируются на решения на базе АИС третьего и даже второго поколения. Какие же основные "мнимые" стереотипы пока не позволяют этим структурам ориентироваться на использования профессиональных СУБД при построении своих АИС [1,2]: