Абсолютная
определяемая количеством элементарных работ, выполняемых в единицу времени;
АРХИТЕКТУРЫ, ХАРАКТЕРИСТИКИ, КЛАССИФИКАЦИЯ ЭВМ
Под архитектурой
ЭВМ понимается общая функциональная и структурная организация машины, определяющая методы кодирования данных, состав, назначение, принципы взаимодействия технических средств и программного обеспечения.
Можно выделить следующие важные для пользователя группы характеристик ЭВМ, определяющих ее архитектуру:
а) характеристики машинного языка и системы команд (количество и номенклатура команд, их форматы, системы адресации, наличие программно-доступных регистров в процессоре и т.п.), которые определяют алгоритмические возможности процессора ЭВМ;
б) технические и эксплуатационные характеристики ЭВМ;
в) характеристики и состав модулей базовой конфигурации ЭВМ;
г) состав программного обеспечения ЭВМ и принципы его взаимодействия с техническими средствами ЭВМ.
Архитектуры вычислительных систем
Точно также, как однопроцессорные компьютеры, представлены архитектурами с одним потоком данных SISD и множеством потоков данных SIMD, так и многопроцессорные системы могут быть представлены двумя базовыми типами архитектур в зависимости от параллелизма данных:
MISD — множество потоков команд — один поток данных;
MIMD — множество потоков команд — множество потоков данных. Класс MISD долгое время пустовал, поскольку не существовало практических примеров реализации систем, в которых одни и те же данные обрабатываются большим числом параллельных процессов. В дальнейшем для MISD нашлась адекватная организация вычислительной системы — распределенная мультипроцессорная система с общими данными.
Наиболее простая и самая распространенная система этого класса — обычная локальная сеть персональных компьютеров, работающая с единой базой данных, когда много процессоров обрабатывают один поток данных. Впрочем, тут есть одна тонкость. Как только в такой сети все пользователи переключаются на обработку собственных данных, недоступных для других абонентов сети, MISD — система превращается в систему с множеством потоков команд и множеством потоков данных, соответствующую MIMD - архитектуре. Так как только MIMD-архитектура включает все уровни параллелизма от конвейера операций до независимых заданий и программ, то любая вычислительная система этого класса в частных приложениях может выступать как SISD и SIMD-система. Например, если многопроцессорный комплекс выполняет одну-единственную программу без каких-либо признаков векторного параллелизма данных, то в этом конкретном случае он функционирует как обычный SISD-компьютер, и весь его потенциал остается невостребованным. Таким образом, употребляя термин «MIMD», надо иметь в виду не только много процессоров, но и множество вычислительных процессов, одновременно выполняемых в системе. MIMD-системы по способу взаимодействия процессоров (рис. 6.1) делятся на системы с сильной и слабой связью.
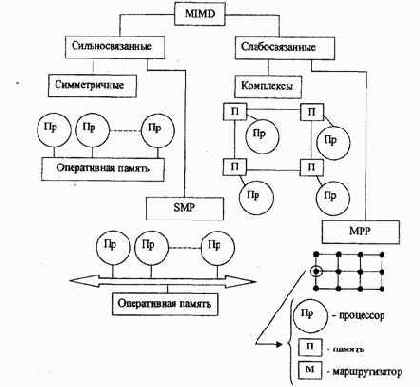
Рис.6.1. Классификация вычислительных систем с МIМD-архитектурой
Системы с сильной связью (иногда их называют «истинными» мультипроцессорами) основаны на объединении процессоров на общем поле оперативной памяти.
Системы со слабой связью, как правило, представляются многомашинными комплексами, в которых отдельные компьютеры объединяются либо с помощью сетевых средств, либо с помощью общей внешней памяти (обычно — дисковые накопители большой емкости). Разница организации MIMD-систем с сильной и слабой связью проявляются при обработке приложений, отличающихся интенсивностью обменов между процессами.
6.2. Сильно связанные многопроцессорные системы
В таких системах, как правило, число параллельных процессов невелико (не больше 16) и управляет ими централизованная операционная система. Процессы обмениваются информацией через общую оперативную память. При этом возникают задержки из-за межпроцессорных конфликтов. При создании больших мультипроцессорных ЭВМ (мэйнфреймов, суперЭВМ) предпринимаются огромные усилия по увеличению пропускной способности оперативной памяти. В результате аппаратные затраты возрастают чуть ли не в квадратичной зависимости, а производительность системы упорно «не желает» увеличиваться пропорционально числу процессоров. Так, сложнейшие средства снижения межпроцессорных конфликтов в оперативной памяти суперкомпьютеров серии CRAY X-MP/Y-MP позволяют получить коэффициент ускорения не более 3,5 для четырехпропессррной конфигурации системы.
То, что могут себе позволить дорогостоящие и сложные мэйнфреймы и суперкомпьютеры, не годится для компактных многопроцессорных серверов. Для простой и «дешевой» поддержки многопроцессорной организации была предложена архитектура SMP — мультипроцессирование с разделением памяти, предполагающая объединение процессоров на общей шине оперативной памяти. За аппаратную простоту реализации средств SMP приходится расплачиваться процессорным временем ожидания в очереди к шине оперативной памяти.В большинстве случаев пользователи готовы добавить в сервер один или более процессоров (но редко — более четырех) в надежде увеличить производительность системы. Стоимость этой операции ничтожна по сравнению со стоимостью всего сервера, а результат чаще всего оправдывает ожидания пользователя. Архитектура SMP стала своего рода стандартом для всех современных многопроцессорных серверов (например, НР9000 и DEC Alpha Server AXP). Стремительное увеличение пропускной способности системных шин предопределяет широкое распространение SMP архитектуры.
Большие ЭВМ
за рубежом часто называют мэйнфреймами
(Mainframe). Они поддерживают многопользовательский режим работы (обслуживают одновременно от 16 до 1000 пользователей).
Основные направления эффективного применения мэйнфреймов — это решение научно-технических задач, работа в вычислительных системах с пакетной обработкой информации, работа с большими базами данных, управление вычислительными сетями и их ресурсами. Последнее направление — использование мэйнфреймов в качестве больших серверов вычислительных сетей - часто отмечается специалистами среди наиболее актуальных.
Родоначальником больших ЭВМ является фирма IBM. По её стандартам (IBM 360, 370, 380, 390) в последние несколько десятилетий развивались ЭВМ этого класса в большинстве стран мира. В нашей стране было создано семейство больших машин ЕС ЭВМ.
Среди лучших современных разработок мэйнфреймов за рубежом следует в первую очередь отметить: IBM ES/9000 (созданные в 1990 г.), IBM S/390 (созданные в 1997 г.), а также японские компьютеры Ml 800 фирмы
Fujitsu.
Центральное устройство управления микропрограммного типа
Микропрограммный принцип управления обеспечивает реализацию одной машинной команды путем выполнения определенной микропрограммы, интерпретирующей алгоритм выполнения данной операции. Совокупность микропрограмм, необходимая для реализации системы команд ЭВМ, хранится в специальной памяти микропрограмм. Каждая микропрограмма состоит из определенной последовательности микрокоманд, которые после выборки из памяти преобразуются в набор управляющих сигналов.
Микрокоманда (МК) имеет операционно-адресную структуру. В операционной части МК размещается информация о микрооперациях (МО), одновременно выполняемых в блоках ЭВМ под управлением данной МК. В адресной части МК находится информация, необходимая для формирования адреса следующей микрокоманды.
Существуют различные способы организации операционной части МК:
- горизонтальное микропрограммирование;
- вертикальное микропрограммирование;
- смешанное микропрограммирование.
В первом случае операционная часть МК содержит столько разрядов, сколько различных МО выполняется в ЭВМ (число управляющих точек). Каждому разряду ставится в соответствие определенный УС, под действием которого выполняется соответствующая микрооперация. Таким образом, нет необходимости в преобразовании операционной части МК в управляющие сигналы. За счет этого сокращаются затраты времени на формирование УС. Недостатком данного метода является большая длина операционной части МК, что ведет к значительным затратам памяти микропрограмм.
По второму способу из всего множества М микроопераций выделяются подмножества, содержащие не более Н совместно выполняемых в каждом такте МО. Номера МО кодируются двоичным кодом, разрядность которого определяется по формуле m ³ log2М. Операционная часть МК должна содержать Н полей, каждое из которых имеет разрядность m и определяет код номера микрооперации. В результате использования данного метода уменьшается длина МК, сокращаются затраты микропрограммной памяти, но возникает необходимость в дешифрировании полей операционной части МК, что приводит к увеличению затрат времени на выработку УС.
В настоящее время наибольшее распространение получил третий способ — смешанное микропрограммирование, в котором сочетаются первые два способа. В этом случае операционная часть МК содержит как коды номеров микроопераций, так и сами УС, соответствующие отдельным МО.
Адресная часть МК используется для определения адреса следующей МК.
Существуют два способа адресации микрокоманд:
- принудительная адресация;
- естественная адресация.
Принудительная адресация МК заключается в том, что в каждой МК указывается адрес следующей МК. Адрес следующей МК может задаваться безусловно, независимо от значений признаков (осведомительных сигналов) или выбираться по условию, определяемому текущими значениями осведомительных сигналов, которые, в свою очередь, отображают текущее состояние операционных блоков процессора. Для этого в адресную часть МК кроме адресных полей включаются поля для задания условий (осведомительных сигналов).
При естественной адресации адрес следующей МК принимается равным увеличенному на единицу адресу предыдущей МК. В этом случае отпадает необходимость во введении адресной части в каждую МК. Если микрокоманды идут в естественном порядке, то процесс адресации реализуется счетчиком адреса МК. Для организации безусловных или условных переходов в микропрограмму включаются дополнительные управляющие МК.
Обобщенная структура блока микропрограммного управления (ЕМУ) представлена на рис. 3.7. Узел ФАМ предназначен для формирования адреса очередной МК с учетом значений адресной части (АЧ) предыдущей МК и множества {х} осведомительных сигналов. Микропрограммная память (МПП) хранит микропрограммы операций и по сформированному адресу в каждом такте выдает значение очередной МК, которое записывается в регистр микрокоманд (РМК). Поля операционной части (OЧ), выбранной МК, при необходимости дешифрируются для выработки управляющих сигналов {y}. Первоначальное обращение к какой-либо микропрограмме осуществляется по начальному адресу (НА), который соответствует коду операции выполняемой команды.
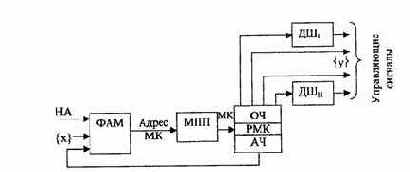
Рис.3.7. Обобщенная структура БМУ
С точки зрения физической реализации управления МПП делится на два вида: память с постоянно записанной информацией и память, допускающая перезапись информации. Память с постоянно записанной информацией (ПЗУ) работает только на чтение информации и, как правило, является более быстродействующей и простой по управлению, нежели память с перезаписью. В то же время память, допускающая перезапись, предоставляет больше дополнительных возможностей для повышения эффективности работы процессора за счет постоянного совершенствования алгоритмов выполнения операций.
Таким образом, использование в составе центрального устройства управления БМУ приводит к двухуровневому принципу управления процессом обработки данных. Первый уровень — это система команд ЭВМ (программное управление), второй — микропрограммное управление. Возникает задача организации перехода от одного уровня к другому. На рис. 3.8 приведена упрощенная структура процессора, в котором решается эта задача. По содержимому счетчика адреса команд (СЧАК) из памяти программ (кэшпамяти) выбирается команда и записывается в регистр команд (РК). Код операции из РКОП подается на дешифратор начального адреса (ДШНА), который на выходе формирует адрес первой микрокоманды микропрограммы, соответствующей данному коду операции. ДШНА реализуется на ПЗУ или ПЛМ (программируемой логической матрице). Под управлением микрокоманд выполняются все последующие действия. Адрес операнда из РА передается в память данных, осуществляется выборка операнда и занесение его в регистр общего назначения (СОЗУ) или в АЛУ. В АЛУ выполняется определенная микропрограммой операция, результат записывается в РОН или память данных.
Анализ аппаратурной (схемной) и микропрограммной реализации устройства управления указывает на зависимость стоимости управления от величины набора команд и их сложности. Для сокращенного набора простых команд выгоднее использовать схемное управление, что и реализуется в RISC-процессорах.
При расширенном составе сложных команд (как в CISC-процессорах) наиболее эффективно, с точки зрения затрат оборудования, микропрограммное управление. Однако оно приводит к увеличению затрат времени на выработку управляющих воздействий. Основным же преимуществом микропрограммного управления является его гибкость, которая позволяет повышать эффективность серийно выпускаемых и эксплуатируемых машин за счет введения новых средств математического обеспечения, использующих дополнительный набор команд и новые функции процессора. Модернизация алгоритмов или реализация дополнительных команд легко осуществляется путем изменения содержимого микропрограммной памяти. Наглядным примером использования данной возможности является технология ММХ, разработанная фирмой Intel. В серийно выпускаемый процессор Pentium были добавлены 57 новых команд для параллельной обработки видео- и аудиоинформации. Аппаратурные средства процессора остались прежними, изменению подверглась лишь микропрограммная память.
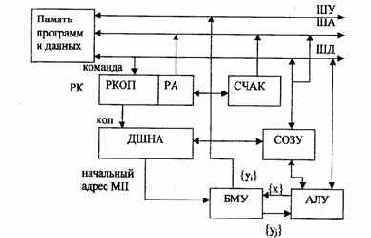
Рис.3.8. Процессор с микропрограммным управлением
33.2. Процедура выполнения команд
Стандартные фазы работы ЦП включают в себя выборку команды, вычисление адреса и выборку операндов, выполнение команды и запись результатов, обработку прерывания, изменение состояния процессора и системы в целом.
Выборка команд (ВК) — передача содержимого счетчика команд в регистр адреса памяти, считывание команды из основной памяти в регистр команды, модификация содержимого счетчика команд для выборки следующей
команды.
Выборка операнда (ВО) — вычисление адреса и обращение в основную память или к регистру локальной памяти. Операнд считывается и принимается в регистр АЛУ.
Арифметическая операция (АО) — инициализация (кодом операции) цикла работы устройства управления, которое, в свою очередь, управляет работой АЛУ, регистров и схем сопряжения. Результат выполнения передается в локальную или основную память и процессор переходит к выборке и выполнению следующей команды.
На рис. 3. 9 показаны временные диаграммы обработки команды с разбиением на этапы (фазы) выполнения (а): последовательная обработка команд (б); обработка команд в режиме совмещения — конвейер команд (в).
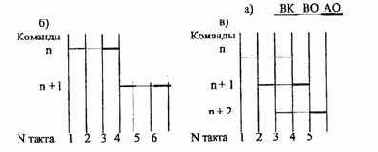
Рис. 3.9. Временные диаграммы обработки команд в процессоре:
а) этапы выполнения команды;
б) последовательное выполнение команд;
в) совмещенное выполнение команд (конвейеризация) »
Совмещенные принципы обработки (конвейер команд) существенно увеличивают пропускную способность процессора, однако эффективность их использования зависит от управления (синхронизации), числа уровней обработки.
Приостановка работы конвейера вызывает любая команда условного перехода в программе или взаимозависимость команд, т. е. использование следующей командой результатов предыдущей команды.
Следует учитывать, что совмещение обработки увеличивает объем оборудования и усложняет схемы управления тем сильнее, чем больше число уровней совмещения.
Все эти обстоятельства приходится учитывать при выборе числа уровней совмещения в каждом конкретном случае для получения заданных параметров и прежде всего удельных затрат (отношение производительности к стоимости). Опыт разработки ЭВМ общего назначения и проведенные исследования показывают, что технически и экономически целесообразной является совмещенная обработка 5-6 команд.
Для обеспечения непрерывности вычислительного процесса и сглаживания влияния логической зависимости команд в структуре ЦП используется блок прогнозирования ветвлений или устройство выполнения переходов.
В большинстве современных компьютеров используется конвейер команд.
Частично ассоциативное распределение
При данном способе несколько соседних строк (фиксированное число, не менее двух) из 128 строк кэш-памяти образуют структуру, называемую
Структура кэш-памяти, основанная на использовании частично ассоциативного распределения, показана на рис. 4.7. В данном случае в одну группу входят 4 строки.
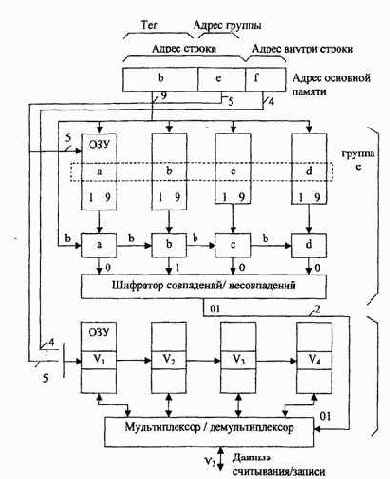
Рис.4.7. Структура кэш-памяти с частично ассоциативным распределением
Адрес строки основной памяти (14 бит) разделяется на две части: b - тег (старшие 9 бит) и е - адрес группы (младшие 5 бит). Адрес строки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бит).
Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адресами. Каждый банк массива тегов имеет длину слова 9 бит для помещения значения тега, а число слов равно числу групп, т.е. 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженных на число групп в кэшпамяти.
Для помещения в кэш-память строки, хранимой в ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырех строк в группе может быть выбрана. Для выбора группы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения.
Когда центральный процессор запрашивает доступ по i-му адресу, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (а, b, с, d), каждый из которых сравнивается со старшими 9 битами (b) адреса строки. На выходе четырех схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразрядный позиционный код, служащий адресом для выбора банка данных^!).
Одновременно осуществляется обращение к массиву данных по адресу
e.f(9 бит) и считывание из банка V;, требуемой строки иди слова.
При пересылке новой строки в кэш-память удаляемая из нее строка выбирается из четырех строк соответствующего набора (группы).
Число классов (уровней) прерывания.
В ЭВМ число различных запросов (причин) прерывания может достигать нескольких десятков или сотен. В таких случаях часть запросов разделяют на отдельные классы или уровни.
Совокупность запросов, инициирующих одну и ту же прерывающую программу, образует класс или уровень прерывания (рис. 3.13).
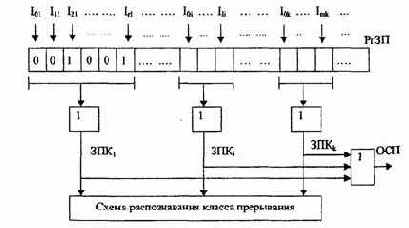
Рис.3.13. Разделение запросов на классы прерывания
Запросы всех источников прерывания поступают на регистр запросов прерывания РгЗП, устанавливая соответствующие его разряды в состояние 1, указывающее на наличие запроса прерывания определенного источника. Запросы классов прерывания ЗПК1-ЗПКk формируются элементами ИЛИ, объединяющими разряды РгЗП, относящиеся к соответствующим классам (уровням). Еще одна схема ИЛИ формирует общий сигнал прерывания ОСП, поступающий в устройство управления процессора.
Информация о действительной причине прерывания, породившей запрос данного класса, содержится в коде прерывания, который отражает состояние разрядов РгЗП, относящихся к данному классу прерывания.
После принятия запроса прерывания на исполнение и передачу управления прерывающей программе соответствующий триггер РгЗП сбрасывается. Объединение запросов в классы прерывания позволяет уменьшить объем аппаратуры. но приводит к замедлению работы системы прерывания.
Данные без знака
На рис. 2.14 показаны три формата данных без знака-
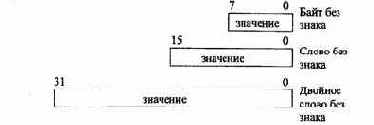
Рис. 2.14. Данные без знака
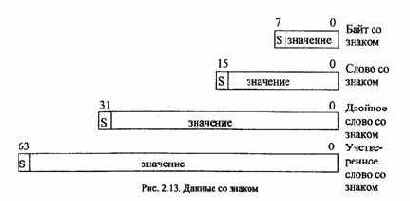
Данные со знаком
На рис. 2.13 приведены 4 формата данных со знаком с фиксированной точкой.
Представление таких данных и выполнение операций производится в дополнительном коде.
Данные типа строка
Строка представляет собой непрерывную последовательность бит, байт, слов или двойных слов (рис. 2.17). Строка бит может быть длиной до 1 Гби-та, а длина остальных строк может составлять от 1 байта до 4 Гбайтов. Поддерживается АЛУ.
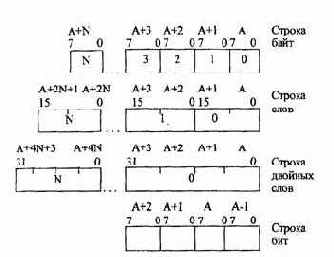
Рис.2.17. Данные типа строка
Данные типа указатель
Указатель содержит величину, которая определяет адрес фрагмента данных. Поддерживается два типа указателей, приведенных на рис. 2.19.
Диапазон представления целых чисел лежит в интервале от -264 до 264. Диапазон нормализованных чисел с двойной точностью - от ±2,23 х 10-308 до ±1,79х 10-308, а с расширенной точностью - от ±3,37 х 10-4932 до ± 1,18 x 104932.
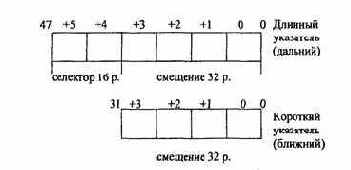
Рис.2.19. Данные типа указатель
Данные в формате с плавающей точкой
Формат включает три поля: знака, мантиссы и порядка (рис. 2.15). Поле мантиссы содержит значащие биты числа, а поле порядка содержит степень 2 и определяет масштабирующий множитель для мантиссы. Поддерживаются блоком FPU.
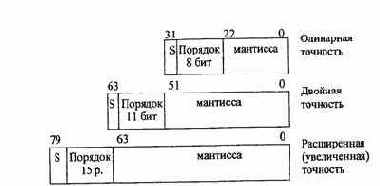
Рис.2.15. Форматы данных с плавающей точкой
Двоично-десятичные данные (
BCD)
На рис. 2.16 приведены форматы двоично-десятичных данных.
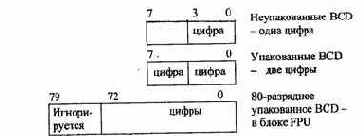
Рис.2.16. Форматы двоично-десятичных данных
Форматы команд и способы адресации в CISC-процессорах
В качестве примера рассмотрим набор команд и способы адресации, используемые в процессорах интеловской архитектуры. Для этих процессоров в табл. 2.1 приведены данные о развитии их системы команд.
Таблица 2.1
Развитие системы команд процессоров архитектуры Intel
| Год появления набора команд | Тип процессора, где набор был реализован впервые | Общее число команд | Смысл расширения | ||||
| 1979 | i8086 | 170 | Исходный набор команд х 86 | ||||
| 1985 | i386 | 220 | 50 новых команд, необходимых для перехода к 32-разрядной архитектуре | ||||
| 1997 | Pentium/MMX | 277 | 57 ММХ-команд для параллельной обработки видео- и аудиоинформации | ||||
| 1999 | Katmai (Pentium III) | 347 | 70 команд: SIMD-FP, дополнена ММХ, управление потоковым обменом данными с памятью |
В базовый набор команд 8086 входили операции с плавающей запятой (FP), но до i386 включительно они выполнялись отдельным сопроцессором, которого могло в компьютере и не быть. Блок FP-функций был включен в состав основного процессора в i486, однако в варианте 486SX обращение к этому блоку было заблокировано. Эти команды стали обязательной частью процессора, только начиная с Pentium.
Базовый набор команд 32-разрядного интеловского процессора обеспечивает выполнение операций над операндами, которые находятся в регистре, памяти или непосредственно в команде. В набор входят безадресные, одно-, двух- и трехадресные команды. Процессор реализует следующие шесть типов двухадресных команд:
- регистр—регистр;
- память — регистр;
- непосредственный операнд — регистр;
- регистр — память;
- память — память;
- непосредственный операнд — память.
Операнды могут содержать 8, 16 или 32 разряда. Для реализации различных типов команд определены форматы, задающие порядок размещения информации о выполняемой операции и способах выбора операндов.
Форматы команд и способы адресации в RISC-процессорах
Рассмотрим архитектурные особенности на примере процессора R3000. Этот процессор строится на основе СБИС 32-разрядного центрального процессора, арифметического сопроцессора и буфера записи.
Система команд включает 74 команды, которые можно разделить на 6 групп: загрузки/запоминания, операционные, переходов, работы с сопроцессором, управления системой и специальные.
Все команды имеют длину 32 бита и могут быть трех форматов:
I - команды с непосредственным операндом и обращения к памяти
KOП(6);Rs(5);Rt(5);I(16),
где Kg, R, - номера регистров, I - непосредственный операнд или смещение;
J - для команд переходов;
КОП (6); АДРЕС ПЕРЕХОДА (26);
R - для операционных команд;
КОП (6); Rs(5); Rt(5); Rd(5); Rl,(5); FUNC (6).
Операционные команды служат для выполнения арифметических, логических операций и сдвигов. Операционные команды используют как R-формат (команды типа регистр-регистр), так и 1-формат (команды регистр - непосредственный операнд). Предусмотрены 8 команд целочисленного умножения и деления.
Команды загрузки/запоминания обеспечивают обмен данными между регистрами общего назначения и памятью. Адреса памяти формируются с использованием базового регистра и 16-разрядного смещения (1-формат).
Безусловные переходы выполняются либо по косвенному адресу (R-формат), либо по прямому адресу (J-формат). В последнем случае старшие биты адреса переходов добавляются из счетчика команд.
Команды управления системой обеспечивают работу с виртуальной памятью.
Команды работы с сопроцессором являются дополнительными, их форматы и состав зависят or типа используемого сопроцессора.
ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ ОРГАНИЗАЦИЯ ЦЕНТРАЛЬНОГО ПРОЦЕССОРА ЭВМ
В области вычислительной техники различают процессоры центральные, специализированные, ввода-вывода, передачи данных и коммуникационные.
Глубина прерывания
- максимальное число программ, которые могут прерывать друг друга. Если после перехода к прерывающей программе и вплоть до ее окончания прием запросов прекращается, то говорят, что система имеет глубину прерывания, равную 1. Глубина равна n, если допускается последовательное прерывание до n программ. Глубина прерывания обычно совпадает с числом уровней приоритета в системе прерывания. На рис. 3.12 показаны процессы прерывания в системах с различной глубиной прерывания (предполагается, что приоритет каждого последующего запроса выше предыдущего). Система с большим значением глубины прерывания обеспечивает более быструю реакцию на срочные запросы.
Если запрос окажется не обслуженным к моменту прихода нового запроса от того же источника, то возникает так называемое насыщение системы прерывания.
В этом случае предыдущий запрос от данного источника будет машинально утерян, что недопустимо.
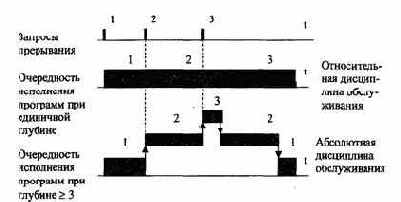
Рис.3.12. Процессы прерывания с различной глубиной прерывания и дисциплиной обслуживания
Характеристики системы прерывания
Для оценки эффективности систем прерывания могут быть использованы следующие характеристики.
Индексная адресация
Для работы программ с массивами, требующими однотипных операций над элементами массива, удобно использовать индексную адресацию. Схема индексной адресации аналогична базированию путем суммирования (см. рис. 2.7). В этом случае адрес i-го операнда в массиве определяется как сумма начального адреса массива (задаваемого полем смещения С) и индекса И, записанного в одном из регистров РП, называемом теперь индексным регистром. Адрес индексного регистра задается в команде полем адреса индекса — Аин (аналогично Aб).
В каждом i-м цикле содержимое индексного регистра изменяется на величину постоянную (часто равную 1). Использование индексной адресации значительно упрощает программирование циклических алгоритмов.
Для эффективной работы при относительной адресации применяется комбинированная индексация с базированием, при которой адрес операнда вычисляется как сумма трех величин (рис. 2.9):
АцОП=Б+И+С.
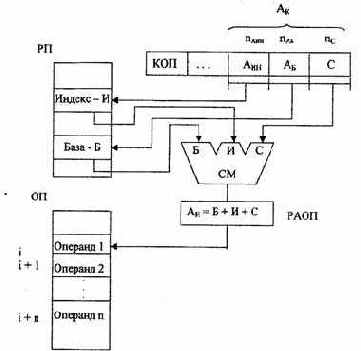
Рис. 2.9. Схема формирования исполнительного адреса при индексной адресации и базировании: Анн - адрес индексного регистра; пдии - длина адреса индексного регистра
Явная и неявная адресация
При явной адресации операнда в команде есть поле адреса этого операнда, в котором задается адресный код Ак. Большинство методов адресации являются явными.
При неявной адресации адресное поле в команде отсутствует, адрес операнда подразумевается кодом операции.
Метод неявной адресации операндов используется во всех процессорах. Основное его назначение — уменьшение длины команды за счет исключения части адресов. При этом методе код операции точно задает адрес операнда. Например, из команды исключается адрес приемника результата. При этом подразумевается, что результат в этой команде помещается на место второго операнда.
Эксплуатационная
— производительность на реальной рабочей нагрузке, формируемой в основном используемыми пакетами прикладных программ (ППП) общего назначения.
Методы определения производительности разделяются на три основных
группы:
- расчетные, основанные на информации, получаемой теоретическим или эмпирическим путем;
- экспериментальные, основанные на информации, получаемой с использованием аппаратно-программных измерительных средств;
- имитационные, применяемые для сложных ЭВМ. Основные единицы оценки .производительности:
Как мы будем действовать
После непреднамеренного удаления одного или нескольких файлов немедленно демонтируйте раздел и запустите дисковый редактор, работающий на секторов уровне. Например, можно воспользоваться BSD-портом уже известного нам редактора lde. К сожалению, на моем системе (4.5 BSD) он работает крайне нестабильно и не отображает основные структуры данных в удобочитаемом виде, хотя поддержка UFS в нем заявлена. При наличии достаточного количества свободного места можно скопировать раздел в файл и натравить на него любой hex-редактор (например, biew) или открыть непосредственно само устройство раздела (типа /dev/ad0s1a). А еще можно вставить в привод загрузочный CD-ROM с Windows PE и воспользоваться любым Windows-редактором от Microsoft Disk Probe до Runtime Disk Explorer'а. То же самое справедливо и для Norton Disk Editor'а, запущенного c дискеты из-под MS-DOS (правда ни диски большого объема, ни SCSI-устройства он не поддерживает). Еще можно запустить KNOPPIX или любой Live LINUX, ориентированный на восстановление (правда, в большинстве "реанимационных" дистрибутивов, и в частности, Frenzy 0.3, никакого дискового редактора вообще нет!)
В общем, как говорится, на вкус и цвет товарищей нет…
Классификация АЛУ
По способу представления чисел различают АЛУ:
- для чисел с фиксированной запятой;
- для чисел с плавающей запятой;
- для десятичных чисел.
По способу действия над операндами АЛУ делятся на последовательные и параллельные. В параллельных АЛУ операнды представляются параллельным кодом и операции совершаются параллельно во времени над всеми разрядами операндов. В последовательных АЛУ операнды представляются в последовательном коде, а операции производятся последовательно во времени над их отдельными разрядами. Такие АЛУ, как правило, используют конвейерный метод обработки, при котором совмещаются во времени фазы выполнения операции для различных разрядов операндов.
По выполняемым функциям АЛУ делятся на многофункциональные и функциональные (блочные). В блочном АЛУ операции над числами с фиксированной и плавающей запятой, десятичными и алфавитно-цифровыми полями, операции типа "умножение" выполняются в отдельных блоках. Такой подход позволяет увеличить скорость работы АЛУ за счет использования быстродействующих блоков, а также за счет организации параллельной работы этих блоков. Однако в этом случае значительно возрастают затраты оборудования.
В многофункциональных АЛУ всевозможные операции для всех форм представления чисел выполняются одними и теми же схемами, которые коммутируются нужным образом в зависимости от требуемого режима работы.
По структурной организации АЛУ можно разделить на устройства,
имеющие:
- регистровую структуру с непосредственными связями и закрепленной
логикой;
- магистральную структуру с сосредоточенной памятью и логикой. Арифметико-логические устройства первого типа базируются на принципе закрепления логических схем, используемых для выполнения микроопераций, за каждым из регистров. Так, на рис. 3.15 регистры Р1 и Р2 выполняют функции приема, хранения и выдачи операндов, поступающих из регистров общего назначения (РОН) процессора или КЭШ-памяти данных. С регистром Р1 непосредственно связан преобразователь кода ПК1.
Комбинационный сумматор КСМ объединен с регистром РЗ по схеме накапливающего сумматора, с которым непосредственно связаны ПК2 и комбинационная схема КС для мультиплексирования входных данных. На регистре РЗ выполняются микрооперации сдвига вправо или влево и сброс. Регистр Р4 выполняет микрооперации сдвига и непосредственно связан с преобразователем кода ПКЗ.
Таким образом, в данной структуре функции хранения и преобразования
информации выполняются одним и тем же операционным блоком.
Магистральная структура АЛУ отличается тем, что в ней регистры и схемы для преобразования информации выделены в отдельные блоки, связанные между собой по входам и выходам. В этом случае блок регистров (БР) выполняет функции приема, хранения, выдачи операндов и результатов, а операционный блок (ОБ) выполняет весь необходимый набор микроопераций над словами, хранимыми в БР. В данной структуре блок регистров может быть реализован двумя способами: либо как совокупность отдельных регистров с индивидуальными схемами управления, либо как сверхоперативное адресное запоминающее устройство.
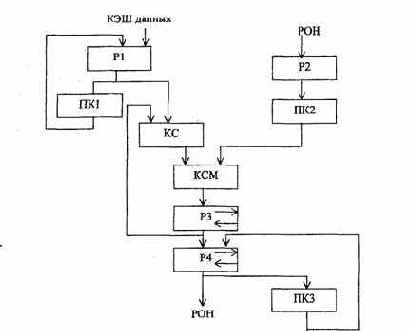
Рис.3.15. Регистровая структура с закрепленной логикой
Структура операционного блока имеет следующие модификации:
- последовательное соединение операционных узлов;
- параллельное соединение операционных узлов.
В первом случае (рис. 3.16) преобразователь кода ПК, комбинационный сумматор КСМ и сдвигатель СДВ соединены последовательно, причем входы ПК и КСМ связаны с выходными шинами блока регистров, а выход СДВ - с входной шиной БР. Такая организация операционного блока дает возможность выполнять с высокой скоростью последовательности микроопераций, обеспечивающей вычисление одного слова-
Во втором случае (рис. 3.17) операционные узлы (СМ, СДВ, ПК, КС) подсоединяются к входным и выходным шинам БР параллельно, что позволяет выполнять несколько микроопераций одновременно.
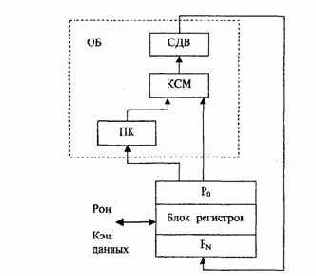
Рис. 3.16. Магистральная структура с последовательным соединением операционных узлов
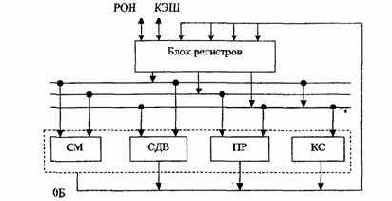
Рнс.3.17. Магистральная структура с параллельным соединением операционных узлов
Классификация ЭВМ по функциональным возможностям и размерам
По функциональным возможностям и размерам ЭВМ можно разделить (рис. 1.3) на супер-ЭВМ, большие, малые и микро-ЭВМ.
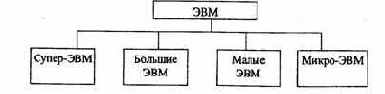
Рис. 1.3. Классификация ЭВМ по функциональным возможностям и размерам
Функциональные возможности ЭВМ обуславливаются основными технико-эксплуатационными характеристиками.
Некоторые сравнительные параметры названных классов современных ЭВМ приведены в табл. 1.4.
Исторически первыми появились большие ЭВМ, элементная база которых прошла путь от электронных ламп до интегральных схем со сверхвысокой степенью интеграции.
Таблица 1.4 Сравнительные параметры различных классов ЭВМ
| Параметр | Супер-ЭВМ | Большие ЭВМ | Малые ЭВМ | МикроЭВМ | |||||||
| Производительность, MIPS | 1000—100000 | 10-1000 | 1 100 | 1-100 | |||||||
| Емкость ОП, Мбайт | 2000—10000 | 64—10000 | 4-512 | 4-256 | |||||||
| Емкость ВЗУ, Гбайт | 500—5000 | 50—1000 | 2—100 | 0,5—10 | |||||||
| Разрядность, бит | 64—128 | 32—64 | 16-64 | 8—64 |
Классификация ЭВМ по назначению
По назначению ЭВМ можно разделить на три группы: универсальные (общего назначения), проблемно-ориентированные и специализированные
(рис. 1.2).

Рис. 1.2. Классификация Э@М по назначению
Универсальные ЭВМ
предназначены для решения самых различных видов задач: научных, инженерно-технических, экономических, информационных, управленческих и других задач. В качестве универсальных ЭВМ используются различные типы компьютеров, начиная от супер-ЭВМ и кончая персональными ЭВМ. Решаемые на этих компьютерах задачи отличаются сложностью алгоритмов и объемами обрабатываемых данных. Причем одни универсальные ЭВМ могут работать в многопользовательском режиме (в вычислительных центрах коллективного пользования, в локальных компьютерных сетях и т.д.), другие — в однопользовательском режиме.
Проблемно-ориентированные ЭВМ
служат для решения более узкого круга задач, связанных, как правило, с управлением технологическими объектами; регистрацией, накоплением и обработкой относительно небольших объемов данных; выполнением расчетов по относительно несложным алгоритмам. На проблемно-ориентированных ЭВМ, в частности, создаются всевозможные управляющие вычислительные комплексы.
Специализированные ЭВМ
используются для решения еще более узкого круга задач или реализации строго определенной группы функций. Такая узкая ориентация ЭВМ позволяет четко специализировать их структуру, во многих случаях существенно снизить их сложность и стоимость при сохранении высокой производительности и надежности их работы.
Классификация способов адресации по кратности обращения в память
Широко используются следующие методы адресации операнда с различной кратностью обращения (г) в память:
1. Непосредственная (г = 0).
2. Прямая (г = 1).
3. Косвенная (г > 2).
Классификация способов формирования исполнительных адресов ячеек памяти
Способы формирования адресов ячеек памяти (Аи) можно разделить на абсолютные и относительные.
Абсолютные способы
формирования предполагают, что двоичный код адреса ячейки памяти — Аи может быть извлечен целиком либо из адресного поля команды (в случае прямой адресации), или из какой-либо другой ячейки (в случае косвенной адресации), никаких преобразований кода адреса не производится.
Относительные способы
формирования Ац предполагают, что двоичный код адреса ячейки памяти образуется из нескольких составляющих: Б — код базы, И - код индекса, С - код смещения, используемых в сочетаниях (Б и С), (И и С). (Б,ИиС).
При относительной адресации применяются два способа вычисления Зд-реса Аи:
- суммирование кодов составляющих адреса;
- совмещение (конкатенация) кодов составляющих адреса. Суммирование кодов составляющих производится для случаев:
Аи= Б + С; Аи = И + С; Аи = Б + И + С.
Косвенная адресация операндов
При этом способе адресный код команды указывает адрес ячейки памяти, в которой находится не сам операнд, а лишь адрес операнда, называемый указателем операнда. Адресация к операнду через цепочку указателей (косвенных адресов) называется косвенной.
Адрес указателя, задаваемый программой, остается неизменным, а косвенный адрес может изменяться в процессе выполнения программы. Косвенная адресация, таким образом, обеспечивает переадресацию данных, т.е. упрощает обработку массивов и списковых структур данных, упрощает передачу параметров подпрограммам, но не обеспечивает перемещаемость программ в памяти (рис. 2.6,а).
Косвенная адресация так же широко используется в ЭВМ, имеющих короткое машинное слово, для преодоления ограничений короткого формата. В этом случае первый указатель должен располагаться в РП (рис. 2.6,6).
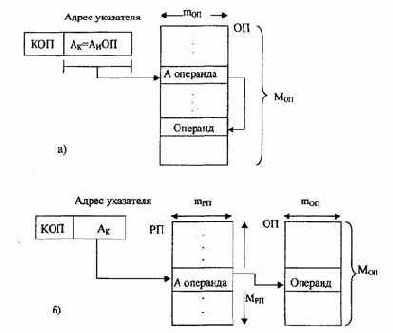
Рис.2.6. Схема косвенной адресации: а) указатель операнда и операнд расположены в одном адресном пространстве ОП; 6) указатель операнда расположен в РП, а операнд-в ОП
формат супер-блока (второстепенные поля опущены)
За концом супеблока, на некотором отдалении от него, находится первая группа цилиндров. В начале каждой группы расположена служебная структура cg (далее по тексту — описатель группы цилиндров, термин мой — КК), содержащая магическую последовательность 55h 02h 09h по которую все уцелевшие группы можно найти даже при полностью испорченном супеблоке (штатным образом, стартовые адреса всех последующих групп вычисляются путем умножения номера группы на ее размер, содержащийся в поле fs_cgsize).
Другие важные параметры:
q cg_cgx — порядковой номер группы, отсчитываемый от нуля;
q cg_old_niblk — кол-во inode в данной группе;
q cg_ndblk — кол-во блоков данных в данной группе;
q csum — кол-во свободных inode и блоков данных в данной группе;
q cg_iusedoff — смещение карты занятых inod'e, отсчитываемое от начала данной группы и измеряемое в байтах;
q cg_freeoff — смещение карты свободного пространства (байты от начла группы);
Структура cg определена в файле /src/ufs/ffs/fs.h и выглядит следующим образом:
#define CG_MAGIC 0x090255
#define MAXFRAG 8
struct cg {
/* 0x00 */ int32_t cg_firstfield; /* historic cyl groups linked list */
/* 0x04 */ int32_t cg_magic; /* magic number */
/* 0x08 */ int32_t cg_old_time; /* time last written */
/* 0x0С */ int32_t cg_cgx; /* we are the cgx'th cylinder group */
/* 0x10 */ int16_t cg_old_ncyl; /* number of cyl's this cg */
/* 0x12 */ int16_t cg_old_niblk; /* number of inode blocks this cg */
/* 0x14 */ int32_t cg_ndblk; /* number of data blocks this cg */
/* 0x18 */ struct csum cg_cs; /* cylinder summary information */
/* 0x28 */ int32_t cg_rotor; /* position of last used block */
/* 0x2С */ int32_t cg_frotor; /* position of last used frag */
/* 0x30 */ int32_t cg_irotor; /* position of last used inode */
/* 0x34 */ int32_t cg_frsum[MAXFRAG]; /* counts of available frags */
/* 0x54 */ int32_t cg_old_btotoff; /* (int32) block totals per cylinder */
/* 0x58 */ int32_t cg_old_boff; /* (u_int16) free block positions */
/* 0x5С */ int32_t cg_iusedoff; /* (u_int8) used inode map */
/* 0x60 */ int32_t cg_freeoff; /* (u_int8) free block map */
/* 0x64 */ int32_t cg_nextfreeoff; /* (u_int8) next available space */
/* 0x68 */ int32_t cg_clustersumoff; /* (u_int32) counts of avail clusters */
/* 0x6С */ int32_t cg_clusteroff; /* (u_int8) free cluster map */
/* 0x70 */ int32_t cg_nclusterblks; /* number of clusters this cg */
/* 0x74 */ int32_t cg_niblk; /* number of inode blocks this cg */
/* 0x78 */ int32_t cg_initediblk; /* last initialized inode */
/* 0x7С */ int32_t cg_sparecon32[3]; /* reserved for future use */
/* 0x00 */ ufs_time_t cg_time; /* time last written */
/* 0x00 */ int64_t cg_sparecon64[3]; /* reserved for future use */
/* 0x00 */ u_int8_t cg_space[1]; /* space for cylinder group maps */
/* actually longer */
структура описателя группы цилиндров
Между описателем группы цилиндров и группой inode расположена карта занятых inode и карта свободного дискового пространства, представляющие собой обыкновенные битовые поля, точно такие же как и в NTFS. При восстановлении удаленных файлов без этих карт никуда! Отделяя зерна от плевел, они существенно сужают круг поиска, что особенно хорошо заметно на дисках, заполненных более чем наполовину.
За картами следует массив inod'ов, смещение которого содержится в поле cg_iusedoff (адрес первой группы inode продублирован в суперблоке). По сути, в UFS структура inode ничем не отличается от ext2fs, только расположение полей другое. К тому же имеется только один блок косвенной адресации вместо трех, но это уже детали, в которые не будет углубляться (иначе или зависнем или завязнем), а лучше рассмотрим назначение фундаментальных полей, к числу которых принадлежат:
q di_nlink — кол-во ссылок на файл (0 означает "удален");
q di_size — размер файла в байтах;
q di_atime/di_atimensec — время последнего доступа к файлу;
q di_mtime/di_mtimensec — время последней модификации;
q di_ctime/di_ctimensec – время последнего изменения inode;
q di_db – адреса первых 12-блоков данных файла, отсчитываемые в фрагментах от начала группы цилиндров;
q di_ib — адрес блоков косвенной адресации (фрагменты от начала группы);
Сама структура inode определена в файле /src/ufs/ufs/dinode.h и для UFS1 выглядит так:
struct dinode {
/* 0x00 */ u_int16_t di_mode; /* 0: IFMT, permissions; see below. */
/* 0x02 */ int16_t di_nlink; /* 2: File link count. */
/* 0x04 */ union {
u_int16_t oldids[2]; /* 4: Ffs: old user and group ids. */
int32_t inumber; /* 4: Lfs: inode number. */
} di_u;
/* 0x08 */ u_int64_t di_size; /* 8: File byte count. */
/* 0x10 */ int32_t di_atime; /* 16: Last access time. */
/* 0x14 */ int32_t di_atimensec; /* 20: Last access time. */
/* 0x18 */ int32_t di_mtime; /* 24: Last modified time. */
/* 0x1C */ int32_t di_mtimensec; /* 28: Last modified time. */
/* 0x20 */ int32_t di_ctime; /* 32: Last inode change time. */
/* 0x24 */ int32_t di_ctimensec; /* 36: Last inode change time. */
/* 0x28 */ ufs_daddr_t di_db[NDADDR]; /* 40: Direct disk blocks. */
/* 0x58 */ ufs_daddr_t di_ib[NIADDR]; /* 88: Indirect disk blocks. */
/* 0x64 */ u_int32_t di_flags; /* 100: Status flags (chflags). */
/* 0x68 */ int32_t di_blocks; /* 104: Blocks actually held. */
/* 0x6C */ int32_t di_gen; /* 108: Generation number. */
/* 0x70 */ u_int32_t di_uid; /* 112: File owner. */
/* 0x74 */ u_int32_t di_gid; /* 116: File group. */
/* 0x78 */ int32_t di_spare[2]; /* 120: Reserved; currently unused */
};
С точки зрения UFS, директории
Имена файлов хранятся в директориях. В inod'ах их нет. С точки зрения UFS, директории являются обыкновенными файлами (ну, может, не совсем обыкновенными) и могут хранится в любом месте, принадлежащем группе цилиндров. Файловая система UFS поддерживает несколько типов хеширования директорий, однако на структуре хранения имен это никак не отражается. Имена хранятся в блоках, называемых DIRBLKSIZ в структурах типа direct, выровненных по 4'х байтовой границе.

структура direct, отвечающая за хранение имен файлов и директорий
На этом описание файловой системы UFS можно считать законченным. Для ручного восстановления данных приведенной информации вполне достаточно.
Малые ЭВМ
(мини-ЭВМ) - надежные, недорогие и удобные в эксплуатации компьютеры, обладающие несколько более низкими по сравнению с мэйнфреймами возможностями. В многопользовательском режиме поддерживаются 16 - 512 пользователей. Основные их особенности: широкий диапазон производительности в конкретных условиях применения, аппаратная реализация большинства системных функций ввода-вывода информации, простая реализация многопроцессорных и многомашинных систем, высокая скорость обработки прерываний, возможность работы с форматами данных различной длины.
К достоинствам мини-ЭВМ можно отнести: специфическую архитектуру с большой модульностью; лучшее, чем у мэйнфреймов, соотношение производительность / стоимость; повышенную точность вычислений.
Мини-ЭВМ ориентированы на использование в качестве управляющих вычислительных комплексов. Традиционная для подобных комплексов широкая номенклатура периферийных устройств дополняется блоками межпроцессорной связи, благодаря чему обеспечивается реализация вычислительных систем с изменяемой структурой.
Кроме этого, мини-ЭВМ успешно применяются для вычислений в многопользовательских вычислительных системах, в системах автоматизированного проектирования, в системах моделирования и искусственного интеллекта.
Родоначальником мини-ЭВМ можно считать компьютеры PDP-11 фирмы DEC (Digital Equipment Corporation) США. Они явились прообразом и наших отечественных мини-ЭВМ - Системы Малых ЭВМ (СМ ЭВМ): СМ1, 2,3,4,1400,1700 и др.
В настоящее время семейство мини-ЭВМ включает большое число моделей от VAX-11 до VAX 8000, супермкни - ЭВМ класса VAX 9000 и др. Модели VAX полностью перекрывают весь диапазон характеристик этого класса "компьютеров, а супермини-ЭВМ стирают грань с мэйнфреймами.
Методы обновления строк основной памяти
В табл. 4.1 приведены условия сохранения и обновления информации в ячейках кэш-памяти и основной памяти.
Таблица 4.1
Условия сохранения и обновления информации
| Режим работы | Наличие копии ячейки ОП в кэш-памяти | Информация | |||||
| В ячейке кэшпамяти | В ячейке основной памяти | ||||||
| Чтение | Копия есть Копии нет | Не изменяется Обновляется (создается копия) | Не изменяется Не изменяется | ||||
| Сквозная запись | Копия есть Копии нет | Обновляется Не изменяется | Обновляется Обновляется | ||||
| Обратная запись | Копия есть Копии нет | Обновляется Создается копия Обновляется | Не изменяется Не изменяется |
Если процессор намерен получить информацию из некоторой ячейки основной памяти, а копия содержимого этой ячейки уже имеется в кэш-памяти (первая строка табл. 4.1.), то вместо оригинала считывается копия. Информация в кэш-памяти и основной памяти не изменяется. Если копии нет, то производится обращение к основной памяти. Полученная информация пересылается в процессор и попутно запоминается в кэш-памяти. Чтение информации в отсутствии копии отражено во второй строке таблицы. Информация в основной памяти не изменяется.
При записи существует несколько методов обновления старой информации. Эти методы называются
стратегией обновления срок основной памяти. Если результат обновления строк кэш-памяти не возвращается в основную память, то содержимое основной памяти становится неадекватным вычислительному процессу. Чтобы избежать этого, предусмотрены методы обновления основной памяти, которые можно разделить на две большие группы: метод сквозной записи и метод обратной записи.
Методы повышения пропускной способности оперативной памяти
Основными методами увеличения полосы пропускания памяти являются: увеличение разрядности или «ширины» памяти, использование расслоения памяти, использование независимых банков памяти, обеспечение режима бесконфликтного обращения к банкам памяти, использование специальных режимов работы динамических микросхем памяти.
Методы управления памятью
Оперативная память (ОП) является важнейшим и наиболее дефицитны ресурсом в вычислительных машинах и системах, требующим тщательного эффективного управления. Проблема усложняется при переходе к мульт программным системам, так как в них ОП одновременно используют н сколько вычислительных процессов (программ).
Методы ускорения процессов обмена между ОП и ВЗУ
Эффективная скорость обмена между оперативным и внешним уровнями памяти в значительной степени определяется затратами на поиск секторов или блоков в накопителе ВЗУ. Для уменьшения влияния затрат времени поиска информации на скорость обмена используют традиционные методы буферизации и распараллеливания. Метод буферизации заключается в использовании так называемой дисковой кэш-памяти. Дисковый кэш уменьшает среднее время обращения к диску. Это достигается за счет того, что копии данных, находящихся в дисковой памяти, заносятся в полупроводниковую память. Когда необходимые данные оказываются находящимися в кэше, время обращения значительно сокращается. За счет исключения задержек, связанных с позиционированием головок, время обращения может быть уменьшено в 2 -10 раз.
Дисковый кэш может быть реализован программно или аппаратно. Программный дисковый кэш — это буферная область в ОП, предназначенная для хранения считываемой с диска информации. При поступлении запроса на считывание информации с диска вначале производится поиск запрашиваемой информации в программном кэше.
При наличии в кэше требуемой информации, она передается в процессор. Если она отсутствует, то осуществляется поиск информации на диске. Считанный с диска информационный блок заносится в буферную область ОП (программный дисковый кэш). Программа, управляющая дисковой кэшпамятью, осуществляет также слежение и за работой диска. Весьма хорошую производительность показывают программы Smart Drv, Ncache и Super PC-Kwik. Иногда для программного кэша используется дополнительная или расширенная память компьютера.
Аппаратный дисковый кэш — это встроенный в контроллер диска кэш-буфер с ассоциативным принципом адресации информационных блоков. По запросу на считывание информации вначале производится поиск запрашиваемого блока в кэше. Если блок находится в кэше, то он передается в ОП. В противном случае информационный блок считывается с диска и заносится в кэш для дальнейшего использования.
При поступлении запроса на запись информационный блок из ОП заносится вначале в дисковый кэш и лишь затем после выполнения соответствующих операций по поиску сектора — на диск, при этом обычно копия блока в дисковом кэше сохраняется. Запись информационного блока из ОП в кэш производится на место блока, копия которого сохранена на диске. Для управления процессами копирования вводятся специальные указатели, которые определяют, сохранена ли данная копия на диске, к какому информационному блоку обращение производилось ранее других и т.п. Копирование блока на диск производится по завершению операции поиска и не связано непосредственно с моментом поступления запроса.
Второй способ, позволяющий уменьшить снижение эффективной скорости обмена, вызванное операциями поиска на диске, связан с использованием нескольких накопителей на диске.
Все информационные блоки распределяются по нескольким накопителям, причем так, чтобы суммарная интенсивность запросов по всем накопителям была одинаковой, а запросы по возможности чередовались. Если известны интенсивности запросов к «каждому информационному блоку, то можно ранжировать эти блоки, а если при этом известны и логические связи между блоками, то связанные блоки с примерно одинаковыми интенсивностями запросов должны размещаться в разных накопителях. Это позволяет совместить операции обмена между ОП и одним из накопителей с операциями поиска очередного блока в других накопителях.
5. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ВВОДА-ВЫВОДА
Методы замещения строк кэш-памяти
Способ определения строки, удаляемой из кэш-памяти, называется стратегией замещения. Для замещения строк кэш-памяти существует несколько методов: метод замещения наиболее давнего по использованию объекта — строки, метод LRU (замещение наименее используемой информации);
метод FIFO (первым пришёл — первым вышел) и метод произвольного замещения.. В первом случае среди строк, являющихся объектами замещения, выбирается строка, к которой наиболее длительное время не было обращений. По методу FIFO среди всех строк, являющихся объектами замещения, выбирается та, которая самой первой была переслана в кэш-память. И наконец, по последнему методу строка выбирается произвольно. Реализация этих методов упрощается в указанной последовательности, но наибольшим эффектом обладает метод замещения наиболее давнего по использованию объекта (строки).
Для реализации этого метода необходимо манипулировать строками, которые являются объектами замещения, с помощью LRU-стека. При каждой загрузке в этот стек помещается строка, в результате чего при замене используется строка, хранящаяся в наиболее глубокой позиции стека, и эта строка удаляется из стека. При доступе к строке, которая уже содержится в LRU-стеке, эта строка удаляется из стека и заново загружается в него. Стек типа LRU устроен таким образом, что, чем дольше к строке не было доступа, тем в более глубокой позиции она располагается. Реализация стека типа LRU, позволяющего с высокой скоростью выполнять такую операцию, усложняется
по мере увеличения числа строк.
По методу частично ассоциативного распределения число строк в каждом стеке LRU равно числу строк в одной группе, и так как это число мало (порядка 2 - 4), то для каждой группы необходимо использовать свой стек. Если число групп сравнительно велико, то оснащение каждой из них стековым механизмом приводит к повышению стоимости.
Модульность.
Средства современной ВТ проектируются на основе модульного (или агрегатного) принципа. Он заключается в том, что отдельные устройства выполняются в виде конструктивно законченных модулей (агрегатов), которые могут сравнительно просто в нужных количествах и номенклатуре объединяться, образуя ЭВМ.
Присоединение нового устройства не должно вызывать в существующей части машины никаких изменений, кроме изменения кабельных соединений и некоторых корректировок программ.
На обломках империи
При удалении файла на UFS-разделе происходит следующее (события перечислены в порядке расположения соответствующих структур в разделе и могут не совпадать с порядком их возникновения):
q в суперблоке обновляется поле fs_time (время последнего доступа к разделу);
q в суперблоке обновляется структура fs_cstotal (кол-во свободных inod'ов и блоков данных в разделе);
q в группе цилиндров обновляются карты занятых inod'ов и блоков данных — inod'е и все блоки данных удаляемого файла помечаются как освобожденные;
q в indoe материнского каталога обновляются поля времени последнего доступа и модификации;
q в indoe материнского каталога обновляется поле времени последнего изменения inode;
q в inode удаляемого файла поля di_mode (IFMT, permissions), di_nlink (кол-во ссылок на файл) и di_size (размер файла) варварски обнуляются;
q в inode удаляемого файла поля di_db (массив указателей на 12 первых блоков файла) и di_ib (указатель на блок косвенной адресации) безжалостно затираются нулями;
q в inode удаляемого файла обновляются поля времени последней модификации и изменения inod'е, время последнего доступа при этом остается неизменным;
q в inode удаляемого файла обновляется поле di_spare. В исходных текстах оно помечено как "Reserved; currently unused", но просмотр дампа показывает, что это не так. Судя по всему здесь хранится нечто вроде последовательности обновления (update sequence), используемой для контроля целостности indoe, однако, это только предположение;
q в директории удаленного файла, размер предшествующей структуры direct увеличивается на d_reclen, в результате чего она как бы "поглощает" имя удаляемого файла, однако, его затирания не происходит, во всяком случае оно затирается не сразу, а только тогда, когда в этом возникнет реальная необходимость;
Назначение и структура центрального процессора
Центральный процессор
— основное устройство ЭВМ, которое наряду с обработкой данных выполняет функции управления системой: инициирование ввода-вывода, обработку системных событий, управление доступом к сновной памяти и т.п.
Организация центрального процессора (ЦП) определяется архитектурой и принципами работы ЭВМ (состав и форматы команд, представление чисел, способы адресации, общая организация машины и её основные элементы), а также технико-экономическими показателями.
Логическую структуру ЦП представляет ряд функциональных средств (рис. 3.1): средства обработки, средства управления системой и программой, локальная память, средства управления вводом-выводом и памятью, системные средства.
Средства обработки обеспечивают выполнение операций с фиксированной и плавающей точкой, операций с десятичными данными и полями переменной длины. Локальная память состоит из регистров общего назначения и с плавающей точкой, а также управляющих регистров. К средствам управления памятью относятся средства управления доступом к ОП и предвыборкой команд, буферная память, средства защиты памяти. Средства управления вводом-выводом обеспечивают приоритетный доступ программ через контроллеры (каналы) к периферийному оборудованию. К системным средствам относятся средства службы времени: часы астрономического времени, таймер, коммутатор и т.д.
Существует обязательный (стандартный) минимальный набор функциональных средств для каждого типа центрального процессора. Он включает в себя: регистры общего назначения, средства выполнения стандартного набора операций и средства управления вычислительным процессом. Конкретная реализация ЦП может различаться составом средств, способом их реализации, техническими параметрами.
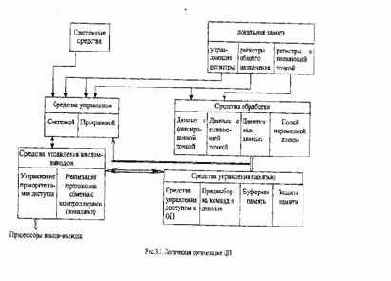
Структурно все функциональные средства разбиваются на следующие устройства (рис. 3.2): центральное устройство управления (ЦУУ), арифметико-логическое устройство (АЛУ), устройство управления памятью (УУП), сверхоперативное запоминающее устройство (СОЗУ), устройство предвыборки команд и данных (УП) и интерфейс магистрали (ИМ).
Центральное устройство управления включает дешифратор команд, блок управления и блок прерываний. Дешифратор команд дешифрирует команды, которые поступают из блока предварительной выборки (очереди команд). Блок управления (БУ) формирует последовательности управляющих сигналов, которые поступают на все блоки процессора, обеспечивающие выполнение очередной команды и переход к следующей. Блок прерываний проводит анализ запросов на прерывания, формирует сигнал прерывания работы процессора и код (вектор) запроса с наивысшим приоритетом.
Арифметико-логическое устройство выполняет все арифметические и логические операции набора команд ЭВМ. В состав устройства входят традиционные арифметико-логические блоки, специализированные аппаратные средства (блок ускоренного умножения), буферные и рабочие регистры, иногда собственный блок управления. Во многих случаях выполнение операций с плавающей точкой осуществляется в отдельном блоке (процессоре), который имеет собственные регистры данных, управления и работает параллельно с центральным процессором.
Сверхоперативное ЗУ (регистровый файл) содержит регистры общего назначения (РОН), в которых хранятся данные и адреса.
Устройство управления памятью (диспетчер памяти) предназначено для сопряжения центрального процессора и подсистемы ввода-вывода с оперативной памятью. Оно состоит из блока сегментации и блока страничной адресации, осуществляющих двухступенчатое формирование физического адреса ячейки памяти: сначала в пределах сегмента, а затем в пределах страницы. Наличие блоков сегментации и страничной адресации, их одновременное функционирование обеспечивают максимальную гибкость проектируемой системы. Сегментация полезна для организации в памяти локальных модулей и является инструментом программиста, в то время как страницы нужны системному программисту для эффективного использования физической памяти системы.
Устройство предвыборки команд и данных включает блок предвыборки команд и внутреннюю кэш-память (кэш-память первого уровня).
Первый осуществляет заполнение очереди команд, причем выборка из памяти производится в промежутках между магистральными циклами команд. Внутренняя кэш-память позволяет существенно повысить производительность процессора за счет буферизации в ней часто используемых команд и данных, сокращения числа обращений к оперативной памяти.
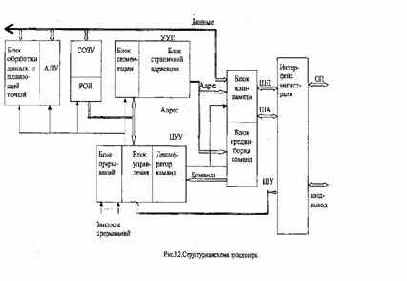
Интерфейс магистрали реализует протоколы обмена центрального процессора с памятью, контроллерами (каналами) ввода-вывода, другими активными устройствами системы. Обмен осуществляется с помощью шин данных, адреса и управления. Состав линий управления, тактовая сетка, магистральные циклы обмена существенно отличаются у различных типов процессоров.
В современных суперскалярных процессорах используется целый ряд параллельно функционирующих исполнительных устройств (от 2 до 6 устройств). В их состав могут входить:
- несколько целочисленных устройств;
- устройство плавающей точки;
- устройство выполнения переходов;
- устройство загрузки/записи.
Устройство выполнения переходов обрабатывает команды условных переходов. Если условия перехода доступны, то решение о направлений перехода принимается немедленно, в противном случае выполнение последующих команд продолжается по предположению (спекулятивно).
Пересылки данных между кэш-памятью данных, с одной стороны, и регистрами общего назначения и регистрами плавающей точки, с другой стороны, обрабатываются устройством загрузки/записи.
Назначение, классификация и организация АЛУ
Арифметико-логическое устройство (АЛУ) является одной из основных функциональных частей процессора, осуществляющей непосредственное
преобразование информации.
Все операции, выполняемые в АЛУ, можно разделить на следующие
группы:
- операции двоичной арифметики для чисел с фиксированной запятой;
- операции двоичной (или шестнадцатеричной) арифметики для чисел с плавающей запятой;
- операции десятичной арифметики (над числами, представленными в
двоично-десятичном коде);
- операции адресной арифметики (при модификации адресов команд);
- операции специальной арифметики;
- логические операции;
- операции над алфавитно-цифровыми полями.
Современные универсальные ЭВМ обычно реализуют операции всех приведенных выше групп, а специализированные ЭВМ часто не имеют аппаратуры для обработки чисел с плавающей запятой, десятичных чисел и операций над алфавитно-цифровыми полями. В этом случае эти операции выполняются специальными подпрограммами.
Основными являются арифметические и логические операции. К арифметическим операциям относятся сложение, вычитание, вычитание модулей ("короткие операции"), умножение и деление ("длинные операции"). Группу логических операций составляют операции дизъюнкции (логическое ИЛИ) и конъюнкции (логическое И) над многоразрядными двоичными словами, сравнение кодов на равенство. Специальные арифметические операции включают в себя нормализацию, арифметический сдвиг (сдвигаются только цифровые разряды, знаковый разряд остается на месте), логический сдвиг (знаковый разряд сдвигается вместе с цифровыми разрядами). Обширна группа операций редактирования алфавитно-цифровой информации.
Для выполнения перечисленных операций в АЛУ включаются следующие функциональные узлы:
- сумматор для выполнения суммирования и других действий над кодами операндов;
- регистры для хранения кодов операндов на время выполнения действий над ними;
- сдвигатели для сдвига кода на один или несколько разрядов вправо или влево;
- преобразователи для преобразования прямого кода числа в обратный или дополнительный код;
- комбинационные схемы для реализации логических операций, мультиплексирования данных, управляемой передачи информации, формирования признаков результата и т.д.
Регистры и в некоторых случаях сумматоры имеют цепи управления приемом, выдачей и сбросом кодов операндов. Логические операции, операции сдвига и преобразования кодов могут выполняться не только специальными устройствами, но и с помощью дополнительных связей регистров и сумматора. В зависимости от типов используемых для суммирования базовых элементов различают комбинационные и накапливающие сумматоры.
Назначение, классификация и организация ЦУУ
Центральное устройство управления — это комплекс средств автоматического управления процессом передачи и обработки информации. ЦУУ вырабатывает управляющие сигналы (УС), необходимые для выполнения всех операций, предусмотренных системой команд, а также координирует работу всех узлов и блоков ЭВМ. В связи с этим можно считать ЦУУ преобразователем первичной командной информации, представленной программой решения задачи, во вторичную командную информацию, представляемую
управляющими сигналами.
В общем случае ЦУУ формирует управляющие сигналы для реализации
следующих функций:
- выборки из памяти кода очередной команды;
- расшифровки кода операции и признаков выбранной команды;
- выборки операндов и выполнения машинной операции;
- обеспечения прерываний при выполнении команд;
- формирования адреса следующей команды;
- учета состояний других устройств машины;
- инициализации работы контроллеров (каналов) ввода-вывода;
- организации контроля работоспособности ЭВМ.
Для дальнейшего рассмотрения характеристик и способов организации ЦУУ введем ряд определений.
Элементарное машинное действие, выполняемое по одному УС, называют микрооперацией.
Набор микроопераций, выполняемых параллельно в одном машинном такте, называют микрокомандой Последовательность микрокоманд, обеспечивающих выполнение некоторой операции, предписанной командой, называют микропрограммой.
К основным характеристикам ЦУУ следует отнести:
- принцип формирования и развертывания временной последовательности УС;
- способ построения цикла работы ЦУУ и ЭВМ в целом;
- общая организация управления ЭВМ;
- способ синхронизации узлов и блоков ЭВМ. По принципу формирования и развертывания временной последовательности УС различают ЦУУ:
- аппаратного (схемного) типа, выполненным в виде управляющего автомата с жесткой логикой, в котором функции переходов и выходов реализуются набором логических элементов, а требуемое количество состояний автомата задается множеством запоминающих элементов;
- микропрограммного типа, в которых блок управления реализован как блок микропрограммного управления (БМУ).
Немного истории
UFS ведет свою историю от S5FS — самой первой файловой системы, написанной для UNIX в далеком 1974 году. S5 FS была крайне простой и неповоротливой (по некоторым данным 2%-5% от "сырой" производительности голого диска), но понятия суперблока (super-block), файловых записей (inodes) и блоков данных (blocks) в ней уже существовали.
В процессе работы над дистрибутивом 4.2 BSD, вышедшим в 1983 году, ординальная файловая система претерпела некоторые улучшения. Были добавлены длинные имена, символические ссылки и т. д. Так родилась UFS.
В 4.3 BSD, увидевшей свет уже в следующем году, улучшения носили намного более радикальный, если не сказать революционный, характер. Появились концепции фрагментов (fragments) и групп цилиндров (cylinder groups). Быстродействие файловой системны существенно возросло, что и определило ее название FFS – Fast File System (быстрая файловая система).
Все последующие версии линейки 4.x BSD прошли под знаменем FFS, но в 5.x BSD файловая система вновь изменилась. Для поддержки дисков большого объема ширину всех адресных полей пришлось удвоить: 32-битная нумерация фрагментов уступила место 64-битной. Были внесены и другие менее существенные усовершенствования.
Фактически мы имеем дело с тремя различными файловыми системами, не совместимыми друг с другом на уровне базовых структур данных, однако, некоторые источники склонны рассматривать FFS как надстройку над UFS. "UFS (and UFS2) define on-disk data layout. FFS sits on top of UFS (1 or 2) and provides directory structure information, and a variety of disk access optimizations" говорит "Little UFS2 FAQ" (UFS/UFS2 определяет раскладку данных на диске. FFS реализована поверх UFS 1 или 2 и отвечает за структуру директорий и некоторых дисковых оптимизаций). Действительно, если заглянуть в исходные тексты файловой системы, можно обнаружить два подкаталога — /ufs и /ffs. В /ffs находится определение суперблока (базовой структуры, отвечающей за раскладку данных), а в /ufs – определение inode и структуры директорий, что опровергает данный тезис, с точки зрения которого все должно быть с точностью до наоборот.
Чтобы не увязнуть в болоте терминологический тонкостей, под UFS мы будем понимать основную файловую систему 4.5 BSD, а под UFS2 – основную файловую систему 5.х BSD.
Непосредственная адресация операнда
При этом способе операнд располагается в адресном поле команды. Обращение к РП или ОП не производится. Таким образом, уменьшается время выполнения операции, сокращается объем памяти. Непосредственная адресация удобна для задания констант, длина которых меньше или равна длине адресного поля команды.
Обобщенная структура ЭВМ и пути её развития
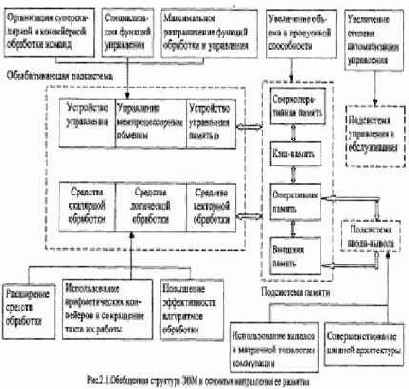
Развитие архитектуры неизбежно ведет к развитию структуры ЭВМ. Реализация принципов интеллектуализации, которые все больше определяют развитие архитектуры ЭВМ, возможна при совершенствовании структурной организации, обеспечивающей повышение эффективности вычислительного процесса и, как следствие этого, рост производительности ЭВМ. В конечном счете, условием и критерием развития структуры является рост производительности ЭВМ.
Основной тенденцией в развитии структуры ЭВМ является разделение функций системы и максимальная специализация подсистем для выполнения этих функций.
Обобщенная структура ЭВМ приведена на рис.2.1. Она состоит из следующих составных частей:
- обрабатывающей подсистемы;
- подсистемы памяти;
- подсистемы ввода-вывода;
- подсистемы управления и обслуживания.
Для каждой подсистемы выделены основные направления их развития.
Обобщенная структурная схема АЛУ
Обобщенная структурная схема АЛУ (рис. 3.18) включает:
- блок регистров для приема и размещения операндов и результатов;
- операционный блок, в котором осуществляется преобразование операндов в соответствии с реализуемыми алгоритмами;
- схемы контроля, обеспечивающие непрерывный оперативный контроль и диагностирование ошибок;
- блок управления (БУ), в котором после приема кода операции (КОП) из центрального устройства управления формируются управляющие сигналы (УС), координирующие взаимодействие всех узлов АЛУ между собой и с другими блоками процессора.
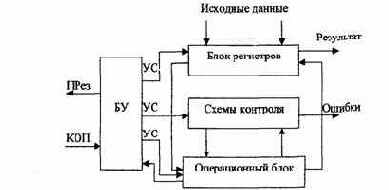
Рис.3.18. Обобщенная схема АЛУ
Блок регистров связан с ГОН центрального процессора и кэш-памятью данных.
Иногда АЛУ не содержит своего БР, в этом случае операционный блок непосредственно работает с регистрами общего назначения процессора. Для оперативного управления выполнением операции в ОБ на разных этапах анализируется преобразуемая информация и формируются сигналы признаков (флаги), которые используются в БУ для выработки и посылки в процессор сигнала признака результата (ПРез).
Для оценки АЛУ используются следующие характеристики: множество выполняемых операций, разрядность, время выполнения операций, надежностные и энергетические характеристики.
Методы повышения быстродействия АЛУ
Одним из эффективных и широко используемых методов повышения быстродействия АЛУ является реализация принципа локального параллелизма. Суть этого принципа заключается в распараллеливании во времени алгоритма выполнения отдельной команды на ряд независимых этапов и их реализации на различных операционных узлах (СМ, СДВ, ПК и т.д.) АЛУ.
Другой хорошо известный метод увеличения быстродействия - конвейерная обработка. Операционный блок разбивается на несколько частей -ступеней (уровней) конвейера. На каждой ступени выполняется определенная стадия операции. Совмещение стадий выполнения нескольких операций на различных ступенях конвейера приводит к тому, что реализация следующей операции начинается в нём до окончания предыдущей.
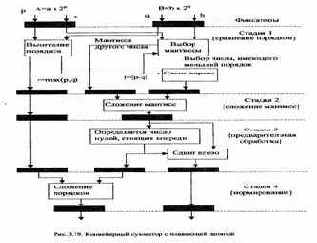
Это значительно увеличивает быстродействие операционного блока. Такую организацию ОБ стали называть арифметическим конвейером.
На рис. 3.19 показана схема конвейерного сумматора с плавающей запятой. Конвейер содержит четыре ступени. Результат выполнения каждой стадии операции фиксируется на регистрах. Когда конвейер полностью заполнен, то стадия 4 (нормирование) выполняется, например, для первой пары операндов, стадия 3 (предварительной обработки) - для второй пары операндов, стадия 2 (сложение мантисс) - для третьей пары, стадия 1 (сравнение порядков) - для четвертой пары операндов. В каждый последующий такт времени на выходе конвейера будет формироваться результат выполнения операции для каждой пары операндов.
Еще один способ сокращения длительности выполнения многотактных операций типа умножения является разработка и использование эффективных алгоритмов. Ускорение выполнения операции умножения достигается одновременным анализом нескольких разрядов множителя, использованием быстрых сумматоров с сохранением переносов и реализацией конвейерного метода обработки. Такой подход широко используется при создании функционально независимых блоков ускоренного умножения (умножителей).
Развитием системы команд универсальных ЭВМ, в том числе и персональных компьютеров, стало введение векторных операций
— операций над упорядоченными массивами данных (у супер ЭВМ векторные операции появились давно).
В связи с этим в структуре процессора наблюдается специализация устройств по типам операндов: скалярные и векторные. В составе процессора появляются регистровая память и средства обработки двух типов: скалярные и векторные.
К векторным средствам обработки относятся:
- один или несколько арифметических'конвейеров для обработки элементов векторов;
- векторные регистры для хранения векторной информации. Векторные средства обработки информации позволяют увеличить производительность ЭВМ в несколько раз.
-
Обрабатывающая подсистема
Развитие обрабатывающей подсистемы в большей степени, чем всех остальных подсистем, идет по пути разделения функций и повышения специализации составляющих ее устройств. Создаются специальные средства, которые осуществляют функции управления системой, освобождая от этих функций средства обработки. Такое распределение функций сокращает эффективное время обработки информации и повышает производительность ЭВМ. В то же время средства управления, как и средства обработки, становятся более специализированными. Устройство управления памятью реализует эффективные методы передачи данных между средствами обработки и подсистемой памяти. Меняются функции центрального устройства управления. С одной стороны, ряд функций передается в другие подсистемы (например, функции ввода-вывода), с другой - развиваются средства организации параллельной обработки нескольких команд (суперскалярная обработка) с одновременным повышением темпа исполнения последовательности команд. Для повышения темпа выполнения последовательности команд применяются методы конвейерной обработки наряду с совершенствованием алгоритмов диспетчеризации и исполнения команд. Бурно развивается управление межпроцессорным обменом как эффективное средство передачи информации между несколькими центральными процессорами, входящими в состав вычислительной системы или комплекса.
Операционные устройства (АЛУ) обрабатывающей подсистемы, кроме традиционных средств скалярной (суперскалярной) и логической обработки, все шире стали включать специальные средства векторной обработки. При этом время выполнения операций можно резко сократить как за счет использования арифметического конвейера (одного или нескольких), так и за счет сокращения такта работы конвейера. Возможности задач к распараллеливанию алгоритма счета снимают принципиальные ограничения к организации существенно параллельной обработки информации и использованию структур с глубокой конвейеризацией. В устройствах скалярной обработки все шире появляются специальные операционные блоки, оптимизированные на эффективное выполнение отдельных операций.
Обратная запись
По методу обратной записи, если адрес объектов, по которым есть запрос обновления, существует в кэш-памяти, то обновляется только кэшпамять, а основная память не обновляется. Если адреса объекта обновления нет в кэш-памяти, то в неё из основной памяти пересылается строка, содержащая этот адрес, после чего обновляется только кэш-память. По методу обратной записи в случае замены строк удаляемую строку необходимо также пересылать в основную память. У этого метода существуют две разновидности: метод SWB (простая обратная запись), по которому удаляемая строка возвращается в основную память, и метод FWB (флатовая обратная запись), по которому в основную память записывается только обновлённая строка кэш-памяти. В последнем случае каждая область строки в кэш-памяти снабжается однобитовым флагом, который показывает, было или нет обновление строки, хранящейся в кэш-памяти.
Метод FWB обладает достаточной эффективностью, однако более эффективным считается метод FPWB (флатовая регистровая обратная запись), в котором благодаря размещению буфера между кэш-памятью и основной памятью предотвращается конфликт между удалением и выборкой строк.
Таким образом, теоретически более предпочтительным алгоритмом записи для кэша является метод обратной записи. Кэш с обратной записью будет хранить новую информацию до тех пор, пока у него не появится необходимость избавиться от неё. Тем самым процессор может более оперативно управлять системой. В связи с тем, что кэш со сквозной записью сразу же передаёт вновь записанную информацию в память следующего уровня, кэш со сквозной записью может вызывать дополнительные потери в быстродействии по сравнению с кэшем с обратной записью. В случае кэша с обратной записью допускается выполнение длинных последовательностей быстрых операций записи из процессора, поскольку нет необходимости немедленно направлять эти данные в основную память.
Общая характеристика и классификация интерфейсов
Объединение отдельных подсистем (устройств, модулей) ЭВМ в единую систему основывается на многоуровневом принципе с унифицированным сопряжением между всеми уровнями — стандартным интерфейсом. Под стандартными интерфейсами понимают такие интерфейсы, которые приняты и рекомендованы в качестве обязательных отраслевыми или государственными стандартами, различными международными комиссиями, а также крупными зарубежными фирмами.
Интерфейсы характеризуются следующими параметрами:
1) пропускной способностью интерфейса — количеством информации которая может быть передана через интерфейс в единицу времени;
2) максимальной частотой передачи информационных сигналов через интерфейс;
3) информационной шириной интерфейса — числом бит или байт данных, передаваемых параллельно через интерфейс;
4) максимально допустимым расстоянием между соединяемыми устройствами;
5) динамическими параметрами интерфейса — временем передачи отдельного слова или блока данных с учетом продолжительности процедур подготовки и завершения передачи;
6) общим числом проводов (линий) в интерфейсе.
В настоящее время не существует однозначной классификации интерфейсов. Можно выделить следующие четыре классификационных признака интерфейсов:
- способ соединения компонентов системы (радиальный, магистральный, смешанный);
- способ передачи информации (параллельный, последовательный, параллельно-последовательный);
- принцип обмена информацией (асинхронный, синхронный);
- режим передачи информации (двусторонняя поочередная передача, односторонняя передача).
На рис. 5.2 представлены радиальный и магистральный интерфейсы, соединяющие центральный модуль (ЦМ) и другие модули (компоненты) системы (M1, ..., Mn ).
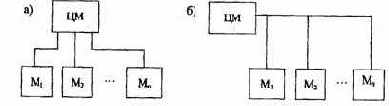
Рис.5.2. Радиальный (а) и магистральный (б) интерфейсы
Радиальный интерфейс позволяет всем модулям (m[, . . ., MJ работать независимо, но имеет максимальное количество шин. Магистральный интерфейс (общая шина) использует принцип разделения времени для связи между ЦМ и другими модулями.
Он сравнительно прост в реализации, но лимитирует скорость обмена.
Параллельные интерфейсы позволяют передавать одновременно опреде-
ленное количество бит или байт информации по многопроводной линии. Последовательные интерфейсы служат для последовательной передачи по двухпроводной линии.
В случае синхронного интерфейса моменты выдачи информации передающим устройством и приема ее в другом устройстве должны синхронизироваться, для этого используют специальную линию синхронизации. При асинхронном интерфейсе передача осуществляется по принципу "запрос-ответ". Каждый цикл передачи сопровождается последовательностью управляющих сигналов, которые вырабатываются передающим и приемным устройствами. Передающее устройство может осуществлять передачу данных (байта или нескольких байтов) только после подтверждения приемником своей готовности к приему данных.
Классификация интерфейсов по назначению отражает взаимосвязь с архитектурой реальных средств вычислительной техники. В соответствии с этим признаком в ЭВМ и вычислительных системах можно выделить несколько уровней сопряжении:
- машинные системные интерфейсы;
- локальные шины;
- интерфейсы периферийных устройств (малые интерфейсы);
- межмашинные интерфейсы.
Машинные (внутримашинные) системные интерфейсы предназначены для организации связей между составными компонентами ЭВМ на уровне обмена информацией с центральным процессором, ОП и контроллерами (адаптерами) ПУ.
Локальной шиной называется шина, электрически выходящая непосредственно на контакты микропроцессора, и предназначенная для увеличения быстродействия видеоадаптеров и контроллеров дисковых накопителей. Она обычно объединяет процессор, память, схемы буферизации для системной шины и ее контроллер, а также некоторые вспомогательные схемы. Типичными примерами локальных шин являются VLB и PCI.
Назначение интерфейсов периферийных устройств (малых интерфейсов) состоит в выполнении функций сопряжения контроллера (адаптера) с конкретным механизмом ПУ.
Межмашинные интерфейсы используются в вычислительных системах и сетях.
С целью снижения стоимости некоторые компьютеры имеют единственную шину (общая шина) для памяти и устройств ввода-вывода. Персональные компьютеры первых поколений, как правило, строились на основе одной системной шины в стандартах ISA, EISA или МСА. Необходимость сохранения баланса производительности по мере роста быстродействия микропроцессоров привела к многоуровневой организации шин на основе использования нескольких системных и локальных шин. В современных компьютерах шины интерфейсов делят на шины, обеспечивающие организацию связи процессора с памятью, и шины ввода-вывода. Шины процессор-память сравни тельно короткие, обычно высокоскоростные и соответствуют организаций подсистемы памяти для обеспечения максимальной пропускной способности канала память-процессор. Шины ввода-вывода могут иметь большую протя- женность, поддерживать подсоединение многих типов устройств и обычно следуют одному из шинных стандартов. Обычно количество и типы уст- ройств ввода-вывода в вычислительных системах не фиксируются, что дает возможность пользователю самому подобрать необходимую конфигурацию Шина ввода-вывода компьютера рассматривается как шина расширения; обеспечивающая постепенное наращивание устройств ввода-вывода. Поэтому стандарты играют огромную роль, позволяя разработчикам компьютеров и устройств ввода-вывода работать независимо.
Общие положения
Оперативная (основная) память представляет собой следующий уровень иерархии памяти. Оперативная память удовлетворяет запросы кэш-памяти и служит в качестве интерфейса ввода/вывода, поскольку является местом назначения для ввода и источником для вывода. Для оценки производительности (быстродействия) основной памяти используются два основных параметра: задержка и полоса пропускания. Традиционно задержка оперативной памяти имеет отношение к кэш-памяти, а полоса пропускания или пропускная способность относится к вводу/выводу. В связи с ростом популярности кэшпамяти второго уровня и увеличением размеров блоков у такой кэш-памяти полоса пропускания основной памяти становится важной также и для кэшпамяти.
Задержка памяти традиционно оценивается двумя параметрами: временем доступа и длительностью цикла памяти.
Оперативная память современных компьютеров реализуется на микросхемах статических и динамических запоминающих устройств с произвольной выборкой. Микросхемы статических ЗУ (СЗУ) имеют меньшее время доступа и не требуют циклов регенерации (восстановления) информации. Микросхемы динамических ЗУ (ДЗУ) характеризуются большей емкостью и меньшей стоимостью, но требуют схем регенерации и имеют значительно большее время доступа. У статических ЗУ время доступа совпадает с длительностью цикла.
Для микросхем, использующих примерно одну и ту же технологию, емкость ДЗУ по грубым оценкам в 4 — 8 раз превышает емкость СЗУ, но последние имеют в 8 — 16 раз меньшую длительность цикла и большую стоимость. По этим причинам в основной памяти практически любого компьютера, проданного после 1975 года, использовались полупроводниковые микросхемы ДЗУ (для построения кэш-памяти при этом применялись СЗУ). Естественно, были и исключения, например, в оперативной памяти суперкомпьютеров компании Cray Research использовались микросхемы СЗУ.
Для обеспечения сбалансированности системы с ростом скорости процессоров должна линейно расти и емкость ОП. В последнее время емкость микросхем динамической памяти учетверялась каждые три года, увеличиваясь примерно на 60 % в год. К сожалению скорость этих схем за этот же период росла гораздо меньшими темпами (примерно на 7 % в год). В то же время производительность процессоров, начиная с 1987 года, практически увеличивалась на 50 % в год.
Таким образом, согласование производительности современных процессоров со скоростью ОП вычислительных машин и систем остается на сегодняшний день одной из важнейших проблем. Методы повышения производительности за счет увеличения размеров кэш-памяти и введения многоуровневой организации кэш-памяти могут оказаться недостаточно эффективными с точки зрения стоимости систем. Поэтому важным направлением современных разработок являются методы повышения пропускной способности памяти за счет ее организации, включая специальные методы организации ДЗУ.
Общие сведения
В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти — кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти.
За единицу информации при обмене между основной памятью и кэшпамятью принята строка, причём под строкой понимается набор слов, выбираемый из оперативной памяти при одном к ней обращении. Хранимая в оперативной памяти информация представляется, таким образом, совокупностью строк с последовательными адресами. В любой момент времени строки в кэш-памяти представляют собой копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как вОП.
Построение кэш-памяти может осуществляться по различным принципам, которые будут рассмотрены ниже. При использовании принципа ассоциативной памяти каждая строка в кэш-памяти связана с так называемым адресным тегом. Адресный тег — это расширенный адрес, который объединяет адреса всех слов, принадлежащих данной строке. Он указывает, какую строку в ОП представляет данная строка в кэш-памяти.
Типовая структура кэш-памяти
Рассмотрим типовую структуру кэш-памяти (рис. 4.4), включающую основные блоки, которые обеспечивают её взаимодействие с ОП и центральным процессором.
Строки, составленные из информационных слов, и связанные с ними адресные теги хранятся в накопителе, который является основой кэш-памяти. Адрес требуемого слова, поступающий от центрального процессора (ЦП), вводится в блок обработки адресов, в котором реализуются принятые в данной кэш-памяти принципы использования адресов при организации их сравнения с адресными тегами. Само сравнение производится в блоке сравнения адресов (БСА), который конструктивно совмещается с накопителем, если кэш-память строится по схеме ассоциативной памяти.
Назначение БСА состоит в выявлении попадания или промаха при обработке запросов от центрального процессора. Если имеет место кэш-попадание (т.е. искомое слово хранится в кэш-памяти, о чём свидетельствует совпадение кодов адреса, поступающего от центрального процессора, и одного из адресов некоторого адресного тега), то соответствующая строка из кэш-памяти переписывается в регистр строк. С помощью селектора-демультиплексора из неё выделяется искомое слово, которое и направляется в центральный процессор. В случае промаха с помощью блока формирования запросов осуществляется инициализация выборки из ОП необходимой строки. Адресация ОП при этом производится в соответствии с информацией, поступившей от центрального процессора. Выбираемая из памяти строка вместе со своим адресным тегом помещается в накопитель и регистр строк, а затем искомое слово передается в центральный процессор.
Для высвобождения места в кэш-памяти с целью записи выбираемой из ОП строки одна из строк удаляется. Определение удаляемой строки производится посредством блока замены строк, в котором хранится информация, необходимая для реализации принятой стратегии обновления находящихся в накопителе строк.
Общий формат команд
Обобщенный вид формата команды показан на рис. 2.10. Он допускает наличие следующих полей: кода операции (1 или 2 байта); байтов адресации (О, 1 или 2 байта); байтов смещения (0, 1,2 или 4 байта); байтов непосредственных данных — операндов (0,1,2 или 4 байта).
| КОП | Байты адресации | Смещение | Операнд | ||||||
| MODR/M | SIB | ||||||||
| 1 или 2 байта | 0 или 1 байт | 0 или 1 байт | 0,1,2 или 4 байта | 0,1,2 или 4 байта |
Рис. 2.10. Общий формат команд
Команды содержат от 1 до 11 байт. Проведенные оценки показывают, что в среднем длина команды составляет 4 — 5 байт.
. Рассмотрим назначение основных полей кода команды (рис.2.10). Код операции (КОП) определяет тип выполняемой операции, а также в некоторых командах в первом байте может содержаться бит W, задающий разрядность операндов:
W=0 — операция с байтами;
W = 1 — операция со словами (16 или 32 разряда).
В ряде команд первый байт КОП содержит поля reg или sreg, определяющие адрес используемых регистров. Трехбитовое поле reg задает выбираемый регистр в соответствии с разрядностью обрабатываемых операндов. Поле sreg (двух или трехбитовое) определяет адрес сегментных регистров.
Байт адресации MOD R/M содержит три поля (рис. 2.11). Поля: MOD и R/M задают адрес одного из операндов, который может храниться в регистре или ячейке памяти. Кодировка этих полей определяет выбираемый способ адресации.

Рис. 2.11. Форматы байтов MOD R/M и SIB
В одноадресных командах поле REG/КОП содержит дополнительные биты кода операции. В двухадресных командах поле REG содержит адрес регистра, в котором хранится второй из операндов. Тип команды (одно- или двухадресная) определяется первым битом КОП. Поле MOD указывает, какой разрядности смещение используется для формирования адреса. Если оно имеет значение 00 (при некоторых значениях R/M) или 01, 10, то используется 8-, 16- или 32-разрядное смещение. Это смещение задается соответствующими байтами в коде команды, которые располагаются после байтов адресации.
Для реализации некоторых способов относительной адресации используется байт SIB. Он содержит 3-битовые поля INDEX и BASE, определяющие выбор регистров, используемых в качестве индексного и базового регистров, и поле SS, задающее масштабный коэффициент для модификации значения индекса.
При выполнении операций с непосредственной адресацией один из операндов задается в последних байтах команды (рис. 2.10). В этом случае КОП ряда команд содержит бит S, определяющий способ использования непосредственно задаваемых данных.
Однопроцессорные архитектуры ЭВМ
Исторически первыми появились однопроцессорные архитектуры. Классическим примером однопроцессорной архитектуры является архитектура фон Неймана со строго последовательным выполнением команд: процессор по очереди выбирает команды программы и также по очереди обрабатывает данные. По мере развития вычислительной техники архитектура фон Неймана обогатилась сначала конвейером команд, а затем многофункциональной обработкой и по классификации М.Флина получила обобщенное название SISD (Single Instruction Single Data — один поток команд, один поток данных). Основная масса современных ЭВМ функционирует в соответствии с принципом фон Неймана и имеет архитектуру класса SISD.
Данная архитектура породила CISC, MSC и архитектуру с суперскалярной обработкой (рис. 1.1).
Компьютеры с CISC (Complex Instruction Set Computer) архитектурой имеют комплексную (полную) систему команд, под управлением которой выполняются всевозможные операции типа «память-память», «память-регистр», «регистр — память», «регистр — регистр».
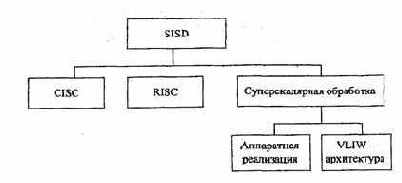
Рис. 1.1. Классификация архитектуры SISD
Данная архитектура характеризуется:
- большим числом команд (более 200);
- переменной длиной команд (от 1 до 11 байт);
- значительным числом способов адресации и форматов команд;
- сложностью команд и многотактностыо их выполнения;
- наличием микропрограммного управления, что снижает быстродействие и усложняет процессор.
Обмен с памятью в процессе выполнения команды делает практически невозможной глубокую конвейеризацию арифметики, т.е. ограничивается тактовая частота процессора, а значит, и его производительность.
Большинство современных компьютеров типа IBM PC относятся к CISC архитектуре, например, компьютеры с микропроцессорами (МП) 8080, 80486, 80586 (товарная марка Pentium).
Компьютеры с RISC (Reduced Instruction Set Computer) архитектурой содержат набор простых, часто употребляемых в программах команд. Основными являются операции типа «регистр — регистр».
Данная архитектура характеризуется:
- сокращенным числом команд;
- тем, что большинство команд выполняется за один машинный такт;
- постоянной длиной команд;
- небольшим количеством способов адресации и форматов команд;
- тем, что для простых команд нет необходимости в использовании микропрограммного управления;
-
большим числом регистров внутренней памяти процессора.
Компьютеры с RISC-архитектурой «обязаны» иметь преимущество в производительности по сравнению с CISC компьютерами, за которое приходится расплачиваться наличием в программах дополнительных команд обмена регистров процессора с оперативной памятью.
В настоящее время практически все ведущие производители компьютеров прилагают большие усилия для производства RISC-процессоров (см. табл. 1.1).
Таблица 1.1
Название фирм и разработанных ими RISC-процессоров
|
Фирма |
RISC-процессор |
|
Sun Microsystems |
Ultra SPARC II |
|
Ultra SPARC III |
|
|
DEC |
Alpha 21164 |
|
HP |
PA-7150, PA-8000 |
|
SGI |
MIPS R-10000 |
|
IBM |
PPC-601, PPC-604 |
|
Motorola |
88000 |
Смысл этого термина заключается в том, что в аппаратуру процессора закладываются средства, позволяющие одновременно выполнять две или более скалярные операции, т.е. команды обработки пары чисел. Суперскалярная архитектура базируется на многофункциональном параллелизме и позволяет увеличить производительность компьютера пропорционально числу одновременно выполняемых операций. Способы реализации суперскалярной обработки могут быть разными. Первый способ применяется как в CISC, так и в RISC - процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение.
В табл. 1.2 для различных типов процессоров приведено максимальное и среднее число команд, выполняемых в одном машинном цикле.
Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
Таблица 1.2
Максимальное и среднее число команд, выполняемых в одном машинном цикле
|
Процессор |
Тактовая частота, Мгц |
Число транзисторов, млн. |
Максимальное число команд на цикл |
Среднее число команд на цикл |
|
Digital Alpha |
500 |
9,3 |
4 |
1,0 |
|
Power PC 620 |
200 |
6,9 |
4 |
1,8 |
|
Power PC 604с |
225 |
5,1 |
4 |
1,5 |
|
Ultra SPARC |
250 |
3,8 |
4 |
1,36 |
|
HP PA-8000 |
180 |
3,9 |
4 |
2,4 |
|
HPPA-7300LC |
160 |
9,2 |
2 |
1,35 |
|
Mips R10000 |
200 |
5,9 |
4 |
1,78 |
|
Mips R 5000 |
180 |
3,6 |
2 |
0,89 |
|
i486 |
25 |
1,2 |
- |
0,45 |
|
Pentium Pro |
200 |
5,5 |
3 |
1,76 |
реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора.
Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет - это четыре разнотипные операции:
(сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими.
Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Архитектуры класса SISD охватывают те уровни программного параллелизма, которые связаны с одинарным потоком данных. Они реализуются многофункциональной обработкой и конвейером команд.
Параллелизм циклов и итераций тесно связан с понятием множественности потоков данных и реализуется векторной обработкой. В классификации компьютерных архитектур М. Флина выделена специальная группа однопроцессорных систем с параллельной обработкой потоков данных - SIMD (Single Instruction Multiple Date, один поток команд - множество потоков данных).
Возможны два способа построения компьютеров этого класса. Это матричная структура и векторно-конвейерная обработка. Суть матричной структуры заключается в том, что имеется множество процессорных элементов, исполняющих одну и ту же команду над различными элементами вектора, объединенных коммутатором. Основная проблема заключается в программировании обмена данными между процессорными элементами через коммутатор.
В отличие от матричной, векторно-конвейерная структура компьютера содержит конвейер операций, на котором обрабатываются параллельно элементы векторов и полученные результаты последовательно записываются в единую память. При этом отпадает необходимость в коммутаторе процессорных элементов, служащем камнем преткновения в матричных компьютерах.
Примером векторных супер-ЭВМ с матричной структурой является знаменитая в свое время система ILLIAC-IV.
Векторно-конвейерную структуру имеют однопроцессорные супер-ЭВМ серии VP фирмы Fujitsu; серии S компании Hitachi; C90, М90, Т90 фирмы Cray Research; Cray-3, Cray-4 фирмы Cray Computer и т.д.
Общим для всех векторных суперкомпьютеров является наличие в системе команд векторных операций, допускающих работу с векторами определенной длины, допустим, 64 элемента по 8 байт. В таких компьютерах операции с векторами обычно выполняются над векторными регистрами.
Еще одним примером SIMD-архитектуры является технология ММХ, которая существенно улучшила архитектуру микропроцессоров фирмы Intel. Она разработана для ускорения выполнения мультимедийных и коммуникационных программ. В ММХ используются 4 новых типа данных и 57 новых инструкций. Команды ММХ выполняют одну и ту же функцию с различными частями данных, например, 8 байт графических данных передаются в процессор как одно упакованное 64-х разрядное число и обрабатываются одной командой. ММХ - команды используют восемь 64-разрядных регистров, «физически» размещенных в мантиссах регистров с плавающей запятой, и используются в том же режиме процессора, что и команды с плавающей запятой.
Все программное обеспечение, созданное для ранее выпущенных процессоров, без всяких изменений может выполняться на процессорах с технологией ММХ.
Организация виртуальной памяти
Уже достаточно давно пользователи столкнулись с проблемой размещения в основной памяти программ, размер которых превышал имеющуюся в наличии свободную память. Решением этой проблемы было использование внешней памяти (дискового пространства). Программы разбивались на части (оверлеи), которые хранились в ОП и на диске. Перемещение их между основной памятью и диском осуществлялось средствами ОС. Однако разбиением программы на части должен был заниматься программист. Это приводило к увеличению трудоемкости программирования и к неэффективному использованию памяти.
Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием виртуальная память. Виртуальным называется такой ресурс, который для пользователя (пользовательской программы) представляется обладающим свойствами, которыми он в действительности не обладает. Так, например, пользователю может быть предоставлена виртуальная оперативная память, размер которой превосходит всю имеющуюся в системе реальную ОП. Пользователь пишет программы так, как будто в его распоряжении имеется однородная (одноуровневая) оперативная память большого объема, но в действительности все данные, используемые программой, хранятся на нескольких разнородных запоминающих устройствах, обычно в ОП и на дисках, и при необходимости частями перемещаются между ними.
Таким образом,
виртуальная память — это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся ОП. Для этого виртуальная память (ВП)
решает следующие задачи:
- размещает данные в запоминающих устройствах разного типа, например, часть программы в ОП, а часть на диске;
- перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы
с диска в ОП;
- преобразует виртуальные адреса в физические.
Все эти действия выполняются автоматически, без участия программиста, т.е. механизм ВП является прозрачным по отношению к пользователю.
Наиболее распространенными реализациями виртуальной памяти являются страничное, сегментное и странично-сегментное распределение памяти (рис. 4.10), атаюке свопинг.
Организация внутренней памяти процессора
Регистровая структура процессора была рассмотрена в разделе 3. Обращает на себя внимание ставший стандартным в современной архитектуре ЭВМ прием организации регистров общего назначения в виде сверхоперативного ЗУ с прямой адресацией
(короткие адреса регистров размещаются в команде). В машинах с коротким словом, вынуждающим прибегать к одноадресным командам, один из общих регистров выделяется в качестве аккумулятора — регистра, в котором находится один из операндов и в который помещается результат операции. Регистр аккумулятор в явном виде в команде не адресуется, используется подразумеваемая адресация. В этом случае СОЗУ с прямой адресацией (рис. 4.2, а) состоит из совокупности регистров Р[ 0" ],..., Р[ М ], связанных с входной Х и выходной Z шинами, по которым передаются n — разрядные слова. Адрес регистра, к которому производится обращение с целью записи или чтения (управляющий сигнал ЗП/ЧТ) информации, поступает по шине А. Дешифратор адреса ДША формирует управляющие сигналы 0, 1,..., М, подключающие регистр с заданным адресом к шинам СОЗУ.
При использовании двухадресных команд типа «регистр-регистр», в которых указываются адреса двух операндов, расположенных в регистрах, и результат операции помещается по одному из этих адресов, данная организация СОЗУ становится неэффективной. Это связано с тем, что за один машинный такт может быть выбрано содержимое только одного регистра. Для реализации таких команд за один такт СОЗУ строится по схеме, приведенной на
рис. 4.2, б.
СОЗУ состоит из совокупности регистров, связанных с входной шиной X и двумя выходными шинами Y, Z. Адреса регистров, к которым производится обращение с целью чтения информации, поступают по шинам А и В. Адрес регистра для записи информации поступает по входу В. Дешифраторы адресов ДША и ДШВ формируют управляющие сигналы 0, 1,... , М, подключающие два регистра к выходным шинам при чтении и один регистр к входной шине при записи.
Основные функциональные регистры:
- регистры общего назначения (РОНы);
- указатель команд;
- регистр флагов;
- регистры сегментов.
Содержимое этих регистров определяется текущей задачей, т.е. в эти регистры автоматически загружается новое значение при переключении задач.
Относительная
определяемая для оцениваемой ЭВМ относительно базовой в виде индекса производительности.
Для каждого вида производительности применяются следующие традиционные методы их определения.
Пиковая производительность (быстродействие) определяется средним числом команд типа «регистр-регистр», выполняемых в одну секунду без учета их статистического веса в выбранном классе задач.
Номинальная производительность (быстродействие) определяется средним числом команд, выполняемых подсистемой «процессор-память» с учетом их статистического веса в выбранном классе задач. Она рассчитывается, как правило, по формулам и специальным методикам, предложенным для процессоров определенных архитектур, и измеряется с помощью разработанных для них измерительных программ, реализующих соответствующую эталонную нагрузку.
Для данных типов производительностей используются следующие единицы измерения:
MIPS (Mega Instruction Per Second) - миллион целочисленных операций в секунду;
MFLOPS (Mega Floating Operations Per Second) - миллион операций с числами с плавающей запятой в секунду;
GFLOPS (Giga Floating Operations Per Second) - миллиард операций не с числами с плавающей загоггой в секунду;
TFLOPS (Tera Floating Operations Per Second) - триллион операций на числами с плавающей запятой в секунду.
Системная производительность измеряется с помощью синтезированны типовых (тестовых) оценочных программ, реализованных на унифицирова! ных языках высокого уровня. Унифицированные тестовые программы и< пользуют типичные алгоритмические действия, характерные для реальны применений, и штатные компиляторы ЭВМ. Они рассчитаны на использовг ние базовых технических средств и позволяют измерять производитеяьност для расширенных конфигураций технических средств. Результаты оценк системной производительности ЭВМ конкретной архитектуры приводятс относительно базового образца, в качестве которого используются ЭВМ, т ляющиеся промышленными стандартами систем ЭВМ различной архитекту ры.
Результата оформляются в виде сравнительных таблиц, двумерных гра фиков и трехмерных изображений.
Существует большое количество различных тестовых программ, напри мер:
SPEC mt 95 и SPEC fp 95 - для интенсивной проверки процессоров п< целочисленным операциям и вычислениям с плавающей запятой (табл. 1.3);
Graphstone - набор из 125 подпрограмм, проверяющих компьютер на'1;
различных типах графических элементов;
Khomevstone - методика испытаний с использованием 21 теста, интен сивно нагружающих центральный процессор, процессор с плавающей зал» той и дисковую подсистему.
Эксплуатационная производительность оценивается на основании ис пользования данных о реальной рабочей нагрузке и функционировании ЭВ^ при выполнении типовых производственных нагрузок в основных областя? применения. Расчеты делаются главным образом на уровне типовых пакете! прикладных программ текстообработки, систем управления базами данных пакетов автоматизации проектирования, графических пакетов и т.д.
Очень часто при сравнении компьютеров пользуются отношением производительности к стоимости.
К другим технико-эксплуатационным характеристикам ЭВМ относятся:
- разрядность обрабатываемых слов и кодовых шин интерфейса;
- типы системного и локальных интерфейсов;
- тип и емкость оперативной памяти;
- тип и емкость накопителя на жестком магнитном диске;
- тип и емкость накопителя на гибком магнитном диске;
- тип и емкость кэш-памяти;
- тип видеоадаптера и видеомонитора;
- наличие средств для работы в компьютерной сети;
- наличие и тип программного обеспечения;
- надежность ЭВМ;
- стоимость;
-
габариты и масса.
-
Таблица 1.3 Результаты тестирования процессоров
|
Фирма |
Процессор |
Результаты тестирования |
|
|
SPECint95 |
SPECfp95 |
||
|
Digital Eguipment |
Alpha 21164/500 Мгц |
15,00 |
20,4 |
|
HP |
PA-8000/180 Мгц |
11,8 |
18,7 |
|
Intel |
Pentium Pro/200 Мгц |
8,58 |
6,68 |
|
Motorola |
Power PC604e/200 Мгц |
8,00 |
6,31 |
|
Solicon Graphics |
Mips R10000/200 Мгц |
8,88 |
13,8 |
|
Sun Microsystems |
Ultra SPARC2/200 Мгц |
7,72 |
13,8 |
Относительная адресация ячейки ОП Базирование способом суммирования
В команде адресный код Ак разделяется на две составляющие: Aб - адрес регистра в регистровой памяти , в котором хранится база Б (базовый адрес); С - код смещения относительно базового адреса (рис. 2.7).
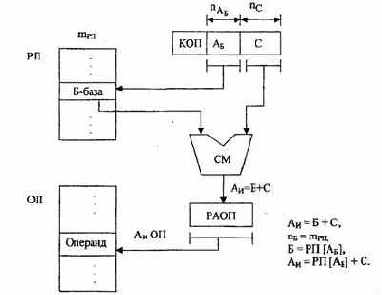
Рис. 2.7. Схема формирования относительного адреса способом суммирования кодов базы и смещения: СМ - сумматор; РАОП - регистр адреса ОП;
Б - база (базовый адрес); С - смещение; Aб- адрес регистра базы;
nб - длина кода базы; nc - длина поля смешения
Для определения максимальной емкости ОП, адресуемой с помощью базирования, способом суммирования, определим длину кода исполнительного адреса
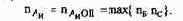
Так как nб
= mрп и обычно больше, чем Пс, то справедливо следующее выражение:
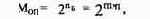
т. е. максимальная адресуемая емкость ОП определяется разрядностью РП. Длина NаБ
поля кода команды, задающего адрес регистра базы Aб, определяется через емкость РП Мрп, по формуле

Таким образом, можно определить количество NаБ
двоичных разрядов в адресном поле команды, необходимое для формирования Аи с размещением базы в РП:

Приведенные выражения позволяют определить числовые значения параметров относительной адресации (базирование способов суммирования). Для того, чтобы увеличить Моп, необходимо выполнить условие:
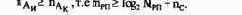
С помощью метода относительной адресации удается получить так называемый перемещаемый программный модуль, который одинаково выполняется процессором независимо от адресов, в которых он расположен. Начальный адрес программного модуля (база) загружается, при входе в модуль, в базовый регистр. Все остальные адреса программного модуля формируются через смещение относительно начального адреса (базы) модуля. Таким образом, одна и та же программа может работать с данными, расположенными в любой области памяти, без перемещения данных и без изменения текста программы только за счет изменения содержания всего одного базового регистра. Однако время выполнения каждой операции при этом возрастает.
Относительная адресация с совмещением составляющих Ад
Для увеличения емкости адресной ОП (Моп) без увеличения длины адресного поля команды Пд можно использовать для формирования исполнительного адреса совмещение (конкатенацию) кодов базы и смещения (рис. 2.8).
При совмещении кодов базы и смещения
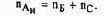
Таким образом,
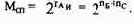
Следует отметить, что емкость ОП (Моп) может быть увеличена в 2nс раз за счет использования способа совмещения. Однако в данном случае начальные адреса массивов не могут быть реализованы произвольно, а должны иметь в младших разрядах nc
нулей.
Рис. 2.8. Схема формирования относительного адреса способом совмещения кодов базы и смещения
Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов так, чтобы вся свободная память образовывала единую свободную область (рис. 4.13). В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей.
Рис.4.13. Распределение памяти перемещаемыми разделами
Эта процедура называется «сжатием». Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором — реже выполняется процедура сжатия. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Пиковая
(предельная) — это производительность процессора без учета времени обращения к оперативной памяти (ОП) за операндами;
- номинальная — производительность процессора с ОП;
По общей организации
управление может быть центральным и смешанным. В первом случае в БУ вырабатываются все УС микроопераций для всех команд, выполняемых процессором ЭВМ. Во втором случае, кроме БУ центрального устройства управления, операционные и другие устройства процессора имеют собственные блоки местного управления. В последнем случае БУ вырабатывает сигналы для запуска в работу блоков местного управления.
По способу синхронизации работы ЭВМ
в зависимости от числа тактов в цикле выполнения команды, различают ЦУУ с постоянным или переменным числом тактов. В микропрограмме рабочего цикла выделяют общую и специальную части. К общей относятся микрокоманды, исполняемые в цикле любой команды: выборки команды, анализа запросов на прерывание работы процессора. Они выполняются за постоянное число тактов. К специальной части относятся микрокоманды, по которым вырабатываются УС в зависимости от содержания операционной части исполняемой команды. В этом случае количество тактов будет переменным для различных команд. В современных ЭВМ с различной структурой используемых команд число тактов в рабочем цикле зависит от формата выбираемой команды, структуры ее адресной части и длины операндов.
По принципу организации циклов различают ЦУУ:
- синхронного типа, в которых время цикла может быть постоянным
или переменным;
- асинхронного типа, в которых продолжительность цикла определяется фактическими затратами времени на выполнение каждой операции. В этом случае необходимо вырабатывать сигналы об окончании операции;
- смешанного типа, где частично реализуются оба предыдущих принципа организации циклов.
По способу построения рабочего цикла различают ЦУУ:
- с прямым циклом, когда на первом этапе производится выборка из памяти команды, а затем следуют этапы выполнения машинной операции;
- с обращенным циклом, когда сначала выдаются УС микроопераций для выполнения машинной операции по коду команды, поступившей в ЦУУ на предыдущем цикле (предвыборка команд), а затем из памяти выбирается код команды, которая будет исполняться в следующем цикле;
- с совмещением во времени циклов выполнения нескольких команд (конвейером команд).
Подсистема памяти
Подсистема памяти современных компьютеров имеет иерархическую структуру, состоящую из нескольких уровней:
- сверхоперативный уровень (локальная память процессора, кэшпамять первого и второго уровня);
- оперативный уровень (оперативная память, дисковый кэш);
- внешний уровень (внешние ЗУ на дисках, лентах и т.д.). Эффективными методами повышения производительности ЭВМ являются увеличение количества регистров общего назначения процессора, использование многоуровневой кэш-памяти, увеличение объема и пропускной способности оперативной памяти, буферизация передачи информации между ОП и внешней памятью. Увеличение пропускной способности оперативной памяти достигается за счет увеличения их расслоения и секционирования.
Подсистема управления и обслуживания
Подсистема управления и обслуживания — это совокупность аппаратно-программных средств, предназначенных для обеспечения максимальной производительности, заданной надежности, ремонтопригодности, удобства настройки и эксплуатации. Она обеспечивает проблемную ориентацию и заданное время наработки на отказ, подготовку и накопление статистических сведений о загрузке и прохождении вычислительного процесса, выполняет функции "интеллектуального" интерфейса с различными категориями обслуживающего персонала, осуществляет инициализацию, тестирование и отладку. Подсистема управления и обслуживания позволяет поднять на качественно новый уровень эксплуатацию современных ЭВМ.
При разработке структуры ЭВМ все подсистемы должны быть сбалансированы между собой. Только оптимальное согласование быстродействия обрабатывающей подсистемы с объемами и скоростью передачи информации подсистемы памяти, с пропускной способностью подсистемы ввода-вывода позволяет добиться максимальной эффективности использования ЭВМ.
Важнейшими факторами, определяющими функциональную и структурную организацию ЭВМ, являются выбор системы и форматов команд, типов данных и способов адресации.