Подсистема ввода-вывода
В состав подсистемы ввода-вывода входит набор специализированных устройств, между которыми распределены функции ввода-вывода, что позволяет свести к минимуму потери производительности системы при операциях ввода-вывода. Эти устройства можно условно разделить на критичные и некритичные по быстродействию. К критичным по быстродействию устройствам относятся обработчики команд ввода-вывода и контроллеры интерфейсов. Эти устройства определяют пропускную способность подсистемы ввода-вывода. Некритичные по быстродействию устройства управляют распределением линий в подсистеме ввода-вывода.
Основными направлениями развития подсистем ввода-вывода являются канальная технология ввода-вывода, матричная топология коммутации периферийных устройств (ПУ), увеличение количества и пропускной способности каналов.
Подсистема защиты памяти
представляет собой комплекс аппаратно-программных средств, обеспечивающих предотвращение взаимного искажения одновременно находящихся в ОП программ и несанкционированного доступа к любой хранящейся в ОП информации. В общем случае защита осуществляется как при записи для предотвращения искажения информации, не относящейся к выполняемой в данный момент программе, так и при считывании для исключения возможности использования информации, не принадлежащей данному пользователю, т.е. для предотвращения несанкционированного доступа к информации.
Независимо от принятых принципов построения подсистемы защиты памяти в основе её функционирования заложена проверка всех адресов, поступающих для обращения к ОП. В результате такой проверки формируется сигналы управления, разрешающий обращение к ОП, если адрес относится к выделенной для данной программы области памяти, в противном случае вырабатывается сигнал, запрещающий выполнение данной команды (при этом посылается запрос на прерывание реализуемой программы с целью установления причины нарушения границ разрешенной для использования области памяти).
Реализация идеи защиты памяти в любом случае не должна сопровождаться заметным снижением производительности машины и не требовать больших аппаратных затрат.
Различают три способа защиты памяти: по граничным адресам, по маскам и по уровням привилегий (ключам).
Защита памяти по граничным адресам
Защита памяти по граничным адресам
осуществляется с помощью регистров и узлов сравнения кодов, размещаемых в блоке защиты памяти (БЗП). Реализация этого способа защиты предусматривает выделение для каждой программы определенной области ОП, составленной из ячеек с последовательными адресами. Границы области отмечаются фиксированием адресов её начальной и конечной ячеек. Граничные адреса вводятся в регистры БЗП управляющей программой операционной системы перед началом выполнения каждой рабочей программы. При выполнении данной рабочей программы каждый поступающий в ОП исполнительный адрес с помощью узлов сравнения кодов сравнивается с граничными адресами.
По результатам сравнения устанавливается возможность обращения к ОП по поступившему адресу: если он находится в пределах граничных адресов, то разрешается доступ к соответствующей ячейке памяти, в противном случае вырабатывается сигнал запроса на прерывание выполняемой программы.
Преимущество данного способа защиты памяти состоит в том, что он позволяет защищать области памяти произвольной длины. Кроме того, блок защиты достаточно прост, а его функционирование не приводит к значительным временным затратам. Однако необходимость размещения программ в областях памяти с последовательными номерами ячеек и ограниченных двумя граничными адресами существенно снижает возможности программирования и даже эффективность работы ЭВМ. Поэтому способ защиты памяти по граничным адресам в настоящее время применяется редко, при статическом распределении памяти, когда для каждой из параллельно выполняемых рабочих программ заранее (до начала их выполнения) отводится определенная область памяти.
Защита памяти по маскам
Защита памяти по маскам
используется при страничной организации ОП. Для каждой программы перед её выполнением указываются номера страниц, отведенные для размещения её команд и всех необходимых данных. Указание о номерах отведенных страниц для данной программы задается управляющей программой операционной системы в виде кода маски или кода признаков страниц. Код маски формируется для каждой рабочей программы. Под маской программы понимается n-разрядный двоичный код, разрядность которого определяется количеством страниц ОП. Каждый i-й разряд маски указывает о принадлежности i-й страницы ОП данной программе: если в i-м разряде задано значение 1, то при обращении к ОП разрешен доступ к любой ячейке i-ой страницы, если же i-й разряд маски содержит ноль, то выполняемой программе доступ к i-й странице запрещен.
Перед выполнением программы её код маски по специальной команде засылается в регистр маски РМ (рис. 4.21) блока защиты.
При каждом обращении к ОП код номера страницы из исполнительного адреса загружается в регистр номера страницы PC и затем расшифровывается дешифратором номера страницы ДШС. На одном из выходов этого дешифратора, номер которого равен номеру страницы, появляется единичный сигнал. Если в соответствующем этой странице двоичном разряде кода маски программы задана единица, то схема сравнения выдает сигнал разрешения передачи адреса ячейки в ОП, в противном случае схема сравнения вырабатывает сигнал прерывания программы.

Рис.4.21. Защита памяти по маскам
По сравнению с защитой по граничным адресам защита памяти по маскам отличается большей гибкостью при организации распределения ОП. Для своей реализации данный метод не требует сложного оборудования.
Однако при большой емкости ОП, состоящей из значительного количества страниц, она становится неэффективной. Это связано с многоразрядно-стью кода маски, возрастанием сложности дешифратора номера страниц и всего БЗП, а также заметным увеличением времени работы БЗП по формированию управляющих сигналов.
Полностью ассоциативное распределение
При полностью ассоциативном распределении допускается размещение каждой строки основной памяти на месте любой строки кэш-памяти. Структура кэш-памяти с полностью ассоциативным распределением представлена на рис. 4.6.
Адрес основной памяти состоит из 14-разрядного адреса строки (тега) и 4-разрядного адреса внутри строки.
При полностью ассоциативном распределении механизм преобразования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память являлась ассоциативной памятью. Входной информацией для ассоциативной памяти тегов является тег -14-разрядный адрес строки, а выходной информацией - адрес строки внутри кэш-памяти. Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса строки внутри кэш-памяти. Ключом для поиска адреса строки внутри кэш-памяти является тег (старшие 14 разрядов адреса основной памяти).
При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных. Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной.
При несовпадении ключа ни с одним из тегов теговой памяти (кэш-Промах) осуществляется обращение к основной памяти и чтение необходимой строки. По этому способу при замене строк кандидатом на удаление могут быть
все строки в кэш-памяти.

Рис.4.6. Структура кэш-памяти с полностью ассоциативным распределением
Порог прерывания.
Этот способ позволяет в ходе вычислительного процесса программным путем изменить уровень приоритета процессора (а следовательно, и обрабатываемой в данный момент на процессоре программы) относительно приоритетов запросов источников прерывания (периферийных устройств), другими словами, задавать порог прерывания, т. е. минимальный уровень приоритета запросов, которым разрешается прерывать программу, идущую на процессоре.
Порог прерывания задается командой программы, устанавливающей в регистре порога прерывания код порога прерывания. Специальная схема выделяет наиболее приоритетный запрос, сравнивает его приоритет с порогом прерывания и, если он оказывается выше порога, вырабатывает общий сигнал прерывания, и начинается процедура прерывания.
Маска прерывания
представляет собой двоичный код, разряды которого поставлены в соответствие запросам или классам (уровням) прерываний. Маска загружается командой программы в регистр маски (рис. 3.14).
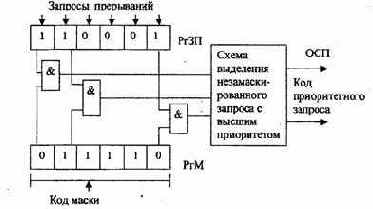
Рис.3.14. Маскирование прерываний
Состояние 1 в данном разряде регистра маски (РгМ) разрешает, а состояние 0 запрещает (маскирует) прерывание текущей программы от соответствующего запроса. Таким образом, программа, изменяя маску в регистре маски, может устанавливать произвольные приоритетные соотношения между программами без перекоммутации линий, по которым поступают запросы прерывания. Каждая прерывающая программа может установить свою маску. При формировании маски 1 устанавливаются в разряды, соответствующие запросам (прерывающим программам) с более высоким, чем у данной программы, приоритетом. Схемы И выделяют поступившие незамаскированные запросы прерывания, из которых специальная схема выделяет наиболее приоритетный и формирует код его номера.
С замаскированным запросом, в зависимости от причины прерывания, поступают двояким образом: или он игнорируется, или запоминается, с тем чтобы осуществить затребованные действия, когда запрет будет снят. Например, если прерывание вызвано окончанием операции в ПУ, то его следует, как правило, запомнить, так как иначе ЭВМ останется неосведомленной о том, что ПУ освободилось.
Прерывание, вызванное переполнением разрядной сетки при арифметической операции, следует при его маскировании игнорировать, так как запоминание этого запроса может оказать действие на часть программы или другую программу, к которым это переполнение не относится.
Организация перехода к прерывающей программе
%,
Вектор начального состояния прерывающей программы называют вектором прерывания. Он содержит всю необходимую информацию для перехода к прерывающей программе, в том числе ее начальный адрес. Каждому запросу (уровню) прерывания соответствует свой вектор прерывания, способный инициировать выполнение соответствующей прерывающей программы. Векторы прерывания обычно находятся в специально выделенных фиксированных ячейках памяти (стеке).
Главное место в процедуре перехода к прерывающей программе занимает передача из соответствующего регистра (регистров) процессора в память (стек) на сохранение текущего вектора состояния прерываемой программы (чтобы можно было вернуться к ее исполнению) и загрузка в регистр (регистры) процессора вектора прерывания прерывающей программы, к которой при этом переходит управление процессором.
Наиболее гибким и динамичным является векторное прерывание, при котором источник прерывания, выставляя запрос прерывания, посылает в процессор (выставляет на шины интерфейса) код адреса в памяти своего вектора прерывания.
При векторном прерывании каждому запросу прерывания или, другими словами, устройству — источнику прерывания, соответствует переход к начальному адресу соответствующей прерывающей программы, задаваемому вектором прерывания.
ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС Иерархическая структура памяти ЭВМ
Памятью ЭВМ называется совокупность устройств, служащих для запоминания, хранения и выдачи информации.
Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита).
Емкость памяти определяется максимальным количеством данных, которые могут в ней храниться. Емкость измеряется в двоичных единицах (битах), машинных словах, но большей частью в байтах (1 байт = 8 бит). Часто емкость памяти выражают через число К = 1024, например, Кбит — килобит, Кбайт — килобайт, 1024 Кбайт = 1 Мбайт (Мегабайт), 1024 Мбайт = 1 Гбайт
(гигабайт), 1024 Гбайт = 1 Тбайт (терабайт).
Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Требования к увеличению емкости и быстродействия памяти, а также к снижению ее стоимости являются противоречивыми. Чем больше быстродействие, тем технически труднее достигается и дороже обходится увеличение емкости памяти. Стоимость памяти составляет значительную часть общей стоимости ЭВМ. Исходя из этого, память ЭВМ организуется в виде иерархической структуры (рис. 4.1) запоминающих устройств, обладающих различным быстродействием и емкостью. Чем выше уровень, тем выше быстродействие соответствующей памяти, но меньше её емкость. К верхнему (сверхоперативному) уровню относятся регистры операционных и управляющих блоков процессора, сверхоперативная память, управляющая память, буферная память. На втором уровне находится основная или оперативная память. На последующих уровнях размещается внешняя и архивная память. Система управления памятью обеспечивает обмен информационными блоками между уровнями, причем обычно первое обращение к блоку информации вызывает его перемещение с низкого медленного уровня на более высокий.
Это позволяет при последующих обращениях к данному блоку осуществлять его выборку с более быстродействующего уровня памяти.
Сравнительно небольшая емкость оперативной памяти (8 — 64 Мбайта) компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства сравнительно медленные — время обращения за данными для магнитных дисков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет 50 не. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти.
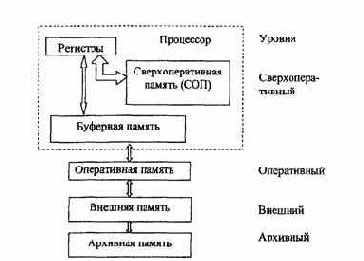
Рис.4.1. Иерархическая струюура памяти
Непрерывный рост производительности ЭВМ проявляется, в первую очередь, в повышении скорости работы процессора. Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора в значительной степени потому, что одновременно происходит опережающий рост её емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП часто оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Это проявляется в несоответствии пропускных способностей процессора и ОП. Возникающая проблема выравнивания их пропускных способностей решается путем использования сверхоперативной буферной памяти небольшой емкости и повышенного быстродействия, хранящей команды и данные, относящиеся к обрабатываемому участку программы.
При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память (СБП). Последующие обращения производятся к копии блока данных, находящейся в СБП. Поскольку время выборки из сверхоперативной буферной памяти t^y (5 ис) много меньше времени выборки из оперативной памяти ton, введение в структуру памяти СБП приводит к уменьшению эквивалентного времени обращения <э по сравнению с ton:
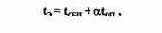
где а = (1 — q) и q — вероятность нахождения блока в СВП в момент обращения к нему, т.е.
вероятность «попадания». Очевидно, что при высокой ве роятности попадания эквивалентное время обращения приближается к времени обращения к СБП.
В основе такой организации взаимодействия ОП и СБП лежит принцип локальности обращений, согласно которому при выполнении какой-либо программы (практически для всех классов задач) большая часть обращений в пределах некоторого интервала времени приходится на ограниченную область адресного пространства ОП, причем обращения к командам и элементам данных этой области производятся многократно. Это позволяет копии наиболее часто используемых участков программ и некоторых данных загрузить в СБП и таким образом обеспечить высокую вероятность попадания q. Высокая эффективность применения СБП достигается при q ³ 0,9.
Буферная память не является программно доступной. Это значит, что она влияет только на производительность ЭВМ, но не должна оказывать влияния на программирование прикладных задач. Поэтому она получила название кэш-памяти (в переводе с английского - тайник). В структуре одних ЭВМ используется объединенная кэш-память команд и данных, в других ЭВМ — раздельные кэш-памяти для команд и для данных. Кэш-память, входящую в состав процессора, называют кэш-памятью первого уровня. В современных компьютерах применяют кэш-память второго уровня, которая находится между процессором и ОП и еще больше повышает производительность ЭВМ.
Принципы организации системы прерывания программ
Во время выполнения ЭВМ текущей программы внутри машины и в связанной с ней внешней среде (технологический процесс, управляемый ЭВМ) "могут возникать события, требующие немедленной реакции на них со стороны машины.
Реакция состоит в том, что машина прерывает обработку текущей программы и переходит к выполнению некоторой другой программы, специально предназначенной для данного события. По завершению этой программы ЭВМ возвращается к выполнению прерванной программы.
Рассматриваемый процесс, называемый прерыванием программ, поясняется на рис. 3.10.
Принципиально важным является то, что моменты возникновения событий, требующих прерывания программ, заранее не известны и поэтому не могут быть учтены при программировании.
Каждое событие, требующее прерывания, сопровождается сигналом, который называют запросом прерывания.
Программу, затребованную запросом прерывания, называют прерывающей программой, противопоставляя ее прерываемой программе, выполнявшейся в ЭВМ до появления запроса.
Запросы на прерывания могут возникать внутри самой ЭВМ и в ее внешней среде. К первым относятся, например, запросы при возникновении в ЭВМ таких событий, как появление ошибки в работе ее аппаратуры, переполнение разрядной сетки, попытка деления на 0, выход из установленной для данной программы области памяти, затребование периферийным устройством операции ввода-вывода, завершение операции ввода-вывода периферийным устройством или возникновение при этой операции особой ситуации и др. Хотя некоторые из указанных событий порождаются самой программой, моменты их появления, как правило, невозможно предусмотреть. Запросы во внешней среде могут возникать от других ЭВМ, от аварийных и некоторых других датчиков технологического процесса и т.п.
Таким образом, запросы прерывания генерируются несколькими развивающимися параллельно во времени процессами, которые в некоторые моменты требуют вмешательства процессора.
К этим процессам, в частности, относится процесс выполнения самой программы, процесс контроля правильности работы ЭВМ, операции ввода -вывода, технологический процесс в управляемом машиной объекте и др.
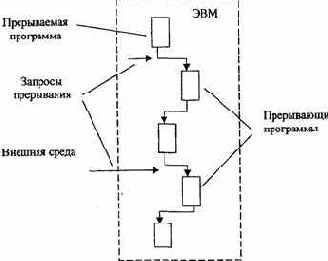
Рис.3.10. Процесс прерывания программы
Возможность прерывания программ - важное архитектурное свойство ЭВМ, позволяющее эффективно использовать производительность процессора при наличии нескольких, протекающих параллельно во времени, процессов, требующих в произвольные моменты времени управления и обслуживания со стороны процессора. В первую очередь это относится к организации параллельной во времени работы процессора и периферийных устройств машины, а также к использованию ЭВМ для управления в реальном времени технологическими процессами,
В некоторых машинах, наряду или вместо прерывания с переключением управления на другую программу, используется примитивное прерывание -так называемая приостановка, когда по соответствующему запросу приостанавливается выполнение программы и выполняется аппаратурными средствами некоторая процедура без изменения содержания счетчика команд, а по ее окончании продолжается выполнение приостановленной программы.
Чтобы ЭВМ могла, не требуя больших усилий от программиста, реализовывать с высоким быстродействием прерывания программ, машине необходимо придать соответствующие аппаратурные и программные средства, совокупность которых получила название
системы прерывания программ. В качестве аппаратных средств используется контроллер прерывания
(блок прерывания).
Основными функциями системы прерывания являются:
- запоминание состояния прерываемой программы и осуществление перехода к прерывающей программе;
- восстановление состояния прерванной программы и возврат к ней. При наличии нескольких источников запросов прерывания между ними должны быть установлены приоритетные соотношения, определяющие, какой из нескольких поступивших запросов подлежит обработке в первую очередь, и устанавливающие: имеет право или нет данный запрос (прерывающая программа) прерывать ту или иную программу.
Прямая адресация операндов
При этом способе (рис. 2.5) адресации обращение за операндом в РП или ОП производится по адресному коду в поле команды, т.е. исполнительный адрес операнда совпадает с адресным кодом команды (Аи = Ак).
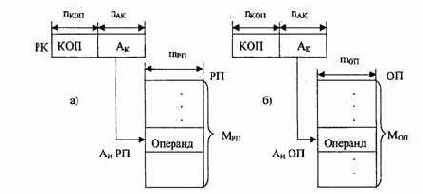
Рис.2.5. Схема прямой адресации: а) к регистровой памяти; б) к основной памяти
Обеспечивая простоту программирования, этот метод имеет существенные недостатки, так как для адресации к ячейкам памяти большой емкости (число адресов М велико) требуется «длинное» адресное поле в команде. Прямая адресация используется широко в сочетании с другими способами адресации. В частности, вся адресация к «малой» регистровой памяти ведется только с помощью прямой адресации.
Прямое распределение
При прямом распределении место хранения строк в кэш-памяти однозначно определяется по адресу строки.
Структура кэш-памяти показана на рис. 4.5.

Рис.4.5. Структура кэш-памяти с прямым распределением
Адрес основной памяти состоит из 14-разрядного адреса строки и 4-разрядного адреса слова внутри этой строки. Адрес строки подразделяется на тег (старшие 7 бит) и индекс (младшие 7 бит).
Для того, чтобы поместить в кэш-память строку из основной памяти с адресом bn, выбирается область внутри кэш-памяти с адресом be, который равен 7 младшим битам адреса строки bn. Преобразование из bn в Ьс сводится только к выборке младших 7 бит адреса строки. По адресу be в кэш-памяти может быть помещена любая из 128 строк основной памяти, имеющих адрес, 7 младших битов которого равны адресу be. Для того чтобы определить, какая именно строка хранится в данное время в кэш-памяти, используется память ёмкостью 7 бит х 128 слов, в которую помещается по соответствующему адресу в качестве тега 7 старших битов адреса строки, хранящейся в данное время по адресу be кэш-памяти. Это специальная память, называемая теговой памятью. Память, в которой хранятся строки, помещенные в кэш, называются памятью данных. В качестве адреса теговой памяти используются младшие 7 битов адреса строки.
Из теговой памяти считывается тег. Параллельно этому осуществляется доступ к памяти данных с помощью 11 младших битов адреса основной памяти (используется 7 разрядов индекса и 4 разряда адреса слова внутри строки). Если считанный из теговой памяти тег и старшие 7 бит адреса основной памяти совпадают, то это означает, что данная строка существует в памяти данных, т.е. осуществляется кэш-попадание.
Если тег отличается от старших 7 бит (кэш-промах), то из основной памяти считывается соответствующая строка, а из кэш-памяти удаляется строка, определяемая 7 младшими разрядами адреса строки, и на его место помещается строка, считанная из основной памяти. Осуществляется также обновление соответствующего тега в теговой памяти.
Способ прямого распределения реализовать довольно просто, однако из-за того, что место хранения строки в кэш-памяти однозначно определяется по адресу строки, вероятность сосредоточения областей хранения строк в некоторой части кэш-памяти высока, т.е. замены строк будут происходить довольно часто. В такой ситуации эффективность кэш-памяти заметно снижается.
Прямой доступ к памяти
Прямой доступ к памяти — это такой способ обмена данными, который обеспечивает автономно от ЦП установление связи и передачу данных между ОП и ПУ. Прямой доступ к памяти освобождает процессор от управления операциями ввода-вывода, позволяет осуществлять параллельно во времени выполнение процессором программы с обменом данными между ОП и ПУ, производить этот обмен со скоростью, ограничиваемой только пропускной способностью ОП или ПУ.
Таким образом, ПДП, разгружая процессор от обслуживания ввода-вывода, способствует возрастанию общей производительности ЭВМ. Повышение предельной скорости ввода-вывода информации делает машину более приспособленной для работы в системах реального времени. Прямым доступом к памяти управляет контроллер ПДП (рис. 5.1), который выполняет следующие функции:
1. Управление инициируемой процессором или ПУ передачей данных между ОП и ПУ.
2. Задание размера блока данных, который подлежит передаче и области памяти, используемой при передаче.
3.
Формирование адресов ячеек ОП, участвующих в передаче.
4. Подсчет числа единиц данных (байт, слов), передаваемых от ПУ в ОП или обратно, и определение момента завершения заданной операции ввода-вывода.

Рис.5.1. Прямой доступ к памяти
Контроллер ПДП обычно имеет более высокий приоритет в занятии цикла памяти по сравнению с процессором. Управление памятью переходит к контроллеру ПДП как только завершится цикл ее работы, выполняемый для текущей команды процессора.
ПДП обеспечивает высокую скорость обмена данными за счет того, что управление обменом производится не программным путем, а аппаратурными средствами.
В современных ЭВМ используется как программно-управляемая передача данных, так и прямой доступ к памяти.
Программно-управляемый обмен сохраняют для операций ввода-вывода отдельных байт (слов), которые выполняются быстрее, чем при ПДП, так как исключаются потери времени на программно-управляемую установку начальных состояний регистров и счетчиков контроллера ПДП (инициализация).
Проблемы организации подсистем ввода-вывода
Производительность и эффективность использования ЭВМ определяются не только возможностями ее процессора и характеристиками основной памяти, но в очень большой степени составом ее периферийных устройств (ПУ), их техническими данными и способом организации их совместной работы с ядром (процессором и основной памятью) ЭВМ.
Связь устройств ЭВМ друг с другом осуществляется с помощью интерфейсов.
Интерфейс представляет собой совокупность линий и шин, сигналов, электронных схем и алгоритмов (протоколов), предназначенную для осуществления обмена информацией между устройствами. От характеристик интерфейсов во многом зависят производительность и надежность ЭВМ.
При разработке систем ввода-вывода должны быть решены следующие проблемы:
1. Должна быть обеспечена возможность реализации машин с переменным составом оборудования (машин с переменной конфигурацией). В первую очередь, с различным набором периферийных устройств с тем, чтобы пользователь мог выбирать состав оборудования (конфигурацию) машины в соответствии с ее назначением, легко дополнять машину новыми устройствами.
2. Для эффективного и высокопроизводительного использования оборудования ЭВМ должны реализовываться параллельная во времени работа процессора над программой и выполнение ПУ процедур ввода-вывода.
3. Для пользователя необходимо упростить и стандартизировать программирование операций ввода-вывода, обеспечить независимость программирования ввода-вывода от особенностей того или иного ПУ.
4. Необходимо обеспечить автоматическое распознавание и реакцию ядра ЭВМ на многообразие ситуаций, возникающих в ПУ (готовность устройства, отсутствие носителя, различные нарушения нормальной работы и Др.)
Особенно актуально решение этих проблем для машин, содержащих большое число разнообразных ПУ.
Отметим основные пути решения указанных проблем.
Программно-управляемый приоритет прерывающих программ
Относительная степень важности программ, их частота повторения, относительная степень срочности в ходе вычислительного процесса могут меняться, требуя установления новых приоритетных отношений. Поэтому во многих случаях приоритет между прерывающими программами не может быть зафиксирован раз и навсегда. Необходимо иметь возможность изменять по мере необходимости приоритетные соотношения программным путем. Приоритет между прерывающими программами должен быть динамичным, т.е. программно управляемым.
В ЭВМ широко применяются два способа программно-управляемого приоритета прерывающих программ:
- использование порога прерывания;
- использование маски прерывания.
Распределение памяти фиксированными разделами
Самым простым способом управления оперативной памятью является разделение её на несколько разделов (сегментов) фиксированной величины (статическое распределение). Это может быть выполнено вручную оператором во время старта системы или во время её генерации. Очередная задача, поступающая на выполнение, помещается либо в общую очередь (рис. 4.11,а), либо в очередь к некоторому разделу (рис. 4.11,6). Подсистема управления памятью в этом случае выполняет следующие задачи: сравнивает размер программы, поступившей на выполнение, и свободных разделов памяти; выбирает подходящий раздел; осуществляет загрузку программы и настройку адресов.
При очевидном преимуществе, заключающемся в простоте реализации, данный метод имеет существенный недостаток — жесткость. Так как в каждом разделе может выполняться только одна программа, то уровень мультипрограммирования заранее ограничен числом разделов независимо от того, какой размер имеют программы.
Даже если программа имеет небольшой объем, она будет занимать весь раздел, что приводит к неэффективному использованию памяти. С другой стороны, даже если объем оперативной памяти машины позволяет выполнить некоторую программу, разбиение памяти на разделы не позволяет сделать этого.

Рис. 4.11. Распределение памяти фиксированными разделами: а) с общей очередью; б) с отдельными очередями
Распределение памяти разделами переменной величины
В этом случае память машины не делится заранее на разделы. Сначала вся память свободна. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На рис. 4.12 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так в момент tg в памяти находится только ОС, а к моменту t, память разделена между 5 задачами, причем задача П4, завершая работу, покидает память к моменту t;. На освободившееся место загружается задача П6, поступившая в момент 1з.
Задачами операционной системы при реализации данного метода управления памятью являются: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти; анализ запроса (при поступлении новой задачи), просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи; загрузка задачи в выделенный ей раздел и корректировка таблиц свободных и занятых областей; корректировка таблиц свободных и занятых областей (после завершения задачи).

Рис. 4.12. Распределение памяти динамическими разделами
Программный код не перемещается во время выполнения, т.е. может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика.
Выбор раздела для вновь поступившей задачи может осуществляться по разным правилам: «первый попавшийся раздел достаточного размера»; «раздел, имеющий наименьший достаточный размер»; «раздел, имеющий наибольший достаточный размер». Все эти правила имеют свои преимущества и недостатки.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток — фрагментация памяти. Фрагментация — это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти1.
Распределение секторов
По данному методу основная память разбивается на секторы, состоящие из фиксированного числа строк, кэш-память также разбивается на секторы, состоящие из такого же числа строк. Рассмотрим случай, когда длина строки равна 16 словам, а сектор состоит из 16 строк. Структура кэш-памяти с распределением секторов представлена на рис. 4.8. В адресе основной памяти старшие 10 бит показывают номер сектора, следующие 4 бит — номер строки внутри сектора, а младшие 4 бит — адрес слова в строке.
По данному методу распределение секторов в основной памяти, и секторов в кэш-памяти осуществляется полностью ассоциативно. Другими словами, каждый сектор в основной памяти может соответствовать любому сектору в кэш-памяти. Распределение строк в секторе одинаково для основной памяти и кэш-памяти. К каждой строке, хранимой в кэш-памяти, добавляется один бит информации, называемый битом достоверности (действительности); он показывает, совпадает или нет содержимое этой строки с содержимым строки в основной памяти, которая в данный момент анализируется на соответствие строки кэш-памяти.

Если слова, запрашиваемого центральным процессором при доступе, не существует в кэш-памяти, то сначала центральный процессор проверяет, был ли сектор, содержащий это слово, ранее помещен в кэш-память. Если он отсутствует, то один из секторов кэш-памяти заменяется на этот сектор. Если все сектора кэш-памяти используются, то выбирается один какой-нибудь сектор, и при необходимости только некоторые строки из этого сектора возвращаются в основную память, а этот сектор можно использовать дальше. Когда осуществляется доступ к этому сектору в кэш-памяти и строка, содержащая нужное слово, пересылается из основной памяти, то бит достоверности устанавливается до пересылки строки. Все биты достоверности других строк этого сектора сбрасываются.
Если сектор, содержащий слово, доступ к которому запрашивается, уже находится в кэш-памяти, то в том случае, когда бит достоверности строки, содержащий это слово, равен 0, этот бит устанавливается и строка пересылается из основной памяти в данную область кэш-памяти. В том случае, когда бит достоверности уже равен 1, данное слово можно считать из кэш-памяти.
Регистр флагов
Регистр флагов является 32-разрядным, имеет имя EFLAGS. Его разряды содержат признаки результата выполнения команды, управляют обработкой прерываний, последовательностью вызываемых задач, вводом/выводом и рядом лпугих nnouenvo.
3.2.2. Регистры процессора обработки чисел с плавающей точкой
Набор регистров, входящих в блок (FPU), изображен на рис. 3.6.
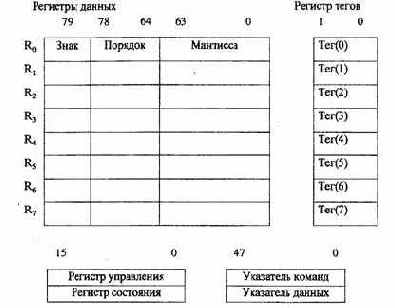
Рис. 3.6. Регистры блока FPU
Регистр тегов FPU.
Он содержит 16-разрядное слово, включающее восемь двухбитовых тегов. Каждый тег (признак) характеризует содержимое одного из регистров данных.
Тег определяет, является ли регистр пустым (незаполненным) - код 11 или в него введено конечное число — 00 (достоверное значение), или нуль -01, неопределенное значение (бесконечность) — 10 (нет числа и неподдерживаемый формат). Слово тегов позволяет оптимизировать функционирование FPU посредством идентификации пустых и непустых регистров данных, проверить содержимое регистра без сложного декодирования хранящихся в нем данных.
Регистровые структуры центрального процессора
Набор регистров и их
структуры рассмотрим на примере процессоров с интеловской архитектурой. Можно выделить следующие группы регистров:
Регистры общего назначения
Восемь 32-разрядных регистров предназначены для хранения данных и адресов. Они поддерживают работу с данными разрядностью 1, 8, 16,32 и 64 бита, битовыми полями длиной от 1 до 32 бит и адресами размером 16 и 32 бита. Младшие 16 разрядов этих регистров (рис. 3.3) доступны отдельно при использовании соответствующего имени, например регистр ЕАХ (имя АХ для 16 разрядов).

Рис. 3.3. Структура регистра общего назначения ЕАХ
При операциях с байтами можно отдельно обращаться к младшему байту (разряды 0 - 7) и старшему байту (8-15) по именам AL и АН. Доступ к отдельным байтам обеспечивает дополнительную гибкость при операциях с данными.
Регистры отладки и тестирования.
Все 16-разрядные регистры микропроцессоров 8086, 80186, 80286 входят в состав набора 32-разрядных регистров. Регистры первых двух групп используются при выполнении прикладных программ, третьей группы _ системных, четвертой — при отладке и тестировании.
Микропроцессор i486, например, имеет одиннадцать регистров отладки и тестирования (все они 32-разрядные). Из них б программно-доступных регистров (DRO — DR3, DR6, DR7) поддерживают процесс отладки программ. Пять программно-доступных регистров (TR3 — TR7) поддерживают тестирование внутренних блоков: TR3 — TR5 используются для проверки кэшпамяти; TR6, TR7 — для тестирования механизма быстрого формирования адресов страниц.
Регистры процессора обработки чисел с плавающей точкой (
FPU):
- регистры данных;
- регистр тегов;
- регистр состояния;
- регистр указателей команд и данных FPU;
- регистр управления FPU.
Регистры сегментов и дескрипторы сегментов
Шесть 16-разрядных сегментных регистров (CS, SS, DS, ES, FS, GS) содержат значения селекторов сегментов, указывающих на текущие адресуемые сегменты памяти. С каждым из них связан программно-недоступный регистр дескриптора сегмента (рис. 3.4).
В защищенном режиме каждый сегмент может иметь размер от 1 байта до 4 Гбайт, в режиме реальных адресов максимальный размер сегмента составляет 64 Кбайта.
Селектор в CS обеспечивает обращение к текущему сегменту команд, селектор в SS — к текущему сегменту стека, селекторы в DS, ES, FS, GS — к текущим сегментам данных. Каждый регистр дескриптора содержит 32-разрядный размер сегмента и другие необходимые атрибуты.
Когда в регистр сегмента загружается новое значение селектора, содержимое соответствующего регистра дескриптора автоматически корректируется. В реальном режиме базовый адрес сегмента получается путем сдвига
значения селектора на 4 разряда влево (20 разрядов), максимальный размер и атрибуты сегмента в реальном режиме имеют фиксированные значения.
Регистры сегментов Регистры дескрипторов

Рис. 3.4. Регистры сегментов и соответствующие регистры дескрипторов
феникс собственной персоной
The Sleuth Kit представляет собой бесплатно распространяемый комплект утилит для ручного восстановления файловой системы, который можно найти по адресу (http://www.sleuthkit.org/), там же (http://www.sleuthkit.org/sleuthkit/docs/ref_fs.html) лежит краткий how-to. Увы, чудес не бывает и вся методика восстановления сводится к сканированию свободного пространства на предмет поиска фрагментов с известным содержимым.
Foremost — еще одна бесплатная утилита для восстановления удаленных файлов, основанная формате их заголовков на особенностях структуры. Естественно, она работает только с теми файлами, чье строение ей известно. Тем не менее, по сравнению с ее предшественницами это большой шаг вперед! Кстати говоря, утилита взаимодействует с файловой системой не напрямую, а обрабатывает файлы полученные командой dd или набором Sleuth Kit, благодаря чему она "поддерживает" все файловые системы. Последняя версия лежит на сервере http://foremost.sourceforge.net/
структура файловой системы s5/ext2fs (а) и ufs (b)
Адресация ведется либо по физическим смещениям, измеряемых в байтах и отсчитываемых от начала группы цилиндров (реже — UFS-раздела), либо в номерах фрагментов, отсчитываемых от тех же самых точек. Допустим, размер блока составляет 16 Кбайт, разбитых на 8 фрагментов. Тогда 69'й сектор будет иметь смещение 512 х 69 == 35328 байт или 1024 x (16/8)/512 x 69 = 276 фрагментов.
В начале раздела расположен загрузочный сектор, затем следует суперблок, за которым находится одна или несколько групп цилиндров. Для перестраховки, копия суперблока дублируется в каждой группе. Загрузочный сектор не дублируется, но по соображениям унификации и единообразия, под него просто выделяется место. Таким образом, относительная адресация блоков в каждой группе остается неизменной.

последовательно расположенные группы цилиндров
В UFS cуперблок располагается по смещению 8192 байт от начала раздела, что соответствует 16-сектору. В UFS2 он "переехал" на 65536 байт (128 секторов) от начала, освобождая место для дисковой метки и первичного загрузчика операционной системы, а для действительно больших (в исходных текстах — piggy, т. е. "свинских") систем предусмотрена возможность перемещения суперблока по адресу 262144 байт (целых 512 секторов)!
Среди прочей информации суперблок содержит:
q cblkno — смещение первой группы блока цилиндров, измеряемый в фрагментах, отсчитываемых от начала раздела;
q fs_iblkno — смещение первой inode в первой группе цилиндров (фрагменты от начала раздела);
q fs_dblkno — смещение первого блока данных в первой группе цилиндров (фрагменты от начала раздела);
q fs_ncg — кол-во групп цилиндров (штуки);
q fs_bsize – размер одного блока в байтах;
q fs_fsize — размер одного фрагмента в байтах;
q fs_frag — кол-во фрагментов в блоке;
q fs_fpg – размер каждой группы цилиндров, выраженный в блоках (так же может быть найден через fs_cgsize);
Для перевода смещений, выраженных в фрагментах, в номера секторов, служит следующая формула: sec_n(fragment_offset) = fragment_offset*(fs_bsize/fs_frag/512) или ее более короткая разновидность: sec_n(fragment_offset) = fragment_offset*fs_fsize
/512;
Структура суперблока определена в файле /src/ufs/ffs/fs.h и в упрощенном виде выглядит так:
struct fs {
/* 0x00 */ int32_t fs_firstfield; /* historic file system linked list, */
/* 0x04 */ int32_t fs_unused_1; /* used for incore super blocks */
/* 0x08 */ ufs_daddr_t fs_sblkno; /* addr of super-block in filesys */
/* 0x0C */ ufs_daddr_t fs_cblkno; /* offset of cyl-block in filesys */
/* 0x10 */ ufs_daddr_t fs_iblkno; /* offset of inode-blocks in filesys */
/* 0x14 */ ufs_daddr_t fs_dblkno; /* offset of first data after cg */
/* 0x18 */ int32_t fs_cgoffset; /* cylinder group offset in cylinder */
/* 0x1C */ int32_t fs_cgmask; /* used to calc mod fs_ntrak */
/* 0x20 */ time_t fs_time; /* last time written */
/* 0x24 */ int32_t fs_size; /* number of blocks in fs */
/* 0x28 */ int32_t fs_dsize; /* number of data blocks in fs */
/* 0x2C */ int32_t fs_ncg; /* number of cylinder groups */
/* 0x30 */ int32_t fs_bsize; /* size of basic blocks in fs */
/* 0x34 */ int32_t fs_fsize; /* size of frag blocks in fs */
/* 0x38 */ int32_t fs_frag; /* number of frags in a block in fs */
/* these are configuration parameters */
/* 0x3С */ int32_t fs_minfree; /* minimum percentage of free blocks */
/* 0x40 */ int32_t fs_rotdelay; /* num of ms for optimal next block */
/* 0x44 */ int32_t fs_rps; /* disk revolutions per second */
/* sizes determined by number of cylinder groups and their sizes */
/* 0x98 */ ufs_daddr_t fs_csaddr; /* blk addr of cyl grp summary area */
/* 0x9C */ int32_t fs_cssize; /* size of cyl grp summary area */
/* 0xA0 */ int32_t fs_cgsize; /* cylinder group size */
/* these fields can be computed from the others */
/* 0xB4 */ int32_t fs_cpg; /* cylinders per group */
/* 0xB8 */ int32_t fs_ipg; /* inodes per group */
/* 0xBC */ int32_t fs_fpg; /* blocks per group * fs_frag */
/* these fields are cleared at mount time */
/* 0xD0 */ int8_t fs_fmod; /* super block modified flag */
/* 0xD1 */ int8_t fs_clean; /* file system is clean flag */
/* 0xD2 */ int8_t fs_ronly; /* mounted read-only flag */
/* 0xD3 */ int8_t fs_flags; /* see FS_ flags below */
/* 0xD4 */ u_char fs_fsmnt[MAXMNTLEN]; /* name mounted on */
};
схематичное изображение inode
В UFS2 формат inode был существенно изменен — появилось множество новых полей, удвоилась ширина адресных полей и т. д. Что это обозначает для нас в практическом плане? Смещения всех полей изменились, только и всего, а общий принцип работы с inod'ами остался прежним:
struct ufs2_dinode {
/* 0x00 */ u_int16_t di_mode; /* 0: IFMT, permissions; see below. */
/* 0x02 */ int16_t di_nlink; /* 2: File link count. */
/* 0x04 */ u_int32_t di_uid; /* 4: File owner. */
/* 0x08 */ u_int32_t di_gid; /* 8: File group. */
/* 0x0C */ u_int32_t di_blksize; /* 12: Inode blocksize. */
/* 0x10 */ u_int64_t di_size; /* 16: File byte count. */
/* 0x18 */ u_int64_t di_blocks; /* 24: Bytes actually held. */
/* 0x20 */ ufs_time_t di_atime; /* 32: Last access time. */
/* 0x28 */ ufs_time_t di_mtime; /* 40: Last modified time. */
/* 0x30 */ ufs_time_t di_ctime; /* 48: Last inode change time. */
/* 0x38 */ ufs_time_t di_birthtime; /* 56: Inode creation time. */
/* 0x40 */ int32_t di_mtimensec; /* 64: Last modified time. */
/* 0x44 */ int32_t di_atimensec; /* 68: Last access time. */
/* 0x48 */ int32_t di_ctimensec; /* 72: Last inode change time. */
/* 0x4C */ int32_t di_birthnsec; /* 76: Inode creation time. */
/* 0x50 */ int32_t di_gen; /* 80: Generation number. */
/* 0x54 */ u_int32_t di_kernflags; /* 84: Kernel flags. */
/* 0x58 */ u_int32_t di_flags; /* 88: Status flags (chflags). */
/* 0x5C */ int32_t di_extsize; /* 92: External attributes block. */
/* 0x60 */ ufs2_daddr_tdi_extb[NXADDR];/* 96: External attributes block. */
/* 0x70 */ ufs2_daddr_tdi_db[NDADDR]; /* 112: Direct disk blocks. */
/* 0xD0 */ ufs2_daddr_tdi_ib[NIADDR]; /* 208: Indirect disk blocks. */
/* 0xE8 */ int64_t di_spare[3]; /* 232: Reserved; currently unused */
};
хранение имен файлов и директорий
Структура direct определена в файле /src/ufs/ufs/dir.h и содержит: номер inode, описывающий данный файл, тип файла, его имя, а так же длину самой структуры direct, используемую для нахождения следующего direct'а в блоке.
struct direct {
/* 0x00 */ u_int32_t d_ino; /* inode number of entry */
/* 0x04 */ u_int16_t d_reclen; /* length of this record */
/* 0x06 */ u_int8_t d_type; /* file type, see below */
/* 0x07 */ u_int8_t d_namlen; /* length of string in d_name */
/* 0x08 */ char d_name[MAXNAMLEN + 1];/* name with length <= MAXNAMLEN */
};
Серверы
— многопользовательские ЭВМ, используемые в компьютерных сетях. Эту интенсивно развивающуюся группу компьютеров обычно относят к микро-ЭВМ, но по своим характеристикам мощные серверы скорее можно отнести к малым ЭВМ и даже к мэйнфреймам, а супер серверы приближаются к супер-ЭВМ.
Символьные данные
Поддерживаются строки символов в коде ASCII и арифметические операции (сложение, умножение) над ними (рис. 2.18). Поддержка осуществляется блоком АЛУ.

Рис.2.18. Символьные данные
Системная
— производительность базовых технических и программных средств, входящих в комплект поставки ЭВМ;
Системные регистры:
- регистры управления микропроцессора;
- регистры системных адресов.
Системные регистры управляют функционированием микропроцессора вцелом и режимами работы отдельных внутренних блоков: процессора с плавающей точкой, кэш-памятью, диспетчера памяти.
Эти регистры доступны только в защищенном режиме для программ.
Набор системных регистров включает три регистра управления (CRO, CR2, CR3) и четыре регистра системных адресов и сегментов.
Регистры управления 32-разрядные, служат для фиксации общего состояния процессора. Эти регистры вместе с регистрами системных адресов хранят информацию о состоянии процессора, которое затрагивает все задачи.
Сквозная запись
По методу сквозной записи обычно обновляется слово, хранящееся в основной памяти. Если в кэш-памяти существует копия этого слова, то она также обновляется. Если же в кэш-памяти отсутствует копия этого слова, то либо из основной памяти в кэш-память пересылается строка, содержащая это слово (метод WTWA — сквозная запись с распределением), либо этого не допускается (метод WTNWA — сквозная запись без распределения). Когда по методу сквозной записи область (строка) в кэш-памяти назначается для хранения другой строки, то в основную память можно не возвращать удаляемый блок, так как копия там есть. Однако в этом случае эффект от использования кэш-памяти отсутствует.
Слабосвязанные многопроцессорные системы
Слабосвязанные процессы время от времени обмениваются небольшими блоками данных, т.е. не предъявляют больших требований к пропускной способности межпроцессорных связей. Теоретически наиболее удачным архитектурным решением для обработки подобных процессов являются системы с массовым параллелизмом (МРР), состоящие из десятков, сотен, а иногда и тысяч процессорных узлов. Каждый узел такой системы содержит процессор и модуль памяти, в котором хранится процесс — совокупность команд, исходных и промежуточных данных вычислений, а также системные идентификаторы процесса. Узлы массово-параллельной системы объединяются коммутационными сетями самой различной формы — от простейшей двумерной решетки до гиперкуба или трехмерного тора. В отличие от архитектуры фон Неймана, передача данных между узлами коммутационной сепг происходит по готовности данных процесса, а не под управлением некоторой программы. Отсюда еще одно название подобных систем — «системы с управлением потоком данных» (иногда просто «потоковые машины»).
К достоинствам данной архитектуры относится то, что она использует стандартные микропроцессоры и обладает неограниченным быстродействием (терафлопсы).
Однако есть и недостатки — программирование коммутаций процессов является слабо автоматизированной и очень сложной процедурой. Так что для коммерческих задач и даже для подавляющего большинства инженерных приложений системы с массовым параллелизмом недоступны.
Современные и перспективные структуры
подсистем ввода-вывода '
Учитывая дальнейший рост производительности микропроцессоров, а также недостатки и ограничения топологии "общая шина", осенью 1998 г. корпорация Intel обнародовала принципиально иную архитектуру, которую скромно адресовала следующему поколению подсистем ввода-вывода — Next Generation I/O (NGVO). Собственно, это было ответом на спецификацию PCI-X.
Основными чертами новой архитектуры являются последовательный обмен данными, канальная технология ввода-вывода и матричная топология. Таким образом, в интеловской архитектуре компьютеров появляются каналы ввода-вывода, которые были на время забыты (хотя до сих пор используются в мэйнфреймах). Базовый микропроцессор не будет сам заниматься рутинной работой по обмену данными с ПУ, а станет только инициировать прием или передачу, давая соответствующие указания процессору (контроллеру) канала. Немаловажно и то, что ПУ будут иметь доступ к ОП исключительно через контроллер канала.
Топология матричной коммутации, заложенная в NGI/0, позволяет взаимодействовать всем устройствам, входящим в матрицу, по принципу "каждый с каждым". Ее задачей является распределение данных по каналам. Ключи матрицы временно образуют коммутационный канал между компьютером и ПУ, организуя обмен "точка-точка".
Благодаря этой технологии исключается проблема арбитража и конфликтов, "горячая" замена устройств становится действительно автоматической, существенно облегчается конфигурирование контроллеров (причем общая производительность не ухудшается из-за неправильного конфигурирования одного из них), расстояние между периферийным контроллером и контроллером памяти может быть увеличено до 30 м. Стоит также отметить, что трудностей с расширением при использовании этой топологии практически не существует. По некоторым данным с помощью NGI/0 к системе (серверу) можно подключить до 64 тыс. устройств.
В качестве интерфейса контроллера памяти сервера (рис. 5.4) служит главный канальный адаптер НСА (Host Channel Adapter).
Он содержит процессор прямого доступа к памяти (DMA). Для связи между матрицей коммутации и контроллерами ввода-вывода ПУ предназначены объектные канальные адаптеры ТСА (Target Channel Adapter). Канальный адаптер может подключаться к другому адаптеру или ключу. Эти ключи и образуют матрицу коммутации.
Скорость передачи для одного канала NGI/0 оценивается на уровне 1,25 - 2,5 Гбит/с, однако при увеличении числа каналов до четырех она соответственно возрастет до 10 Гбит/с.
Сразу после объявления NGI/0 по инициативе корпорации IBM был создан альянс для разработки открытого стандарта на архитектуру под названием Future I/O. Уже известно, что для данной архитектуры, как и для NGI/0 планируется использовать матричную топологию, позволяющую получить соединение типа "точка-точка". Правда в отличие от NGI/0 в спецификации Future I/O допускается применение PCI-адаптеров. Сделано это для того, чтобы продлить жизнь своему детищу - PCI-X. Максимальная производительность одного соединения может достигать 2 Гб/с по медному кабелю на расстоянии 5 - 10 м, а по оптоволоконному - до 300 м.
В начале 2000 г. спецификация должна быть утверждена, а первые результаты применения новой технологии могут быть получены не ранее 2001 г.

Рнс.5.4. Архитектура подсистемы ввода-вывода NGI/0
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Каган Б.М. Электронные вычислительные машины и системы. Учеб. пособие для вузов. - 3-е изд. - М.: Энергоатомиздат, 1991.
2. Вычислительные машины, комплексы и сети: Учебник /А.П. Пятибратов, С.Н. Беляев, Г.М. Козырева и др.; Под ред. А.П. Пятибратова. - М.: Финансы и статистика, 1991.
3. Пятибратов А.П., Гудыко Л.П., Кириченко А.А. Вычислительные системы, сети и телекоммуникации. Учебник / Под ред. А.П. Пятибратова. - М.: Финансы и статистика, 1998.
4. Вычислительные машины и системы: Учебник для вузов /В.Д. Ефремов, В.Ф. Мелехин, К.П. Дурандин и др.; Под ред. В.Д. Ефремова. - М.: Высш. шк., 1993.
5. Водяхо А.И., Горнец Н.Н., Пузанков Д.В. Высокопроизводительные системы обработки данных: Учеб. пособие для вузов. - М.: Высш. шк., 1997.
6. Компьютерные системы и сети. Учеб. пособие /В.П. Косарев и др. — М.: Финансы и статистика, 1999.
7. Информатика: Учебник /Под ред. Н.В. Макаровой. - М.: Финансы и статистика, 1997.
8. Амамия М., Танака К>. Архитектура ЭВМ и искусственный интеллект /Пер. с японск. - М.: Мир, 1996.
9. Перспективы развития вычислительной техники: В 11 кн.: Справ, пособие /Под ред. Ю.М. Смирнова. - М.:Высш. шк., 1989. - Кн.З: ЭВМ общего назначения. /Ю.С. Ломов, К.С. Ораевский, А.П. Заморин, А.И. Слуцкий.
Ю.Мячев А.А., Степанов В.Н. Персональные ЭВМ и микро ЭВМ. Основы организации: Справочник./Под ред. А.А. Мячева.-М.:Радио и связь, 1991.
П.Гук М. Процессоры Pentium II, Pentium Pro, просто Pentium. - СПб.: Питер КОМ, 1999.
12. Корнеев В.В. Параллельные вычислительные системы. - М.: «Нолидиж», 1999.
13-Леонтьев В. Новейшая энциклопедия ПК. - М.: ОЛМА-ПРЕСС, 1999.
14-Кодесов А. Новшества архитектуры Katmaill PC Week/RE № 42-43,1998.
15.Бройтман Д. Микропроцессор Pentium. Часть 11 Монитор, № 4,1993.
16.Бродин В.Б., Шагурин И.И. Микропроцессор i486. Архитектура, программиро-вание, интерфейс.-М.: «ДИАЛОГ-МИФИ», 1993.
17.Супер ЭВМ. Аппаратная и программная организация/ Пер. с англ.; Под ред. С. Фернбаха. - М.: Радио и связь, 1991.
Способ расширения кодов операции
В машинах с коротким словом практически невозможно в одном формате команды, т.е. при фиксированном назначении ее полей, кодировать большое число различных операций и одновременно иметь гибкую форму адресации операндов. Это противоречие в машинах с коротким словом преодолевается расширением кодов операций в команде. Для задания небольшой группы основных операций (арифметических и др.) используется короткий код операции, а получаемая при этом сравнительно большая адресная часть команды позволяет реализовать гибкую, например двухадресную с многими модификациями, адресацию. Для задания других операций используются более длинные (расширяемые) коды операций, при этом сокращаемая адресная часть оставляет возможность лишь для более простой, например одноадресной адресации операндов. В пределе расширяемый код операции занимает весь формат команды (безадресная команда).
Обычно в ЭВМ используется несколько структур и форматов команд разной длины.
Приведенные на рис. 2.2. структуры команд достаточно схематичны. В действительности адресные поля команд большей частью содержат не сами адреса, а только информацию, позволяющую определить действительные (исполнительные) адреса операндов в соответствии с используемыми в командах способами адресации.
Способы адресации
Интеловский 32-разрядный процессор реализует сегментную организацию оперативной памяти, при которой физический адрес ячейки памяти формируется путем сложения базового адреса сегмента и относительного адреса ячейки внутри сегмента.
Базовый адрес определяется содержимым 16-разрядного сегментного регистра и зависит от режима работы процессора. Если он работает в режиме обработки 16-разрядных данных (режим реальных адресов), то 20-разрядный базовый адрес формируется путем сдвига содержимого сегментного регистра на 4 разряда влево. Если процессор работает в режиме обработки 32-разрядных данных (защищенный режим), то 32-разрядный базовый адрес содержится в дескрипторе, выбор которого из таблицы дескрипторов осуществляется с помощью селектора — содержимого соответствующего сегментного регистра.
В качестве относительного адреса используется содержимое регистров общего назначения или эффективный адрес (ЕА), который формируется в соответствии с заданным способом адресации. ЕА является 16- или 32- разрядным и формируется в зависимости от значения полей MOD и R/M и содержимого байта SIB (для 32-разрядных адресов). В общем случае ЕА образуется путем арифметического сложения трех компонентов:
- содержимого базового регистра;
- содержимого индексного регистра;
- 8, 16, 32-разрядного смещения, заданного в одном, двух или четырех
байтах команды.
В зависимости от значений полей MOD и R/M для формирования ЕА используются все или часть этих слагаемых.
В процессоре осуществляются следующие способы адресации операндов:
- непосредственная адресация;
- регистровая адресация;
- косвенно-регистровая адресация;
- прямая адресация;
- базовая адресация;
- индексная адресация;
- базово-индексная адресация;
- базово-индексная адресация со смещением.
Способы адресации информации в ЭВМ
Существует два различных принципа поиска операндов в памяти: ассоциативный и адресный.
Ассоциативный поиск
операнда (поиск по содержанию ячейки) предполагает просмотр содержимого всех ячеек памяти для выявления кодов, содержащих заданный командой ассоциативный признак. Эти коды и выбираются из памяти в качестве искомых операндов.
Адресный поиск
предполагает, что искомый операнд извлекается из ячейки, номер которой формируется на основе информации в адресном поле команды.
Ниже мы будем рассматривать только реализацию адресного принципа поиска операнда.
Следует различать понятия "адресный код" в команде Ак и "исполнительный (физический) адрес" АИ.
Адресный код — это информация об адресе операнда, содержащаяся в команде.
Исполнительный адрес - это номер ячейки памяти, к которой производится фактическое обращение. В современных ЭВМ адресный код, как правило, не совпадает с исполнительным адресом.
Таким образом, способ адресации можно определить как способ формирования исполнительного адреса операнда Аи по адресному коду команды Ак.
Способов адресации существует много. Параметры процесса обработки информации существенно зависят от выбранного способа адресации. Одни способы адресации позволяют увеличить объём адресуемой памяти без удлинения команды, но снижают скорость выполнения операции, другие ускоряют операции над массивами данных, третьи - упрощают работу с подпрограммами и т. д.
В системах команд современных ЭВМ часто предусматривается возможность использования нескольких способов адресации операндов для одной и той же операции. Для указания способа адресации в некоторых системах команд выделяется специальное поле в команде - «метод» (указатель адресации УА), (рис. 2.3,а). В этом случае любая операция может выполняться с любым способом адресации, что значительно упрощает программирование.

Рис.2.3. Общая структура команды: а) с указателем метода адресации; б) без указателя метода адресации
Если только небольшая часть операций должна работать с различными способами адресации, то в команде поле УА не выделяется, а способ адресации определяется по коду операции, длина которого при этом возрастает (рис. 2.3,6).
Способ адресации операнда определяется многими характеристиками. Многообразие способов адресации обусловлено сочетанием различных значений этих характеристик. Укажем некоторые из этих характеристик и рассмотрим наиболее употребляемые способы адресации.
Вспомним некоторые важные для этой темы понятия и введем необходимые обозначения.
Адресуемые в командах операнды хранятся в основной памяти (ОП) и регистровой памяти (РП), (рис. 2.4).
Рис.2.4. Памяти для хранения адресуемых операндов
Каждая память (РП и ОП) имеет самостоятельную нумерацию ячеек (регистров), самостоятельные средства адресования. Пусть:
m - длина многоразрядного двоичного кода, хранимого одной ячейкой
(регистром);
nA
- длина двоичного кода адреса ячейки (Аи);
М - емкость памяти, количество ячеек в адресуемом пространстве памяти. Обычно М =
2Na ячеек.
Регистровую память и ОП можно описать следующими параметрами:
Мрп - кол-во регистров в РП;
mрп
- разрядность регистра;
АиРП - исполнительный адрес в РП;
АиОП — исполнительный адрес в ОП.
Способы организации передачи данных
В подсистемах ввода-вывода ЭВМ используются два основных способа организации передачи данных между памятью и ПУ:
программно-управляемая передача и прямой доступ к памяти (ЦДЛ).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора, который при этом выполняет специальную подпрограмму ввода-вывода. Операция ввода-вывода может инициироваться центральным процессором, т.е. текущей командой программы, или запросом прерывания от ПУ. Первый случай является простым в реализации, но при обработке команды ввода-вывода ЦП бесполезно тратит время, ожидая готовности ПУ. Это значительно снижает производительность ЭВМ. Программно-управляемая передача, инициируемая запросом прерывания от ПУ, позволяет организовать более гибкое взаимодействие между ЦП и ПУ. Предположим, что в качестве ПУ используется клавиатура (клавишное устройство), предназначенная для ввода в ЭВМ команд, инструкций и данных. Каждый раз, когда пользователь (оператор) нажимает клавишу, ПУ выдает в ЦП запрос на прерывание. ЦП приостанавливает работу по текущей программе и передает управление подпрограмме ввода-вывода. Подпрограмма обрабатывает запрос и по ее завершению ЦП возвращается к работе по текущей программе. Выполнение текущей программы продолжается до следующего нажатия клавиши, и далее процесс повторяется. В этом случае преимущество от использования прерывания очевидно.
При программно-управляемой передаче данных ЦП на все время этой передачи отвлекается от выполнения основной программы. Операция пересылки данных логически слишком проста, чтобы эффективно загружать логически сложную быстродействующую аппаратуру процессора. Вместе с тем при пересылке блока данных ЦП приходится для каждой единицы передаваемых данных (байт, слово) выполнять довольно много инструкций, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных данных, формирование адресов в памяти и т.п. В результате скорость передачи данных при пересылке блока данных под управлением процессора оказывается недостаточной. Поэтому для быстрого ввода-вывода блоков данных и разгрузки ЦП от управления операциями ввода-вывода используют прямой доступ к памяти.
Способы размещения данных в кэш-памяти
.3.2. Способы размещения данных в кэш-памяти
Существует четыре способа размещения данных в кэш-памяти: прямое распределение, полностью ассоциативное распределение, частично ассоциативное распределение и распределение секторов. Ниже подробно описан каждый способ размещения и его механизм преобразования адресов. Для того, чтобы конкретизировать описание, положим, что кэш-память может содержать 128 строк, размер строки - 16 слов, а основная память может содержать 16384 строк. Для адресации основной памяти используется 18 бит.
Из них старшие 14 показывают адрес строки, а младшие 4 бит — адрес слова внутри этой строки. При одном обращении к памяти выбирается одна строка. 128 строк кэш-памяти указываются 7-разрядными адресами.
Стековая адресация
Стековая память (стек) является эффективным элементом современных ЭВМ, реализует неявное задание адреса операнда. Хотя адрес обращения в стек отсутствует в команде, он формируется схемой управления автоматически по специальному правилу.
Стековая память,
реализующая безадресное задание операндов, является эффективным элементом архитектуры ЭВМ. Стек представляет собой группу последовательно пронумерованных регистров (аппаратный стек) или ячеек памяти, снабженных указателем стека (обычно регистром), в котором автоматически при записи и считывании устанавливается номер (адрес) первой свободной ячейки стека (вершина стека). При операции записи заносимое в стек слово помещается в свободную ячейку стека, а при считывании из стека извлекается последнее поступившее в него слово. Таким образом, в стеке реализуется правило «последний пришел - первый ушел» - магазинная адресация.
Механизм стековой адресации поясняется на рис. 4.3. Для реализации магазинной адресации используется счетчик адреса СЧА, который перед началом работы устанавливается в состояние ноль, и память (стек) считается пустой. Состояние СЧА определяет адрес первой свободной ячейки. Слово загружается в стек с входной шины Х в момент поступления сигнала записи
ЗП.
По сигналу ЗП слово Х записывается в регистр Р[СЧА], номер которого
определяется текущим состоянием счетчика адреса, после чего с задержкой D, достаточной для выполнения микрооперации записи Р[СЧА]:=Х, состояние счетчика увеличивается на единицу. Таким образом, при последовательной загрузке слова А, В и С размещаются в регистрах с адресами P[S], P[S + 1] и P[S + 2], где S — состояние счетчика на момент начала загрузки. Операция чтения слова из ЗУ инициируется сигналом ЧТ, при поступлении которого состояние счетчика уменьшается на единицу, после чего на выходную шину Y поступает слово, записанное в стек последним. Если слова загружались в стек в порядке А. В, С, то они могут быть прочитаны только в обратном
порядке С, В, А. '
В современных архитектурах процессоров и микропроцессоров стек и
стековая адресация широко используется при организации переходов к подпрограммам и возврата из них, а также в системах прерывания.
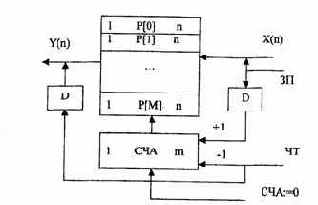
Рис.4.3. Стек с магазинной адресацией
Страничное распределение
На рис. 4.14 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами- В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами
(или блоками).
Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т.д., это позволяет упростить механизм преобразования адресов.
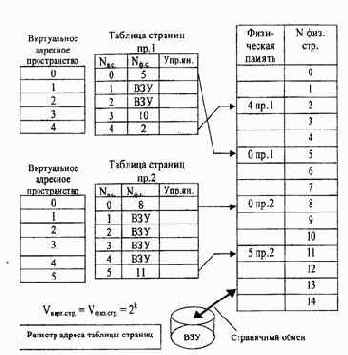
Рис.4.14. Страничное распределение памяти
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные — на диск. Смежные виртуальные страницы необязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру — таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск (ВЗУ). Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемое™ (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.
При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса.
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический.
Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
В данной ситуации может быть использовано много разных критериев выбора, наиболее популярные из них следующие:
- дольше всего не использовавшаяся страница;
- первая попавшаяся страница;
- страница, к которой в последнее время было меньше всего обращений.
В некоторых системах используется понятие рабочего множества страниц. Рабочее множество определяется для каждого процесса и представляет собой перечень наиболее часто используемых страниц, которые должны постоянно находиться в оперативной памяти и поэтому не подлежат выгрузке.
После того, как выбрана страница, которая должна покинуть оперативную память, анализируется ее - признак модификации (из таблицы страниц). Если выталкиваемая страница с момента загрузки была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то она может быть просто уничтожена, т.е. соответствующая физическая страница объявляется свободной.
Рассмотрим механизм преобразования виртуального адреса в физический при страничной организации памяти (рис. 4.15).
Виртуальный адрес при страничном распределении может быть представлен в виде пары (р, s), где р — номер виртуальной страницы процесса (нумерация страниц начинается с 0), s — смещение в пределах виртуальной страницы. Учитывая, что размер страницы равен 2 в степени k, смещение s может быть получено простым отделением k младших разрядов в двоичной записи виртуального адреса.
Оставшиеся старшие разряды представляют со бой двоичную запись номера страницы р.
При каждом обращении к оперативной памяти аппаратными средствами
выполняются следующие действия:
1.
На основании начального адреса таблицы страниц (содержимое регистра адреса таблицы страниц), номера виртуальной страницы (старшие разряды виртуального адреса) и длины записи в таблице страниц (системная константа) определяется адрес нужной записи в таблице.
2. Из записи извлекается номер физической страницы.
3. К номеру физической страницы присоединяется смещение (младшие разряды виртуального адреса.

Рис.4.16. Распределение памяти сегментами
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g — номер сегмента, as — смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Странично-сегментное распределение
Как видно из названия, данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента.
Оперативная па мять делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении.
Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс. На рис. 4.17 показана схема преобразования виртуального адреса в физический для данного метода.
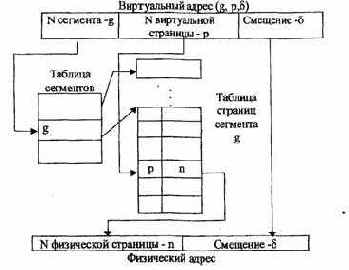
Рис.4.17. Схема преобразования виртуального адреса в физический для сегментно-страничной организации памяти
Процесс преобразования адресов посредством таблиц является достаточно длительным и, естественно, приводит к снижению производительности
системы. С целью ускорения этого процесса преобразование может осуществляться специальными аппаратными средствами, в основе которых лежит использование принципа ассоциативной памяти. Реализуемый при этом механизм получил название механизма динамического преобразования адресов (рис. 4.18).
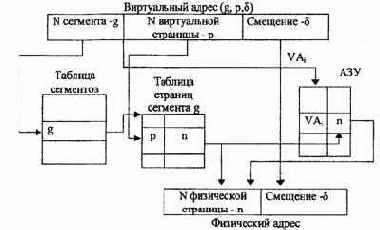
Рис.4.18. Механизм динамического преобразования адресов
Виртуальный адрес страницы VA, составленный из полей g и р, передается в ассоциативную память (буфер быстрой переадресации) в качестве поискового признака — первое поле ассоциативного ЗУ (АЗУ). Вторым полем АЗУ является физический адрес страницы в ОП. При обнаружении совпадения VAi с содержимым памяти из соответствующей ячейки АЗУ выбирается физический адрес страницы п, позволяющий сформировать полный физический адрес элемента данных, находящегося в ОП. Если совпадение не произошло, то трансляция адресов осуществляется обычными методами через таблицы сегментов и страниц. Эффективность механизма динамического преобразования адресов зависит от коэффициента «попадания», т.е.
от того, насколько редко приходится обращаться к табличным методам трансляции адресов. Учитывая принцип локальности программ и данных, можно сказать, что при первом обращении к странице, расположенной в ОП, физический адрес определяется с помощью таблиц и загружается в соответствующую ячейку АЗУ. Последующие обращения к странице выполняются с использованием АЗУ.
Свопинг
Разновидностью виртуальной памяти является свопинг. На рис. 4.19 показан график зависимости коэффициента загрузки процессора в зависимости от числа одновременно выполняемых процессов и доли времени, проводимого этими процессами в состоянии ожидания ввода-вывода.
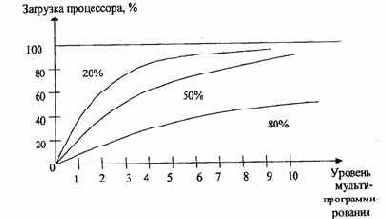
Рис. 4.19. Зависимость загрузки процессора от числа задач и интенсивности ввода-вывода
Из рисунка видно, что для загрузки процессора на 90 % достаточно всего трех счетных задач. Однако для того, чтобы обеспечить такую же загрузку интерактивными задачами, выполняющими интенсивный ввод-вывод, потребуются десятки таких задач. Необходимым условием для выполнения задачи является загрузка её в оперативную память, объем которой ограничен. В этих условиях был предложен метод организации вычислительного процесса, называемый свопингом. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс.
При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, т.е. в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
Структура и форматы команд ЭВМ
Все возможные преобразования, дискретной информации могут быть сведены к четырем основным видам:
- передача информации в пространстве (из одного блока ЭВМ в другой);
- передача информации во времени (хранение);
- логические (поразрядные) операции;
- арифметические операции.
ЭВМ, являющаяся универсальным преобразователем дискретной информации, выполняет указанные виды преобразований.
Обработка информации (решение задач) в ЭВМ осуществляется автоматически путем программного управления. Программа представляет собой алгоритм обработки информации (решение задачи), записанный в виде последовательности команд, которые должны быть выполнены машиной для получения результата.
Команда представляет собой код, определяющий операцию и данные, участвующие в операции. Команда содержит также в явной или не явной форме информацию об адресе, по которому помещается результат операции, и об адресе следующей команды.
По характеру выполняемых операций различают следующие основные группы команд:
а) команды арифметических операций над числами с фиксированной и плавающей точками;
б) команды десятичной арифметики;
в) команды логических операций;
г) команды передачи кодов;
д) команды операций ввода-вывода;
е) команды передачи управления;
ж) команды задания режима работы машины и др.
В команде, как правило, содержатся не сами операнды, а информация об адресах ячеек памяти или регистрах, в которых они находятся.
Команда в общем случае состоит из операционной и адресной частей (рис.2.2,а).
В свою очередь, эти части, что особенно характерно для адресной части, могут состоять из нескольких полей.

Рис. 2.2. Структуры команд: а) обобщенная; б) четырех-; в) трех-;
г) двух -; д) одно -; е) безадресная
Операционная часть содержит код операции (КОП), который задает вид операции (сложение, умножение и др.). Адресная часть содержит информацию об адресах операндов и результате операции, а в некоторых случаях -информацию об адресе следующей команды.
Структура команды
определяется составом, назначением и расположением полей в команде.
Форматом команды
называют ее структуру с разметкой номеров разрядов (бит), определяющих границы отдельных полей команды, или с указанием числа бит в определенных полях.
Важной и сложной проблемой при проектировании ЭВМ является выбор структуры и форматов команды, т.е. ее длины, назначения и размерности отдельных ее полей. Естественно стремление разместить в команде в возможно более полной форме информацию о предписываемой командой операции. Однако в условиях, когда в современных ЭВМ значительно возросло число выполняемых различных операций и соответственно команд (в компьютерах с CISC-архитектурой более 200 команд) и значительно увеличилась емкость адресуемой основной памяти (32, 64 Мб), это приводит к недопустимо большой длине формата команды.
Действительно, число двоичных разрядов, отводимых под код операции, должно быть таким, чтобы можно было представить все выполняемые машинные операции. Если ЭВМ выполняет М различных операций, то число разрядов в коде операции
nком > log 2 M, например, при М=200, пкоп = 8.
Если основная память содержит S адресуемых ячеек (байт), то для явного представления только одного адреса необходимо в команде иметь адресное поле для одного операнда с числом разрядов
nA > log2S, например, при S = 64 Мб, nA
= 26.
Вместе с тем для упрощения аппаратуры и повышения быстродействия ЭВМ длина формата команды должна быть согласована с выбираемой, исходя из требований к точности вычислений, длиной обрабатываемых машиной слов (операндов), составляющей для большинства применений 32 бита с тем, чтобы для операндов и команд можно было эффективно использовать одни и те же память и аппаратные средства обработки информации. Формат команды должен быть по возможности короче, укладываться в машинное слово или полуслово, а для ЭВМ с коротким словом (8-16 бит) должен быть малократным машинному слову.
Решение проблемы выбора формата команды значительно усложняется в микропроцессорах, работающих с коротким словом.
Отмечавшиеся ранее характерные для процесса развития ЭВМ расширение системы (наборы) команд и увеличение емкости основной памяти, а особенно создание микроЭВМ с коротким словом, потребовали разработки методов сокращения длины команды. При решении этой проблемы существенно видоизменилась структура команды, получили развитие различные способы адресации информации.
Проследим изменения классических структур команд.
Чтобы команда содержала в явном виде всю необходимую информацию о задаваемой операции, она должна, как это показано на рис. 2.2,6, содержать следующую информацию:
А1 , А2; - адреса операндов, А3 - адрес результата, А4 _ адрес следующей команды (принудительная адресация команд).
Такая структура приводит к большей длине команды (например, при S = 200, S = 32 Мб длина команды - 108 бит) и неприемлема для прямой адресации операндов основной памяти. В компьютерах с RISC-архитектурой четырехадресные команды используются для адресации операндов, хранящихся в регистровой памяти процессора.
Можно установить, как это принято для большинства машин, что после выполнения данной команды, расположенной по адресу К (и занимающей L ячеек), выполняется команда из (К+L)-й ячейки. Такой порядок выборки команды называется естественным. Он нарушается только специальными командами (передачи управления). В таком случае отпадает необходимость указывать в команде в явном виде адрес следующей команды.
В трехадресной команде (рис. 2.2,в) первый и второй адреса указывают ячейки памяти, в которых расположены операнды, а третий определяет ячейку, в которую помещается результат операции.
Можно условиться, что результат операции всегда помещается на место одного из операндов, например первого. Получим двухадресную команду (рис. 2.2,г), т.е. для результата используется подразумеваемый адрес.
В одноадресной команде (рис. 2.2д) подразумеваемые адреса имеют уже и результат операции и один из операндов.
Один из операндов указывается адресом в команде, в качестве второго используется содержимое регистра процессора, называемого в этом случае регистром результата или аккумулятором (Akk). Результат операции записывается в тот же регистр:
Akk :=Аkk*ОП[А1].
Наконец, в некоторых случаях возможно использование безадресных команд (рис. 2.2,е), когда подразумеваются адреса обоих операндов и результата операции, например, при работе со стековой памятью.
С точки зрения программиста, наиболее естественны и удобны трехадресные команды. Однако из-за необходимости иметь большее число разрядов для представления адресов основной памяти и кода операции длина трехадресной команды становится недопустимо большой, и ее не удается разместить в машинном слове. Следует отметить, что очень часто в качестве операндов используются результаты предыдущих операций, хранимые в регистрах машины. По указанным причинам в современных ЭВМ применяют трехадресные команды для адресации регистров.
Структура UFS
Внешне UFS очень похожа на ext2fs – те же inod'ы, блоки данных, файлы, директории… Но есть и отличия. В ext2fs имеется только одна группа inod'ов и только одна группа блоков данных для всего раздела. UFS же делит раздел на несколько зон одинакового размера, называемых группами цилиндров. Каждая зона имеет свою группу inod'ов и свою группу блоков данных, независимую ото всех остальных зон. Другим словами, inod'е описывают блоки данных той и только той зоны, к которой они принадлежат. Это увеличивает быстродействие файловой системы (головка жесткого диска совершает более короткие перемещения) и упрощает процедуру восстановления при значительном разрушении данных, поскольку, как показывает практика, обычно гибнет только первая группа inod'e. Чтобы погибли все группы… ну я даже не знаю что же такого с жестким диском нужно сделать. А! Знаю! Под пресс положить!
В UFS каждый блок разбит на несколько фрагментов фиксированного размера, предотвращающих потерю свободного пространства в хвостах файлов. Благодаря этому, использование блоков большого размера уже не кажется расточительной идей, напротив, это увеличивает производительность и уменьшает фрагментацию. Если файл использует более одного фрагмента в двух несмежных блоках, он автоматически перемещается на новое место, в наименее фрагментированный регион свободного пространства. Поэтому, фрагментация в UFS очень мала или же совсем отсутствует, что существенно облегчает восстановление удаленных файлов и разрушенных данных.
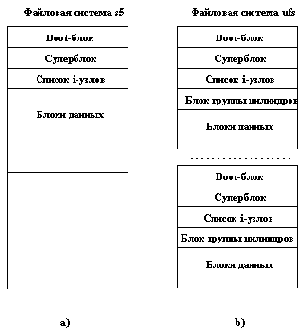
Супер-ЭВМ
— мощные, высокоскоростные вычислительные машины (системы) с производительностью от сотен миллионов до триллионов операций с плавающей запятой в секунду. Супер-ЭВМ выгодно отличаются от больших универсальных ЭВМ по быстродействию числовой обработки, а от специализированных машин, обладающих высоким быстродействием в сугубо ограниченных областях, возможностью решения широкого класса задач с числовыми расчетами.
При производительности порядка нескольких GFLOPS можно еще обойтись одним векторно-конвейерным процессором (однопроцессорные суперЭВМ). Создание высокопроизводительной супер-ЭВМ с TFLOPS-ным быстродействием по современной технологии на одном процессоре не представляется возможным. Это связано с ограничением, обусловленным конечным значением скорости распространения электромагнитных волн (300 000 км/сек), так как время распространения сигнала на расстояние нескольких миллиметров (линейный размер стороны микропроцессора) при быстродействии 100 млрд. оп/с становится соизмеримым с временем выполнения одной операции. Поэтому супер-ЭВМ с такой производительностью создаются в виде высокопараллельных многопроцессорных вычислительных систем.
В настоящее время в мире насчитывается несколько тысяч супер-ЭВМ, начиная от простых офисных до мощных: Gray Y-MP C90 (фирмы Gray Research), Cyber 205 (фирмы Control Data), VP 2000 (фирмы Fujitsu), VPP500 (фирмы Siemens) и др., производительностью несколько десятков GFLOPS.
Самый мощный компьютер мира был проанонсирован в 1998 г. Это массивно-параллельный компьютер ASCI Blue (другое название - Blue Pacific) создан совместно корпорацией IBM и Ливерморской Национальной Лабораторией Департамента Энергетики США на основе распространенной архитектуры RISC процессора IBM RS/6000 SP2.
Система ASCI Blue построена на базе 4-процеСсорных High-узлов с архитектурой SMP. Система состоит из 1464 таких узлов или, в общей сложности, из 5856 процессоров, обеспечивая пиковую производительность в 3,88 Тфлопс. Общая сумма контракта на поставку системы Составляет 94 млн. дол.
ASCI Blue побьет современный «барьер скорости вычислений», выполняя 3,9 трлн. операций в секунду, т.е. примерно в 15 тысяч раз больше, чем типичный настольный компьютер. Суммарный объем оперативной памяти составляет 2,6 Тбайт, что примерно в 80 тысяч раз больше, чем у современных ПК.
Микро-ЭВМ
по назначению можно разделить на универсальные и специализированные (рис. 1.4).
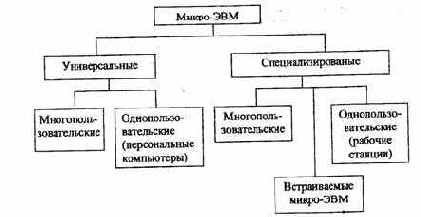
Рис. 1.4. Классификация микро-ЭВМ
Связь между функциональной и структурной организацией ЭВМ
Существуют два взгляда на построение и функционирование ЭВМ. Первый - взгляд пользователя, не интересующегося технической реализацией ЭВМ и озабоченного только получением некоторого набора функций и услуг, обеспечивающих эффективное решение его задач; второй - разработчика ЭВМ, усилия которого направлены на рациональную техническую реализацию необходимых пользователю функций. С учетом этого обстоятельства и вводятся понятия "функциональная и структурная организация компьютера.
Действительно, с точки зрения пользователя решение любой задачи на ЭВМ требует поэтапного выполнения некоторой последовательности действий: кодирования, программирования, ввода, обработки, документирования. На каждом из этих этапов учет запросов пользователя может потребовать расширения реализуемых ЭВМ функцией услуг, что решается при проектировании ЭВМ и входит в понятие функциональной организации ЭВМ.
В результате создается абстрактная модель ЭВМ, описывающая функциональные возможности машины и предоставляемые ею услуги. Функциональная организация ЭВМ в значительной степени определяется предъявляемыми к ней требованиями, уровнем подготовки потенциальных пользователей, типом решаемых ими задач, потребностями в развитии компьютера (по емкости ЗУ, разрядности, составу периферийных устройств и др.).
Предусматриваемые абстрактной моделью функции ЭВМ реализуются на основе реальных, физических средств (устройств, блоков, узлов, элементов) в рамках определенной структуры. В общем случае под структурной организацией ЭВМ понимается некоторая физическая модель, устанавливающая состав, порядок и принципы взаимодействия основных функциональных частей машины (без излишних деталей их технической реализации).
По степени детальности различают структурные схемы, составленные на уровне устройств, блоков, узлов и элементов.
Блок — функциональный компонент ЭВМ, состоящий из элементов, узлов и выполняющий операции над машинными словами или управляющий такими операциями (сумматор, блок регистров).
Устройство — наиболее крупная функциональная часть ЭВМ, состоящая из элементов, узлов, блоков и выполняющая глобальные операции над кодированными данными (запоминание, обработку, преобразование).
Блоки и устройства часто изготавливаются в виде самостоятельных конструктивов-модулей.
Функциональная организация ЭВМ играет ведущую роль и в значительной степени определяет структурную организацию машины, хотя и не дает жестких ограничений на конечную техническую реализацию структурных элементов. Вместе с тем функции и структура любого элемента находятся в диалектической взаимосвязи и взаимозависимости. С одной стороны, функциональным назначением устройства (блока, узла) ЭВМ определяется необходимый состав материальных объектов (реальных аппаратных и программных средств) и характер их взаимодействия. С другой стороны, одна и та же функция может быть реализована на совершенно разных технических средствах, а изменение состава или связей между элементами, изменение пропорций между аппаратными и программными средствами может сохранить неизменной функцию системы, сообщив ей новые свойства.
Теги и дескрипторыСамоопределяемые данные
Одним из эффективных средств совершенствования архитектуры современных ЭВМ является теговая организация памяти, при которой каждое хранящееся в памяти (или регистре) слово снабжается указателем - тегом (рис. 2.20,а). Последний определяет тип данных - целое двоичное число, число с плавающей точкой, десятичное число, адрес, строка символов, дескриптор и т.д.

Рис.2.20. Структура описания данных: а) с теговой * организацией памяти; б) дескриптор данных
В поле тега обычно указывается не только тип, но и длина (формат) и некоторые другие его параметры. Теги формируются компилятором.
Наличие тегов придает хранящимся в машине данным свойство самооп-ределяемости, вносящее принципиальные особенности в архитектуру и функционирование ЭВМ.
Отметим, что ЭВМ с теговой памятью (самоопределяемыми данными) выходит за рамки модели вычислительной машины фон Неймана, где тип (характер) данного определяется командой, использующей данное в качестве операнда. В обычных ЭВМ, соответствующих классической модели фон Неймана, тип данных — операндов и их формат задаются кодом операции команды, а в раде случаев размер (формат) определяется следующими полями команды.
Теговая организация памяти позволяет достигнуть инвариантности команд относительно типов и форматов операндов, что приводит к значительному сокращению набора команды машины. Это упрощает и делает более регулярной структуру процессора, облегчает работу программиста, в том числе при отладке программ, упрощает компиляторы и сокращает затраты времени на компиляцию (отпадает необходимость выбора типа команды в зависимости от типа данных), облегчает обнаружение ошибок, связанных с некорректным заданием типов данных (например, при попытке сложить адрес с числом с плавающей точкой).
Теговая организация памяти способствует реализации принципа независимости программ от данных.
И, наконец, нечто неожиданное. Использование тегов приводит к экономии памяти, так как в программах обычных машин имеется большая информационная избыточность на задание типов и размеров операндов при их использовании несколькими командами.
В качестве недостатка теговой организации памяти можно указать на некоторое замедление работы процессора из-за того, что установление соответствия типа команды типу данных, в обычных ЭВМ выполняемое на этапе компиляции, при использовании тегов переносится на этап выполнения программы.
В архитектуре некоторых ЭВМ используются
дескрипторы — служебные слова, содержащие описание массивов данных и команд, причем дескрипторы могут употребляться как в машинах с теговой организацией памяти, так и без тегов.
Дескриптор содержит сведения о размере массива данных, его местоположении (в ОП или внешней памяти), адресе начала массива, типе данных, режиме защиты данных (например, запрет записи в ячейки массива) и некоторых других параметрах данных. Отметим, что задание в дескрипторе размера массива позволяет контролировать выход за границу массива при индексации его элементов. На рис. 2.20,6 в качестве примера представлен один из видов дескрипторов - дескриптор данных.
Дескриптор содержит специфический тег — ТДС, указывающий, что данное слово является дескриптором определенного вида; Ук — группа указателей; А — адрес начала массива данных; L — длина массива; Х — индекс.
Использование в архитектуре ЭВМ дескрипторов подразумевает, что обращение к информации в памяти производится через дескрипторы, которые при этом можно рассматривать как дальнейшее развитие аппарата косвенной адресации.
Адресация информации в памяти может осуществляться с помощью цепочки дескрипторов, при этом реализуется многоступенчатая косвенная адресация. Более того, сложные многомерные массивы данных (таблицы и т. п.) эффективно описываются древовидными структурами дескрипторов.
Технические и эксплуатационные характеристики ЭВМ
Основным техническим параметром ЭВМ является её производительность. Этот показатель определяется архитектурой процессора, иерархией внутренней и внешней памяти, пропускной способностью системного интерфейса, системой прерывания, набором периферийных устройств в конкретной конфигурации, совершенством операционной системы и т.д.
Различают следующие виды производительности:
Техника восстановления файлов
Начнем с грустного. Поскольку, при удалении файла ссылки на 12первых блоков и 3 блока косвенной адресации необратимо затираются, автоматическое восстановление данных невозможно в принципе. Найти удаленный файл можно только по его содержимому. Искать, естественно, необходимо в свободном пространстве. Вот тут-то нам и пригодятся карты, расположенные за концом описателя группы цилиндров.
Если нам повезет и файл окажется нефрагментированным (а на UFS, как уже отмечалось, фрагментация обычно отсутствует или крайне невелика), остальное будет делом техники. Просто выделяем группу секторов и записываем ее на диск, но только ни в коем случае не на сам восстанавливаемый раздел! (Например, файл можно передать на соседнюю машину по сети). К сожалению, поле длины файла безжалостно затирается при его удалении и актуальный размер приходится определять "на глазок". Звучит намного страшнее, чем выглядит. Неиспользуемый хвост последнего фрагмента всегда забивается нулями, что дает хороший ориентир. Проблема в том, что некоторые типы файлов содержат в своем конце некоторое количество нулей, при отсечении которых их работоспособность нарушается, поэтому тут приходится экспериментировать.
А если файл фрагментирован? Первые 13 блоков (именно блоков, а не фрагментов!) придется собирать руками. В идеале это будет один непрерывный регион. Хуже, если первый фрагмент расположен в "чужом" блоке (т. е. блоке частично занятом другим файлом), а оставшиеся 12 блоков находятся в одном или нескольких регионах. Вообще-то достаточно трудно представить себе ситуацию, в которой первые 13 блоков были бы сильно фрагментированы (а поддержка фоновой дефрагментации в UFS на что?) Такое может произойти только при интересной "перегруппировке" большого количеств файлов, что в реальной жизни практически никогда не встречается (ну разве только что вы задумали навести порядок на своем жестком диске). Короче, будем считать, что 13'й блок файла найден. В массив непосредственной адресации он уже не влезает (там содержатся только 12 блоков) и ссылка на него, как и на все последующие блоки файла, должна содержаться в блоках косвенной адресации, которые при удалении файла помечается как свободные но не затирается, точнее затираются, но не сразу.
Большинство файлов обходятся только одним косвенным блоком, что существенно упрощает нашу задачу.
Как найти этот блок на диске? Вычисляем смещение 13'го блока файла от начала группы цилиндров, переводим его в фрагменты, записываем получившееся число задом наперед (так, чтобы младшие байты располагались по меньшим адресами) и осуществляем контекстный поиск в свободном пространстве.
Отличить блок косвенной адресации от всех остальных типов данных очень легко — он представляет собой массив указателей на блоки, а в конце идут нули. Остается только извлечь эти блоки с диска и записать их в файл, обрезая его по нужной длине. Внимание! Если вы нашли несколько "кандидатов" в блоки косвенной адресации, это означает, что 13'й блок удаленного файла в разное время принадлежал различным файлам (а так, скорее всего и будет). Не все косвенные блоки были затерты, вот ссылки и остались. Как отличить "наш" блок от "чужих"? Если хотя бы одна из ссылок указывает на уже занятый блок данных (что легко определить по карте), такой блок можно сразу откинуть. Оставшиеся блоки перебираются вручную до получения работоспособной копии файла. Имя файла (если оно еще не затерто) можно извлечь из директории. Естественно, при восстановлении нескольких файлов мы не можем однозначно сказать какое из имен какому файлу принадлежит, тем не менее это все же лучше, чем совсем ничего. Директории восстанавливаются точно так же как и обыкновенные файлы, хотя по правде говоря, в них кроме имен файлов нечего восстанавливать…
Типы адресов
Для идентификации переменных и команд используются символьш имена (метки), виртуальные адреса и физические адреса (рис. 4.9).
Символьные имена присваивает пользователь при написании программ на алгоритмическом языке или ассемблере.
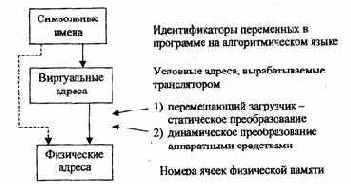
Рис.4.9. Типы адресов
Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Так как во время трансляции в общем случае неизвестно, в какое место ОП будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса (программы) называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство. Максимальный размер виртуального адресного пространства ограничивается разрядностью адреса, присущей данной архитектуре компьютера и, как правило, не совпадает с объемом физической памяти, имеющимся в компьютере.
Физические адреса соответствуют номерам ячеек ОП, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами.
В первом случае замену виртуальных адресов на физические делает специальная системная программа — перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной транслятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая её с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизменном виде в виртуальных адресах, при этом ОС фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к ОП выполняется преобразование виртуального адреса в физический.
Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку. Вместе с тем использование загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае — каждый раз при обращении по " данному адресу.
В некоторых случаях (обычно в специализированных системах), когда заранее точно известно, в какой области ОП будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах.
Все методы управления памятью могут быть разделены на два класса (рис. 4.10):
- методы распределения ОП без использования внешней памяти (дискового пространства);
- методы распределения памяти с использованием дискового пространства;
Рассмотрим вначале первую группу методов.
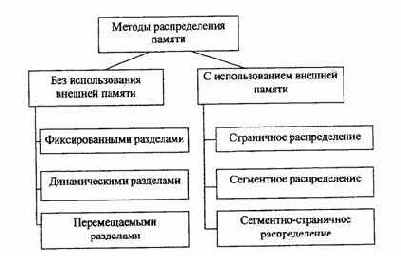
Рис.4.10. Методы распределения памяти
Типы данных
Основными типами данных в компьютерах являются байты, слова, двойные слова и квадрослова (рис. 2.12).

Рис. 2.12. Основные типы данных
Каждый из представленных на рис. 2.12 типов данных может начинаться с любого адреса: это означает, что слово не обязано начинаться с четного адреса; двойное слово - с адреса, кратного 4 и т.д. Таким образом достигается максимальная гибкость структур данных и эффективность использования памяти.
Однако обмен данными между процессором и памятью осуществляется в Pentium через 64-битовую ШД (i486 - 32 р.) и для достижения максимальной производительности этого обмена желательно выравнивать слова по чётным адресам, двойные слова - по адресам, кратным 4 и т.д.
На базе основных типов данных строятся все остальные тишя, распознаваемые командами процессора.
Типы и характеристики стандартных шин
Типы и характеристики стандартных шин, используемых в настоящее время, приведены в табл. 5.1.
Таблица 5.1 Характеристики стандартные шин
| Тип шины | Разрядность шины (бит) | Тактовая частота (МГц) | Пропускная способность (Мб/сек) | ||||
| ISA | 16 | 8 | 16 | ||||
| EISA | 32 | 8 | 33 | ||||
| МСА | 32 | 10 | - | ||||
| VLB(VESA) | 32 | 40 | 130 | ||||
| VLB2 | 64* | 400* | |||||
| PCI | 32 | 33,66 | 120, 133 | ||||
| VME32 | 32 | - | 32 | ||||
| VME64 | 64 | - | 160 | ||||
| Sbus | 32,64 | 20,25 | 80,100 | ||||
| Mbus | 64 | 50 | 125 (400) | ||||
| XDBus | 64 | - | 310(400) | ||||
| AGP | 32 | 133 | 533 | ||||
| PCI-X | 64 | 133 | 1060 |
Системная шина ISA (Industry Standard Architecture) впервые стала применяться в ПК IBM PC/AT на базе процессора i2826. Данная шина позволяет передавать параллельно 16 бит данных и обращаться к 16 Мбайт системной памяти. В современных компьютерах используется как шина ввода/вывода для организации связи с медленно действующими периферийными устройствами.
С появлением процессоров i386, i486 системная шина ISA стала "узким местом" ПК на их основе. Другая системная шина EISA (Extended Industry Standard Architecture), разработанная в 1988 году, обеспечивает адресное пространство в 4 Гбайта, 32-битовую передачу данных, тактируется частотой около 8 Мгц, имеет максимальную теоретическую скорость передачи данных 33 Мбайт/с и совместима с шиной ISA.
Шина МСА также обеспечивает 32-разрядную передачу данных, тактируется частотой 10 МГц, но не совместима с шиной ISA и используется только в компьютерах компании IBM.
Локальная шина VESA-Local-Bus (VLB) предназначалась для увеличения быстродействия видеоадаптеров и контроллеров дисковых накопителей. Она подключалась непосредственно к процессору i486, и только к нему. После появления процессора Pentium ассоциация VESA приступила к работе над новым стандартом VLB версии 2, который предусматривает использование 64-битовой шины данных и увеличение количества разъемов расширения. Ожидаемая скорость передачи данных — до 400 Мбайт/сек.
Шина PCI (Peripheral Component Interconnection) в первом варианте использовалась как локальная шина и предназначалась для тех же целей, что и предыдущая шина (VLB). В действующем втором варианте шина PCI относится к шинам ввода/вывода. В данном случае соединение шин центрального процессора и PCI осуществляется через так называемую PCI-перемычку, мост PCI или контроллер, которые согласуют шину центрального процессора с шиной PCI. Это означает, что PCI может работать с процессорами различных платформ и поколений.
Шина УМЕ приобрела большую популярность как шина ввода/вывода в рабочих станциях и серверах на базе RISC-процессоров. Эта шина высоко стандартизирована, имеет несколько версий этого стандарта: VME32,
VME64.
В однопроцессорных и многопроцессорных рабочих станциях и серверах на основе микропроцессоров архитектуры SPARC одновременно используются несколько типов шин: Sbus, Mbus и XDBus, причем шина Sbus применяется в качестве шины ввода/вывода, а Mbus и XDBus — в качестве шин для объединения большого числа процессоров и памяти.
Спустя почти четыре года с того времени, когда шина PCI стала стандартом в настольных ПК, корпорация Intel объявила о новой, предназначенной исключительно для графики, шине AGP, способной повысить производительность видео-, 2D-, ЗD-пpилoжeний. Шина AGP (Accelerated Graphics Port) относится к локальным шинам. Для использования технологии AGP необходим набор микросхем Intel 440LX (появившийся в 1997 году), который позволяет разгрузить сравнительно "узкую" (133 Мб/с) шину PCI от жадного на ресурсы видеоадаптера и подключить последний к специально предназначенной для него более "широкой" (528 Мб/с) шине AGP.
На долю же PCI ос таются более медленные устройства, функционирование которых существенно улучшается благодаря отключению от шины более быстродействующих устройств, то и дело создающих "пробки" в стремительном потоке данных. Набор 440LX не только имеет поддержку AGP, но и допускает использование в машинах на базе Pentium II быстродействующей памяти SDRAM, которая обеспечивает более высокую производительность, чем ОЗУ типа EDO DRAM, применяемое в машинах Pentium II со старым набором микросхем 440 FX. Конструктивно 440 LX состоит из двух устройств: микросхемы 82443LX (РАС или PCI AGP Controller) и многофункционального моста 82371АВ (PIIX4 или PCI, ISA, IDE Accelerator).
В целом же шинная архитектура настольного ПК нового (на ближайшие два-три года) поколения содержит несколько шин (рис. 5.3) с различной пропускной способностью: шины (1 Гб/с), соединяющей ядро Pentium II с кэш-. памятью второго уровня, трех шин (528 Мб/с), соединяющих новый набор AGPset с ядром процессора, SDRAM и графическим акселератором, а также шины PCI (133 Мб/с).
Применение такой шиной организации увеличивает быстродействие компьютеров при выполнении целочисленных операций, действий с плавающей запятой и работе с мультимедиа-приложениями.
В 1998 году три крупнейшие компьютерные компании — Compaq, Hewlett-Packard и IBM — разработали новую спецификацию — расширение шины PCI, названную PCI-X, которая работает на тактовой частоте 133 МГц. Шина PCI-X обладает обратной совместимостью с PCI, требует нового набора микросхем Intel 450 NX, кроме того, благодаря новой схеме обмена регистр-регистр достигается пропускная способность 1,06 Гб/с (8 Гбит/с), что обеспечивает почти шестикратный выигрыш в производительности. В первую очередь PCI-X предназначена для подключения высокопроизводительных адаптеров типа Gigabit Ethernet, Ultra 3SCSI и Fibre Channel (FC-AL).
Рис.5.3. Шинная архитектура ПК на базе набора микросхем 440LX
Указатель команд
Указатель команд (рис. 3.5) представляет собой 32-разрядный регистр с именем EIP, содержимое которого используется в качестве смещения при определении адреса следующей выполняемой команды. Смещение задается относительно базового адреса сегмента команд CS. Младшие 16 бит (0 — 15) содержат 16-разрядный указатель команд с именем IP, который используется при 16-разрядной адресации.

Рис. 3.5. Структура регистра указателя команд
Указатель команд непосредственно программисту недоступен. Его содержимое изменяется при выполнении команд передачи управления и прерываний.
Унифицированные
(не зависящие от типа ПУ) форматы данных, которыми ПУ обмениваются с ядром ЭВМ, в том числе унифицированный формат сообщения, которое ПУ посылает в ядро о своем состоянии. Преобразование унифицированных форматов данных в индивидуальные, приспособленные для отдельных ПУ, производится в самих ПУ, точнее, в блоках управления ПУ (контроллерах, адаптерах).
(не зависящие от типа ПУ) формат и набор команд
процессора для операций ввода-вывода. Операция ввода-вывода с любым ПУ представляет для процессора просто операцию передачи данных независимо от особенностей принципа действия данного ПУ, типа его носителя и т.п.
Унификация распространяется на семейство (ряд, систему) моделей ЭВМ.
Для обеспечения параллельной во времени работы ПУ с выполнением программы процессором схемы управления вводом-выводом отделяют от процессора и придают им достаточную степень автономности.
Многие функции управления операциями ввода-вывода, как например управление прямым доступом к памяти, являются общими, они не зависят от типа ПУ. Другие являются специфичными для данного типа устройств.
Выполнение общих функций возлагают на общие для групп ПУ унифицированные устройства — контроллеры прямого доступа к памяти, процессоры (каналы) ввода-вывода, а специфических — на специализированные для данного типа ПУ электронные блоки управления (адаптеры).
Унифицированный интерфейс,
т.е. унифицированный по составу и назначению набор линий и шин, унифицированные схемы подключения, сигналы и алгоритмы (протоколы) управления обменом информацией между ПУ и ядром ЭВМ.
Универсальные многопользовательские ЭВМ
- это мощные микро ЭВМ, оборудованные несколькими видеотерминалами и функционирующие в режиме разделения времени, что позволяет эффективно работать на них сразу нескольким пользователям. Это универсальные серверы
(Server) компьютерных сетей, обрабатывающие запросы от всех станций сети.
Персональные компьютеры (ПК)
— однопользовательские микроЭВМ, удовлетворяющие требованиям общедоступности и универсальности применения.
Специализированные ЭВМ
ориентированы на решение определенного (постоянного) класса задач в течение периода своей эксплуатации. Ориентация специализированных ЭВМ осуществляется различными способами: специальной аппаратурной организацией самих ЭВМ или их внешних связей;
созданием для ЭВМ специального программного обеспечения; введением дополнительных аппаратных блоков, .расширяющих те или иные функции, возлагаемые на ЭВМ, и др. Сферы использования таких ЭВМ как в нашей стране, так и за рубежом имеют устойчивую тенденцию к расширению. Можно выделить следующие основные области применения специализированных ЭВМ: промышленное производство и транспорт; военная техника и оборона; непромышленная сфера.
Примером специализированных однопользовательских микро-ЭВМ, ориентированных для выполнения определенного круга задач (графических, инженерных, издательских и др.), являются
рабочие станции (Work Station).'
Специализированные серверы,
осуществляющие управление базами и архивами данных, многопользовательскими терминалами, поддерживающими факсимильную связь, электронную почту и др., относятся к классу специализированных многопользовательских микро-ЭВМ.
Встраиваемые микро-ЭВМ
входят составным элементом в промышленные и транспортные системы, технические устройства и аппараты, бытовые приборы. Они способствуют существенному повышению их эффективности функционирования, улучшению технико-экономических и эксплуатационных характеристик.
Персональный компьютер
для удовлетворения требованиям общедоступности и универсальности применения должен иметь следующие характеристики:
- малую стоимость, находящуюся в пределах доступности для индивидуального покупателя;
- автономность эксплуатации без специальных требований к условиям окружающей среды;
- гибкость архитектуры, обеспечивающую ее адаптивность к разнообразным применениям в сфере управления, науки, образования, в быту;
- «дружественность» операционной системы и прочего программного обеспечения для пользователя;
-
высокую надежность работы (более 5000 ч. наработки на отказ).
Наибольшей популярностью в настоящее время пользуется ПК архитектурного направления (платформы) IBM с микропроцессорами фирмы Intel. Данное направление имеет большое количество клонов, т.е. аналогичных компьютеров, выпускаемых различными фирмами США, Западной Европы, России, Японии и др.
Существенно им уступают по популярности ПК направления DEC с микропроцессорами фирмы Motorola, занимающие 2-е место.
В начале 90-х годов мировой парк компьютеров составлял примерно 150 млн.шт., из них около 90 % — это персональные компьютеры. В их числе более 100 млн.шт. (около 75 % всех ПК) типа IBM PC, типа DEC около 5 млн.шт.
Классификация ПК по конструктивным особенностям показана на рис. 1.5.
Рис. 1.5. Классификация персональных компьютеров по конструктивным особенностям
Переносные компьютеры
— быстроразвивающийся подкласс персональных компьютеров. По прогнозам специалистов в 2000 г. около 80 % пользователей будут использовать именно переносные машины.
Переносные компьютеры весьма разнообразны:
- мощные переносные компьютеры (рабочие станции) массой до 15 «от., носят жаргонное название Nomadic - кочевник;
- портативные (наколенные) компьютеры типа «LapTop» массой 5-Ююг;
- компьютеры-блокноты (Note Book и Sub Note Book, их называют также и Omni Book - «вездесущие») массой 1,5-4 кг;
- карманные компьютеры (Palm Top - «наладонные») имеют массу до 300 г;
- электронные секретари (PDA - Personal Digital Assistent, иногда их называют Hand Help - ручной помощник) массой не более 0,5 кг, но с более широкими возможностями, чем у Palm Top.
Универсальный сервер
— это компьютер, выделенный для обработки запросов от всех станций вычислительной сети, предоставляющий этим станциям доступ к общим системным ресурсам (вычислительным мощностям, базам данных, библиотекам программ, принтерам, факсам и др.) и распределяющий эти ресурсы.
Специализированные серверы
используются для устранения наиболее «узких» мест в работе сети: создание и управление базами и архивами данных, поддержка многоадресной факсимильной связи и электронной почты, управление многопользовательскими терминалами (принтером, плоттером и Профайл-сервер используется для работы с файлами данных, имеет объемные дисковые ЗУ, часто на отказоустойчивых дисковых массивах RAID.
Архивационный сервер (сервер резервного копирования) предназначен для резервного копирования информации, использует накопители на магнитной ленте (стриммеры) со сменными картриджами.
Факс-сервер, почтовый сервер - выделенные компьютеры для организации эффективной многоадресной факсимильной связи или электронной почты.
Рабочая станция (Work station), по определению экспертов IDC " (International Data Corporation), - это однопользовательская система с мощным процессором и многозадачной ОС, имеющая развитую графику с высоким разрешением, большую дисковую и оперативную память и встроенные сетевые средства.
Рабочие станции (WS) появились на рынке ЭВМ почти одновременно с ПК и находились впереди по своим вычислительным возможностям. Это в значительной мере и определяло их область применения и проблемную ориентацию за последние 10 лет: автоматизированное проектирование, банковское дело, управление производством, разведка и добыча нефти, связь, издательская деятельность и др. Стоимость таких рабочих станций на много превышала стоимость ПК.
Переломным моментом в развитии WS стало появление новой архитектуры микропроцессоров - RISC, позволившей резко поднять производительность ЭВМ. Прогресс технологии привел к тому, что цены на WS упали до уровня ПК, а порой даже ниже.
Выяснилось, что работать за новыми WS проще, чем за персональными компьютерами (десятилетия упорного труда инженеров и программистов не прошли даром). Современная рабочая станция - это не просто большая вычислительная мощность. Это тщательно сбалансированные возможности всех подсистем машины, чтобы ни одна из них не стала «бутылочным горлышком», сводя на нет преимущества других. Рабочая станция стала местом для эффективной, плодотворной работы
пользователя.
Бесспорным лидером на мировом рынке рабочих станций является американская фирма Sun Microsystems, она контролирует 40 % этого рынка (Н.Р. - 20 %, IBM - 7 %, DEC - 11 %). Архитектура SPARC, разработанная фирмой Sun и использующаяся в её машинах, стала фактически стандартом де-факто. Компьютеры этой архитектуры составляют более 75 % среди всех RISC-машин. Уже несколько десятков фирм в Америке, Европе, Японии производят SPARC-совместимые машины.
Традиционно доминирующей ОС на рынке WS была система Unix и ей подобные системы (Solaris и др.). В частности в 1991 г. 92,6 % рабочих станций продавалось именно с этой ОС. В последнее время появились два фактора, которые могут поколебать положение Unix на рынке WS. С появлением новых WS фирмы DEC на базе процессоров Alpha ожидается некоторый рост использования операционной системы VAX VMS.
Однако главным конкурентом является ОС Windows NT. Фирма HP в 1997 г. представила новую серию недорогих высокопроизводительных рабочих станций Kayak, построенных на основе процессора Pentium II корпорации Intel и работающих под управлением ОС Windows NT. Корпорация Intel проявляет повышенный интерес к этому типу платформ, направляет усилия на разработку комплектов микросхем, памяти, графики и других продуктов VAX VMS.
Такое развитие событий не сулит ничего хорошего рабочим станциям Unix-стандарта, которые уступают рынок NT-системам пядь за пядью на протяжении вот уже более пяти лет.
Восстановление удаленных файлов под BSD
крис касперски
статья описывает структуру файловых систем типа FFS/UFS1/UFS2 и рассказывает о методиках ручного восстановления удаленных файлов. материал ориентирован на квалифицированных пользователей, администраторов и системных программистов, работающих под BSD-подобными системами.
командной строке посвящается…
Время реакции
— время между появлением запроса прерывания и моментом прерывания текущей программы. На рис. 3.11 приведена упрощенная временная диаграмма процесса прерывания.

Рис.3.11. Упрощенная временная диаграмма процесса прерывания
Для одного и того же запроса задержки в исполнении прерывающей программы зависят от того, сколько программ со старшим приоритетом ждут обслуживания, поэтому время реакции определяют для запроса с наивысшим приоритетом (tр).
Время реакции зависит от того, в какой момент допустимо прерывание. Большей частью прерывание допускается после окончания текущей команды. В этом случае время реакции определяется в основном длительностью выполнения команды.
Это время реакции может оказаться недопустимо большим для ЭВМ, предназначенных для работы в реальном масштабе времени. В таких машинах часто допускается прерывание после любого такта выполнения команды (микрокоманды). Однако при этом возрастает количество информации, подлежащей запоминанию и восстановлению при переключении программ, так как в этом случае необходимо сохранять также и состояние в момент прерывания счетчика тактов, регистра кода операции и некоторых других узлов, поэтому такая организация прерывания возможна только в машинах с быстродействующей сверхоперативной памятью.
Имеются ситуации, в которых желательно немедленное прерывание. Если аппаратура контроля обнаружила ошибку, то целесообразно сразу же прервать операцию, пока ошибка не оказала влияние на следующие такты работы программы.
>>> Врезка чем восстанавливать?
Копания Stellarinfo (stellarinfo.com) выпустила утилиту "Phoenix", предназначенную для восстановления данных и поддерживающую практически все популярные файловые системы, которые только известны на сегодняшний день (и UFS в том числе). Демонстрационную копию можно сказать по адресу http://www.stellarinfo.com/spb.exe. Обратите внимание на расширение файла. Это exe. Судя по графе "Platform Supported" он рассчитан на BSD. Ага, так он в BSD и запустится! Потребуется устанавливать в систему дополнительный винчестер с рабочей Windows и инсталлировать Phoenix поверх нее. Под WindowsPE он работать отказывается… На Windows 2000 запускается, но при попытке анализа заведомо исправного раздела падает с воплем о критической ошибке. На других системах я его не проверял. Тем не менее, ссылку на файл все-таки даю. Во-первых, пусть все знают, что это за зверь и особых надеж на него не возлагают, а во-вторых, не исключено что у кого-то он все-таки сработает.

это основная файловая система для
UFS (расшифровывается как UNIX File System) — это основная файловая система для BSD-систем, устанавливаемая по умолчанию. Многие коммерческие UNIX'ы также используют либо саму UFS, либо нечто очень на нее похожее. В противоположность ext2fs, исхоженной вдоль и поперек, UFS крайне поверхностно описана в доступной литературе и единственным источником информации становятся исходные тексты, в которых не так-то просто разобраться! Существует множество утилит, восстанавливающих уничтоженные данные (или во всяком случае пытающихся это делать), но на проверку все они оказываются неработоспособными, что в общем-то и неудивительно, поскольку автоматическое восстановление удаленных файлов под UFS невозможно в принципе. Тем не менее, это достаточно легко сделать вручную, если, конечно, знать как.
Выборка широким словом
Прямой способ сокращения числа обращений к ОП состоит в организации выборки широким словом.
Этот способ основывается на свойстве локальности данных и программ. При выборке широким словом за одно обращение к ОП производится одновременная запись или считывание нескольких команд или слов данных из «широкой» ячейки. Широкое слово заносится в буферную память (кэш-память) или регистр, где оно расформировывается на отдельные команды или слова данных, которые могут последовательно использоваться процессором без дополнительных обращений к ОП.
В системах с кэш-памятью первого уровня ширина шин данных ОП часто соответствует ширине шин данных кэш-памяти, которая во многих случаях имеет физическую ширину шин данных, соответствующую количеству разрядов в слове. Удвоение и учетверение ширины шин кэш-памяти и ОП удваивает или учетверяет соответственно полосу пропускания системы памяти.
Реализация выборки широким словом вызывает необходимость мультиплексирования данных между кэш-памятью и процессором, поскольку основной единицей обработки данных в процессоре все еще остается слово. Эти мультиплексоры оказываются на критическом пути поступления информации в процессор. Кэш-память второго уровня несколько смягчает эту проблему, т.к. в этом случае мультиплексоры могут располагаться между двумя уровнями кэш-памяти, т.е. вносимая ими задержка не столь критична. Другая проблема, связанная с увеличением разрядности памяти, заключается в необходимости определения минимального объема (инкремента) памяти для поэтапного её расширения, которое часто выполняется самими пользователями во время эксплуатации системы. Удвоение или учетверение ширины памяти приводит к удвоению или учетверению этого минимального инкремента. Кроме того, имеются проблемы и с организацией коррекции ошибок в системах с широкой памятью.
Примером организации широкой ОП является система Alpha AXP21064, в которой кэш второго уровня, шина памяти и сама ОП имеют разрядность 256 бит.
Расслоение обращений
Другой способ повышения пропускной способности ОП связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются последовательные обращения к различным физическим модулям. Обращения к различным модулям могут перекрываться, и таким образом образуется своеобразный конвейер. Эта процедура носит название расслоения памяти.
Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Известно несколько вариантов организации расслоения. Наиболее часто используется способ расслоения обращений за счет расслоения адресов. Этот способ основывается на свойстве локальности программ и данных, предполагающем, что адрес следующей команды программы на единицу больше адреса предыдущей (линейность программ нарушается только командами перехода). Аналогичная последовательность адресов генерируется процессором при чтении и записи слов данных. Таким образом, типичным случаем распределения адресов обращений к памяти является последовательность вида а, а+ 1, а + 2,... Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а+ 1, а + 2,... будут размещаться в блоках 0, 1,2,... Такое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида

где В - к-разрядный адрес модуля (младшая часть адреса) и С - п-разрядный адрес ячейки в модуле В (старшая часть адреса).
Принцип расслоения обращений иллюстрируется на рис. 4.20,а. Все программы и данные «размещаются» в адресном пространстве последовательно. Однако ячейки памяти, имеющие смежные адреса, находятся в различных физических модулях памяти. Если ОП состоит из 4-х модулей, то номер модуля кодируется двумя младшими разрядами адреса. При этом полные т-разрядные адреса 0, 4, 8,... будут относиться к блоку 0, адреса 1, 5, 9, ... - к блоку 1, адреса 2, 6, 10,...
— к блоку 2 и адреса 3, 7, 11,... - к блоку 3. В результате этого последовательность обращений к адресам 0, 1, 2, 3, 4, 5, ... будет расслоена между модулями 0,1,2,3,0,1,....
Поскольку каждый физический модуль памяти имеет собственные схемы управления выборкой, можно обращение к следующему модулю производить, не дожидаясь ответа от предыдущего. Так на временной диаграмме (рис. 4.20,6) показано, что время доступа к каждому модулю составляет т = 4Т, где Т = ti+1-ti - длительность такта. В каждом такте следуют непрерывно обращения к модулям памяти в моменты времени t1, t2, t3 ... .
При наличии четырех модулей темп выдачи квантов информации из памяти в процессор будет соответствовать одному такту Т, при этом скорость выдачи информации из каждого модуля в четыре раза ниже.
Задержка в выдаче кванта информации относительно момента обращения также составляет 4Т, однако задержка в выдаче каждого последующего кванта относительно момента выдачи предыдущего составит Т.
При реализации расслоения по адресам число модулей памяти может быть произвольным и необязательно кратным степени 2. В некоторых компьютерах допускается произвольное отключение модулей памяти, что позволяет исключать из конфигурации неисправные модули.
В современных высокопроизводительных компьютерах число модулей обычно составляет 4 -16, но иногда превышает 64.
Так как схема расслоения по адресам базируется на допущении о локальности, она дает эффект в тех случаях, когда это допущение справедливо, т.е. при решении одной задачи.
Для повышения производительности мультипроцессорных систем, работающих в многозадачных режимах, реализуют другие схемы, при которых различные процессоры обращаются к различным модулям
памяти. Необходимо помнить, что процессоры ввода-вывода также занимают циклы памяти и вследствие этого могут сильно влиять на производительность системы. Для уменьшения этого влияния обращения центрального процессора и процессоров ввода-вывода можно организовать к разным модулям памяти.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контроллеров памяти позволяют модулям памяти (или группам расслоенных модулей памяти) работать независимо.
Если система памяти разработана для поддержки множества независимых запросов (как это имеет место при работе с кэш-памятью, при реализации многопроцессорной и векторной обработки), эффективность системы будет в значительной степени зависеть от частоты поступления независимых запросов к разным модулям. Обращения по последовательным адресам, или в более общем случае обращения по адресам, отличающимся на нечетное число, хорошо обрабатываются традиционными схемами расслоения памяти. Проблемы возникают, если разница в адресах последовательных обращений четная. Одно из решений, используемое в больших компьютерах, заключается в том, чтобы статистически уменьшить вероятность подобных обращений путем значительного увеличения количества модулей памяти. Например, в суперкомпьютере NEC SX/3 используются 128 модулей памяти.
Прямое уменьшение числа конфликтов за счет организации чередующихся обращений к различным модулям памяти может быть достигнуто путем размещения программ и данных в разных модулях. Доля команд в программе, требующих ссылок к находящимся в ОП данным, зависит от класса решаемой задачи и от архитектурных особенностей компьютера. Для
большинства ЭВМ с традиционной архитектурой и задач научно-технического характера эта доля превышает 50 %. Поскольку обращения к командам и элементам данных чередуются, то разделение памяти на память команд и память данных повышает быстродействие машины подобно рассмотренному выше механизму расслоения. Разделение памяти на память команд и память данных широко используется в системах управления или обработки сигналов. В подобного рода системах в качестве памяти команд нередко используются постоянные запоминающие устройства (ПЗУ), цикл которых меньше цикла устройств, допускающих запись, это делает разделение программ и данных весьма эффективным.Следует отметить, что обращения процессоров ввода-вывода в режиме прямого доступа в память логически реализуются как обращения к памяти данных.
Выбор той или иной схемы расслоения для компьютера (системы) определяется целями (достижение высокой производительности при решении множества задач или высокого быстродействия при решении одной задачи), архитектурными и структурными особенностями системы, а также элементной базой (соотношением длительностей циклов памяти и узлов обработки). Могут использоваться комбинированные схемы расслоения.
Описанный метод восстановления данных страдает
Описанный метод восстановления данных страдает кучей ограничений. В частности, при удалении большого количества сильно фрагментированных двоичных файлов он говорит "пас" и уходит в кусты. Вы только убьете свое время, но навряд ли найдете среди обломков файловой системы что-то полезное. Но как бы там ни было, другого выхода просто нет (если, конечно, не считать резервной копию, которой тоже нет), поэтому, я все-таки считаю, что данная статья будет совсем небесполезной.
Защита памяти по ключам (уровням привилегий)
используется в большинстве современных многопрограммных ЭВМ со страничной организацией памяти и динамическим её распределением между параллельно выполняемыми программами. В её основе лежит применение специальных кодов (уровней) для проверки соответствия используемых массивов ячеек памяти номеру выполняемой программы.
Каждой рабочей программе ОС придает специальный ключ — ключ программы. Все выделенные для данной рабочей программы страницы отмечаются одним и тем же ключом страницы или ключом защиты. В качестве ключа защиты обычно указывается двоичный код номера программы. В процессе обращения к ОП производится сравнение ключа выполняемой про граммы с ключами защиты соответствующих страниц памяти. Обращение разрешается только при совпадении сравниваемых кодов ключей. Защита памяти по ключам применяется не только при работе ОП с процессором, но и в ходе обмена информацией с ВЗУ через каналы ввода-вывода. Тогда вместо ключей программ используются ключи каналов. Разрядность кодов ключей определяется максимальным количеством параллельно выполняемых программ.
Структура БЗП по ключам приведена на рис. 4.22. Его основу составляет память ключей защиты ПКЗ адресного типа. Емкость ПКЗ строго соответствует количеству страниц. Разрядность ячеек ПКЗ равна разрядности кодов ключей (k) с добавлением одного или нескольких разрядов для задания режима защиты (j). Ввод кодов защиты в ПКЗ осуществляется под управлением ОС при каждом распределении поля ОП между параллельно выполняемыми программами и каналами ввода-вывода, а также при любом перераспределении поля ОП. Выборка информации
из ПКЗ производится по номерам страниц, представляемых старшими разрядами кода адреса ячейки ОП, по которому идет обращение к ОП.
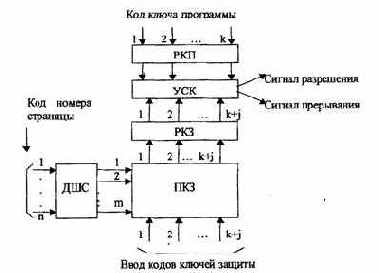
Рис.4.22. Защита памяти по ключам
Кроме ПКЗ в состав блока защиты памяти входят: дешифратор номера страниц ДШС для расшифровки кодов номеров страниц; регистр ключей защиты РКЗ для фиксации выбираемых из ПКЗ кодов; регистр ключей программ РКП для приема и хранения кодов ключей программ, поступающих из регистра слова состояния программы (системного регистра) процессора, или кодов ключей каналов; узел сравнения ключей УСК для сравнения ключей защиты с ключами программ (или каналов).
Код ключа некоторой программы вводится в РКП операционной системой при каждой инициализации этой программы, т.е. при каждом переходе к выполнению её команд. При работе с каналом в РКП вводится ключ канала. В УСК, представляющем собой комбинационную схему, производится сравнение ключа защиты, выбранного из ПКЗ при данном обращении к ОП и зафиксированного в РКЗ, и кода ключа программы (ключа канала), поступающего от РКП. По результатам сравнения узел сравнения кодов формирует либо сигнал разрешения обращения к ОП, либо сигнал прерывания выполняемой программы.
Функционирование БЗП начинается с ввода в ДШС кода номера страницы ОП, к которой производится обращение. По номеру страницы из ПКЗ выбирается соответствующий ключ защиты, код которого помещается в РКЗ. В УСК код ключа защиты сравнивается с кодом ключа программы (канала) и формируются управляющие сигналы разрешения или прерывания.
Защита памяти по ключам (уровням привилегий) является наиболее универсальной и гибкой, особенно эффективной при страничной или сегментно-страничной организации виртуальной памяти и динамическом её распределении. Однако такой способ защиты требует для своей технической реализации заметных дополнительных аппаратных затрат, прежде всего необходима ПКЗ с очень небольшим временем выборки кода ключей. Память ключей защиты строится так, чтобы время выборки кода было практически на порядок меньше времени выборки из ОП.
Затраты времени на переключение программ
(издержки прерывания) равны суммарному расходу времени на запоминание и восстановление состояния программы (рис. 3.11):
