Учебник по промышленной статистике
Непараметрическая статистика и подгонка распределения
Непараметрическая статистика и подгонка распределения
- Основная цель
- Краткий обзор непараметрических процедур
- Какой метод использовать
- Подгонка распределения
- Основная цель
- Краткий обзор непараметрических процедур
- Какой метод использовать
- Подгонка распределения
Основная цель
Основная цель
Краткий обзор понятия "критерий значимости".
Краткий обзор понятия "критерий значимости".
Для того чтобы понять идеи непараметрической
статистики (термин был впервые введен Wolfowitz, 1942), следует познакомиться с идеями параметрической статистики. Глава Элементарные понятия статистики знакомит с понятием статистической значимости критерия, основанного на выборочном распределении определенной статистики (вы можете просмотреть эту главу, прежде чем продолжить чтение). Говоря кратко, если вы знаете распределение наблюдаемой переменной, то можете предсказать, как в повторных выборках равного объема будет "вести себя" используемая статистика - т.е. каким образом она будет распределена. Пусть, например, имеется 100 случайных выборок, из одной популяции по 100 взрослых человек в каждой. Вычислим средний рост субъектов в каждой выборке, т.е. построим выборочное среднее. Тогда распределение выборочных средних можно хорошо аппроксимировать нормальным распределением (более точно, t распределением Стьюдента с 99 степенями свободы). Теперь представьте, что случайным образом извлечена еще одна выборка из жителей некоего города ("Вышгород"), где, по вашим представлениям, проживают люди с ростом выше среднего. Если средний рост людей в этой выборке попадает в верхнюю 95% критическую область tраспределения, то можно сделать обоснованный вывод, что жители Вышгорода, действительно, в среднем более высокие (чем в целом в популяции), т.е. что это действительно город высоких людей.
Действительно ли большинство переменных имеют нормальное распределение?
В рассмотренном примере использовался тот факт, что в повторных выборках равного объемы средние значения (роста людей) будут иметь t распределение (с определенным средним и дисперсией).
Однако, это верно лишь, если рассматриваемая переменная (рост) имеет нормальное распределение, т.е. что распределение людей определенного роста нормально распределено.
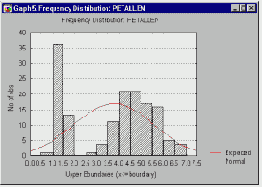
Для многих изучаемых переменных невозможно сказать с уверенностью, что это действительно так. Например, является ли доход нормально распределенной величиной? - скорее всего, нет. Случаи редких болезней не являются нормально распределенными в популяции, число автомобильных аварий также не является нормально распределенным, как и многие переменные, интересующие исследователя.
Дополнительную информацию о нормальном распределении можно посмотреть в разделе Элементарные понятия статистики.
Объем выборки.
Объем выборки.
Другим фактором, часто ограничивающим применимость критериев, основанных на предположении нормальности, является объем или размер выборки, доступной для анализа. До тех пор пока выборка достаточно большая (например, 100 или больше наблюдений), можно считать, что выборочное распределение нормально, даже если вы не уверены, что распределение переменной в популяции, действительно, является нормальным. Тем не менее, если выборка очень мала, то критерии, основанные на нормальности, следует использовать только при наличии уверенности, что переменная действительно имеет нормальное распределение. Однако нет способа проверить это предположение на малой выборке.
Проблемы измерения.
Проблемы измерения.
Использование критериев, основанных на предположении нормальности, кроме того, ограничено точностью измерений. Например, рассмотрим исследование, в котором средний балл успеваемости (СБУ) является основной переменной. Можно ли сказать, что средняя успеваемость студента A в два раза выше, чем успеваемость студента C? Является ли различие между средним баллом студентов B и A сравнимым с различием между студентами D и C? Индекс СБУ является грубой мерой, позволяющей только ранжировать студентов в порядке "хороший" - "плохой". Эта общая задача измерений обычно обсуждается в учебниках по статистике в терминах типов измерений или шкалы измерения.
Не вдаваясь в детали, отметим, что наиболее общие статистические методы, такие как дисперсионный анализ (t-критерий), регрессия и т.д. предполагают, что исходные измерения выполнены, по крайней мере, в интервальной шкале, в которой интервалы можно разумным образом сравнивать между собой (например, B минус A равняется D минус C). Тем не менее, как в данном примере, такие предположения часто неестественны, и данные скорее просто упорядочены (измерены в порядковой шкале), чем измерены точно.
Параметрические и непараметрические методы.
Параметрические и непараметрические методы.
Надеемся, что после этого введения становится ясной необходимость наличия статистических процедур, позволяющих обрабатывать данные "низкого качества" из выборок малого объема с переменными, про распределение которых мало что или вообще ничего не известно. Непараметрические методы как раз и разработаны для тех ситуаций, достаточно часто возникающих на практике, когда исследователь ничего не знает о параметрах исследуемой популяции (отсюда и название методов - непараметрические). Говоря более специальным языком, непараметрические методы не основываются на оценке параметров (таких как среднее или стандартное отклонение) при описании выборочного распределения интересующей величины. Поэтому эти методы иногда также называются свободными от параметров или свободно распределенными.
| В начало |
Краткий обзор непараметрических процедур
Краткий обзор непараметрических процедур
По существу, для каждого параметрического критерия имеется, по крайней мере, один непараметрический аналог. Эти критерии можно отнести к одной из следующих групп:
- критерии различия между группами (независимые выборки);
- критерии различия между группами (зависимые выборки);
- критерии зависимости между переменными.
Непараметрическими альтернативами этому критерию являются: критерий серий Вальда-Вольфовица, U критерий Манна-Уитни и двухвыборочный критерий Колмогорова-Смирнова. Если вы имеете несколько групп, то можете использовать дисперсионный анализ (см. Дисперсионный анализ). Его непараметрическими аналогами являются: ранговый дисперсионный анализ Краскела-Уоллиса и медианный тест. Различия между зависимыми группами.
Различия между зависимыми группами.
Если вы хотите сравнить две переменные, относящиеся к одной и той же выборке (например, математические успехи студентов в начале и в конце семестра), то обычно используется t-критерий для зависимых выборок (в модуле Основные статистики и таблицы. Альтернативными непараметрическими тестами являются: критерий знаков и критерий Вилкоксона парных сравнений. Если рассматриваемые переменные по природе своей категориальны или являются категоризованными (т.е. представлены в виде частот попавших в определенные категории), то подходящим будет критерий хи-квадрат Макнемара. Если рассматривается более двух переменных, относящихся к одной и той же выборке, то обычно используется дисперсионный анализ (ANOVA) с повторными измерениями. Альтернативным непараметрическим методом является ранговый дисперсионный анализ Фридмана или Q критерий Кохрена (последний применяется, например, если переменная измерена в номинальной шкале). Q критерий Кохрена используется также для оценки изменений частот (долей).
Зависимости между переменными.
Зависимости между переменными.
Для того, чтобы оценить зависимость (связь) между двумя переменными, обычно вычисляют коэффициент корреляции. Непараметрическими аналогами стандартного коэффициента корреляции Пирсона являются статистики Спирмена R, тау Кендалла и коэффициент Гамма (см. Непараметрические корреляции). Если две рассматриваемые переменные по природе своей категориальны, подходящими непараметрическими критериями для тестирования зависимости будут: Хи-квадрат, Фи коэффициент, точный критерий Фишера. Дополнительно доступен критерий зависимости между несколькими переменными так называемый коэффициент конкордации Кендалла.
Этот тест часто используется для оценки согласованности мнений независимых экспертов (судей), в частности, баллов, выставленных одному и тому же субъекту.
Описательные статистики.
Описательные статистики.
Если данные не являются нормально распределенными, а измерения, в лучшем случае, содержат ранжированную информацию, то вычисление обычных описательных статистик (например, среднего, стандартного отклонения) не слишком информативно. Например, в психометрии хорошо известно, что воспринимаемая интенсивность стимулов (например, воспринимаемая яркость света) представляет собой логарифмическую функцию реальной интенсивности (яркости, измеренной в объективных единицах - люксах). В данном примере, обычная оценка среднего (сумма значений, деленная на число стимулов) не дает верного представления о среднем значении действительной интенсивности стимула. (В обсуждаемом примере скорее следует вычислить геометрическое среднее.) Модуль Непараметрическая статистика вычисляет разнообразный набор мер положения (среднее, медиану, моду и т.д.) и рассеяния (дисперсию, гармоническое среднее, квартильный размах и т.д.), позволяющий представить более "полную картину" данных.
| В начало |
Какой метод использовать
Какой метод использовать
Нелегко дать простой совет, касающийся использования непараметрических процедур. Каждая непараметрическая процедура в модуле имеет свои достоинства и свои недостатки. Например, двухвыборочный критерий Колмогорова-Смирнова чувствителен не только к различию в положении двух распределений, например, к различиям средних, но также чувствителен и к форме распределения. Критерий Вилкоксона парных сравнений предполагает, что можно ранжировать различия между сравниваемыми наблюдениями. Если это не так, лучше использовать критерий знаков. В общем, если результат исследования является важным (например, оказывает ли людям помощь определенная очень дорогостоящая и болезненная терапия?), то всегда целесообразно применить различные непараметрические тесты.
Возможно, результаты проверки (разными тестами) будут различны. В таком случае следует попытаться понять, почему разные тесты дали разные результаты. С другой стороны, непараметрические тесты имеют меньшую статистическую мощность (менее чувствительны), чем их параметрические конкуренты, и если важно обнаружить даже слабые отклонения (например, является ли данная пищевая добавка опасной для людей), следует особенно внимательно выбирать статистику критерия.
Большие массивы данных и непараметрические методы.
Большие массивы данных и непараметрические методы.
Непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, n > 100), то не имеет смысла использовать непараметрические статистики. Глава Элементарные понятия статистики предлагает краткое ознакомление с центральной предельной теоремой. Главное здесь состоит в том, что когда выборки становятся очень большими, то выборочные средние подчиняются нормальному закону, даже если исходная переменная не является нормальной или измерена с погрешностью. Таким образом, параметрические методы, являющиеся более чувствительными (имеют большую статистическую мощность), всегда подходят для больших выборок. Большинство критериев значимости многих непараметрических статистик, описанных далее, основываются на асимптотической теории (больших выборок) поэтому соответствующие тесты часто не выполняются, если размер выборки становится слишком малым. Обратитесь к описаниям определенных критериев, чтобы узнать больше об их мощности и эффективности.
Подгонка распределения
Подгонка распределения
В некоторых исследовательских проектах можно сформулировать гипотезы относительно распределения рассматриваемой переменной. Например, переменные, значения которых определяются бесконечным числом независимых факторов, распределены по нормальному закону: можно предположить, что рост индивидуума является результатом воздействия многих независимых факторов, таких как различные генетические предрасположенности, болезни, перенесенные в раннем возрасте и т.д.
Как следствие, рост имеет тенденцию к нормальному распределению в населении. С другой стороны, если наблюдаемые значения переменной являются результатом очень редких событий, то переменная будет иметь распределение Пуассона (которое иногда называется распределением редких событий). Например, несчастные случаи на производстве можно рассматривать как результат пересечения ряда неудачных событий (на житейском языке стечением маловероятных обстоятельств), поэтому их частота приближенно описывается распределением Пуассона. Эти и другие полезные распределения подробно описываются в соответствующих разделах.
Гипотеза нормальности.
Гипотеза нормальности.
Другим обычным приложением процедуры подгонки распределения является проверка гипотезы нормальности до того, как использовать какой-либо параметрический тест (см. выше).
| В начало |

(c) Copyright StatSoft, Inc., 1984-2001
STATISTICA является торговой маркой StatSoft, Inc.