Учебник по промышленной статистике
Деревья классификации
Деревья классификации
- Основные идеи
- Характеристики деревьев классификации
- Иерархическая природа деревьев классификации
- Гибкость метода деревьев классификации
- Сила и слабости метода деревьев классификации
- Вычислительные методы
- Выбор критерия точности прогноза
- Выбор типа ветвления
- Определение момента прекращения ветвлений
- Определение "подходящих" размеров дерева
- Сравнение с другими программами построения деревьев классификации
- Основные идеи
- Характеристики деревьев классификации
- Иерархическая природа деревьев классификации
- Гибкость метода деревьев классификации
- Сила и слабости метода деревьев классификации
- Вычислительные методы
- Выбор критерия точности прогноза
- Выбор типа ветвления
- Определение момента прекращения ветвлений
- Определение "подходящих" размеров дерева
- Сравнение с другими программами построения деревьев классификации
Деревья классификации - это метод, позволяющий предсказывать принадлежность наблюдений или объектов к тому или иному классу категориальной зависимой переменной в зависимости от соответствующих значений одной или нескольких предикторных переменных. Построение деревьев классификации - один из наиболее важных методов, используемых при проведении "добычи данных".
Цель построения деревьев классификации заключается в предсказании (или объяснении) значений категориальной зависимой переменной, и поэтому используемые методы тесно связаны с более традиционными методами Дискриминантного анализа, Кластерного анализа, Непараметрической статистики
и Нелинейного оценивания. Широкая сфера применимости деревьев классификации делает их весьма привлекательным инструментом анализа данных, но не следует поэтому полагать, что его рекомендуется использовать вместо традиционных методов статистики. Напротив, если выполнены более строгие теоретические предположения, налагаемые традиционными методами, и выборочное распределение обладает некоторыми специальными свойствами, то более результативным будет использование именно традиционных методов.
Однако, как метод разведочного анализа, или как последнее средство, когда отказывают все традиционные методы, деревья классификации, по мнению многих исследователей, не знают себе равных.
Что же такое деревья классификации? Представьте, что вам нужно придумать устройство, которое отсортирует коллекцию монет по их достоинству (например, 1, 2, 3 и 5 копеек). Предположим, что какое-то из измерений монет, например - диаметр, известен и, поэтому, может быть использован для построения иерархического устройства сортировки монет. Заставим монеты катиться по узкому желобу, в котором прорезана щель размером с однокопеечную монету. Если монета провалилась в щель, то это 1 копейка; в противном случае она продолжает катиться дальше по желобу и натыкается на щель для двухкопеечной монеты; если она туда провалится, то это 2 копейки, если нет (значит это 3 или 5 копеек) - покатится дальше, и так далее. Таким образом, мы построили дерево классификации. Решающее правило, реализованное в этом дереве классификации , позволяет эффективно рассортировать горсть монет, а в общем случае применимо к широкому спектру задач классификации.
Изучение деревьев классификации не слишком распространено в вероятностно-статистическом распознавании образов (см. работу Ripley, 1996), однако они широко используются в таких прикладных областях, как медицина (диагностика), программирование (анализ структуры данных), ботаника (классификация) и психология (теория принятия решений). Деревья классификации идеально приспособлены для графического представления, и поэтому сделанные на их основе выводы гораздо легче интерпретировать, чем если бы они были представлены только в числовой форме.
Деревья классификации могут быть, а иногда и бывают очень сложным. Однако использование специальных графических процедур, позволяет упростить интерпретацию результатов даже для очень сложных деревьев. Если пользователя интересуют прежде всего условия попадания объекта в один определенный класс, например, в класс с высоким уровнем отклика, он может обратиться к специальной дискретной Карте линий уровня , показывающей, к какой из терминальных вершин дерева классификации отнесены большинство наблюдений с высоким уровнем отклика.
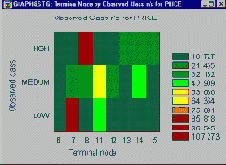
В примере, показанном на этой Карте линий уровня , мы можем мысленно "пройти" по ветвям дерева, ведущим к терминальной вершине 8, чтобы понять, при каких условиях достигается высокий уровень отклика.
Возможность графического представления результатов и простота интерпретации во многом объясняют большую популярность деревьев классификации в прикладных областях, однако наиболее важными отличительными свойствами деревьев классификации является их иерархичность и широкая применимость.
Вычислительные аспекты методов деревьев классификации описаны в разделе Вычислительные методы. См. также раздел Методы разведочного анализа данных.
| В начало |
Характеристики деревьев классификации
Иерархическая природа деревьев классификации
Иерархическая природа деревьев классификации
В книге Breiman et al. (1984) приводится ряд примеров применения деревьев классификации. Один из них посвящен диагностике больных, поступающих в стационар с сердечным приступом. В приемном отделении у них измеряют несколько десятков показателей (частоту пульса, кровяное давление и т.д.). Одновременно в базу данных заносится много другой информации о больном (возраст, перенесенные болезни и др.). Из последующей истории пациента можно, в частности, выделить такой показатель: прожил ли он 30 дней (или более) после приступа. Для разработки методов лечения больных с сердечной недостаточностью, а также для развития разделов медицинской науки, касающихся болезней сердца, было бы весьма полезно научиться по данным первичного обследования выявлять пациентов с высокой степенью риска (тех, кто, вероятнее всего, не сможет прожить больше 30 дней). Одно из деревьев классификации , построенных авторами для этой задачи, представляло собой довольно простое дерево решений с тремя вопросами. На словах это бинарное дерево классификации можно описать следующей фразой: "Если нижнее давление у пациента в течение первых суток не опускается ниже 91, то, если его возраст превосходит 62.5 года, то, если у него наблюдается синусоидальная тахикардия, то в этом и только в этом случае следует ожидать, что пациент не сможет прожить 30 дней." Из этого предложения несложно представить себе соответствующее "дерево" решений.
Вопросы задаются последовательно (иерархически), и окончательное решение зависит от ответов на все предыдущие вопросы. Это похоже на то, как положение листа на дереве можно задать, указав ведущую к нему последовательность ветвей (начиная со ствола и кончая самой последней веточкой, на которой лист растет). Иерархическое строение дерева классификации - одно из наиболее важных его свойств (не следует, однако, чересчур буквально принимать аналогию между ним и настоящим деревом; деревья решений чаще всего рисуются на бумаге вверх ногами, так что если уж искать аналогии в живой природе, то придется обратиться к такому мало поэтичному образу, как корневая система растения).
Иерархическую структуру дерева классификации легко себе уяснить, сравнив используемую там процедуру принятия решения с тем, что происходит при проведении Дискриминантного анализа. Классический линейный дискриминантный анализ данных по сердечной недостаточности выдал бы набор коэффициентов, задающих одну, вполне определенную линейную комбинацию показателей кровяного давления, возраста и данных о синусовой тахикардии, которая наилучшим образом отделяет пациентов с высоким уровнем риска от остальных. Значение дискриминантной функции для каждого пациента будет вычисляться как комбинация результатов измерений трех предикторных переменных с весами, которые задаются соответствующими коэффициентами дискриминантной функции. При классификации данного пациента как имеющего высокий (низкий) уровень риска принимаются в расчет одновременно значения всех трех предикторных переменных. Пусть, например, предикторные переменные обозначаются через P (минимальное за последние сутки систолическое кровяное давление), A (возраст) и T (наличие синусоидальной тахикардии: 0 = нет; 1 = есть), p, a и t - соответствующие им весовые коэффициенты в дискриминантной функции, а c - "пороговое значение" дискриминантной функции, разделяющее пациентов на два класса. Решающее правило будет тогда иметь вид "если для данного пациента pP + aA + tT - c меньше или равно нулю, то у него низкий уровень риска, иначе - высокий уровень риска."
В случае же с решающим деревом, построенным в Breiman et al. (1984), процедура будет иметь следующий, иерархический, вид: пусть значения p, a и t равны соответственно -91, -62.5 и 0, тогда правило формулируется так: "Если p + P меньше или равно нулю, то у пациента низкий уровень риска, иначе если a + A меньше или равно нулю, то у пациента низкий уровень риска, иначе если t + T меньше или равно нулю, то у пациента низкий уровень риска, иначе у пациента высокий уровень риска." На первый взгляд, процедуры принятия решения Дискриминантного анализа и деревьев классификации выглядят похожими, так в обеих участвуют решающие уравнения и коэффициенты. Однако имеется принципиальное различие между одновременным принятием решения в Дискриминантном анализе и последовательным (иерархическим) в деревьях классификации.
Различие между этими двумя подходами станет яснее, если посмотреть, как в том и другом случае выполняется Регрессия. В рассматриваемом примере риск представляет собой дихотомическую зависимую переменную, и прогнозирование с помощью Дискриминантного анализа осуществляется путем одновременной множественной регрессии риска на три предикторных переменных для всех пациентов. С другой стороны, прогнозирование методом деревьев классификации состоит из трех отдельных этапов простого регрессионного анализа: сначала берется регрессия риска на переменную P для всех пациентов, затем - на переменную A для тех пациентов, которые не были классифицированы как низкорисковые на первом шаге регрессии, и, наконец - на переменную T для пациентов, не отнесенных к низкорисковым на втором шаге. Здесь отчетливо проявляются различие одновременного принятия решения в Дискриминантном анализе и последовательного (рекурсивного, иерархического) -- в деревьях классификации. Эта характеристика деревьев классификации имеет далеко идущие последствия.
Гибкость метода деревьев классификации
Гибкость метода деревьев классификации
Другая отличительная черта метода деревьев классификации - это присущая ему гибкость.
Мы уже сказали о способности деревьев классификации последовательно изучать эффект влияния отдельных переменных. Есть еще целый ряд причин, делающих деревья классификации более гибким средством, чем традиционные методы анализа. Способность деревьев классификации выполнять одномерное ветвление для анализа вклада отдельных переменных дает возможность работать с предикторными переменными различных типов. В примере с сердечными приступами, рассмотренном в работе Breiman et al. (1984), давление и возраст являются непрерывными, а наличие/отсутствие синусоидальной тахикардии - категориальной (двухуровневой) предикторной переменной. Простое разветвление предиктора можно было бы выполнить, даже если бы тахикардия измерялась по трехуровневой категориальной шкале (например: 0 = отсутствует; 1 = присутствует; 3 = неизвестно или показания неясны). Если новая категория содержит какую-то дополнительную информацию о риске, то к дереву решений можно добавить новые узлы, учитывающие и использующие эту информацию. Таким образом, при построении одномерных ветвлений деревья классификации позволяют использовать для ветвления как непрерывные, так и категориальные переменные.
В классическом линейном дискриминантном анализе требуется, чтобы предикторные переменные были измерены как минимум в интервальной шкале. В случае же деревьев классификации с одномерным ветвлением по переменным, измеренным в порядковой шкале, любое монотонное преобразование предикторной переменной (т.е. любое преобразование, сохраняющее порядок в значениях переменной) создаст ветвление на те же самые предсказываемые классы объектов (наблюдений) (если используется Одномерное ветвление по методу CART, смотрите Breimen и др., 1984). Поэтому дерево классификации на основе одномерного ветвления можно строить независимо от того, соответствует ли единичное изменение непрерывного предиктора единичному изменению лежащей в его основе величины или нет, достаточно, чтобы предикторы были измерены в порядковой шкале. Иными словами, на способ измерения предикторной переменной накладываются гораздо более слабые ограничения.
Деревья классификации не ограничены использованием только одномерных ветвлений по предикторным переменным. Если непрерывные предикторы измерены хотя бы в интервальной шкале, то деревья классификации могут использовать ветвления по линейным комбинациям, подобно тому, как это делается в линейном дискриминантном анализе. При этом ветвления по линейным комбинациям, применяемые для построения деревьев классификации, имеют ряд важных отличий от своих аналогов из дискриминантного анализа. В линейном дискриминантном анализе максимальное количество линейных дискриминантных функций равно минимуму из числа предикторных переменных и числа классов зависимой переменной минус один. При рекурсивном подходе, который используется в модуле Деревья классификации, мы не связаны этим ограничением. Например, для десяти предикторных переменных и всего двух классов зависимой переменной мы можем использовать десятки последовательных ветвлений по линейным комбинациям. Это выгодно отличается от единственного ветвления по линейной комбинации, предлагаемого в данном случае традиционным нерекурсивным линейным дискриминантным анализом. При этом значительная часть информации, содержащейся в предикторных переменных, может остаться неиспользованной.
Рассмотрим теперь ситуацию, когда имеется много категорий, но мало предикторов. Предположим, например, что мы хотим рассортировать монеты различных достоинств, имея только данные измерений их толщины и диаметра. В обычном линейном дискриминантном анализе можно получить самое большее две дискриминантных функции, и монеты могут быть успешно рассортированы только в том случае, если они различаются не более чем двумя параметрами, представимыми в виде линейных комбинаций толщины и диаметра монеты. Напротив, в подходе, который используется в модуле Деревья классификации, мы не связаны ограничениями в количестве ветвлений по линейным комбинациям, которое можно проделать.
Аппарат ветвления по линейным комбинациям, реализованный в модуле Деревья классификации, может быть использован также как метод анализа при построении деревьев классификации с одномерным ветвлением.
На самом деле одномерное ветвление есть частный случай ветвления по линейной комбинации. Представьте себе такое ветвление по линейной комбинации, при котором весовые коэффициенты при всех предикторных переменных, кроме какой-то одной, равны нулю. Поскольку значение комбинации фактически зависит от значений только одной предикторной переменной (коэффициент при которой отличен от нуля), полученное в результате этого ветвление будет одномерным.
Реализованные в модуле Деревья классификации методы дискриминантного Одномерного ветвления по категориальным и порядковым предикторам и дискриминантного Многомерного ветвления по линейным комбинациям порядковых предикторов представляют собой адаптацию соответствующих алгоритмов пакета QUEST (Quick, Unbiased, Efficient Statistical Trees). QUEST - это программа деревьев классификации, разработанная Loh и Shih (1997), в которой используются улучшенные варианты метода рекурсивного квадратичного дискриминантного анализа и которая содержит ряд новых средств для повышения надежности и эффективности деревьев классификации, которые она строит.
Алгоритмы пакета QUEST довольно сложны (ссылки на источники, где имеются описания алгоритмов, см. в разделе Замечания о вычислительных алгоритмах), однако в модуле Деревья классификации имеется опция Тип ветвления, предоставляющая пользователю другой, концептуально более простой подход. Реализованный здесь алгоритм Одномерного ветвления по методу CART является адаптацией алгоритмов пакета CART, см. Breiman и др. (1984). CART (Classification And Regression Trees) - это программа деревьев классификации, которая при построении дерева осуществляет полный перебор всех возможных вариантов одномерного ветвления.
Опции анализа QUEST и CART естественно дополняют друг друга. В случаях, когда имеется много предикторных переменных с большим числом уровней, поиск методом CART может оказаться довольно продолжительным. Кроме того, этот метод имеет склонность выбирать для ветвления те предикторные переменные, у которых больше уровней.
Однако поскольку здесь производится полный перебор вариантов, есть гарантия, что будет найден вариант ветвления, дающий наилучшую классификацию (по отношению к обучающей выборке; вообще говоря, это необязательно будет так для кросс-проверочных выборок).
Метод QUEST - быстрый и несмещенный. Его преимущество в скорости перед методом CART становится особенно заметным, когда предикторные переменные имеют десятки уровней (см. Loh & Shih, 1997, где приводится пример, когда метод QUEST потребовал 1 секунды времени процессора, а CART - 30.5 часов). Отсутствие у метода QUEST смещения в выборе переменных для ветвления также является его существенным преимуществом в случаях, когда одни предикторные переменные имеют мало уровней, а другие - много (предикторы со многими уровнями часто порождают "методы тыка", которые хорошо согласуются с данными, но дают плохую точность прогноза, см. Doyle, 1973, и Quinlan & Cameron-Jones, 1995). Наконец, метод QUEST не жертвует точностью прогноза ради скорости вычислений (Lim, Loh, & Shih, 1997). Сочетание опций QUEST и CART позволяет полностью использовать всю гибкость аппарата деревьев классификации.
Сила и слабости метода деревьев классификации
Сила и слабости метода деревьев классификации
Преимущества (по крайней мере, для некоторых областей применения) метода деревьев классификации перед такими традиционными методами, как линейный дискриминантный анализ, можно проиллюстрировать на простом условном примере. Чтобы соблюсти объективность, мы затем рассмотрим примеры с другим набором данных, где методы линейного дискриминантного анализа превосходят метод деревьев классификации.
Предположим, что у Вас имеются данные о координатах - Долготе - Longitude и Широте - Latitude - для 37 циклонов, достигающих силы урагана, по двум классификациям циклонов - Baro и Trop. Приведенный ниже модельный набор данных использовался для целей иллюстрации в работе Elsner, Lehmiller, и Kimberlain (1996), авторы которой исследовали различия между бароклинными и тропическими циклонами в Северной Атлантике.
| 59.00 59.50 60.00 60.50 61.00 61.00 61.50 61.50 62.00 63.00 63.50 64.00 64.50 65.00 65.00 65.00 65.50 65.50 65.50 66.00 66.00 66.00 66.50 66.50 66.50 67.00 67.50 68.00 68.50 69.00 69.00 69.50 69.50 70.00 70.50 71.00 71.50 |
17.00 21.00 12.00 16.00 13.00 15.00 17.00 19.00 14.00 15.00 19.00 12.00 16.00 12.00 15.00 17.00 16.00 19.00 21.00 13.00 14.00 17.00 17.00 18.00 21.00 14.00 18.00 14.00 18.00 13.00 15.00 17.00 19.00 12.00 16.00 17.00 21.00 |
BARO BARO BARO BARO BARO BARO BARO BARO BARO TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP TROP BARO BARO BARO BARO BARO BARO BARO BARO BARO BARO |
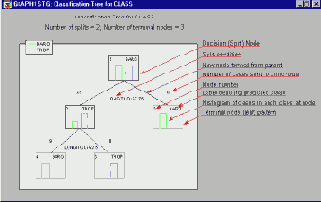
В заголовке графа приведена общая информация, согласно которой полученное дерево классификации имеет 2 ветвления и 3 терминальные вершины. Терминальные вершины (или, как их иногда называют, листья) это узлы дерева, начиная с которых никакие решения больше не принимаются. На рисунке терминальные вершины показаны красными пунктирными линиями, а остальные - так называемые решающие вершины или вершины ветвления - сплошными черными линиями. Началом дерева считается самая верхняя решающая вершина, которую иногда также называют корнем дерева. На рисунке она расположена в левом верхнем углу и помечена цифрой 1. Первоначально все 37 циклонов приписываются к этой корневой вершине и предварительно классифицируются как Baro - на это указывает надпись Baro в правом верхнем углу вершины.
Класс Baro был выбран для начальной классификации потому, что число циклонов Baro немного больше, чем циклонов Trop (см. гистограмму, изображенную внутри корневой вершины). В левом верхнем углу графа имеется надпись - легенда , указывающая, какие столбики гистограммы вершины соответствуют циклонам Baro и Trop.
Корневая вершина разветвляется на две новых вершины. Под корневой вершиной имеется текст, описывающий схему данного ветвления. Из него следует, что циклоны, имеющие значение Долготы меньшее или равное 67.75, отнесены к вершине номер 2 и предположительно классифицированы как Trop, а циклоны с Долготой, большей 67.75 приписаны к вершине 3 и классифицированы как Baro. Числа 27 и 10 над вершинами 2 и 3 соответственно обозначают число наблюдений, попавших в эти две дочерние вершины из родительской корневой вершины. Затем точно так же разветвляется вершина 2. В результате 9 циклонов со значениями Долготы меньшими или равными 62.5 приписываются к вершине 4 и классифицируются как Baro, а остальные 18 циклонов с Долготой, большей 62.5, - к вершине 5 и классифицируются как Trop.
На Графе дерева вся эта информация представлена в простом, удобном для восприятия виде, так что для ее понимания требуется гораздо меньше времени, чем его ушло у Вас на чтение двух последних абзацев. Если теперь мы посмотрим на гистограммы терминальных вершин дерева, расположенных в нижней строке, то увидим, что дерево классификации сумело абсолютно правильно расклассифицировать циклоны. Каждая из терминальных вершин "чистая", то есть не содержит неправильно классифицированных наблюдений. Вся информация, содержащаяся в Графе дерева, продублирована в таблице результатов Структура дерева, которая приведена ниже.
Таблица 1
Таблица 1
| 2 4 |
3 5 |
19 9 10 9 0 |
18 18 0 0 18 |
BARO TROP BARO BARO TROP |
-67.75 -62.50 |
LONGITUD LONGITUD |
Обратите внимание на то, что в этой таблице результатов вершины с 3-й по 5-ю помечены как терминальные, так как в них не происходит ветвления. Обратите также внимание на знаки Постоянных ветвления - например -67.75 для вершины 1. В Графе дерева условие ветвления в вершине 1 записано как LONGITUD 67.75 вместо эквивалентного -67.75 + LONGITUD 0. Это сделано просто для экономии места на рисунке.
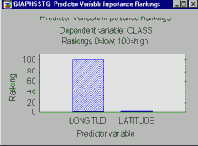
Если делаются одномерные ветвления, то каждой предикторной переменной можно приписать ранг по шкале от 0 до 100 в зависимости от степени ее влияния на отклик зависимой переменной. В нашем примере очевидно, что Долгота - Longitude имеет большую важность, а Широта - Latitude - относительно небольшую.
Дерево классификации для переменной Класс - Class, построенное с использованием Дискриминантных одномерных ветвлений, дает почти такие же результаты. В приведенной ниже таблице результатов Структура дерева для этого варианта анализа константы ветвления равны -63.4716 и -67.7516 - то есть почти те же, что получились в варианте Полного перебора деревьев с одномерным ветвлением по методу CART . Здесь, однако, один циклон класса Trop в терминальной вершине 2 неправильно классифицирован как Baro.
Таблица 2
Таблица 2
| 2 4 |
3 5 |
19 9 10 0 10 |
18 1 17 17 0 |
BARO BARO TROP TROP BARO |
-63.4716 -67.7516 |
LONGITUD LONGITUD |
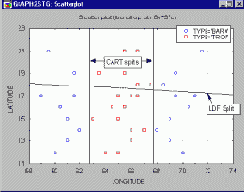
График ясно показывает, что нет отчетливой линейной связи между переменными широты, долготы или какой-либо их линейной комбинацией с одной стороны, и переменной Class - с другой. Переменная Class функционально не связана с долготой и широтой, по крайней мере, в линейном смысле. На графике показана попытка ветвления посредством LDF (линейной дискриминантной функции): циклоны, относительно которых делается прогноз Trop, находятся над линией ветвления, а прогнозируемые как Baro - под этой линией. Хорошо видно, что получился почти что "выстрел наугад". Возможности одномерного ветвления CART не ограничены вычислением единственной линейной комбинации широты и долготы, и этот метод находит "критические значения" переменной Longitude , позволяющие получить наилучшую возможную (а в данном случае - идеальную) классификацию для переменной Class.
Рассмотрим теперь ситуацию, в которой проявляются слабые стороны деревьев классификации. Рассмотрим другой набор данных о циклонах. Их можно найти в демонстрационном файле данных Barotro2.sta.
Таблица 3
Таблица 3
| 59.00 59.50 60.00 60.50 61.00 61.00 61.50 61.50 62.00 63.00 63.50 64.00 64.50 65.00 65.00 65.00 65.50 65.50 65.50 66.00 66.00 66.00 66.50 66.50 66.50 67.00 67.50 68.00 68.50 69.00 69.00 69.50 69.50 70.00 70.50 71.00 71.50 |
17.00 21.00 12.00 16.00 13.00 15.00 17.00 19.00 14.00 15.00 19.00 12.00 16.00 12.00 15.00 17.00 16.00 19.00 21.00 13.00 14.00 17.00 17.00 18.00 21.00 14.00 18.00 14.00 18.00 13.00 15.00 17.00 19.00 12.00 16.00 17.00 21.00 |
BARO BARO TROP BARO TROP TROP BARO BARO TROP TROP BARO TROP TROP TROP TROP BARO TROP BARO BARO TROP TROP BARO BARO BARO BARO TROP BARO TROP BARO TROP TROP TROP BARO TROP TROP TROP BARO |
Анализ посредством дерева классификации по переменной Класс - Class в случае Полного перебора деревьев с одномерным ветвлением по методу CART также дает правильную классификацию для всех 37 циклонов, но для этого требуется дерево с 5 ветвлениями и 6 терминальными вершинами. Какой результат проще интерпретировать? В линейном дискриминантном анализе коэффициенты канонической дискриминантной функции при переменных Долгота - Longitude и Широта - Latitude равны соответственно 0.122073 и -0.633124, так что чем больше долгота и чем меньше широта, тем вероятнее данный циклон будет классифицирован как Trop. Интерпретация может быть такой: циклоны в южных широтах западной Атлантики вероятнее всего будут циклонами Trop, а циклоны в северных широтах восточной Атлантики - Baro.
Ниже показан Граф дерева для дерева классификации в варианте анализа, в котором используется Полный перебор деревьев с одномерным ветвлением по методу CART.
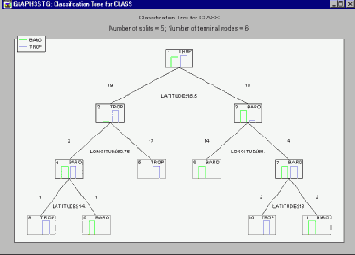
Можно было бы последовательно описать все ветвления дерева классификации, как это было проделано в предыдущем примере, но поскольку ветвлений много, интерпретировать результаты было бы труднее, чем в случае одной дискриминантной функции, получающейся при линейном дискриминантном анализе.
Вспомним, однако, про опцию Многомерное ветвление по линейным комбинациям порядковых предикторов, о которой мы говорили в разделе, посвященном гибким возможностям модуля Деревья классификации, и которая использует алгоритмы QUEST. Граф дерева для дерева классификации , построенного путем ветвления по линейным комбинациям, показан ниже.
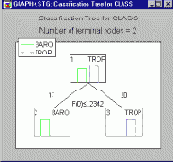
Обратите внимание на то, что уже одно ветвление дерева дает идеальный прогноз. Каждая из терминальных вершин - "чистая", то есть не содержит наблюдений неправильно классифицированных циклонов. Ветвление по линейной комбинации в корневой вершине, ведущее к левой дочерней вершине и правой дочерней вершине, имеет вид "F(0) -.2342". Это означает, что если значение функции ветвления (обозначено через F(0) ) для данного циклона меньше или равно -0.2342 , то он попадет в левую дочернюю вершину и будет классифицирован как Baro, в противном случае он попадет в правую дочернюю вершину и будет классифицирован как Trop.
Коэффициенты функции ветвления (0.011741 для Долготы и -0. 060896 для Широты) имеют одинаковый знак и по относительной величине близки к соответствующим коэффициентам линейной дискриминантной функции из линейного дискриминантного анализа, так что оба метода в этом примере с прогнозированием переменной Class являются функционально эквивалентными.
Мораль всей этой истории об успехах и неудачах метода деревьев классификации можно сформулировать так: метод деревьев классификации хорош настолько, насколько удачным окажется выбор варианта анализа. Чтобы построить модель, дающую хороший прогноз, в любом случае нужно хорошо понимать природу взаимосвязей между предикторными и зависимыми переменными.
Итак, мы увидели, что методы анализа с помощью деревьев классификации можно охарактеризовать как набор иерархических, чрезвычайно гибких средств предсказания принадлежности наблюдений (объектов) к определенному классу значений категориальной зависимой переменной по значениям одной или нескольких предикторных переменных. Теперь мы готовы к тому, чтобы рассмотреть методы построения деревьев классификации более детально.
Информацию о том, для чего нужны деревья классификации, см. в разделе Основные идеи. См. также раздел Методы разведочного анализа данных.
| В начало |
Вычислительные методы
Процесс построения дерева классификации состоит из четырех основных шагов:
- Выбор критерия точности прогноза
- Выбор типа ветвления
- Определение момента прекращения ветвлений
- Определение "подходящих" размеров дерева
Выбор критерия точности прогноза
Выбор критерия точности прогноза
В конечном счете, цель анализа с помощью деревьев классификации состоит в том, чтобы получить максимально точный прогноз. К сожалению, очень сложно четко сформулировать, что такое точный прогноз. Эта проблема решается "переворачиванием с ног на голову": наиболее точным прогнозом считается такой, который связан с наименьшей ценой. Термин цена не содержит в себе ничего загадочного.
В большинстве приложений цена - это просто доля неправильно классифицированных наблюдений. Понятие цена вводится для того, чтобы распространить на более широкий класс ситуаций ту идею, что самый лучший прогноз - такой, который дает наименьший процент неправильных классификаций.
Необходимость минимизировать не просто долю неправильно классифицированных наблюдений, а именно потери, возникает тогда, когда некоторые ошибки прогноза ведут к более катастрофическим последствиям, чем другие, или же когда ошибки некоторого типа встречаются чаще других. Цена ошибки классификации для игрока, поставившего все свое состояние на одну ставку, несоизмеримо больше, чем от проигрыша нескольких ставок, на которые были поставлены мелкие суммы. Может случиться и наоборот, что потери от проигрыша большого количества мелких ставок будут больше, чем от проигрыша небольшого числа крупных. Усилия, которые следует уделять для минимизации убытков от ошибок прогноза, должны быть тем больше, чем больше возможный размер этих убытков.
Априорные вероятности.
Априорные вероятности.
Заметим, однако, что если Априорные вероятности выбраны пропорциональными размерам классов, а Цена ошибки классификации - одинаковая для всех классов, то минимизация потерь в точности эквивалентна минимизации доли неправильно классифицированных наблюдений. Рассмотрим априорные вероятности подробнее. Эти величины выражают то, как мы, не располагая никакой априорной информацией о значениях предикторных переменных модели, оцениваем вероятность попадания объекта в тот или иной класс. Например, изучая данные об учащихся, исключенных из школ, мы обнаружим, что в целом их количество существенно меньше, чем тех, кто продолжает учебу (т.е. различны исходные частоты); поэтому априорная вероятность того, что учащийся покинет школу, меньше, чем вероятность того, что он продолжит учебу.
Выбор априорных вероятностей, используемых для минимизации потерь, очень сильно влияет на результаты классификации. Если различия между исходными частотами в данной задаче не считаются существенными или если мы знаем заранее, что классы содержат примерно одинаковое количество наблюдений, то тогда можно взять одинаковые априорные вероятности.
В случаях, когда исходные частоты связаны с размерами классов (так будет, например, когда мы работаем со случайной выборкой), следует в качестве оценок для априорных вероятностей взять относительные размеры классов в выборке. Наконец, если Вы (например, на основании данных предыдущих исследований) располагаете какой-то информацией об исходных частотах, то априорные вероятности нужно выбирать с учетом этой информации. Например, априорная вероятность человека быть носителем рецессивного гена вдвое выше вероятности того, что этот ген имеет проявления. В любом случае, приписывая классу ту или иную априорную вероятность, мы "учитываем" степень важности ошибки классификации объектов этого класса. Минимизация потерь - это минимизация общего числа неправильно классифицированных наблюдений с Априорными вероятностями, пропорциональными размерам классов (и Ценами ошибки классификации, одинаковыми для всех классов), поскольку прогноз, чтобы давать меньший итоговый процент ошибок классификации, должен быть более точным на больших классах.
Цена ошибки классификации.
Цена ошибки классификации.
Бывает так, что по причинам, не связанным с размерами классов, для одних классов требуется более точный прогноз, чем для других. Гораздо важнее выявить переносчиков инфекционного заболевания, постоянно контактирующих с другими людьми, чем тех же переносчиков, не имеющих постоянных контактов, - и это независимо от относительной численности тех и других. Если мы примем, что избежать контактов с "контактирующим переносчиком" гораздо важнее, чем с "неконтактирующим", то следует приписать ошибочной классификации "контактирующего" как "неконтактирующего" большую цену, чем ошибочной классификации "неконтактирующего" как "контактирующего". Как уже говорилось, минимизация потерь - это минимизация общей доли неправильно классифицированных наблюдений с Априорными вероятностями, пропорциональными размерам классов, и Ценами ошибки классификации, одинаковыми для всех классов.
Веса наблюдений.
Веса наблюдений.
На менее концептуальном уровне, использование весов для весовой переменной в качестве множителей наблюдений для агрегированных данных также имеет отношение к минимизации потерь. Любопытно, что вместо того, чтобы использовать веса наблюдений для агрегированных данных, можно ввести подходящие априорные вероятности и/или цены ошибки классификации и получить те же самые результаты, не тратя времени на обработку множества наблюдений, имеющих одинаковые значения всех переменных. Предположим, например, что в агрегированном множестве данных с двумя равновеликими классами веса наблюдений из первого класса равны 2, а наблюдений из второго класса - 3. Если положить априорные вероятности равными соответственно 0.4 и 0.6, цены ошибки классификации взять одинаковыми и проанализировать данные без весов наблюдений, то доля неправильных классификаций получится такой же, как если бы мы оценили априорные вероятности по размерам классов, цены ошибки классификации взяли бы одинаковыми и анализировали агрегированные данные с использованием весов наблюдений. Точно такая же доля ошибок классификации получилась бы и в том случае, если бы мы положили все априорные вероятности одинаковыми, цену ошибочной классификации объекта из 1-го класса как принадлежащего ко 2-му классу взяли равной 2/3 от цены неправильной классификации объекта 2-го класса как принадлежащего 1-му классу, и анализировали бы данные без весов наблюдений.
За исключением простейших случаев, взаимосвязи между априорными вероятностями, ценами ошибок классификации и весами наблюдений являются довольно сложными (см. Breiman и др., 1984; Ripley, 1996). Однако если минимизация цены соответствует минимизации доли неправильных классификаций, все эти обстоятельства можно не принимать во внимание. Априорные вероятности, цена ошибок классификации и веса наблюдений были рассмотрены здесь для того, чтобы показать, как самые разнообразные ситуации в прогнозировании можно охватить единой концепцией минимизации цены, - в противоположность достаточно узкому (хотя, возможно, часто встречающемуся) классу задач прогнозирования, для которых подходит более ограниченная (хотя и простая) идея минимизации доли неправильных классификаций.
Далее, минимизация цены есть истинная цель классификации посредством деревьев классификации, и это отчетливо проявляется на четвертом (заключительном) этапе анализа: стремясь выбрать дерево "нужного размера", мы в действительности выбираем дерево с минимальной оценкой для цены. Для многих видов задач прогнозирования понять смысл уменьшения оценки для цены бывает очень важно для лучшего понимания окончательных результатов всего анализа.
Выбор типа ветвления
Выбор типа ветвления
Второй шаг анализа с помощью деревьев классификации заключается в том, чтобы выбрать способ ветвления по значениям предикторных переменных, которые используются для предсказания принадлежности анализируемых объектов к определенным классам значений зависимой переменной. В соответствии с иерархической природой деревьев классификации, такие ветвления производятся последовательно, начиная с корневой вершины, переходя к вершинам-потомкам, пока дальнейшее ветвление не прекратится и "неразветвленные" вершины-потомки окажутся терминальными. Ниже описаны три метода типа ветвления.
Дискриминантное одномерное ветвление.
Дискриминантное одномерное ветвление.
Если выбрано Одномерное ветвление, прежде всего нужно решить вопрос, какую из терминальных вершин дерева, построенного к данному моменту, следует расщепить на данном шаге и какую из предикторных переменных при этом использовать. Для каждой терминальной вершины вычисляются p-уровни для проверки значимости зависимостей между принадлежностью объектов к классам и уровнями каждой из предикторных переменных. В случае категориальных предикторов p-уровни вычисляются для проверки критерия Хи-квадрат для гипотезы независимости принадлежности классам от уровня категориального предиктора в данном узле дерева. В случае порядковых предикторов p-уровни вычисляются для анализа ANOVA взаимосвязи классовой принадлежности и значений порядкового предиктора в данном узле. Если наименьший из вычисленных p-уровней оказался меньше p-уровня Бонферони для множественных 0.05-сравнений, принимаемого по умолчанию, или иного порогового значения, установленного пользователем, то для разветвления этого узла выбирается та предикторная переменная, которая и дала этот наименьший.
Если среди p- уровней не оказалось ни одного, меньшего чем заданное пороговое значение, то p-уровни вычисляются по статистическим критериям, устойчивым к виду распределения, например F Левена. Более подробно процедура выбора узла и предикторной переменной для ветвления в случае, когда ни один из p-уровней не опустился ниже заданного порога, описана в Loh и Shih (1997).
Следующий шаг - собственно ветвление. В случае порядковых предикторов для построения двух относящихся к данной вершине "суперклассов" применяется алгоритм кластеризации 2-средних, описанный в Hartigan , Wong (1979, см. также Кластерный анализ). При этом находятся корни квадратного уравнения, характеризующего различие средних значений по "суперклассам" порядкового предиктора, и для каждого из корней вычисляются значения порога ветвления. Выбирается вариант ветвления, для которого значение ближе к среднему по "суперклассу". В случае категориального предиктора создаются фиктивные переменные, представляющие уровни этого предиктора, а затем с помощью метода сингулярного разложения фиктивные переменные преобразуются в совокупность неизбыточных порядковых предикторов. Затем применяется описанный выше алгоритм для порядковых предикторов, после чего полученное ветвление "проецируется обратно" в уровни исходной категоризующей переменной и трактуется как различие между двумя множествами уровней этой переменной. Как и в предыдущем случае, за подробностями мы отсылаем читателя к книге Loh , Shih (1997). Описанные процедуры довольно сложны, однако они позволяют уменьшить смещение при выборе ветвления, которое характерно для Полного перебора деревьев с одномерным ветвлением по методу CART. Смещение имеет место в сторону выбора переменных с большим числом уровней ветвления, и при интерпретации результатов оно может исказить относительную значимость влияния предикторов на значения зависимой переменной (см. Breiman и др., 1984).
Дискриминантное многомерное ветвление по линейным комбинациям.
Дискриминантное многомерное ветвление по линейным комбинациям.
Другим типом ветвления является многомерное ветвление по линейным комбинациям для порядковых предикторных переменных (при этом требуется, чтобы предикторы были измерены как минимум по интервальной шкале). Любопытно, что в этом методе способ использования непрерывных предикторных переменных, участвующих в линейной комбинации, очень похож на тот, который применялся в предыдущем методе для категоризующих переменных. С помощью сингулярного разложения непрерывные предикторы преобразуются в новый набор неизбыточных предикторов. Затем применяются процедуры создания "суперклассов" и поиска ветвления, ближайшего к среднему по "суперклассу", после чего результаты "проецируются назад" в исходные непрерывные предикторы и представляются как одномерное ветвление линейной комбинации предикторных переменных.
Полный перебор деревьев с одномерным ветвлением по методу CART.
Полный перебор деревьев с одномерным ветвлением по методу CART.
Третий метод выбора варианта ветвления, реализованный в данном модуле - Полный перебор деревьев с одномерным ветвлением по методу CART для категоризующих и порядковых предикторных переменных. В этом методе перебираются все возможные варианты ветвления по каждой предикторной переменной, и находится тот из них, который дает наибольший рост для критерия согласия (или, что то же самое, наибольшее уменьшение отсутствия согласия). Что определяет набор возможных ветвлений в некотором узле? Для категоризующей предикторной переменной, принимающей в данном узле k значений, имеется ровно 2(k-1) - 1 вариантов разбиения множества ее значений на две части. Для порядкового предиктора, имеющего в данном узле k различных уровней, имеется k -1 точек, разделяющих разные уровни. Мы видим, что количество различных вариантов ветвления, которые необходимо просмотреть, будет очень большим, если в задаче много предикторов, у них много уровней значений и в дереве много терминальных вершин. Каким образом определяется улучшение критерия согласия? В модуле Деревья классификации доступны три способа измерения критерия согласия.
Мера Джини однородности вершины принимает нулевое значение, когда в данной вершине имеется всего один класс (если используются априорные вероятности, оцененные по размерам классов или исходя из одинаковой цены ошибок классификации, то мера Джини вычисляется как сумма всех попарных произведений относительных размеров классов, представленных в данной вершине; ее значение будет максимальным, когда размеры всех классов одинаковы). Меру Джини в качестве критерия согласия использовали разработчики пакета CART (Breiman и. др., 1984). В модуле Деревья классификации имеются еще две возможности: мера Хи-квадрат Бартлетта (Bartlett, 1948) и мера G-квадрат measure, совпадающая с мерой максимума правдоподобия Хи-квадрат, которая применяется в моделировании структурными уравнениями (см., например, документацию по модулю Моделирование структурными уравнениями). При Полном переборе деревьев с одномерным ветвлением по методу CART ищется вариант ветвления, при котором максимально уменьшается значение выбранного критерия согласия. Классификация будет абсолютно точной, если согласие окажется полным.
Определение момента прекращения ветвлений
Определение момента прекращения ветвлений
Третий этап анализа с помощью деревьев классификации заключается в выборе момента, когда следует прекратить дальнейшие ветвления. Деревья классификации обладают тем свойством, что если не установлено ограничение на число ветвлений, то можно прийти к "чистой" классификации, когда каждая терминальная вершина содержит только один класс наблюдений (объектов). Однако обычно такая "чистая" классификация нереальна. Даже в простом дереве классификации из примера с сортировкой монет будут происходить ошибки классификации из-за того, что некоторые монеты имеют неправильный размер и/или размеры прорезей для них меняются со временем от износа. В принципе, такие ошибки можно было бы устранить, подвергая дальнейшей классификации монеты, провалившиеся в каждую прорезь, однако на практике всегда приходится в какой-то момент прекращать сортировку и удовлетворяться полученными к этому времени результатами.
Аналогично, если при анализе с помощью дерева классификации данные о классификации зависимой переменной или уровни значений предикторных переменных содержат ошибки измерений или составляющую шума, то было бы нереально пытаться продолжать сортировку до тех пор, пока каждая терминальная вершина не станет "чистой". В модуле Деревья классификации имеются две опции для управления остановкой ветвлений. Их выбор прямо связан с выбором для данной задачи Правила остановки.
Число неклассифицированных.
Число неклассифицированных.
В этом варианте ветвления продолжаются до тех пор, пока все терминальные вершины не окажутся чистыми или будут содержать не более чем заданное число объектов (наблюдений). Эта опция доступна в качестве Правила остановки в двух вариантах: По ошибке классификации или По вариации. Нужное минимальное число наблюдений задается как Число неклассифицированных, и ветвление прекращается, когда все терминальные вершины, содержащие более одного класса, содержат не более чем заданное число объектов (наблюдений).
Доля неклассифицированных.
Доля неклассифицированных.
При выборе этого варианта ветвления продолжаются до тех пор, пока все терминальные вершины не окажутся чистыми или будут содержать количество объектов, не превышающее заданную долю численности одного или нескольких классов. Требуемую минимальную долю следует задать как Долю неклассифицированных и тогда, если априорные вероятности взяты одинаковыми и размеры классов также одинаковы, ветвление прекратится, когда все терминальные вершины, содержащие более одного класса, будут содержать количество наблюдений, не превышающее заданную долю объема одного или нескольких классов. Если же априорные вероятности выбирались не одинаковыми, то ветвление прекратится, когда все терминальные вершины, содержащие более одного класса, будут содержать количество наблюдений, не превышающее заданную долю объема одного или нескольких классов.
Определение "подходящих" размеров дерева
Определение "подходящих" размеров дерева
Некий дотошный любитель играть на скачках, тщательно изучив все результаты очередного дня, конструирует огромное дерево классификации с множеством ветвлений, полностью учитывающее все данные по каждой лошади и каждому заезду. Предвкушая финансовый успех, он берет точную копию своего Графа дерева, с помощью дерева классификации сортирует лошадей, участвующих в заездах на следующий день, строит свой прогноз, делает ставки в соответствии с ним и ... уходит с ипподрома несколько менее богатым человеком, чем рассчитывал. Наш игрок наивно полагал, что дерево классификации, построенное по обучающей выборке с заранее известными результатами будет так же хорошо предсказывать результат и для другой - независимой тестовой выборки. Его дерево классификации не выдержало кросс-проверки. Вполне вероятно, что денежный выигрыш нашего игрока был бы гораздо значительнее, если бы он использовал небольшое дерево классификации , не вполне идеально классифицирующее обучающую выборку, но обладающее способностью столь же хорошо прогнозировать результат для тестовой выборки.
Можно высказать ряд общих соображений о том, что следует считать "подходящими размерами" для дерева классификации. Оно должно быть достаточно сложным для того, чтобы учитывать имеющуюся информацию, и в то же время оно должно быть как можно более простым. Дерево должно уметь использовать ту информацию, которая улучшает точность прогноза, и игнорировать ту информацию, которая прогноза не улучшает. По возможности оно должно углублять наше понимание того явления, которое мы пытаемся описать посредством этого дерева. Очевидно, однако, что сказанное можно отнести вообще к любой научной теории, так что мы должны более конкретно определить, что же такое дерево классификации "подходящего размера". Одна из возможных стратегий состоит в том, чтобы наращивать дерево до нужного размера, каковой определяется самим пользователем на основе уже имеющихся данных, диагностических сообщений системы, выданных на предыдущих этапах анализа, или, на крайний случай, интуиции.
Другая стратегия связана с использованием хорошо структурированного и документированного набора процедур для выбора "подходящего размера" дерева, разработанных Бриманом (Breiman) и др. (1984). Нельзя сказать (и авторы это явно отмечают), чтобы эти процедуры были доступны новичку, но они позволяют получить из процесса поиска дерева "подходящего размера" некоторые субъективные суждения.
Прямая остановка по методу FACT.
Прямая остановка по методу FACT.
Начнем с описания первой стратегии, в которой пользователь сам устанавливает размеры дерева классификации, до которых оно может расти. В этом варианте мы в качестве Правила остановки выбираем опцию Прямая остановка по методу FACT, а затем задаем Долю неклассифицированных, которая позволяет дереву расти до нужного размера. Ниже описаны три возможных способа определения, удачно ли выбран размер дерева, три варианта кросс-проверки для построенного дерева классификации.
Кросс-проверка на тестовой выборке.
Кросс-проверка на тестовой выборке.
Первый, наиболее предпочтительный вариант кросс-проверки - кросс-проверка на тестовой выборке. В этом варианте кросс-проверки дерево классификации строится по обучающей выборке, а его способность к прогнозированию проверяется путем предсказания классовой принадлежности элементов тестовой выборки. Если значение цены на тестовой выборке окажется больше, чем на обучающей выборке (напомним Вам, что цена - это доля неправильно классифицированных наблюдений при условии, что были использованы оцениваемые априорные вероятности, а цены ошибок классификации были взяты одинаковыми), то это свидетельствует о плохом результате кросс-проверки, и, возможно, в этом случае следует поискать дерево другого размера, которое бы лучше выдерживало кросс-проверку. Тестовая и обучающая выборки могут быть образованы из двух независимых наборов данных, или, если в нашем распоряжении имеется большая обучающая выборка, мы можем случайным образом отобрать часть (например, треть или половину) наблюдений и использовать ее в качестве тестовой выборки.
V-кратная кросс-проверка.
V-кратная кросс-проверка.
Второй тип кросс-проверки, реализованный в модуле Деревья классификации, - так называемая V-кратная кросс-проверка. Этот вид кросс-проверки разумно использовать в случаях, когда в нашем распоряжении нет отдельной тестовой выборки, а обучающее множество слишком мало для того, чтобы из него выделять тестовую выборку. Задаваемое пользователем значение V (значение по умолчанию равно 3) определяет число случайных подвыборок - по возможности одинакового объема, - которые формируются из обучающей выборки. Дерево классификации нужного размера строится V раз, причем каждый раз поочередно одна из подвыборок не используется в его построении, но затем используется как тестовая выборка для кросс-проверки. Таким образом, каждая подвыборка V - 1 раз участвует в обучающей выборке и ровно один раз служит тестовой выборкой. Цены кросс-проверки, вычисленные для всех V тестовых выборок, затем усредняются, и в результате получается V-кратная оценка для цены кросс-проверки, которая, вместе со своей стандартной ошибкой, доступна в таблице результатов Последовательность деревьев.
Глобальная кросс-проверка.
Глобальная кросс-проверка.
Третий тип кросс-проверки, реализованный в модуле Деревья классификации - глобальная кросс-проверка. В этом варианте производится заданное число итераций (по умолчанию - 3), причем всякий раз часть обучающей выборки (равная единице, деленной на заданное целое число) оставляется в стороне, а затем по очереди каждая из отложенных частей используется как тестовая выборка для кросс-проверки построенного дерева классификации. Этот вариант кросс-проверки, вероятно, уступает методу V-кратной кросс-проверки в случае, если была выбрана опция Прямая остановка по методу FACT, однако он может оказаться очень полезным для проверки методов автоматического построения дерева (обсуждение этих вопросов см. в Breiman и др., 1984). В результате мы естественно приходим ко второй из возможных стратегий выбора "подходящего размера" для дерева - методу автоматического построения дерева, который основывается на результатах Breiman и др. (1984) и называется "кросс-проверочным отсечением по минимальной цене-сложности".
Кросс-проверочное отсечение по минимальной цене-сложности.
Кросс-проверочное отсечение по минимальной цене-сложности.
Для того чтобы в Деревья классификации выполнить кросс-проверочное отсечение по минимальной цене-сложности, нужно выбрать опцию По ошибке классификации в качестве Правила остановки, а кросс-проверочное отсечение по минимальному отклонению-сложности выполняется, если в качестве Правила остановки выбрано отсечение По вариации. Единственное различие между этими двумя опциями - способ измерения ошибки прогноза. При отсечении По ошибке классификации используется неоднократно упоминавшаяся функция потерь (равная доли неправильно классифицированных объектов при оцениваемых априорных вероятностях и одинаковых ценах ошибок классификации). При отсечении По вариации используется мера, основанная на принципе максимума правдоподобия и называемая отклонением (см. Ripley, 1996). Мы сосредоточимся на кросс-проверочном отсечении по минимальной цене-сложности (предложенном Breiman и др., 1984), поскольку отсечение по отклонению-сложности отличается от него только способом измерения ошибки прогноза.
Функция цены, которая требуется для кросс-проверочного отсечения по минимальной цене-сложности, вычисляется по мере построения дерева, начиная с ветвления в корневой вершине, пока дерево не достигнет максимально допустимого размера, определяемого величиной Число неклассифицированных. Цена для обучающей выборки пересчитывается при каждом новом ветвлении дерева, так что в результате получается, вообще говоря, убывающая последовательность цен (это отражает улучшение качества классификации). Цена обучающей выборки называется ценой обучения, чтобы отличать ее от цены кросс-проверки, - это необходимо делать, поскольку V-кратная кросс-проверка также производится при каждом новом ветвлении дерева. В качестве значения цены для корневой вершины следует использовать оценку цены кросс-проверки из V-кратной кросс-проверки. Размер дерева можно определить как число терминальных вершин, потому что для бинарных деревьев при каждом новом ветвлении размер дерева увеличивается на единицу.
Введем теперь так называемый параметр сложности. Положим его сначала равным нулю, и для каждого дерева (начиная с исходного, состоящего из одной вершины) будем вычислять функцию, равную цене дерева плюс значение параметра сложности, умноженное на размер дерева. Станем теперь постепенно увеличивать значение параметра сложности, пока значение этой функции для максимального дерева не превысит ее значения для какого-либо из деревьев меньшего размера, построенных на предыдущих шагах. Примем это меньшее дерево за новое максимальное дерево и будем дальше увеличивать значение параметра сложности, пока значение функции для этого дерева не станет больше ее значения для какого-то еще меньшего дерева. Будем продолжать этот процесс до тех пор, пока дерево, состоящее из единственной корневой вершины, не станет максимальным. (Читатели, знакомые с численными методами, заметили, что в этом алгоритме мы использовали так называемую штрафную функцию. Она представляет собой линейную комбинацию цены, которая в общем случае убывает с ростом дерева, и размера дерева, который линейно растет. По мере того, как значение параметра сложности увеличивается, большие по размеру деревья получают все больший штраф за свою сложность, пока не будет достигнуто пороговое значение, при котором более высокая цена меньшего дерева будет перевешиваться сложностью большего дерева.
Последовательность максимальных деревьев, которая получается в процессе выполнения этого алгоритма, обладает рядом замечательных свойств. Они являются вложенными, поскольку при последовательном усечении каждое дерево содержит все вершины следующего (меньшего) дерева в последовательности. Поначалу при переходе от очередного дерева к последующему отсекается, как правило, большое число вершин, однако по мере приближения к корневой вершине на каждом шаге будет отсекаться все меньше вершин. Деревья последовательности усекаются оптимально в том смысле, что каждое дерево в последовательности имеет наименьшую цену среди всех деревьев такого же размера.
Доказательства и подробные пояснения можно найти в Breiman и др. (1984).
Выбор дерева по результатам усечений.
Выбор дерева по результатам усечений.
Выберем теперь из последовательности оптимально усеченных деревьев дерево "подходящего размера". Естественным критерием здесь является Цена кросс-проверки. Не будет никакой ошибки, если мы в качестве дерева "подходящего размера" выберем то, которое дает наименьшую цену кросс-проверки, однако часто оказывается, что есть еще несколько деревьев с ценой кросс-проверки, близкой к минимальной. Breiman и др. (1984) высказывают разумное предложение, что в качестве дерева "подходящего размера" нужно брать наименьшее (наименее сложное) из тех, чьи цены кросс-проверки несущественно отличаются от минимальной. Авторы предложили правило "1 SE": в качестве дерева "подходящего размера" нужно брать наименьшее дерево из тех, чьи цены кросс-проверки не превосходят минимальной цены кросс-проверки плюс умноженная на единицу стандартная ошибка цены кросс-проверки для дерева с минимальной Ценой кросс-проверки.
Существенное преимущество "автоматического" выбора дерева состоит в том, что оно позволяет избежать как "недо-", так и "пересогласованности" с данными. На следующем рисунке изображены типичные графики цены обучения и цены кросс-проверки для цепочки последовательно усекаемых деревьев.
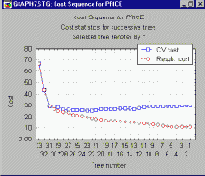
Как видно из графика, цена обучения (например, доля неправильных классификаций в обучающей выборке) заметно уменьшается с увеличением размера дерева. В то же время, цена кросс-проверки с ростом размера дерева быстро достигает минимума, а затем - для очень больших размеров дерева - начинает расти. Обратите внимание на то, что выбранное дерево "подходящего размера" располагается близко к точке перегиба этой кривой, то есть близко к той точке, где первоначальное резкое уменьшение цены кросс-проверки начинает сходить на нет. Процедура "автоматического" выбора дерева направлена на то, чтобы выбирать наиболее простое (наименьшее по размеру) дерево с ценой кросс-проверки, близкой к минимальной, и тем самым избегать потери точности прогноза, происходящей от "недо-" или " пересогласованности " с данными (похожая логика используется в графике каменистой осыпи для определения числа факторов в факторном анализе, см.
также Просмотр результатов анализа главных компонент)
Итак, мы видим, что кросс-проверочное отсечение по минимальной цене-сложности и последующий выбор дерева "подходящего размера" - действительно "автоматические" процедуры. Алгоритм самостоятельно принимает все решения, необходимые для выбора дерева "подходящего размера", за исключением разве что выбора множителя в SE-правиле. В связи с этим возникает вопрос о том, насколько хорошо воспроизводятся результаты, то есть, не может ли получиться так, что при повторении этого процесса "автоматического выбора" будут строиться деревья, сильно отличающиеся друг от друга по размеру. Именно здесь очень полезной может оказаться глобальная кросс-проверка. Как уже говорилось выше, при глобальной кросс-проверке все этапы анализа повторяются заданное число раз (по умолчанию - 3), и при этом часть наблюдений используется как тестовая выборка для кросс-проверки полученного дерева классификации. Если средняя цена тестовых выборок, которая называется ценой глобальной кросс-проверки, превышает цену кросс-проверки выбранного дерева, или если стандартная ошибка цены глобальной кросс-проверки превышает стандартную ошибку цены кросс-проверки для выбранного дерева, то это свидетельствует о том, что процедура "автоматического" выбора дерева вместо устойчивого выбора дерева с минимальным оцененным значением цены дает недопустимо большой разброс результатов.
Деревья классификации в сравнении с традиционными методами.
Деревья классификации в сравнении с традиционными методами.
Как видно из описания методов построения деревьев классификации, в целом ряде аспектов метод деревьев классификации существенно отличается от традиционных статистических методов предсказания принадлежности объекта к определенному классу значений категориальной зависимой переменной. Для сортировки объектов по классам здесь применяется иерархия (последовательность) прогнозов, при этом для одного и того же объекта прогноз может делаться много раз.
В отличие от этого, в традиционных методах используется техника, при которой отнесение каждого объекта к тому или иному классу производится один раз и окончательно. В других отношениях, например по своей конечной цели - достижению точного прогноза, - анализ методом деревьев классификации не отличается от классических методов. Время покажет, достаточно ли у этого метода достоинств, чтобы встать в один ряд с традиционными методами.
Об основных целях анализа с помощью деревьев классификации см. раздел Основные идеи. Об иерархической природе и гибкости деревьев классификации см. раздел Характеристики деревьев классификации.
См. также Методы разведочного анализа данных.
| В начало |
Сравнение с другими пакетами, в которых реализован метод деревьев классификации
Для решения задачи прогнозирования принадлежности объекта (случая) к определенному классу значений зависимой категориальной переменной по данным измерений одной или нескольких предикторных переменных было разработано большое число программ, реализующих метод деревьев классификации. В предыдущем разделе Вычислительные методы мы рассмотрели методы программ QUEST (Loh & Shih, 1997) и CART (Breiman и др., 1984), предназначенные для построения бинарного дерева классификации с помощью одномерных ветвлений для категориальных, порядковых (т.е. измеренных как минимум в порядковой шкале) или смеси обоих типов предикторных переменных. Кроме того, в данном модуле имеется возможность строить дерево классификации с помощью ветвлений по линейным комбинациям для интервальных предикторных переменных.
Некоторые из программ деревьев классификации, в частности FACT (Loh & Vanichestakul, 1988) и THAID (Morgan & Messenger, 1973, сюда же относятся пакеты AID - Automatic Interaction Detection, Morgan & Sonquist, 1963, и CHAID - Chi-Square Automatic Interaction Detection, Kass, 1980) при построении дерева классификации выполняют не бинарные, а многоуровневые ветвления. При многоуровневом ветвлении от одной родительской вершины идут ветви в более чем две дочерние вершины, тогда как при бинарном (двоичном) ветвлении мы всегда получаем ровно две дочерние вершины (независимо от числа уровней переменной ветвления и числа классов зависимой переменной).
Необходимо отметить, что многоуровневое ветвление на самом деле не имеет никаких преимуществ (потому что любое многоуровневое ветвление может быть представлено в виде нескольких последовательных двоичных ветвлений), но может иметь определенные недостатки. В некоторых пакетах фиксированная предикторная переменная может быть использована для многоуровневого ветвления лишь один раз, так что получающееся в результате дерево классификации оказывается слишком коротким и неинтересным (Loh & Shih, 1997). Более серьезная трудность связана со смещением при выборе переменной для ветвления. Такое смещение возможно в любой программе типа THAID (Morgan & Sonquist, 1973), где применяется полный перебор вариантов ветвления (обсуждение этого вопроса см. в Loh & Shih, 1997). Смещение в выборе переменной проявляется в том, что преимущественно выбираются переменные, имеющие много уровней значений, и такое смещение может исказить относительную важность разных предикторных переменных в смысле их влияния на отклик зависимой переменной (см. Breiman и др., 1984).
Смещения в выборе переменной можно избежать, выбрав опцию дискриминантного одномерного или многомерного ветвления модуля Деревья классификации. При этом используются алгоритмы QUEST (Loh & Shih, 1997), предотвращающие смещение в выборе переменной. Опция Полный перебор деревьев с одномерным ветвлением по методу CART модуля Деревья классификации предназначена для тех ситуаций, когда целью анализа является отыскание системы ветвлений, дающей наилучшую классификацию обучающей выборки (которая необязательно окажется лучшей на независимом кросс-проверочной выборке). Для построения надежных вариантов ветвления, а также для большей скорости вычислений мы рекомендуем опцию дискриминантного одномерного ветвления. О построении дерева классификации см. в разделе Вычислительные методы.
Дополнительная информация по методам анализа данных, добычи данных, визуализации и прогнозированию содержится на Портале StatSoft (http://www.statsoft.ru/home/portal/default.asp) и в Углубленном Учебнике StatSoft (Учебник с формулами).

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.