Учебник по промышленной статистике
Нейронные сети
Нейронные сети
- Введение
- Параллели из биологии
- Базовая искусственная модель
- Применение нейронных сетей
- Сбор данных для нейронной сети
- Выводы
- Пре/пост процессирование
- Многослойный персептрон (MLP)
- Обучение многослойного персептрона
- Алгоритм обратного распространения
- Переобучение и обобщение
- Отбор данных
- Как обучается многослойный персептрон
- Другие алгоритмы обучения многослойного персептрона
- Радиальная базисная функция
- Вероятностная нейронная сеть
- Обобщенно-регрессионная нейронная сеть
- Линейная сеть
- Сеть Кохонена
- Решение задач классификации в пакете ST: Neural Networks
- Таблица статистик классификации
- Решение задач регрессии в пакете ST: Neural Networks
- Прогнозирование временных рядов в пакете ST: Neural Networks
- Отбор переменных и понижение размерности
Многие понятия, относящиеся к методам нейронных сетей, лучше всего объяснять на примере конкретной нейронно-сетевой программы. Поэтому в данном разделе будет много ссылок на пакет STATISTICA Neural Networks ( сокращенно, ST Neural Networks, нейронно-сетевой пакет фирмы StatSoft), представляющий собой реализацию всего набора нейросетевых методов анализа данных.
- Введение
- Параллели из биологии
- Базовая искусственная модель
- Применение нейронных сетей
- Сбор данных для нейронной сети
- Выводы
- Пре/пост процессирование
- Многослойный персептрон (MLP)
- Обучение многослойного персептрона
- Алгоритм обратного распространения
- Переобучение и обобщение
- Отбор данных
- Как обучается многослойный персептрон
- Другие алгоритмы обучения многослойного персептрона
- Радиальная базисная функция
- Вероятностная нейронная сеть
- Обобщенно-регрессионная нейронная сеть
- Линейная сеть
- Сеть Кохонена
- Решение задач классификации в пакете ST: Neural Networks
- Таблица статистик классификации
- Решение задач регрессии в пакете ST: Neural Networks
- Прогнозирование временных рядов в пакете ST: Neural Networks
- Отбор переменных и понижение размерности
Многие понятия, относящиеся к методам нейронных сетей, лучше всего объяснять на примере конкретной нейронно-сетевой программы.
Поэтому в данном разделе будет много ссылок на пакет STATISTICA Neural Networks ( сокращенно, ST Neural Networks, нейронно-сетевой пакет фирмы StatSoft), представляющий собой реализацию всего набора нейросетевых методов анализа данных.
Введение
Введение
В последние несколько лет мы наблюдаем взрыв интереса к нейронным сетям, которые успешно применяются в самых различных областях - бизнесе, медицине, технике, геологии , физике. Нейронные сети вошли в практику везде, где нужно решать задачи прогнозирования, классификации или управления. Такой впечатляющий успех определяется несколькими причинами:
- Богатые возможности. Нейронные сети - исключительно мощный метод моделирования, позволяющий воспроизводить чрезвычайно сложные зависимости. В частности, нейронные сети нелинейны по свой природе (смысл этого понятия подробно разъясняется далее в этой главе). На протяжение многих лет линейное моделирование было основным методом моделирования в большинстве областей, поскольку для него хорошо разработаны процедуры оптимизации. В задачах, где линейная аппроксимация неудовлетворительна (а таких достаточно много), линейные модели работают плохо. Кроме того, нейронные сети справляются с "проклятием размерности", которое не позволяет моделировать линейные зависимости в случае большого числа переменных
- Простота в использовании. Нейронные сети учатся на примерах. Пользователь нейронной сети подбирает представительные данные, а затем запускает алгоритм обучения, который автоматически воспринимает структуру данных. При этом от пользователя, конечно, требуется какой-то набор эвристических знаний о том, как следует отбирать и подготавливать данные, выбирать нужную архитектуру сети и интерпретировать результаты, однако уровень знаний, необходимый для успешного применения нейронных сетей, гораздо скромнее, чем, например, при использовании традиционных методов статистики.
В будущем развитие таких нейро-биологических моделей может привести к созданию действительно мыслящих компьютеров. Между тем уже "простые" нейронные сети, которые строит система ST Neural Networks , являются мощным оружием в арсенале специалиста по прикладной статистике.
| В начало |
Параллели из биологии
Параллели из биологии
Нейронные сети возникли из исследований в области искусственного интеллекта, а именно, из попыток воспроизвести способность биологических нервных систем обучаться и исправлять ошибки, моделируя низкоуровневую структуру мозга (Patterson, 1996). Основной областью исследований по искусственному интеллекту в 60-е - 80-е годы были экспертные системы. Такие системы основывались на высокоуровневом моделировании процесса мышления (в частности, на представлении, что процесс нашего мышления построен на манипуляциях с символами). Скоро стало ясно, что подобные системы, хотя и могут принести пользу в некоторых областях, не ухватывают некоторые ключевые аспекты человеческого интеллекта. Согласно одной из точек зрения, причина этого состоит в том, что они не в состоянии воспроизвести структуру мозга. Чтобы создать искусственных интеллект, необходимо построить систему с похожей архитектурой. Мозг состоит из очень большого числа (приблизительно 10,000,000,000) нейронов, соединенных многочисленными связями (в среднем несколько тысяч связей на один нейрон, однако это число может сильно колебаться). Нейроны - это специальная клетки, способные распространять электрохимические сигналы. Нейрон имеет разветвленную структуру ввода информации (дендриты), ядро и разветвляющийся выход (аксон). Аксоны клетки соединяются с дендритами других клеток с помощью синапсов. При активации нейрон посылает электрохимический сигнал по своему аксону. Через синапсы этот сигнал достигает других нейронов, которые могут в свою очередь активироваться. Нейрон активируется тогда, когда суммарный уровень сигналов, пришедших в его ядро из дендритов, превысит определенный уровень (порог активации).
.Интенсивность сигнала, получаемого нейроном (а следовательно и возможность его активации), сильно зависит от активности синапсов. Каждый синапс имеет протяженность, и специальные химические вещества передают сигнал вдоль него. Один из самых авторитетных исследователей нейросистем, Дональд Хебб, высказал постулат, что обучение заключается в первую очередь в изменениях "силы" синаптических связей. Например, в классическом опыте Павлова, каждый раз непосредственно перед кормлением собаки звонил колокольчик, и собака быстро научилась связывать звонок колокольчика с пищей. Синаптические связи между участками коры головного мозга, ответственными за слух, и слюнными железами усилились, и при возбуждении коры звуком колокольчика у собаки начиналось слюноотделение.
Таким образом, будучи построен из очень большого числа совсем простых элементов (каждый из которых берет взвешенную сумму входных сигналов и в случае, если суммарный вход превышает определенный уровень, передает дальше двоичный сигнал), мозг способен решать чрезвычайно сложные задачи. Разумеется, мы не затронули здесь многих сложных аспектов устройства мозга, однако интересно то, что искусственные нейронные сети способны достичь замечательных результатов, используя модель, которая ненамного сложнее, чем описанная выше.
| В начало |
Базовая искусственная модель
Базовая искусственная модель
Чтобы отразить суть биологических нейронных систем, определение искусственного нейрона дается следующим образом:
- Он получает входные сигналы (исходные данные либо выходные сигналы других нейронов нейронной сети) через несколько входных каналов. Каждый входной сигнал проходит через соединение, имеющее определенную интенсивность (или вес); этот вес соответствует синаптической активности биологического нейрона. С каждым нейроном связано определенное пороговое значение. Вычисляется взвешенная сумма входов, из нее вычитается пороговое значение и в результате получается величина активации нейрона (она также называется пост-синаптическим потенциалом нейрона - PSP).
- Сигнал активации преобразуется с помощью функции активации (или передаточной функции) и в результате получается выходной сигнал нейрона.
В действительности, как мы скоро увидим, пороговые функции редко используются в искусственных нейронных сетях. Учтите, что веса могут быть отрицательными, - это значит, что синапс оказывает на нейрон не возбуждающее, а тормозящее воздействие (в мозге присутствуют тормозящие нейроны). Это было описание отдельного нейрона. Теперь возникает вопрос: как соединять нейроны друг с другом? Если сеть предполагается для чего-то использовать, то у нее должны быть входы (принимающие значения интересующих нас переменных из внешнего мира) и выходы (прогнозы или управляющие сигналы). Входы и выходы соответствуют сенсорным и двигательным нервам - например, соответственно, идущим от глаз и в руки. Кроме этого, однако, в сети может быть еще много промежуточных (скрытых) нейронов, выполняющих внутренние функции. Входные, скрытые и выходные нейроны должны быть связаны между собой.
Ключевой вопрос здесь - обратная связь (Haykin, 1994). Простейшая сеть имеет структуру прямой передачи сигнала: Сигналы проходят от входов через скрытые элементы и в конце концов приходят на выходные элементы. Такая структура имеет устойчивое поведение. Если же сеть рекуррентная (т.е. содержит связи, ведущие назад от более дальних к более ближним нейронам), то она может быть неустойчива и иметь очень сложную динамику поведения. Рекуррентные сети представляют большой интерес для исследователей в области нейронных сетей, однако при решении практических задач, по крайней мере до сих пор, наиболее полезными оказались структуры прямой передачи, и именно такой тип нейронных сетей моделируется в пакете ST Neural Networks.
.Типичный пример сети с прямой передачей сигнала показан на рисунке. Нейроны регулярным образом организованы в слои. Входной слой служит просто для ввода значений входных переменных. Каждый из скрытых и выходных нейронов соединен со всеми элементами предыдущего слоя. Можно было бы рассматривать сети, в которых нейроны связаны только с некоторыми из нейронов предыдущего слоя; однако, для большинства приложений сети с полной системой связей предпочтительнее, и именно такой тип сетей реализован в пакете ST Neural Networks.
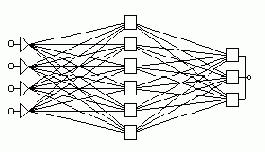
При работе (использовании) сети во входные элементы подаются значения входных переменных, затем последовательно отрабатывают нейроны промежуточных и выходного слоев. Каждый из них вычисляет свое значение активации, беря взвешенную сумму выходов элементов предыдущего слоя и вычитая из нее пороговое значение. Затем значение активации преобразуются с помощью функции активации, и в результате получается выход нейрона. После того, как вся сеть отработает, выходные значения элементов выходного слоя принимаются за выход всей сети в целом.
| В начало |
Применение нейронных сетей
Применение нейронных сетей
В предыдущем разделе в несколько упрощенном виде было описано, как нейронная сеть преобразует входные сигналы в выходные. Теперь возникает следующий важный вопрос: как применить нейронную сеть к решению конкретной задачи? Класс задач, которые можно решить с помощью нейронной сети, определяется тем, как сеть работает и тем, как она обучается. При работе нейронная сеть принимает значения входных переменных и выдает значения выходных переменных. Таким образом, сеть можно применять в ситуации, когда у Вас имеется определенная известная информация, и Вы хотите из нее получить некоторую пока не известную информацию (Patterson, 1996; Fausett, 1994). Вот некоторые примеры таких задач:
Прогнозирование на фондовом рынке.
Прогнозирование на фондовом рынке.
Зная цены акций за последнюю неделю и сегодняшнее значение индекса FTSE, спрогнозировать завтрашнюю цену акций.
Предоставление кредита.
Предоставление кредита.
Требуется определить, высок ли риск предоставления кредита частному лицу, обратившемуся с такой просьбой. В результате разговора с ним известен его доход, предыдущая кредитная история и т.д.
Управление.
Управление.
Нужно определить что должен делать робот (повернуться направо или налево, двигаться вперед и т.д.), чтобы достичь цели; известно изображение, которое передает установленная на роботе видеокамера.
Разумеется, вовсе не любую задачу можно решить с помощью нейронной сети.
Если Вы хотите определить результаты лотереи, тираж которой состоится через неделю, зная свой размер обуви, то едва ли это получится, поскольку эти вещи не связаны друг с другом. На самом деле, если тираж проводится честно, то не существует такой информации, на основании которой можно было бы предсказать результат. Многие финансовые структуры уже используют нейронные сети или экспериментируют с ними с целью прогнозирования ситуации на фондовом рынке, и похоже, что любой тренд, прогнозируемый с помощью нейронных методов, всякий раз уже бывает "дисконтирован" рынком, и поэтому (к сожалению) эту задачу Вам тоже вряд ли удастся решить.
Итак, мы приходим ко второму важному условию применения нейронных сетей: Вы должны знать (или хотя бы иметь серьезные подозрения), что между известными входными значениями и неизвестными выходами имеется связь. Эта связь может быть искажена шумом (так, едва ли можно ожидать, что по данным из примера с прогнозированием цен акций можно построить абсолютно точный прогноз, поскольку на цену влияют и другие факторы, не представленные во входном наборе данных, и кроме того в задаче присутствует элемент случайности), но она должна существовать.
Как правило, нейронная сеть используется тогда, когда неизвестен точный вид связей между входами и выходами, - если бы он был известен, то связь можно было бы моделировать непосредственно. Другая существенная особенность нейронных сетей состоит в том, что зависимость между входом и выходом находится в процессе обучения сети. Для обучения нейронных сетей применяются алгоритмы двух типов (разные типы сетей используют разные типы обучения): управляемое ("обучение с учителем") и не управляемое ("без учителя"). Чаще всего применяется обучение с учителем, и именно этот метод мы сейчас рассмотрим (о неуправляемом обучении будет рассказано позже).
Для управляемого обучения сети пользователь должен подготовить набор обучающих данных. Эти данные представляют собой примеры входных данных и соответствующих им выходов.
Сеть учится устанавливать связь между первыми и вторыми. Обычно обучающие данные берутся из исторических сведений. В рассмотренных выше примерах это могут быть предыдущие значения цен акций и индекса FTSE, сведения о прошлых заемщиках - их анкетные данные и то, успешно ли они выполнили свои обязательства, примеры положений робота и его правильной реакции.
Затем нейронная сеть обучается с помощью того или иного алгоритма управляемого обучения (наиболее известным из них является метод обратного распространения, предложенный в работе Rumelhart et al., 1986), при котором имеющиеся данные используются для корректировки весов и пороговых значений сети таким образом, чтобы минимизировать ошибку прогноза на обучающем множестве. Если сеть обучена хорошо, она приобретает способность моделировать (неизвестную) функцию, связывающую значения входных и выходных переменных, и впоследствии такую сеть можно использовать для прогнозирования в ситуации, когда выходные значения неизвестны.
| В начало |
Сбор данных для нейронной сети
Сбор данных для нейронной сети
Если задача будет решаться с помощью нейронной сети, то необходимо собрать данные для обучения. Обучающий набор данных представляет собой набор наблюдений, для которых указаны значения входных и выходных переменных. Первый вопрос, который нужно решить, - какие переменные использовать и сколько (и каких) наблюдений собрать. Выбор переменных (по крайней мере первоначальный) осуществляется интуитивно. Ваш опыт работы в данной предметной области поможет определить, какие переменные являются важными. При работе с пакетом ST Neural Networks Вы можете произвольно выбирать переменные и отменять предыдущий выбор; кроме того, система ST Neural Networks умеет сама опытным путем отбирать полезные переменные. Для начала имеет смысл включить все переменные, которые, по Вашему мнению, могут влиять на результат - на последующих этапах мы сократим это множество.
Нейронные сети могут работать с числовыми данными, лежащими в определенном ограниченном диапазоне.
Это создает проблемы в случаях, когда данные имеют нестандартный масштаб, когда в них имеются пропущенные значения, и когда данные являются нечисловыми. В пакете ST Neural Networks имеются средства, позволяющие справиться со всеми этими трудностями. Числовые данные масштабируются в подходящий для сети диапазон, а пропущенные значения можно заменить на среднее значение (или на другую статистику) этой переменной по всем имеющимся обучающим примерам (Bishop, 1995).
Более трудной задачей является работа с данными нечислового характера. Чаще всего нечисловые данные бывают представлены в виде номинальных переменных типа Пол = {Муж , Жен }. Переменные с номинальными значениями можно представить в числовом виде, и в системе ST Neural Networks имеются средства для работы с такими данными. Однако, нейронные сети не дают хороших результатов при работе с номинальными переменными, которые могут принимать много разных значений.
Пусть, например, мы хотим научить нейронную сеть оценивать стоимость объектов недвижимости. Цена дома очень сильно зависит от того, в каком районе города он расположен. Город может быть подразделен на несколько десятков районов, имеющих собственные названия, и кажется естественным ввести для обозначения района переменную с номинальными значениями. К сожалению, в этом случае обучить нейронную сеть будет очень трудно, и вместо этого лучше присвоить каждому району определенный рейтинг (основываясь на экспертных оценках).
Нечисловые данные других типов можно либо преобразовать в числовую форму, либо объявить незначащими. Значения дат и времени, если они нужны, можно преобразовать в числовые, вычитая из них начальную дату (время). Обозначения денежных сумм преобразовать совсем несложно. С произвольными текстовыми полями (например, фамилиями людей) работать нельзя и их нужно сделать незначащими.
Вопрос о том, сколько наблюдений нужно иметь для обучения сети, часто оказывается непростым. Известен ряд эвристических правил, увязывающих число необходимых наблюдений с размерами сети (простейшее из них гласит, что число наблюдений должно быть в десять раз больше числа связей в сети).
На самом деле это число зависит также от (заранее неизвестной) сложности того отображения, которое нейронная сеть стремится воспроизвести. С ростом количества переменных количество требуемых наблюдений растет нелинейно, так что уже при довольно небольшом (например, пятьдесят) числе переменных может потребоваться огромное число наблюдений. Эта трудность известна как "проклятие размерности", и мы обсудим ее дальше в этой главе.
Для большинства реальных задач бывает достаточно нескольких сотен или тысяч наблюдений. Для особо сложных задач может потребоваться еще большее количество, однако очень редко может встретиться (даже тривиальная) задача, где хватило бы менее сотни наблюдений. Если данных меньше, чем здесь сказано, то на самом деле у Вас недостаточно информации для обучения сети, и лучшее, что Вы можете сделать - это попробовать подогнать к данным некоторую линейную модель. В пакете ST Neural Networks реализованы средства для подгонки линейных моделей (см. раздел про линейные сети, а также материал по модулю Множественная регрессия системы STATISTICA).
Во многих реальных задачах приходится иметь дело с не вполне достоверными данными. Значения некоторых переменных могут быть искажены шумом или частично отсутствовать. Пакет ST Neural Networks имеет специальные средства работы с пропущенными значениями (они могут быть заменены на среднее значение этой переменной или на другие ее статистики), так что если у Вас не так много данных, Вы можете включить в рассмотрение случаи с пропущенными значениями (хотя, конечно, лучше этого избегать). Кроме того, нейронные сети в целом устойчивы к шумам. Однако у этой устойчивости есть предел. Например, выбросы, т.е. значения, лежащие очень далеко от области нормальных значений некоторой переменной, могут исказить результат обучения. В таких случаях лучше всего постараться обнаружить и удалить эти выбросы (либо удалив соответствующие наблюдения, либо преобразовав выбросы в пропущенные значения). Если выбросы выявить трудно, то можно воспользоваться имеющимися в пакете ST Neural Networks возможностями сделать процесс обучения устойчивым к выбросам (с помощью функции ошибок типа "городских кварталов"; см.
Bishop, 1995), однако такое устойчивое к выбросам обучение, как правило, менее эффективно, чем стандартное.
Выводы
Выводы
Выбирайте такие переменные, которые, как Вы предполагаете, влияют на результат.
С числовыми и номинальными переменными в пакете ST Neural Networks можно работать непосредственно. Переменные других типов следует преобразовать в указанные типы или объявить незначащими.
Для анализа нужно иметь порядка сотен или тысяч наблюдений; чем больше в задаче переменных, тем больше нужно иметь наблюдений. Пакет ST Neural Networks имеет средства для распознавания значимых переменных, поэтому включайте в рассмотрение переменные, в значимости которых Вы не уверены.
В случае необходимости можно работать с наблюдениями, содержащими пропущенные значения. Наличие выбросов в данных может создать трудности. Если возможно, удалите выбросы. Если данных достаточное количество, уберите из рассмотрения наблюдения с пропущенными значениями.
| В начало |
Пре/пост процессирование
Пре/пост процессирование
Всякая нейронная сеть принимает на входе числовые значения и выдает на выходе также числовые значения. Передаточная функция для каждого элемента сети обычно выбирается таким образом, чтобы ее входной аргумент мог принимать произвольные значения, а выходные значения лежали бы в строго ограниченном диапазоне ("сплющивание"). При этом, хотя входные значения могут быть любыми, возникает эффект насыщения, когда элемент оказывается чувствительным лишь к входным значениям, лежащим в некоторой ограниченной области. На этом рисунке представлена одна из наиболее распространенных передаточных функций - так называемая логистическая функция (иногда ее также называют сигмоидной функцией, хотя если говорить строго, это всего лишь один из частных случаев сигмоидных - т.е. имеющих форму буквы S - функций). В этом случае выходное значение всегда будет лежать в интервале (0,1), а область чувствительности для входов чуть шире интервала (-1,+1). Данная функция является гладкой, а ее производная легко вычисляется - это обстоятельство весьма существенно для работы алгоритма обучения сети (в этом также кроется причина того, что ступенчатая функция для этой цели практически не используется).
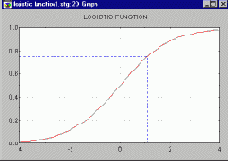
Коль скоро выходные значения всегда принадлежат некоторой ограниченной области, а вся информация должна быть представлена в числовом виде, очевидно, что при решении реальных задач методами нейронных сетей требуются этапы предварительной обработки - пре-процессирования - и заключительной обработки - пост-процессирования данных (Bishop, 1995). Соответствующие средства имеются в пакете ST Neural Networks. Здесь нужно рассмотреть два вопроса:
Шкалирование.
Шкалирование.
Числовые значения должны быть приведены в масштаб, подходящий для сети. Обычно исходные данные масштабируются по линейной шкале. В пакете ST Neural Networks реализованы алгоритмы минимакса и среднего/стандартного отклонения, которые автоматически находят масштабирующие параметры для преобразования числовых значений в нужный диапазон.
В некоторых случаях более подходящим может оказаться нелинейное шкалирование (например, если заранее известно, что переменная имеет экспоненциальное распределение, имеет смысл взять ее логарифм). Нелинейное шкалирование не реализовано в модуле ST Neural Networks. Вы можете прошкалировать переменную средствами преобразования даных базовой системы STATISTICA, а затем работать с ней в модуле ST Neural Networks.
Номинальные переменные.
Номинальные переменные.
Номинальные переменные могут быть двузначными (например, Пол ={Муж, Жен}) или многозначными (т.е. принимать более двух значений или состояний). Двузначную номинальную переменную легко преобразовать в числовую (например, Муж = 0, Жен = 1). С многозначными номинальными переменными дело обстоит сложнее. Их тоже можно представить одним числовым значением (например, Собака = 0, Овца = 1, Кошка = 2), однако при этом возникнет (возможно) ложное упорядочивание значений номинальной переменной: в рассмотренном примере Овца окажется чем-то средним между Собакой и Кошкой. Существует более точный способ, известный как кодирование 1-из-N, в котором одна номинальная переменная представляется несколькими числовыми переменными.
Количество числовых переменных равно числу возможных значений номинальной переменной; при этом всякий раз ровно одна из N переменных принимает ненулевое значение (например, Собака = {1,0,0}, Овца = {0,1,0}, Кошка = {0,0,1}). В пакете ST Neural Networks имеются возможности преобразовывать как двух-, так и многозначные номинальные переменные для последующего использования в нейронной сети. К сожалению, номинальная переменная с большим числом возможных состояний потребует при кодировании методом 1-из-N очень большого количества числовых переменных, а это приведет к росту размеров сети и создаст трудности при ее обучении. В таких ситуациях возможно (но не всегда достаточно) смоделировать номинальную переменную с помощью одного числового индекса, однако лучше будет попытаться найти другой способ представления данных.
Задачи прогнозирования можно разбить на два основных класса: классификация и регрессия.
В задачах классификации нужно бывает определить, к какому из нескольких заданных классов принадлежит данный входной набор. Примерами могут служить предоставление кредита (относится ли данное лицо к группе высокого или низкого кредитного риска), диагностика раковых заболеваний (опухоль, чисто), распознавание подписи (поддельная, подлинная). Во всех этих случаях, очевидно, на выходе требуется всего одна номинальная переменная. Чаще всего (как в этих примерах) задачи классификации бывают двузначными, хотя встречаются и задачи с несколькими возможными состояниями.
В задачах регрессии требуется предсказать значение переменной, принимающей (как правило) непрерывные числовые значения: завтрашнюю цену акций, расход топлива в автомобиле, прибыли в следующем году и т.п.. В таких случаях в качестве выходной требуется одна числовая переменная.
Нейронная сеть может решать одновременно несколько задач регрессии и/или классификации, однако обычно в каждый момент решается только одна задача. Таким образом, в большинстве случаев нейронная сеть будет иметь всего одну выходную переменную; в случае задач классификации со многими состояниями для этого может потребоваться несколько выходных элементов (этап пост-процессирования отвечает за преобразование информации из выходных элементов в выходную переменную).
В пакете ST Neural Networks для решения всех этих вопросов реализованы специальные средства пре- и пост-процессирования, которые позволяют привести сырые исходные данные в числовую форму, пригодную для обработки нейронной сетью, и преобразовать выход нейронной сети обратно в формат входных данных. Нейронная сеть служит "прослойкой"между пре- и пост-процессированием, и результат выдается в нужном виде (например, в задаче классификации выдается название выходного класса). Кроме того, в пакете ST Neural Networks пользователь может (если пожелает) получить прямой доступ к внутренним параметрам активации сети.
| В начало |
Многослойный персептрон (MLP)
Многослойный персептрон (MLP)
Вероятно, эта архитектура сети используется сейчас наиболее часто. Она была предложена в работе Rumelhart, McClelland (1986) и подробно обсуждается почти во всех учебниках по нейронным сетям (см., например, Bishop, 1995). Вкратце этот тип сети был описан выше. Каждый элемент сети строит взвешенную сумму своих входов с поправкой в виде слагаемого и затем пропускает эту величину активации через передаточную функцию, и таким образом получается выходное значение этого элемента. Элементы организованы в послойную топологию с прямой передачей сигнала. Такую сеть легко можно интерпретировать как модель вход-выход, в которой веса и пороговые значения (смещения) являются свободными параметрами модели. Такая сеть может моделировать функцию практически любой степени сложности, причем число слоев и число элементов в каждом слое определяют сложность функции. Определение числа промежуточных слоев и числа элементов в них является важным вопросом при конструировании MLP (Haykin, 1994; Bishop, 1995). Количество входных и выходных элементов определяется условиями задачи. Сомнения могут возникнуть в отношении того, какие входные значения использовать, а какие нет, - к этому вопросу мы вернемся позже. Сейчас будем предполагать, что входные переменные выбраны интуитивно и что все они являются значимыми.
Вопрос же о том, сколько использовать промежуточных слоев и элементов в них, пока совершенно неясен. В качестве начального приближения можно взять один промежуточный слой, а число элементов в нем положить равным полусумме числа входных и выходных элементов. Опять-таки, позже мы обсудим этот вопрос подробнее.
Обучение многослойного персептрона
Обучение многослойного персептрона
После того, как определено число слоев и число элементов в каждом из них, нужно найти значения для весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. С использованием собранных исторических данных веса и пороговые значения автоматически корректируются с целью минимизировать эту ошибку. По сути этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибка для конкретной конфигурации сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Все такие разности суммируются в так называемую функцию ошибок, значение которой и есть ошибка сети. В качестве функции ошибок чаще всего берется сумма квадратов ошибок, т.е. когда все ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются. При работе с пакетом ST Neural Networks пользователю выдается так называемая среднеквадратичная ошибка (RMS) - описанная выше величина нормируется на число наблюдений и переменных, после чего из нее извлекается квадратный корень - это очень хорошая мера ошибки, усредненная по всему обучающему множеству и по всем выходным элементам.
В традиционном моделировании (например, линейном моделировании) можно алгоритмически определить конфигурацию модели, дающую абсолютный минимум для указанной ошибки. Цена, которую приходится платить за более широкие (нелинейные) возможности моделирования с помощью нейронных сетей, состоит в том, что, корректируя сеть с целью минимизировать ошибку, мы никогда не можем быть уверены, что нельзя добиться еще меньшей ошибки.
В этих рассмотрениях оказывается очень полезным понятие поверхности ошибок. Каждому из весов и порогов сети (т.е. свободных параметров модели; их общее число обозначим через N) соответствует одно измерение в многомерном пространстве. N+1-е измерение соответствует ошибке сети. Для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N+1-мерном пространстве, и все такие точки образуют там некоторую поверхность - поверхность ошибок. Цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку.
В случае линейной модели с суммой квадратов в качестве функции ошибок эта поверхность ошибок будет представлять собой параболоид (квадрику) - гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом. В такой ситуации локализовать этот минимум достаточно просто.
В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и обладает рядом неприятных свойств, в частности, может иметь локальные минимумы (точки, самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), плоские участки, седловые точки и длинные узкие овраги.
Аналитическими средствами невозможно определить положение глобального минимума на поверхности ошибок, поэтому обучение нейронной сети по сути дела заключается в исследовании поверхности ошибок. Отталкиваясь от случайной начальной конфигурации весов и порогов (т.е. случайно взятой точки на поверхности ошибок), алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) поверхности ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в нижней точке, которая может оказаться всего лишь локальным минимумом (а если повезет - глобальным минимумом).
Алгоритм обратного распространения
Алгоритм обратного распространения
Самый известный вариант алгоритма обучения нейронной сети - так называемый алгоритм обратного распространения (back propagation; см.
Patterson, 1996; Haykin, 1994; Fausett, 1994). Существуют современные алгоритмы второго порядка, такие как метод сопряженных градиентов и метод Левенберга-Маркара (Bishop, 1995; Shepherd, 1997) (оба они реализованы в пакете ST Neural Networks), которые на многих задачах работают существенно быстрее (иногда на порядок). Алгоритм обратного распространения наиболее прост для понимания, а в некоторых случаях он имеет определенные преимущества. Сейчас мы опишем его, а более продвинутые алгоритмы рассмотрим позже. Разработаны также эвристические модификации этого алгоритма, хорошо работающие для определенных классов задач, - быстрое распространение (Fahlman, 1988) и Дельта-дельта с чертой (Jacobs, 1988) - оба они также реализованы в пакете ST Neural Networks.
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Этот вектор указывает направление кратчайшего спуска по поверхности из данной точки, поэтому если мы "немного" продвинемся по нему, ошибка уменьшится. Последовательность таких шагов (замедляющаяся по мере приближения к дну) в конце концов приведет к минимуму того или иного типа. Определенную трудность здесь представляет вопрос о том, какую нужно брать длину шагов.
При большой длине шага сходимость будет более быстрой, но имеется опасность перепрыгнуть через решение или (если поверхность ошибок имеет особо вычурную форму) уйти в неправильном направлении. Классическим примером такого явления при обучении нейронной сети является ситуация, когда алгоритм очень медленно продвигается по узкому оврагу с крутыми склонами, прыгая с одной его стороны на другую. Напротив, при маленьком шаге, вероятно, будет схвачено верное направление, однако при этом потребуется очень много итераций. На практике величина шага берется пропорциональной крутизне склона (так что алгоритм замедляет ход вблизи минимума) с некоторой константой, которая называется скоростью обучения. Правильный выбор скорости обучения зависит от конкретной задачи и обычно осуществляется опытным путем; эта константа может также зависеть от времени, уменьшаясь по мере продвижения алгоритма.
Обычно этот алгоритм видоизменяется таким образом, чтобы включать слагаемое импульса (или инерции). Этот член способствует продвижению в фиксированном направлении, поэтому если было сделано несколько шагов в одном и том же направлении, то алгоритм "увеличивает скорость", что (иногда) позволяет избежать локального минимума, а также быстрее проходить плоские участки.
Таким образом, алгоритм действует итеративно, и его шаги принято называть эпохами. На каждой эпохе на вход сети поочередно подаются все обучающие наблюдения, выходные значения сети сравниваются с целевыми значениями и вычисляется ошибка. Значение ошибки, а также градиента поверхности ошибок используется для корректировки весов, после чего все действия повторяются. Начальная конфигурация сети выбирается случайным образом, и процесс обучения прекращается либо когда пройдено определенное количество эпох, либо когда ошибка достигнет некоторого определенного уровня малости, либо когда ошибка перестанет уменьшаться (пользователь может сам выбрать нужное условие остановки).
Переобучение и обобщение
Переобучение и обобщение
Одна из наиболее серьезных трудностей изложенного подхода заключается в том, что таким образом мы минимизируем не ту ошибку, которую на самом деле нужно минимизировать, - ошибку, которую можно ожидать от сети, когда ей будут подаваться совершенно новые наблюдения. Иначе говоря, мы хотели бы, чтобы нейронная сеть обладала способностью обобщать результат на новые наблюдения. В действительности сеть обучается минимизировать ошибку на обучающем множестве, и в отсутствие идеального и бесконечно большого обучающего множества это совсем не то же самое, что минимизировать "настоящую" ошибку на поверхности ошибок в заранее неизвестной модели явления (Bishop, 1995).
Сильнее всего это различие проявляется в проблеме переобучения, или слишком близкой подгонки. Это явление проще будет продемонстрировать не для нейронной сети, а на примере аппроксимации посредством полиномов, - при этом суть явления абсолютно та же.
Полином (или многочлен) - это выражение, содержащее только константы и целые степени независимой переменной. Вот примеры:
y=2x+3
y=3x2+4x+1
Графики полиномов могут иметь различную форму, причем чем выше степень многочлена (и, тем самым, чем больше членов в него входит), тем более сложной может быть эта форма. Если у нас есть некоторые данные, мы можем поставить цель подогнать к ним полиномиальную кривую (модель) и получить таким образом объяснение для имеющейся зависимости. Наши данные могут быть зашумлены, поэтому нельзя считать, что самая лучшая модель задается кривой, которая в точности проходит через все имеющиеся точки. Полином низкого порядка может быть недостаточно гибким средством для аппроксимации данных, в то время как полином высокого порядка может оказаться чересчур гибким, и будет точно следовать данным, принимая при этом замысловатую форму, не имеющую никакого отношения к форме настоящей зависимости (см. Рисунок ).
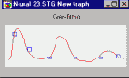
Нейронная сеть сталкивается с точно такой же трудностью. Сети с большим числом весов моделируют более сложные функции и, следовательно, склонны к переобучению. Сеть же с небольшим числом весов может оказаться недостаточно гибкой, чтобы смоделировать имеющуюся зависимость. Например, сеть без промежуточных слоев на самом деле моделирует обычную линейную функцию.
Как же выбрать "правильную" степень сложности для сети? Почти всегда более сложная сеть дает меньшую ошибку, но это может свидетельствовать не о хорошем качестве модели, а о переобучении.
Ответ состоит в том, чтобы использовать механизм контрольной кросс-проверки. Мы резервируем часть обучающих наблюдений и не используем их в обучении по алгоритму обратного распространения. Вместо этого, по мере работы алгоритма, они используются для независимого контроля результата. В самом начале работы ошибка сети на обучающем и контрольном множестве будет одинаковой (если они существенно отличаются, то, вероятно, разбиение всех наблюдений на два множества было неоднородно). По мере того, как сеть обучается, ошибка обучения, естественно, убывает, и, пока обучение уменьшает действительную функцию ошибок, ошибка на контрольном множестве также будет убывать.
Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные и обучение следует остановить (в пакете ST Neural Networks можно задать автоматическую остановку обучения при появлении эффекта переобучения). Это явление чересчур точной аппроксимации в процессе обучения и называется переобучением. Если такое случилось, то обычно советуют уменьшить число скрытых элементов и/или слоев, ибо сеть является слишком мощной для данной задачи. Если же сеть, наоборот, была взята недостаточно богатой для того, чтобы моделировать имеющуюся зависимость, то переобучения, скорее всего, не произойдет, и обе ошибки - обучения и проверки - не достигнут достаточного уровня малости.
Описанные проблемы с локальными минимумами и выбором размера сети приводят к тому, что при практической работе с нейронными сетями, как правило, приходится экспериментировать с большим числом различных сетей, порой обучая каждую из них по нескольку раз (чтобы не быть введенным в заблуждение локальными минимумами) и сравнивая полученные результаты. Главным показателем качества результата является здесь контрольная ошибка. При этом, в соответствии с общенаучным принципом, согласно которому при прочих равных следует предпочесть более простую модель, из двух сетей с приблизительно равными ошибками контроля имеет смысл выбрать ту, которая меньше.
Необходимость многократных экспериментов ведет к тому, что контрольное множество начинает играть ключевую роль в выборе модели, то есть становится частью процесса обучения. Тем самым ослабляется его роль как независимого критерия качества модели - при большом числе экспериментов есть риск выбрать "удачную" сеть, дающую хороший результат на контрольном множестве. Для того, чтобы придать окончательной модели должную надежность, часто (по крайней мере, когда объем обучающих данных это позволяет) поступают так: резервируют еще одно - тестовое множество наблюдений. Итоговая модель тестируется на данных из этого множества, чтобы убедиться, что результаты, достигнутые на обучающем и контрольном множествах реальны, а не являются артефактами процесса обучения.
Разумеется, для того чтобы хорошо играть свою роль, тестовое множество должно быть использовано только один раз: если его использовать повторно для корректировки процесса обучения, то оно фактически превратится в контрольное множество.
Итак, построение сети (после выбора входных переменных) состоит из следующих шагов:
- Выбрать начальную конфигурацию сети (например, один промежуточный слой с числом элементов в нем, равным полусумме числа входов и числа выходов - Наставник (Network Advisor) пакета ST Neural Networks предложит Вам такую конфигурацию по умолчанию).
- Провести ряд экспериментов с различными конфигурациями, запоминая при этом лучшую сеть (в смысле контрольной ошибки). В пакете ST Neural Networks предусмотрено автоматическое запоминание лучшей сети во время эксперимента. Для каждой конфигурации следует провести несколько экспериментов, чтобы не получить ошибочный результат из-за того, что процесс обучения попал в локальный минимум.
- Если в очередном эксперименте наблюдается недообучение (сеть не выдает результат приемлемого качества), попробовать добавить дополнительные нейроны в промежуточный слой (слои). Если это не помогает, попробовать добавить новый промежуточный слой.
- Если имеет место переобучение (контрольная ошибка стала расти), попробовать удалить несколько скрытых элементов (а возможно и слоев).
Отбор данных
Отбор данных
На всех предыдущих этапах существенно использовалось одно предположение. А именно, обучающее, контрольное и тестовое множества должны быть репрезентативными (представительными) с точки зрения существа задачи (более того, эти множества должны быть репрезентативными каждое в отдельности). Известное изречение программистов "garbage in, garbage out" ("мусор на входе - мусор на выходе") нигде не справедливо в такой степени, как при нейросетевом моделировании. Если обучающие данные не репрезентативны, то модель, как минимум, будет не очень хорошей, а в худшем случае - бесполезной. Имеет смысл перечислить ряд причин, которые ухудшают качество обучающего множества:
Будущее непохоже на прошлое. Обычно в качестве обучающих берутся исторические данные. Если обстоятельства изменились, то закономерности, имевшие место в прошлом, могут больше не действовать.
Следует учесть все возможности.
Следует учесть все возможности.
Нейронная сеть может обучаться только на тех данных, которыми она располагает. Предположим, что лица с годовым доходом более $100,000 имеют высокий кредитный риск, а обучающее множество не содержало лиц с доходом более $40,000 в год. Тогда едва ли можно ожидать от сети правильного решения в совершенно новой для нее ситуации.
Сеть обучается тому, чему проще всего обучиться. Классическим (возможно, вымышленным) примером является система машинного зрения, предназначенная для автоматического распознавания танков. Сеть обучалась на ста картинках, содержащих изображения танков, и на ста других картинках, где танков не было. Был достигнут стопроцентно "правильный" результат. Но когда на вход сети были поданы новые данные, она безнадежно провалилась. В чем же была причина? Выяснилось, что фотографии с танками были сделаны в пасмурный, дождливый день, а фотографии без танков - в солнечный день. Сеть научилась улавливать (очевидную) разницу в общей освещенности. Чтобы сеть могла результативно работать, ее следовало обучать на данных, где бы присутствовали все погодные условия и типы освещения, при которых сеть предполагается использовать - и это еще не говоря о рельефе местности, угле и дистанции съемки и т.д.
Несбалансированный набор данных.
Несбалансированный набор данных.
Коль скоро сеть минимизирует общую погрешность, важное значение приобретает пропорции, в которых представлены данные различных типов. Сеть, обученная на 900 хороших и 100 плохих примерах будет искажать результат в пользу хороших наблюдений, поскольку это позволит алгоритму уменьшить общую погрешность (которая определяется в основном хорошими случаями). Если в реальной популяции хорошие и плохие объекты представлены в другой пропорции, то результаты, выдаваемые сетью, могут оказаться неверными. Хорошим примером служит задача выявления заболеваний. Пусть, например, при обычных обследованиях в среднем 90% людей оказываются здоровыми. Сеть обучается на имеющихся данных, в которых пропорция здоровые/больные равна 90/10. Затем она применяется для диагностики пациентов с определенным жалобами, среди которых это соотношение уже 50/50. В этом случае сеть будет ставить диагноз чересчур осторожно и не распознает заболевание у некоторых больных. Если же, наоборот, сеть обучить на данных "с жалобами", а затем протестировать на "обычных" данных, то она будет выдавать повышенное число неправильных диагнозов о наличии заболевания. В таких ситуациях обучающие данные нужно скорректировать так, чтобы были учтены различия в распределении данных (например, можно повторять редкие наблюдения или удалить часто встречающиеся), или же видоизменить решения, выдаваемые сетью, посредством матрицы потерь (Bishop, 1995). Как правило, лучше всего постараться сделать так, чтобы наблюдения различных типов были представлены равномерно, и соответственно этому интерпретировать результаты, которые выдает сеть.
Как обучается многослойный персептрон
Как обучается многослойный персептрон
Мы сможем лучше понять, как устроен и как обучается многослойный персептрон (MLP), если выясним, какие функции он способен моделировать. Вспомним, что уровнем активации элемента называется взвешенная сумма его входов с добавленным к ней пороговым значением.
Таким образом, уровень активации представляет собой простую линейную функцию входов. Эта активация затем преобразуется с помощью сигмоидной ( имеющей S-образную форму) кривой.
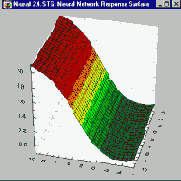
Комбинация линейной функции нескольких переменных и скалярной сигмоидной функции приводит к характерному профилю "сигмоидного склона", который выдает элемент первого промежуточного слоя MLP (На приведенном здесь рисунке соответствующая поверхность изображена в виде функции двух входных переменных. Элемент с большим числом входов выдает многомерный аналог такой поверхности). При изменении весов и порогов меняется и поверхность отклика. При этом может меняться как ориентация всей поверхности, так и крутизна склона. Большим значениям весов соответствует более крутой склон. Так например, если увеличить все веса в два раза, то ориентация не изменится, а наклон будет более крутым.
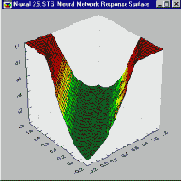
В многослойной сети подобные функции отклика комбинируются друг с другом с помощью последовательного взятия их линейных комбинаций и применения нелинейных функций активации. На этом рисунке изображена типичная поверхность отклика для сети с одним промежуточным слоем, состоящим из двух элементов, и одним выходным элементом, для классической задачи "исключающего или" (Xor). Две разных сигмоидных поверхности объединены в одну поверхность, имеющую форму буквы "U".
Перед началом обучения сети весам и порогам случайным образом присваиваются небольшие по величине начальные значения. Тем самым отклики отдельных элементов сети имеют малый наклон и ориентированы хаотично - фактически они не связаны друг с другом. По мере того, как происходит обучение, поверхности отклика элементов сети вращаются и сдвигаются в нужное положение, а значения весов увеличиваются, поскольку они должны моделировать отдельные участки целевой поверхности отклика.
В задачах классификации выходной элемент должен выдавать сильный сигнал в случае, если данное наблюдение принадлежит к интересующему нас классу, и слабый - в противоположном случае.
Иначе говоря, этот элемент должен стремиться смоделировать функцию, равную единице в той области пространства объектов, где располагаются объекты из нужного класса, и равную нулю вне этой области. Такая конструкция известна как дискриминантная функция в задачах распознавания. "Идеальная" дискриминантная функция должна иметь плоскую структуру, так чтобы точки соответствующей поверхности располагались либо на нулевом уровне, либо на высоте единица.
Если сеть не содержит скрытых элементов, то на выходе она может моделировать только одинарный "сигмоидный склон": точки, находящиеся по одну его сторону, располагаются низко, по другую - высоко. При этом всегда будет существовать область между ними (на склоне), где высота принимает промежуточные значения, но по мере увеличения весов эта область будет сужаться.
Такой сигмоидный склон фактически работает как линейная дискриминантная функция. Точки, лежащие по одну сторону склона, классифицируются как принадлежащие нужному классу, а лежащие по другую сторону - как не принадлежащие. Следовательно, сеть без скрытых слоев может служить классификатором только в линейно-отделимых задачах (когда можно провести линию - или, в случае более высоких размерностей, - гиперплоскость, разделяющую точки в пространстве признаков).
Сеть, содержащая один промежуточный слой, строит несколько сигмоидных склонов - по одному для каждого скрытого элемента, - и затем выходной элемент комбинирует из них "возвышенность". Эта возвышенность получается выпуклой, т.е. не содержащей впадин. При этом в некоторых направлениях она может уходить на бесконечность (как длинный полуостров). Такая сеть может моделировать большинство реальных задач классификации.
На этом рисунке показана поверхность отклика, полученная многослойным персептроном для решения задачи исключающего или: хорошо видно, что она выделяет область пространства, расположенную вдоль диагонали.
Сеть с двумя промежуточными слоями строит комбинацию из нескольких таких возвышенностей.
Их будет столько же, сколько элементов во втором слое, и у каждой из них будет столько сторон, сколько элементов было в первом скрытом слое. После небольшого размышления можно прийти к выводу, что, используя достаточное число таких возвышенностей, можно воспроизвести поверхность любой формы - в том числе с впадинами и вогнутостями.
Как следствие наших рассмотрений мы получаем, что, теоретически, для моделирования любой задачи достаточно многослойного персептрона с двумя промежуточными слоями (в точной формулировке этот результат известен как теорема Колмогорова). При этом может оказаться и так, что для решения некоторой конкретной задачи более простой и удобной будет сеть с еще большим числом слоев. Однако, для решения большинства практических задач достаточно всего одного промежуточного слоя, два слоя применяются как резерв в особых случаях, а сети с тремя слоями практически не применяются.
В задачах классификации очень важно понять, как следует интерпретировать те точки, которые попали на склон или лежат близко от него. Стандартный выход здесь состоит в том, чтобы для пороговых значений установить некоторые доверительные пределы (принятия или отвержения), которые должны быть достигнуты, чтобы данных элемент считался "принявшим решение". Например, если установлены пороги принятия/отвержения 0.95/0.05, то при уровне выходного сигнала, превосходящем 0.95 элемент считается активным, при уровне ниже 0.05 - неактивным, а в промежутке - "неопределенным".
Имеется и более тонкий (и, вероятно, более полезный) способ интерпретировать уровни выходного сигнала: считать их вероятностями. В этом случае сеть выдает несколько большую информацию, чем просто "да/нет": она сообщает нам, насколько (в некотором формальном смысле) мы можем доверять ее решению. Разработаны (и реализованы в пакете ST Neural Networks) модификации метода MLP, позволяющие интерпретировать выходной сигнал нейронной сети как вероятность, в результате чего сеть по существу учится моделировать плотность вероятности распределения данного класса.
При этом, однако, вероятностная интерпретация обоснована только в том случае, если выполнены определенные предположения относительно распределения исходных данных (конкретно, что они являются выборкой из некоторого распределения, принадлежащего к семейству экспоненциальных распределений; Bishop, 1995). Здесь, как и ранее, может быть принято решение по классификации, но, кроме того, вероятностная интерпретация позволяет ввести концепцию "решения с минимальными затратами".
Другие алгоритмы обучения MLP
Другие алгоритмы обучения MLP
Выше было описано, как с помощью алгоритма обратного распространения осуществляется градиентный спуск по поверхности ошибок. Вкратце дело происходит так: в данной точке поверхности находится направление скорейшего спуска, затем делается прыжок вниз на расстояние, пропорциональное коэффициенту скорости обучения и крутизне склона, при этом учитывается инерция, те есть стремление сохранить прежнее направление движения. Можно сказать, что метод ведет себя как слепой кенгуру - каждый раз прыгает в направлении, которое кажется ему наилучшим. На самом деле шаг спуска вычисляется отдельно для всех обучающих наблюдений, взятых в случайном порядке, но в результате получается достаточно хорошая аппроксимация спуска по совокупной поверхности ошибок. Существуют и другие алгоритмы обучения MLP, однако все они используют ту или иную стратегию скорейшего продвижения к точке минимума.
В некоторых задачах бывает целесообразно использовать такие - более сложные - методы нелинейной оптимизации. В пакете ST Neural Networks реализованы два подобных метода: методы спуска по сопряженным градиентам и Левенберга -Маркара (Bishop, 1995; Shepherd, 1997), представляющие собой очень удачные варианты реализации двух типов алгоритмов: линейного поиска и доверительных областей.
Алгоритм линейного поиска действует следующим образом: выбирается какое-либо разумное направление движения по многомерной поверхности. В этом направлении проводится линия, и на ней ищется точка минимума (это делается относительно просто с помощью того или иного варианта метода деления отрезка пополам); затем все повторяется сначала.
Что в данном случае следует считать "разумным направлением"? Очевидным ответом является направление скорейшего спуска (именно так действует алгоритм обратного распространения). На самом деле этот вроде бы очевидный выбор не слишком удачен. После того, как был найден минимум по некоторой прямой, следующая линия, выбранная для кратчайшего спуска, может "испортить" результаты минимизации по предыдущему направлению (даже на такой простой поверхности, как параболоид, может потребоваться очень большое число шагов линейного поиска). Более разумно было бы выбирать "не мешающие друг другу " направления спуска - так мы приходим к методу сопряженных градиентов (Bishop, 1995).
Идея метода состоит в следующем: поскольку мы нашли точку минимума вдоль некоторой прямой, производная по этому направлению равна нулю. Сопряженное направление выбирается таким образом, чтобы эта производная и дальше оставалась нулевой - в предположении, что поверхность имеет форму параболоида (или, грубо говоря, является "хорошей и гладкой "). Если это условие выполнено, то для достижения точки минимума достаточно будет N эпох. На реальных, сложно устроенных поверхностях по мере хода алгоритма условие сопряженности портится, и тем не менее такой алгоритм, как правило, требует гораздо меньшего числа шагов, чем метод обратного распространения, и дает лучшую точку минимума (для того, чтобы алгоритм обратного распространения точно установился в некоторой точке, нужно выбирать очень маленькую скорость обучения).
Метод доверительных областей основан на следующей идее: вместо того, чтобы двигаться в определенном направлении поиска, предположим, что поверхность имеет достаточно простую форму, так что точку минимума можно найти (и прыгнуть туда) непосредственно. Попробуем смоделировать это и посмотреть, насколько хорошей окажется полученная точка. Вид модели предполагает, что поверхность имеет хорошую и гладкую форму (например, является параболоидом), - такое предположение выполнено вблизи точек минимума.
Вдали от них данное предположение может сильно нарушаться, так что модель будет выбирать для очередного продвижения совершенно не те точки. Правильно работать такая модель будет только в некоторой окрестности данной точки, причем размеры этой окрестности заранее неизвестны. Поэтому выберем в качестве следующей точки для продвижения нечто промежуточное между точкой, которую предлагает наша модель, и точкой, которая получилась бы по обычному методу градиентного спуска. Если эта новая точка оказалась хорошей, передвинемся в нее и усилим роль нашей модели в выборе очередных точек; если же точка оказалась плохой, не будем в нее перемещаться и увеличим роль метода градиентного спуска при выборе очередной точки (а также уменьшим шаг). В основанном на этой идее методе Левенберга-Маркара предполагается, что исходное отображение является локально линейным (и тогда поверхность ошибок будет параболоидом).
Метод Левенберга-Маркара (Levenberg, 1944; Marquardt, 1963; Bishop, 1995) - самый быстрый алгоритм обучения из всех, которые реализованы в пакете ST Neural Networks, но, к сожалению, на его использование имеется ряд важных ограничений. Он применим только для сетей с одним выходным элементом, работает только с функцией ошибок сумма квадратов и требует памяти порядка W**2 (где W - количество весов у сети; поэтому для больших сетей он плохо применим). Метод сопряженных градиентов почти так же эффективен, как и этот метод, и не связан подобными ограничениями.
При всем сказанном метод обратного распространения также сохраняет свое значение, причем не только для тех случаев, когда требуется быстро найти решение (и не требуется особой точности). Его следует предпочесть, когда объем данных очень велик, и среди данных есть избыточные. Благодаря тому, что в методе обратного распространения корректировка ошибки происходит по отдельным случаям, избыточность данных не вредит (если, например, приписать к имеющемуся набору данных еще один точно такой же набор, так что каждый случай будет повторяться дважды, то эпоха будет занимать вдвое больше времени, чем раньше, однако результат ее будет точно таким же, как от двух старых, так что ничего плохого не произойдет).
Методы же Левенберга-Маркара и сопряженных градиентов проводят вычисления на всем наборе данных, поэтому при увеличении числа наблюдений продолжительность одной эпохи сильно растет, но при этом совсем не обязательно улучшается результат, достигнутый на этой эпохе (в частности, если данные избыточны; если же данные редкие, то добавление новых данных улучшит обучение на каждой эпохе). Кроме того, обратное распространение не уступает другим методам в ситуациях, когда данных мало, поскольку в этом случае недостаточно данных для принятия очень точного решения (более тонкий алгоритм может дать меньшую ошибку обучения, но контрольная ошибка у него, скорее всего, не будет меньше).
Кроме уже перечисленных, в пакете ST Neural Networks имеются две модификации метода обратного распространения - метод быстрого распространения (Fahlman, 1988) и дельта-дельта с чертой (Jacobs, 1988), - разработанные с целью преодолеть некоторые ограничения этого подхода. В большинстве случаев они работают не лучше, чем обратное распространение, а иногда и хуже (это зависит от задачи). Кроме того, в этих методах используется больше управляющих параметров, чем в других методах, и поэтому ими сложнее пользоваться. Мы не будем описывать это методы подробно в данной главе.
| В начало |
Радиальная базисная функция
Радиальная базисная функция
В предыдущем разделе было описано, как многослойный персептрон моделирует функцию отклика с помощью функций "сигмоидных склонов " - в задачах классификации это соответствует разбиению пространства входных данных посредством гиперплоскостей. Метод разбиения пространства гиперплоскостями представляется естественным и интуитивно понятным, ибо он использует фундаментальное простое понятие прямой линии. Столь же естественным является подход, основанный на разбиении пространства окружностями или (в общем случае) гиперсферами. Гиперсфера задается своим центром и радиусом. Подобно тому, как элемент MLP реагирует (нелинейно) на расстояние от данной точки до линии "сигмоидного склона", в сети, построенной на радиальных базисных функциях (Broomhead and Lowe, 1988; Moody and Darkin, 1989; Haykin, 1994), элемент реагирует (нелинейно) на расстояние от данной точки до "центра", соответствующего этому радиальному элементу.
Поверхность отклика радиального элемента представляет собой гауссову функцию (колоколообразной формы), с вершиной в центре и понижением к краям. Наклон гауссова радиального элемента можно менять подобно тому, как можно менять наклон сигмоидной кривой в MLP (см. Рисунок ).
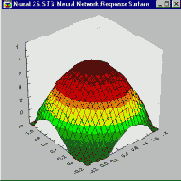
Элемент многослойного персептрона полностью задается значениями своих весов и порогов, которые в совокупности определяют уравнение разделяющей прямой и скорость изменения функции при отходе от этой линии. До действия сигмоидной функции активации уровень активации такого элемента определяется гиперплоскостью, поэтому в системе ST Neural Networks такие элементы называется линейными (хотя функция активации, как правило, нелинейна). В отличие от них, радиальный элемент задается своим центром и "радиусом". Положение точки в N-мерном пространстве определяется N числовыми параметрами, т.е. их ровно столько же, сколько весов у линейного элемента, и поэтому координаты центра радиального элемента в пакете ST Neural Networks хранятся как "веса". Его радиус (отклонение) хранится как "порог". Следует отчетливо понимать, что "веса" и "пороги" радиального элемента принципиально отличаются от весов и порогов линейного элемента, и если забыть об этом, термин может ввести Вас в заблуждение. Радиальные веса на самом деле представляют точку, а радиальный порог - отклонение.
Сеть типа радиальной базисной функции (RBF) имеет промежуточный слой из радиальных элементов, каждый из которых воспроизводит гауссову поверхность отклика. Поскольку эти функции нелинейны, для моделирования произвольной функции нет необходимости брать более одного промежуточного слоя. Для моделирования любой функции необходимо лишь взять достаточное число радиальных элементов. Остается решить вопрос о том, как следует скомбинировать выходы скрытых радиальных элементов, чтобы получить из них выход сети. Оказывается, что достаточно взять их линейную комбинацию (т.е. взвешенную сумму гауссовых функций).
Сеть RBF имеет выходной слой, состоящий из элементов с линейными функциями активации (Haykin, 1994; Bishop, 1995).
Сети RBF имеют ряд преимуществ перед сетями MLP. Во-первых, как уже сказано, они моделируют произвольную нелинейную функцию с помощью всего одного промежуточного слоя, и тем самым избавляют нас от необходимости решать вопрос о числе слоев. Во-вторых, параметры линейной комбинации в выходном слое можно полностью оптимизировать с помощью хорошо известных методов линейного моделирования, которые работают быстро и не испытывают трудностей с локальными минимумами, так мешающими при обучении MLP. Поэтому сеть RBF обучается очень быстро (на порядок быстрее MLP).
С другой стороны, до того, как применять линейную оптимизацию в выходном слое сети RBF, необходимо определить число радиальных элементов, положение их центров и величины отклонений. Соответствующие алгоритмы, хотя и работают быстрее алгоритмов обучения MLP, в меньшей степени пригодны для отыскания субоптимальных решений. В качестве компенсации, Автоматический конструктор сети пакета ST Neural Networks сможет выполнить за Вас все необходимые действия по экспериментированию с сетью.
Другие отличия работы RBF от MLP связаны с различным представлением пространства модели: "групповым" в RBF и "плоскостным" в MLP.
Опыт показывает, что для правильного моделирования типичной функции сеть RBF, с ее более эксцентричной поверхностью отклика, требует несколько большего числа элементов. Конечно, можно специально придумать форму поверхности, которая будет хорошо представляться первым или, наоборот, вторым способом, но общий итог оказывается не в пользу RBF. Следовательно, модель, основанная на RBF, будет работать медленнее и потребует больше памяти, чем соответствующий MLP (однако она гораздо быстрее обучается, а в некоторых случаях это важнее).
С "групповым" подходом связано и неумение сетей RBF экстраполировать свои выводы за область известных данных. При удалении от обучающего множества значение функции отклика быстро спадает до нуля.
Напротив, сеть MLP выдает более определенные решения при обработке сильно отклоняющихся данных. Достоинство это или недостаток - зависит от конкретной задачи, однако в целом склонность MLP к некритическому экстраполированию результата считается его слабостью. Экстраполяция на данные, лежащие далеко от обучающего множества, - вещь, как правило, опасная и необоснованная.
Сети RBF более чувствительны к "проклятию размерности" и испытывают значительные трудности, когда число входов велико. Мы обсудим этот вопрос ниже.
Как уже говорилось, обучение RBF-сети происходит в несколько этапов. Сначала определяются центры и отклонения для радиальных элементов; после этого оптимизируются параметры линейного выходного слоя.
Расположение центров должно соответствовать кластерам, реально присутствующим в исходных данных. Рассмотрим два наиболее часто используемых метода.
Расположение центров должно соответствовать кластерам, реально присутствующим в исходных данных. Рассмотрим два наиболее часто изпользуемых метода.
Выборка из выборки. В качестве центров радиальных элементов берутся несколько случайно выбранных точек обучающего множества. В силу случайности выбора они "представляют" распределение обучающих данных в статистическом смысле. Однако, если число радиальных элементов невелико, такое представление может быть неудовлетворительным (Haykin, 1994).
Алгоритм K-средних.
Алгоритм K-средних.
Этот алгоритм (Bishop, 1995) стремится выбрать оптимальное множество точек, являющихся центроидами кластеров в обучающих данных. При K радиальных элементах их центры располагаются таким образом, чтобы:
- Каждая обучающая точка "относилась" к одному центру кластера и лежала к нему ближе, чем к любому другому центру;
- Каждый центр кластера был центроидом множества обучающих точек, относящихся к этому кластеру.
Если эти функции выбраны слишком острыми, сеть не будет интерполировать данные между известными точками и потеряет способность к обобщению. Если же гауссовы функции взяты чересчур широкими, сеть не будет воспринимать мелкие детали. На самом деле сказанное - еще одна форма проявления дилеммы пере/недообучения. Как правило, отклонения выбираются таким образом, чтобы колпак каждой гауссовой функций захватывал "несколько" соседних центров. Для этого имеется несколько методов:
Явный. Отклонения задаются пользователем.
Изотропный. Отклонение берется одинаковым для всех элементов и определяется эвристически с учетом количества радиальных элементов и объема покрываемого пространства (Haykin, 1994).
K ближайших соседей. Отклонение каждого элемента устанавливается (индивидуально) равным среднему расстоянию до его K ближайших соседей (Bishop, 1995). Тем самым отклонения будут меньше в тех частях пространства, где точки расположены густо, - здесь будут хорошо учитываться детали, - а там, где точек мало, отклонения будут большими (и будет производится интерполяция).
После того, как выбраны центры и отклонения, параметры выходного слоя оптимизируются с помощью стандартного метода линейной оптимизации - алгоритма псевдообратных матриц (сингулярного разложения) (Haykin, 1994; Golub and Kahan, 1965).
Могут быть построены различные гибридные разновидности радиальных базисных функций. Например, выходной слой может иметь нелинейные функции активации, и тогда для его обучения используется какой-либо из алгоритмов обучения многослойных персептронов, например метод обратного распространения. Можно также обучать радиальный (скрытый) слой с помощью алгоритма обучения сети Кохонена - это еще один способ разместить центры так, чтобы они отражали расположение данных.
| В начало |
Вероятностная нейронная сеть
Вероятностная нейронная сеть
В предыдущем разделе, говоря о задачах классификации, мы кратко упомянули о том, что выходы сети можно с пользой интерпретировать как оценки вероятности того, что элемент принадлежит некоторому классу, и сеть фактически учится оценивать функцию плотности вероятности.
Аналогичная полезная интерпретация может иметь место и в задачах регрессии - выход сети рассматривается как ожидаемое значение модели в данной точке пространства входов. Это ожидаемое значение связано с плотностью вероятности совместного распределения входных и выходных данных. Задача оценки плотности вероятности (p.d.f.) по данным имеет давнюю историю в математической статистике (Parzen, 1962) и относится к области байесовой статистики. Обычная статистика по заданной модели говорит нам, какова будет вероятность того или иного исхода (например, что на игральной кости шесть очков будет выпадать в среднем одном случае из шести). Байесова статистика переворачивает вопрос вверх ногами: правильность модели оценивается по имеющимся достоверным данным. В более общем плане, байесова статистика дает возможность оценивать плотность вероятности распределений параметров модели по имеющимся данных. Для того, чтобы минимизировать ошибку, выбирается модель с такими параметрами, при которых плотность вероятности будет наибольшей.
При решении задачи классификации можно оценить плотность вероятности для каждого класса, сравнить между собой вероятности принадлежности различным классам и выбрать наиболее вероятный. На самом деле именно это происходит, когда мы обучаем нейронную сеть решать задачу классификации - сеть пытается определить (т.е. аппроксимировать) плотность вероятности.
Традиционный подход к задаче состоит в том, чтобы построить оценку для плотности вероятности по имеющимся данным. Обычно при этом предполагается, что плотность имеет некоторый определенный вид (чаще всего - что она имеет нормальное распределение). После этого оцениваются параметры модели. Нормальное распределение часто используется потому, что тогда параметры модели (среднее и стандартное отклонение) можно оценить аналитически. При этом остается вопрос о том, что предположение о нормальности не всегда оправдано.
Другой подход к оценке плотности вероятности основан на ядерных оценках (Parzen, 1962; Speckt, 1990; Speckt, 1991; Bishop, 1995; Patterson, 1996).
Можно рассуждать так: тот факт, что наблюдение расположено в данной точке пространства, свидетельствует о том, что в этой точке имеется некоторая плотность вероятности. Кластеры из близко лежащих точек указывают на то, что в этом месте плотность вероятности большая. Вблизи наблюдения имеется большее доверие к уровню плотности, а по мере отдаления от него доверие убывает и стремится к нулю. В методе ядерных оценок в точке, соответствующей каждому наблюдению, помещается некоторая простая функция, затем все они складываются и в результате получается оценка для общей плотности вероятности. Чаще всего в качестве ядерных функций берутся гауссовы функции (с формой колокола). Если обучающих примеров достаточное количество, то такой метод дает достаточно хорошее приближение к истинной плотности вероятности.
Метод аппроксимации плотности вероятности с помощью ядерных функций во многом похож на метод радиальных базисных функций, и таким образом мы естественно приходим к понятиям вероятностной нейронной сети (PNN) и обобщенно-регрессионной нейронной сети (GRNN) (Speckt 1990, 1991). PNN-сети предназначены для задач классификации, а GRNN - для задач регрессии. Сети этих двух типов представляют собой реализацию методов ядерной аппроксимации, оформленных в виде нейронной сети.
Сеть PNN имеет по меньшей мере три слоя: входной, радиальный и выходной. Радиальные элементы берутся по одному на каждое обучающее наблюдение. Каждый из них представляет гауссову функцию с центром в этом наблюдении. Каждому классу соответствует один выходной элемент. Каждый такой элемент соединен со всеми радиальными элементами, относящимися к его классу, а со всеми остальными радиальными элементами он имеет нулевое соединение. Таким образом, выходной элемент просто складывает отклики всех элементов, принадлежащих к его классу. Значения выходных сигналов получаются пропорциональными ядерным оценкам вероятности принадлежности соответствующим классам, и пронормировав их на единицу, мы получаем окончательные оценки вероятности принадлежности классам.
Базовая модель PNN-сети может иметь две модификации.
В первом случае мы предполагаем, что пропорции классов в обучающем множестве соответствуют их пропорциям во всей исследуемой популяции (или так называемым априорным вероятностям). Например, если среди всех людей больными являются 2%, то в обучающем множестве для сети, диагностирующей заболевание, больных должно быть тоже 2%. Если же априорные вероятности будут отличаться от пропорций в обучающей выборке, то сеть будет выдавать неправильный результат. Это можно впоследствии учесть (если стали известны априорные вероятности), вводя поправочные коэффициенты для различных классов.
Второй вариант модификации основан на следующей идее. Любая оценка, выдаваемая сетью, основывается на зашумленных данных и неизбежно будет приводить к отдельным ошибкам классификации (например, у некоторых больных результаты анализов могут быть вполне нормальными). Иногда бывает целесообразно считать, что некоторые виды ошибок обходятся "дороже" других (например, если здоровый человек будет диагностирован как больной, то это вызовет лишние затраты на его обследование, но не создаст угрозы для жизни; если же не будет выявлен действительный больной, то это может привести к смертельному исходу). В такой ситуации те вероятности, которые выдает сеть, следует домножить на коэффициенты потерь, отражающие относительную цену ошибок классификации. В пакете ST Neural Networks в вероятностную нейронную сеть может быть добавлен четвертый слой, содержащий матрицу потерь. Она умножается на вектор оценок, полученный в третьем слое, после чего в качестве ответа берется класс, имеющий наименьшую оценку потерь. (Матрицу потерь можно добавлять и к другим видам сетей, решающих задачи классификации.)
Вероятностная нейронная сеть имеет единственный управляющий параметр обучения, значение которого должно выбираться пользователем, - степень сглаживания (или отклонение гауссовой функции). Как и в случае RBF-сетей, этот параметр выбирается из тех соображений, чтобы шапки " определенное число раз перекрывались": выбор слишком маленьких отклонений приведет к "острым" аппроксимирующим функциям и неспособности сети к обобщению, а при слишком больших отклонениях будут теряться детали.
Требуемое значение несложно найти опытным путем, подбирая его так, чтобы контрольная ошибка была как можно меньше. К счастью, PNN-сети не очень чувствительны к выбору параметра сглаживания.
Наиболее важные преимущества PNN-сетей состоят в том, что выходное значение имеет вероятностный смысл (и поэтому его легче интерпретировать), и в том, что сеть быстро обучается. При обучения такой сети время тратится практически только на то, чтобы подавать ей на вход обучающие наблюдения, и сеть работает настолько быстро, насколько это вообще возможно.
Существенным недостатком таких сетей является их объем. PNN-сеть фактически вмещает в себя все обучающие данные, поэтому она требует много памяти и может медленно работать.
PNN-сети особенно полезны при пробных экспериментах (например, когда нужно решить, какие из входных переменных использовать), так как благодаря короткому времени обучения можно быстро проделать большое количество пробных тестов. В пакете ST Neural Networks PNN-сети используются также в Нейро-генетическом алгоритме отбора входных данных - Neuro-Genetic Input Selection, который автоматически находит значимые входы (будет описан ниже).
| В начало |
Обобщенно-регрессионная нейронная сеть
Обобщенно-регрессионная нейронная сеть
Обобщенно-регрессионная нейронная сеть (GRNN) устроена аналогично вероятностной нейронной сети (PNN), но она предназначена для решения задач регрессии, а не классификации (Speckt, 1991; Patterson, 1996; Bishop, 1995). Как и в случае PNN-сети, в точку расположения каждого обучающего наблюдения помещается гауссова ядерная функция. Мы считаем, что каждое наблюдение свидетельствует о некоторой нашей уверенности в том, что поверхность отклика в данной точке имеет определенную высоту, и эта уверенность убывает при отходе в сторону от точки. GRNN-сеть копирует внутрь себя все обучающие наблюдения и использует их для оценки отклика в произвольной точке. Окончательная выходная оценка сети получается как взвешенное среднее выходов по всем обучающим наблюдениям, где величины весов отражают расстояние от этих наблюдений до той точки, в которой производится оценивание (и, таким образом, более близкие точки вносят больший вклад в оценку). Первый промежуточный слой сети GRNN состоит из радиальных элементов.
Второй промежуточный слой содержит элементы, которые помогают оценить взвешенное среднее. Для этого используется специальная процедура. Каждый выход имеет в этом слое свой элемент, формирующий для него взвешенную сумму. Чтобы получить из взвешенной суммы взвешенное среднее, эту сумму нужно поделить на сумму весовых коэффициентов. Последнюю сумму вычисляет специальный элемент второго слоя. После этого в выходном слое производится собственно деление (с помощью специальных элементов "деления"). Таким образом, число элементов во втором промежуточном слое на единицу больше, чем в выходном слое. Как правило, в задачах регрессии требуется оценить одно выходное значение, и, соответственно, второй промежуточный слой содержит два элемента.
Можно модифицировать GRNN-сеть таким образом, чтобы радиальные элементы соответствовали не отдельным обучающим случаям, а их кластерам. Это уменьшает размеры сети и увеличивает скорость обучения. Центры для таких элементов можно выбирать с помощью любого предназначенного для этой цели алгоритма (выборки из выборки, K-средних или Кохонена), и программа ST Neural Networks соответствующим образом корректирует внутренние веса.
Достоинства и недостатки у сетей GRNN в основном такие же, как и у сетей PNN - единственное различие в том, что GRNN используются в задачах регрессии, а PNN - в задачах классификации. GRNN-сеть обучается почти мгновенно, но может получиться большой и медленной (хотя здесь, в отличие от PNN, не обязательно иметь по одному радиальному элементу на каждый обучающий пример, их число все равно будет большим). Как и сеть RBF, сеть GRNN не обладает способностью экстраполировать данные.
| В начало |
Линейная сеть
Линейная сеть
Согласно общепринятому в науке принципу, если более сложная модель не дает лучших результатов, чем более простая, то из них следует предпочесть вторую. В терминах аппроксимации отображений самой простой моделью будет линейная, в которой подгоночная функция определяется гиперплоскостью. В задаче классификации гиперплоскость размещается таким образом, чтобы она разделяла собой два класа (линейная дискриминантная функция); в задаче регрессии гиперплоскость должна проходить через заданные точки.
Линейная модель обычно записывается с помощью матрицы NxN и вектора смещения размера N. На языке нейронных сетей линейная модель представляется сетью без промежуточных слоев, которая в выходном слое содержит только линейные элементы (то есть элементы с линейной функцией активации). Веса соответствуют элементам матрицы, а пороги - компонентам вектора смещения. Во время работы сеть фактически умножает вектор входов на матрицу весов, а затем к полученному вектору прибавляет вектор смещения.
В пакете ST Neural Networks имеется возможность создать линейную сеть и обучить ее с помощью стандартного алгоритма линейной оптимизации, основанного на псевдообратных матрицах (SVD) (Golub and Kahan, 1965). Разумеется, метод линейной оптимизации реализован также в модуле Множественная регрессия системы STATISTICA; однако, линейные сети пакета ST Neural Networks имеют то преимущество, что здесь Вы можете в единой среде сравнивать такие сети с "настоящими" нейронными сетями.
Линейная сеть является хорошей точкой отсчета для оценки качества построенных Вами нейронных сетей. Может оказаться так, что задачу, считавшуюся очень сложной, можно успешно не только нейронной сетью, но и простым линейным методом. Если же в задаче не так много обучающих данных, то, вероятно, просто нет оснований использовать более сложные модели.
| В начало |
Сеть Кохонена
Сеть Кохонена
Сети Кохонена принципиально отличаются от всех других типов сетей, реализованных в пакете ST Neural Networks. В то время как все остальные сети предназначены для задач с управляемым обучением, сети Кохонена главным образом рассчитана на неуправляемое обучение (Kohonen, 1982; Haykin, 1994; Patterson, 1996; Fausett, 1994). При управляемом обучении наблюдения, составляющие обучающие данные, вместе с входными переменными содержат также и соответствующие им выходные значения, и сеть должна восстановить отображение, переводящее первые во вторые. В случае же неуправляемого обучения обучающие данные содержат только значения входных переменных.
На первый взгляд это может показаться странным. Как сеть сможет чему-то научиться, не имея выходных значений? Ответ заключается в том, что сеть Кохонена учится понимать саму структуру данных.
Одно из возможных применений таких сетей - разведочный анализ данных. Сеть Кохонена может распознавать кластеры в данных, а также устанавливать близость классов. Таким образом пользователь может улучшить свое понимание структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи классификации. Сети Кохонена можно использовать и в тех задачах классификации, где классы уже заданы, - тогда преимущество будет в том, что сеть сможет выявить сходство между различными классами.
Другая возможная область применения - обнаружение новых явлений. Сеть Кохонена распознает кластеры в обучающих данных и относит все данные к тем или иным кластерам. Если после этого сеть встретится с набором данных, непохожим ни на один из известных образцов, то она не сможет классифицировать такой набор и тем самым выявит его новизну.
Сеть Кохонена имеет всего два слоя: входной и выходной, составленный из радиальных элементов (выходной слой называют также слоем топологической карты). Элементы топологической карты располагаются в некотором пространстве - как правило двумерном (в пакете ST Neural Networks реализованы также одномерные сети Кохонена).
Обучается сеть Кохонена методом последовательных приближений. Начиная со случайным образом выбранного исходного расположения центров, алгоритм постепенно улучшает его так, чтобы улавливать кластеризацию обучающих данных. В некотором отношении эти действия похожи на алгоритмы выборки из выборки и K-средних, которые используются для размещения центров в сетях RBF и GRNN, и действительно, алгоритм Кохонена можно использовать для размещения центров в сетях этих типов. Однако, данный алгоритм работает и на другом уровне.
Помимо того, что уже сказано, в результате итеративной процедуры обучения сеть организуется таким образом, что элементы, соответствующие центрам, расположенным близко друг от друга в пространстве входов, будут располагаться близко друг от друга и на топологической карте.
Топологический слой сети можно представлять себе как двумерную решетку, которую нужно так отобразить в N-мерное пространство входов, чтобы по возможности сохранить исходную структуру данных. Конечно же, при любой попытке представить N-мерное пространство на плоскости будут потеряны многие детали; однако, такой прием иногда полезен, так как он позволяет пользователю визуализировать данные, которые никаким иным способом понять невозможно.
Основной итерационный алгоритм Кохонена последовательно проходит одну за другой ряд эпох, при этом на каждой эпохе он обрабатывает каждый из обучающих примеров, и затем применяет следующий алгоритм:
- Выбрать выигравший нейрон (то есть тот, который расположен ближе всего к входному примеру);
- Скорректировать выигравший нейрон так, чтобы он стал более похож на этот входной пример (взяв взвешенную сумму прежнего центра нейрона и обучающего примера).
Свойство топологической упорядоченности достигается в алгоритме с помощью дополнительного использования понятия окрестности. Окрестность - это несколько нейронов, окружающих выигравший нейрон. Подобно скорости обучения, размер окрестности убывает со временем, так что вначале к ней принадлежит довольно большое число нейронов (возможно, почти вся топологическая карта); на самых последних этапах окрестность становится нулевой (т.е. состоящей только из самого выигравшего нейрона). На самом деле в алгоритме Кохонена корректировка применяется не только к выигравшему нейрону, но и ко всем нейронам из его текущей окрестности.
Результатом такого изменения окрестностей является то, что изначально довольно большие участки сети "перетягиваются" - и притом заметно - в сторону обучающих примеров.
Сеть формирует грубую структуру топологического порядка, при которой похожие наблюдения активируют группы близко лежащих нейронов на топологической карте. С каждой новой эпохой скорость обучения и размер окрестности уменьшаются, тем самым внутри участков карты выявляются все более тонкие различия, что в конце концов приводит к тонкой настройке каждого нейрона. Часто обучение умышленно разбивают на две фазы: более короткую, с большой скоростью обучения и большими окрестностями, и более длинную с малой скоростью обучения и нулевыми или почти нулевыми окрестностями.
После того, как сеть обучена распознаванию структуры данных, ее можно использовать как средство визуализации при анализе данных. С помощью данных, выводимых в окне Частоты выигрышей - Win Frequencies , (где для каждого нейрона подсчитывается, сколько раз он выигрывал при обработке обучающих примеров), можно определить, разбивается ли карта на отдельные кластеры. Можно также обрабатывать отдельные наблюдения и смотреть, как при этом меняется топологическая карта, - это позволяет понять, имеют ли кластеры какой-то содержательный смысл (как правило при этом приходится возвращаться к содержательному смыслу задачи, чтобы установить, как соотносятся друг с другом кластеры наблюдений). После того, как кластеры выявлены, нейроны топологической карты помечаются содержательными по смыслу метками (в некоторых случаях помечены могут быть и отдельные наблюдения). После того, как топологическая карта в описанном здесь виде построена, на вход сети можно подавать новые наблюдения. Если выигравший при этом нейрон был ранее помечен именем класса, то сеть осуществляет классификацию. В противном случае считается, что сеть не приняла никакого решения.
При решении задач классификации в сетях Кохонена используется так называемый порог доступа. Ввиду того, что в такой сети уровень активации нейрона есть расстояние от него до входного примера, порог доступа играет роль максимального расстояния, на котором происходит распознавание.
Если уровень активации выигравшего нейрона превышает это пороговое значение, то сеть считается не принявшей никакого решения. Поэтому, когда все нейроны помечены, а пороги установлены на нужном уровне, сеть Кохонена может служить как детектор новых явлений (она сообщает о непринятии решения только в том случае, если поданный ей на вход случай значительно отличается от всех радиальных элементов).
Идея сети Кохонена возникла по аналогии с некоторыми известными свойствами человеческого мозга. Кора головного мозга представляет собой большой плоский лист (площадью около 0.5 кв.м.; чтобы поместиться в черепе, она свернута складками) с известными топологическими свойствами (например, участок, ответственный за кисть руки, примыкает к участку, ответственному за движения всей руки, и таким образом все изображение человеческого тела непрерывно отображается на эту двумерную поверхность).
| В начало |
Решение задач классификации в пакете ST Neural Networks
Решение задач классификации в пакете ST Neural Networks
В задаче классификации сеть должна отнести каждое наблюдение к одному из нескольких классов (или, в более общем случае, оценить вероятность принадлежности наблюдения к каждому из классов). В пакете ST Neural Networks для классификации используется номинальная выходная переменная - различные ее значения соответствуют различным классам. В пакете ST Neural Networks классификацию можно осуществлять с помощью сетей следующих типов: многослойного персептрона, радиальной базисной функции, сети Кохонена, вероятностной нейронной сети и линейной сети. Единственная из сетей пакета ST Neural Networks , не предназначенная для задач классификации, - это обобщенно-регрессионная сеть (на самом деле, если Вы потребуете, GRNNs будет пытаться это сделать, но мы этого не рекомендуем).
Номинальные переменные представляются в пакете ST Neural Networks в одном из двух видов ( первый из них годится только для переменных с двумя значениями): 1) бинарном (два состояния) и 2) один-из-N.
При бинарном представлении переменной соответствует один узел сети, при этом значение 0.0 означает активное состояние, а 1.0 - неактивное. При кодировании 1-из-N на каждое состояние выделяется один элемент, так что каждое конкретное состояние представляется как 1.0 в соответствующем элементе и 0.0 во всех других.
Номинальные входные переменные в пакете ST Neural Networks могут быть преобразованы одним из этих методов как на этапе обучения сети, так и при ее работе. Целевые выходные значения для элементов, соответствующих номинальным переменным, также легко определяются во время обучения. Несколько большие усилия требуются на то, чтобы по результатам работы сети определить выходной класс.
Каждый из выходных элементов будет содержать числовые значения в интервале от 0.0 до 1.0. Чтобы уверенно определить класс по набору выходных значений, сеть должна решить, "достаточно ли близки" они к нулю или единице. Если такой близости не наблюдается, класс считается "неопределенным".
Кроме того, в пакете ST Neural Networks для интерпретации выходных значений используются доверительные уровни (пороги принятия и отвержения). Эти пороговые значения можно корректировать, чтобы заставить сеть быть более или, наоборот, менее "решительной" при объявлении класса. Схемы здесь немного различаются для случаев бинарного и 1-из-N представлений:
Бинарное.
Бинарное.
Если выходное значение элемента превышает порог принятия, то выбирается класс 1.0. Если выходное значение лежит ниже порога отвержения, выбирается класс 0.0. Если выходное значение лежит между порогами, класс считается не определенным.
Один -из-N.
Один -из-N.
Определенный класс выбирается только в том случае, если значение соответствующего выходного элемента выше порога принятия, а всех остальных выходных элементов - ниже порога отвержения. Если же данное условие не выполнено, класс не определяется.
При кодировании методом 1-из-N имеет место одна особенность. На первый взгляд кажется, что "наиболее решительной" будет сеть с порогами принятия и отвержения, равными 0.5.
Это действительно так для бинарного кодирования, но уже не так для кодирования 1-из-N. Можно сделать так, чтобы порог принятия был ниже порога отвержения, и наиболее решительной будет сеть, у которой порог принятия 0.0 , а порог отвержения 1.0. При такой, на первый взгляд странной настройке сети элемент с наивысшим уровнем активации будет определять класс вне зависимости от того, что происходит в других элементах. Вот точная схема действия алгоритма определения класса в пакете ST Neural Networks:
- Выбирается элемент с наивысшим выходным сигналом. Если его выходной сигнал выше или равен порогу принятия, а выходные сигналы всех остальных элементов ниже порога отвержения, то в качестве ответа выдать класс, определяемый этим элементом.
Хотя для понимания описанной процедуры требуются определенные усилия, после того, как Вы к ней привыкнете, Вы сможете устанавливать для задачи различные тонкие условия. Например, уровни принятия/отвержения, равные 0.3/0.7 , означают следующее: "выбрать класс, соответствующий выигравшему элементу, при условии, что его выход был не ниже 0.3 и ни у какого другого элемента активация не превышала 0.7" - другими словами, для того, чтобы решение было принято, победитель должен показать заметный уровень активации, а проигравшие - не слишком высокий.
Все сказанное относится к механизму выбора класса для большинства типов сетей: MLP, RBF, линейных сетей и PNN (одно исключение: в PNN-сети нельзя использовать бинарное кодирование, и даже бинарные номинальные выходные переменные оцениваются с помощью кодирования 1-из-N ).
В отличие от них, сеть Кохонена действует совершенно иначе.
В сети Кохонена выигравшим элементом топологической карты (выходного слоя) является тот, у которого самый высокий уровень активации (он измеряет расстояние от входного примера до точки, координаты которой хранятся в элементе сети). Некоторые или даже все элементы топологической карты могут быть помечены именами классов. Если это расстояние достаточно мало, то данный случай причисляется к соответствующему классу (при условии, что указано имя класса). В пакете ST Neural Networks значение порога принятия - это наибольшее расстояние, на котором принимается положительное решение о классификации наблюдения. Если же входной случай лежит от выигравшего элемента на более далеком расстоянии или если выигравший элемент не был помечен (или если его метка не соответствует ни одному из значений выходной номинальной переменной), то случай остается нерасклассифицированным. Порог отвержения в сетях Кохонена не используется.
В наших рассмотрениях мы предполагали, что "положительному" решению о классификации должно соответствовать значение, близкое к 1.0, а "отрицательному" - близкое к 0.0. Это действительно так в том случае, если на выходе используются логистические функции активации. Кроме того, это удобно, поскольку вероятность может принимать значения от 0.0 до 1.0. Однако, в некоторых ситуациях может оказаться более удобным использовать другой диапазон. Иногда применяется обратная упорядоченность, так что положительное решение соответствует малым выходным значениям. Пакет ST Neural Networks поддерживает любой из этих вариантов работы.
Вначале в качестве границ диапазона для каждой переменной используются значения минимум/среднее и максимум/стандартное отклонение. Для логистической выходной функции активации хорошими значениями по умолчанию являются 0.0 и 1.0. Некоторые авторы советуют использовать в качестве функции активации гиперболический тангенс, который принимает значения в интервале (-1.0,+1.0) .
Таким приемом можно улучшить обучение, потому что эта функция (в отличие от логистической) симметрична. В этом случае нужно изменить значения минимум/среднее и максимум/стандартное отклонение, и программа ST Neural Networks автоматически будет правильно интерпретировать классы.
Обратная упорядоченность, как правило, применяется в двух ситуациях. Одну из них мы только что обсудили: это сети Кохонена, в которых выходное значение есть мера удаленности, и ее малое значение соответствует большему доверию. Вторая ситуация возникает при использовании матрицы потерь (которая может быть добавлена в вероятностную сеть на этапе ее построения или вручную - к сетям других типов). Если используется матрица потерь, то выходы сети означают ожидаемые потери от выбора того или иного класса, и цель заключается в том, чтобы выбрать класс с наименьшими потерями. Упорядоченность можно обратить, объявив выходной сигнал не уровнем доверия, а мерой ошибки. В таком случае порог принятия будет ниже порога отвержения.
Таблица статистик классификации
Таблица статистик классификации
При выборе порогов принятия/отвержения и оценке способностей сети к классификации очень помогает информация, содержащаяся в окне Статистики классификации - Classification Statistics. В нем указывается, сколько наблюдений было классифицировано правильно, сколько неправильно или вообще не классифицировано. Кроме того, выдается информация о том, сколько наблюдений каждого класса было отнесено к другим классам. Все эти данные выдаются отдельно для обучающего, контрольного и тестового множеств.
| В начало |
Решение задач регрессии в пакете ST Neural Networks
Решение задач регрессии в пакете ST Neural Networks
В задачах регрессии целью является оценка значения числовой (принимающей непрерывный диапазон значений) выходной переменной по значениям входных переменных. Задачи регрессии в пакете ST Neural Networks можно решать с помощью сетей следующих типов: многослойный персептрон, радиальная базисная функция, обобщенно-регрессионная сеть и линейная сеть.
При этом выходные данные должны иметь стандартный числовой (не номинальный) тип. Особую важность для регрессии имеют масштабирование (шкалирование) выходных значений и эффекты экстраполяции.
Нейронные сети наиболее часто используемых архитектур выдают выходные значения в некотором определенном диапазоне (например, на отрезке [0,1] в случае логистической функции активации). Для задач классификации это не создает трудностей. Однако для задач регрессии совершенно очевидно, что тут есть проблема, и некоторые ее детали оказываются весьма тонкими. Сейчас мы обсудим возникающие здесь вопросы.
Для начала применим алгоритм масштабирования, чтобы выход сети имел "приемлемый" диапазон. Простейшей из масштабирующих функций пакета ST Neural Networks является минимаксная функция: она находит минимальное и максимальное значение переменной по обучающему множеству и выполняет линейное преобразование (с применением коэффициента масштаба и смещения), так чтобы значения лежали в нужном диапазоне (как правило, на отрезке [0.0,1.0]). Если эти действия применяются к числовой (непрерывной) выходной переменной, то есть гарантия, что все обучающие значения после преобразования попадут в область возможных выходных значений сети, и следовательно сеть может быть обучена. Кроме того, мы знаем, что выходы сети должны находиться в определенных границах. Это обстоятельство можно считать достоинством или недостатком - здесь мы приходим к вопросам экстраполяции.
Посмотрим на рисунок.
Мы стремимся оценить значение Y по значению X. Необходимо аппроксимировать кривую, проходящую через заданные точки. Вероятно, вполне подходящей для этого покажется кривая, изображенная на графике - она (приблизительно) имеет нужную форму и позволяет оценить значение Y в случае, если входное значение лежит в интервале, который охватывается сплошной частью кривой - в этой области возможна интерполяция.
Но что делать, если входное значение расположено существенно правее имеющихся точек? В таких случаях возможны два подхода к оценке значения Y.
Первый вариант - экстраполяция: мы продолжаем подогнанную кривую вправо. Во втором варианте мы говорим, что у нас нет достаточной информации для осмысленной оценки этого значения, и потому в качестве оценки мы принимаем среднне значение всех выходов (в отсутствие какой-либо информации это может оказаться лучшим выходом из положения).
Предположим, например, что мы используем многослойный персептрон (MLP). Применение минимакса по описанной выше схеме весьма ограничительно. Во-первых, кривая не будет экстраполироваться, как бы близко мы не находились к обучающим данным (в действительности же, если мы лишь чуть-чуть вышли за область обучающих данных, экстраполяция вполне оправдана). Во-вторых, оценка по среднему также не будет выполняться: вместо этого будет браться минимум или максимум смотря по тому, росла или убывала в этом месте оцениваемая кривая.
Чтобы избежать этих недостатков в MLP используется ряд приемов:
Во-первых, логистическую функцию активации в выходном слое можно заменить на линейную, которая не меняет уровня активации (N.B.: функции активации меняются только в выходном слое; в промежуточных слоях по-прежнему остаются логистические и гиперболические функции активации). Линейная функция активации не насыщается, и поэтому способна экстраполировать (при этом логистические функции предыдущих уровней все-таки предполагают насыщение на более высоких уровнях). Линейные функции активации в MLP могут вызвать определенные вычислительные трудности в алгоритме обратного распространения, поэтому при его использовании следует брать малые (менее 0.1) скорости обучения. Описанный подход пригоден для целей экстраполяции.
Во-вторых, можно изменить целевой диапазон минимаксной масштабирующей функции (например, сделать его [0.25,0.75]). В результате обучающие наблюдения будут отображаться в уровни, соответствующие средней части диапазона выходных значений. Интересно заметить, что если этот диапазон выбран маленьким, и обе его границы находятся вблизи значения 0.5, то он будет соответствовать среднему участку сигмоидной кривой, на котором она "почти линейна", - тогда мы будем иметь практически ту же схему, что и в случае линейного выходного слоя.
Такая сеть сможет выполнять экстраполяцию в определенных пределах, а затем будет насыщаться. Все это можно хорошо себе представить так: экстраполяция допустима в определенных границах, а вне их она будет пресекаться.
Если применяется первый подход и в выходном слое помещены линейные элементы, то может получиться так, что вообще нет необходимости использовать алгоритм масштабирования, поскольку элементы и без масштабирования могут выдавать любой уровень выходных сигналов. В пакете ST Neural Networks имеется возможность для большей эффективности вообще отключить все масштабирования. Однако, на практике полный отказ от масштабирования приводит к трудностям в алгоритмах обучения. Действительно, в этом случае разные веса сети работают в сильно различающихся масштабах, и это усложняет начальную инициализацию весов и (частично) обучение. Поэтому мы не рекомендуем Вам отключать масштабирование, за исключением тех случаев, когда диапазон выходных значений очень мал и расположен вблизи нуля. Это же соображение говорит в пользу масштабирования и при пре-процессировании в MLP-сетях (при котором, в принципе, веса первого промежуточного слоя можно легко корректировать, добиваясь этим любого нужного масштабирования).
До сих пор в нашем обсуждении мы уделяли основное внимание тому, как в задачах регрессии применяются сети MLP, и в особенности тому, как сети такого типа ведут себя в смысле экстраполяции. Сети, в которых используются радиальные элементы (RBF и GRNN), работают совершенно иначе и о них следует поговорить отдельно.
Радиальные сети по самой своей природе неспособны к экстраполяции. Чем дальше входной пример расположен от точек, соответствующих радиальным элементам, тем меньше становятся уровни активации радиальных элементов и (в конце концов) тем меньше будет выходной сигнал сети. Входной пример, расположенный далеко от центров радиальных элементов, даст нулевой выходной сигнал. Стремление сети не экстраполировать данные можно считать достоинством (это зависит от предметной области и Вашего мнения), однако убывание выходного сигнала (на первый взгляд) достоинством не является.
Если мы стремимся избегать экстраполяции, то для входных точек, отличающихся большой степенью новизны, в качестве выхода мы, как правило, хотим иметь усредненное значение.
Для радиальных сетей в задачах регрессии этого можно достичь с помощью масштабирующей функции среднее/стандартное отклонение. Обучающие данные масштабируются таким образом, чтобы среднее выходное значение равнялось 0.0, а все другие значения были бы промасштабированы на стандартное отклонение выходных сигналов. При обработке входных точек, лежащих вне областей действия радиальных элементов, выходной сигнал сети будет приблизительно равен среднему значению.
Качество работы сети в задаче регрессии можно проверить несколькими способами.
Во-первых, сети можно сообщить выходное значение, соответствующее любому наблюдению (или какому-то новому наблюдению, который Вы хотели бы проверить). Если это наблюдение содержалось в исходных данных, то выдается значение разности (невязки).
Во-вторых, могут быть получены итоговые статистики. К ним относятся среднее значение и стандартное отклонение, вычисленные для обучающих данных и для ошибки прогноза. В общем случае среднее значение ошибки прогноза будет очень близко к нулю (в конце концов, нулевое среднее для ошибки прогноза можно получить, попросту оценив среднее значение обучающих данных и вовсе не обращаясь к значениям входных переменных). Наиболее важным показателем является стандартное отклонение ошибки прогноза. Если оно не окажется существенно меньше стандартного отклонения обучающих данных, это будет означать, что сеть работает не лучше, чем простая оценка по среднему. Далее, в пакете ST Neural Networks пользователю выдается отношение стандартного отклонения ошибки прогноза к стандартному отклонению обучающих данных. Если оно существенно меньше единицы (например, ниже 0.1), то это говорит о хорошем качестве регрессии. Это регрессионное отношение (точнее, величину единица минус это отношение) иногда называют долей объясненной дисперсии модели.
В-третьих, можно вывести изображение поверхности отклика.
На самом деле, разумеется, эта поверхность представляет собой N+1-мерный объект, где N - число входных элементов, а оставшееся измерение соответствует высоте точки на поверхности. Понятно, что непосредственно визуально представить такую поверхность при N большем двух невозможно (а реально N всегда больше двух). Тем не менее, в пакете ST Neural Networks Вы можете выводить срезы поверхности отклика по любым двум входным переменным. При этом значения всех остальных входных переменных фиксируются, и меняются только два выбранные. Всем остальным переменным можно придать любое значение по своему усмотрению (по умолчанию система ST Neural Networks возьмет для них средние значения). Значения двух исследуемых переменных можно менять в произвольном диапазоне (по умолчанию - в диапазоне изменения обучающих данных).
| В начало |
Прогнозирование временных рядов в пакете ST Neural Networks
Прогнозирование временных рядов в пакете ST Neural Networks
В задачах анализа временных рядов целью является прогноз будущих значений переменной, зависящей от времени, на основе предыдущих значений ее и/или других переменных (Bishop, 1995) Как правило, прогнозируемая переменная является числовой, поэтому прогнозирование временных рядов - это частный случай регрессии. Однако такое ограничение не заложено в пакет ST Neural Networks, так что в нем можно прогнозировать и временные ряды номинальных (т.е. классифицирующих) переменных.
Обычно очередное значение временного ряда прогнозируется по некоторому числу его предыдущих значений (прогноз на один шаг вперед во времени). В пакете ST Neural Networks можно выполнять прогноз на любое число шагов. После того, как вычислено очередное предполагаемое значение, оно подставляется обратно и с его помощью (а также предыдущих значений) получается следующий прогноз - это называется проекцией временного ряда. В пакете ST Neural Networks можно осуществлять проекцию временного ряда и при пошаговом прогнозировании. Понятно, что надежность такой проекции тем меньше, чем больше шагов вперед мы пытаемся предсказать.
В случаях, когда требуется совершенно определенная дальность прогноза, разумно будет специально обучить сеть именно на такую дальность.
В пакете ST Neural Networks для решения задач прогноза временных рядов можно применять сети всех типов (тип сети должен подходить, в зависимости от задачи, для регрессии или классификации). Сеть конфигурируется для прогноза временного ряда установкой параметров Временное окно - Steps и Горизонт - Lookahead. Параметр Временное окно задает число предыдущих значений, которые следует подавать на вход, а параметр Горизонт указывает, как далеко нужно строить прогноз. Количество входных и выходных переменных может быть произвольным. Однако, чаще всего в качестве входной и одновременно (с учетом горизонта) выходной выступает единственная переменная. При конфигурировании сети для анализа временных рядов изменяется метод пре-процессирования данных (извлекаются не отдельные наблюдения, а их блоки), но обучение и работа сети происходят точно так же, как и в задачах других типов.
В задачах анализа временных рядов обучающее множество данных, как правило, бывает представлено значениями одной переменной, которая является входной/выходной (т.е. служит для сети и входом, и выходом).
В задачах анализа временных рядов особую сложность представляет интерпретация понятий обучающего, контрольного и тестового множеств, а также неучитываемых данных. В обычной ситуации каждое наблюдение рассматривается независимо, и никаких вопросов здесь не возникает. В случае же временного ряда каждый входной или выходной набор составлен из данных, относящихся к нескольким наблюдениям, число которых задается параметрами сети Временное окно - Steps и Горизонт - Lookahead. Из этого следуют два обстоятельства:
Категория, которое будет отнесен набор, определяется категорией выходного наблюдения. Например, если в исходных данных первые два наблюдения не учитываются, а третье объявлено тестовым, и значения параметров Временное окно и Горизонт равны соответственно 2 и 1, то первый используемый набор будет тестовым, его входы будут браться из первых двух наблюдений, а выход - из третьего.
Таким образом, первые два наблюдения, хотя и помечены как не учитываемые, используются в тестовом множестве. Более того, данные одного наблюдения могут использоваться сразу в трех наборах, каждый из которых может быть обучающим, контрольным или тестовым. Можно сказать, что данные "растекаются" по обучающему, контрольному и тестовому множествам. Чтобы полностью разделить эти множества, пришлось бы сформировать отдельные блоки обучающих, контрольных и тестовых наблюдений, отделенные друг от друга достаточным числом неучитываемых наблюдений.
Несколько первых наблюдений можно использовать только в качестве входных данных. При выборе наблюдений во временном ряду номер наблюдения всегда соответствует выходному значению. Поэтому первые несколько наблюдений вообще невозможно выбрать (для этого были бы нужны еще несколько наблюдений, расположенных перед первым наблюдением в исходных данных), и они автоматически помечаются как неучитываемые.
| В начало |
Отбор переменных и понижение размерности
Отбор переменных и понижение размерности
До сих пор, говоря о построении и конструировании сети, мы предполагали, что входной и выходной слои заданы, то есть, что мы уже знаем, какие переменные будут подаваться на вход сети, и что будет ее выходом. То, какие переменные будут выходными, известно всегда (по крайней мере в случае управляемого обучения). Что же касается входных переменных, их правильный выбор порой представляет большие трудности (Bishop, 1995). Часто мы не знаем заранее, какие из входных переменных действительно полезны для решения задачи, и выбор хорошего множества входов бывает затруднен целым рядом обстоятельств:
- Проклятие размерности. Каждый дополнительный входной элемент сети - это новая размерность в пространстве данных. С этой точки зрения становится понятно следующее: чтобы достаточно плотно "заселить" N-мерное пространство и "увидеть" структуру данных, нужно иметь довольно много точек. Необходимое число точек быстро возрастает с ростом размерности пространства (грубо говоря, как 2**N для большинства методов).
Большинство типов нейронных сетей ( в частности, многослойный персептрон MLP) в меньшей степени страдают от проклятия размерности, чем другие методы, потому что сеть умеет следить за проекциями участков многомерного пространства в пространства малой размерности (например, если все веса, выходящие из некоторого входного элемента, равны нулю, то MLP-сеть полностью игнорирует эту входную переменную). Тем не менее, проклятие размерности остается серьезной проблемой, и качество работы сети можно значительно улучшить, исключив ненужные входные переменные. На самом деле, чтобы уменьшить эффект проклятия размерности иногда бывает целесообразно исключить даже те входные переменные, которые несут в себе некоторою (небольшую) информацию. - Внутренние зависимости между переменными. Было бы очень хорошо, если бы каждую переменную - кандидата на то, чтобы служить входом сети, можно было бы независимо оценить на "полезность", а затем отобрать самые полезные переменные. К сожалению, как правило, это бывает невозможно сделать, и две или более взаимосвязанных переменных могут вместе нести существенную информацию, которая не содержится ни в каком их подмножестве. Классическим примером может служить задача с двумя спиралями, в которой точки данных двух классов расположены вдоль двух переплетающихся двумерных спиралей. Ни одна из переменных в отдельности не несет никакой полезной информации (классы будут выглядеть совершенно перемешанными), но глядя на обе переменные вместе, классы легко разделить. Таким образом, в общем случае переменные нельзя отбирать независимо.
- Избыточность переменных. Часто бывает так, что одна и та же информация в большей или меньшей степени повторяется в разных переменных. Например, данные о росте и весе человека, как правило, несут в себе сходную информацию, поскольку они сильно коррелированы. Может оказаться так, что в качестве входов достаточно взять лишь часть из нескольких коррелированных переменных, и этот выбор может быть произвольным. В таких ситуациях вместо всего множества переменных лучше взять их часть - этим мы избегаем проклятия размерности.
Перед тем, как непосредственно начинать работать с пакетом ST Neural Networks , имеет смысл произвести предварительный отбор переменных, используя при этом свои знания в предметной области и стандартные статистические критерии. Затем, уже средствами пакета ST Neural Networks можно будет попробовать различные комбинации входных переменных. В пакете ST Neural Networks имеется возможность "игнорировать" некоторые переменные, так что полученная сеть не будет использовать их в качестве входов. Можно поочередно экспериментировать с различными комбинациями входов, строя всякий раз новые варианты сетей. При таком экспериментировании очень полезными оказываются вероятностные и обобщенно-регрессионные сети. Несмотря на то, что они работают медленнее более компактных MLP и RBF сетей, они обучаются почти мгновенно, и это важно, поскольку при переборе большого числа комбинаций входных переменный приходится каждый раз строить новые сети. Кроме того, PNN и GRNN (как и RBF) - это радиальные сети (в первом слое они имеют радиальные элементы, и аппроксимирующие функция строятся в виде комбинаций гауссовых функций). При отборе входных переменных это является преимуществом, поскольку радиальные сети в меньшей степени страдают от проклятия размерности, чем сети, построенные на линейных элементах.
Чтобы понять причину этого, рассмотрим, что произойдет, если мы добавим в сеть новую, возможно совершенно несущественную входную переменную. Сеть на линейных элементах, например MLP, может научиться присваивать весам, идущим от этой переменной, нулевые значения, что означает игнорирование переменной (реально это происходит так: изначально малые веса этой переменной так и остаются малыми, а веса содержательных входных переменных меняются нужным образом). Радиальная сеть типа PNN или GRNN не может позволить себе такую роскошь: кластеры, образующиеся в пространстве небольшого числа существенных переменных, будут "размазаны" по направлениям несущественных размерностей - для учета разброса по несущественным направлениям требуется большее число элементов.
Сеть, в большей степени страдающая от наличия плохих входных данных, имеет преимущество, когда мы стремимся избавиться то этих плохих данных.
Поскольку описанный процесс экспериментирования занимает много времени, в пакете ST Neural Networks имеется инструмент, который может сделать это за Вас. Для выбора подходящей комбинации входных переменных здесь используется так называемый генетический алгоритм (Goldberg, 1989). Генетические алгоритмы хорошо приспособлены для задач такого типа, поскольку они позволяют производить поиск среди большого числа комбинаций при наличии внутренних зависимостей в переменных.
Существует и другой подход к проблеме размерности, который может использоваться как альтернатива или как дополнение к методам отбора переменных: это понижение размерности. Суть его состоит в том, что исходная совокупность переменных преобразуется в новую совокупность, состоящую из меньшего числа переменных, но при этом (как мы надеемся) содержащую по возможности всю информацию, заложенную в исходных данных. В качестве примера рассмотрим данные, все точки которых расположены на некоторой плоскости в трехмерном пространстве. Истинная размерность данных равна двум (поскольку вся информация на самом деле содержится в двумерном подпространстве). Если мы сумеем обнаружить эту плоскость, то на вход нейронной сети можно будет подавать входные данные меньшей размерности, и будет больше шансов на то, что такая сеть будет работать правильно.
Самый распространенный метод понижения размерности - это анализ главных компонент (Bishop, 1995; см. также Факторный анализ). Метод состоит в следующем: к данным применяется линейное преобразование, при котором направлениям новых координатных осей соответствуют направления наибольшего разброса исходных данных. Как правило, уже первая компонента отражает большую часть информации, содержащейся в данных. Поскольку анализ главных компонент (АГК) представляет собой линейный метод, его можно реализовать с помощью линейной сети, и в пакете ST Neural Networks предусмотрена возможность обучать линейную сеть для выполнения АГК.
Очень часто метод АГК выделяет из многомерных исходных данных совсем небольшое число компонент, сохраняя при этом структуру информации.
Один из недостатков метода главных компонент (АГК) состоит в том, что это чисто линейный метод, и из-за этого он может не учитывать некоторые важные характеристики структуры данных. В пакете ST Neural Networks реализован также вариант "нелинейного АГК", основанный на использовании так называемой автоассоциативной сети (Bishop, 1995; Fausett, 1994; Bouland and Kamp, 1988). Это такая нейронная сеть, которую обучают выдавать в качестве выходов свои собственные входные данные, но при этом в ее промежуточном слое содержится меньше нейронов, чем во входном и выходном слоях. Поэтому, чтобы восстановить свои входные данные, сеть должна научиться представлять их в более низкой размерности. Сеть "впихивает" наблюдения в формат промежуточного слоя и только потом выдает их на выходе. После обучения автоассоциативной сети ее внешний интерфейс может быть сохранен и использован для понижения размерности. Как правило, в качестве автоассоциативной сети берется многослойный персептрон с тремя промежуточными слоями. При этом средний слой отвечает за представление данных в малой размерности, а два других скрытых слоя служат соответственно для нелинейного преобразования входных данных в средний слой и выходов среднего слоя в выходной слой. Автоассоциативная сеть с единственным промежуточным слоем может выполнять только линейное понижение размерности, и фактически осуществляет АГК в стандартном варианте.
| В начало |

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.