Учебник по промышленной статистике
Методы добычи данных
Методы добычи данных
- Понятие добычи данных
- Хранилища данных
- Опертивная аналитическая обработка данных (OLAP)
- Разведочный анализ данных (РАД) и методы добычи данных
- РАД и проверка гипотез
- Вычислительные методы РАД
- Графические методы РАД (визуализация данных)
- Проверка результатов РАД
- Нейронные сети
- Понятие добычи данных
- Хранилища данных
- Опертивная аналитическая обработка данных (OLAP)
- Разведочный анализ данных (РАД) и методы добычи данных
- РАД и проверка гипотез
- Вычислительные методы РАД
- Графические методы РАД (визуализация данных)
- Проверка результатов РАД
- Нейронные сети
Понятие "добыча данных" (Data Mining)
StatSoft определяет понятие "добыча данных" как процесс аналитического исследования больших массивов информации (обычно экономического характера) с целью выявления определенных закономерностей и систематических взаимосвязей между переменными, которые затем можно применить к новым совокупностям данных. Этот процесс включает три основных этапа: исследование, построение модели или структуры и ее проверку. В идеальном случае, при достаточном количестве данных можно организовать итеративную процедуру для построения устойчивой (робастной) модели. В то же время, в реальной ситуации практически невозможно проверить экономическую модель на стадии анализа и поэтому начальные результаты имеют характер эвристик, которые можно использовать в процессе принятия решения (например, "Имеющиеся данные свиделельствуют о том, что у женщин частота приема снотворных средств увеличивается с возрастом быстрее, чем у мужчин.").

Методы добычи данных приобретают все большую популярность в качестве инструмента для анализа экономической информации, особенно в тех случаях, когда предполагается, что из имеющихся данных можно будет извлечь знания для принятия решений в условиях неопределенности. Хотя в последнее время возрос интерес к разработке новых методов анализа данных, специально предназначенных для сферы бизнеса (например, Деревья классификации), в целом системы добычи данных по-прежнему основываются на классических принципах разведочного анализа данных (РАД) и построения моделей и используют те же подходы и методы.
Имеется, однако, важное отличие процедуры добычи данных от классического разведочного анализа данных (РАД) : системы добычи данных в большей степени ориентированы на практическое приложение полученных результатов, чем на выяснение природы явления. Иными словами, при добыче данных нас не очень интересует конкретный вид зависимостей между переменными задачи. Выяснение природы участвующих здесь функций или конкретной формы интерактивных многомерных зависимостей между переменными не является главной целью этой процедуры. Основное внимание уделяется поиску решений, на основе которых можно было бы строить достоверные прогнозы. Таким образом, в области добычи данных принят такой подход к анализу данных и извлечению знаний, который иногда характеризуют словами "черный ящик". При этом используются не только классические приемы разведочного анализа данных, но и такие методы, как нейронные сети , которые позволяют строить достоверные прогнозы, не уточняя конкретный вид тех зависимостей, на которых такой прогноз основан.
Очень часто добыча данных трактуется как "смесь статистики, методов искуственного интеллекта (ИИ) и анализа баз данных" (Pregibon, 1997, p. 8), и до последнего времени она не признавалась полноценной областью интереса для специалистов по статистике, а порой ее даже называли "задворками статистики" (Pregibon, 1997, p. 8). Однако, благодаря своей большой практической значимости, эта проблематика ныне интенсивно разрабатывается и привлекает большой интерес (в том числе и в ее статистических аспектах), и в ней достигнуты важные теоретические результаты (см. например, материалы ежегодно проводимой Международной конференции по поиску знаний и добыче данных( International Conferences on Knowledge Discovery and Data Mining), одним из организаторов которой в 1997 году стала Американская статистическая ассоциация - American Statistical Association).
Информацию по методам добычи данных можно найти в разделах Разведочный анализ данных и Нейронные сети; подробный обзор и обсуждение этой проблематики см.
в работах Fayyad, Piatetsky-Shapiro, Smyth & Uthurusamy (1996). Большой набор статей по этой тематике имеется в журнале Proceedings from the American Association of Artificial Intelligence Workshops on Knowledge Discovery in Databases published by AAAI Press (см. в частности, Piatetsky-Shapiro, 1993; Fayyad & Uthurusamy, 1994).
Добыча данных часто рассматривается как естественное развитие концепции хранилищ данных (см. далее).
| В начало |
Хранилища данных (Data Warehousing)
Хранилища данных (Data Warehousing)
StatSoft определяет понятие хранилища данных как способ хранения больших многомерных массивов данных, который позволяет легко извлекать и использовать информацию в процедурах анализа.
Эффективная архитектура хранилища данных должна быть организована таким образом, чтобы быть составной частью информационной системы управления предприятием (или по крайней мере иметь связь со всеми доступными данными). При этом необходимо использовать специальные технологии работы с корпоративными базами данных (например, Oracle, Sybase, MS SQL Server). Высокопроизводительная технология хранилищ данных, позволяющая пользователям организовать и эффективно использовать базу данных предприятия практически неограниченной сложности, разработана компанией StatSoft enterprise systems и называется SENS [STATISTICA Enterprise System] и SEWSS [STATISTICA Enterprise-Wide SPC System]).
| В начало |
Оперативная аналитическая обработка данных (OLAP)
Оперативная аналитическая обработка данных (OLAP)
Термин OLAP (или FASMI - быстрый анализ распределенной многомерной информации) обозначает методы, которые дают возможность пользователям многомерных баз данных в реальном времени генерировать описательные и сравнительные сводки ("views") данных и получать ответы на различные другие аналитические запросы. Обратите внимание, что несмотря на свое название, этот метод не подразумевает интерактивную обработку данных (в режиме реального времени); он означает процесс анализа многомерных баз данных (которые, в частности, могут содержать и динамически обновляемую информацию) путем составления эффективных "многомерных" запросов к данным различных типов. Средства OLAP могут быть встроены в корпоративные (масштаба предприятия) системы баз данных и позволяют аналитикам и менеджерам следить за ходом и результативностью своего бизнеса или рынка в целом (например, за различными сторонами производственного процесса или количеством и категориями совершенных сделок по разным регионам). Анализ, проводимый методами OLAP может быть как простым (например, таблицы частот, описательные статистики, простые таблицы), так и достаточно сложным (например, он может включать сезонные поправки, удаление выбросов и другие способы очистки данных).
Хотя методы добычи данных можно применять к любой, предварительно не обработанной и даже неструктурированной информации, их можно также использовать для анализа данных и отчетов, полученных средствами OLAP, с целью более углубленного исследования, как правило, в более высоких размерностях. В этом смысле методы добычи данных можно рассматривать как альтернативный аналитический подход (служащий иным целям, нежели OLAP) или как аналитическое расширение систем OLAP.
| В начало |
Разведочный анализ данных (РАД)
Разведочный анализ данных (РАД)
РАД и проверка гипотез
РАД и проверка гипотез
В отличие от традиционной проверки гипотез, предназначенной для проверки априорных предположений, касающихся связей между переменными (например, "Имеется положительная корреляция между возрастом человека и его/ее нежеланием рисковать"), разведочный анализ данных (РАД) применяется для нахождения связей между переменными в ситуациях, когда отсутствуют (или недостаточны) априорные представления о природе этих связей. Как правило, при разведочном анализе учитывается и сравнивается большое число переменных, а для поиска закономерностей используются самые разные методы. Вычислительные методы РАД
Вычислительные методы РАД
Вычислительные методы разведочного анализа данных включают основные статистические методы, а также более сложные, специально разработанные методы многомерного анализа, предназначенные для отыскания закономерностей в многомерных данных. Основные методы разведочного статистического анализа.
Основные методы разведочного статистического анализа.
К основным методам разведочного статистического анализа относится процедура анализа распределений переменных (например, чтобы выявить переменные с несимметричным или негауссовым распределением, в том числе и бимодальные), просмотр корреляционных матриц с целью поиска коэффициентов, превосходящих по величине определенные пороговые значения (см. предыдущий пример), или анализ многовходовых таблиц частот (например, "послойный" последовательный просмотр комбинаций уровней управляющих переменных).
Методы многомерного разведочного анализа.
Методы многомерного разведочного анализа.
Методы многомерного разведочного анализа специально разработаны для поиска закономерностей в многомерных данных (или последовательностях одномерных данных). К ним относятся: кластерный анализ, факторный анализ, анализ лискриминантных функций, многомерное шкалирование, логлинейный анализ, канонические корреляции, пошаговая линейная и нелинейная (например, логит) регрессия, анализ соответствий, анализ временных рядов и деревья классификации.
Нейронные сети.
Нейронные сети.
Этот класс аналитических методов основан на идее воспроизведения процессов обучения мыслящих существ (как они представляются исследователям) и функций нервных клеток. Нейронные сети могут прогнозировать будущие значения переменных по уже имеющимся значениям этих же или других переменных, предварительно осуществив процесс так называемого обучения на основе имеющихся данных.
Дополнительную информацию см. в разделе Нейронные сети; а также в модуле STATISTICA Neural Networks.
Графические методы РАД (визуализация данных)
Графические методы РАД (визуализация данных)
Широкий набор мощных методов разведочного анализа данных представлен также средствами графической визуализации данных. С их помощью можно находить зависимости, тренды и смещения, "скрытые" в неструктурированных наборах данных. Закрашивание.
Закрашивание.
Возможно, самым распространенным и исторически первым из методов, которые с полным основанием можно отнести к графическому разведочному анализу данных, стало закрашивание - интерактивный метод, позволяющий пользователю выбирать на экране компьютера отдельные точки-наблюдения или группы таких точек, находить их характеристики (в том числе общие) и изучать влияние отдельных наблюдений на соотношения между различными переменными . Эти соотношения между переменными также могут быть визуализированы с помощью подгоночных функций (например, прямыми в двумерном или поверхностями в трехмерном случае) вместе с соответствующими доверительными интервалами, и, таким образом, пользователь может в интерактивном режиме исследовать изменения параметров этих функций, временно удаляя или добавляя фрагменты набора данных.
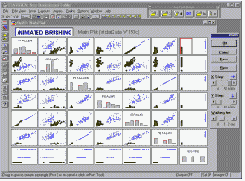
С помощью закрашивания, например, можно выбрать (выделить) на одной из матричных диаграмм рассеяния все точки данных, принадлежащие определенной категории, На следующем рисунке, например, на четвертом графике в первом ряду выделены точки, соответствущие "среднему" уровню дохода.

Таким образом можно определить, как эти наблюдения влияют на взаимосвязи между другими переменными этого набора данных (например, на корреляцию между переменными "debt" и "assets" ). В режиме "динамического закрашивания" или "автоматического обновления функции подгонки" можно задать движение кисти по определенным последовательным диапазонам выбранной переменной (например, по непрерывным значениям переменной "income" или по ее дискретным значениям, как показано на предыдущем рисунке) и исследовать динамику вклада этой переменной в связи между другими переменными текущего набора данных.
Другие графические методы РАД.
Другие графические методы РАД.
К другим аналитическим графическим методам относятся подгонка и построение функций, сглаживание данных, наложение и объединение нескольких изображений, категоризация данных, расщепление или слияние подгрупп данных на графике, агрегирование данных, идентификация и маркировка подгрупп данных, удовлетворяющих определенным условиям, построение пиктографиков,
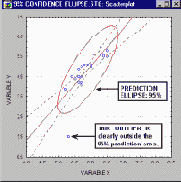
штриховка, построение доверительных интервалов и областей (например, эллипсов),
создание мозаичных структур, спектральных плоскостей,
послойное сжатие,
а также использование карт линий уровня, методов редукции выборки, интерактивного (и динамического) вращения
и динамического расслоения трехмерных изображений, выделение определенных наборов и блоков данных.
Проверка результатов РАД
Проверка результатов РАД
Предварительное исследование данных может служить лишь первым этапом в процессе их анализа, и пока результаты не подтверждены (методами кросс-проверки) на других фрагментах базы данных или на независимом множестве данных, их можно воспринимать самое большее как гипотезу.
Если результаты разведочного анализа говорят в пользу некоторой модели, то ее правильность можно затем проверить, применив ее к новым данных и определив степень ее согласованности с данными (проверка "способности к прогнозированию"). Для быстрого выделения различных подмножеств данных (например, для очистки, проверки и пр.) и оценки надежности результатов удобно пользоваться условиями выбора наблюдений.
| В начало |
Нейронные сети
Нейронные сети
Нейронные сети - это класс аналитических методов, построенных на (гипотетических) принципах обучения мыслящих существ и функционирования мозга и позволяющих прогнозировать значения некоторых переменных в новых наблюдениях по данным других наблюдений (для этих же или других переменных) после прохождения этапа так называемого обучения на имеющихся данных. Нейроные сети являются одним из методов так называемой добычи данных.
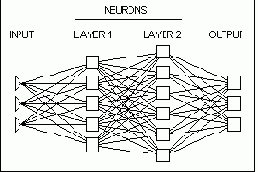
При применении этих методов прежде всего встает вопрос выбора конкретной архитектуры сети (числа "слоев" и количества "нейронов" в каждом из них). Размер и структура сети должны соответствовать (например, в смысле формальной вычислительной сложности) существу исследуемого явления. Поскольку на начальном этапе анализа природа явления обычно не бывает хорошо известна, выбор архитектуры является непростой задачей и часто связан с длительным процессом "проб и ошибок" (однако, в последнее время стали появляться нейронно-сетевые программы, в которых для решения этой трудоемкой задачи поиска "наилучшей" архитектуры сети применяются методы искусственного интеллекта).
Затем построенная сеть подвергается процессу так называемого "обучения". На этом этапе нейроны сети итеративно обрабатывают входные данных и корректируют свои веса таким образом, чтобы сеть наилучшим образом прогнозировала (в традиционных терминах следовало бы сказать "осуществляла подгонку") данные, на которых выполняется "обучение". После обучения на имеющихся данных сеть готова к работе и может использоваться для построения прогнозов.
"Сеть", полученная в результате "обучения", выражает закономерности, присутствующие в данных. При таком подходе она оказывается функциональным эквивалентом некоторой модели зависимостей между переменными, подобной тем, которые строятся в традиционном моделировании. Однако, в отличие от традиционных моделей, в случае "сетей" эти зависимости не могут быть записаны в явном виде, подобно тому как это делается в статистике (например, "A положительно коррелировано с B для наблюдений, у которых величина C мала, а D - велика"). Иногда нейронные сети выдают прогноз очень высокого качества; однако, они представляют собой типичный пример нетеоретического подхода к исследованию (иногда это называют "черным ящиком"). При таком подходе мы сосредотачиваемся исключительно на практическом результате - в данном случае - на точности прогнозов и их прикладной ценности, - а не на сути механизмов, лежащих в основе явления, или соответствии полученных результатов какой-либо имеющейся "теории".
Следует, однако, отметить, что методы нейронных сетей могут применяться и в таких исследованиях, где целью является построение объясняющей модели явления, поскольку нейронные сети помогают изучать данные на предмет поиска значимых переменных или групп таких переменных, и полученные результаты могут облегчить процесс последующего построения модели. Более того, сейчас имеются нейросетевые программы, которые с помощью сложных алгоритмов могут находить наиболее важные входные переменные, что уже непосредственно помогает строить модель.
Одно из главных преимуществ нейронные сетей состоит в том, что они, по крайней мере теоретически, могут аппроксимировать любую непрерывную функцию, и поэтому исследователю нет необходимости заранее принимать какие-либо гипотезы относительно модели, и даже - в ряде случаев - о том, какие переменные действительно важны. Однако, существенным недостатком нейронных сетей является то обстоятельство, что окончательное решение зависит от начальных установок сети и, как уже говорилось выше, его практически невозможно "интерпретировать" в традиционных аналитических терминах, которые обычно применяются при построении теории явления.
Некоторые авторы отмечают тот факт, что нейронные сети используют или, точнее, предполагают использование вычислительных систем с массовым параллелизмом. Например Haykin (1994, p. 2) определяет нейронную сеть как
"процессор с массивным распараллеливанием операций, обладающий естественной способностью сохранять экспериментальные знания и делать их доступными для последующего использования. Он похож на мозг в двух отношениях: (1) сеть приобретает знания в результате процесса обучения и (2) для хранения информации используются величины интенсивности межнейронных соединений, которые называются синаптическими весами". (p. 2).
Однако, как отмечает Ripley (1996), большинство существующих нейросетевых программ работают на однопроцессорных компьютерах. По его мнению, существенное ускорение работы может быть достигнуто не только за счет разработки программного обеспечения, использующего преимущества многопроцессорных систем, но также путем разработки более эффективных алгоритмов обучения.
Нейронные сети - это один из методов, применяемых для так называемой добычи данных; см. также Разведочный анализ данных. Дополнительную информацию по нейронным сетям можно найти в работах Haykin (1994), Masters (1995), Ripley (1996) и Welstead (1994). Относительно характеристик нейронных сетей как инструмента статистического анализа см. работу Warner и Misra (1996). См. также описание модуля STATISTICA Neural Networks.
| В начало |

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.