Учебник по промышленной статистике
Графические методы анализа данных
Графические методы анализа данных
Краткий обзор типов графиков
2М графики                    3М XYZ графики     |
  3М последовательные графики      4М/Тернарные графики      2М категоризованные графики   |
3М категоризованные графики Тернарные категоризованные графики n-мерные пиктографики         Матричные графики    |
Типичные методы визуализации
- Категоризованные графики
- Что такое категоризованные графики?
- Методы категоризации
- Гистограммы
- Диаграммы рассеяния
- Вероятностные графики
- Графики квантиль-квантиль
- Графики вероятность-вероятность
- Линейные графики
- Диаграммы размаха
- Круговые диаграммы
- Графики пропущенных значений и диапазонов
- 3М графики
- Тернарные графики
- Закрашивание
- Сглаживание двумерных распределений
- Послойное сжатие
- Проекции трехмерных наборов данных
- Пиктографики
- Анализ пиктографиков
- Систематизация пиктографиков
- Стандартизация значений
- Применения
- Близкие способы графического представления
- Типы графиков
- Маркировка пиктограмм
- Выборка данных
- Вращение (в трехмерном пространстве)
Категоризованные графики
Одним из наиболее мощных аналитических методов исследования является разделение ("разбиение") данных на группы для сравнения структуры получившихся подмножеств. Эти методы широко применяются как в разведочном анализе данных, так и при проверке гипотез и известны под разными названиями (классификация, группировка, категоризация, разбиение, расслоение и пр.). Например, взаимосвязь между возрастом и риском инфаркта может отличаться для мужчин и женщин (для мужчин эта зависимость сильнее). Или например, зависимость между приемом лекарств и снижением уровня холестерина может наблюдаться только для женщин с пониженным давлением и в возрасте 30-40 лет. Производительность или гистограммы мощности могут различаться для временных промежутков, когда управление осуществляется разными операторами. Разным экспериментальным группам также могут соответствовать разные наклоны линий регрессии.
Для количественного описания различий между группами наблюдений разработаны многочисленные вычислительные методы, основанные на группировке данных (например, дисперсионный анализ). Однако графические средства (такие как рассматриваемые в этом разделе категоризованные графики) дают особые преимущества и позволяют выявить закономерности, которые трудно поддаются количественному описанию и которые весьма сложно обнаружить с помощью вычислительных процедур (например, сложные взаимосвязи, исключения или аномалии). В этих случаях графические методы предоставляют уникальные возможности многомерного аналитического исследования или "добычи" данных.
Что такое категоризованные графики
Что такое категоризованные графики
Термин "категоризованные графики" впервые был использован в программе STATISTICA компании StatSoft в 1990 году (кроме того, Becker, Cleveland и Clark из Bell Labs называют их графиками на решетке).
Эти графики представляют собой наборы двумерных, трехмерных, тернарных или n-мерных графиков (таких как гистограммы, диаграммы рассеяния, линейные графики, поверхности, тернарные диаграммы рассеяния и пр.), по одному графику для каждой выбранной категории (подмножества) наблюдений, например, опрашиваемых из Нью-Йорка, Чикаго или Далласа. Эти "входящие" графики располагаются последовательно в одном графическом окне, позволяя сравнивать структуру данных для каждой из указанных подгрупп (например, городов).
Для выбора подгрупп можно использовать множество методов, самый простой из них - это введение категориальной переменной (например, переменной City с значениями New York, Chicago и Dallas). На следующем графике показаны гистограммы переменной, представляющей данные о самооценке стресса жителями каждого из трех городов.
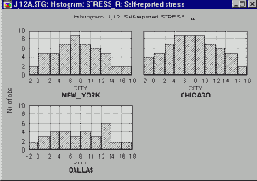
На основе этих данных можно сделать вывод о том, что жители Далласа не очень подвержены стрессам, в то время как распределения уровня стресса в Нью-Йорке и Чикаго довольно похожи.
Некоторые программы (например, система STATISTICA) поддерживают двухвходовую или многомерную категоризацию, где для задания подгрупп используется не один (например, City), а два или более критериев (например, City и Time ). Двухвходовые категоризованные графики можно рассматривать как "таблицы графиков", где каждый входящий график находится на "пересечении" определенных значений первой (например, City) и второй (например, Time) группирующих переменных.

Добавление второго фактора показывает, что картины стрессовых нагрузок в Нью-Йорке и Чикаго в действительности сильно различаются, если учитывается время опроса, в то время как фактор времени практически ничего не меняет в Далласе.
Категоризованные и матричные графики. Матричные графики также состоят из нескольких графиков; однако здесь каждый из них основывается (или может основываться) на одном и том же множестве наблюдений, и графики строятся для всех комбинаций переменных из одного или двух списков.
Для категоризованных графиков требуется такой же выбор переменных, как и для некатегоризованных графиков соответствующего типа (например, две переменных для диаграммы рассеяния). В то же время для категоризованных графиков необходимо указать по крайней мере одну группирующую переменную (или способ разбиения наблюдений на категории), где содержалась бы информация о принадлежности каждого наблюдения к определенной подгруппе (например, Chicago, Dallas). Группирующая переменная не будет непосредственно изображена на графике (т.е. не будет построена), однако она будет служить критерием для разделения всех анализируемых наблюдений на отдельные подгруппы. Как показано выше, для каждой группы (категории), определяемой группирующей переменной, будет построен один график.
Общие и независимые шкалы.
Общие и независимые шкалы.
Каждый элементарный график, входящий в состав категоризованного графика, может быть масштабирован в соответствии со своим собственным диапазоном значений (независимые шкалы).
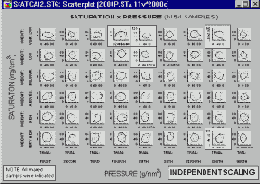
Или все графики могут иметь общую шкалу, достаточно широкую, чтобы охватить весь диапазон значений.

Общий масштаб позволяет сравнивать диапазоны и распределения значений разных категорий. Однако, если эти диапазоны сильно различаются (что приводит к очень большой общей шкале), то исследование некоторых графиков может быть затруднено. Использование независимого масштаба может упростить выявление трендов и определенных закономерностей внутри категорий, но в то же время затруднить сравнение диапазонов значений разных подгрупп.
Методы категоризации
Методы категоризации
Существует пять основных методов категоризации значений, которые будут кратко описаны в этом разделе: целые числа, категории, границы, коды и сложные подгруппы. Обратите внимание, что одни и те же методы категоризации можно использовать как для разбиения наблюдений по входящим графикам, так и для категоризации наблюдений внутри входящих графиков ( например, на гистограммах или диаграммах размаха).
Целые числа.
Целые числа.
При использовании этого режима для определения категорий будут использованы целые значения выбранной группирующей переменной, и для всех наблюдений, принадлежащих каждой категории (заданной этими целыми числами), будет построено по одному графику.
Если выбранная группирующая переменная содержит не целочисленные значения, то программа автоматически округлит каждое значение выделенной переменной до целого числа.
Категории.
Категории.
В этом режиме категоризации нужно указать желаемое число категорий. Программа разделит весь диапазон значений выбранной группирующей переменной (от минимального до максимального) на указанное число интервалов равной длины.
Границы.
Границы.
Метод границ также представляет собой интервальную категоризацию, однако в этом случае интервалы могут иметь произвольную (например, различную) длину, определяемую пользователем (например, "меньше -10", "больше или равно -10, но меньше 0", "больше или равно 0, но меньше 10" и "больше или равно 10").
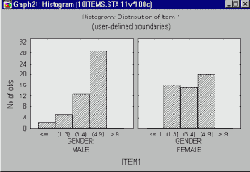
Коды.
Коды.
Этот метод следует использовать в том случае, если выбранная группирующая переменная содержит "коды " (т.е. особые смысловые значения, такие как Male, Female), по которым можно разбить данные на категории.
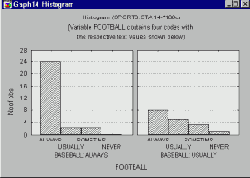
Сложные подгруппы.
Сложные подгруппы.
Этот метод дает возможность пользователю использовать для выделения подгрупп более одной переменной. Другими словами, категоризация, основанная на выделении сложных подгрупп, может представлять не распределения конкретных переменных, а распределения частот определенных "событий" при заданной комбинации значений любого числа переменных текущего набора данных. Например, можно указать шесть категорий, задаваемых комбинациями значений трех переменных Gender, Age и Employment.
Гистограммы
Гистограммы
Гистограммы используются для изучения распределений частот значений переменных. Такое частотное распределение показывает, какие именно конкретные значения или диапазоны значений исследуемой переменной встречаются наиболее часто, насколько различаются эти значения, расположено ли большинство наблюдений около среднего значения, является распределение симметричным или асимметричным, многомодальным (т.е.
имеет две или более вершины) или одномодальным и т.д. Гистограммы также используются для сравнения наблюдаемых и теоретических или ожидаемых распределений.
Категоризованные гистограммы представляют собой наборы гистограмм, соответствующих различным значениям одной или нескольких категоризующих переменных или наборам логических условий категоризации (см. Методы категоризации).
Частотные распределения могут представлять интерес по двум основным причинам.
- По форме распределения можно судить о природе исследуемой переменной (например, бимодальное распределение позволяет предположить, что выборка не является однородной и содержит наблюдения, принадлежащие двум различным множествам, которые в свою очередь нормально распределены).
- Многие статистики основываются на определенных предположениях о распределениях анализируемых переменных; гистограммы позволяют проверить, выполняются ли эти предположения.
Гистограммы и группировка. Категоризованные гистограммы предоставляют такую же информацию о данных, как и группировка (например, среднее, медиану, минимум, максимум, разброс и т.п.; см. главу Основные статистики и таблицы). Хотя конкретные (числовые) значения описательных статистик легко увидеть в таблице, в то же время общую структуру и глобальные характеристики распределения проще изучать на графике. Более того, график дает качественную информацию о распределении, которую невозможно отразить с помощью какого-либо одного параметра. Например, по асимметрии распределения значений дохода можно сделать вывод о том, что большинство населения имеет низкий, а не высокий уровень доходов. Если помимо этого провести группировку данных по этническому и половому признакам, то можно обнаружить, что в некоторых подгруппах эта структура распределения станет еще более ярко выраженной. Хотя эта информация содержится в значении коэффициента асимметрии (для каждой подгруппы), но она легче воспринимается и запоминается, будучи графически представленной на гистограмме. Кроме того, на гистограмме можно наблюдать некоторые "впадины и выпуклости", которые могут свидетельствовать о социальном расслоении в исследуемой группе населения или об аномалиях в распределении дохода отдельных подгрупп, связанных с недавней налоговой реформой.
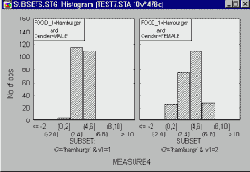
Категоризованные гистограммы и диаграммы рассеяния. Полезное применение категоризации для непрерывных переменных - это представление взаимосвязи трех переменных одновременно. Ниже показана диаграмма рассеяния для двух переменных Load 1 и Load 2.
Предположим, к ним нужно добавить третью переменную (Output) и исследовать ее распределение при различных значения совместного распределения переменных Load 1 и Load 2. Для этого можно построить следующий график:
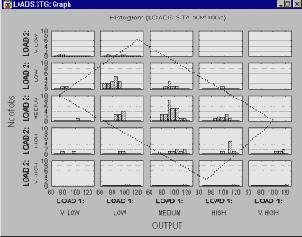
На этом графике обе переменные Load 1 и Load 2 сгруппированы в 5 интервалов, и для каждой комбинации этих интервалов вычислено распределение переменной Output. Обратите внимание, что внутри "прямоугольника" (параллелограмма) находятся наблюдения, одинаковые для обоих показанных выше графиков.
Диаграммы рассеяния
Диаграммы рассеяния
Двумерные диаграммы рассеяния используются для визуализации взаимосвязей между двумя переменными X и Y (например, весом и ростом). На этих диаграммах отдельные точки данных представлены маркерами на плоскости, где оси соответствуют переменным. Две координаты (X и Y), определяющие положение точки, соответствуют значениям переменных. Если между переменными существует сильная взаимосвязь, то точки на графике образуют упорядоченную структуру (например, прямую линию или характерную кривую). Если переменные не взаимосвязаны, то точки образуют "облако".
Можно построить также категоризованные диаграммы рассеяния, сгруппированные по значениям одной или нескольких переменных, а с помощью метода сложных подгрупп (см. Методы категоризации) - диаграммы рассеяния, категоризованные по заданным логическим условиям выбора подгрупп наблюдений.
Категоризованные диаграммы рассеянияпредставляют собой мощный исследовательский и аналитический метод для изучения взаимосвязей между двумя и более переменными среди различных подгрупп.
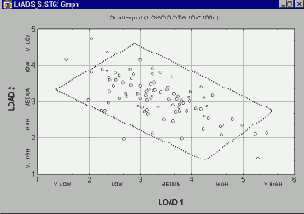
Однородность двумерных распределений (форма взаимосвязей).Диаграммы рассеяния обычно используются для выявления природы взаимосвязи двух переменных (например, кровяного давления и уровня холестерина), поскольку они предоставляют гораздо больше информации, чем коэффициент корреляции.
Например, неоднородность выборки, по которой рассчитываются корреляции, может привести к искажению значений коэффициента корреляции. Предположим, коэффициент корреляции рассчитывается по данным, полученным в двух экспериментальных группах, но этот факт при вычислениях игнорируется. Пусть эксперимент в одной из подгрупп привел к увеличению значений обеих переменных, и на диаграмме рассеяния данные из каждой группы образуют отдельные "облака" (как показано на картинке).
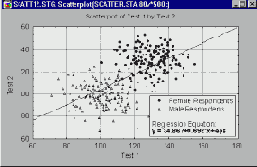
В этом примере большое значение коэффициента корреляции целиком обусловлено распределением по группам и не отражает "истинную" взаимосвязь между двумя переменными, которая практически близка к 0 (это хорошо видно, если рассматривать каждую группу отдельно).
Если вы предполагаете, что подобная структура присутствует и в ваших данных, и знаете, каким образом выделить "подгруппы" наблюдений, то имеет смысл построить категоризованную диаграмму рассеяния.
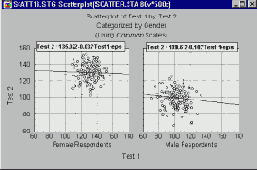
Такой график поможет вам прояснить структуру взаимосвязей между переменными X и Y внутри каждой подгруппы (после соответствующего разбиения наблюдений).
Нелинейные зависимости. С помощью диаграмм рассеяния можно исследовать и нелинейные взаимосвязи между переменными. При этом не существует каких-либо "автоматических" или простых способов оценки нелинейности. Стандартный коэффициент корреляции Пирсона r позволяет оценить только линейность связи, а некоторые непараметрические корреляции, например, Спирмена R, дают возможность оценить нелинейность, но только для монотонных зависимостей. На диаграммах рассеяния можно изучить структуру взаимосвязей, чтобы затем с помощью преобразования привести данные к линейному виду или выбрать подходящую нелинейную подгонку.
Дополнительную информацию можно найти в разделах Основные статистики, Непараметрическая статистика и распределения, Множественная регрессия и Нелинейное оценивание.
Вероятностные графики
Вероятностные графики
Существует три типа категоризованных вероятностных графиков: нормальные, полунормальные и с исключенным трендом.
Нормальные вероятностные графики - это быстрый способ визуальной проверки степени соответствия данных нормальному распределению.
В свою очередь категоризованные вероятностные графики дают возможность исследовать близость к нормальному распределению различных подгрупп данных .
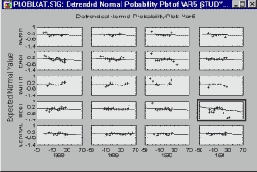
Категоризованные нормальные вероятностные графики представляют собой эффективный инструмент для исследования однородности группы наблюдений с точки зрения соответствия нормальному распределению.
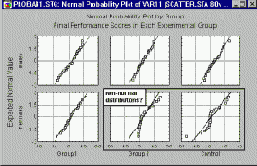
Графики квантиль-квантиль
Графики квантиль-квантиль
Категоризованные графики квантиль-квантиль (или К-К) используются для поиска в определенном семействе распределений того распределения, которое наилучшим образом описывает имеющиеся данные.
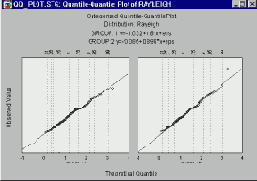
В случае категоризованных графиков К-К строится набор графиков квантиль-квантиль, по одному для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации). Для графиков К-К используются следующие семейства распределений: экспоненциальное, экстремальное, нормальное, Релея, бета-, гамма-, логнормальное и Вейбулла.
Графики вероятность-вероятность
Графики вероятность-вероятность
Категоризованные графики вероятность-вероятность (или В-В) используются для проверки соответствия конкретного теоретического распределения имеющимся исходным данным. На этих графиках для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации) создается по одному графику вероятность-вероятность.
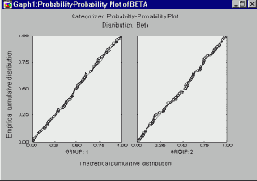
На графиках В-В строится наблюдаемая функция распределения (доля непропущенных значений

Если не все точки данных располагаются на диагональной линии, то на таком графике можно визуально выделить группы наблюдений, соответствующие и не соответствующие искомому распределению (если, к примеру, точки образуют кривую S-образной формы вокруг диагональной линии, то к ним можно применить определенное преобразование для приведения к нужной форме распределения).
Линейные графики
Линейные графики
На линейных графиках отдельные точки данных соединяются линиями. Это простой способ визуального представления последовательности значений (например, цены на фондовом рынке за несколько дней торгов). Категоризованные линейные графики строятся в том случае, если необходимо разбить данные на несколько групп (категоризовать) с помощью группирующей переменной (например, цены при закрытии рынка по понедельникам, вторникам и т.д.) или с помощью логических условий, составленных по нескольким переменным (например, цены при закрытии рынка в те дни, когда две другие акции и индекс Доу Джонса выросли по сравнению с другими ценами закрытия; см. Методы категоризации).
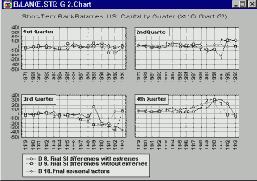
Диаграммы размаха
Диаграммы размаха
На диаграммах размаха (этот термин был впервые использован Тьюки в 1970 году) представлены диапазоны значений выбранной переменной (или переменных) для отдельных групп наблюдений. Для выделения этих групп используются от одной до трех категориальных (группирующих) переменных или набор логических условий выбора подгрупп.
Для каждой группы наблюдений вычисляется центральная тенденция (медиана или среднее), а также размах или изменчивость (квартили, стандартные ошибки или стандартные отклонения). Выбранные параметры отображаются на графике одним из пяти способов (Прямоугольники-Отрезки, Отрезки, Прямоугольники, Столбцы или Верхние-нижние засечки). На этом графике можно показать и выбросы (см. разделы о выбросах и крайних точках).
На следующем графике, например, выбор факторов можно было бы считать вполне удачным, если бы не "досадное" несоответствие, на которое указывают выделенные на рисунке выбросы (в данном случае это значения, попадающие за пределы 1,5 квартильных размахов):
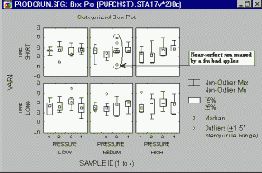
А на следующем рисунке не показаны ни выбросы, ни крайние точки.
Можно выделить два основных направления использования диаграмм размаха: (a) отображение диапазонов значений отдельных элементов, наблюдений или выборок (например, типичные минимаксные графики цен на акции или товары или графики агрегированных данных с диапазонами), (б) отображение изменения значений в отдельных группах или выборках (например, когда точкой внутри прямоугольника представлено среднее значение для каждой выборки, сам прямоугольник соответствует значениям стандартной ошибки, а меньший прямоугольник или пара "отрезков" обозначает стандартное отклонение от среднего).
С помощью диаграмм размаха, на которых представлены характеристики изменчивости, можно быстро оценить и "интуитивно представить" силу связи между группирующей и зависимой переменной. Предположив, что зависимая переменная нормально распределена, и зная долю наблюдений, попадающих, к примеру, в интервал ±1 или ±2 стандартных отклонения от среднего (см. Элементарные понятия статистики), можно сделать, например, вывод о том, что 95% наблюдений из экспериментальной группы 1 попадают в другой диапазон значений, нежели 95% наблюдений из группы 2.
На этих графиках можно изобразить и так называемые усеченные средние (этот термин был впервые использован Тьюки в 1962 году), которые вычисляются после исключения заданного пользователем процента наблюдений с концов (хвостов) распределения.
Круговые диаграммы
Круговые диаграммы
Одним из наиболее широко используемых типов графического представления данных являются круговые диаграммы, на которых показаны пропорции или сами значения переменных. Категоризованные графики этого типа состоят из нескольких круговых диаграмм, где данные разделены по группам с помощью одной или нескольких группирующих переменных (например, gender) или категоризованы согласно логическим условиям выбора подгрупп (см.
Методы категоризации).
В дальнейшем, говоря о категоризации этих графиков, мы будем иметь ввиду круговые диаграммы частот (в противоположность круговым диаграммам значений). Эти типы графиков, называемые также частотными круговыми диаграммами, представляют данные аналогично гистограммам. Все значения выбранной переменной категоризуются с помощью заданного метода категоризации, а затем относительные значения частот отображаются в виде сегментов круговой диаграммы пропорционального размера. Таким образом, эти графики являются альтернативным представлением гистограммы частот (см. раздел о категоризованных гистограммах).
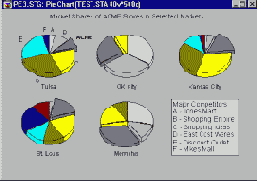
Диаграммы рассеяния круговых диаграмм. Еще одно очень полезное применение категоризованных круговых диаграмм - это представление относительных частот значений какой-либо переменной в различных "местах" совместного распределения двух других переменных. Например:

Обратите внимание, что круговые диаграммы изображены только в тех "местах", где имеются данные. Показанный выше график напоминает диаграмму рассеяния (переменных L1 и L2), где маркерами точек являются круговые диаграммы. Однако помимо обычной информации, содержащейся в диаграмме рассеяния, здесь в каждой точке дополнительно показано относительное распределение третьей переменной (а именно, доля значений Low, Medium и High Quality).
Графики пропущенных значений и данных вне диапазона
Графики пропущенных значений и данных вне диапазона
На этих графиках можно наглядно представить структуру распределения точек данных, содержащих пропущенные значения или находящихся "вне диапазонов", заданных пользователем. При этом строится по одной двумерной диаграмме для каждой группы наблюдений, выделенной с помощью группирующих переменных или с помощью условий выбора сложных подгрупп (см. Методы категоризации).
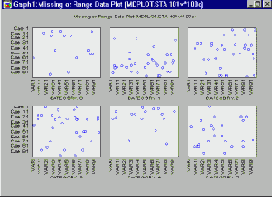
Эти типы графиков используются в разведочном анализе данных, чтобы определить, является ли случайным распределение точек с пропущенными значениями, а также для оценки их диапазона.
Трехмерные (3М) графики
Трехмерные (3М) графики
Трехмерные диаграммы рассеяния (пространственные, спектральные, трассировочные и диаграммы отклонений), карты линий уровня и поверхности также можно построить для подгрупп наблюдений, заданных с помощью выбранной категориальной переменной или логических условий выбора (см. Методы категоризации). Основная задача этих графиков - упростить сравнение взаимосвязей между тремя и более переменными для различных групп или категорий наблюдений.
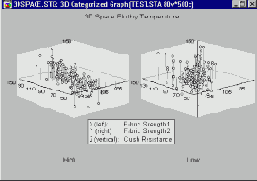
Применения. Трехмерные графики в координатах XYZ отображают взаимосвязи между тремя переменными. С помощью различных способов категоризации можно исследовать эти зависимости при различных условиях (т.е. в разных группах).
Изучая, например, показанный ниже категоризованный график поверхности, можно сделать вывод о том, что величина допуска прибора не влияет на измерения (переменные Depend1, Depend2 и Height), кроме случая, когда она
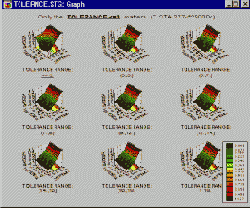
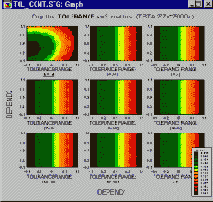
Этот вывод становится еще более очевидным, если использовать вместо поверхности карту линий уровня.
Тернарные графики
Тернарные графики
Категоризованные тернарные графики используются для исследования взаимосвязей между тремя и более переменными, три из которых представляют собой компоненты смеси (т.е. для каждого наблюдения значения их суммы являются постоянной величиной), при этом отдельный график строится для каждого уровня группирующей переменной.
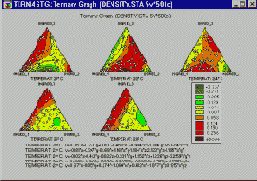
Для построения тернарных графиков используется треугольная система координат на плоскости или в пространстве и строится зависимость между четырьмя (или более) переменными (компонентами X, Y и Z и откликами V1, V2 и т.д.). При этом накладываются ограничения на относительные значения каждой из компонент, чтобы они в сумме давали одинаковую величину для каждого наблюдения (например, 1).
На категоризованных тернарных графиках строится по одному графику для каждого значения группирующей переменной (или заданного пользователем подмножества данных), и все они отображаются в одном графическом окне, чтобы можно было сравнивать различные подгруппы наблюдений.
Применения. Эти графики применяются для анализа результатов эксперимента, в котором измеряемый отклик зависит от относительного соотношения трех компонент (например, трех химических веществ при составлении смесей), которое варьируется с целью определения его оптимального значения. Эти типы графического представления можно использовать и в других случаях, когда взаимосвязь между переменными, на которые наложены определенные ограничения, необходимо исследовать для различных групп или категорий наблюдений.

| В начало |
Закрашивание
Закрашивание
Закрашивание является одним из первых и, по-видимому, наиболее широко распространенных методов, известных как графический разведочный анализ данных. Этот метод позволяет интерактивно выделять на экране отдельные точки или подмножества данных и задавать их характеристики, или исследовать их влияние на взаимосвязи между переменными (например, на матрицах диаграмм рассеяния) и идентифицировать выбросы(например, с помощью меток).
Связи между переменными можно наглядно представить с помощью аппроксимирующих функций (например, двумерных кривых или трехмерных поверхностей) и доверительных интервалов. Интерактивно удаляя или добавляя определенные подгруппы наблюдений, можно наблюдать за изменениями этих функций и их параметров. Одно из применений метода закрашивания - это, например, выделение на матричной диаграмме рассеяния всех точек данных, принадлежащих определенной категории (например, на показанном ниже рисунке на правом верхнем графике выделена группа наблюдений, соответствующих значению "среднего" уровня дохода).
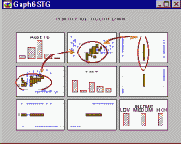
Такое исследование помогает определить, как эти конкретные наблюдения влияют на связи между другими переменными того же набора данных (например, на корреляцию между "расходами" и "активами").
В режиме "динамического закрашивания" (см. следующий пример) или "автоматического обновления функции подгонки" можно задать движение кисти по определенным последовательным диапазонам выбранной переменной (например, непрерывной, а не дискретной, как на показанном ранее примере) и исследовать динамику вклада этой переменной в связи между другими переменными этого набора данных.

| В начало |
Сглаживание двумерных распределений
Сглаживание двумерных распределений
Для наглядного представления таблицы значений двух переменных используются трехмерные гистограммы. Их можно рассматривать как объединение двух простых гистограмм для совместного анализа частот значений двух переменных. Чаще всего на этом графике для каждой "ячейки" таблицы нарисован один трехмерный столбец, а его высота соответствует частоте значений в этой ячейке. При построении трехмерной гистограммы для каждой из двух переменных можно использовать свой метод категоризации (см. ниже).
Когда предусмотрены процедуры сглаживания данных, то трехмерное представление частот значений можно аппроксимировать поверхностью. Такое сглаживание можно осуществить для любой трехмерной гистограммы. Для достаточно простой структуры данных (как на предыдущем рисунке) такое сглаживание не имеет особого смысла.
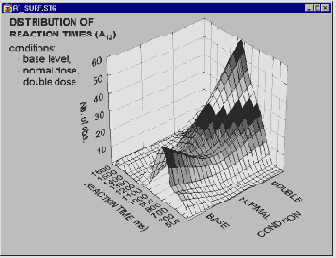
Однако, в случае более сложной картины распределения частот эта процедура может оказаться эффективным инструментом разведочного анализа данных

и позволит выявить особенности, которые трудно обнаружить на обычной трехмерной гистограмме (например, показанную выше "волновую структуру" поверхности).
| В начало |
Послойное сжатие
Послойное сжатие
На графиках этого типа за счет сокращения области основного графика освобождается место для графиков на полях, которые располагаются в правой и верхней части графического окна (включая маленький угловой график). Эти графики на полях представляют собой соответственно вертикально и горизонтально сжатые изображения основного графика.
Послойное сжатие двумерных графиков является методом разведочного анализа данных, который дает возможность скрытые тренды и структуры двумерных наборов данных. Рассмотрим следующий рисунок.
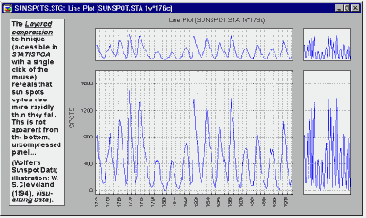
Здесь на примере, приведенном Кливландом (Cleveland, 1993), можно убедиться, что в каждом цикле солнечной активности число пятен уменьшается гораздо медленнее, чем нарастает в начале цикла.
Такое поведение совершенно не очевидно при исследовании обычного линейного графика, в то время как сжатый график позволяет обнаружить эту скрытую картину.
| В начало |
Проекции трехмерных наборов данных
Полезным методом изучения и аналитического исследования структуры поверхности (созданной, как правило, по трехмерным наборам данных) является построение ее проекции на плоскость в виде карты линий уровня.

Эти графики менее эффективны для быстрого визуального анализа формы трехмерных структур по сравнению с графиками поверхности,
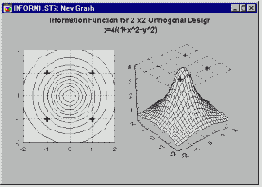
однако их преимущество заключается в возможности точного исследования формы поверхности -

на картах линий уровня отображается ряд не искаженных горизонтальных "сечений".
| В начало |
Пиктографики
Пиктографики
На пиктографиках каждое наблюдение представлено в виде многомерного символа, что позволяет использовать эти типы графического представления данных в качестве не очень простого, но мощного исследовательского инструмента. Главная идея такого метода анализа основана на человеческой способности "автоматически" фиксировать сложные связи между многими переменными, если они проявляются в последовательности элементов (в данном случае "пиктограмм"). Иногда понимание (или "чувство") того, что некоторые элементы "чем-то похожи" друг на друга, приходит раньше, чем наблюдатель (аналитик) может объяснить, какие именно переменные обусловливают это сходство (Lewicki, Hill, & Czyzewska, 1992). Конкретную природу проявившихся взаимосвязей между переменными позволяет выявить уже последующий анализ данных, основанный на изучении этого интуитивно обнаруженного сходства.
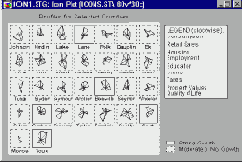
Основная идея пиктографиков заключается в представлении элементарных наблюдений как отдельных графических объектов, где значения переменных соответствуют определенным чертам или размерам объекта (обычно одно наблюдение = одному объекту). Это соответствие устанавливается таким образом, чтобы общий вид объекта менялся в зависимости от конфигурации значений.
Таким образом, объекты имеют определенный "внешний вид", который уникален для каждой конфигурации значений и может быть идентифицирован наблюдателем. Изучение таких пиктограмм помогает выявить как простые связи, так и сложные взаимодействия между переменными.
Анализ пиктографиков
Анализ пиктографиков
Целесообразно проводить анализ пиктографиков в пять этапов.
- Сначала выберите порядок анализируемых переменных. В большинстве случаев наилучшим вариантом оказывается случайная последовательность. Кроме того, можно попробовать расположить их в порядке, соответствующем полученному уравнению множественной регрессии, факторным нагрузкам или объясняемым факторам (см. главу Факторный анализ). Таким образом можно упростить и сделать более "однородным" общий вид пиктограмм, чтобы легче идентифицировать слабо выраженные различия. В то же время такой подход может затруднить идентификацию некоторых структур. На этом этапе можно дать только один универсальный совет: прежде чем использовать какие-либо сложные методы, попробуйте наиболее простой и быстрый вариант, а именно, случайную последовательность переменных.
- Попробуйте обнаружить какие-либо закономерности, например, сходства между группами пиктограмм, выбросы или определенные связи между элементами (например, " если первые два луча звезды длинные, то как правило, с другой стороны есть один или два коротких луча"). На этом этапе лучше использовать пиктографики кругового типа.
- При обнаружении закономерностей постарайтесь сформулировать их в терминах конкретных переменных.
- Измените соответствие переменных и элементов пиктограмм (или переключитесь на один из последовательных пиктографиков), чтобы проверить обнаруженную структуру взаимосвязей (например, попробуйте переместить ближе друг к другу элементы, между которыми обнаружена связь). В некоторых случаях в конце этого этапа целесообразно исключить из рассмотрения те переменные, которые не вносят явного вклада в обнаруженную структуру.
- И наконец, используйте один из численных методов (таких как регрессионный анализ, нелинейное оценивание, дискриминантный или кластерный анализ), чтобы проверить и попытаться количественно оценить обнаруженные закономерности или хотя бы их часть.
Систематизация пиктографиков
Большинство пиктографиков можно отнести к одной из двух групп: круговые и последовательные.
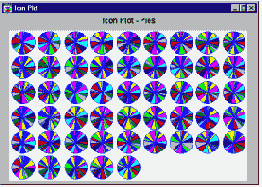
Круговые пиктографики. Круговые пиктографики (звезды, лучи, многоугольники) имеют вид "велосипедного колеса", на них значения переменных представлены расстояниями между центром пиктограммы ("втулкой") и их концами.
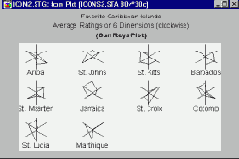
Такие графики могут помочь в обнаружении связей между переменными, которые проявляются в общей структуре пиктограмм и зависят от конфигурации значений самих переменных.
Чтобы описать такую " общую картину" в терминах конкретных моделей или проверить имеющиеся предположения, имеет смысл использовать последовательные пиктографики, которые могут оказаться более эффективными, если уже известно, что именно требуется обнаружить.
Последовательные пиктографики. Последовательные пиктографики (столбцы, профили, линии) представляют собой набор картинок с маленькими последовательными графиками (различных типов).
Последовательные пиктографики. Последовательные пиктографики (столбцы, профили, линии) представляют собой набор картинок с маленькими последовательными графиками (различных типов).

Значения переменных представлены здесь расстояниями между основанием пиктограммы и последовательными точками (например, высотами показанных выше столбцов). Эти графики менее эффективны на начальной стадии разведочного анализа, поскольку пиктограммы очень похожи между собой. Однако, как уже упоминалось ранее, такое представление может быть весьма полезным для проверки уже сформулированной гипотезы.
Пиктограммы круговых диаграмм. Эти пиктографики нельзя однозначно отнести к одной из двух групп. Все они имеют круговую форму, но в то же время последовательно разделены в соответствии с значениями переменных.
Пиктограммы круговых диаграмм. Эти пиктографики нельзя однозначно отнести к одной из двух групп. Все они имеют круговую форму, но в то же время последовательно разделены в соответствии с значениями переменных.
Их можно отнести скорее к последовательным, чем к круговым пиктографикам, но можно использовать и в том, и в другом случае.
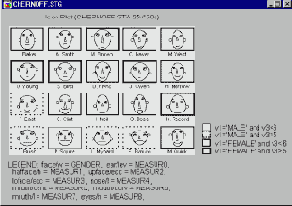
"Лица Чернова". Этот тип пиктографиков составляет отдельную группу. Здесь каждое наблюдение представляет собой схематичное изображение лица, определенным чертам которого соответствуют относительные значения выбранных переменных.
"Лица Чернова". Этот тип пиктографиков составляет отдельную группу. Здесь каждое наблюдение представляет собой схематичное изображение лица, определенным чертам которого соответствуют относительные значения выбранных переменных.

Некоторые исследователи рассматривают этот способ графического представления данных как уникальный многомерный метод разведочного анализа, позволяющий выявить такие скрытые картины взаимосвязей между переменными, которые не могут быть обнаружены другими методами. Вероятно, такое заявление можно считать преувеличением. Кроме того, следует заметить, что этот способ исследования весьма непрост в применении и требует большого опыта в том, что касается сопоставления переменных чертам лица. См. также раздел Методы "добычи данных" .
Стандартизация значений
Стандартизация значений
Как правило, при построении пиктографиков значения переменных должны быть стандартизованы, чтобы их можно было сравнивать в пределах одной пиктограммы. Исключения составляют те случаи, когда на пиктограммах необходимо отобразить глобальные различия диапазонов выбранных переменных. Поскольку масштаб пиктограммы определяется наибольшим значением, то на пиктограмме могут отсутствовать те переменные, которые имеют значения другого порядка малости, например, на пиктограмме звезды некоторые лучи могут оказаться настолько короткими, что совсем не будут видны..
Применения
Применения
Пиктографики обычно используются: (1) для обнаружения структур или кластеров наблюдений и (2) для исследования сложных взаимосвязей между несколькими переменными. Первый вариант соответствует кластерному анализу; т.е. процедуре классификации наблюдений.
Предположим, вы изучали характеры актеров и записали их ответы на вопросы анкеты.
С помощью пиктографика можно определить, существуют ли группы артистов, которые отличаются по их ответам на заданные вопросы (можно, к примеру, обнаружить, что некоторые артисты являются творческими, недисциплинированными и независимыми личностями, в то время как другая группа состоит из умных, дисциплинированных людей, которые ценят свою популярность).
Другая область применений - изучение взаимосвязей между переменными - напоминает факторный анализ, который используется для исследования вопроса о зависимости переменных. Предположим, изучалось мнение группы людей о различных марках автомобилей. В файле данных записаны средние оценки по каждому из свойств (рассматриваемых как переменные) для каждого из автомобилей (рассматриваемых как наблюдения).
При изучении "лиц Чернова" (где каждое лицо представляет мнение об одном из автомобилей) может оказаться, что улыбающиеся лица обычно имеют большие уши; при этом, если цене соответствует "ширина" улыбки, а динамическим качествам - размер ушей, то это "открытие" означает, что быстрые машины являются более дорогими. Разумеется, это очень простой пример; однако при реальном анализе данных применение этого метода может сделать более очевидными сложные взаимосвязи между многими переменными.
Близкие способы графического представления
Близкие способы графического представления
Связи между переменными из одного или двух списков могут быть представлены на матричных графиках. Использование матричных графиков одновременно с выделением подгрупп позволяет получить информацию, подобную той, которая отображается на пиктографиках.
Если использовать методы выделения подгрупп на диаграммах рассеяния, то для исследования взаимосвязей между двумя переменными можно использовать обычные 2М диаграммы рассеяния; а в случае трех переменных - 3Мдиаграммы рассеяния.
Типы графиков
Типы графиков
Существуют различные типы пиктографиков.
"Лица Чернова". Для каждого наблюдения рисуется отдельное "лицо"; при этом относительные значения выбранных переменных соответствуют форме и размерам определенных его черт (например, длине носа, изгибу бровей, ширине лица).
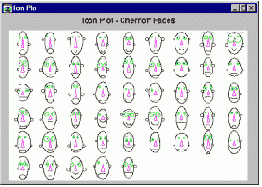
Дополнительно см. абзац "Лица Чернова" в разделе Систематизация пиктографиков.
Звезды. Это пиктографики кругового типа. Для каждого наблюдения рисуется пиктограмма в виде звезды; относительные значения выбранных переменных соответствуют относительным длинам лучей каждой звезды (по часовой стрелке, начиная с 12:00). Концы лучей соединены линиями.

Лучи. Эти пиктографики также относятся к круговому типу. Для каждого наблюдения строится одна пиктограмма. Каждый луч соответствует одной из выбранных переменных (по часовой стрелке, начиная с 12:00), и на нем отложено значение соответствующей переменной. Эти значения соединены линиями.

Многоугольники. Это пиктографикикругового типа. Для каждого наблюдения рисуется отдельный многоугольник; относительные значения выбранных переменных соответствуют расстояниям вершин от центра многоугольника (по часовой стрелке, начиная с 12:00).

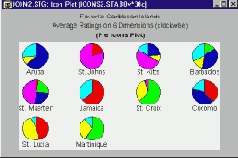
Круговые диаграммы. Это пиктографики кругового типа. Для каждого наблюдения рисуется круговая диаграмма; относительные значения выбранных переменных соответствуют размерам сегментов диаграммы (по часовой стрелке, начиная с 12:00).
Столбцы. Это пиктографики последовательного типа. Для каждого наблюдения строится столбчатая диаграмма; относительные значения выбранных переменных соответствуют высотам последовательных столбцов.
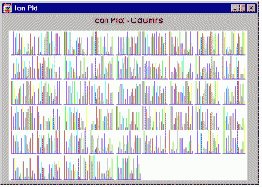
Линии. Это пиктографики последовательного типа.
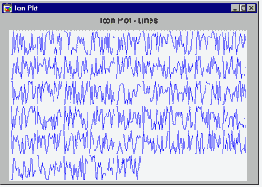
Для каждого наблюдения строится линейный график; относительные значения выбранных переменных соответствуют расстояниям точек излома линии от основания графика.
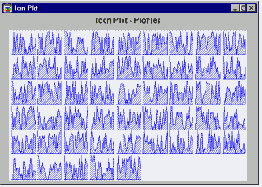
Профили. Это пиктографики последовательного типа. Для каждого наблюдения строится зонный график; относительные значения выбранных переменных соответствуют расстояниям последовательных пиков сечения над линией основания.
Маркировка пиктограмм
Маркировка пиктограмм
Если программа позволяет вам выделять подгруппы наблюдений, то это свойство можно использовать и для маркировки соответствующих пиктограмм.
При этом вокруг выделенных пиктограмм будут нарисованы рамки.
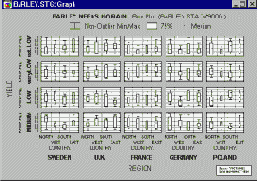
Шаблоны рамок, идентифицирующих заданные подгруппы, будут показаны в условных обозначениях рядом с текстом соответствующих условий выбора наблюдений. На следующем графике показан пример маркированных подгрупп.
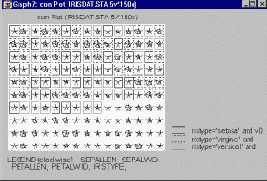
Все наблюдения, удовлетворяющие условию для подгруппы 1 (значение переменной Iristype равно значению переменной Setosa и номер наблюдения меньше 100), обозначены специальной рамкой вокруг пиктограммы.
А все наблюдения, которые удовлетворяют условию для подгруппы 2 (значение переменной Iristype равно значению переменной Virginic и номер наблюдения меньше 100), обозначены на графике рамкой другого цвета.
| В начало |
Выборка данных
Выборка данных
Иногда отображение на графике слишком большого числа точек данных затрудняет изучение их структуры (см. следующий рисунок). Если файл данных слишком большой, то имеет смысл показать на графике лишь подмножество наблюдений, чтобы общая картина не была скрыта маркерами точек.

Некоторые программы предлагают методы выборки (или оптимизации) данных, которые в ряде случаев могут оказаться весьма полезны. При этом пользователь может задать целое число n, меньшее числа наблюдений в файле данных, а программа случайным образом выберет из этого файла приблизительно n допустимых наблюдений и именно их построит на графике.
Заметим, что такие методы сокращения набора данных (или размера выборки) эффективно отображают случайную структуру этих данных. Очевидно, эти методы принципиально отличаются от методов выделения конкретного подмножества или подгруппы наблюдений с помощью определенных критериев (например, по полу, области или уровню холестерина). Последние можно применять интерактивно (например, в режиме динамического закрашивания) или каким-либо другим способом (например, на категоризованных графиках или с помощью условий выбора наблюдений). Все эти методы в равной мере могут помочь в идентификации сложной структуры большого набора данных.
| В начало |
Вращение (в трехмерном пространстве)
Вращение (в трехмерном пространстве)
Изменение угла зрения при отображении трехмерной диаграммы рассеяния (простой, спектральной или пространственной) может оказаться эффективным средством для выявления некоторой структуры, которая видна только при определенном повороте "облака" точек (см. следующий рисунок).
Некоторые программы предоставляют полезный инструмент для интерактивного изменения перспективы и вращения изображения. Эти средства контроля изображения позволяют подобрать подходящий угол зрения и перспективу, чтобы найти наиболее удачное расположение "точки зрения" на график, а также дают возможность управлять его вращением в горизонтальной и вертикальной плоскости.
Эти инструменты могут оказаться весьма полезными не только при начальном разведочном анализе данных, но и при исследовании факторного пространства (см.Факторный анализ) или пространства размерностей (см. Многомерное шкалирование).
| В начало |

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.