Математический анализ в Maple 9
Интерполяция методом Лагранжа
На практике очень часто приходится иметь дело с данными, которые представлены в виде таблиц и задают зависимость одних параметров исследуемого явления от других. Задача состоит в том, чтобы по таким данным восстановить соответствующую аналитическую зависимость.
Предположим, имеется таблица значений неизвестной функции f(x) в точках х0, х,, ... х„. Другими словами, известны только значения функции в этих точках: f(x), к = 0..и. По этим значениям предстоит построить такую функцию f(х), чтобы она с приемлемой точностью аппроксимировала исходную функцию f(x) (что такое приемлемая точность — вопрос отдельный!) и ее значения в точках хк совпадали со значениями функции в этих точках (которые, кстати, называются узлами). Задача построения такой функции и называется задачей интерполирования.
К задачам интерполирования прибегают не только в случаях, когда вид функции f(x) неизвестен, но и когда известное аналитическое выражение для f(x) слишком громоздко и неприемлемо для проведения вычислительных оценок.
Как правило, при интерполировании выбирается набор базисных функций и интерполирующая функция <р(х) строится в виде линейной их комбинации. Такие базисные функции, как минимум, должны быть линейно независимы на отрезке, на котором выполняется интерполирование. Часто в качестве базисных функций выбирают ограниченный базис из набора ортогональных функций — например, классических ортогональных полиномов.
На заметку
Ограниченным базис называется потому, что используются не все функции этого базиса (все функции образуют бесконечное множество). По полному базису можно разложить практически любую функцию, удовлетворяющую условию квадратичной интегрируемости (интеграл от квадрата функции на данном интервале должен быть ограниченным). Однако чтобы однозначно разложить функцию по бесконечному базису, необходимо либо иметь бесконечное число условий (что, понятно, недостижимо), либо знать саму функцию (в этом случае нет необходимости выполнять интерполяцию). Поскольку функция интерполируется по конечному числу точек, используется конечный базис. В результате в общем случае выражение для функции получаем приближенное — "точное попадание" является случайностью.
Ниже рассмотрим некоторые наиболее популярные методы построения интерполяционных функций.
При интерполяции методом Лагранжа интерполяционная функция строится в виде полинома, а в качестве базисных функций выбираются степенные функции из последовательности 1, х , хг, ... х", ... . Количество таких функций определяется числом базовых точек. Таким образом, при построении интерполяционного полинома по N точкам степень полинома равна N-1. Сама интерполяционная функция L(x) ищется в виде L(х) = f(x)<*>,(*) где f(x,) есть табличные значения интерполируемой зависимости в узлах, а функции <рХх) являются полиномами степени N и равны нулю во всех узловых точках, кроме той, индекс которой совпадает с индексом функции. Другими словами, имеет место соотношение <pAx,) = s,1 > гДе < — символ Кронекера. Следовательно, можем создать процедуру, которая по базовым точкам и значениям функции в этих точках будет строить интерполяционный полином Лагранжа. Программный код процедуры lagr() приведен ниже. У процедуры всего один параметр — список с узловыми точками и значениями функции. С точки зрения Maple этот параметр является списком, элементы которого также являются списком. Данный факт отражен указанием типа параметра list (list). Будем исходить из предположения, что узловая точка и значение функции в этой точке являются списком из двух элементов (первый — узел, второй — значение функции в узле). Эти списки, в свою очередь, объединяются в общий список, образуя тем самым параметр процедуры.
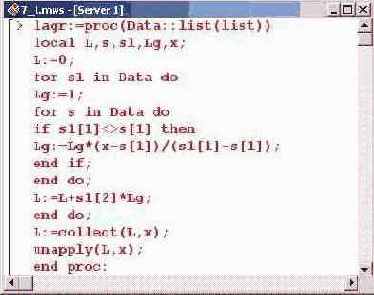
Основу процедуры составляют два вложенных цикла. В рамках первого цикла переменная si пробегает значения из списка-параметра процедуры. Такими значениями являются списки, определяющие точку и значение функции. Сначала переменная Lg устанавливается равной 1, после чего, используя второй цикл и переменную цикла s, перебираются элементы списка Data, и если выбранный элемент не совпадает с текущим элементом si, переменная Lg умножается на s[l]).
На заметку
Команда sl[l] возвращает в качестве значения узловую точку из списка, выбранного в первом цикле, в то время как с помощью команды s[l] возвращается узловая точка списка, выбранного во втором, вложенном в первый, операторе цикла. После выполнения внутреннего цикла переменная Lg представляет собой не что иное, как один из базовых полиномов, по которым строится интерполяционная функция.
Переменная Lg, после выполнения внутреннего цикла, умножается на значение функции в соответствующем узле (команда si[2]) и прибавляется к переменной L, которая предварительно, в самом начале процедуры, инициализируется с начальным значением, равным нулю. По окончании выполнения внешнего цикла, в переменной L будет записан интерполяционный полином Лагранжа. В этом полиноме собираются слагаемые при соответствующих степенях аргумента (команда collect (L,x)), а результат выполнения процедуры возвращается как функциональный оператор, действие которого на аргумент состоит в построении интерполяционного полинома по данным Data. Оператор задается командой unapply(L,x). После этого процедура готова к использованию.
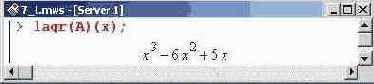
Для проверки работы последней создаем список А.

Если теперь по заданным точкам строить интерполяционную функцию, получим следующий полином третьей степени.
Внимание!
Поскольку процедура lagr(), согласно ее определению, является оператором, она должна действовать на аргумент, который и является переменной интерполирования.
Процедура определена таким образом, что точки интерполирования не обязательно указывать в порядке их естественного следования. Например, можем создать список А1, который получается из списка А путем перестановки элементов.

Как несложно проверить, интерполяционный полином при этом не меняется:

Ниже определим процедуру, которая будет отображать в области вывода график для интерполяционного полинома Лагранжа вместе с базовыми точками, по которым выполняется интерполяция.
Параметрами процедуры plotl() определим список базовых интерполяционных точек и переменную интерполирования. Код процедуры приведен ниже.
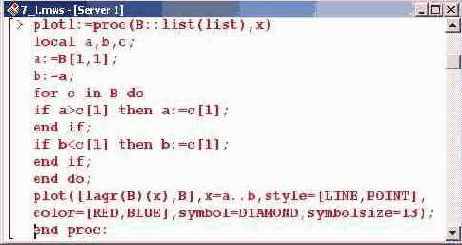
Локальные переменные а и b в теле процедуры используются для определения нижней и верхней границ области интерполирования соответственно Значения обеих переменных инициализируются равными первой указанной в списке-параметре процедуры интерполяционной точке (ссылка В [1,1]— первый элемент из первой пары "точка-значение" списка В). После этого перебираются все интерполяционные точки (ссылка с[1]), и если среди них встречается значение, меньшее текущего значения а, — оно присваивается этой переменной. Значение переменной b переопределяется в том случае, если выбранная точка имеет значение, большее текущего значения Ь. В результате выполнения цикла в переменной а будет записана самая левая точка, в переменной b — правая. Наконец, вызывается процедура отображения двухмерной графики plot(), в которой отображаемыми функциями указаны интерполяционный полином Лагранжа, построенный по точкам списка В, а также сами эти точки. Ниже приведен пример вызова разработанной только что процедуры.
Аппроксимация зависимостей интерполяционными полиномами Лагранжа наиболее эффективна, когда интерполируемая функция сама является полиномом. В этом случае, если взять достаточное количество базовых точек, можно добиться абсолютного совпадения. Однако подобные ситуации случаются не часто, и вопрос о погрешности, возникающей вследствие интерполяции, представляется актуальным. Что касается непосредственно метода Лагранжа, то на границах области интерполирования соответствующие полиномы могут в значительной степени отклоняться от прямой, соединяющей соседние точки. Последнее далеко не всегда приемлемо. В качестве примера рассмотрим "случайный" полином, т.е. созданный по базовым точкам, заданным генератором случайных чисел. Ниже приведен код для генерирования значений интерполируемой функции и результат его выполнения. Все команды объединены в одну исполнительную группу, так что для их выполнения достаточно щелкнуть кнопкой мыши на любой команде группы и нажать <Enter>. Результат выполнения в области вывода приводится сразу для всей группы.
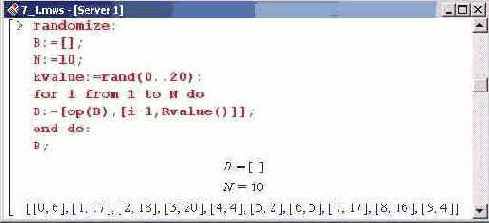
Первой в группе является команда randomize инициализации генератора случайных чисел. После этого в качестве пустого списка инициализируется переменная в. Значение переменной N, определяющей количество узлов, по которым будет строиться интерполяционный многочлен Лагранжа, установлено равным 10. Далее посредством команды rand(0..20) определяется процедура Rvalue(), которая будет генерировать случайное число в диапазоне от 0 до 20.
На заметку
По умолчанию процедурой rand() генерируется целое случайное число из двенадцати цифр
Затем выполняется оператор цикла, в котором переменная цикла i пробегает все значения в диапазоне от 1 до N. Для каждого значения переменной цикла список В дополняется новым элементом, который сам является списком из двух чисел и записывается в конец списка В. Узлами интерполирования являются точки с 0 по 9 включительно (в общем случае верхняя граница равна N-l), a значения функции в этих точках есть случайные числа в диапазоне от 0 до 20, и эти числа генерируются с помощью процедуры Rvalue(). В конце оператора цикла стоит двоеточие, чтобы в процессе дополнения списка В новыми элементами каждое обновленное значение переменной не выводилось на экран. После оператора цикла указана переменная В. В этом случае пользователь увидит уже окончательный список интерполяционных узлов.
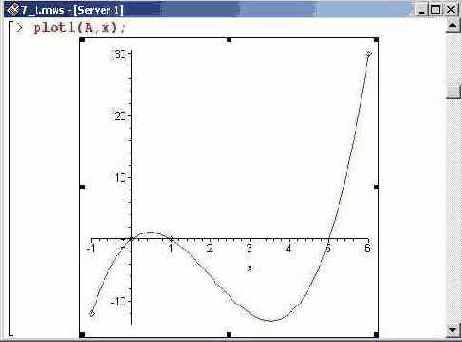
По сгенерированным таким образом точкам можно построить график интерполяционной функции. Делаем это посредством ранее созданной процедуры plotl(). Результат представлен ниже.
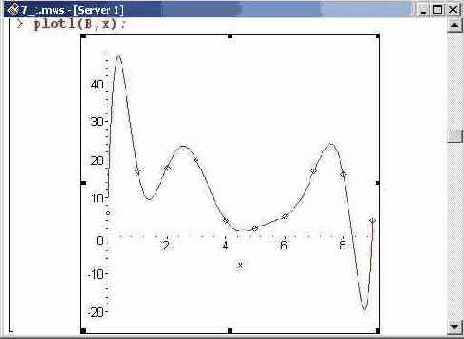
Как несложно заметить, на границах области интерполирования отклонения полинома действительно существенны.
Внимание!
Если пользователь скопирует приведенный выше программный код в рабочий лист Maple и несколько раз подряд выполнит его, то каждый раз он будет получать разные наборы базовых точек и, соответственно, будет видеть иную картинку
В общем случае, когда абсолютно ничего не известно об интерполируемой функции, сделать оценку для погрешности интерполяции невозможно Но такую оценку можно выполнить, если известны оценки для производных интерполируемой функции.
Внимание!
Погрешность при решении задачи интерполяции может быть вызвана следующими причинами Во-первых, существует погрешность, связанная с неточностью заданных узловых точек и значений интерполируемой функции в этих точках Во-вторых, погрешность возникает при вычислениях из-за округления чисел с плавающей точкой Наконец, существует погрешность вследствие замены исходной интерполируемой функции интерполяционным полиномом Здесь и далее речь идет именно о такой погрешности
Предположим, что число узловых точек, по которым выполняется интерполяция, равно п+1. Это автоматически означает, что порядок интерполяционного полинома равен п.
На заметку
Если число интерполяционных точек равно n+1, то полином может иметь порядок и ниже п Это имеет место, например, в тех случаях, когда интерполируемая функция сама является полиномом степени, меньшей n
Далее предположим, что производная порядка (n+1) от интерполируемой функции на интервале интерполирования не превышает по абсолютной величине значения М . Тогда погрешность интерполирования в точке х не превышает величины. Не затрагивая вопроса о том, как выполнить оценку для производной интерполируемой функции (это зависит от конкретных рассматриваемых ситуаций и выходит за рамки тема-лоси книги), разработаем процедуру, которая будет автоматически определять погрешность интерполирования при заданном значении М. Соответствующий программный код приведен ниже.
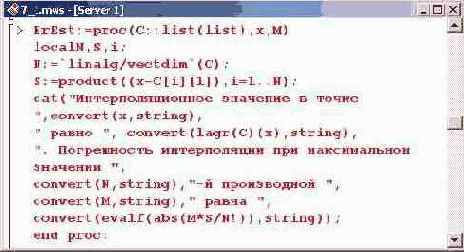
Процедура ErEst() имеет три параметра. Первым параметром является базовый список с интерполяционными точками. Второй и третий параметры — переменная интерполирования и оценка для производной интерполируемой функции соответственно.
Первой командой в теле процедуры определяется количество элементов в списке С. Для этого вызывается процедура vectdim() из пакета linalg. Полученное в результате число присваивается в качестве значения переменной N. Далее переменной S присваивается произведение, которое формируется процедурой product(). Множители в произведении— это разность переменной интерполирования и значения узловой точки. Ссылки на узловые точки выполнены в виде C[i][1] через индексную переменную!, которая пробегает значения от 1 до N. Погрешность интерполяции, таким образом, не превышает модуль (процедура abs()) величины MS/N1.
Внимание!
Элементы списка С нумеруются, начиная с индекса 1 и заканчивая индексом N. Число интерполяционных точек, таким образом, равно N. Порядок интерполяционного полинома равен N-1. Поэтому оценка М является верхней границей на интервале интерполирования для производной порядка N. Ведь порядок производной должен совпадать с числом точек и быть на единицу больше, чем порядок интерполяционного полинома. Отсюда в выражении для погрешности и далее для порядка производной указано N, а не N+1.
Результат выполнения процедуры оформляется в виде строки. Строка создается процедурой объединения cat(). Параметрами процедуры указаны базовые текстовые фразы вперемежку с командами преобразования численных выражений в строки. В последнем случае использована процедура convert () с опцией string.
Совет
Проверим, как работает созданная процедура. Для этого вызовем ее, указав в качестве базового интерполяционного списка созданный ранее генератором случайных чисел список В. Оценку для производной оставим в символьном виде. Кроме того, допускается использовать символьное выражение и для второго аргумента. Ниже приведен результат для точки х=2.5.

Если третьим параметром указать число, погрешность также будет представлена числом. Посмотрим, что произойдет, если в качестве второго параметра указать узловую точку.

Ничего удивительного в том, что погрешность равна нулю, нет. Ведь в узловой точке, по определению, значение интерполяционного полинома точно совпадает со значением функции.
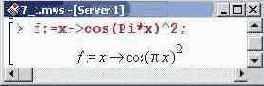
Нетрудно понять, что погрешность интерполирования зависит не только от интерполируемой функции, но и от выбора интерполяционных точек. Проиллюстрировать это можно следующим примером. Определим тригонометрическую функцию.
После этого создаем два списка. В каждом из этих списков табулируем значения функции по пяти узловым точкам. Однако узловые точки в каждом случае выбраны по-разному.
В первом случае выбираем равноудаленные узлы.
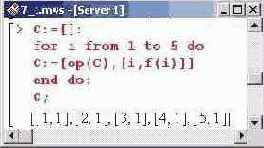
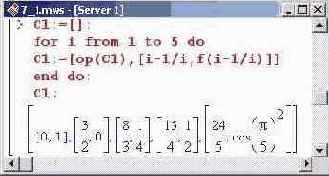
Во втором случае узлы выбираются согласно формуле xi=(i-l/i), а индексная переменная i пробегает значения от 1 до 5.
Теперь на одном рисунке отобразим все три графика: для интерполируемой функции и двух интерполяционных полиномов для каждого набора точек. Точки из первого набора, определяемого списком С, обозначены квадратами, а из второго набора, определяемого списком С1, — кругами.
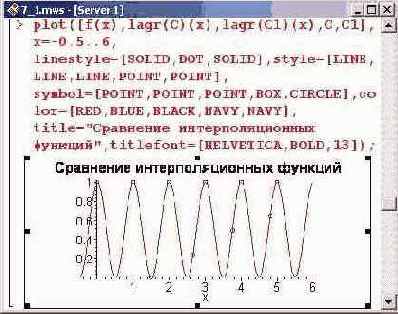
Как видно из рисунка, интерполяционные полиномы весьма далеки от совершенства. Полином по первому множеству вообще представляет собой прямую. Поэтому естественным образом возникает вопрос о том, как следует выбирать интерполяционные точки, чтобы полином наиболее адекватно описывал интерполируемую функцию. Понятно, что если исходная функция неизвестна и узловые точки заданы a priori, постановка такой задачи не имеет смысла. Однако, как уже отмечалось, часто нужно интерполировать известную функцию. В этом случае задача выбора узловых точек на интервале интерполирования полностью ложится на пользователя.
Не вдаваясь в детальный теоретический анализ, сформулируем сразу ответ (читателей, интересующихся данной проблемой, отсылаем к специальной литературе). Состоит он в том, что нам понадобится вычислить нули ортогональных полиномов Чебышева. Зачем это делается, будет объясняться по ходу изложения материала.
В главе 3 об ортогональных полиномах Чебышева первого рода речь уже велась. Можно, разумеется, использовать встроенную команду для вызова соответствующего полинома. Однако поскольку способ их определения достаточно прост, зададим собственную функцию, зависящую от двух аргументов: индекса полинома и непосредственно полиномиальной переменной.

Прежде чем искать нули полиномов, изменим значение переменной среды _EnvAllSolutions. Это нужно для того, чтобы при решении соответствующего уравнения искались все решения.

Теперь находим нули полинома Чебышева первого рода индекса n.

Решение представлено через переменную среды _Z1, которая в области вывода сопровождается тильдой. Это значит, что на переменную наложены ограничения. Чтобы узнать, каким условиям эта переменная должна удовлетворять, воспользуемся процедурой about().
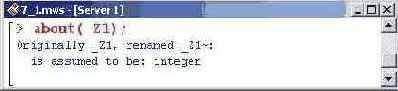
Перевод содержимого области вывода гласит, что исходная переменная _Z1 переименована в Z1" и предполагается, что это целое число.
Теория говорит о том, что для построения оптимального полинома, который при прочих неизменных условиях будет аппроксимировать функцию на интервале от -1 до 1 с наименьшей погрешностью (наименьшая верхняя граница для погрешности), в качестве базовых узлов следует взять нули полинома Чебышева порядка, который равен числу узловых точек. Другими словами, если базовый полином строится по 10 точкам, то и полином следует брать с индексом 10. Если интерполяция выполняется на интервале (а,Ь), отличном от интервала (-1,1), то узловые точки все равно выражаются через нули указанного полинома согласно формуле хя =((Ь-а)со&{(2т+1)n/2n)+(Ь + а))/2.
Количество нулей полинома совпадает с его порядком. Чтобы перебрать все эти нули, достаточно предположить, что переменная среды принимает значения от 0 до n-1, где n — порядок полинома. Ниже приведен код процедуры, которой выполняется вычисление базового узла с индексом m на интервале (а,Ь) при общем количестве узлов n.

В качестве интерполируемой возьмем функцию Бесселя нулевого порядка.

Ниже в качестве пустого списка инициализируется переменная Fp. Далее вычисляются узловые точки (переменная X) и значения интерполируемой функции в этих точках (переменная Y), после чего эти данные заносятся в список Fp. Стоит обратить внимание на то, что как точки, так и значения функции, вычисляются в формате чисел с плавающей точкой. Весь описанный блок команд размещен ё одной исполнительной группе. В самом конце этой группы указана команда вывести окончательное значение списка Fp.
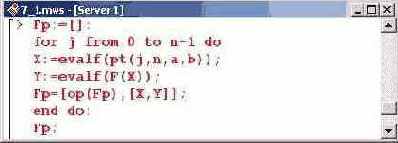
Теперь по этим базовым точкам можно построить интерполяционный полином. На графике, представленном ниже, показана исходная функция, точки интерполяции и интерполяционный полином.
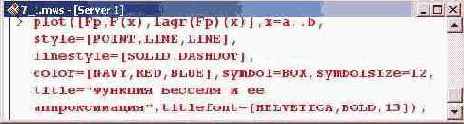
Можем получить выражение для представленного выше на рисунке полинома.

Поскольку элементы списка Fp, по которому строился полином, определялись в формате числа с плавающей точкой, в таком же виде представлены и коэффициенты интерполяционного полинома.
Содержание