Арифметика повышенной точности
Проблема точности возникает, как правило, при работе с микро- и миниЭВМ, имеющих небольшую длину машинного слова (1-2 байта). Рассмотрим микропроцессор, работающий со словами длины 1 байт. Этот формат позволяет представить целые числа в диапазоне от -128 до 127. Очевидно, что для решения большинства задач такого диапазона чисел недостаточно. Использование двух однобайтовых слов (16 бит) позволяет представить уже числа в диапазоне от -32768 до 32767. Это так называемые числа с двойной точностью. Иногда используются числа тройной точности (1 бит – знак и 23 бита для модуля числа). Это обеспечивает диапазон уже от ?8388608 до 8388607, т.е. точность существенно повышается.
Однако при работе с арифметикой повышенной точности требуется больший объем памяти для хранения того же объема данных и более интенсивная работа процессора. Увеличение объема требуемой памяти достаточно очевидно. Рассмотрим очень коротко последовательность операций при сложении чисел с тройной точностью. Здесь уже недостаточно извлечь два слова из памяти, сформировать сумму в аккумуляторе и переслать результат в однобайтовую ячейку памяти. Сначала необходимо произвести обращение к младшему значащему байту каждого числа. После сложения результат записывается в память, а возможные при этом переносы подлежат временному хранению. Затем извлекаются средние по значимости байты, их складывают и к сумме добавляют биты переноса, полученные в результате предыдущей операции. Результат записывается в память на место, специально зарезервированное для среднего байта суммы. Со старшим байтом поступают аналогично.
Таким образом, при использовании арифметики тройной точности требуются в три раза большие объем памяти и время на операции сложения по сравнению с арифметикой одинарной точности. Кроме того, в случае возникновения прерываний необходимо временно хранить содержимое регистра переносов (то же самое для вычитания, умножения и деления).
Большие ЭВМ общего назначения
На первых этапах внедрения ЭВМ в деятельность человека решаемые задачи, в основном, можно было разделить на два больших класса:
- научные и технические
расчеты – для них типичным является возможность работы со словами фиксированной длины, относительно небольшие объемы входной информации (исходных данных) и выходной информации (результатов расчета) и очень большое количество разнотипных вычислительных операций, которые необходимо выполнить в процессе решения;
- планово-экономические расчеты, статистика носят совсем иной характер. Они связаны с вводом в машину очень большого количества (массивов) исходных данных. Сама же обработка требует сравнительно небольшого числа простейших логических и арифметических операций. Однако в результате обычно выводится и печатается большое количество информации, причем, как правило, в отредактированной форме – в виде таблиц, ведомостей, различных форм и т.д. Задачи такого типа получили название задач обработки данных. ЭВМ, предназначенные для их решения, часто называли системами автоматизированной обработки данных. Подобные ЭВМ составляли основу систем АСУ.
Для систем обработки данных важно иметь возможность ввода, хранения, обработки и вывода большого количества текстовой (алфавитно-цифровой) информации, которая представлена словами переменной длины. Кроме того, для таких систем важно наличие значительного числа периферийных запоминающих устройств, хранящих большое количество информации (накопители на дисках и лентах), а также высокопроизводительных устройств ввода и вывода данных.
Для решения этих двух типов задач первоначально строили ЭВМ, которые различались уже на уровне аппаратного обеспечения. Однако резкое расширение сферы использования ЭВМ, совершенствование аппаратного и программного обеспечения, расширение понятия научно-технических расчетов привели к стиранию границ между этими двумя типами задач, а следовательно, и типами ЭВМ. В результате появились ЭВМ общего назначения (mainframe), которые стали выполнять основной объем вычислительных работ и машинной обработки информации в различных ВЦ и АСУ.
ЭВМ общего назначения универсальны и могут использоваться как для решения научно-технических задач численными методами, так и в режиме автоматической обработки данных в АСУ. Такие ЭВМ имеют высокое быстродействие, память большого объема, гибкую систему команд и способов представления данных, широкий набор периферийных устройств. Появление персональных компьютеров на некоторое время (3-4 года) снизило интерес к подобным ЭВМ, и их производство стало сокращаться. Однако уже к концу 80-х годов стало ясно, что персональные компьютеры не могут полностью заменить мэйнфреймы. В настоящее время многие фирмы (в том числе IBM) продолжают разрабатывать и выпускать новые модели мэйнфреймов, на долю которых, по мнению некоторых авторов, и приходится основной объем перерабатываемой в мире информации.
Для того чтобы понять радикальные отличия структуры первых микро- и миниЭВМ, появившихся в начале 70 годов, от структур основных типов ЭВМ, существовавших в то время – ЭВМ общего назначения, необходимо рассмотреть структуру типичных представителей этих ЭВМ (например, ЕС–ЭВМ), прототипами которых были машины IBM 360/370. Их быстродействие составляло от 200 тысяч оп/с (ЕС 1030) до 5000 тысяч оп/с (ЕС 1065) и более для старших моделей машин этого семейства. Характерной особенностью подобных ЭВМ было наличие большого количества как "быстрых", так и "медленных" периферийных устройств, которые функционировали параллельно с центральным процессором и требовали специальных средств управления. Упрощенная структура ЭВМ серии ЕС изображена на рис. 1.3.
Собственно обработка данных производилась в центральном процессоре (ЦП), содержащем АЛУ и УУ. Это самая быстродействующая часть ЭВМ, поэтому возникала проблема взаимодействия быстродействующего процессора с большим числом сравнительно медленно действующих периферийных устройств (ПУ). Для эффективного использования всего вычислительного комплекса требовалось организовать параллельную во времени работу ЦП и ПУ. Такой режим в ЭВМ общего назначения организовывался при помощи специализированных вспомогательных процессоров ввода/вывода, называемых каналами.Периферийные устройства связывались с каналами через собственные блоки управления (УПУ) –их часто называли контроллерами
ПУ– и систему сопряжения, называемую интерфейсом. Коротко рассмотрим функции этих устройств.

Числа с фиксированной запятой
Первые ЭВМ были машинами с фиксированной запятой, причем запятая фиксировалась перед старшим разрядом. В настоящее время форму ЧФЗ, как правило, применяют для представления целых чисел (запятая фиксируется после младшего разряда). Следует отметить, что нумерация разрядов в слове может быть разная. Наиболее распространенной в настоящее время является нумерация разрядов справа налево. Между тем, возможна нумерация и слева направо, которая традиционно использовалась в старых мэйнфреймах, например IBM-360/370 и некоторых других ЭВМ, в том числе и миниЭВМ.
Поскольку фиксация точки слева от СЗР в настоящее время практически не используется, рассмотрим только формат представления целых чисел на примере 32-разрядного слова, используемого в мэйнфреймах IBM-360 (рис. 2.7). Аналогичный формат используется и в современных 32-разрядных процессорах, причем нумерация разрядов может быть как справа налево, так и слева направо.

Целые числа могут быть представлены как в формате слова (32 разряда), так и в формате полуслова (16 разрядов).
Используют два варианта представления целых чисел – со знаком и без знака. В последнем случае все разряды служат для представления модуля числа. В ЭВМ реализуются оба этих варианта в формате слова и полуслова.
В мини- и микроЭВМ разрядность слова обычно меньше (16 бит), но формат представления целых чисел аналогичен рассмотренному (рис. 2.8), за исключением того, что нумерация разрядов в большинстве случаев осуществляется в другую сторону.
Следует иметь в виду, что в мини- и микроЭВМ целые числа могут быть представлены как в формате слова (16 или 8 бит), так и в формате двойного слова (32 или 16 бит). В микроЭВМ целые числа часто представляют без знака в формате слова (8 бит) или двойного слова. В современных ЭВМ, как правило, слова содержат целое число байт, кратное степени двойки (1,2,4… байта).

Рассмотрим диапазон представления чисел с фиксированной запятой (только целых чисел, т.е. точка фиксирована справа от МЗР).
Если в разрядной сетке N разрядов, то под модуль числа отводится N-1 разряд (число со знаком). Самое большое по модулю число, записанное в такой сетке, имеет вид

Следовательно, |X|max = 2N-1 -1 или 0 £|X|£ 2N-1 - 1.
При записи отрицательных чисел в дополнительном коде наибольшее по модулю отрицательное число – это -2N-1. Но модуль этого числа при такой же разрядной сетке (N бит) получить уже нельзя. Поэтому диапазон представления десятичных чисел N-разрядным двоичным числом определяется следующим выражением:
-2N-1£X£ 2N-1-1 .
В табл. 2.2 приведены диапазоны представления десятичных чисел 8-, 16- и 32- разрядными двоичными числами.
Таблица 2.2
|
N |
8 |
16 |
32 |
|
Xmax |
127 |
32767 |
2147483647 |
|
Xmin |
-128 |
-32768 |
- 2147483648 |
В настоящее время представление чисел с фиксированной запятой используется как основное и единственное лишь в сравнительно небольших по своим вычислительным возможностям машинах. Подобные ЭВМ применяют в системах передачи данных, для управления технологическими процессами, для обработки измерительной информации в реальном масштабе времени, для построения кодирующих и декодирующих устройств в каналах связи. В ЭВМ общего назначения основным является представление чисел с плавающей запятой.
Числа с плавающей запятой
Представление чисел в виде ЧПЗ позволяет избавиться от операции масштабирования при вычислениях, поскольку диапазон представляемых чисел существенно расширяется по сравнению с ЧФЗ. Однако в большинстве ЭВМ общего назначения, для целых чисел сохраняется возможность представления в виде ЧФЗ. Операции с ЧФЗ всегда выполняются за меньшее время, чем операции с ЧПЗ. В частности, к операциям с целыми числами сводятся операции над кодами адресов (операции индексной арифметики).
Представление чисел с плавающей запятой в общем случае имеет вид:
X = Sp*q; |q|<1,
где q – мантисса (правильная дробь со знаком),
p – порядок (целое число со знаком),
S – основание,
Sp – характеристика.
В ЭВМ q и p представлены в системе счисления с основанием S в соответствующей двоичной кодировке. Знак числа совпадает со знаком мантиссы. Порядок может быть как положительным, так и отрицательным и определяет положение точки в числе X. Арифметические действия над ЧПЗ требуют помимо действий с мантиссами, определенные операции над порядками (сравнение, вычитание и др.). Для упрощения операций над p их сводят к действиям над целыми положительными числами, применяя представление ЧПЗ со смещенным порядком.
В этом случае к порядку p прибавляют целое число R=2k, где k – число двоичных разрядов, используемых для представления модуля порядка. Смещенный порядок PСМ=P+R всегда больше нуля или равен ему. Для его представления требуется такое же количество двоичных разрядов, как и для представления знака и модуля p.
При фиксированном числе разрядов мантиссы любая величина представляется в ЭВМ нормализованным числом с наибольшей возможной точностью. Число называется нормализованным, если мантисса q удовлетворяет условию 1>|q|³1/S, т.е. старший разряд мантиссы в S-ричной системе счисления отличен от нуля, иначе число не нормализовано. Так, например, в десятичной системе счисления число 0.00726*10-3 не нормализовано, а число 0.726*10-5 – нормализовано.
В процессе вычислений числа могут оказаться ненормализованными. Обычно ЭВМ автоматически нормализует такие числа, выполняя ряд действий. На рис. 2.9 представлен обобщенный формат представления ЧПЗ в микро- и миниЭВМ.

Пусть r старших разрядов S-ричной мантиссы равны нулю. Тогда нормализация состоит:
- из сдвиг мантиссы на r разрядов влево;
- уменьшения PСМ
на r единиц;
- запись нуля в r младших разрядах мантиссы.
При этом число не изменяется, а условия нормализации выполняются.
Пример.
Нормализовать двоичное число.
Ненормализованное двоичное число:

Нормализованное двоичное число:

Пример.
Нормализовать двоичное число.
Ненормализованное двоичное число:

Нормализованное двоичное число:

Следует иметь в виду, что нормализация может происходить в другую сторону, если в результате выполнения операции слева от точки появилась единица. В этом случае необходимо выполнить следующие операции:
- сдвиг мантиссы на один разряд вправо;
- увеличение PСМ
на единицу.
В различных ЭВМ числа с плавающей запятой используются в системах счисления с различными основаниями S, но равными целым степеням числа 2, т.е. S=2W. При этом порядок представляют целым числом, а мантиссу q – числом, в котором группы по W двоичных разрядов изображают цифры мантиссы с основанием системы счисления S=2W. В современных ЭВМ используются, как правило, S = 2, 16.
Использование S>2 позволяет:
- расширить диапазон представления чисел;
- ускорить выполнение операций нормализации, поскольку сдвиг может сразу происходить на несколько разрядов (при S=16 – сдвиг на 4 разряда).
Пример.
В результате операции получили (S=16):

Произведем нормализацию. Для этого q нужно сдвинуть влево на один шестнадцатеричный разряд, т.е. на 4 двоичные единицы, а из P вычесть 1. В результате получим

Итак, диапазон представляемых в ЭВМ чисел с плавающей запятой зависит от основания системы счисления S и числа разрядов, выделенных для P.
Точность вычисления для ЧПЗ определяется числом разрядов q. С увеличением числа разрядов q увеличивается точность, но одновременно увеличивается и время выполнения арифметических операций. Ввиду этого использование S, отличного от 2, несколько уменьшает точность вычислений при фиксированном числе двоичных разрядов q. Традиционно шестнадцатеричная арифметика используется в мэйнфреймах.
Задачи, решаемые на ЭВМ, предъявляют различные требования к точности вычисления, поэтому большинство машин общего назначения имеют несколько форматов ЧПЗ с различным числом разрядов q. Рассмотрим только короткие форматы ЧПЗ в ЭВМ с 32-разрядным словом, использующих шестнадцатеричную (S=16) и двоичную (S=2) системы счисления.
Формат ЧПЗ при S=16 представлен на рис. 2.10.

Всего под q отведено 24 двоичных разряда. Общая длина слова N – 32 двоичных разряда. Еще есть длинный формат (64 бита) и расширенный (128 бит). Во всех форматах под PСМ отведено по 7 двоичных разрядов (с первого по седьмой). Если бы порядок был несмещенный, то один двоичный разряд отводился бы под знак порядка и k разрядов – под модуль (k = 6). При этом диапазон изменения модуля несмещенного порядка P составил бы 0 ¸ 2k-1 или 0 ¸ 63, а полный диапазон изменения порядка Р = (-64) ¸ (+63). Выражение для смещенного порядка соответственно имеет вид

Таким образом, при S=16 диапазон изменения PСМ = 0 ¸ 127.
Следует иметь в виду, что при изображении машинного слова с помощью шестнадцатеричных символов первые две старшие шестнадцатеричные цифры представляют совместно знак числа и смещенный порядок.
Формат ЧПЗ при S=2 представлен на рис. 2.11.

Общая длина слова N – 32 двоичных разряда. Обычно еще есть длинный формат, имеющий N = 64 бита. В обоих форматах под смещенный порядок отведено 8 двоичных разрядов. Таким образом, диапазоны изменения смещенного и несмещенного порядков составляют соответственно
PСМ
= 0...255 и P = -128...+127 .
Поскольку числа в памяти хранятся в нормализованной форме, старший разряд q всегда равен единице, поэтому он не запоминается, а подразумевается., В таких ЭВМ точность представления числа фактически определяется мантиссой q в 24 двоичных разряда (короткий формат) и 56 двоичных разрядов (длинный формат).
Рассмотрим только короткие форматы.
Диапазон представления ЧПЗ определяется значением S и числом разрядов, отведенных под P.
Двоичное основание (S=2): (k=7) Xmax=2127® 1038 .
Шестнадцатеричное основание (S=16): (k=6) Xmax=1663® 1076 .
Точность представления ЧПЗ определяется значением S и числом разрядов мантиссы в соответствующей системе счисления. И при S=16, и при S=2 под q отведено фактически 24 двоичных разряда:
при S=2: 24 двоичных разряда обеспечивают точность, соответствующую семи десятичным разрядам;
при S=16: точность при использовании короткого слова (N = 32) ниже за счет другого способа нормализации, т.е. в q могут быть три нуля слева, поскольку шестнадцатеричное число при этом еще не равно нулю. В двоичных числах слева всегда единица, то есть разрядная сетка используется полнее. Пояснить это можно на примере 8-разрядной сетки:

При S=16 нормализация не произойдет, так как d1 не равно нулю. Это приведет к потере четырех младших разрядов результата. При S=2 нормализация произойдет и будет потерян только один младший разряд результата. В связи с этим в ЭВМ с S=16 обычно предусматриваются еще длинный и расширенный форматы.
Еще до недавнего времени каждый производитель процессоров пользовался собственным представлением вещественных чисел (чисел с плавающей точкой). За последние несколько лет ситуация изменилась. Большинство поставщиков процессоров в настоящее время для представления вещественных чисел придерживаются стандарта ANSI/IEEE 754-1985 Standard for Binary Floating-Point Arithmetic.
Стандарт описывает два основных формата ЧПЗ: одиночный (single – 32 бита) и двойной (double – 64 бита). В IEEE 754 не указан точный размер расширенного формата, но описаны минимальная точность и размер (79 бит).
Формат числа – структура, определяющая поля, составляющие число с плавающей запятой, их размер, расположение и интерпретацию.
Одиночный формат
Одиночный формат состоит из трех полей: 23-разрядной мантиссы f, 8-разрядного смещенного порядка e, знакового бита s (см.
рис. 2.12).

В табл. 2. 3 показано соответствие между значениями трех полей и значением числа с плавающей запятой.
Таблица 2.3
|
Комбинация значений полей |
Значение |
|
0 < e < 255 |
(-1)s × 2e-127 × 1.f (нормализованные числа) |
|
e= 0; f ¹ 0 (по крайней мере, один бит не нулевой) |
(-1)s × 2-126 × 0.f (ненормализованные числа) |
|
e= 0; f = 0 (все биты нулевые) |
(-1)s × 0.0 (ноль со знаком) |
|
e= 255; f = 0 (все биты нулевые) |
INF (бесконечность со знаком) |
|
e= 255; f ¹0 (по крайней мере, один бит не нулевой) |
NaN (Not-a-Number) |
Двойной формат
Двойной формат состоит из трех полей: 53-разрядной мантиссы f, 11-разрядного смещенного порядка e, знакового бита s. Эти поля хранятся в двух 32-разрядных словах, как показано на рис. 2.13. В x86–архитектуре слово с меньшим адресом содержит младшие разряды мантиссы, в то время как, например, в SPARC– архитектуре младшие разряды мантиссы содержит слово с большим адресом.

В табл. 2.4 показано соответствие между значением трех полей и значением ЧПЗ двойной точности.
Таблица 2.4
|
Комбинация значений полей |
Значение |
|
0 < e < 2047 |
(-1)s × 2e-1023 × 1.f (нормализованное число) |
|
e = 0; f ¹ 0 |
(-1)s × 2-1022 × 0.f (ненормализованное число) |
|
e = 0; f = 0 |
(-1)s × 0.0 (ноль со знаком) |
|
s = 0; e = 2047; f = 0 |
+INF (положительная бесконечность) |
|
s = 1; e = 2047; f = 0 |
-INF (отрицательная бесконечность) |
|
e = 2047; f ¹ 0 |
NaN (Not-a-Number) |
Расширенный формат (SPARC– архитектура)
Расширенный формат состоит из трех полей: 112-разрядной мантиссы f,
15-разрядного смещенного порядка e, знакового бита s. Эти поля хранятся в четырех 32-разрядных словах, как показано на рис. 2.14. В SPARC–архитектуре младшие разряды мантиссы содержит слово с большим адресом.

В табл. 2.5 показано соответствие между значением трех полей и значением ЧПЗ расширенного формата для SPARC–архитектуры.
Таблица 2.5
|
Комбинация значений полей |
Значение |
|
0 < e < 32767 |
(-1)s × 2e-16383 × 1.f (нормализованное число) |
|
e = 0; f ¹ 0 |
(-1)s × 2-16382 × 0.f (ненормализованное число) |
|
e = 0; f = 0 |
(-1)s × 0.0 (ноль со знаком) |
|
s = 0; e = 32767; f = 0 |
+INF (положительная бесконечность) |
|
s = 1; e = 32767; f = 0 |
-INF (отрицательная бесконечность) |
|
e = 32767; f ¹ 0 |
NaN (Not-a-Number) |
Расширенный формат состоит из 4-ч полей: 63-разрядной мантиссы f, явного старшего значащего бита j, 15-разрядного смещенного порядка e, знакового бита s.
В х86–архитектуре эти поля сохранены в восьми последовательно адресованных 8-разрядных байтах. Однако UNIX System V Application Binary Interface Intel 386 Processor Supplement (Intel ABI) требует, чтобы числа расширенного формата занимали три последовательно адресованных 32-разрядных слова в стеке, оставляя 16 старших бит неиспользованными, как показано на рис. 2.15.

В табл. 2.6 показано соответствие между значениями трех полей и значением ЧПЗ расширенного формата для х86–архитектуры.
Таблица 2.6
|
Комбинация значений полей |
Значение |
|
j = 0; 0 < e < 32767 |
Не поддерживается |
|
j = 1; 0 < e < 32767 |
(-1)s × 2e-16383 × 1.f (нормализованное число) |
|
j = 0; e = 0; f ¹ 0 |
(-1)s × 2-16382 × 0.f (ненормализованное число) |
|
j = 1; e = 0 |
(-1)s × 2-16382 × 0.f (псевдоненормализованное число) |
|
j = 0; e = 0; f = 0 |
(-1)s × 0.0 (ноль со знаком) |
|
j = 1; s = 0; e = 32767; f = 0 |
+INF (положительная бесконечность) |
|
j = 1; s = 1; e = 32767; f = 0 |
-INF (отрицательная бесконечность) |
|
j = 1; e = 32767; f ¹ 0 |
quiet или signaling NaN |
Мэйнфреймы
В мэйнфреймах фирмы IBM используемое еще со времен S/360 шестнадцатеричное представление чисел с плавающей запятой – с шестнадцатеричной мантиссой и характеристикой (HFР) – в ESA/390 (мэйнфреймы серии S/390) дополнено двоичным представлением BFP, удовлетворяющим стандарту IEEE 754. Это представление определяет 3 формата данных – короткий, длинный и расширенный– и 87 новых команд для работы с ними.
BFP появилось в ESA/390 относительно недавно, в 1998 году. Одновременно было введено 12 дополнительных регистров FR (общее число FR достигло 16). Кроме того, в архитектуре появился управляющий регистр с плавающей запятой и средства сохранения содержания регистров при операции записи состояния. Добавлено еще 8 новых команд, не связанных однозначно с тем или иным представлением данных с плавающей запятой, в том числе 4 – для преобразования между форматами HFP и BFP.
Для работы с HFP-данными появилось 26 новых команд, являющихся аналогами соответствующих BFP-команд. Эти новые команды включают, в частности, преобразования между форматами чисел с фиксированной и с плавающей запятой и новые операции с расширенной точностью.
В суперкомпьютерах NEC SX-4 (представленных в 1995 году) целые числа могут быть как 32-, так и 64-разрядными. Для чисел с плавающей запятой применяется стандарт IEEE 754 (как для 32-, так и для 64-разрядных чисел). Кроме того, SX-4 может работать со 128-разрядными числами с плавающей запятой расширенной точности и с форматами чисел с плавающей запятой, используемыми в PVP-системах Cray и мэйнфреймах IBM. При этом производительность SX-4 не зависит от формата представления, а сам этот формат выбирается при компиляции.
Деление
Деление – операция, обратная умножению, поэтому при делении двоичных чисел, так же как и в десятичной системе счисления, операция вычитания повторяется до тех пор, пока уменьшаемое не станет меньше вычитаемого. Число этих повторений показывает, сколько раз вычитаемое укладывается в уменьшаемом.
Пример.
Вычислить 204(10) /12(10)
в двоичном коде.

Таким образом, процедура деления не так проста для машинной реализации, поскольку постоянно приходится выяснять, сколько раз делитель укладывается в определенном числе. В общем случае частное от деления получается дробным, причем выбор положения точки совершенно аналогичен тому, как это делается при операциях с десятичными числами.

Вычислить 1100.011(2)/10.01(2).
Деление чисел с плавающей запятой
Алгоритмы деления чисел с плавающей запятой в настоящем курсе не рассматриваются. Информацию о них можно найти в литературе, приведенной в конце главы.
Деление модулей двоично-десятичных чисел
Операция деления выполняется путем многократного вычитания, сдвига и анализа результата подобно тому, как это делается при обычном делении. В настоящем курсе эта операция не рассматривается. Информация о ней может быть найдена в литературе, приведенной в конце главы.
Деление в дополнительном коде
Деление в дополнительном коде осуществляется по тем же правилам, что были описаны в п. 5.4. разд. "Двоичная арифметика". Но метод деления "столбиком" для ЭВМ не пригоден. Используются более громоздкие методы деления, которые здесь не рассматриваются. Информацию о них можно найти в литературе, приведенной в конце главы.
Десятичная арифметика
Необходимый перевод для ЭВМ десятичных чисел в двоичные и обратно требует затраты времени и ресурсов. В цифровых устройствах, где основная часть операций связана не с обработкой и хранением информации, а с самим ее вводом и выводом на какие-либо устройства отображения с десятичным представлением полученных результатов, имеет смысл проводить вычисления в десятичной системе счисления. Но ЭВМ требует информацию только в двоичной форме. Следовательно, десятичные цифры нужно кодировать каким-либо легко реализуемым и быстрым способом. Для этих целей используется двоично-десятичный код, в котором каждая десятичная цифра 0...9 изображается соответствующим 4-разрядным числом (от 0000 до 1001). Такой код называется еще кодом 8421 (цифры, соответствующие весам двоичных разрядов).
Пример.
Представление десятичного числа в двоично-десятичном коде.

Две двоично-десятичные цифры составляют 1 байт, т.е. с помощью 1 байта можно представить десятичные числа от 0 до 99.
Действия над двоично-десятичными числами выполняются как над двоичными. Сложности возникают при переносе из тетрады в тетраду.
Кроме того, следует отметить, что выполнение сложения и вычитания двоично-десятичных чисел со знаком сводится к сложению или вычитанию модулей путем определения фактически выполняемой операции по знаку операндов и виду выполняемой операции. Например, требуется вычислить Z=X-Y при X<0 и Y<0. Тогда выполняется операция |Z|=|Y|-|X|, а затем знак |Z| изменяется на противоположный.
Дополнительный код
Дополнительный код (ДК) строится следующим образом. Сначала формируется обратный код (ОК), а затем к младшему разряду (МЗР) добавляют 1. При выполнении арифметических операций положительные числа представляются в прямом коде (ПК), а отрицательные числа – в ДК, причем обратный перевод ДК в ПК осуществляется аналогичными операциями в той же последовательности. На рис. 2.3 рассмотрена цепь преобразований числа из ПК в ДК и обратно в двух вариантах.

Пример.
Число -5(10) перевести в ДК и обратно (первый вариант).

Пример.
Число -5(10) перевести в ДК и обратно (второй вариант).

Использование ДК для представления отрицательных чисел устраняет двусмысленное представление нулевого результата (наличие двух нулей: +0 и -0), так как -0 исчезает.
В общем случае использованием ДК для записи отрицательных чисел можно перекрыть диапазон десятичных чисел от -2k-1
до +2k-1-1, где k – число используемых двоичных разрядов, включая знаковый. Так, с помощью одного байта можно представить десятичные числа от -128 до +127 либо только положительные числа от 0 до 255 (здесь под положительными числами понимаются числа без знака). В табл.2.1 приведены 4-разрядные двоичные числа от 0000 до 1111 и десятичные числа для представления их со знаком и без знака. Из этой таблицы следует, что в формате 4-разрядного двоичного числа могут быть представлены десятичные числа со знаком в диапазоне от -8 до +7 или десятичные числа без знака в диапазоне от 0 до +15.
Оба способа представления чисел широко используются в ЭВМ.
Таблица 2.1
Представление десятичных чисел одним полубайтом
| 4 - разрядное
двоичное число | Десятичные эквиваленты двоичного числа со знаком | Десятичные эквиваленты двоичного числа без знака | |||
 | +0 | 0 | |||
| 0001 | +1 | 1 | |||
| . . . . ПК | . . . | . . . | |||
| 0110 | +6 | 6 | |||
| 0111 | +7 | 7 | |||
 | -8 | 8 | |||
| 1001 | -7 | 9 | |||
| 1010 | -6 | 10 | |||
| . . . . ДК | . . . | . . . | |||
| 1110 | -2 | 14 | |||
| 1111 | -1 | 15 |
В ЭВМ используется быстрый способ формирования ДК.При этом двоичное число просматривается от МЗР к СЗР. Пока встречаются нули, их копируют в разряды результата. Первая встретившаяся единица также копируется в соответствующий разряд, а каждый последующий бит исходного числа заменяется на противоположный (0 на 1, 1 на 0).
Пример.
Число -44(10) (10101100
(2)) перевести в ДК и обратно.
Проверка:

Пример.
Перевести в ДК модуль числа -44.

Видно, что результаты преобразований обоими методами совпадают.
Два класса ЭВМ
Любая сфера человеческой деятельности, любой процесс функционирования технического объекта связаны с передачей и преобразованием информации. Одно из важнейших положений кибернетики состоит в том, что без информации, ее передачи и переработки невозможны организованные системы – ни биологические, ни технические, искусственно созданные человеком.
Информацией называются сведения о тех или иных явлениях природы, событиях общественной жизни, процессах в технических устройствах. Информация, зафиксированная в некоторых материальных формах (на материальном носителе), называется сообщением, например:
статистические данные о работе предприятия и потребности производства в материалах;
данные переписи населения;
данные для диспетчера аэропорта о перемещении самолетов в воздухе;
данные о толщине прокатываемого листа.
Все эти сообщения отличаются друг от друга по источнику информации, по способу представления, по продолжительности и т.д. Но их объединяет одно – информацию, которую они несут, необходимо передать, переработать и как-то использовать.
В общем случае сообщения могут быть непрерывными (аналоговыми) и дискретными (цифровыми).
Аналоговое сообщение представляется некоторой физической величиной (обычно электрическим током или напряжением), изменение которой во времени отражает протекание рассматриваемого процесса, например температуры в нагревательной печи. Физический процесс, передающий непрерывное сообщение, может в определенном интервале принимать любые значения и изменяться в произвольные моменты времени, т.е. может иметь бесконечное множество состояний.
Дискретное сообщение характеризуется конечным набором состояний, например, передача текста. Каждое из этих состояний можно представить в виде конечной последовательности символов или букв, принадлежащих конечному множеству, называемому алфавитом. Такая операция называется кодированием, а последовательность символов – кодом. Число символов, входящих в алфавит, называется основанием кода. Важным здесь является не физическая природа символов кода, а то, что за конечное время можно передать только конечное число состояний сообщения.
Причем, чем меньше основание кода, тем длиннее требуются кодовые группы для передачи фиксированного набора состояний сообщения.
В настоящее время в абсолютном большинстве случаев используются коды с основанием два, т.е. информация представляется в виде бинарных импульсных последовательностей, или двоичных кодов.
Передачу и преобразование любой дискретной информации всегда можно свести к эквивалентной передаче и преобразованию двоичных кодов, или цифровой информации.
Более того, возможно с любой заранее заданной степенью точности непрерывное сообщение заменить цифровым путем квантования непрерывного сообщения по уровню и дискретизации его по времени. Однако следует иметь в виду, что с увеличением точности представления аналогового сообщения растет разрядность кода. Это может привести к тому, что обработка аналогового сообщения в цифровой форме на конкретной ЭВМ в реальном масштабе времени окажется невозможной.
Таким образом, любое сообщение может быть с определенной степенью точности представлено в цифровой форме.
Электронные вычислительные машины (ЭВМ) являются преобразователями информации. В них исходные данные задачи преобразуются в результат ее решения. В соответствии с используемой формой представления информации при преобразовании ЭВМ делятся на два больших класса – аналоговые и дискретного действия – цифровые. Их обозначают как АВМ и ЦВМ соответственно. С 70-х годов термин ЭВМ относят именно к машинам дискретного действия, или ЦВМ, принципы функционирования которых и будут рассмотрены в настоящем курсе.
Двоичная арифметика
Правила выполнения арифметических действий над двоичными числами определяются арифметическими действиями над одноразрядными двоичными числами.

перенос в
старший разряд
Правила выполнения арифметических действий во всех позиционных системах счисления аналогичны.
Двоичная система счисления
В двоичной системе счисления основание S = 2, т.е. используются всего два символа: 0 и 1. Двоичная система счисления проще десятичной. Однако двоичное изображение числа требует большего (для многоразрядного числа примерно в 3,3 раза) числа разрядов, чем его десятичное представление. Тем не менее применение двоичной системы создает большие удобства для проектирования ЭВМ, так как для представления в машине разряда двоичного числа может быть использован любой простой элемент, имеющий всего два устойчивых состояния. Также достоинством двоичной системы счисления является простота двоичной арифметики.
В общем виде двоичное число выглядит следующим образом:


Вес каждого разряда в двоичной системе счисления кратен 2 или 1/2.
Пример.
Двоичное число – 101101(2).
Веса
 |  |  |
т.е.

Как и в десятичной, в двоичной системе счисления для отделения целой части от дробной используется точка. Значение веса разрядов справа от точки равно основанию двоичной системы (2), возведенному в отрицательную степень. Такие веса – это дроби вида: 1/2, 1/22, 1/23, 1/24, 1/25 или 1/2, 1/4, 1/8, 1/16. Их можно выразить через десятичные дроби: 2-1 = 0.5, 2-2 = 0.25, 2-3
= 0.125, 2-4 = 0,0625.
В общем случае двоичное число имеет целую и дробную части, например 1101101.10111.
Каждая позиция, занятая двоичной цифрой, называется битом. Бит является наименьшей единицей информации в ЭВМ. Наименьшим значащим битом (МЗР) называют самый младший двоичный разряд, а самым старшим двоичным разрядом – наибольший значащий бит (СЗР). В двоичном числе эти биты имеют соответственно наименьший и наибольший вес. Обычно двоичное число записывают так, что старший значащий бит является крайним слева.
Двоично-десятичная система счисления
Эта система имеет основание S = 10, но каждая цифра изображается четырехразрядным двоичным числом, называемым тетрадой. Обычно данная система счисления используется в ЭВМ при вводе и выводе информации. Однако в некоторых типах ЭВМ в АЛУ имеются специальные блоки десятичной арифметики, выполняющие операции над числами в двоично-десятичном коде. Это позволяет в ряде случаев существенно повышать производительность ЭВМ.
Например, в автоматизированной системе обработки данных чисел много, а вычислений мало. В этом случае операции, связанные с переводом чисел из одной системы в другую, существенно превысили бы время выполнения операций по обработке информации.
Перевод чисел из десятичной системы в двоично-десятичную весьма прост и заключается в замене каждой цифры двоичной тетрадой.
Пример.
Записать десятичное число 572.38(10)
в двоично-десятичной системе счисления.

Обратный перевод также прост: необходимо двоично-десятичное число разбить на тетрады от точки влево (для целой части) и вправо (для дробной), дописать необходимое число незначащих нулей, а затем каждую тетраду записать в виде десятичной цифры.
Пример.
Записать двоично-десятичное число 10010.010101(2-10) в десятичной системе счисления.

Перевод чисел из двоично-десятичной в двоичную систему осуществляется по общим правилам, описанным выше.
Форма Ответы на вопросы
1. На листах ответа должны быть указаны номер группы, фамилия студента и номер его варианта.
2. Номера вопросов выбираются студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 2.7 аn-1 – предпоследняя цифра номера, аn
– последняя цифра. В клетках таблицы стоят номера вопросов, на которые необходимо дать письменный ответ
Таблица 2.7
| an
an-1 | 0 | 1 | 2 | 3 | 4 | ||||||
| 0 | 1,5,9,13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | ||||||
| 1 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9,16,23 | 1,5,11,14,21 | 3,6,9,14,19 | ||||||
| 2 | 1,6,9,18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9,18,22 | 2,7,9,17,19 | ||||||
| 3 | 1,5,9,13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | ||||||
| 4 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9,16,23 | 1,5,11,14,21 | 3,6,9,14,19 | ||||||
| 5 | 1,6,9,18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9,18,22 | 2,7,9,17,19 | ||||||
| 6 | 1,5,9,13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 | ||||||
| 7 | 3,8,10,18,20 | 4,6,12,13,22 | 2,7,9,16,23 | 1,5,11,14,21 | 3,6,9,14,19 | ||||||
| 8 | 1,6,9,18,19 | 2,5,10,17,20 | 1,8,11,16,21 | 3,5,9,18,22 | 2,7,9,17,19 | ||||||
| 9 | 1,5,9,13,19 | 2,6,10,14,20 | 3,7,11,15,21 | 4,8,12,16,22 | 1,7,12,17,23 |
| an
an-1 | 5 | 6 | 7 | 8 | 9 | ||||||
| 0 | 2,8,9,15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 | ||||||
| 1 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | ||||||
| 2 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9,17,21 | ||||||
| 3 | 2,8,9,15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 | ||||||
| 4 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | ||||||
| 5 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9,17,21 | ||||||
| 6 | 2,8,9,15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 | ||||||
| 7 | 4,7,10,13,20 | 1,6,12,14,23 | 2,7,11,15,20 | 3,5,11,18,21 | 4,8,10,15,22 | ||||||
| 8 | 1,6,10,14,22 | 3,7,12,16,19 | 4,7,12,15,23 | 2,5,10,13,23 | 4,6,9,17,21 | ||||||
| 9 | 2,8,9,15,19 | 3,5,10,16,20 | 4,6,11,13,21 | 1,8,11,17,22 | 2,5,12,18,23 |
Форма Выполнение арифметических операций над числами
1. Все действия, производимые над операндами и результатами, включая перевод чисел из одной системы счисления в другую, должны быть подробно расписаны в соответствии с алгоритмами, рассмотренными в этом разделе.
2. В операциях перемножения указать вариант операции, т.е. "старшими разрядами вперед" или "младшими разрядами вперед".
3. Результаты представить в десятичной системе счисления.
4. На листах ответа должны быть указаны номер группы, фамилия студента и номер варианта задания.
5. Номер варианта задания выбирается студентом в соответствии с двумя последними цифрами в его зачетной книжке. В табл. 2.8 аn-1 – предпоследняя цифра номера, аn
– последняя цифра. В клетках табл. 2.8 стоят номера вариантов заданий, полный список которых приведен в табл. 2.9.
Таблица 2.8
| an
an-1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||
| 0 | 1 | 19 | 34 | 27 | 5 | 14 | 20 | 30 | 9 | 26 | |||||||||||
| 1 | 28 | 2 | 31 | 4 | 13 | 6 | 15 | 8 | 32 | 10 | |||||||||||
| 2 | 21 | 35 | 3 | 12 | 22 | 33 | 7 | 16 | 23 | 18 | |||||||||||
| 3 | 29 | 24 | 11 | 36 | 28 | 25 | 30 | 29 | 17 | 34 | |||||||||||
| 4 | 20 | 9 | 12 | 8 | 22 | 5 | 15 | 4 | 27 | 1 | |||||||||||
| 5 | 11 | 36 | 21 | 35 | 14 | 32 | 24 | 33 | 18 | 31 | |||||||||||
| 6 | 19 | 10 | 13 | 7 | 23 | 6 | 16 | 3 | 26 | 2 | |||||||||||
| 7 | 17 | 25 | 1 | 15 | 34 | 33 | 27 | 29 | 12 | 20 | |||||||||||
| 8 | 14 | 2 | 22 | 5 | 35 | 8 | 36 | 9 | 21 | 11 | |||||||||||
| 9 | 3 | 16 | 4 | 18 | 6 | 19 | 7 | 13 | 10 | 17 |
Задание 1. Выполнить арифметические действия, рассматривая операнды как ЧФЗ справа от МЗР в формате 1-го байта. Определить модуль результата. Формат результата – 2 байта.
Задание 2. Выполнить арифметические действия, рассматривая операнды как ЧПЗ с основанием 2 в следующем формате: несмещенный порядок – 4 бита, мантисса – 8 бит.
Формат результата – тот же. Округление производить после приведения операнда к нормализованной форме. Результат нормализовать.
Задание 3. Выполнить арифметические действия над операндами, представив их в двоично-десятичном коде.
Варианты заданий Таблица 2.9
|
№ варианта |
Операнды |
Задание 1 (ЧФЗ) |
Задание 2 (ЧПЗ) |
Задание 3 (2-10) |
||||||
|
Операции |
Операции |
Операции |
||||||||
|
X+Y |
X-Y |
X*Y |
X+Y |
X-Y |
X*Y |
X+Y |
X-Y |
X*Y |
||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
01 |
X Y |
15 33 |
15 33 |
15 33 |
15.33 33.15 |
15.33 33.15 |
15.33 33.15 |
153 331 |
153 331 |
153 331 |
|
02 |
X Y |
32 67 |
32 67 |
32 67 |
32.67 67.32 |
32.67 67.32 |
32.67 67.32 |
326 673 |
326 673 |
326 673 |
|
03 |
X Y |
17 37 |
17 37 |
17 37 |
17.37 37.17 |
17.37 37.17 |
17.37 37.17 |
173 371 |
173 371 |
173 371 |
|
04 |
X Y |
30 63 |
30 63 |
30 63 |
30.63 63.30 |
30.63 63.30 |
30.63 63.30 |
306 633 |
306 633 |
306 633 |
|
05 |
X Y |
19 41 |
19 41 |
19 41 |
19.41 41.19 |
19.41 41.19 |
19.41 41.19 |
194 411 |
194 411 |
194 411 |
|
06 |
X Y |
28 59 |
28 59 |
28 59 |
28.59 59.28 |
28.59 59.28 |
28.59 59.28 |
285 592 |
285 592 |
285 592 |
|
07 |
X Y |
21 45 |
21 45 |
21 45 |
21.45 45.21 |
21.45 45.21 |
21.45 45.21 |
214 452 |
214 452 |
214 452 |
|
08 |
X Y |
26 55 |
26 55 |
26 55 |
26.55 55.26 |
26.55 55.26 |
26.55 55.26 |
265 552 |
265 552 |
265 552 |
|
09 |
X Y |
23 49 |
23 49 |
23 49 |
23.49 49.23 |
23.49 49.23 |
23.49 49.23 |
234 492 |
234 492 |
234 492 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
10 |
X Y |
24 51 |
24 51 |
24 51 |
24.51 51.24 |
24.51 51.24 |
24.51 51.24 |
245 512 |
245 512 |
245 512 |
|
11 |
X Y |
25 53 |
25 53 |
25 53 |
25.53 53.25 |
25.53 53.25 |
25.53 53.25 |
255 532 |
255 532 |
255 532 |
|
12 |
X Y |
22 47 |
22 47 |
22 47 |
22.47 47.22 |
22.47 47.22 |
22.47 47.22 |
224 472 |
224 472 |
224 472 |
|
13 |
X Y |
27 57 |
27 57 |
27 57 |
27.57 57.27 |
27.57 57.27 |
27.57 57.27 |
275 572 |
275 572 |
275 572 |
|
14 |
X Y |
20 43 |
20 43 |
20 43 |
20.43 43.20 |
20.43 43.20 |
20.43 43.20 |
204 432 |
204 432 |
204 432 |
|
15 |
X Y |
29 61 |
29 61 |
29 61 |
29.61 61.29 |
29.61 61.29 |
29.61 61.29 |
296 612 |
296 612 |
296 612 |
|
16 |
X Y |
38 54 |
38 54 |
38 54 |
38.54 54.38 |
38.54 54.38 |
38.54 54.38 |
385 543 |
385 543 |
385 543 |
|
17 |
X Y |
31 65 |
31 65 |
31 65 |
31.65 65.31 |
31.65 65.31 |
31.65 65.31 |
316 653 |
316 653 |
316 653 |
|
18 |
X Y |
16 35 |
16 35 |
16 35 |
16.35 35.16 |
16.35 35.16 |
16.35 35.16 |
163 351 |
163 351 |
163 351 |
|
19 |
X Y |
13 31 |
13 31 |
13 31 |
13.31 31.13 |
13.31 31.13 |
13.31 31.13 |
133 331 |
133 331 |
133 331 |
|
20 |
X Y |
18 72 |
18 72 |
18 72 |
18.72 72.18 |
18.72 72.18 |
18.72 72.18 |
187 721 |
187 721 |
187 721 |
|
21 |
X Y |
15 48 |
15 48 |
15 48 |
15.48 48.15 |
15.48 48.15 |
15.48 48.15 |
154 481 |
154 481 |
154 481 |
|
22 |
X Y |
41 58 |
41 58 |
41 58 |
41.58 58.41 |
41.58 58.41 |
41.58 58.41 |
415 584 |
415 584 |
415 584 |
|
23 |
X Y |
22 81 |
22 81 |
22 81 |
22.81 81.22 |
22.81 81.22 |
22.81 81.22 |
228 812 |
228 812 |
228 812 |
|
24 |
X Y |
19 74 |
19 74 |
19 74 |
19.74 74.19 |
19.74 74.19 |
19.74 74.19 |
197 741 |
197 741 |
197 741 |
|
25 |
X Y |
46 73 |
46 73 |
46 73 |
46.73 73.46 |
46.73 73.46 |
46.73 73.46 |
467 734 |
467 734 |
467 734 |
|
26 |
X Y |
38 62 |
38 62 |
38 62 |
38.62 62.38 |
38.62 62.38 |
38.62 62.38 |
386 623 |
386 623 |
386 623 |
|
27 |
X Y |
14 51 |
14 51 |
14 51 |
14.51 51.14 |
14.51 51.14 |
14.51 51.14 |
145 511 |
145 511 |
145 511 |
|
28 |
X Y |
23 36 |
23 36 |
23 36 |
23.36 36.23 |
23.36 36.23 |
23.36 36.23 |
233 362 |
233 362 |
233 362 |
|
29 |
X Y |
34 71 |
34 71 |
34 71 |
34.71 71.34 |
34.71 71.34 |
34.71 71.34 |
347 713 |
347 713 |
347 713 |
|
30 |
X Y |
19 64 |
19 64 |
19 64 |
19.64 64.19 |
19.64 64.19 |
19.64 64.19 |
196 641 |
196 641 |
196 641 |
|
31 |
X Y |
42 69 |
42 69 |
42 69 |
42.69 69.42 |
42.69 69.42 |
42.69 69.42 |
426 694 |
426 694 |
426 694 |
|
32 |
X Y |
35 68 |
35 68 |
35 68 |
35.68 68.35 |
35.68 68.35 |
35.68 68.35 |
356 683 |
356 683 |
356 683 |
|
33 |
X Y |
21 75 |
21 75 |
21 75 |
21.75 75.21 |
21.75 75.21 |
21.75 75.21 |
217 752 |
217 752 |
217 752 |
|
34 |
X Y |
17 66 |
17 66 |
17 66 |
17.66 66.17 |
17.66 66.17 |
17.66 66.17 |
176 661 |
176 661 |
176 661 |
Окончание табл. 2.9
|
35 |
X Y |
35 52 |
35 52 |
35 52 |
35.52 52.35 |
35.52 52.35 |
35.52 52.35 |
355 523 |
355 523 |
355 523 |
|
36 |
X Y |
28 83 |
28 83 |
28 83 |
28.83 83.28 |
28.83 83.28 |
28.83 83.28 |
288 832 |
288 832 |
288 832 |
Интерфейс
Связи всех устройств ЭВМ друг с другом осуществлялись, как и в современных ЭВМ, с помощью интерфейсов. Интерфейс представляет собой совокупность линий и шин сигналов, электронных схем и алгоритмов, предназначенную для осуществления обмена информацией между устройствами. От характеристик интерфейсов во многом зависят производительность и надежность ЭВМ.
В заключение следует отметить, что все вышесказанное относится к серийно выпускаемым в свое время крупным ЭВМ общего назначения серии ЕС (IBM 360/370). Однако в этот же период были разработаны и серийно производились суперЭВМ типа Крэй1, Крэй2, Кибер-205, "Эльбрус", ПС-2000, и т.д. Их колоссальная производительность достигалась за счет уникальных структур аппаратного и программного обеспечения. Эти ЭВМ выпускались в незначительных количествах, как правило, под конкретный заказ. Более подробно о многопроцессорных ЭВМ речь пойдет в отдельном разделе данного курса.
Каналы
Поскольку каналы предназначались для освобождения центрального процессора от вспомогательных операций, не связанных с вычислениями, они имели непосредственный доступ к ОП параллельно ЦП, естественно со своими приоритетами. Ввиду того что ПУ различаются по быстродействию и режимам работы, каналы подразделялись на байт-мультиплексные, блок-мультиплексные и селекторные.
Байт-мультиплексный канал мог обслуживать одновременно несколько сравнительно медленно действующих ПУ – печатающих, УВВ с перфокарт и перфолент, дисплеев и др. Этот канал попеременно организовывал с ними сеансы связи для передачи между ОП и ПУ небольших порций информации фиксированной длины (обычно 1-2 слова или байта). В простейшем случае происходил циклический опрос ПУ, например при работе с дисплейной станцией. В более сложном варианте байт-мультиплексный канал начинал обслуживать ПУ по их запросу, причем первым опрашивался ПУ с высшим приоритетом, а затем по очереди шло обращение ко всем остальным ПУ. Таким образом, байт-мультиплексный канал работал с "медленными" устройствами, способными ожидать обслуживание без потери информации.
Селекторный и блок-мультиплексный каналы связывали ЦП и ОП с ПУ, работающими с высокой скоростью передачи информации (магнитные диски, ленты и др.).
Селекторный канал предназначался для монопольного обслуживания одного устройства. При работе с селекторным каналом ПУ после пуска операции оставалось связанным с каналом до окончания цепи операций. Запросы на обслуживание других ПУ, так же как и новые команды пуска операций ввода-вывода от процессора, в это время не воспринимались каналом: до завершения цепи операций селекторный канал по отношению к процессору представлялся занятым устройством. Таким образом, селекторный канал предназначался для работы с быстродействующими устройствами, которые могут терять информацию вследствие задержек или прерываний в обслуживании.
Блок-мультиплексный канал обладал тем свойством, что операции, не связанные с передачей данных (установка головок на цилиндр, поиск записи и т.д.), выполнялись для нескольких устройств в мультиплексном режиме, а передача блока информации происходила в монопольном (селекторном) режиме.
Аппаратные средства каналов разделялись на две части: средства, предназначенные для обслуживания отдельных ПУ, подключенных к каналу, и оборудование, являющееся общим для устройств и разделяемое всеми устройствами во времени. Средства канала, выделенные для обслуживания одного ПУ, назывались подканалами.
Кодирование МК
Выбор способа кодирования микрокоманд представляет собой достаточно сложную задачу и зависит от структуры процессора и его целевого назначения, системы команд, быстродействия и т.д. Рассмотрим только основные способы кодирования микрокоманд.
1. Горизонтальное кодирование (рис. 3.11, а). Это простейший вариант кодирования микрокоманд, при котором каждый разряд поля кода микроопераций однозначно определяет управляющий сигнал для выполнения микрооперации.
Достоинство данного способа состоит в том, что он допускает работу нескольких устройств, т.е. параллельное выполнение ряда МО, что повышает быстродействие.
Недостаток способа – при большом наборе МО (от нескольких десятков до нескольких сотен) возрастает разрядность МК и, следовательно, разрядность ПМК.
2. Вертикальное кодирование (рис. 3.11, б). Это другой подход к кодированию МК с целью максимального сокращения разрядности поля КМО. В этом случае требуется дешифратор МО, который увеличивает временные задержки и, следовательно, время выполнения МО.

Помимо увеличения времени на МО к недостаткам следует отнести невозможность параллельного выполнения МО.
3. Смешанное кодирование (рис. 3.11, в). Это кодирование устраняет основные недостатки, присущие горизонтальному и вертикальному кодированиям.
При таком кодировании в отдельных полях кода МО объединяют взаимоисключающие наборы для обеспечения параллельного выполнения МО с разных полей. Данный способ кодирования находит широкое применение в микропрограммных УУ.
Способы 1, 2, 3 – это прямые способы кодирования. Здесь каждое поле КМО формирует определенный набор управляющих сигналов, интерпретируемых всегда одинаковым образом.
4. Косвенное кодирование (рис. 3.11, г). Этот способ кодирования позволяет еще больше уменьшить разрядность МК. Здесь одно и то же поле можно использовать для формирования СУ для различных блоков, при этом его функции определяются другим полем.
На рис. 3.11 КМО1 кодирует одну из четырех групп МО, поле КМО2 определяет реализуемую в данной группе операцию.
Пример

01 – МО в памяти и регистрах контроллеров периферийных устройств;
10 – МО безусловного и условного переходов;
11 – константы для загрузки регистров и счетчиков.
КМО2 позволяет выполнить 64 МО в любой из указанных групп оборудования.
Недостатком такого способа кодирования является увеличение объема оборудования и, следовательно, дополнительных задержек при исполнении МО.
Рассмотренные способы кодирования являются одноуровневыми. На практике используют и многоуровневое кодирование (микрокоманды, нанокоманды и т. д.).
Малые ЭВМ
Наиболее массовое внедрение ЭВМ в деятельность человека началось тогда, когда в конце 60-х годов удалось построить небольшие, достаточно простые, надежные и дешевые вычислительные устройства, элементной базой которых были микросхемы. Уменьшение объема аппаратуры и стоимости машины было достигнуто за счет укорочения машинного слова (8-16 разрядов вместо 32-64 в машинах общего назначения), уменьшения по сравнению с ЭВМ общего назначения количества типов обрабатываемых данных (в некоторых моделях только целые числа без знака), ограниченного набора команд, сравнительно небольшого объема ОП и небольшого набора ПУ.
Укорочение машинного слова повлекло за собой множество проблем, связанных с представлением данных, адресацией, составом и структурой команд, логической структурой процессора, организацией обмена информацией между устройствами ЭВМ. В процессе эволюции ЭВМ эти проблемы, так или иначе, решались, что привело к созданию малых ЭВМ, структура которых существенно отличалась от структуры больших машин.
Следует отметить, что структуры современных микро - и миниЭВМ весьма сложны и в ряде случаев мало отличаются от структуры мощных ЭВМ – все зависит от мощности используемого процессора, объема и быстродействия ОП, производительности подсистем ввода-вывода и т.д. Однако первые мини - и микроЭВМ, появившиеся в начала 70-х годов, имели весьма простую структуру, радикально отличавшуюся от структуры больших машин того времени.
Типичная структура такой микроЭВМ изображена на рис. 1.4.

Такая структура называется магистрально-модульной. Ее основу составляет общая магистраль (общая шина), к которой подсоединены в нужной номенклатуре и количестве все устройства машины, выполненные в виде конструктивно законченных модулей. Эта структура более простая и гибкая, чем у больших ЭВМ. Устройства машины обмениваются информацией только через общую магистраль.
Такая структура оказывается эффективной, а система обмена данных через общую шину – достаточно динамичной лишь при небольшом наборе ПУ.
Универсальность применения миниЭВМ при ограниченном наборе команд могла быть обеспечена лишь при сравнительно высоком быстродействии процессора – в первых моделях около 200-800 тысяч операций в секунду, что превышало скорость многих ЭВМ общего назначения. Это позволяло малым ЭВМ обслуживать технологические процессы в реальном масштабе времени, а также компенсировать замедление обработки данных, связанное с тем, что малый объем аппаратных средств вынуждал реализовывать многие процедуры обработки программным путем (например, операции арифметики с плавающей запятой).
Подобное решение оказалось настолько эффективным, что и сейчас простейшие контроллеры и микроЭВМ строятся по этой же схеме. Однако структуры сколько-нибудь сложных микро- и миниЭВМ, в частности персональных компьютеров, в процессе эволюции существенно усложнились. Современный персональный компьютер имеет сложную структуру магистралей, иерархию внутренней памяти и множество подсистем ввода-вывода различного быстродействия. Архитектура современного персонального компьютера будет рассмотрена в отдельном разделе.
Методы ускорения умножения
Рассмотренный в предыдущей теме материал показывает, что умножение – это достаточно длинная операция, состоящая из N суммирований и сдвигов, а также выделений очередных цифр множителя.
Из этого следует актуальность задачи максимального сокращения времени, затрачиваемого на операцию умножения, особенно для систем, работающих в реальном масштабе времени. В современных ЭВМ методы ускорения умножения можно разделить:
на аппаратные;
логические (алгоритмические);
комбинированные.
Аппаратные методы
1. Распараллеливание вычислительных операций. Например, совмещение во времени суммирования и сдвига.
2. Табличное умножение. Это довольно распространенный способ реализации различных функций. Остановимся на нем подробнее.
Пусть X и Y – целые числа длиной в 1 байт. Надо вычислить Z=X*Y. Можно использовать 65 Кбайт памяти и занести в них значения Z для всех возможных комбинаций X и Y, а сомножители X и Y использовать в качестве адреса. Получается своеобразная таблица следующего вида:

Алгоритмические методы
Эти методы разнообразны. Приведем только один пример: при S=16 можно за один такт обрабатывать несколько разрядов множителя (4 разряда). Сдвиги тоже осуществляются на 4 разряда. Следует отметить, однако, что в большинстве случаев алгоритмические методы требуют определенную аппаратную поддержку.
Комбинированные методы
Рассмотрим пример. Пусть X и Y – 16-разрядные числа. Надо вычислить произведение вида Z=X*Y. Использовать непосредственно табличный метод не удастся, поскольку для этих целей потребуется очень большой объем памяти. Однако можно представить каждый сомножитель как сумму двух 16-разрядных слагаемых, каждое из которых представляет группы старших и младших разрядов сомножителей. В этом случае произведение примет вид
Z = X*Y = (x15 ... x0)*(y15 ... y0) =
= (x15...x8000...0 + 000...0x7...x0)* (y15...y8000...0 + 000...0y7...y0) =
= 216(x15...x8) (y15...y8) + 28(x15...x8) (y7...y0) + 28(x7...x0) (y15...y8) +
+ (x7...x0)*(y7...y0) .
Таким образом, произведение раскладывается на простые 8-разрядные сомножители. Эти произведения 8-разрядных операндов вычисляются табличным методом, а затем следует сдвиг слагаемых сразу на 16,8,8,0 разрядов и суммирование.
Модифицированные коды
Эти коды отличаются от прямого, обратного и дополнительного кодов тем, что на изображение знака отводится два разряда: если число положительное – 00, если число отрицательное – 11. Такие коды оказались удобны (с точки зрения построения АЛУ) для выявления переполнения разрядной сетки. Если знаковые разряды результата принимают значение 00 и 11, то переполнения разрядной сетки не было, а если 01 или 10 – то было переполнение. Вернемся к примерам в п. 2.6.5.

В предыдущих разделах рассмотрены основные принципы выполнения арифметических операций, из которых видно, что все арифметические операции с двоичными числами могут быть сведены к операциям суммирования в прямом или дополнительном кодах, а также операциям сдвига двоичного числа вправо или влево. Реальные алгоритмы выполнения операций умножения и деления в современных ЭВМ достаточно громоздки и здесь не рассматриваются.
Нарушение ограничений ЭВМ
При выполнении арифметических операций возможны ситуации, когда нарушаются ограничения, связанные с конечной длиной разрядной сетки ЭВМ. При этом в ЭВМ формируются признаки соответственно:
для ЧФЗ:
- переполнение, когда результат не вмещается в отведенное количество бит (имеются в виду ЧФЗ справа от МЗР);
для ЧПЗ:
- положительное переполнение порядка, когда PZ>Pmax;
- отрицательное переполнение порядка, когда PZ<Pmin (исчезновение порядка).
Конкретная реакция различных ЭВМ и различных операционных систем на признаки нарушения ограничений в общем случае различна. Однако все они обязательно выполняют следующие операции:
- при обработке программы после выполнения операций, где возможно переполнение, предусматривается анализ соответствующего признака и в зависимости от его значения, реализуется то или иное конкретное действие;
- при возникновении признака в любом месте программы в ЭВМ формируется запрос на прерывание и выполняется программа его обслуживания.
Немного истории
Считается, что первым механизмом для счета являлся абак, в котором сложение и вычитание чисел выполнялось перемещением камешков по желобам доски. Подобные устройства встречаются в разных вариантах в различных странах древнего мира.
Но настоящая потребность в автоматизации вычислений возникла в средние века в связи с резко возросшими в этот период торговыми операциями и океанским судоходством. Торговля требовала больших денежных расчетов, а судоходство – надежных навигационных таблиц.
Первые эскизы счетной машины создал Леонардо да Винчи (около 1500 года). А первые сведения о работающей счетной машине относятся к 1646 году (Германия). Но подробностей устройства этой счетной машины не сохранилось. В 1646 году во Франции Паскаль создал механическое устройство, которое складывало и вычитало многозначные числа. В 1673 году в Германии Лейбниц строит счетную машину, выполняющую все четыре арифметических действия. Он же предложил использовать двоичную систему счисления для нужд вычислительной математики. В этот период были созданы и другие счетные машины. Все они были построены в одном экземпляре (поскольку создавались десятки лет) и не могли долго работать – слишком сложны были их механизмы и слишком примитивна технология их изготовления. Только в 1820 году был налажен серийный выпуск (сотни штук в год) арифмометров конструкции Томаса де Кальмера. Вычисления, состоящие из последовательности арифметических операций, все еще лежали за пределами возможностей счетной машины.
В 1834 году Ч. Бэббидж разработал проект счетной машины, позволяющей реализовать вычисления любой сложности. Машина была задумана как механическая. Но Ч. Бэббиджа можно назвать пророком, поскольку его "аналитическая" машина стала прообразом ЭВМ, появившейся 100 лет спустя. Его машина содержала механический эквивалент практически всех основных устройств простейшей ЭВМ: память ("склад" на 1000 чисел по 50 десятичных знаков), арифметическое устройство ("мельница"), устройство управления, устройства ввода и вывода информации.
Последовательность выполнения операций и пересылки чисел между устройствами задавалась программой на перфокартах Жаккарда (1804), которые использовались для управления работой ткацких станков. Кроме того, в машине Бэббиджа предусматривалась возможность изменения программы в зависимости от результата вычислений. Говоря современным языком, имелись команды условных переходов. Интересно отметить, что Бэббидж изобрел наиболее эффективный способ сложения чисел – сложение по схеме со сквозным переносом. Эту машину Бэббидж строил всю оставшуюся жизнь (до 1871 года), но создал только ее отдельные узлы. В то же время (50-е годы прошлого столетия) благодаря трудам английского математика Ады Лавлейс зародилось машинное программирование. Ада Лавлейс пыталась написать программы к еще не созданной счетной машине Бэббиджа.
В конце XIX –начале XX века начали появляться электромеханические счетно-аналитические машины для выполнения расчетно-бухгалтерских и статистических операций. Сильным толчком к развитию таких устройств стал конкурс, объявленный в США при проведении переписи 1888 года. В нем победил табулятор Холлерита, который явился родоначальником целого семейства электронно-механических машин для обработки статистических данных. В 1898 году Холлерит организовал фирму, которая поставляла такие машины всему миру. Эти машины непрерывно совершенствовались: в 1913 году создан табулятор, печатающий результаты; в 1921 году к нему добавлена коммутационная доска, на которой хранилась программа обработки данных, считываемых с различных позиций перфокарты.
Первые вычислительные машины в современном смысле появились в конце 30-х – начале 40-х годов. В 1936 -1937 году К. Цузе (Германия) спроектировал машину с программным управлением. В 1941 году она была создана (машина на электромагнитных реле). Это первая в мире ЭВМ с программным управлением. Программа наносилась на перфоленту и целиком вводилась в машину. После этого оператор уже не мог влиять на последовательность выполнения команд программы.
Поскольку перфолента двигалась в одну сторону, все циклы записывались в развернутом виде, т.е. в виде последовательности групп команд.
В 1937 году Г. Айкин (США) разработал проект электромеханической универсальной ЭВМ с программным управлением. Она была построена в 1944 году фирмой IBM и названа "Марк-1". В 1947 году под руководством Айкина построена более мощная машина "Марк-2". В ней для хранения чисел и выполнения операций использовано 16000 электромеханических реле. В этот период был разработан целый ряд подобных релейных вычислительных машин, одна из которых практически полностью повторяла "аналитическую" машину Бебиджа.
Эти релейные вычислительные машины были ненадежны, медленно работали и потребляли много энергии, но позволили накопить большой опыт по созданию машин для автоматизированных вычислений. На них было опробовано двоичное кодирование чисел, представление чисел в форме с плавающей запятой, способы выполнения операций над числами на основе релейных схем и т.д.
В этот же период начали появляться машины, построенные на электронных лампах, причем первоначально лампы стали использоваться в простейших счетчиках импульсов. На них строились схемы с двумя устойчивыми состояниями, впоследствии названные триггерами (впервые подобная схема была разработана в 1918 году Бонч-Бруевичем). Исследуя свойства триггеров, американские ученые
Дж. Моучли и Д. Эккер пришли к выводу о целесообразности использования в вычислительных машинах вместо электромеханических реле ламповых триггеров. В 1946 году под их руководством построена вычислительная машина "ЭНИАК" для баллистических расчетов. Она содержала 18000 электронных ламп и 1500 реле. Использование электронных ламп позволило резко (на два порядка) повысить скорость выполнения операций.
Анализируя работу этой машины, математик Дж. Нейман сформулировал основные концепции организации ЭВМ. В соответствии с этими концепциями началась разработка ЭВМ "ЭДВАК" – прообраза современных ЭВМ.Она была построена в 1950 году. А в 1949 году в Англии была введена в эксплуатацию первая в мире ЭВМ с хранимой в памяти программой – "ЭДСАК", созданная под руководством М. Уилкса.
Вычислительные машины "ЭДВАК" и "ЭДСАК" положили начало первому поколению ЭВМ – поколению ламповых машин. С начала 50-х годов было осуществлено много проектов ЭВМ, в каждом из которых применялись новые типы устройств, способы управления вычислительным процессом и обработки информации. Особое внимание уделялось улучшению характеристик памяти, поскольку в ламповых ЭВМ она была незначительной. Так, в 1952 г. впервые были использованы ферритовые сердечники.
На этом закончим рассмотрение истории развития вычислительных машин и перейдем к принципам действия ЭВМ.
Обратный код
В обратном коде (ОК), так же как и в прямом коде, для обозначения знака положительного числа используется бит, равный нулю, и знака отрицательного – единица. Обратный код отрицательного двоичного числа формируется дополнением модуля исходного числа нулями до самого старшего разряда модуля, а затем поразрядной заменой всех нулей числа на единицу и всех единиц на нули. В знаковом разряде обратного кода у положительных чисел будет 0, а у отрицательных – 1.
На рис. 2.2 приведен формат однобайтового двоичного числа в обратном коде.

В общем случае ОК является дополнением модуля исходного числа до наибольшего числа без знака, помещенного в разрядную сетку.
Алгоритм формирования ОК очень прост, при этом ОК позволяет унифицировать операции сложения и вычитания в АЛУ, которые в прямом коде выполняются по-разному. Однако работа с ОК вызывает ряд трудностей. В частности, возникают два нуля: +0 и -0, т.е. в прямом коде (в котором представлены положительные числа) имеет место (+0) = 000...0, а в обратном коде (в котором представлены отрицательные числа): (-0) = 111...1.
Кроме того, в операциях сложения и вычитания требуется дополнительная операция по прибавлению бита переноса в младший разряд суммы. Рассмотрим правила алгебраического сложения в ОК (поскольку А-В=А+(-В)). Алгоритм сложения в ОК содержит:
сложение кодов, включая знаковый разряд;
прибавление переноса к МЗР (младшему значащему разряду) суммы.
Пример.
Вычислить выражение -3(10)
-2(10).

Пример.
Вычислить 7(10)-3(10).

Указанные трудности привели к тому, что в современных ЭВМ абсолютное большинство операций выполняется в дополнительном коде.
Общие вопросы истории развития и построения ЭВМ
С момента своего возникновения человек старался облегчить свой труд с помощью различных приспособлений. В начале это касалось только физического труда, а затем также и умственного. В результате уже в XVII веке начали появляться первые механические устройства, позволяющие выполнять некоторые арифметические действия над числами. Они предназначались, в основном, для коммерческих расчетов и составления навигационных таблиц.
Совершенствование технологии обработки металлов, а затем и появление первых электромеханических устройств типа электромагнитных реле привело к интенсивному совершенствованию вычислительных устройств. Кроме того, совершенствование вычислительных устройств было обусловлено все возрастающим объемом информации, требующей переработки.
До 30-х годов прошлого столетия разработкой вычислительных устройств занимались механики, математики, электрики. Но с конца 30-х годов к этому процессу подключились электронщики, поскольку вычислительные устройства стали создавать на электронных элементах – электронных лампах. Вычислительные устройства превратились в электронные вычислительные машины (ЭВМ0, а все, что связано было с созданием ЭВМ, превратилось в отдельную область человеческих знаний, которую условно можно было назвать "Теория и принципы проектирования ЭВМ".
Однако уже в 50-е годы разнообразие проблем теории и методов проектирования объектов вычислительной техники, сложность ее элементов, устройств, машин и систем закономерно привели к тому, что из дисциплины "Теория и принципы проектирования ЭВМ", еще недавно охватывающей все основные аспекты этой области науки и техники, выделились самостоятельные курсы: схемотехника ЭВМ, методы оптимизации, периферийные устройства, операционные системы, теория программирования и т.д. Современная ЭВМ – настолько сложное устройство, что в одном курсе физически невозможно охватить подробно все проблемы проектирования, создания и эксплуатации ЭВМ, которые в общем случае имеют три аспекта:
- пользовательский (т.е. ЭВМ является инструментом решения прикладных задач);
- программный (т.е. ЭВМ является объектом системного программирования);
- электронный (т.е. ЭВМ является сложным электронным устройством, созданным с использованием сложных технологий).
Настоящий курс "Организация ЭВМ и систем" без излишней детализации рассматривает комплекс основных вопросов, относящихся к теории, принципам построения и функционирования ЭВМ как сложного электронного устройства. При этом основное внимание уделяется микроЭВМ и устройствам на базе микропроцессорных комплектов. Следует иметь в виду также, что под ЭВМ понимается любое устройство переработки цифровой информации (от микроконтроллера, управляющего стиральной машиной, до суперЭВМ), а не только персональный компьютер.
Операционные устройства (АЛУ)
В разделе "Представление информации в ЭВМ" было показано, что различные арифметические операции над числами (представленными, кроме, того в различной кодировке) требуют существенно различных последовательностей микроопераций. Кроме того, очевидно, что чем многофункциональнее электронное устройство, тем сложнее его структура (больше элементов) и тем медленнее оно работает. С другой стороны, функции такого сложного устройства может выполнить набор более простых и быстродействующих устройств, однако аппаратурные затраты и цена будут выше.
В общем случае операции, выполняемые в АЛУ, можно разделить на следующие группы:
- операции двоичной арифметики для ЧФЗ;
- операции двоичной (шестнадцатеричной) арифметики для ЧПЗ;
- операции десятичной арифметики;
- логические операции;
- операции индексной арифметики (при модификации адресов команд);
- операции специальной арифметики:нормализация чисел, арифметический сдвиг (сдвигаются только цифровые разряды без знакового), логический сдвиг (сдвигаются все разряды) и т.д..
ЭВМ общего назначения обычно реализуют операции приведенных выше групп, но делают это по-разному, в зависимости от типа АЛУ, используемого в процессоре.
АЛУ подразделяется на блочные и многофункциональные.
В блочных АЛУ (рис. 3.3) перечисленные группы операций выполняются в отдельных электронных блоках, при этом повышается скорость работы, так как блоки могут параллельно выполнять соответствующие операции. Кроме того, специализированный блок всегда выполняет операции быстрее, чем универсальный перенастраиваемый блок.

Блочные АЛУ характерны для больших ЭВМ, где главным является максимальное быстродействие, а не аппаратные затраты и стоимость. Простейшие сопроцессоры в микроЭВМ, выполняющие операции с ЧПЗ, также можно рассматривать как специализированные блоки, поэтому АЛУ микроЭВМ с сопроцессорами можно иногда рассматривать как блочные.
В многофункциональных АЛУ перечисленные группы операций выполняются одними и теми же схемами, которые коммутируются нужным образом в зависимости от требуемого режима работы. Такие АЛУ характерны для мини- и микроЭВМ, построенных на простых процессорах.
Существуют и другие структуры АЛУ (смешанные), находящиеся где-то между блочными и многофункциональными.
Следует иметь в виду, что часто ЭВМ, построенные на базе простейших микропроцессоров, имеют АЛУ, позволяющие выполнять только операции двоичной арифметики над ЧФЗ и некоторые логические операции. В этом случае остальные группы операций выполняются специальными подпрограммами, что сильно понижает скорость их выполнения.
Рассмотрим несколько подробнее структуру АЛУ простейшего процессора и определим минимально необходимый набор входящих в него устройств. Из изложенного выше следует, что в состав такого АЛУ должно входить устройство, выполняющее операции двоичного суммирования (сумматор). Кроме того, для хранения операндов и результата необходимо иметь, по крайней мере, три буферных регистра (регистры временного хранения). Однако в простейшем случае результат операции можно записывать в один из регистров временного хранения на место одного из операндов. Этот регистр принято называть аккумулятором, а процессор в целом – процессором аккумуляторного типа. Аккумулятор должен обязательно иметь двунаправленную связь с внутренней шиной данных процессора. (В более сложных АЛУ результат операции может быть записан по желанию программиста в любой из специально выделенных для этой цели регистр). Для выполнения арифметико-логических операций необходимо устройство, выполняющее сдвиги двоичных чисел (сдвигатель). И, наконец, необходим регистр, в котором хранятся некоторые признаки результата выполненной операции, необходимые для функционирования УУ (регистр признаков).
Структурная схема АЛУ простейшего микропроцессора аккумуляторного типа изображена на рис. 3.4.

Поколения ЭВМ
Выше рассматривались три понятия: аппаратные средства, программное обеспечение и архитектура ЭВМ. Рассмотрим коротко этапы развития ЭВМ за последние 50 лет с точки зрения этих понятий, составляющих основу классификации ЭВМ по поколениям.
Ранее отмечалось, что ближайшими прототипами современной ЭВМ можно считать машины "ЭДВАК" и "ЭДСАК", построенные в Англии и США в 1949-1950 годах. С начала 50-х годов началось массовое производство ЭВМ различных типов, которые сейчас принято относить к ЭВМ первого поколения. Следует иметь в виду, что поколения ЭВМ не имеют четких временных границ. Элементы каждого нового поколения ЭВМ разрабатывались и опробовались на ЭВМ предыдущего поколения.
Первое поколение (1950-1960 гг.)
ЭВМ этого поколения строилось на дискретных элементах и вакуумных лампах, имели большие габариты, массу, мощность, обладая при этом малой надежностью. Основная технология сборки – навесной монтаж. Они использовались в основном для решения научно-технических задач атомной промышленности, реактивной авиации и ракетостроения.
Увеличению количества решаемых задач препятствовали низкая надежность и производительность, а также чрезвычайно трудоемкий процесс подготовки, ввода и отладки программы, написанной на языке машинных команд, т.е. в форме двоичных кодов. Машины этого поколения имели быстродействие порядка 10-20 тысяч операций в секунду и ОП порядка 1К (1024 слова). В этот же период появились первые простые языки для автоматизированного программирования.
Второе поколение (1960-1965 гг.)
В качестве элементной базы использовались дискретные полупроводниковые приборы и миниатюрные дискретные детали. Основная технология сборки – одно- и двухсторонний печатный монтаж невысокой плотности. По сравнению с предыдущим поколением резко уменьшились габариты и энергозатраты, возросла надежность. Возросли также быстродействие (приблизительно 500 тысяч оп/с) и объем оперативной памяти (16-32К слов). Это сразу расширило круг пользователей, а следовательно, и решаемых задач.
Появились языки высокого уровня (Фортран, Алгол, Кобол) и соответствующие им трансляторы. Были разработаны служебные программы для автоматизации профилактики и контроля работы ЭВМ, а также для лучшего распределения ресурсов при решении пользовательских задач. (Задача экономии времени процессора и ОП осталась, как и в первом поколении).
Все эти вышеперечисленные служебные программы оформились в ОС, которая первоначально просто автоматизировала работу оператора: ввод текста программы, вызов нужного транслятора, вызов необходимых библиотечных программ, размещение программ в основной памяти и т.д. Теперь вместе с программами и исходными данными вводилась целая инструкция о последовательности обработки программы и требуемых ресурсах.
Совершенствование аппаратного обеспечения, построенного на полупроводниковой базе, привело к тому, что появилась возможность строить в ЭВМ помимо центрального (основного) процессора еще ряд вспомогательных. Эти процессоры управляли всей периферией, в частности устройствами ввода/вывода, избавляли от вспомогательной работы центральный процессор. Одновременно совершенствовались и ОС. Это позволило на ЭВМ второго поколения реализовать режим пакетной обработки программ, а также режим разделенного времени. Последний был необходим для параллельного решения нескольких задач управления производством и организации многопользовательского режима через дисплейные станции. В машинах второго поколения широко использовались ОП на ферритовых кольцах (так называемые кубы памяти). Все это позволило поднять производительность ЭВМ и привлечь к ней массу новых пользователей.
Третье поколение (1965-1970 гг.)
В качестве элементной базы использовались интегральные схемы малой интеграции с десятками активных элементов на кристалл, а также гибридные микросхемы из дискретных элементов. Основная технология сборки – двухсторонний печатный монтаж высокой плотности. Это сократило габариты и мощность, повысило быстродействие, снизило стоимость универсальных (больших) ЭВМ.
Но самое главное – появилась возможность создания малогабаритных, надежных, дешевых машин – миниЭВМ. МиниЭВМ первоначально предназначались для замены аппаратно-реализуемых контроллеров в контурах управления различных объектов и процессов (в том числе и ЭВМ),. Появление миниЭВМ сократило сроки разработки контроллеров, поскольку вместо разработки сложных логических схем требовалось купить миниЭВМ и запрограммировать ее надлежащим образом. Универсальное устройство обладало избыточностью, однако малая цена и универсальность периферии оказались большим плюсом, обеспечившим высокую экономическую эффективность.
Но вскоре потребители обнаружили, что после небольшой доработки на миниЭВМ можно решать и вычислительные задачи. Простота обслуживания новых машин и их низкая стоимость позволили снабдить подобными вычислительными машинами небольшие коллективы исследователей, разработчиков, учебные заведения и т.д. В начале 70-х гг. с термином миниЭВМ уже связывали два существенно различных типа вычислительной техники:
- контроллер – универсальный блок обработки данных и выдачи управляющих сигналов, серийно выпускаемый для использования в различных специализированных системах контроля и управления;
- универсальная ЭВМ небольших габаритов, проблемно-ориентированная пользователем на ограниченный круг задач в рамках одной лаборатории, технологического участка и т.д.
Четвертое поколение (с 1970 г.)
Успехи микроэлектроники позволили создать БИС и СБИС, содержащие десятки тысяч активных элементов. Одновременно уменьшались и габариты дискретных электронных компонентов. Основной технологией сборки стал многослойный печатный монтаж. Это позволило разработать более дешевые ЭВМ с большой ОП. Стоимость одного байта памяти и одной машинной операции резко снизилась. Но затраты на программирование почти не сократились, поэтому на первый план вышла задача экономии человеческих, а не машинных ресурсов.
Для этого разрабатывались новые ОС, позволяющие пользователю вести диалог с ЭВМ, что облегчало работу пользователя и ускоряло разработку программ.
Это потребовало, в свою очередь, совершенствовать организацию одновременного доступа к ЭВМ целого ряда пользователей, работающих с терминалов.
Совершенствование БИС и СБИС привело в начале 70-х гг. к появлению новых типов микросхем – микропроцессоров (в 1968 г. фирма Intel по заказу Дейта-Дженерал разработала и изготовила первые БИС микропроцессоров, которые предполагалось использовать как составные части больших процессоров).
В те годы под микропроцессором понималась БИС, в которой полностью размещен процессор простой архитектуры, т.е. АЛУ и УУ. В результате были созданы дешевые микрокалькуляторы и микроконтроллеры
– управляющие устройства, построенные на одной или нескольких БИС, содержащие процессор, память и устройства сопряжения с датчиками и исполнительными механизмами. С совершенствованием технологии их производства и, следовательно, падением цен микроконтроллеры начали внедряться даже в бытовые приборы и автомашины.
В 70-е же годы появились первые микроЭВМ – универсальные вычислительные системы, состоящие из процессора, памяти, схем сопряжения с устройствами ввода/вывода и тактового генератора, размещенные в одной БИС (однокристальная
микроЭВМ) или в нескольких БИС, установленных на одной печатной плате (одноплатные
микроЭВМ).
Совершенствование технологии позволило изготовить СБИС, содержащие сотни тысяч активных элементов, и сделать их достаточно дешевыми. Это привело к созданию небольшого настольного прибора, в котором размещалась микроЭВМ, клавиатура, монитор, магнитный накопитель (кассетный или дисковый), а также схемы сопряжения с малогабаритным печатающим устройством, измерительной аппаратурой, другими ЭВМ и т.д. Этот прибор получил название персональный компьютер.
В 1976 г. была зарегистрирована компания Apple Comp (Стив Джекоб и Стефан Возняк), которая и начала серийный выпуск первых в мире персональных компьютеров "Макинтош".
Благодаря ОС, обеспечивающей простоту общения с этой ЭВМ больших библиотек прикладных программ, а также низкой стоимости персональный компьютер начал стремительно внедряться в различные сферы человеческой деятельности во всем мире.
Об областях и целях его использования можно прочитать в многочисленных литературных источниках. По данным на 1985 год, общий объем мирового производства уже составил 200×106
микропроцессоров и 10×106
персональных компьютеров в год.
Что касается больших ЭВМ этого поколения, то происходит дальнейшее упрощение контакта человек-машина. Использование в больших ЭВМ микропроцессоров и СБИС позволило резко увеличить объем памяти и реализовать некоторые функции программ ОС аппаратными методами, например аппаратные реализации трансляторов с языков высокого уровня и т.п. Это сильно увеличило производительность ЭВМ, хотя несколько возросла и цена.
Характерным для крупных ЭВМ 4-го поколения является наличие нескольких процессоров, ориентированных на выполнение определенных операций, процедур или решение определенных классов задач. В рамках этого поколения создаются многопроцессорные вычислительные системы с быстродействием в несколько десятков или сотен миллионов операций/с и многопроцессорные управляющие комплексы повышенной надежности с автоматическим изменением структуры.
Примером вычислительной системы 4-го поколения является многопроцессорный комплекс "Эльбрус-2" с суммарным быстродействием 100×106 оп/с или вычислительная система ПС-2000, содержащая до 64 процессоров, управляемых общим потоком команд. При распараллеливании вычислительного процесса суммарная скорость достигает 200×106
оп/с. Подобные суперЭВМ развивают максимальную производительность только при решении определенных типов задач (под которые они и строились). Это, прежде всего, задачи сплошных сред, связанные с аэродинамическими расчетами, прогнозами погоды, силовыми энергетическими полями и т.д. Производство суперЭВМ во всем мире составляет в настоящее время десятки штук в год, и строятся они, как правило, "под заказ".
Пятое поколение
Характерной особенностью пятого поколения ЭВМ является то, что основные концепции этого поколения были заранее формулированы в явном виде.
Задача разработки принципиально новых компьютеров впервые поставлена в 1979 году японскими специалистами, объединившими свои усилия под эгидой научно-исследовательского центра по обработке информации – JIPDEC. В 1981 г. JIPDEC опубликовал предварительный отчет, содержащий детальный многостадийный план развертывания научно-исследовательских и опытно-конструкторских работ с целью создания к 1991 г. прототипа ЭВМ нового поколения.
Указанная программа произвела довольно сильное впечатление сначала в Великобритании, а затем и в США. Под эгидой JIPDEC прошли ряд международных конференций, в частности – "Международная конференция по компьютерным системам пятого поколения" (1981 г.), на которых полностью оформился "образ компьютера пятого поколения". Были предложены концепции создания не только поколения ЭВМ в целом, но и вопросы архитектуры основных типов ЭВМ этого поколения, структуры программных средств и языков программирования, разработки наиболее перспективной элементной базы и способов хранения информации.
Следует отметить, однако, что оптимистические прогнозы японских специалистов не сбылись. До сих пор не создан компьютер, в полной мере удовлетворяющий требованиям, предъявляемым к компьютерам пятого поколения.
Прежде чем перейти к изучению дальнейшего материала, следует сделать некоторые замечания. Дело в том, что, несмотря на общие принципы функционирования всех ЭВМ, их конкретные реализации существенно различаются. Особенно это касается суперЭВМ, решающих весьма специфические задачи. Да и обычные серийные большие ЭВМ общего назначения работают, как правило, в составе вычислительных центров, и доступ к ним возможен только через терминалы. Кроме того, их архитектура, аппаратное и программное обеспечение достаточно сложны для первоначального изучения, поэтому в дальнейшем основное внимание будет уделено небольшим ЭВМ, построенным на базе микропроцессоров, в том числе персональным компьютерам. Это имеет смысл еще и потому, что ЭВМ, построенные на базе микропроцессорных комплектов, представляют наибольший интерес для современного инженера, поскольку непосредственно участвуют в работе систем автоматизации производственных процессов, обрабатывают данные научных экспериментов, принимают и обрабатывают потоки информации в каналах связи, решают небольшие расчетные инженерные задачи и т.д.В ряде случаев для решения конкретных задач пользователь сам на базе микропроцессорных комплектов создает специализированные контроллеры и ЭВМ.
Рассмотрим очень коротко основное отличие структур больших ЭВМ общего назначения и малых ЭВМ (миниЭВМ), появившихся в начале 70-х годов.
Понятие о системе программного (математического) обеспечения ЭВМ
Каждая ЭВМ обладает определенными свойствами, такими как возможность обрабатывать информацию в той или иной форме, возможность выполнять арифметические и логические операции, операции, связанные с организацией совместной работы устройств машины и т.д.
Для придания определенных свойств ЭВМ используют средства двух видов – аппаратные и программные (hard & soft). Последние называются также средствами программного обеспечения.
Часть свойств ЭВМ приобретает благодаря наличию в ней электронного и электромеханического оборудования, специально предназначенного для реализации этих свойств. Примером такого устройства является АЛУ.
Ряд других свойств реализуется без специальных электронных блоков с помощью программных средств. При этом используются имеющиеся аппаратные средства ЭВМ, выполняющие действия, предписанные специальными программами.
Так, например, ЭВМ может не иметь аппаратно реализованной операции извлечения корня. Но если есть программа извлечения корня, то существующие аппаратные средства могут выполнить эту операцию. Причем, с точки зрения пользователя, ЭВМ приобретет свойство вычисления корня.
Следует иметь в виду, что с помощью аппаратных средств соответствующие функции ЭВМ выполняются значительно быстрее, чем программным путем, но при этом ЭВМ становится сложнее и дороже. Всвязи с этим в ЭВМ с достаточно простыми процессорами стремятся как можно больше функций реализовать программным путем, а в мощных ЭВМ для повышения быстродействия – по максимуму использовать аппаратные средства.
Вообще же стремятся как можно оптимальнее соотнести аппаратные и программные средства, чтобы при умеренных аппаратных затратах и стоимости достигнуть высокой эффективности и быстродействия.
Таким образом, аппаратные и программные средства являются тесно связанными компонентами современной ЭВМ. Поскольку с точки зрения пользователя, как правило, неважно аппаратно или программно выполнены те или иные функции, можно говорить о виртуальной (кажущейся) ЭВМ.
Система программного (математического) обеспечения – это комплекс программных средств, в котором можно выделить операционную систему, комплект программ технического обслуживания и пакеты прикладных программ.
На рис. 1. 2 изображена упрощенная структура вычислительной системы как совокупности аппаратных и программных средств.
Операционная система (ОС) – это центральная и важнейшая часть программного обеспечения ЭВМ, предназначенная для эффективного управления вычислительным процессом, планирования работы и распределения ресурсов ЭВМ, автоматизации процесса подготовки программ и организации их выполнения при различных режимах работы машины, облегчения общения оператора и пользователя с машиной.

ОС состоит из программ, относящихся к двум большим группам.
Управляющие программы осуществляют управление работой устройств ЭВМ, т.е. координируют работу устройств в процессе ввода, подготовки и выполнения других программ.
Обрабатывающие программы осуществляют работу по подготовке новых программ для ЭВМ и исходных данных для них, например, сборку отдельно транслируемых модулей в одну или несколько исполняемых программ, работы с библиотеками программ, перезаписи массивов информации между ВП и ОП и т.д.
ОС в большинстве случаев являются универсальными и не учитывают особенности конкретных аппаратных средств. В современных ЭВМ для адаптации универсальной ОС к конкретным аппаратным средствам используют аппаратно-ориентированную часть операционной системы, которая в персональных компьютерах называется BIOS (Basic Input / Output System – базовая система ввода/вывода).
Следует иметь в виду, что оператор и пользователь не имеют прямого доступа к аппаратным средствам ЭВМ. (В частном случае, например при работе с персональным компьютером, оператор и пользователь являются одним и тем же лицом.) Все связи осуществляются только через ОС, обеспечивающую определенный уровень общения человека и машины. А уровень общения определяется в первую очередь уровнем языка, на котором оно происходит. На схеме представлена приближенная иерархия таких языков.
Проблемно-ориентированный – это язык, строго ориентированный на какую-либо проблему (моделирование сложных технических и экономических систем, САПР самых различных направлений, задачи анимации и т.д.).
Процедурно-ориентированный – это язык, ориентированный на выполнение общих процедур переработки данных (Фортран, Паскаль, Бейсик и т.д.).
Машинный язык – это самый нижний уровень языка. Команды записываются в виде двоичных кодов. Адреса ячеек памяти – абсолютные. Программирование очень трудоемко.
Ассемблер – это язык более высокого уровня, использующий мнемокоды (т.е. команды обозначаются буквенными сочетаниями). Запись программы ведется с использованием символических адресов, т.е. вместо численных значений адреса используются имена, за исключением первого оператора программы, который жестко привязан к физическому адресу. (Вообще, более правильно говорить язык ассемблера, поскольку Ассемблер –служебная программа, преобразующая символические имена команд и символические адреса в команды в машинном коде и числовые адреса.)
Макроязык – в первом приближении его можно определить как язык процедур, написанных на языке ассемблера, т.е. когда вместо целого комплекса команд (которые часто встречаются) используется только имя (название) этого комплекса.
Язык ОС – это язык, на котором оператор может выдавать директивы ОС, вмешиваться в ход вычислительного процесса.
Пакет программно-технического обслуживания
предназначен для уменьшения трудоемкости эксплуатации ЭВМ. Эти программы проводят тестирование работоспособности ЭВМ и ее отдельных устройств, определяют места неисправностей.
Пакеты прикладных программ представляют собой комплексы программ для решения определенных, достаточно широких классов задач (научно-технических, планово-экономических), а также для расширения функций ОС (управление базами данных, реализация режимов телеобработки данных, реального времени и др.).
Все это, как уже отмечалось, в совокупности с аппаратными средствами составляет вычислительную систему. Причем при создании новых ЭВМ разработка аппаратного и программного обеспечения производится одновременно. В настоящее время программное обеспечение – такой же вид промышленной продукции, как и сама ЭВМ, причем его стоимость зачастую дороже аппаратной части.
Сложность современных вычислительных систем (ВС) привела к возникновению понятия архитектуры ВС. Это понятие охватывает комплекс общих вопросов построения ВС, существенных в первую очередь для пользователя, интересующегося главным образом возможностями ЭВМ, а не деталями ее технического исполнения. К числу таких вопросов относятся вопросы общей структуры, организации вычислительного процесса и общения пользователя с машиной, вопросы логической организации представления, хранения и преобразования информации и вопросы логической организации совместной работы различных устройств, а также аппаратных и программных средств машины.
Позиционные системы счисления
Под системой счисления понимают способ представления любого числа с помощью некоторого алфавита символов, называемых цифрами. Существуют различные системы счисления. От их особенностей зависят наглядность представления числа при помощи цифр и сложность выполнения арифметических операций.
В ЭВМ используются только позиционные системы счисления с различными основаниями. Позиционные системы счисления характеризуются тем, что одна и та же цифра имеет различное значение, определяющееся позицией цифры в последовательности цифр, изображающих число.
Пример.:
Десятичная система счисления – позиционная,
Римская система счисления – непозиционная.
Количество S различных цифр, употребляющихся в позиционной системе счисления, называется ее основанием. В общем случае, любое число в позиционной системе счисления можно представить в виде полинома от основания S:

В качестве коэффициента e могут стоять любые из S цифр, используемых в системе счисления. Однако для краткости число принято изображать в виде последовательности цифр.

Позиции цифры, отсчитанные от запятой (точки), отделяющей целую часть от дробной, называются разрядами. В позиционной системе счисления вес каждого разряда больше соседнего в число раз, равное основанию системы S.
Пример.
Для десятичной системы счисления (основание S = 10) имеем число 6321.564. Веса разряда и коэффициенты e для этого числа будут следующими:
| Веса | 103 | 102 | 101 | 100 | 10-1 | 10-2 | 10-3 | ||||||||
| 6 | 3 | 2 | 1 | 5 | 6 | 4 |
В ЭВМ применяют двоичную, восьмеричную и шестнадцатеричную системы счисления. В дальнейшем систему счисления, в которой записано число, будем обозначать подстрочным индексом, заключенным в круглые скобки. Например: 1101(2), 369(10), BF(16) и т.д.
Правило перевода из дополнительного кода в десятичную систему
Перевод чисел из дополнительного кода в десятичную систему можно проводить по схеме, приведенной на рис. 2.5.
Однако существует прямой способ перевода числа из ДК в десятичную систему без использования промежуточного перевода в ПК.

Рассмотрим машинное слово произвольной длины (рис. 2.6). При прямом способе перевода десятичное число со знаком формируется как сумма разрядов со своими весами и знаками (старший N-й разряд имеет отрицательный вес).

Проиллюстрируем перевод чисел из ДК в десятичную систему примерами.
Пример.
Перевести число 1110 из ДК в десятичную систему.

Проверим правильность перевода, используя промежуточный перевод в ПК:

Пример.
Перевести число 101100 из ДК в десятичную систему.
101100(2)
(ДК) = -25+23+22 = -32+8+4 = -20(10)
Проверим:

Представление буквенно-цифровой информации
По своей природе компьютеры могут работать лишь с числами. И для того чтобы они могли хранить в памяти и обрабатывать буквы или другие символы, каждому из них должно быть поставлено в соответствие некоторое число, т.е. использована та или иная система кодировки символов.
До недавнего времени было принято представлять один символ буквенно-цифровой информации в виде одного байта. С помощью одного байта в общем случае можно закодировать 28=256 символов. Исторически сложилось так, что различные производители стали использовать для представления символов внутри ЭВМ различные коды. В мире имели хождение десятки схем подобного кодирования символов. Но ни одна из этих схем не была столь универсальной, чтобы описать все необходимые символы. По большому счёту, даже для отдельного языка, например, английского, не существовало единой системы кодирования, включавшей в себя все обычно используемые буквы, знаки пунктуации, технические и математические символы.
Среди однобайтовых систем кодировок наибольшее распространение в мире получил Стандартный американский код обмена информацией ASCII, имеющий несколько модификаций. В базовом варианте кода ASCII для кодирования каждого символа используется 7 бит, т.е. можно закодировать 27=128 символов, например:

Обычно код информации и управляющих символов представлялся в виде двухразрядного шестнадцатеричного числа. Восьмой бит в байте использовался для расширения отображаемого набора символов или для проверки правильности переданной кодовой комбинации, например проверки на четность.
В отечественных ЭВМ также использовались различные коды. Так, в ЕС-ЭВМ использовался двоичный код обработки информации (ДКОИ), 8-разрядный код обмена информацией (КОИ-8). Использовались также 7-разрядный код КОИ-7 и его модификации, причем код КОИ-7 наиболее близок к базовому варианту кода ASCII. Код КОИ-8 за счет использования 8-го бита позволял представлять помимо служебных символов, цифр и латинских букв еще и русские буквы.
Между тем все эти однобайтовые схемы кодирования часто даже не были совместимы друг с другом.
Например, две разные кодировки могли использовать один и тот же код для представления двух разных
символов или присваивать разные коды одной и той же букве. В этой ситуации для любого компьютера, а особенно сервера, приходилось поддерживать несколько разных кодировок, которые могли понадобиться. Но даже и тогда при передаче данных на другую платформу или при их преобразовании в другую кодировку всегда оставался риск, что эти данные окажутся повреждёнными.
Указанные выше недостатки 8-битовых систем кодирования символов привели к появлению 16-битовых систем, в которых для кодирования любого символа используются два байта. В настоящее время международным стандартом стала двухбайтовая система кодирования символов Unicode, разработанная Unicode Consortium. Unicode Consortium является некоммерческой организацией, основанной для разработки и развития стандарта Unicode, определяющего представление символьной информации в современных программных продуктах и стандартах, и для содействия его широкому распространению и использованию.
Система Unicode присваивает уникальный двухбайтовый код любому символу, независимо от платформы, независимо от программы, независимо от языка. Unicode был принят как стандарт такими лидерами компьютерной индустрии, как Apple, HP, IBM, JustSystem, Microsoft, Oracle, SAP, Sun, Sybase, Unisys, и многими другими. Именно эта схема кодирования используется такими современными технологиями и стандартами, как, например, XML, Java, ECMAScript (JavaScript), LDAP, CORBA 3.0, WML и так далее. Именно Unicode является официальной схемой реализации стандарта ISO/IEC 10646, определяющего способы кодировки символов. Эта кодировка поддерживается во множестве операционных систем, во всех современных браузерах Интернет. Повсеместное распространение стандарта Unicode и доступность поддерживающих его средств в настоящее время являются одними из наиболее важных направлений развития индустрии программного обеспечения. Следует отметить, что для сохранения преемственности программного обеспечения Unicode включает в себя как подмножества прежние наиболее распространенные однобайтовые системы кодирования символов.
Использование Unicode в многоуровневых приложениях или программных комплексах, построенных в рамках архитектуры клиент-сервер, а также при представлении данных в сети Интернет, приводит к значительному снижению расходов на поддержку этих продуктов или сервисов по сравнению со случаем использования старых схем кодирования. Unicode позволяет создавать единый программный продукт или Интернет-сайт для множества платформ, языков и стран без каких-либо переделок. Его использование при передаче данных между различными системами предохраняет эти данные от повреждения.
Представление дробных чисел в ЭВМ Числа с фиксированной и плавающей запятой
В ЭВМ числа представлены в двоичной форме и под число отводится N разрядов. N-разрядное двоичное число называют машинным словом. Диапазон представления чисел можно расширить за счет использования машинных слов двойной и большей длины. Но увеличение длины слова не может разрешить всех проблем представления чисел. Рассмотрим, как обращаться с дробной частью числа, как представлять очень большие и очень малые числа.
Используют две формы представления чисел:
числа с плавающей запятой (точкой), которые сокращенно называются ЧПЗ (ЧПТ);
числа с фиксированной запятой (точкой) – ЧФЗ (ЧФТ), которые подразделяются по месту фиксации запятой на:
- слева от СЗР (дробные |X| < 1);
- справа от МЗР (целые).
Преобразование десятичных чисел в двоичные
При работе с ЭВМ, особенно с микропроцессорами, очень часто приходится выполнять преобразование десятичных чисел в двоичные.
Для преобразования целого десятичного числа в двоичное необходимо разделить его на основание новой системы счисления (S = 2). Полученное частное снова делится на основание новой системы счисления, до тех пор пока частное, полученное в результате очередного деления, не будет меньше основания новой системы счисления. Последнее частное (являющееся старшим значащим разрядом) и все полученные остатки от деления составляют число в новой системе счисления.
Проиллюстрируем преобразование на примере.
Пример.
Перевести целое десятичное число 10(10)
в двоичное число.

Если процедуру перевода выполняет человек, то последний шаг получения частного, равного нулю, никогда не делается. Если перевод выполняется ЭВМ, то он необходим. Таким образом, полный вариант преобразования 10(10)
будет иметь следующий вид:

Пример.
Десятичное число 57(10)
преобразовать в двоичное число.

Для перевода дробных чисел (или дробных частей вещественных чисел) требуется другая процедура преобразования. Рассмотрим ее на примере.
Пример.
Десятичное число 0.375(10)
преобразовать в двоичное число.
1. Умножим дробь на основание новой системы счисления S = 2: 2*0.375 = 0.75.
2. Если результат умножения меньше единицы, то СЗР присваивают значение 0. Если больше единицы, то присваивают значение 1. Поскольку 0.75<1, то СЗР=0.
3. Результат предыдущей операции вновь умножаем на основание новой системы счисления 2. Если бы он был больше единицы, то в этой операции умножения участвовала бы только его дробная часть. В данном случае: 2*0.75=1.5.
4. Поскольку 1.5>1, то ближайшему разряду справа от СЗР присваивается значение один, а следующая операция умножения производится только над дробной частью числа 1.5, т.е. над числом 0.5: 2*0.5=1.
5. Шаги описанной процедуры повторяются до тех пор, пока либо результат умножения не будет точно равен 1 (как в рассматриваемом примере), либо не будет достигнута требуемая точность.
Таким образом, 0.375(10) = 0.011(2).
Если в результате умножения на основание новой системы счисления S = 2 результат не равен единице, операцию останавливают при достижении необходимой точности, а целую часть результата последней операции умножения используют в качестве значения МЗР.
Пример.
Десятичное число 0.34375(10)
преобразовать в двоичное число.

Таким образом, 0.34375(10) = 0.01011(2).
Пример.
Десятичное число 0.3(10)
преобразовать в двоичное число.

Далее будут следовать повторяющиеся группы операций и результатов, поэтому ограничимся восемью разрядами, т.е. 0.3(10) = 0.01001100(2).
Из рассмотренных выше примеров видно, что если десятичное число дробное, то его преобразование в двоичное должно выполняться отдельно над его целой и дробной частями.
Следует иметь в виду, что рассмотренные процедуры перевода целых и дробных чисел из десятичных в двоичные и обратно являются общими для перевода чисел в любых позиционных системах счисления (т.е. целое число делится на основание системы счисления, в которую число переводится, а правильная дробь умножается). Притом надо помнить, что при выполнении переводов чисел из одной системы счисления в другую все необходимые арифметические действия выполняются в той системе счисления, в которой записано переводимое число.
Преобразование двоичных чисел в десятичные
Для преобразования двоичных чисел в десятичные необходимо сложить десятичные веса всех разрядов двоичного числа, в которых содержатся единицы.
Пример.
Преобразовать целое двоичное число 11001100(2)
в десятичное.

Преобразование вещественного двоичного числа 101.011(2)
будет выглядеть следующим образом:

Если преобразуемое число большое, то операцию перевода удобнее делать отдельно для целой и дробной частей.
Пример выполнения контрольного задания (форма
| №
варианта | Операнды | Задание 1 (ЧФЗ) | Задание 2 (ЧПЗ) | Задание 3 (2-10) | |||||||||||||||||
| Операции | Операции | Операции | |||||||||||||||||||
| X+Y | X-Y | X*Y | X+Y | X-Y | X*Y | X+Y | X-Y | X*Y | |||||||||||||
| № | X
Y | 18
33 | 18
33 | 18
33 | 18.33
33.18 | 18.33
33.18 | 18.33
33.18 | 183
331 | 183
331 | 183
331 |
Задание 1. Выполнить арифметические действия, рассматривая операнды как ЧФЗ справа от МЗР в формате 1-го байта. Определить модуль результата. Формат результата – 2 байта.
1. Выполним операцию сложения Z = X+Y = 18(10)
+ 33(10) = 51(10).
X = 18(10) = 0001 0010(2); Y = 33(10) = 0010 0001(2).
Выполним сложение в ПК:

Результат: Z = 0011 0011(2) = 51(10)
.
2. Выполним операцию вычитания Z = X-Y = 18(10) – 33(10) = -15(10).


Результат: Z = 1000 1111(2) = 15(10) .
3. Выполним операцию умножения Z = X*Y = 18(10)*33(10)
= 594(10).
X = 18(10) = 0001 0010(2); Y = 33(10) = 0010 0001(2).
Выполним операцию умножения младшими разрядами вперед:

Задание 2. Выполнить арифметические действия, рассматривая операнды как ЧПЗ с основанием 2 в следующем формате: несмещенный порядок – 4 бита, мантисса – 8 бит. Формат результата – тот же. Округление производить после приведения операнда к нормализованной форме. Результат нормализовать.
X = 18.33(10); Y = 33.18(10).
Преобразуем дробную часть Х, равную 0.33(10), в двоичное число:

Таким образом, 0.33(10)
= 0.01010100(2), a X = 18.33(10) = 00010010.01010100(2).
Представим X в формате ЧПЗ, округлив значение мантиссы до 8 разрядов (ненормализованное число):

Нормализуем X:

Преобразуем дробную часть Y, равную 0.18(10), в двоичное число:

Таким образом, 0.18(10) = 0.00101110(2), a Y = 33.18(10) = 00100001.00101110(2).
Представим Y в формате ЧПЗ, округлив значение мантиссы до 8 разрядов (ненормализованное число):

Нормализуем Y:

1. Выполним операцию сложения Z = X+Y = 18.33(10) + 33.18(10) = 51.51(10).

2. Выполним операцию вычитания Z = X-Y = 18.33(10)
+ 33.18(10) = -14.85(10).





Результат: Z = (-) 0110 * 0.00111100(2) = - 26 * 0.234375 = - 15(10)
3). Выполним операцию умножения Z = X*Y = 18.33(10)*33.18(10) = 608.1894(10).


Перемножим мантиссы сомножителей (вариант умножения младшими разрядами вперед):

















Сложим порядки сомножителей:


Нормализуем произведение:

Результат: Z = 1010 * 0.10011000(2) = 210 * 0.59375(10)
= 608(10).
Задание 3.
Выполнить арифметические действия над операндами, представив их в двоично-десятичном коде.
1. Выполним операцию сложения Z=X+Y= 183(10) + 331(10)
= 514(10).
X = 183(10) = 0001 1000 0011(2-10); Y = 331(10) = 0011 0011 0001(2-10).



Результат: Z = 0101 0001 0100(2-10)
= 514(10).
2. Выполним операцию вычитания Z = X – Y = 183(10) – 331(10)
= -148(10).
Представим |Y| в ДК с избытком 6:

Выполним сложение:

Отсутствие переноса из старшей тетрады является признаком того, что результат получился в ДК (т.е. отрицательный).
Перейдем к нескорректированному избыточному ПК:

Произведем коррекцию результата в соответствии с п. 5 алгоритма выполнения операции вычитания двоично-десятичных чисел:

Поскольку ранее результат получался в ДК, т.е. отрицательный, необходимо добавить знак (-).
Результат: Z = - ( 0001 0100 1000)(2-10) = -148(10).
3. Выполним операцию умножения Z = X * Y = 183(10) * 331(10)
= 60573(10)
X = 183(10) = 0001 1000 0011(2-10); Y = 331(10) = 0011 0011 0001(2-10).
Для решения примера выберем вариант перемножения "младшие разряды вперед". В соответствии с п. 1 алгоритма полагаем сумму частичных произведений P0=0. (Частичные произведения будем обозначать Pi).

Формирование второго и третьего частичных произведений – более длительная операция, поскольку вторая и третья анализируемые тетрады содержат 3(10), поэтому каждая операция суммирования требует проверки необходимости коррекции.Вычислим P2 ( P2 = Р3 ), последовательно суммируя слагаемые, образующие P2:

Таким образом, второе (а также и третье) частичное произведение, состоящее из трех слагаемых, имеет вид
P2 = Р3 = 0101 0100 1001(2-10).
Теперь можно вычислить сумму первого, второго и третьего частичного произведений, т.е. результат.

Окончательный результат: Z = 0110 0000 0101 0111 0011(2-10)
= 60573(10).
Принципы действия ЭВМ
Рассмотрим вначале вычисления с помощью калькулятора. Предварительно на листе бумаги выписываются формулы и исходные данные, а часто и таблицы для занесения промежуточных и конечных результатов. В процессе вычисления числа с листа заносятся в регистр микрокалькулятора, а затем включается нужная по формуле операция. Полученные результаты переписываются с регистра (индикатора микрокалькулятора) на лист бумаги (в таблицу).
Таким образом, микрокалькулятор выполняет арифметические операции над числами, которые в него вводит человек. Лист бумаги выполняет в данном случае роль запоминающего устройства, хранящего программу (расчетную формулу), исходные, промежуточные и конечные результаты. Человек управляет процессом вычисления, включая перенос чисел с листа в микрокалькулятор и обратно, а также выбирает нужный вариант продолжения процесса вычисления в соответствии с полученным результатом. Интересно, что в данном случае быстродействие устройства, выполняющего арифметические операции (механического или электронного), практически не влияет на скорость вычислительного процесса, так как остальные операции выполняются очень медленно.
Принципиальный эффект достигается, если к быстродействующему арифметическому устройству добавить быстродействующую память, а также быстродействующее устройство, производящее все необходимые операции по реализации программы вычислений и пересылке чисел между арифметическим устройством и памятью. Если добавить к такому комплексу аппаратуры устройства связи с внешним миром, т.е. устройства ввода исходных данных и программы и вывода результата, то придем к классической пятиблочной структуре Неймана, несколько модифицированный вид которой показан на рис. 1.1 (первоначально устройство ввода и вывода изображалось одним блоком, а память не разделялась на основную и внешнюю).

Рассмотрим основные функции устройств, входящих в состав неймановской модели ЭВМ.
АЛУ – производит арифметические и логические преобразования над поступающими в него машинными словами, т.е.
двоичными кодами определенной длины, представляющими собой числа или другой вид информации.
Память – хранит информацию, передаваемую из других устройств, в том числе поступающую извне через устройство ввода, и выдает во все другие устройства информацию, необходимую для протекания вычислительного процесса. В ЭВМ первых поколений память состояла только из двух существенно отличных по своим характеристикам частей – быстродействующей основной,
или оперативной (внутренней), памяти (ОП) и значительно более медленной внешней
памяти (ВП), способной хранить очень большие объемы информации. Память современных ЭВМ имеет более сложную структуру, поскольку внутренняя память ЭВМ разделилась на ряд иерархических уровней, обладающих различным объемом и быстродействием – ОП, кэш-память, сверхоперативная память, память каналов и т.д. Однако при первоначальном рассмотрении многоуровневость памяти можно не учитывать и считать, что внутренняя память состоит из одной ОП. Внутренняя память состоит из ячеек, каждая из которых служит для хранения одного машинного слова. Номер ячейки называется адресом. В запоминающем устройстве (ЗУ) ЭВМ, реализующем функцию памяти, выполняются операции считывания и записи информации. Причем при считывании информация не разрушается и может считываться любое число раз. При записи прежнее содержимое ячейки стирается.
Непосредственно в вычислительном процессе участвует только ОП. Обмен информацией между ОП и ВП происходит только после окончания отдельных этапов вычислений. Физическая реализация ОП и ВП будет рассмотрена в последующих разделах данного курса.
Устройство управления (УУ) – автоматически, без участия человека, управляет вычислительным процессом, посылая всем другим устройствам сигналы, предписывающие те или иные действия, в частности заставляет ОП пересылать необходимые данные, включать АЛУ на выполнение необходимой операции, перемещать полученный результат в необходимую ячейку ОП. Следует иметь в виду, что в современных ЭВМ АЛУ и УУ всегда объединены в одно устройство, которое называется процессор.
Пульт управления – позволяет оператору вмешиваться в процесс решения задачи, т.е. давать директивы устройству управления.
Устройство ввода – позволяет ввести программу решения задачи и исходные данные в ЭВМ и поместить их в ОП. В зависимости от типа устройства ввода исходные данные для решения задачи вводятся непосредственно с клавиатуры (дисплей, пишущая машинка) либо должны быть предварительно помещены на какой-либо носитель – перфокарты, перфоленты, магнитные карты, магнитные ленты, магнитные и оптические диски и т.д. В системах САПР осуществляется ввод графической информации.
Устройство вывода – служит для вывода из ЭВМ результатов обработки исходной информации. Чаще всего это символьная информация, которая выводится с помощью печатающих устройств (ПчУ) или на экран дисплея. В ряде случаев это графическая информация в виде чертежей и рисунков, которые могут быть выведены с помощью графических дисплеев, графопостроителей, принтеров, и т.д.
Теперь необходимо определить понятия алгоритм и программа. Понятие алгоритма не замыкается только областью вычислительной техники (ВТ). По интуитивному определению:
Алгоритм – это совокупность правил, строго следуя которым можно перейти от исходных данных к конечному результату.
В ВТ под "совокупностью правил" понимается последовательность арифметических и логических операций. (Утверждают, что слово алгоритм произошло от имени Мухаммед аль Хорезми, написавшем в IX веке трактат по арифметике десятичных чисел.)
Программа – это запись алгоритма в форме, воспринимаемой ЭВМ. Любая программа состоит из отдельных команд. Каждая команда предписывает определенное действие и указывает, над какими операндами это действие производится. Программа представляет собой совокупность
команд, записанных в определенной последовательности, обеспечивающих решение задачи на ЭВМ. Для того,чтобы УУ могло воспринять команды, они должны быть закодированы в цифровой форме (во всех современных ЭВМ – это двоичный код).
Автоматическое управление процессом решения задачи достигается на основе принципа программного управления, являющегося основной особенностью ЭВМ. (Без программного управления ЭВМ превратится в обычный быстродействующий арифмометр или калькулятор.).
Другим важнейшим принципом является принцип хранимой в памяти программы. Согласно этому принципу программа, закодированная в цифровом виде, хранится в памяти наравне с числами. Поскольку программа хранится в памяти, одни и те же команды можно извлекать и выполнять необходимое количество раз. Более того, над кодами команд можно выполнять некоторые арифметические операции и тем самым модифицировать адреса обращения к ОП.
Команды программы выполняются в порядке, соответствующем их расположению в последовательных ячейках памяти. Однако команды безусловного
и условного переходов могут изменять этот порядок соответственно безусловно или при выполнении некоторого условия, задаваемого отношениями типа больше, меньше или равно. В большинстве случаев сравниваются результаты выполнения предыдущей операции и некоторое число, указанное в команде условного перехода. Именно команды условного перехода позволяют строить не только линейные, но также ветвящиеся и циклические программы.
Принципы построения элементарного процессора
Ранее, при рассмотрении обобщенной структуры ЭВМ, отмечалось, что основным устройством, непосредственно осуществляющим переработку поступающей в ЭВМ информации, является процессор (в больших ЭВМ – центральный процессор). Естественно, что конкретные типы ЭВМ содержат в своем составе процессоры, построенные по различным схемам, и процессоры больших ЭВМ существенно отличаются от процессоров мини- и микроЭВМ (о суперЭВМ и говорить не приходится). Однако основные принципы построения процессоров, в общем-то, одинаковые, причем наиболее наглядно их можно продемонстрировать на примере простейшего микропроцессора. Это оправдано и с той точки зрения, что инженер-разработчик радиоэлектронной аппаратуры или аппаратов автоматического управления имеет дело не с большими ЭВМ, а с микропроцессорными комплектами и построенными на их базе мини- и микроЭВМ. Ввиду этого рассмотрев общие вопросы построения ЭВМ, более подробно остановимся на обобщенной структуре гипотетического микропроцессора.
Ранее рассматривались действия над числами (сложение, вычитание, умножение), представленными в различной форме. Было подчеркнуто, что все эти действия осуществляются с помощью элементарных
операций, выполняемых в определенной последовательности.
К таким элементарным операциям относятся:
- запись числа в регистр;
- инвертирование содержимого разрядов регистра;
- пересылка содержимого регистров;
- сдвиг содержимого регистра;
- сложение кодов;
- поразрядные логические операции или анализ разрядов;
- операция счета с+1 или с-1 (инкремент или декремент).
Пример.
Операция умножения реализуется с помощью:
- анализа разряда множителя;
- суммирования;
- сдвига.
Все эти действия выполняются в устройстве, называемом процессором, которое состоит из двух устройств – операционного
(ОУ) и управляющего (УУ).
ОУ – выполняет указанные элементарные операции.
УУ – управляет ОУ, задавая необходимую последовательность выполнения этих операций.
Это соответствует принципу В.М. Глушкова, что в любом устройстве обработки цифровой информации можно выделить операционный и управляющий блоки.
В качестве узлов УУ и ОУ включают в себя регистры, счетчики, сумматоры, мультиплексоры, дешифраторы и т.д., т.е. устройства импульсной цифровой техники. Кроме того, нормальное функционирование процессора и всей ЭВМ возможно только при наличии высокостабильных импульсных последовательностей, формируемых, как правило, из одной импульсной последовательности, вырабатываемой кварцевым генератором. Эти тактовые импульсные последовательности синхронизируют работу узлов процессора, а иногда и всей ЭВМ.
Обобщенная структура любого процессора изображена на рис. 3.1.
Каждая элементарная операция, выполняемая в одном из узлов ОУ в течение одного тактового периода, называется микрооперацией.
В определенные тактовые периоды одновременно могут выполняться несколько микроопераций, например: R2
¬ 0, Сч ¬ (Сч) – 1 и т.д. Такая совокупность непротиворечивых микроопераций называется микрокомандой, а набор микрокоманд, предназначенный для решения задачи, называется микропрограммой.
Если в ОУ предусмотрена возможность выполнения n различных микроопераций, то из УУ должно выходить n управляющих цепей S1,...,Sn, каждая из которых соответствует своей микрооперации. В силу того что УУ определяет микропрограмму, т.е. какие и в какой временной последовательности должны выполняться микрооперации, оно получило название микропрограммного автомата. Соответственно ОУ часто называют операционным автоматом.

Формирование управляющих сигналов S1,...,Sn может зависеть как от внешних сигналов КОП (команды ассемблера), так и от состояния узлов ОУ, определяемого известительными сигналами признаков состояния P1,...,Pm, поступающими с выхода ОУ на соответствующие входы УУ.
Как уже отмечалось, ОУ выполняет над исходными данными различные арифметические и логические операции, поэтому ОУ наиболее часто называют арифметико-логическим устройством, или АЛУ.
Деление любого процессора на программный и операционный автоматы достаточно очевидно и не вызывает особых трудностей в понимании. Однако структурные схемы даже простейших реальных процессоров, помимо АЛУ и УУ, содержат еще ряд узлов (регистров, счетчиков, дешифраторов), которые вроде бы не относятся ни к АЛУ, ни к УУ. Для устранения путаницы в дальнейшем материале необходимо сделать ряд замечаний:
1. В абсолютном большинстве случаев устройства обработки цифровой информации имеют многоуровневую структуру, т.е. построены по принципу "матрешки". Это означает, что УУ и ОУ могут сами распадаться на пары УУ' и ОУ', которые, в свою очередь, также могут распадаться на соответствующие УУ и ОУ. Все зависит от степени детализации рассмотрения данного цифрового устройства. Этот принцип многоуровневости справедлив для всех устройств ЭВМ.
Действительно, если рассматривать процессор в целом и делить его на УУ и ОУ, то совершенно безразлично, как выполняются арифметико-логические операции в ОУ – с помощью очень сложных логических схем или с помощью простой логики, работающей под управлением какого-либо вспомогательного УУ. Аналогичные рассуждения справедливы и для УУ.
Так, например, центральный процессор больших ЭВМ общего назначения середины 70-х годов разбивался на 4-5 уровней, на каждом из которых можно выделить свое УУ и ОУ. Современные процессоры имеют еще более сложную структуру.
Более того, эти рассуждения справедливы в целом для ЭВМ, которую можно разложить на ряд виртуальных (кажущихся) машин и с каждой работать на соответствующем уровне. В общем случае современные универсальные ЭВМ имеют шесть уровней:
-

- процедурно-ориентированный язык;
- ассемблерный уровень (язык ассемблера);
- уровень операционной системы (язык операционной системы);
-

- микропрограммный уровень (язык микрокоманд).
Машинные языки двух нижних уровней являются цифровыми, и программы на них состоят из длинных числовых последовательностей, очень неудобных для человека, но понятных машине. Все более высокие уровни содержат слова и аббревиатуру, что более удобно для человека.
2. Из сказанного следует, что только самые простейшие процессоры имеют один уровень и могут быть в чистом виде разложены на УУ и ОУ, состоящие из комбинационных логических схем, способных выполнять элементарные арифметико-логические операции.
3. В настоящее время нет строгого определения АЛУ, что вызывает некоторую путаницу при пользовании различной литературой. АЛУ обычно обозначают так, как показано на рис. 3.2. При этом одни авторы подразумевают под АЛУ только комбинационные логические схемы, способные выполнять операции двоичного суммирования (т.е. фактически двоичный сумматор), другие – целый комплекс схем для выполнения арифметико-логических операций, который сам может быть разложен на УУ и ОУ.

4. Из сказанного следует вывод, что в общем случае понятия микрооперации и микропрограммы относительны и требуют конкретизации уровня рассмотрения процессора, поскольку один такт верхнего уровня может включать в себя несколько тактов нижнего уровня.
5. Для устранения путаницы при изучении основных принципов построения элементарных процессоров будем считать:
- процессор имеет один уровень;
- процессор пользуется одной тактовой последовательностью;
- значок АЛУ (см. рис. 3.2) обозначает комплекс комбинационных схем, способных выполнять двоичное суммирование, сдвиг двоичного числа, простейшие поразрядные логические операции;
- узлы микропроцессора, не относящиеся непосредственно к схеме управления, будем считать вспомогательными узлами АЛУ, или, точнее, узлами, обеспечивающими нормальное функционирование АЛУ.
Признак переполнения разрядной сетки
При алгебраическом суммировании двух чисел, помещающихся в разрядную сетку, может возникнуть переполнение, т.е. образуется сумма, требующая для своего представления на один двоичный разряд больше, чем разрядная сетка слагаемых. Предполагается, что положительные числа представляются в прямом коде, а отрицательные - в дополнительном.
Признаком переполнения является наличие переноса в знаковый разряд суммы при отсутствии переноса из знакового разряда (положительное переполнение) или наличие переноса из знакового разряда суммы при отсутствии переноса в знаковый разряд (отрицательное переполнение).
При положительном переполнении результат операции положительный, а при отрицательном переполнении – отрицательный.
Если и в знаковый, и из знакового разряда суммы есть переносы или этих переносов нет, то переполнение отсутствует.
Рассмотрим простейшие примеры с трехбитовыми словами. Диапазон чисел, которые они представляют, равен от -4 до +3. В рассматриваемых словах 1 бит знака и 2 информационных бита.
1. Алгебраическое суммирование без переноса.

Поскольку перенос в знаковый разряд или из знакового разряда суммы отсутствует, то переполнения нет.
Результат – положительное число в ПК, равное 3.
2. Алгебраическое суммирование с двумя переносами.

Имеются переносы в знаковый разряд и из знакового разряда вычисляемой суммы, поэтому переполнения нет.
Результат – отрицательное число в ДК, равное -4.
3. Алгебраическое суммирование с одним переносом.
(Положительное переполнение).

При суммировании есть перенос в знаковый разряд суммы, а перенос из знакового разряда отсутствует, т.е. имеет место положительное переполнение, и результат операции положительный.
Число 4 нельзя представить в прямом коде. Формальный результат равен -4.
4. Алгебраическое суммирование с одним переносом.
(Отрицательное переполнение).

Число -5 нельзя представить 3-битовой комбинацией. Формальный результат равен +3.
Из рассмотренных ранее примеров видно, что арифметические операции в дополнительном коде выполняются достаточно просто. Необходимо только не упускать из виду то, с какими числами происходит работа в данный момент – без знака или со знаком. Поскольку внешний вид обоих чисел одинаков, возможны ошибки.
Прямой код
Это обычный двоичный код, рассмотренный в разделе двоичной системы счисления. Если двоичное число является положительным, то бит знака равен 0, если двоичное число отрицательное, то бит знака равен 1. Цифровые разряды прямого кода содержат модуль представляемого числа, что обеспечивает наглядность представления чисел в прямом коде (ПК).
Рассмотрим однобайтовое представление двоичного числа. Пусть это будет 28(10). В двоичном формате – 0011100(2) (при однобайтовом формате под величину числа отведено 7 разрядов). Двоичное число со знаком будет выглядеть так, как показано на рис. 2.1.

Сложение в прямом коде чисел, имеющих одинаковые знаки, достаточно просто: числа складываются, и сумме присваивается знак слагаемых. Значительно более сложным является алгебраическое сложение в прямом коде чисел с разными знаками. В этом случае приходится определять большее по модулю число, производить вычитание модулей и присваивать разности знак большего по модулю числа. Такую операцию значительно проще выполнять, используя обратный и дополнительный коды.
Прямой, обратный и дополнительный коды
В целях упрощения выполнения арифметических операций и определения знака результата применяют специальные коды для представления чисел. Операция вычитания (или алгебраического сложения) чисел сводится к арифметическому сложению кодов, облегчается выработка признаков переполнения разрядной сетки. В результате упрощаются устройства, выполняющие арифметические операции.
Для представления чисел со знаком в ЭВМ применяют прямой, обратный и дополнительный коды.
Общая идея построения кодов такова. Код трактуется как число без знака, а диапазон представляемых кодами чисел без знака разбивается на два поддиапазона. Один из них представляет положительные числа, другой – отрицательные. Разбиение выполняется таким образом, чтобы принадлежность к поддиапазону определялась максимально просто.
Наиболее распространенным и удобным является формирование кодов таким образом, чтобы значение старшего разряда указывало на знак представляемых чисел, т.е. использование такого кодирования позволяет говорить о старшем разряде как о знаковом (бит знака) и об остальных как о цифровых разрядах кода.
Шестнадцатеричная система счисления
Эта система счисления имеет основание S = 16. В общем виде шестнадцатеричное число выглядит следующим образом:

где


Шестнадцатеричная система счисления позволяет еще короче записывать многоразрядные двоичные числа и, кроме того, сокращать запись 4-разрядного двоичного числа, т.е. полубайта, поскольку 16=24. Шестнадцатеричная система также применяется в текстах программ для более краткой и удобной записи двоичных чисел.
Для перевода числа из двоичной системы счисления в шестнадцатеричную необходимо разбить это число влево и вправо от точки на тетрады и представить каждую тетраду цифрой в шестнадцатеричной системе счисления.
Пример.
Двоичное число 10101011111101(2)
записать в шестнадцатеричной системе.

Пример.
Двоичное число 11101.01111(2)
записать в шестнадцатеричной системе.

Для перевода числа из шестнадцатеричной системы счисления в двоичную, необходимо, наоборот, каждую цифру этого числа заменить тетрадой.
В заключение следует отметить, что перевод из одной системы счисления в другую произвольных чисел можно осуществлять по общим правилам, описанным в разделе “Двоичная система счисления”. Однако на практике переводы чисел из десятичной системы в рассмотренные системы счисления и обратно осуществляются через двоичную систему счисления.
Кроме того, следует помнить, что шестнадцатеричные и восьмеричные числа – это только способ представления больших двоичных чисел, которыми фактически оперирует процессор. При этом шестнадцатеричная система оказывается предпочтительнее, поскольку в современных ЭВМ процессоры манипулируют словами длиной 4, 8, 16, 32 или 64 бита, т.е. длиной слов, кратной 4. В восьмеричной же системе счисления предпочтительны слова, кратные 3 битам, например слова длиной 12 бит (как в PDP-8 фирмы DEC).
Синхронизация МК
С этой точки зрения МК делятся на однофазные и многофазные. При этом в МК может быть включен дополнительный разряд, определяющий тип синхронизации.
Достоинством однофазных МК (рис. 3.12, а) является простота технической реализации.
Многофазные МК (рис. 3.12, б) позволяют минимизировать число МК в памяти, упрощают выполнение сложных МК и связь между приемником и источником информации. Недостатком является увеличение объема оборудования для формирования многофазных синхросигналов.

Время выполнения некоторых МО бывает существенно меньше рабочего такта процессора (время выполнения одной МК), что позволяет при горизонтальном кодировании в одном такте выполнять не только совместимые, но и ряд несовместимых МО. Для этого рабочий такт процессора делят на подтакты (фазы), в каждом из которых выполняется одно или несколько элементарных действий (МО) по реализации МК.
Сложение
Как и в десятичной системе счисления, сложение двоичных чисел начинается с правых (младших) разрядов. Если результат сложения цифр МЗР обоих слагаемых не помещается в этом же разряде результата, то происходит перенос. Цифра, переносимая в соседний разряд слева, добавляется к его содержимому. Такая операция выполняется над всеми разрядами слагаемых от МЗР до СЗР.
Пример.
Сложить два числа в десятичном и двоичном представлении (формат – 1 байт).
Перенос (единицы) 11 1111111
Слагаемое 1 099(10) 01100011(2)
Слагаемое 2 095(10) 01011111(2)
Сумма 194(10) 11000010(2)
Операция получается громоздкая со многими переносами, но удобная для ЭВМ.
Сложение двоично-десятичных чисел
В операции сложения двоично-десятичных чисел участвуют только модули чисел. Поскольку код одноразрядных двоично-десятичных чисел полностью совпадает с их двоичным кодом, никаких проблем при выполнении операции сложения не возникает. Однако многоразрядные двоично-десятичные числа не совпадают с двоичными, поэтому при использовании двоичной арифметики получается результат, в который надо вводить коррекцию. Рассмотрим это подробнее.
Уже отмечалось, что каждая цифра десятичного числа может быть представлена кодом от 0000 до 1001, поэтому если при сложении разряда j двоично-десятичного числа результат меньше, либо равен 9, то коррекции не требуется, так как двоично-десятичный код результата полностью совпадает с его двоичным кодом.
Пример.
Zj=Xj+Yj
= 3(10)+5(10), где j – номер разряда десятичного числа

Если при сложении j-разрядов чисел результат Zj
будет больше или равен 10, то требуется коррекция результата. Рассмотрим, как машина может идентифицировать эту ситуацию. Существуют два варианта.
Вариант 1. Zj=10...15 = (1010...1111)
Здесь требуется коррекция, т.е. перенос 1 в старший (j+1) десятичный разряд. Необходимость коррекции в этом случае ЭВМ узнает по чисто формальным признакам:

Эту ситуацию можно описать логическим выражением:

Пример.
Zj=Xj+Yj
= 5(10)+7(10) , где j – номер разряда десятичного числа.

Перенос из разряда j означает в десятичной системе счисления, что


Zjкор = Zj - 10(10) + 16(10) = Zj + 6(10).
Тогда в рассмотренном выше примере

Вариант 2. Zj=16,17,18 = (8+8, 8+9, 9+9)
В этом случае из младшей тетрады в старшую происходит перенос 1 или 16(10). Но в десятичной системе счисления переносится в старший разряд только 10. Следовательно, для компенсации в младший разряд следует прибавить 6.
Пример.
Zj=Xj+Yj
= 8(10)+9(10) = 17(10), где j – номер разряда десятичного числа.

Таким образом, можно сформулировать правило, по которому следует осуществлять коррекцию каждого десятичного разряда результата:
если при сложении многоразрядных двоично-десятичных чисел возник перенос из разряда или f=1, то этот разряд требует коррекции (прибавления 6(10)). При этом корректируются все тетрады последовательно, начиная с младшей.
Пример.
Z = X + Y = 927 + 382 = 1309.

При практической реализации двоично-десятичной арифметики поступают несколько по-другому.
Алгоритм выполнения операции состоит в следующем:
1. Одно из слагаемых представляется в коде с избытком 6, т.е. к каждой тетраде двоично-десятичного числа добавляется число 0110. Избыток не обязательно добавлять к одному из слагаемых. Его можно добавить к результату сложения обоих модулей.
2. Сложение двоично-десятичных модулей выполняется по правилам двоичной арифметики.
3. Если при сложении тетрад получается результат Zj больше или равный 10, то автоматически вырабатывается перенос в следующий разряд (тетраду), поскольку фактически Zj³16. В этом случае результат в данной тетраде получается в естественном двоично-десятичном коде 8421 и коррекции не требуется. Однако, если избыток добавлять к результату сложения модулей, а не к одному из слагаемых, то при выяснении необходимости коррекции следует учитывать переносы как при сложении модулей, так и при добавлении избытка.
4. Если при сложении в каких-либо тетрадах переносы отсутствуют, то для получения правильного результата из кодов этих тетрад необходимо вычесть избыток 6. Это можно сделать двумя способами:
просто вычесть число 0110(2) = 6(10);
сложить с дополнением до 16(10) , т.е. с числом 10(10)
= 1010(2).
Возникшие при этом межтетрадные переносы не учитываются.
На практике реализуют второй способ.
Пример.
Z = X + Y = 132 + 57 = 189.

Перед сложением операнды выравниваются по крайней правой тетраде. Теперь надо к Z’ добавить избыток (6(10)):

Такой же результат получится, если с избытком +6 взять один из операндов (X или Y). Тогда к результату избыток прибавлять не нужно.
В данном примере при вычислении Z6’ не было переносов из каких-либо тетрад, поэтому необходима коррекция каждой тетрады суммы Z6’. Коррекция производится путем прибавления к каждой тетраде числа 10(10)= 1010(2):

Пример.
Z = X + Y = -93(10) - 48(10)
= -(93+48)(10) = -141(10).

Перед сложением операнды выравниваются по крайней правой тетраде. После этого к Z необходимо добавить избыток (6(10)):

Такой же результат получится, если с избытком +6 взять один из операндов (X или Y). Тогда к результату избыток прибавлять нет необходимости. В данном примере из двух тетрад переносы существуют, поэтому необходима коррекция только старшей тетрады (из нее нет переноса):

Пример.
Z = X + Y = 99(10) + 99(10)
= 198(10).

При сложении модулей возникли переносы. Добавим избыток:

При добавлении избытка 6 переносов не было, однако они имели место при сложении модулей. Их следует учитывать при оценке необходимости коррекции, поэтому, в данном случае, коррекция требуется только для старшей тетрады:

Сложение и вычитание в дополнительном коде
При выполнении арифметических операций в современных ЭВМ используется представление положительных чисел в прямом коде (ПК), а отрицательных – в обратном (ОК) или в дополнительном (ДК) кодах. Это можно проиллюстрировать схемой на рис. 2.4.

Общее правило. При алгебраическом сложении двух двоичных чисел, представленных обратным (или дополнительным) кодом, производится арифметическое суммирование этих кодов, включая разряды знаков. При возникновении переноса из разряда знака единица переноса прибавляется к МЗР суммы кодов при использовании ОК и отбрасывается при использовании ДК. В результате получается алгебраическая сумма в обратном (или дополнительном) коде.
Рассмотрим подробнее алгебраическое сложение для случая представления отрицательных чисел в ДК.
При алгебраическом сложении чисел со знаком результатом также является число со знаком. Суммирование происходит по всем разрядам, включая знаковые, которые при этом рассматриваются как старшие. При переносе из старшего разряда единица переноса отбрасывается и возможны два варианта результата:
знаковый разряд равен нулю: результат – положительное число в ПК;
знаковый разряд равен единице: результат – отрицательное число в ДК.
Для определения абсолютного значения результата его необходимо инвертировать, затем прибавить единицу.
Пример.
Вычислить алгебраическую сумму 58-23.

Пример.
Вычислить алгебраическую сумму 26-34.


Пример.
Вычислить алгебраическую сумму -5-1.

Сложение (вычитание) ЧПЗ
Требуется вычислить Z=X±Y при условии, что |X|³|Y|. Формальное выражение для выполнения этой операции можно записать следующим образом:


Алгоритм выполнения операции состоит в следующем:
производится выравнивание порядков, при котором порядок меньшего по модулю числа принимается равным порядку большего, а мантисса меньшего числа сдвигается вправо на число S-ричных разрядов, равное разности (Px-Py), т.е. происходит денормализация;
производится сложение (вычитание) мантисс, в результате чего получается мантисса суммы (разности);
порядок результата равен порядку большего числа;
полученный результат нормализуется.
Пример.
Сложить два числа (ЧПЗ) Z=X+Y для S = 2.

В общем случае сложение и вычитание q производится по правилам сложения и вычитания чисел с фиксированной точкой, т.е. с использованием прямого, обратного и дополнительного кодов.
Операции сложения и вычитания чисел с плавающей запятой, в отличие от операций с фиксированной запятой, выполняются приближенно, так как при выравнивании порядков происходит потеря младших разрядов одного из слагаемых (меньшего) в результате его сдвига вправо (погрешность всегда отрицательна).
Умножение
Как и в десятичной системе счисления, операция перемножения двоичных многоразрядных чисел производится путем образования частичных произведений и последующего их суммирования. Частичные произведения формируются в результате умножения множимого на каждый разряд множителя, начиная с МЗР. Каждое частичное произведение смещено относительно предыдущего на один разряд. Поскольку умножение идет в двоичной системе счисления, каждое частичное произведение равно либо 0 (если в соответствующем разряде множителя стоит 0), либо является копией множимого, смещенного на соответствующее число разрядов влево (если в разряде множителя стоит 1). Поэтому умножение двоичных чисел идет путем сдвига и сложения. Таким образом, количество частичных произведений определяется количеством единиц в множителе, а их сдвиг – положением единиц (МЗР частичного произведения совпадает с положением соответствующей единицы в множителе). Положение точки в дробном числе определяется так же, как и при умножении десятичных чисел.
Пример.
Вычислить произведение 17(10)*12(10)
в двоичной форме.

Естественно, что при сложении частичных произведений в общем случае возникают переносы.
Теперь рассмотрим машинный вариант операции перемножения. Общий алгоритм перемножения имеет вид

Как отмечалось выше, операция перемножения состоит в формировании суммы частичных произведений, которые суммируются с соответствующими сдвигами относительно друг друга. Этот процесс суммирования можно начинать либо с младшего, либо со старшего частичного произведения. В ЭВМ процессу суммирования придают последовательный характер, т.е. формируют одно частичное произведение, к нему с соответствующим сдвигом прибавляют следующее и т.д. (т.е. не формируют все частичные произведения, а потом их складывают). В зависимости от того, с какого частичного произведения начинается суммирование (старшего или младшего), сдвиг текущей суммы осуществляется влево или вправо. При умножении целых чисел для фиксации результата в разрядной сетке число разрядов должно равняться сумме числа разрядов в X и Y.
Рассмотрим на примере два машинных варианта выполнения умножения целых чисел: начиная со старшего частичного произведения (“старшими разрядами вперед”) и начиная с младшего частичного произведения (“младшими разрядами вперед”).
Пример.
Найти произведение двух чисел X*Y=1101(2)*1011(2)=13(10)*11(10)= 143(10).
Обозначим Pi – i-е частичное произведение.
1. Умножение старшими разрядами вперед:

2. Умножение младшими разрядами вперед:

Умножение ЧПЗ
Требуется вычислить

Z=X*Y=qxSPx*qySPy= qxqyS(Px+Py)=qzSPz .
Алгоритм выполнения операции состоит в следующем:
мантиссы сомножителей перемножаются;
порядки сомножителей складываются;
произведение нормализуется;
произведению присваивается знак в соответствии с алгоритмом, приведенным для ЧФЗ, а именно:
В данном случае имеется в виду способ умножения, предполагающий отделение от сомножителей их знаковых разрядов и раздельное выполнение действий над знаками и модулями чисел. Однако на практике в современных ЭВМ используют алгоритмы, не требующие раздельных операций над знаками и модулями, например алгоритм Бута. Информацию о них можно найти в литературе, приведенной в конце главы.
Рассмотрим простейший раздельный алгоритм перемножения ЧПЗ.
Умножение ЧПЗ сводится к следующим операциям:
алгебраическое суммирование порядков – это операции над целыми числами или ЧФЗ с фиксацией точки справа от МЗР;
перемножение мантисс – это операции над правильными дробями или над ЧФЗ с фиксацией точки слева от СЗР;
определение знака произведения.
Операции над целыми числами были рассмотрены ранее. Теперь рассмотрим только перемножение правильных дробей. Вручную дроби можно перемножать столбиком. Подсчет знаков в дробной части такой же, как и при перемножении десятичных дробей. В ЭВМ для перемножения мантисс (как и для целых чисел) возможны два варианта перемножения: "старшими разрядами вперед" и "младшими разрядами вперед".
Если требуется сохранить все разряды, то в устройстве, формирующем произведение, число разрядов должно равняться сумме числа разрядов множителя и множимого. Однако часто в произведении требуется сохранить то же количество разрядов, что и в множимом. Это приводит к потере младших разрядов.
Рассмотрим пример перемножения двух чисел "младшими разрядами вперед" для случая, когда разрядная сетка результата соответствует разрядной сетке сомножителей.
Пример.
Вычислить Z=X*Y=0.1101(2)
* 0.1011(2) = 0.8125(10) * 0.6875(10) = 0.55859375(10).

Таким образом, результат Z=0.1000(2)=0.5(10), поскольку последние четыре разряда потеряны.
При перемножении мантисс ( правильных дробей) последнее сложение можно не делать, а ограничиться просто последним сдвигом. Из примера видно, что если разрядная сетка ограничена числом разрядов X, то результаты правее вертикального пунктира не фиксируются после выполнения сдвигов. Таким образом, четыре младших разряда будут потеряны, и результат будет приближенный 0.1000(2). В ряде случаев используется округление по правилу: если старший из отбрасываемых разрядов содержит 1, то к младшему из сохранившихся разрядов добавляется 1. В данном примере получается число 0.1001(2).
В заключение отметим следующее:
если мантисса X или Y равна 0, то перемножение не проводится и Z=0;
если при суммировании PX и PY возникло переполнение и PZ<0, то это означает, что Z меньше минимального представляемого в машине числа, и Z присваивают 0 без перемножения мантисс;
если при суммировании PX и PY возникло переполнение и PZ>0, может оказаться, что Z все же находится в диапазоне представляемых в ЭВМ чисел, так как после нормализации полученного qZ
переполнение в порядке может исчезнуть.
Умножение модулей двоично-десятичных чисел
Операция умножения сводится к образованию и многократному сложению частичных двоично-десятичных произведений.
Алгоритм выполнения операции состоит в следующем:
1. Сумма частичных произведений полагается равной нулю.
2. Анализируется очередная тетрада множителя, и множимое прибавляется к сумме частичных произведений столько раз, какова цифра, определяемая этой тетрадой.
3. Сумма частичных произведений сдвигается на одну тетраду, и повторяются действия, указанные в п. 2, пока все цифры (тетрады) множителя не будут обработаны. Направление сдвига зависит от того, какой вариант перемножения выбран – "старшие разряды вперед" или "младшие разряды вперед".
4. Каждая операция суммирования завершается десятичной коррекцией, соответствующей случаю суммирования двоично-десятичных чисел без избытка 6 (т.е. необходимо добавить 0110 к тем тетрадам, из которых был перенос или в которых f=1).
Пример.
Z = X * Y = 25(10) * 13(10)
= 325(10).
X = 25(10) = 0010 0101(2-10); Y = 13(10) = 0001 0011(2-10).
Для решения примера выберем вариант перемножения "старшие разряды вперед". В соответствии с п. 1 алгоритма полагаем сумму частичных произведений P0=0. (Частичные произведения будем обозначать Pi).

Формирование второго частичного произведения - более длительная операция, поскольку вторая анализируемая тетрада содержит 3(10), поэтому каждая операция суммирования требует проверки необходимости коррекции. Вычислим P2, последовательно суммируя слагаемые, образующие P2:

Таким образом, второе частичное произведение, состоящее из трех слагаемых, имеет вид
P2
= 0111 0101.
Теперь можно вычислить сумму первого и второго частичного произведений, т.е. результат:

Окончательный результат: Z = 0011 0010 0101(2-10)
= 325(10).
Следует отметить, что в данном случае при суммировании операндов не возникало переносов, поэтому коррекция осуществлялась только по признаку f=1.
Управляющие устройства
Выше отмечалось, что УУ (рис. 3.5) управляет работой АЛУ путем выработки последовательности микрокоманд, необходимых для выполнения той или иной операции (+, -, /, * и т.д.). Порядок выполнения микрокоманд определен микропрограммой реализации операции, но может изменяться в зависимости от признаков операции, вырабатываемых в АЛУ (P1,...,Pm) и подаваемых на вход УУ.

Микропрограммы могут иметь как линейную структуру, так и быть разветвленными, причем условные переходы осуществляются в соответствии с признаками P.
Технические реализации УУ даже простейших процессоров разнообразны. Однако в самом общем случае их различают по способу хранения микропрограмм. По этому критерию УУ подразделяются на УУ с жесткой (схемной) логикой и УУ с хранимой в специальной памяти микропрограммой. Если микропроцессорная память доступна программисту, то УУ являются микропрограммируемыми и позволяют изменить систему команд процессора. Если микропрограммная память не доступна, то процессор имеет неизменную систему команд, как и в случае УУ с жесткой логикой.
Данные варианты отличаются друг от друга принципами построения, аппаратными затратами, временем реализации микропрограмм, возможностью изменения последовательности микрокоманд, а следовательно, и системы команд процессора.
УУ современных процессоров во многих случаях комбинированные. Выполнением простых команд управляет быстродействующее УУ на жесткой логике, а выполнением сложных команд – более медленное УУ с микропрограммной памятью.
Ниже будут рассмотрены общие принципы построения обоих типов УУ.
УУ с хранимой в памяти логикой
Идея создания микропрограммного
УУ возникла давно, в 1951г., но реализовать ее в полном объеме удалось сравнительно недавно – с появлением компактных устройств памяти на БИС. Обобщенная структурная схема микропрограммного УУ изображена на рис. 3.8.
В общем случае МК может задавать одну или несколько МО. Микропрограмма хранится в ПМК. Адрес МК формируется контроллером КПМК и запоминается в регистре адреса МК (РгАМК). МК считывается из памяти в регистр микрокоманды (РгМК). МК, в общем случае, имеет три поля – АСМК, КМО, КПР.
В последнее заносят признак разветвления в микропрограмме, который необходимо анализировать в КПМК. Адрес первой МК определяет КОП, т.е. происходит вызов соответствующей микроподпрограммы. АСМК может указываться в МК явным образом или формироваться естественным путем (при последовательной выборке МК). После выдачи СУ на ОУ происходит выполнение МК, после чего цикл (выборка-реализация) повторяется.
 |
УУ с жесткой логикой
УУ, построенные на жесткой логике (рис. 3.6), исторически появились первыми. Основным преимуществом таких УУ является их быстродействие. Именно поэтому абсолютное большинство специализированных процессоров, особенно предназначенных для обработки информации в режиме реального времени, имеют УУ на жесткой логике. Под специализированными понимаются процессоры, предназначенные для выполнения узкого набора специальных функций (обработка сигналов радиолокационных станций, преобразование Фурье, матричные операции, обработка сигналов в скоростных линиях связи и т.д.) с максимальной скоростью.
Однако и в процессорах общего назначения с универсальными наборами команд УУ на жесткой логике также используются очень широко, особенно, как уже отмечалось, для управления выполнением простых команд. Системы команд таких процессоров всегда фиксированные и не могут быть изменены пользователем. Подобные УУ иногда называют специализированными.
Специализированные УУ формируют неизменные последовательности сигналов управления (СУ).
Блок логических схем состоит из комбинационных схем, регистров, счетчиков, дешифраторов и других устройств, выполняющих функции запоминания текущего состояния автомата, определяющего СУ, и формирования следующего состояния в соответствии с входными признаками.
Микропрограмма в таком автомате хранится за счет системы жестких связей между узлами УУ. Для изменения микропрограммы требуется демонтаж жестких связей и создание новой схемы.

Одним из недостатков УУ на жесткой логике является то, что любые изменения или модификации команд универсального процессора, требующие изменения микропрограмм, приведут к изменению структуры управляющего автомата, а следовательно, и топологии его внутренних связей. При производстве специализированных процессоров требуется весьма широкая номенклатура УУ (по числу решаемых задач) при относительно небольшой потребности в каждом конкретном типе. С точки зрения технологии микроэлектронного производства процессоров в виде БИС и СБИС указанный недостаток является весьма существенным.
Увеличивается цена каждого выпущенного кристалла процессора за счет увеличения расходов на разработку новых топологий УУ и отладку технологии их производства.
Оптимальным решением этой проблемы явилось построение УУ на специализированных логических структурах с фиксированной топологией – программируемых логических матрицах (ПЛМ). ПЛМ является слоистой структурой, в каждом слое которой сосредоточены однотипные логические элементы. Топология связей построена таким образом, что на входы каждого элемента последующего слоя подаются выходные сигналы всех элементов предыдущего слоя. ПЛМ может выполняться как отдельная БИС, так и формироваться внутри кристалла процессора, являясь весьма удобным элементом для создания управляющих автоматов.
Обобщенная функциональная схема простейшей ПЛМ представлена на
рис. 3.7.

При изготовлении ПЛМ образуется схема, допускающая множество вариантов обработки входных сигналов. Входные элементы позволяют иметь все входные переменные как в прямой, так и в инверсной форме. На входы любого элемента "И" поданы все входные переменные и их инверсии. Ко входам каждого элемента "ИЛИ" подключены выходы всех элементов "И". Наконец, выходные элементы позволяют получить любую из выходных функций в прямом или инверсном виде.
Программирование матрицы состоит в устранении ненужных связей с помощью фотошаблонов или выжиганием (подобно тому, как это делается в ПЗУ).
Программируя ПЛМ, можно реализовать нужные системы булевых функций. Это позволяет строить управляющие автоматы весьма сложной структуры. В силу своей сложности УУ, как правило, описывается большим количеством булевых функций многих переменных. Эти переменные, в свою очередь, часто бывают зависимыми, поэтому оказывается необходимой совместная
минимизация системы булевых функций, реализуемой ПЛМ.
Рассмотренная выше функциональная схема иллюстрирует только саму идею построения ПЛМ. Структура же реально выпускаемых БИС достаточно разнообразна. Для построения управляющих автоматов наиболее удобны БИС, содержащие наряду с ПЛМ набор выходных триггеров.
Следующим поколением устройств типа ПЛМ являются ПЛИС – программируемые логические интегральные схемы, позволяющие программно скомпоновать в одном корпусе электронную схему, эквивалентную схеме, включающей от нескольких десятков до нескольких сотен ИС стандартной логики.
В настоящее время на мировом рынке доминируют несколько производителей ПЛИС – XILINX, ALTERA, LATTICE, AT&T, INTEL. Выпускаемые ими ПЛИС весьма разнообразны по сложности, назначению, многофункциональности и т.д., однако все они делятся на две большие группы – EPLD и FPGA.
EPLD – многократно программируемые для сохранения конфигурации используется ППЗУ с ультрафиолетовым стиранием).
FPGA – многократно реконфигурируемые для сохранения конфигурации используется статическое ОЗУ).
Фирмы-производители поставляют также полное инструментальное обеспечение для разработки и применения устройств на базе EPLD и FPGA с помощью персональных компьютеров.
Вопросы для самопроверки
1. Укажите, чем АВМ отличается от ЦВМ.
2. Назовите основные этапы эволюции ЭВМ.
3. Опишите классическую структуру ЭВМ по Нейману и укажите свойства каждого блока.
4. В чем заключается принцип оптимального соотношения аппаратных и программных средств при построении вычислительной техники?
5. Опишите способ обращения пользователя ЭВМ к ее аппаратным средствам.
6. Что нового появилось в каждом поколении по отношению к предыдущему.
7. Чем различается принцип построения малых ЭВМ и больших ЭВМ общего пользования?
1. Какие виды систем счисления вы знаете?
2. В каких случаях целесообразно применять двоичную, восьмеричную и шестнадцатеричную систему счисления?
3. Чем двоичная система счисления отличается от двоично-десятичной?
4. Как различаются прямой, обратный и дополнительный коды для представления чисел?
5. Когда следует применять прямой, обратный и дополнительный коды для представления чисел?
6. Что такое переполнение разрядной сетки?
7. В каких случаях возникает переполнение разрядной сетки?
8. Для чего используют модифицированные коды?
9. Опишите алгоритм перевода из дополнительного кода в десятичную систему.
10. Поясните понятие «арифметика повышенной точности».
11. Опишите формат ЧФЗ.
12. Для чего нужны ЧФЗ, почему при работе с ними вводят масштабный коэффициент?
13. Опишите формат ЧПЗ.
14. В каких случаях используют ЧПЗ? В чем преимущества ЧФЗ и ЧПЗ?
15. Что такое нормализация числа?
16. Назовите существующие форматы ЧПЗ, используемые в ЭВМ.
17. От чего зависит точность представления ЧПЗ в ЭВМ?
18. Для чего используется нормализация числа?
19. Какие методы ускорения умножения вы знаете? Кратко охарактеризуйте их.
20. В каких случаях используется десятичная арифметика?
21. Зачем нужна двоично-десятичная коррекция?
22. Какие признаки формируются в ЭВМ при нарушении ограничения на длину разрядной сетки?
23. Каким образом хранится символьная информация в ЭВМ?
1. Опишите обобщенную структуру процессора.
2. Как принцип академика Глушкова реализуется в структуре процессора?
3. Почему устройства обработки цифровой информации имеют многоуровневую структуру?
4. Какие операции выполняются в АЛУ? Как в зависимости от реализации этих операций подразделяются АЛУ?
5. Чем отличаются АЛУ блочного типа от многофункциональных АЛУ?
6. Опишите структуру АЛУ простейшего микропроцессора.
7. Опишите общие принципы построения УУ.
8. Укажите основные отличия УУ на жесткой логике от УУ с хранимой в памяти логикой.
9. Перечислите преимущества УУ с жесткой логикой.
10. В чем заключается главный недостаток УУ на жесткой логике?
11. Какое решение было найдено для устранения главного недостатка УУ на жесткой логике?
12. Для чего нужна ПЛМ?
13. Что такое ПЛИС?
14. Опишите структуру УУ с хранимой в памяти логикой.
15. Перечислите варианты взаимного расположения циклов выборка-реализация МК.
16. Охарактеризуйте основные способы формирования адреса следующей МК.
17. Какие форматы микрокоманд бывают?
18. Опишите алгоритмы формирования адреса следующей МК.
19. Назовите способы кодирования МК. Приведите для каждого способа схему кодирования МК.
20. Опишите достоинства и недостатки каждого способа кодирования микрокоманды.
21. Как подразделяются МК с точки зрения синхронизации?
Восьмеричная система счисления
В восьмеричной системе счисления употребляются всего восемь цифр, т.е. эта система счисления имеет основание S = 8. В общем виде восьмеричное число выглядит следующим образом:

где

Восьмеричная система счисления не нужна ЭВМ в отличие от двоичной системы. Она удобна как компактная форма записи чисел и используется программистами (например, в текстах программ для более краткой и удобной записи двоичных кодов команд, адресов и операндов). В восьмеричной системе счисления вес каждого разряда кратен восьми или одной восьмой, поэтому восьмиразрядное двоичное число позволяет выразить десятичные величины в пределах 0-255, а восьмеричное охватывает диапазон 0-99999999 (для двоичной это составляет 27 разрядов).
Поскольку 8=23, то каждый восьмеричный символ можно представить трехбитовым двоичным числом. Для перевода числа из двоичной системы счисления в восьмеричную необходимо разбить это число влево (для целой части) и вправо (для дробной) от точки (запятой) на группы по три разряда (триады) и представить каждую группу цифрой в восьмеричной системе счисления. Крайние неполные триады дополняются необходимым количеством незначащих нулей.
Пример.
Двоичное число 10101011111101(2)
записать в восьмеричной системе счисления.

Пример.
Двоичное число 1011.0101(2)
записать в восьмеричной системе счисления.

Перевод из восьмеричной системы счисления в двоичную осуществляется путем представления каждой цифры восьмеричного числа трехразрядным двоичным числом (триадой).
Выборка и выполнение МК
Возможны три варианта взаимного расположения циклов выборка-реализация.
Последовательный способ (рис. 3.9, а).
В этом случае выборка следующей МКi+1 не инициируется до момента окончания предыдущей МКi. Достоинством метода является прежде всего простота организации МК-цикла.
Параллельный способ (конвейер МК) –рис. 3.9, б.
Имеет место совмещение этапов выборки МКi+1 и реализации МКi. При равенстве периодов выборки и реализации достигается сокращение МК-цикла теоретически в 2 раза.
Параллельно-последовательный способ (рис. 3.9, в).
Используется при наличии МК условной передачи управления, когда адрес следующей МК зависит от результата предыдущей МК. Выборка МКi+2, стоящей после МКi+1
условного перехода, возможна только после завершения МКi+1.
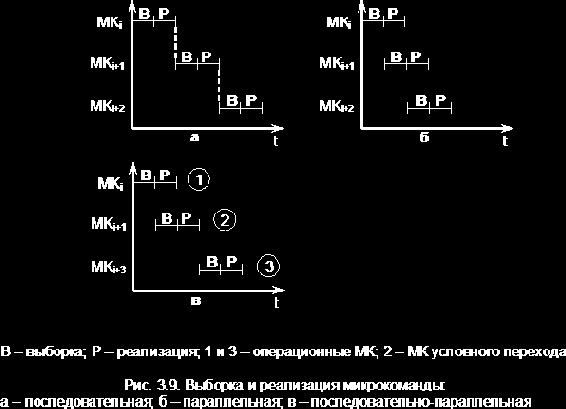
Используются два основных способа адресации – принудительная и естественная.
Принудительная
адресация сводится к тому, что в каждой микрокоманде, включая операционные, указывается адрес следующей за ней микрокоманды (рис. 3.10, а).
Естественная
адресация характерна тем, что адрес следующей микрокоманды образуется путем увеличения адреса предыдущей микрокоманды на 1. Это позволяет исключить поле адреса из операционных микрокоманд и уменьшить разрядность ПМК.
Для выполнения условных и безусловных переходов в микропрограмме используются управляющие
микрокоманды, содержащие адрес перехода и поле признаков (КПР) при обоих типах адресации. Таким образом, операционные и управляющие микрокоманды должны различаться некоторым признаком (рис. 3.10, б и в). Признак a определяет тип МК (например, a = 1 – операционная).
Коротко остановимся на формировании адреса при естественной адресации. В КПМК есть специальный счетчик адреса микрокоманд (СчА), в котором в конечном итоге формируется адрес следующей микрокоманды. Алгоритм формирования адреса следующей МК зависит от ее типа, а именно:
- операционная МК – после выборки МК СчА := СчА + 1;
- управляющая МК – после выборки происходит проверка условия, заложенного в МК. Если условие выполняется, то СчА := АСМК, а если условие не выполняется, то СчА := СчА + 1.

Вычитание
Операция вычитания двоичных чисел аналогична операции в десятичной системе счисления. Операция вычитания начинается, как и сложение, с МЗР. Если содержимое разряда уменьшаемого меньше содержимого одноименного разряда вычитаемого, то происходит заем 1 из соседнего старшего разряда. Операция повторяется над всеми разрядами операндов от МЗР до СЗР.
Поясним это примером.
Пример.
Вычесть два числа в десятичном и двоичном представлении (формат – 1 байт).
Заем (единица) 1 01100000
Уменьшаемое 109(10) 01101101(2)
Вычитаемое 049(10) 00110001(2)
Разность 060(10) 00111100(2)
Второй вариант операции вычитания – когда уменьшаемое меньше вычитаемого – приведен в разделе представления двоичных чисел в дополнительном коде.
Вычитание модулей двоично-десятичных чисел
По аналогии с операциями вычитания в двоичном коде операцию X-Y можно представить как X + (-Y). При этом отрицательное число представляется в дополнительном коде, аналогичном дополнительному коду в двоичной арифметике. Этот код используется только для выполнения операций вычитания. Хранятся двоично-десятичные числа (как положительные, так и отрицательные) в прямом коде со знаком.
Алгоритм выполнения операции состоит в следующем:
1. Модуль положительного числа представляется в прямом двоично-десятичном коде (8421).
Модуль отрицательного числа – в дополнительном коде (ДК) с избытком 6.
Для получения ДК необходимо:
- инвертировать значения разрядов всех тетрад числа;
- к младшему разряду младшей тетрады прибавить 1.
Таким образом, цепочка ПК (mod) ® ОК ® ОК+1 ® ДК аналогична цепочке в двоичной арифметике. Только здесь получается ДК с избытком 6, так как дополнение идет не до 10, а до 16.
2. Произвести сложение операндов (X) в ПК и (Y) в ДК.
3. Если при сложении тетрад возник перенос из старшей тетрады, то он отбрасывается, а результату присваивается знак "+", т.е. результат получается в прямом избыточном коде. Он корректируется по тем же правилам, что и при сложении модулей.
4. Если при сложении тетрад не возникает переноса из старшей тетрады, то результату присваивается знак "-", т.е. результат получается в избыточном ДК. В этом случае необходимо перейти к избыточному ПК (т.е. инвертировать все двоичные разряды двоично-десятичного числа и прибавить к младшему разряду 1).
5. Полученный в этом случае результат в ПК корректируется. Для этого к тем тетрадам, из которых возникал перенос при выполнении пункта 2 (при суммировании), необходимо добавить 10(10) или 1010(2). Возникшие при этом межтетрадные переносы не учитываются. Таким образом, корректировка происходит в тех тетрадах, которые в положительных числах не корректируются. Следует отметить, что при выполнении операции вычитания большего числа из меньшего (X - Y = Z, при |X|£|Y|), т.е.
при Z£ 0 алгоритм коррекции результата после перевода Z из ДК в ПК требует уточнения. А именно, после перевода Z в ПК необходимость коррекции определяется не только приведенными правилами, но и следующими требованиями:
а) нулевой результат не корректируется;
б) значащие нули справа в результате не корректируются;
в) если Z¹0 и в нем отсутствуют значащие нули справа (т.е. пп. а, б не имеют места), необходимо анализировать Y. Если в Y есть значащие нули справа, то соответствующие им разряды (тетрады) Z требуют обязательной коррекции, независимо от наличия переносов при сложении XПК
и YДК.
Пример.
Z=X-Y=49(10) -238(10)
=-189(10).

Представим |Y| в ДК с избытком 6:

Выполним сложение:

Отсутствие переноса из старшей тетрады является признаком того, что результат получился в ДК (т.е. отрицательный).
Перейдем к нескорректированному избыточному ПК:

Произведем коррекцию результата в соответствии с п. 5 алгоритма:

Поскольку ранее результат получался в ДК, т.е. отрицательный, необходимо добавить знак (-). Окончательный результат будет следующий:
Z= -(0001 1000 1001) = -189(10)
Пример.
Z=X-Y=143(10) -58(10)
=85(10).

Представим |Y| в ДК с избытком 6:

Выполним сложение:

Наличие переноса из старшей тетрады указывает на то, что результат получился в ПК (т.е. положительный).
Произведем коррекцию результата в соответствии с п. 3 алгоритма:

Заключительные замечания
Представленный выше материал дает только общее представление о выполнении арифметических операций над двоичными числами в различных системах счисления. Реальные алгоритмы выполнения арифметических операций, используемые в современных ЭВМ, позволяют существенно ускорить процесс вычислений, особенно для операций умножения и деления. Однако эти алгоритмы весьма громоздки и сложны для первоначального понимания. Более полную информацию о них можно найти в литературных источниках, перечисленных ниже.
Библиографический сисок
1. Искусство программирования. Т.1. Основные алгоритмы. 3-е изд., испр. и доп. / Д. Кнут; Под ред. Ю.В. Козаченко М.; СПб.; Киев: ВИЛЬЯМС, 2000. 729 с.
2. Искусство программирования. Т.2: Получисленные алгоритмы. 3-е изд., испр. и доп. / Д. Кнут; Под ред. Ю.В. Козаченко М.; СПб.; Киев: ВИЛЬЯМС, 2000. 832с.
3. Основы информатики: Учебник для вузов А.Я. Савельев. М.: МГТУ им. М.Э. Баумана, 2001. 328 с.
4. Информатика: Системы счисления и компьютерная арифметика:
/ Е.Андреева, И.Фалина; М.: Лаборатория базовых знаний, 1999. 256 с.
5. Электронные вычислительные машины и системы: Учеб. пособие для вузов. 3-е изд., перераб. и доп. / Б.М. Каган;М.: Энергоатомиздат, 1991. 592 с.
6. Программирование арифметических операций в микропроцессорах: Учеб. пособие для технических вузов. / Злобин В.К., Григорьев В.Л. М.: Высшая школа, 1991. 303 с.
7. Микропроцессоры и их применение в системах передачи и обработки сигналов: Учеб. пособие для вузов / Б.А. Калабеков; М.: Радио и связь, 1988. 368 с.
8. Введение в микропроцессорную технику / Ч. Гилмор; Под ред. В.М. Кисельникова. М.: Мир, 1984. 334 с.