Математический анализ в Maple 9
Численное дифференцирование
Очень часто приходится сталкиваться с ситуацией, когда при численном решении той или иной задачи необходимо вычислить производную или решить дифференциальное уравнение — в численном виде, разумеется. В этих случаях используется все та же процедура dsolvef), что уже встречалась ранее при решении дифференциальных уравнений в аналитическом виде. Однако для нахождения численного решения (или производной в численном виде) при вызове процедуры следует указать опцию numeric. Во всем остальном синтаксис вызова процедуры практически такой же, как и при поиске аналитических решений, но некоторые отличия все же имеются.
Процедура может использоваться, как уже отмечалось, для вычисления производных, а также решения задач Коши и краевых задач. По умолчанию при решении задач Коши применяется метод Рунге-Кутта-Фэлберга (Runge-Kutta-Fehlbeig) порядка четыре-пять, а при решении краевых задач — экстраполяция Ричардсона (Richardson). Метод может быть изменен явным указанием значения опции method. Возможные значения опции и их описание приведены в табл. 7.4.
Таблица 7.4. Значения опции method
| Значение опции | Описание |
| bvp | Используется при решении краевых задач. Тип задачи (то ли это задача Коши, то ли краевая задача) вычислительным ядром Maple определяется автоматически Поэтому значение для опции указывается в таком формате: method=bvp[метод] В качестве iaoiaa могут указываться значения: trapdef er (метод трапеций), middef ег (метод средней точки), traprich (усовершенствованная схема для метода трапеций) или midrich (усовершенствованная схема для метода средней точки). По умолчанию используется метод traprich |
| classical | Классический метод построения численного решения. Допускается два типа определения значения: method=classical или method-classical [метод]. Здесь метод может быть таким: f oreuler (прямой метод Эйлера; используется по умолчанию), heun-f orm (усовершенствованный метод Эйлера, или правило трапеций), impoly (модифицированный метод Эйлера), rk2 (классический метод Рунге-Кутта второго порядка), гкЗ (классический метод Рунге-Кутта третьего порядка), rk4 (классический метод Рун-ге-Кута четвертого порядка), adambash (метод Адамса-Бэшфорда (Adams-Bashford), или метод предиктора) или abmoulton (метод Адамса-Бэшфорда-Молтона (Adams-Bashford-Moulton), или метод предиктора-корректора) |
| dverk78 | Метод Рунге-Кутта порядка семь-восемь |
| gear | Метод простой экстраполяции. Метод можно конкретизировать, указав method=gear[bstoer] или method=gear[polyextr]. В первом случае используется рациональная экстраполяция, во втором — полиномиальная |
| lsode | Опция активизации утилиты решения жестких дифференциальных задач. Допускается восемь встроенных методов, среди которых вызываемый по умолчанию метод Адамса с использованием функциональных итераций без вычисления функционального определителя (adamsf unc), метод Адамса с использованием итераций и вычислением полного функционального определителя (adamsf ull), метод Адамса с использованием итераций и вычислением диагонального функционального определителя (adamsdiag), метод Адамса с вычислением ленточного функционального определителя (adamsband), метод обратного дифференцирования с использованием функциональных итераций (backf unc), метод обратного дифференцирования с использованием итераций и вычислением полного функционального определителя (backf ull), метод обратного дифференцирования с использованием итераций и вычислением диагонального функционального определителя (backdiag) и метод обратного дифференцирования с использованием итераций и вычислением ленточного функционального определителя (backhand). При использовании методов adamsband и backhand необходимо также задавать параметры функциональной матрицы |
| rkf45 | Метод Рунге-Кутта-Фэлберга порядка четыре-пять |
| rosenbrock | Метод Рунге-Кутта-Розенброка (Rosenbrock) порядка три-четыре |
| taylorseries | Решение ищется в виде разложения в ряд Тейлора |
Кроме опции method, могут быть задействованы и другие опции. Они приведены в табл. 7.5.
Таблица 7.5. Некоторые опции процедуры dsolve()
| Опция | Тип значения | Описание |
| abserr | Число | Опцией устанавливается допустимая погрешность. Опция может использоваться со всеми методами, кроме classical. Кроме того, в методе rkf-45 допустимая погрешность фиксирована и определяется в основном значением переменной среды Digits |
| output | Ключевое слово или массив | Значением может быть одно из ключевых слов — procedurelist (значение по умолчанию), listprocedure или piecewise (добавлено в Maple 9) или список значений переменной, для которых следует вычислить значение выражения. При значении опции, равном procedurelist, независимая переменная является аргументом процедуры, а результат выводится в виде списка, в котором указываются через знак равенства: независимая переменная и ее значение, зависимая переменная и ее значение, производные от зависимой переменной по независимой и их значения. Если значение опции установить равным listprocedure, то результат для перечисленных выше параметров будет выводиться не через указание их значений, а через указание процедур, которые могут быть использованы для вычисления значений. Ключевое слово piecewise используется только при работе с методами rkf 45 и rosenbrock и позволяет выводить результат в виде кусочно-непрерывной зависимости |
| range | Диапазон с численными границами | Опцией задается диапазон изменения независимой переменной |
| relerr | Число | Предел для относительной погрешности. Опция не может использоваться при выполнении расчетов методами classical, taylorseries и bvp |
| stiff | Логический тип | Если установить значение опции равным true, то вместо используемого по умолчанию нежесткого метода rkf 45 будет вызван метод rosenbrock. Если при этом также явно задан используемый метод, то выполняется проверка на предмет его соответствия значению опции stiff |
| stop cond" | Список | Значением функции задается список условий приостановки процесса вычислений. Опция может использоваться для вызываемых по умолчанию нежесткого метода rkf 45 и жесткого метода rosenbrock |
Кроме перечисленных выше опций, общих для процедуры dsolve(), при работе с каждым конкретным методом можно использовать специфичные именно для этого метода опции. Подробнее о них читатель может узнать, обратившись к справочной системе.
Ниже показано, как следует вызывать процедуру dsolve() для численного решения дифференциальных уравнений.
В качестве первого примера рассмотрим уравнение первого порядка.

С учетом начального условия решим данное уравнение в численном виде (решать уравнение в численном виде без начальных условий крайне проблематично).
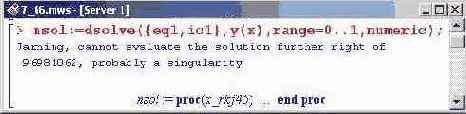
Прежде чем появится результат, выводится сообщение, гласящее буквально следующее: "Внимание, невозможно определить значение далее .96981062, возможна сингулярность". Поэтому значения функции будем определять только на интервале от 0 до указанного выше значения. Для того, чтобы вычислить значение функции в точке, следует указать эту точку аргументом определенной выше процедуры nsol(). Например, значение в нуле вычисляется так.

На заметку
В данном случае в результате выполнения команды nsol(0) выводится список, в котором указано значение точки и значение функции в этой точке. В общем случае в таком списке присутствует еще и значение для всех производных вплоть до порядка, на единицу меньшего порядка старшей производной в решаемом уравнении. Поскольку старшей производной в данном уравнении является производная первого порядка, в списке представлены только точка и значение функции в этой точке.
Выведем численные значения функции на интервале от 0.1 до 0.8 с шагом 0.1. Результат представлен ниже.
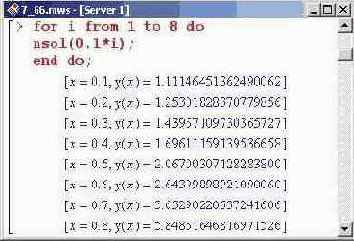
Сами по себе эти значения мало о чем говорят. Интересно их сравнить с точным решением уравнения. Maple с такой задачей справляется, однако результат довольно громоздок. Нас интересуют значения функции только в некоторых точках, причем значения эти, чтобы их можно было сравнивать, должны быть в формате чисел с плавающей точкой. Поэтому поступим следующим образом: решим уравнение, а к полученному результату применим операцию выделения функциональной зависимости unapply(). Результат присвоим переменной f, но выводить на экран его не будем.

Внимание!
Результатом решения уравнения является, как известно, равенство. Если процедуру unapply() применить к равенству, то получим оператор, действие которого на аргумент состоит в восстановлении равенства, правда, уже с переменной, указанной аргументом оператора. Это замечание важно для понимания результата выполнения команд, приведенных ниже.
Выведем значения функции, полученной в качестве точного решения.
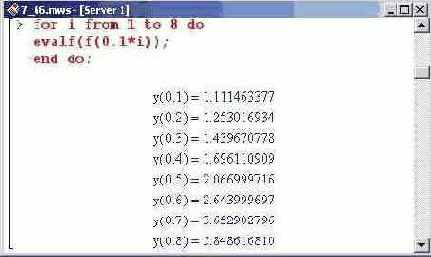
Как несложно заметить, совпадение данных более чем приемлемое.
Теперь попробуем "обойти" особенность, о которой шла речь в полученном выше предупреждении. Для этого в процедуре численного дифференцирования используем альтернативный метод вычислений. По сравнению с предыдущим случаем ниже будут внесены два существенных изменения. Во-первых, явно указано, что следует использовать классический метод (method=classical). Во-вторых, указано значение опции output, которое является массивом с явно выписанными точками, в которых будет вычисляться значение функции. Поэтому после выполнения соответствующей команды переменной nsol2 будет присвоена в качестве значения структура (матрица) с точками и значениями функции в этих точках.
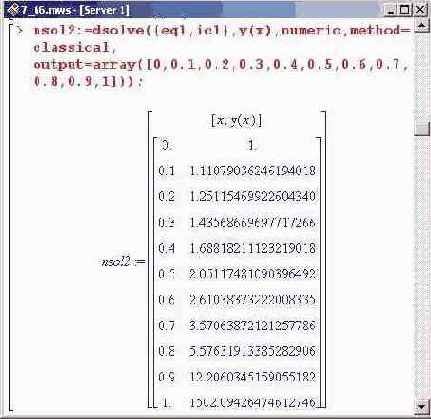
Никакие предупреждающие сообщения в данном случае не появляются, и значения для функции вычисляются для всего указанного диапазона. Однако точность оставляет желать лучшего.
Рассмотрим другое уравнение, уже второго порядка.

Поскольку выше значение опции output указано равным listprocedure, в результате возвращается список равенств, левые части которых — переменная, функция и производная от этой функции, а правые части — процедуры, с помощью которых соответствующие значения могут быть вычислены. Предположим, что нас интересует значение производной функции в точке х. Тогда можем определить функциональный оператор dy.

Выше процедура eval () после оператора присваивания первым параметром содержит производную от функции у(х) по переменной х, а вторым параметром является определенная ранее процедура nums. В этом случае выражение (производная), указанное первым аргументом, вычисляется с использованием процедуры nums. Значения для производной на множестве точек можем получить следующим образом.
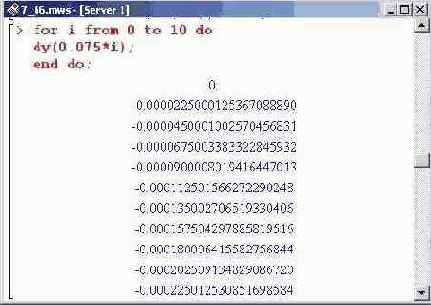
Аналогичным образом вычисляются и значения самой функции. Проверим, как численные методы работают при решении краевых задач. С этой целью определим следующее уравнение.
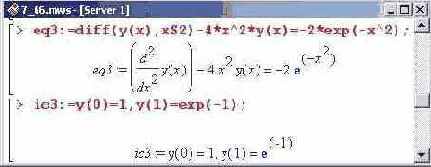
Будем вычислять значения функции на интервале от 0 до 1 с шагом 0.1. Для этого вводим такую команду (метод решения краевой задачи вычислительным ядром определяется автоматически на основе классификации задачи).
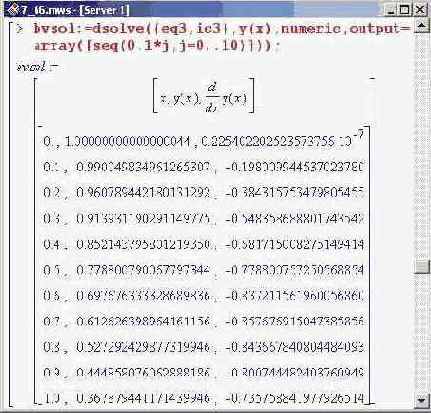
Как всегда, сравниваем численное решение с точным. Определяем функциональный оператор, задающий точное решение задачи.
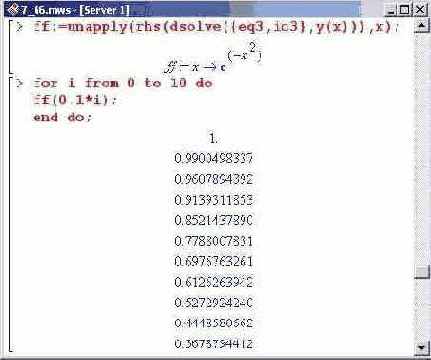
Совпадение хорошее. Однако следует проверить точность вычисления не только функции, но и ее производной.
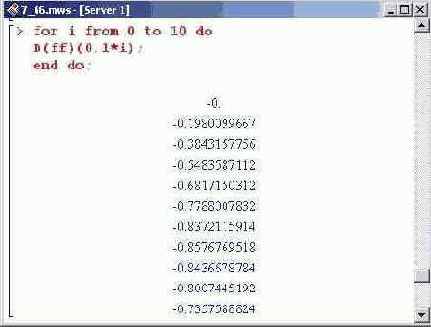
Как видим, производная также вычисляется достаточно корректно.